List Definitions
-
Linear relationship
- 각각의 요소들은 첫 번째를 제외하면, prdecessor(전임자)가 있고, 마지막을 제외하면, successor(후임자)가 있다.
-
Length
- 리스트안의 항목들의 갯수들이다.
Unsorted List
-
Unsorted List : 리스트의 아이템이 정렬되지 않은 리스트를 의미한다.
-
Logical level
-
Constructor
- Class Name
-
Transformer
-
appendItem(value)
-
insertItem(pos,value)
-
removeItem(value)
-
updateItem(pos,new_value)
-
clear()
-
-
Observer
-
size()
-
isFull()
-
isEmpty()
-
findItem(item)
-
getItem(pos)
-
-
<리스트 그림>
Unsorted List의 동작설명
-
appendItem()
-
넣고자 하는 리스트에 isFull()인지 확인을 한다.
- isFull이면 아무것도 리턴하지 않는다.
-
이후 현재 data의 length(아이템 갯수)의 인덱스를 통해 새로운 값을 넣는다.
-
이후 length에 1을 더해 length을 최신화 해준다.
-
-
insertItem()
-
넣고자 하는 리스트에 isFull()인지 확인을 한다.
- isFull이면 아무것도 리턴하지 않는다.
-
이후 원하는 위치의 인덱스에서 부터 뒤까지 한 칸씩 value를 뒤로 이동시킨다.
-
그리고 리스트에 넣고자 하는 위치에 사용자가 지정한 value값을 다시 붙인다.
-
이후 length에 1을 더해 length을 최신화 해준다.
-
-
appendItem() vs insertItem()
-
appendItem은 item의 value를 리스트의 맨 마지막에 추가해준다.
-
insertItem은 item의 value를 사용자가 원하는 특정한 위치에 추가해준다.
-
시간복잡도는 insertItem이 더 오래 걸린다.
-
appendItem() -> O(1) // insertItem() -> O(N)
-
-
insertItem()은 O(N)이 최선인가?
-
insertItem의 시간복잡도가 O(N)이 최선이지 않다.
-
new_insertItem()의 동작
-
새롭게 추가하고자 하는 Item의 위치의 원래 값을 리스트 맨 뒤로 이동시킨다.
-
그 후 추가하려는 value를 사용자가 원하는 위치에 값을 붙인다.
-
-
리스트의 맨 뒤로 이동하는 시간 복잡도 = O(1)
-
사용자가 원하는 위치에 값을 붙이는 시간 복잡도 = O(1)
-
최종 시간 복잡도 O(1+1) = O(2) = O(1)
-
-
removeItem()
-
리스트에 제거하고자 하는 Item의 위치를 찾는다 --> K라 가정
-
이후 K번째 값으로 한 칸씩 앞으로 당긴다. --> N - K번
-
리스트의 전체 길이 length의 값에서 1을 뺀다. -- 1번
-
최종 Big - O 값 : O( N - K + 1 ) = O( N )
-
-
removeItem()은 O(N)이 최선인가?
-
removeItem의 시간복잡도가 O(N)이 최선이지 않다.
-
new_removeItem()의 동작
- 없애고자 하는 Item의 위치의 원래 값에 리스트 맨 뒤의 값을 적용시킨다.
- 그 후 리스트의 전체 길이 length의 값에서 1을 뺀다.
-
-
updateItem()
-
update하고자 하는 위치가 length보다 크거나 같으면 그냥 return한다.
-
그렇지 않을 경우 리스트의 위치에 새로운 값을 덧붙인다.
-
시간복잡도 : O(1)
-
-
clear()
-
length의 값을 0으로 전환한다.
-
시간복잡도 : O(1)
-
-
findItem()
- 리스트의 인덱스 값을 0으로 초기화한다.
- 인덱스 값이 length보다 작을 때까지 리스트의 item에 유저가 원하는 item이 있는지 확인하고 있으며, True, 없으면 False를 반환한다.
