정리(순서 섞임)
C는 HW 접근을 남겨놈 --> 메모리 접근 오류 잘 뜬다(위험성)
C의 철학: 개발 자유
int** p[2][4]
int 포인터의 포인터를 원소로 가지는 2 * 4 배열 int(**p)[2][4]
int원소를 가지는 2*4배열을 가리키는 포인터의 포인터 C자료형
Primitive data type : char, int, double ...
Derived data type :
char (*parr)[3]
char(*)[3]
void (*fp1)(void)
void(*)(void)
int (*fp2)(int, int, int)
int(*)(int, int, int) 자료형이 같으면 대입 가능
기본형의 경우 자료형이 다르면 type conversion으로 가능
type conversion = implicit or explicit
lvalue: 변수, rvalue: 상수
Parameter(함수정의 인자) vs Argument(전달인자)
포인터 자료형의 크기는 컴퓨터 시스템(32bit, 64bit)의 크기에 따라 달라짐
limit.h파일에 자료형 크기 정해져 있음(HW종속적)
word는 정해진 자료형이 아니다. 프로세서가 한 번에 처리할 수 있는 데이터 양, 32bit 시스템은 word 크기가 32bit
16bit프로세서는 int를 처리하기 위해 2번 함
- 32bit 프로세서가 core만 64bit인 경우도 있음 --> I/O 호환성 문제로 시스템은 CPU에 비해 낮을 수 있음
임베디드 특성상 요구사항이 다양해 비슷한 스펙을 가진 제품군이 다양하다.
차량 코드 표준: MISRA C, iso26262
배열의 특징 2가지: 같은 데이터형의 집합(다른 데이터형의 집합은 구조체), 배열의 이름은 시작주소
배열의 단점: 크기늘리기 불가능,
정적전역변수 vs 정적지역변수 vs 전역변수 : 프로그램 실행될 때 ~ 종료까지 생존
정적전역변수는 다른 프로그램에서 사용이 불가능
정적지역변수는 다른 함수에서 선언 불가능(남아 있음)
전역변수 < 정적전역변수 < 정적지역변수(최소한으로 노출시켜야 함)
static이 붙어 있으면 초기값 0나옴
정적지역변수의 특징
#include <stdio.h>
void aa() {
int a = 0;
static int b;
a++; b++;
printf("%d %d\n", a, b);
}
int main() {
aa(); // 1 1
aa(); // 1 2
aa(); // 1 3
aa(); // 1 4
return 0;
} union은 같은 메모리 사용하는 자료형
typedef union packet_t {
int total[4];
struct { // ECU에 시직/ 전압 / 전류 / 끝 을 보낼 때 파싱하는 데 쓰임
int sof;
int volt;
int amp;
int eof;
};
}; 리틀엔디안 실습
#include <stdio.h>
int main() {
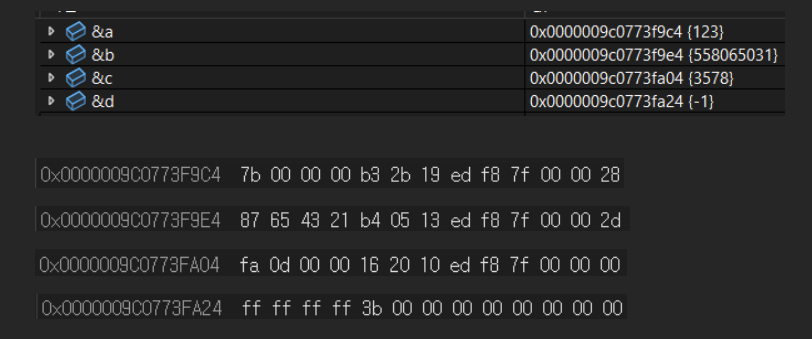
int a = 123; //0x00 00 00 7b --> 7b 00 00 00로 메모리 나타남(리틀엔디안)
int b = 558065031; // 0x21 43 65 87 --> 0x87 65 43 21
int c = 3578; // 0x00 00 0D FA --> 0xFA 0D 00 00
int d = -1; // FF FF FF FF --> FF FF FF FF
printf("%d\n", a);
printf("%d\n", b);
return 0;
