
What is abstraction? (추상화란 무엇인가?)
추상화(abstraction)이란, 시스템의 viewer의 관점에서 필수적인 세부사항들만 포함하고 있는, 복잡한 시스템의 모델이다.
즉, 프로그램들은 추상화이다. -> 우린 프로그램이 무엇(what)인지 알아도, 어떻게 동작하는 지는 모른다.
Abstract Data Type(ADT)
자료 자체의 형태와 그 자료에 관계된 연산들을 수학적으로만 정의한 것.
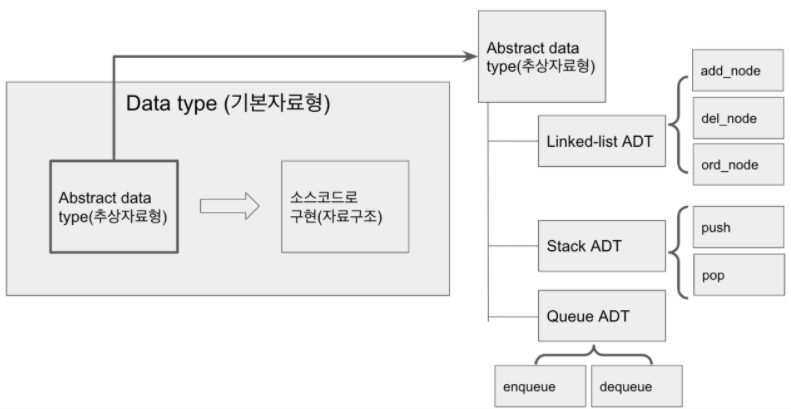
- ADT는 DATA + Operations로, 어떤 형태로 보관하고, 어떻게 접근하며 검색하고 계산할지에 대한 것이다.
예시 Python - list
test = []
test.append(1)
test.append(3)
test.append(5)
print(test)
test.remove(5)
print(test)test라는 리스트의 요소들이 어떻게 출력될지 예상이 되는가?
=> [1,3,5] // [1,3] 이렇게 출력이된다.
하지만 test라는 리스트의 요소들이 어떻게 리스트에 추가되고, 빼지는지 동작 상으로 알 수 있는가?
=> 모른다. 그저, 함수를 통해 리스트의 자료를 추가하고 뺄 뿐이다.
-
그렇다면 리스트와 같이 자료가 어떻게 넣어지고 빼지는 지 동작에 대해 일일이 알아야하는가?
-
아니!! 그럴 필요없다!!!
-
우린 이미 동작하는 방식을 알고 있다. 어떻게 동작하는지를 모를 뿐이다.
-
자동차를 몰기 위해서 자동차 엔진이 어떻게 바퀴를 굴리는지 알 필요가 있는가?
-
Information Hiding (정보은닉)
객체에 대한 구체적인 정보를 노출시키지 않도록 하는 기법. / 필수적인 것에만 접근하도록 허용하고 나머진에는 접근을 금한다.
오로지, public 상호작용과 방식으로만 접근이 허용된다.
캡슐화(encapsulation)과 유사하다.
- 방금전 리스트를 떠올려보아라.
test = []
test.append(1)
test.append(3)
test.append(5)
print(test)
test.remove(5)
print(test)
- 실제 test 리스트가 어떻게 동작하는가?
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject
-> 우린 실제로 **ob_item에 접근할 수도, 수정할 수도 없다. : Information Hiding
Data Structure
자료구조란, 대량의 데이터를 효율적으로 저장, 조직, 관리, 수정하기 위해 논리적 규칙에 따라 데이터를 배치하는 구조를 뜻한다.
-
자료구조의 특징들
-
여러 데이터들의 집합체인 만큼 구성 요소로 분해될 수 있다.
-
각각의 요소들을 어떻게 배치하냐에 따라, 접근 방식이 달라진다.
-
배치와, 그들에게 접근하는 방식은 캡슐화가 되어있다.
-
Composite Data Type (복합 데이터)
복합 데이터란, 각각의 데이터 구성요소가 하나의 변수 이름 아래에 저장될 수 있는 데이터 타입을 의미한다.
개별 데이터 요소들을 접근하는 것을 허용한다
-
예시
-
Array (structured) - homogenous
-
Class (unstructured) - unhomogenous
-
Struct (unstructured) - unhomogenous
-
Memory Allocation
-
우리가 사용하는 PC는 어떻게 프로그램을 돌리는 것인가?
Memory Allocation - Variables
프로그램이 실행될 때, 운영체제는 자동적으로 프로그램이 필요한 메모리를 할당해준다.
object가 만들어진다면, 멤버들을 위한 메모리 공간이 할당된다.
-> 이때 이 메모리를 보다 효율적이고, 안정적으로 프로그램이 돌아갈 수 있도록 최적화된 메모리 운영방식에 '자료 구조'개념이 필요하다.
============================================================
추가 개념
One - Dimensional Array
-
1차원 배열은 유한한 크기의 특정 데이터만 저장이 가능하다.
-
각 요소들의 위치는 직접적으로 접근이 가능하다. (인덱스 개념 사용)
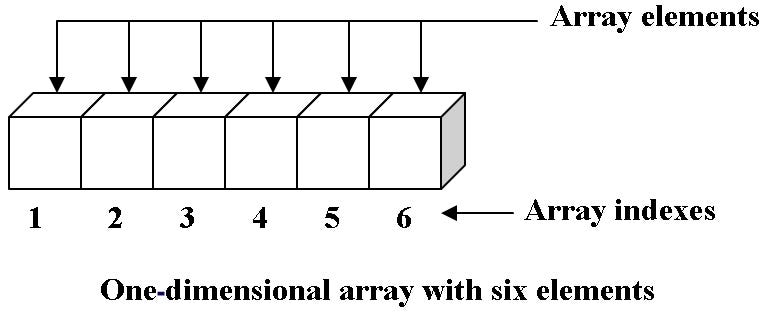
-
Address[index] = BaseAddress + Index * Size Of Element
-
BaseAdress는 첫 번째 요소의 메모리 위치이다.
Two - Dimensional Array
- 2차원 배열은 유한한 크기의 특정 데이터만 저장이 가능하다.
- 각 요소들의 위치는 직접적으로 접근이 가능하다. (인덱스 개념 사용)
- 각각의 위치는 행과 열의 개념으로 한 쌍의 인덱스의 값이 저장되어 사용된다.
- 메모리에선 2차원 배열이 선형으로 일직선 형태로 저장된다.
- Address[row][col] = BaseAddress + (row x column 길이' + guswo colmun) x Size Of Element