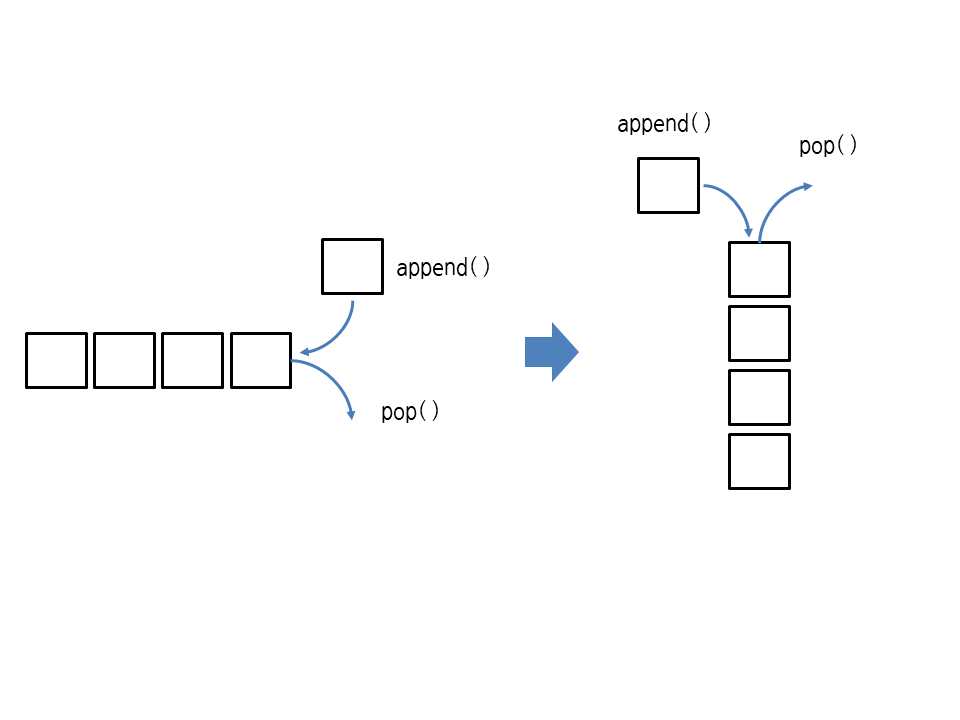
<pop과 append의 설명 그림>
Sorted List
-
Sorted List : 리스트의 아이템이 정렬의 기준(key)을 가지고 의미 있는 관계로 배열된 리스트를 뜻한다.
- Key : 정렬의 기준이자 논리적 순서를 결정하는 속성이다. ex). 나이, 성별...
Sorted List 동작설명
-
insertItem()
-
추가하고자 하는 Item의 적절한 위치를 찾아낸다. --> N번 가정
-
한칸씩 나중 item들의 위치를 옮겨준다. --> N-K라 가정
-
사용자가 원하는 아이템을 추가해서 넣는다. --> 1
-
리스트의 length값에 1을 더해준다. --> 1
-
시간 복잡도 : O(2N + 2 - K) = O(2N) = O(N)
-
-
finditem()
-
기본적인 동작 : 선형탐색
-
리스트의 모든 Item들을 하나씩 비교해가며, 찾아본다.
- 시간 복잡도는 O(N)이다.
-
이게 최선의 방법(선형탐색)일까?
- search scope(검색 범위)를 좁히면 개선되지 않을까?
-
Binary Search (이진 탐색)
-
Mid : 리스트의 중앙값(길이 length의 절반 인덱스의 위치하는 값)
-
First : 리스트의 처음 값, Last : 리스트의 맨 마지막 값.
-
찾는 값이 중앙값보다 작으면 Last = Mid - 1로 재설정한다.
-
찾는 값이 중앙값보다 크면 Last = Mid + 1로 재설정한다.
-
이런 식으로 반복하다 First가 Last보다 큰 경우일 경우 False로 리턴한다.
-
-
Binary Search는 얼마나 개선되었는가?
-
length가 1000이라면 최악의 경우에도 약 10번의 계산이 걸린다.
-
2^k = N --> K = log(N) // (2는 생략 가능)
-
선형일 경우 1000번 걸릴 것이 10번으로 줄어들었다. 100배의 효과.
-
-
Big - O 비교(리스트의 동작)
| Operation | Unsorted | Sorted |
|---|---|---|
| size( ) | O( 1 ) | O( 1 ) |
| isFull( ) / isEmpty( ) | O( 1 ) | O( 1 ) |
| clear( ) | O( 1 ) | O( 1 ) |
| getItem(int pos) | O( 1 ) | O( 1 ) |
| appendItem(ItemType Value) | O( 1 ) | X |
| updateItem(int pos, ItemType Value) | O( 1 ) | X |
| findItem( ) | O( N ) | O(N) - linear // O(logN) - binary |
| insertItem( ) | O( 1 ) | O(N) |
| removeItem( ) | O( N ) | O(N) |
추가 개념
-
ADT의 동작 방식 기본 개념
-
Constructor : ADT의 새로운 object를 만든다.
-
Transformer : object의 하나 이상의 데이터 값의 상태를 변경한다.
-
Observer : object의 변형없이 데이터의 상태를 관찰한다.
-
-
Class Constructor
-
class가 만들어질때, 암묵적으로 호출되는 특별한 멤버 함수이다.
-
리턴할 value의 type가 없다.
-
한 class는 여러개의 constructor들을 가질 수 있다.(overloading)
-
파라메타가 없는 constructor가 기본 설정이다.
-
-
Time Complexity (시간 복잡도)
-
효율적인 프로그램이란?
-
시간을 더 짧게 사용하고, 컴퓨터 자원을 더 적게 사용하는 것이 효율적이다.
-
계산(computations)이 많을 수록 시간이 더 많이 걸린다.