} 
const int a = 3;
리터럴 상수 == 3, 심볼릭상수 == a
char str1[]와 char*의 차이
char str1[] = “bits”;
const char *str2 = “exo”; // str1은 주소를 가지는 상수값
strcat(str1, str2); 는 가능, strcat(str2 str1);은 불가능
헷갈리지 않게 const char*형식으로 문자열을 사용하자 음수 저장 방법
1. Signed magnitude
1비트가 부호표시로 사용, 0이 2개(+0, -0) --> CPU에 알려줘야 함(분기문 발생) --> 계산복잡해짐
2. 1’s complement
2+(-3)
0010
1100
1110 != -1, 자리올림(carry)이 없으면 1의 보수 취하고 -를 붙이기 -> 1001 (-1)
5+(-3)
0101
1100
0001에 carry발생으로 1 더해주기 == 0010 (2)
여전히 0이 2개
3. 2’s complement
5+(-3)
0101
1101
0010 (2) --> 캐리발생 무시 가능
2-3= -1
0010
1101
1111 --> 2의보수 취하고 -부호 붙이면 1001 (-1)
장점
MSB=0, MSB=1 부호 절대값 방식을 유지, 음수더하기로 뺼셈 가능, 0이 한개 존재, 음수 비교 가능
0010 -> 1110(-2) > 1101(-3) <- 0011
사용이유
양수에서 사용하는 기존 ALU사용해 효율적(부호 사용시 분기문 발생으로 1 Cycle에 끝나지 못함)
배열을 포인터로 받는 법
#include <stdio.h>
void func1(int* arr, int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\r\n");
}
void func3(int (*arr)[3], int size) {
for (int i = 0; i < size; i++) {
for (int j = 0; j < sizeof(*arr) / sizeof(int); j++) {
//printf("%d ", *(*(arr + i) + j));
//printf("%d ", (*(arr + i))[j]);
printf("%d ", arr[i][j]);
}
printf("\r\n");
}
}
int main(void) {
int arr1[3] = { 11,22,33 };
int arr3[2][3] = {
{1,2,3},
{4,5,6}
};
func1(arr1, 3);
func3(arr3, 2);
return 0;
}
func3(int**, int)로는 받을 수가 없다. 포인터의 배열로는 받기 가능함 return 여러개 할려면 strcut 사용하기, 전역변수도 가능
함수포인터는 콜백함수에 사용 --> 비동기적 호출
콜백함수는 다른 함수의 인자로서 넘겨주는 함수
즉시 실행, 나중 실행, 어떤 조건이 되면 실행 등 다양하 조건에서 실행함
모든 함수 등록한 후 함수포인터에 설정을 해 인수로 주면 됨
함수 인자 받는 사람은 함수포인터로 인자를 설정해 두고 함수를 만들면 되고 함수인자 만드는 사람은 함수만들어서 함수포인터로 전달해 주면 됨
함수포인터 사용 예제(운동선수 정렬)
int main() {
void (*fp)(void) = NULL;
fp = bts;
hive(fp);
fp = nana;
hive(fp);
return 0;
} 비동기구현
폴링으로 조건이 될때까지 탐색하는 것이 아니라 조건이 되면 바로 실행하는 비동기 구현 가능
if-else를 줄일 수 있다.
