[딥러닝/컴퓨터비전] 2장 - Image Classification
Image Classification이란 주어진 이미지에 대한 label을 붙이는 것이다. 이번 단원에서는 Tensorflow를 이용하여 classification을 직접해보고, 정확도를 어떻게하면 높일 수 있을까에 관해 공부한다.
📃 2단원 학습목표
- MNSIT 학습하기
- 다른 이미지 데이터셋으로 적용해보기
- 이미지 classfication에 적용할 만한 딥러닝 모델
- cat vs dog 분류해보기
📕 Training the MNIST model in Tensorflow
The MNIST datasets
먼저 시작에 앞서, MNIST가 무엇인지 알아보자.
MNIST란? Modified National Institute of Standards and Technology의 약자로, 0부터 9까지 10개의 숫자를 손글씨로 쓴 데이터 셋이다. 약 60000개의 training 데이터와 10000 testing 데이터가 있다. 이미지는 28x28의 크기로 이루어져있으며, gray scale이다.
아래 링크를 통해서 데이터셋 다운로드 링크로 갈 수 있다.
THE MNIST DATABASE of handwritten digits
위 링크를 거치지 않고 텐서플로우에서 직접 사용하는 방법도 있다. 나는 이 방법을 이용해서 데이터를 불러왔다.
Loading the MNIST data
이제 텐서플로우를 이용하여 학습하기 전에 MNIST 데이터를 불러와야한다.
책에는 다음과 같은 코드로 불러온다고 되어 있는데 실행하면 ModuleNotFoundError: No module named 'tensorflow.examples' 와 같은 에러가 발생한다.
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets('MNIST_data', one_hot = True)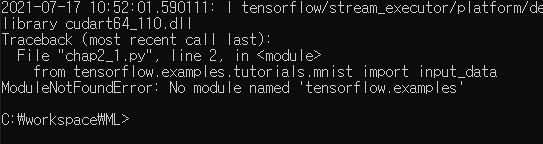
이 책이 2018년에 쓰여져 tensorflow.examples.tutorials 폴더가 없어 발생하는 문제다. 따라서 본 내용은 tensorflow 공식 홈페이지에서 제공하는 내용으로 공부하였다.
먼저 tensorflow를 import하고, 사용하고자 하는 mnist 데이터셋을 불러온다.
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255.0 ,x_test/255.0먼저 train데이터와 test 데이터로 나누고, x input 값과 y라벨 값으로 분리하여 load data를 실행한다.
test와 training input값에 각각 255.0으로 나누어준 이유는 부동소수점으로 샘플값을 변환하기 위함이다.
위를 실행하면 다음과 데이터가 로드 되는 모습을 볼 수 있다.

batch 설정하기
batch란?
모델을 학습할 때, 학습 데이터를 한꺼번에 하지 않고, 여러 group으로 나누어 학습을 진행한다. 이렇게하면 학습 속도를 높일 수 있다. 이러한 작은 group을 batch라고 한다.
tf.data이용하여 batch 설정하기
이번에는 batch를 설정해줄 것이다.
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(100000).batch(32
test_ds = tf.data.Dataset.from_tensor_slices(
(x_test,y_test)).batch(32)입력 데이터를 batch로 나누는 것이기 때문에 training data set 과 testing data set에 해당하는 데이터를 batch로 나눈다.
tensorflow에서 제공하는 data모듈을 이용할 것이다. tf.data.Dataset에서 (x_train,y_train) 값을 shuffle 함수를 이용하여 섞어준다. batch 함수를 이용하여 파라미터의 개수만큼 batch를 생성한다.
모델 생성하기
모델을 생성하기 위한 방법으로는 sequential 모델, functional 모델, subclassing 모델이 있는데 아래는 subclassing 모델로 생성하였다.
subclassing 모델 방식으로 모델을 생성하는 경우, 모델을 직접 하나의 class로 생성하여 init에는 사용할 layer들을 작성하고, call 함수에서는 init에서 사용한 layer들을 배치한다.
class MyModel(tf.keras.Model) :
def __init__(self): #객체 생성할 때 호출
super(MyModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(32,3,activation = 'relu')
self.flatten = tf.keras.layers.Flatten()
self.d1 = tf.keras.layers.Dense(128, activation ='relu')
self.d2 = tf.keras.layers.Dense(10, activation = 'softmax')
def call(self, x): #인스턴스 생성할 때 호출
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
model = MyModel()init 함수를 살펴보면, 사용하고자 하는 layer들을 생성하였다. tf.Keras는 딥러닝 모델을 빌드하고 학습하기 위한 API를 제공한다. 이를 이용하여 모델의 일부 요소인 layer들을 생성할 수 있다.
- Conv2d() : convolution 레이어
- Flatten(): 이미지 배열을 flat하게 1차원의 배열로 변환한다.
keras.layers.Flatten(input_shape=(28, 28)),위의 코드는 28x28의 이미지를 flatten 한다는 의미이다.
- Dense(): dense-즉 밀집하게 연결되어 있는 층을 의미한다. 이를 fully-connected라고도 한다.
keras.layers.Dense(128, activation='relu'),첫번째 파리미터는 128개의 node를 가진다는 의미이다. 두번째 파리미터는 activation function을 설정한 것이다.
