1. 개요
현재 우리의 project는 운영 server(사용자가 이용하는 server)와 개발 server를 분리하여 사용하고 있다. DB도 이와 마찬가지로 운영 server용 DB와 개발 server용 DB로 처음부터 분리하여 운영하고 있다. 예상치 못한 예외, 실수로 인한 db 훼손 등의 risk 감소가 목적이다.
팀장님이 업무를 분배했다. 총괄은 project leader가 하고, 다른 팀원은 개발 및 운영 server 이관과 이를 위한 master branch 관리가 할당되었고, 나에게는 개발 server에서 운영 server로 DBMS migration 관리가 할당되었으나, 사고를 쳤다. 이후 포스팅으로 후술하겠다.
2. DB Migration
내가 실무에서 이해한 DB migration이란 특정 DB과 대상 DB의 data를 일치시키는 작업이다. 개발 server와 운영 server를 분리해 놓았다고 했는데, 개발 server가 안정적으로 굴러가면 운영 server에 적용할 수 있도록 DB를 백업하는 작업이라고 볼 수 있겠다.
3. DB Migration 방법
'어떻게 마이그레이션 할지 고민해 보세요'. 정답이 있다면 바로 알려 줄 텐데 팀장님은 고민해 보라고 했다. migration 방법이 딱 정해져 있지 않고 다른 모양이다. 찾아 보니까 개발 tool에 따라 다르기도 하고, migration할 data의 범위나, data의 특성에 따라서 다른 것 같기도 하다. 이미 column 변동이 없는 수준에서 진행되기 때문에 나는 data migration을 할 예정이다.
DBMS: DBeaver/MariaDB
3-1. Data Export
Data Export 창 진입
Source가 될(data를 내보내기 할) table을 선택한 뒤 우클릭, data 내보내기를 누른다.
Transfer targets
내보낼 대상(data)의 type과 format의 환경 설정하는 창이다.
나는 같은 DBMS를 사용하는 table로 migration할 예정이라 table>table로 옮기므로 table을 선택한다.
Tables mapping
data를 보낼 table과 data를 받을 table을 mapping하는 화면이다.
창 우측에 table mapping이 안 될 때 도와줄 여러 button이 있으니 참고하자.
Target table 경로 설정:
target container 옆에 folder 표시를 누른다. 받을 table이 있는 database로 선택한 뒤, Mapping 항목을 보면 된다. 보통 자동적으로 칸이 채워지지만 ?로 표시되어 있으면 이름과 matching되는 data를 받는 table이 없다는 뜻이다.
Mapping 확인:
같은 이름의 table이 존재하여 mapping이 되면 existing이라고 뜨고, 아니면 create라고 뜨면서 해당 column을 새로 만들려고 설정한다. 이걸로 내가 경로를 잘 선택했는지 구분하면 된다.
혹시 migration을 하지 않을 column이 있다면 Mapping 열에서 해당 table의 칸을 누른다.
skip option이 있어 진행하지 않거나, recreate를 통해서 새로 만들 수도 있다.
Transform option 선택:
만약 옮기는 동안 어떤 열의 value 값을 변경하고 싶다면 선택한다.
Set to Null: 선택한 table에 해당하는 모든 value 값을 null로 setting한다.
Constant: 선택한 table에 해당하는 모든 value 값을 상수로 setting한다.
Expression: 기본적인 산술 계산과 표현식을 쓰는 table 명을 사용할 수 있다.
3-2. Extraction settings & Data load settings
내보내기 환경 설정이다.
Extraction settings
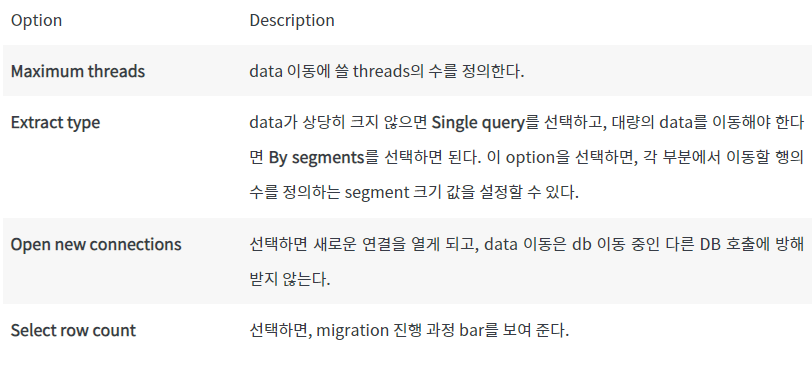
Option Description
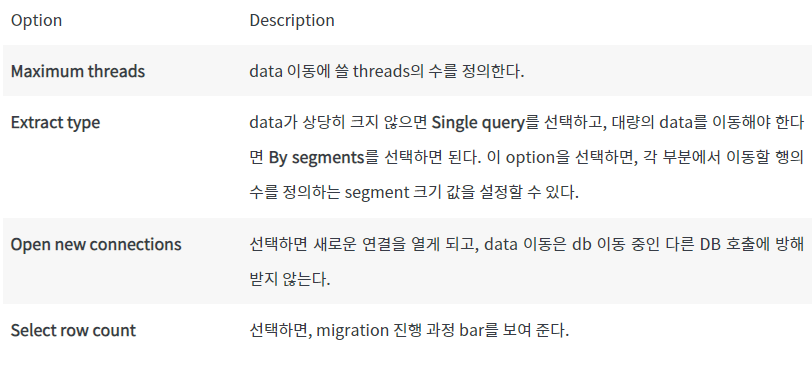
Maximum threads: data 이동에 쓸 threads의 수를 정의한다.