#include <stdio.h>
#include <stdlib.h> // malloc과 free를 위해 필요
void one(void) { printf("one\n"); }
void two(void) { printf("two\n"); }
void three(void) { printf("three\n"); }
void four(void) { printf("four\n"); }
void five(void) { printf("five\n"); }
void six(void) { printf("six\n"); }
void seven(void) { printf("seven\n"); }
void eight(void) { printf("eight\n"); }
void nine(void) { printf("nine\n"); }
int main() {
int n;
scanf("%d", &n);
if (n == 1) one();
else if (n == 2) two();
else if (n == 3) three();
else if (n == 4) four();
else if (n == 5) five();
else if (n == 6) six();
else if (n == 7) seven();
else if (n == 8) eight();
else if (n == 9) nine();
void (*fp[])(void) = {NULL, one, two, three, four, five, six, seven, eight, nine};
fp[n]();
return 0;
} If_else를 함수포인터로 바꾼 결과
다형성을 C는 함수포인터, C++은 문법으로 구현함
매크로함수 vs 인라인함수(면접에서 나온 질문, 대답 못함)
매크로함수는 전처리기에 의해 치환되어 동작
타입체크 무시, 성능저하X, 코드사이즈 커짐(메모리가 부족할 경우 문제)
인라인함수는 컴파일러에 의해 처리
일반 함수가 stack을 거쳐서 수행하는 것에 비해, inline 함수는 함수의 바디가 그대로 대입된다. (스택소모 X)
그래서 일반함수에 비해 더욱 빠르다.
컴파일러가 판단하여 매크로처럼 코드를 교체함, 함수의 심볼(주소)가 없음
선언(알려줌) 정의(메모리사용)
void func(); 선언
void func(){
} 정의
기본형의 경우 선언과 정의가 동시에 됨, struct나 함수는 선언과 정의가 따로 논다.
Int* pa = &a;
*pa = 111;
위에꺼는 포인터임을 알려주는 *
아래꺼는 역참조연산자(서로 다른의미를 가짐)
인자는 가급적 address로 넘기기 or 수정하지 않을 경우 const
typedef struct _dummy_t {
char arr[1000];
} dummy_t; void func(dummy_t* a) {
if(a == NULL){
}
}
값 복사는 비효율적
참조를 받을 때는 NULL 체크 C언어 등장 배경
HW의존도가 높고 배우기가 어려운 어셈블리어 --> HW의존도가 낮고(다른 언어와 달리 HW를 강력히 제어) 배우기가 쉽다(어셈블리어보다)
단점: HW를 제어하기에 안정성이 떨어진다.
Storage class
auto: 지역변수
extern: 전역변수, 메모리공간 차지 안함(어디에 있다고 알려줌)
static: 정적변수
C++레퍼런스는 만들 때 참조를 안하면 만들 수 없다 -> NULL체크 안함(안전성 좋음)
메모리 이슈
1. 메모리 누수: 메모리 해제를 안한 경우
2. 메모리 단편화: 메모리가 쪼개져 있어 할당을 못하는 상태
3. 세그먼테이션 폴트: 잘못된 참조
해결책: C의 경우 가급적 stack에 만들기, C++의 경우 스마트포인터, 레퍼런스
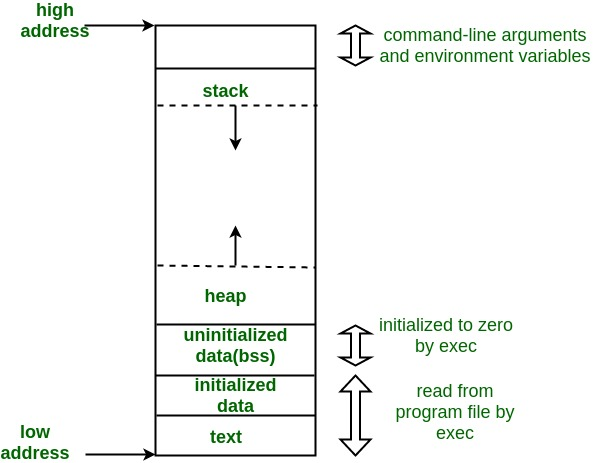
메모리 세그먼트
text: 소스 공간, 일반적으로 Read-Only, 변형되지 않기 위해 stack과 heap 밑에 존재
data: 초기화된 변수 영역(전역변수, 정적변수)
bss: 초기화 되지 않은 영역
data와 bss 구분 이유
data영역에 들어가는 변수들은 값을 넣어주는 공간만큼 용량이 필요
bss영역에 들어가는 변수들은 값이 0이기에 변수존재여부만 알려주면 됨 -> 값을 안넣음 -> 프로그램 용량 작아짐
stack: 컴파일에서 크기 결정, 지역 변수
heap: 동작중에 크기 결정, 사용자가 할당
객체 만들고 free한 후에도 사용 가능
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
typedef struct _car_t {
uint8_t fuel;
uint8_t speed;
} car_t;
int main() {
car_t* my_car = (car_t*)malloc(sizeof(car_t));
if (my_car == NULL) {
printf("my_car create error\r\n");
return 0;
}
else {
printf("my_car create ok\r\n");
}
my_car->fuel = 11;
my_car->speed =22;
printf("%d, %d\r\n", my_car->fuel, my_car->speed);
free(my_car);
my_car->fuel = 55; // 이 값이 그대로 나온다.
