AI 시리즈
1.AI(Artificial Intelligence) 란?

근래 몇년 간, AI의 소식이 빠지지 않고 있다가장 널리 알려진 ChatGPT 부터 시리, 빅스비 등 요즘은 AI 빼놓고 생활할 수는 없다최근 개발을 진행하다보니 추천 시스템이나, 흔히 보는 웹툰들의 해시태그 부여 방식 등 AI를 서비스해보고 싶은 필요성이 생겼다그래서
2.[ML] 머신러닝이란?

머신러닝은 데이터를 주어지면 학습을 한다고 했는데, 이 학습의 종류에 따라 다시 3가지로 나눠진다 1. 지도 학습 정답이 있는 입력 데이터들을 주고 학습을 시켜 원하는 답을 추론하도록하는 방식을 말한다 그럼 왜 지도(Supervisor)라고 할까? 자, A에 대한 정
3.[ML] AI 모델 개발 과정
새로운 기술을 배운다는 것은 마치 책을 읽는 것과 같다 책의 작가의 말을 보고 어떤 책인지 알고, 목차를 보며 어떤 식으로 이야기가 전개될지 파악해보듯이, 새로운 기술도 그것의 정의와 종류가 뭔지, 어떻게 흘러가는지 등 대략적인 부분을 먼저 알아두어야 한다 이전 편에
4.[ML] 전처리(Preprocessing)란?
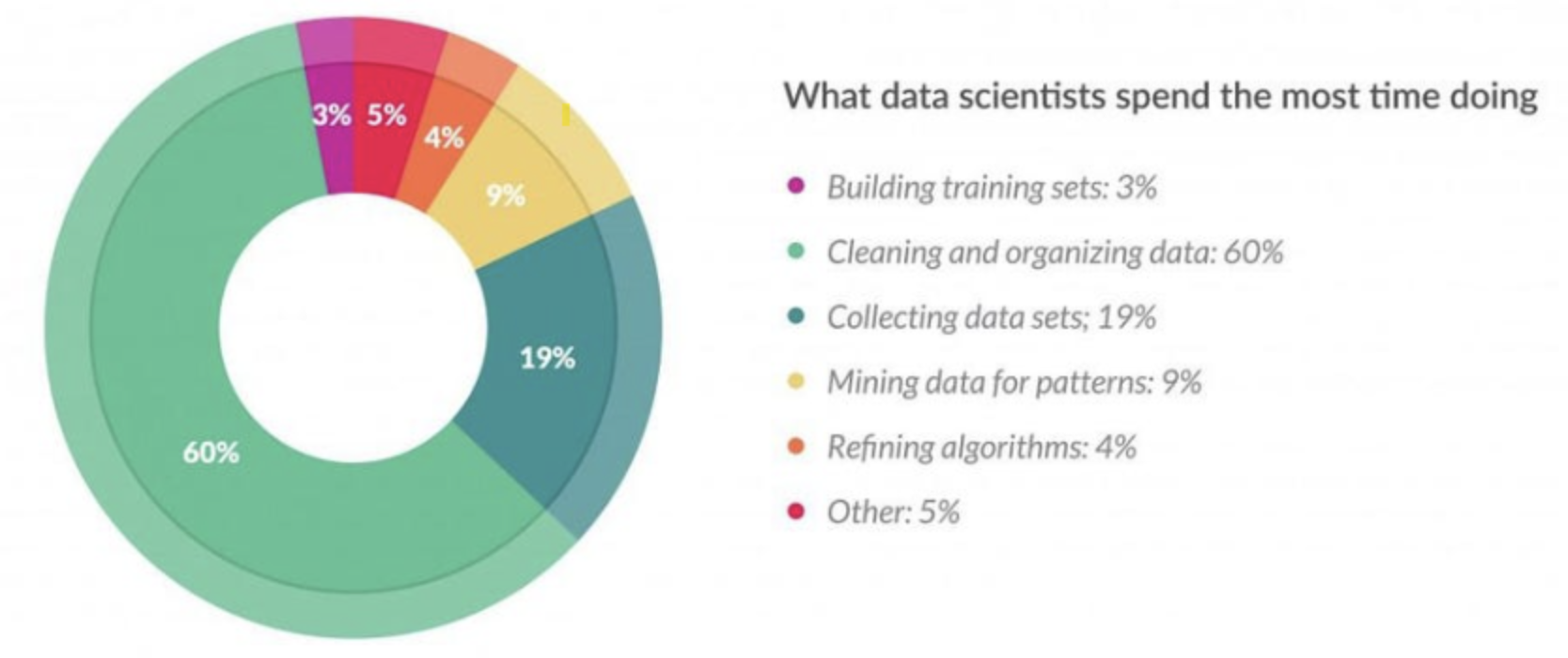
데이터 전처리란 직역하면 미리 진행하는 프로세스, 즉 분석하기 전에 그에 맞게 데이터를 가공하는 것을 말한다데이터를 아무리 많이 수집하더라도 그것은 어디까지나 날 것의 데이터(Raw Data)이다수집 과정에서 오류 발생하여 결측치가 있을 수도, 유난히 튀는 이상치가 발
5.[전처리] Q) 데이터를 임의로 바꿔도 될까?
사실 전처리를 배우면서 가장 궁금했던 부분이다결측치나 이상치 같은 데이터를 처리하는 것은 이해할 수 있다애초에 데이터 자체가 잘못되었기 때문에, 이를 임의로 처리하는 것은 올바르다고 생각한다이해가 가지 않았던 부분은 데이터 변환 단계의 피쳐 엔지니어링 이었다중요하지 않