-
-
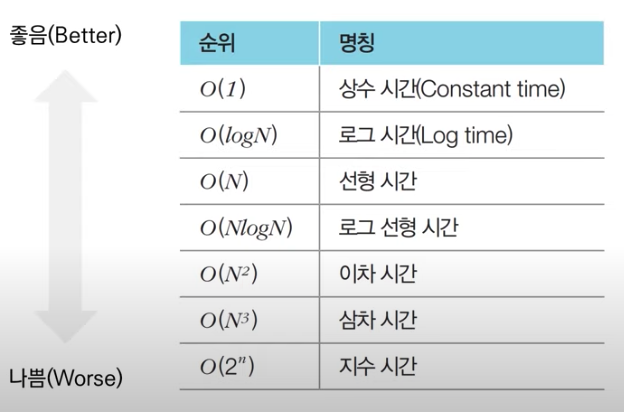
Big - O 표기법
-
흔히 시간복잡도를 계산할 때, 최악의 경우를 산정하고 계산한다.
-
규칙1 : 앞의 계수는 무시한다. -> O(2N) = O(N) // O(2) = O(1)
-
규칙2 : 작은 단위는 무시한다. -> O( N + 1 ) = O( N )
-
-
<Big - O 표기법 그래프 비교>
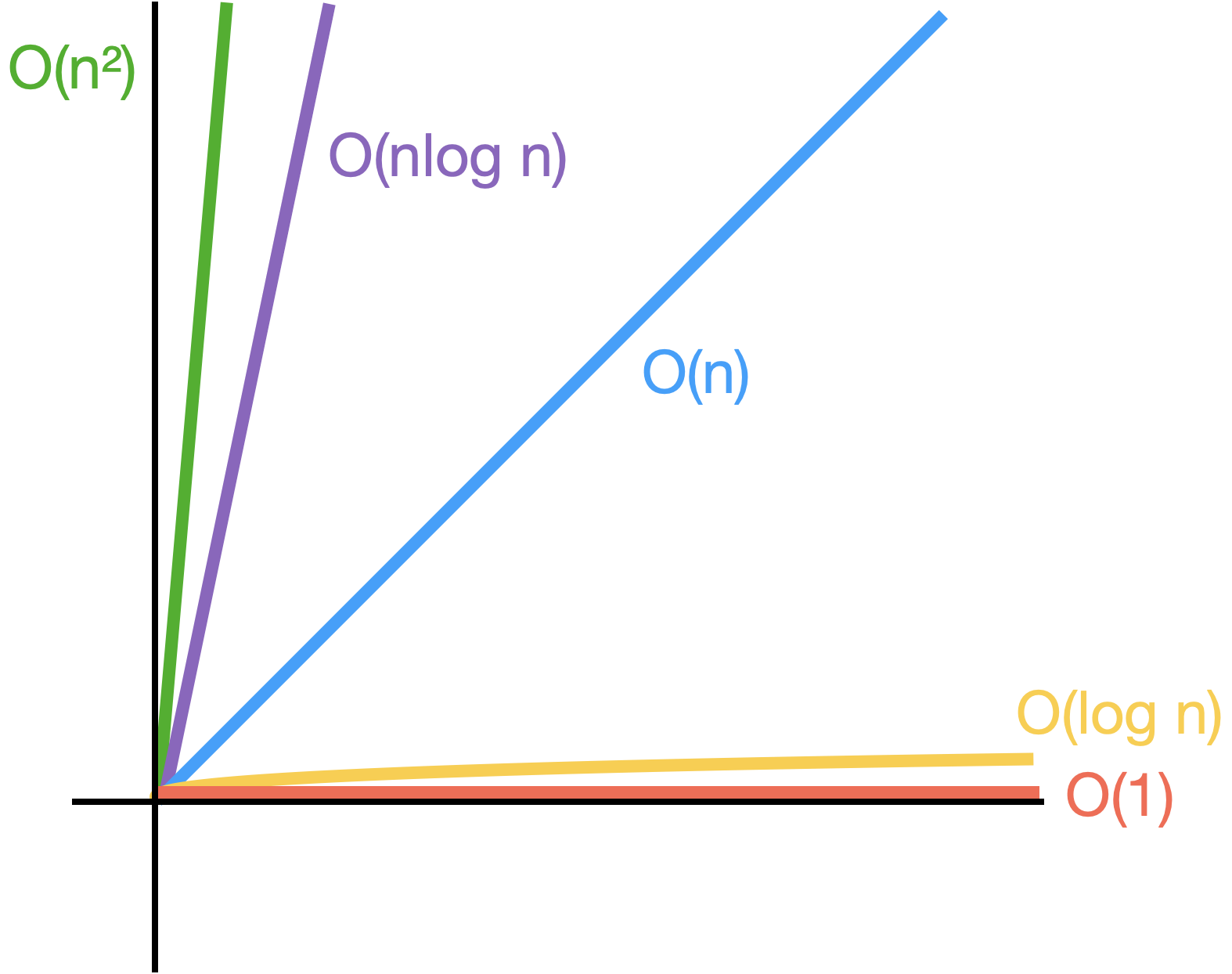
<Big - O 표기법 그래프 설명>