printf("%d, %d\r\n", my_car->fuel, my_car->speed); // speed값은 다른 값이 나옴
return 0;
} free는 NULL로 초기화 하는 것이 아닌 누구나 메모리에 사용가능하다는 표시만 해주는 것
지역변수의 참조를 리턴하면 안된다 -> 스택에 저장된 값이기에 리턴하면 쓸모없는 값이다.(댕글리 포인터)
단, 정적 지연변수로 만들면 가능
void(*p)(void) = &bts;
void(*p)(void) = bts;
두개 다 결과 가 같음 arr과 &arr도 결과가 같음
윈도우즈에서는 \r\n으로 다음줄 첫번째로 가고 유닉스에서 \n으로 다음 줄 첫번째로 간다
텍스트형식에서는 \n만 써도 C라이브러리가 자동으로 \r\n으로 바꿔주기에 상관 없지만 바이너리 파일에서는 적용이 안돼 \r\n을 사용해야 한다.
구조체 패딩
PC에서는 알 필요 없지만 strcut 데이터 송수신 할 때 문제가 생긴다.
typedef struct _A_t {
int a; // 4
int b; // 4 // 8
} A_t;
typedef struct _B_t {
char a; // 1
int b; // 4 // 8
} B_t;
typedef struct _C_t {
char a; // 1
char b; // 1
char c; // 1
char d; // 1
char e; // 1
int f; // 4 // 12
} C_t;
typedef struct _D_t {
int a; // 4
int b; // 4
double c; // 8
int d; // 4 // 24
} D_t; 가장 큰 자료형의 배수만큼 메모리 할당됨, 하지만 중간에 작은 수가 있으면 중간에 비는 공간에 넣는다.
Ex) 1 1 1 1 1 4면 (1 1 1 1) (1 남는공간) (4) == 12, (4 4) (8) (4 남는공간) == 24
#pragma pack(push, 1)
typedef struct _C_t {
char a; // 1
char b; // 1
char c; // 1
char d; // 1
char e; // 1
int f; // 4 // 12
} C_t;
#pragma pack(pop) 이렇게 하면 9가 나온다.
- #pragme는 컴파일러에게 명령하는 전처리 명령어다.
상수포인터와 포인터상수
상수포인터(상수를 가리키는 포인터)
const int* pa;
값변경X, 주소변경O
포인터상수
Int* const pa;
값변경O, 주소변경X, 배열
1차 동적배열 만들기
#include <stdio.h>
#include <stdlib.h>
#define DEFAULT_SIZE (5)
int main() {
int* arr = (int*)calloc(DEFAULT_SIZE, sizeof(int));
if (arr == NULL) { printf("calloc error"); return; }
arr[0] = 11;
arr[1] = 22;
*(arr + 2) = 33;
*(arr + 3) = 44;
for (int i = 0; i < DEFAULT_SIZE; i++) {
printf("%d, ", arr[i]);
}
printf("\n");
free(arr);
return (0);
}calloc, malloc 차이점: size만큼 0으로 채워줌(malloc은 쓰레기값)
2처 동적배열 만들기
#include <stdio.h>
#include <stdlib.h>
#define col_size (2) // 3x2 배열을 만들어 보자.