Extract type: data가 상당히 크지 않으면 Single query를 선택하고, 대량의 data를 이동해야 한다면 By segments를 선택하면 된다. 이 option을 선택하면, 각 부분에서 이동할 행의 수를 정의하는 segment 크기 값을 설정할 수 있다.
Open new connections: 선택하면 새로운 연결을 열게 되고, data 이동은 db 이동 중인 다른 DB 호출에 방해 받지 않는다.
Select row count: 선택하면, migration 진행 과정 bar를 보여 준다.
Data load settings
Option Description
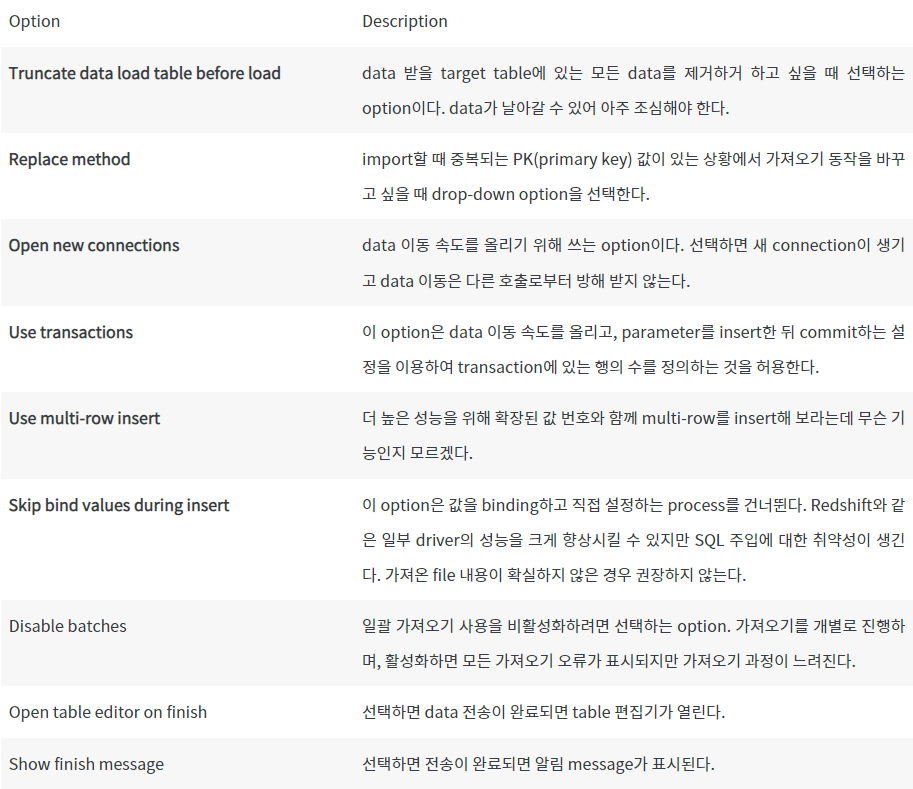
Truncate data load table before load: data 받을 target table에 있는 모든 data를 제거하거 하고 싶을 때 선택하는 option이다. data가 날아갈 수 있어 아주 조심해야 한다.
Replace method: import할 때 중복되는 PK(primary key) 값이 있는 상황에서 가져오기 동작을 바꾸고 싶을 때 drop-down option을 선택한다.
Open new connections: data 이동 속도를 올리기 위해 쓰는 option이다. 선택하면 새 connection이 생기고 data 이동은 다른 호출로부터 방해 받지 않는다.
Use transactions: 이 option은 data 이동 속도를 올리고, parameter를 insert한 뒤 commit하는 설정을 이용하여 transaction에 있는 행의 수를 정의하는 것을 허용한다.
Use multi-row insert: 더 높은 성능을 위해 확장된 값 번호와 함께 multi-row를 insert해 보라는데 무슨 기능인지 모르겠다.
Skip bind values during insert: 이 option은 값을 binding하고 직접 설정하는 process를 건너뛴다. Redshift와 같은 일부 driver의 성능을 크게 향상시킬 수 있지만 SQL 주입에 대한 취약성이 생긴다. 가져온 file 내용이 확실하지 않은 경우 권장하지 않는다.
Disable batches: 일괄 가져오기 사용을 비활성화하려면 선택하는 option. 가져오기를 개별로 진행하며, 활성화하면 모든 가져오기 오류가 표시되지만 가져오기 과정이 느려진다.
Open table editor on finish: 선택하면 data 전송이 완료되면 table 편집기가 열린다.
Show finish message: 선택하면 전송이 완료되면 알림 message가 표시된다.
3-3. Confirm
확인하는 단계이다.
잘 넘어갈지 내가 선택한 setting이 맞는지 확인하고 start를 하면 옮길 수 있다.