모델 학습 하기
-
Loss function(손실함수)
모델이 파라미터를 학습하기 위해서는 Loss를 최소화하는 방향으로 진행해야한다. 이 loss를 계산하기 위한 function을 설정해볼 것이다.
예제로 이용할 loss function은 categorical crossentropy로 classification 라벨이 3개 이상인 경우 one-hot 으로 많이 사용된다. -
optimizer 란?
optimizer란 loss를 어떠한 방식으로 최소화 할 것인지를 결정하는 것이다. SGD(stochastic gradient descent), GD(gradient descent) 등의 방법이 있다. 본 예제에서는 Adam optimizer을 이용하여 진행한다.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()- 측정 지표 정하기: tf.keras.metrics.Mean
이 측정 값을 바탕으로 해서 최종 결과물을 내어 놓는다.
train_loss = tf.keras.metrics.Mean(name = 'train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name = 'train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
모델 훈련하기
tf.GradientTape란?
Tensorflow에서는 미분을 계산하기 위한 gradientTape라는 API를 제공한다. gradient 인 미분 값을 tape에 저장한다는 의미이다. 이를 활용하여 모델을 훈련해보려고 한다.
@tf.function
이러한 표현을 파이썬 함수 앞에 쓰고 적으면, 파이썬 함수를 tensorflow operation과 같이 사용할 수 있다는 것을 의미한다.
#모델 훈련 시키기
@tf.function
def train_step(images,labels):
with tf.GradientTape() as tape:
#모델로 예측한 값
predictions = model(images)
# loss function으로 계산한 loss
loss = loss_object(labels, predictions)
#tape에서 gradient 값
gradients = tape.gradient(loss, model.trainable_variables)
#optimizer로 update
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(lables, predictions)모델 테스트하기
Epoch란?
Epoch의 사전적인 의미는 '시대'이다. 딥러닝에서는 이를 학습 횟수를 뜻한다. 즉, training set이 전체 신경망을 몇번 통과 했는지를 의미한다.
다음은 모델을 test하기 위해 정의된 test_step function이다.
# 학습된 모델 test하기
@tf.function
def test_step(images, labels):
#모델로 예측한 값
predictions = model(images)
#실제 vs 예측값 비교한 loss 값
t_loss = loss_object(labels, predictions)
#정확도 계산하기
test_loss(t_loss)
test_accuracy(labels, predictions)이 모델을 이용하여 epoch 5로, training과 testing을 진행해보았다.
EPOCHS = 5
for epoch in range(EPOCHS):
#training
for images, labels in train_ds :
train_step(images, labels)
#testing
for test_images , test_labels in test_ds:
test_step(test_images, test_labels)
# 결과값 출력
template = '에포크: {}, 손실: {}, 정확도: {}, 테스트 손실: {}, 테스트 정확도: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))전체 코드
import tensorflow as tf
from tensorflow.keras.models import Sequential
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train/255.0 ,x_test/255.0
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(100000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test,y_test)).batch(32)
class MyModel(tf.keras.Model) :
def __init__(self): #객체 생성할 때 호출
super(MyModel, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(32,3,activation = 'relu')
self.flatten = tf.keras.layers.Flatten()
self.d1 = tf.keras.layers.Dense(128, activation ='relu')
self.d2 = tf.keras.layers.Dense(10, activation = 'softmax')
def call(self, x): #인스턴스 생성할 때 호출
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
return self.d2(x)
model = MyModel()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name = 'train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name = 'train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
#모델 훈련 시키기
@tf.function
def train_step(images,labels):
with tf.GradientTape() as tape:
#모델로 예측한 값
predictions = model(images)
# loss function으로 계산한 loss
loss = loss_object(labels, predictions)
#tape에서 gradient 값
gradients = tape.gradient(loss, model.trainable_variables)
#optimizer로 update
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
# 학습된 모델 test하기
@tf.function
def test_step(images, labels):
#모델로 예측한 값
predictions = model(images)
#실제 vs 예측값 비교한 loss 값
t_loss = loss_object(labels, predictions)
#정확도 계산하기
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
#training
for images, labels in train_ds :
train_step(images, labels)
#testing
for test_images , test_labels in test_ds:
test_step(test_images, test_labels)
# 결과값 출력
template = '에포크: {}, 손실: {}, 정확도: {}, 테스트 손실: {}, 테스트 정확도: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))결과
실행 시 아래와 같은 결과가 나왔다.

설정한 5 EPOCH만큼 실행이 되었으며 뒤의 Epoch 일수록, 정확도가 95.8% 부터 시작하여 98%까지 높아진 것을 확인할 수 있었다. loss도 0.1에서 0.04까지 줄어들었다.
느낀점
딥러닝을 이용하여 image classification 실습을 처음부터 끝까지 진행해보았다. 전체적인 과정이 어떻게 이루어져있는지 이해할 수 있게 된 것 같다. 다음으로는 tensorboard 이용하기, CIFAR 데이터 셋으로 이용하는 등의 실습을 진행할 예정이다.