#define row_size (3)
int main(){
int** arr = NULL;
arr = (int**)malloc((col_size) * sizeof(int*));
if(arr == NULL) { return 0; }
for(int i = 0; i < col_size; i++){
arr[i] = (int*)malloc(row_size * sizeof(int));
}
for(int i = 0; i < col_size; i++){
for(int j = 0; j < row_size; j++){
*(*(arr + i) + j) = 0;
}
}
*(*(arr + 0) + 0) = 11;
*(*(arr + 0) + 1) = 12;
*(*(arr + 0) + 2) = 13;
*(*(arr + 1) + 0) = 21;
*(*(arr + 1) + 1) = 22;
*(*(arr + 1) + 2) = 23;
for(int i = 0; i < col_size; i++){
for(int j = 0; j < row_size; j++){
printf("%d, ", *(*(arr + i) + j));
//printf("%d, ", arr[i][j]);
}
}
free(arr[0]);
free(arr[1]);
*(arr + 0) = NULL; // 해제하고 접근해도 참조 못하게 하기
*(arr + 1) = NULL;
free(arr);
arr = NULL;
return 0;
}
함수선언
#include <stdio.h>
void exo(); // 전방선언(forward declaration)
void bts() {
printf("bts\r\n");
}
void exo() {
bts();
printf("exo\r\n");
}
int main() {
printf("main\r\n");
bts();
exo();
return (0);
} 함수호출전에 함수를 미리 선언, 반드시 선언할 필요 X, 함수 정의를 넣어도 됨
헤더가드
void bts() {
printf("bts\r\n");
}
#endif
이거거는 gcc에 적용되는 헤더가드
하지만 #pragma once는 visual studio전용이기에 gcc헤더가드 쓸 것
헤더파일은 컴파일이 될까?
X, 컴파일 대상이 아님
main
#include <stdio.h>
#include "h1.h"
#include "h2.h"
int main() {
abc();
return 0;
} hi.h
ifndef __H1_H__
#define __H1_H__
#include "h2.h"
void ccc() {
}
void abc() {
bbq();
}
#endif h2.h
#ifndef __H2_H__
#define __H2_H__
#include "h1.h"
void bbq() {
ccc();
}
#endif 위 코드를 전처리한 main.i
void bbq() {
ccc();
}
void ccc() {
}
void abc() {
bbq();
}
int main() {
abc();
return 0;
} ccc()함수 선언 전에 이미 호출해버려서 에러남
문제점: 헤더파일에 함수 정의를 넣음
해결책: 함수선언을 미리 하면 된다.
링킹에러
main
#include <stdio.h>
#include <stdlib.h>
#include "a.c"
int main() {
return 0;
} a.c
#include <stdio.h>
#include <stdlib.h>
void abc(); 위 코드에서는 오류 안생김
main
#include "a.c"
int main() {
return 0;
} a.c
int x = 1;
int y = 1; 컴파일을 각각 해놓고 합치는데 이미 x, y가 존재함

컴파일 에러가 아닌 링킹에러
해결책: 헤더와 소스로 나눈다.
main
#include "a.c"
#include "a.h"
void abc() {
}
int main() {
abc();
return 0;
} a.h
int x = 1;
int y = 1; a.c
#include <stdio.h>
void abc(); 이러면 링킹에러 안남
헤더가드 해도 링킹에러가 나는 경우
main
#include "a.h"
int main() {
return 0;
} a.c
#include "a.h" a.h
#pragma once
#include <stdio.h>
void abc() {
printf("DDD");
} 결론: 헤더파일에는 중복되도 상관없는 코드(함수 선언 등) 소스파일에는 중복되면 안되는 코드(함수 정의)
분할 컴파일
분할 컴파일 시 가변코드 불변코드로 나누는게 좋음
예를들어 임베디드 관점에서 불변코드는 로직부분, OS에 종속적이지 않은 부분, 가변코드는 HW에 종속적인 코드 -> 보드가 없어도 로직부분은 개발 가능
