
가장 기본적인 원칙에서부터 DOM 다시 생각해보기
브라우저는 지금 매우 이상한 상황에 놓여 있습니다. 웹 어셈블리는 서버에서도 성공을 거두었지만, 클라이언트 측은 여전히 10년 전 모습과 다를 바 없어 보입니다.
열정적인 개발자들은 최소한의 JS 연결과 WASM을 통해 네이티브 웹 API에 접근할 수 있다고 할 것입니다.
하지만 정작 묻지 않은 질문이 있습니다. 왜 굳이 DOM에 접근하냐는 것입니다. 사실 접근할 수 있는 유일한 선택지이기 때문입니다. 그래서 저는 이제 DOM 및 DOM 관련 API를 보내줘야하는 이유와, 그 방법에 대해 몇 가지 아이디어를 제시하고자 합니다.
저는 브라우저의 모든 것에 대해 알지 못합니다. 그런 사람은 아무도 없고, 그것이 바로 문제입니다.

문서(document) 모델
실제로 DOM이 얼마나 문제가 많은지 제대로 아는 사람은 거의 없습니다. 크롬에서 document.body 객체에는 무려 350개가 넘는 속성이 있으며, 대략 다음과 같이 구분됩니다.
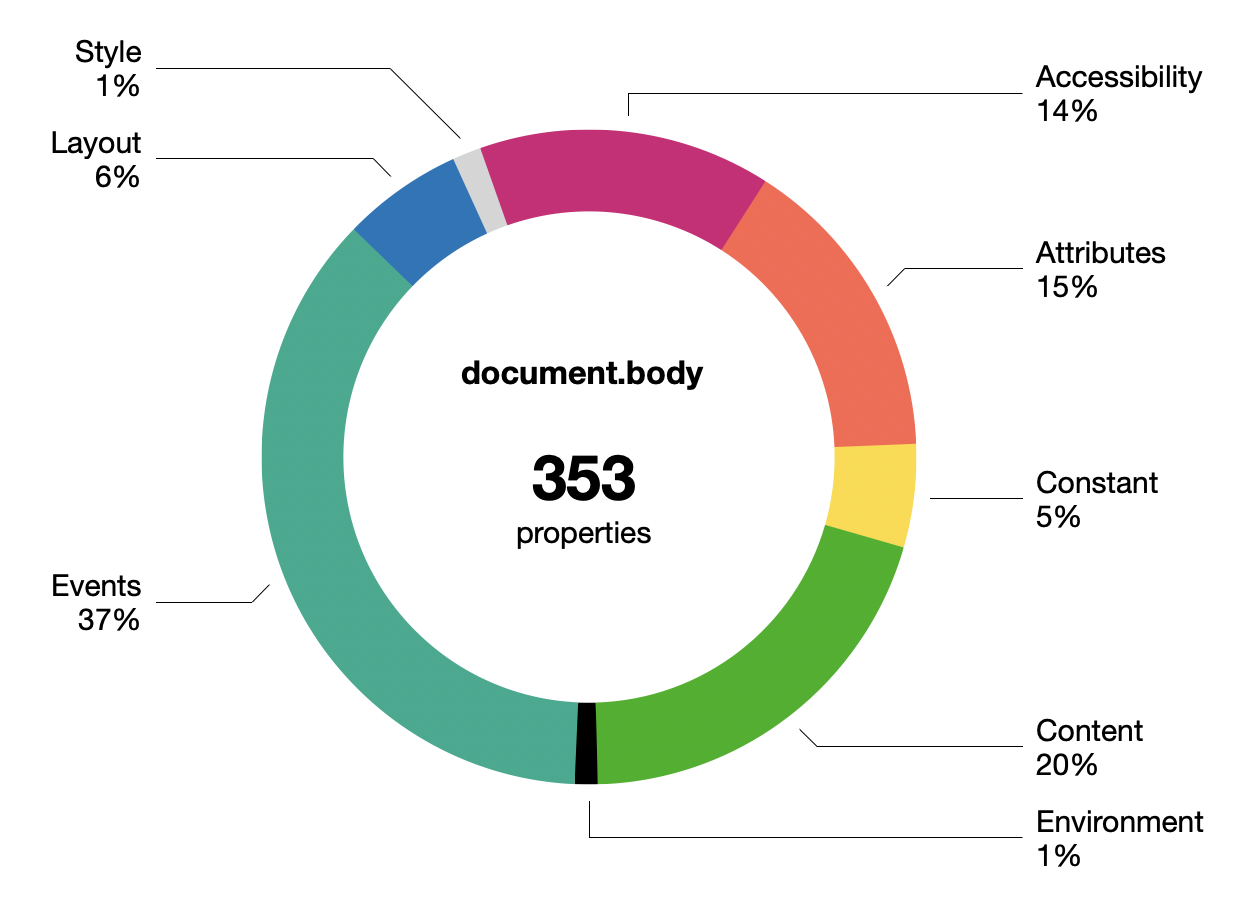
심지어 document.body.style내의 660개나 되는 CSS 속성들은 여기에 포함되지도 않습니다.
프로퍼티와 메서드 사이의 경계는 매우 모호합니다. 대부분은 단순한 인터페이스에 불과하며 내부적으로 보이지 않는 setter 로직이 동작합니다. 일부 getter는 호출만 해도 즉석에서 레이아웃 재계산(just-in-time re-layout)을 일으킬 수 있습니다. onevent 프로퍼티와 같이 더 이상 아무도 사용하지 않는 오래된 기능도 여전히 남아 있습니다.
DOM은 결코 가볍지 않고, 오히려 점점 비대해지고 있습니다. 다만 이를 체감하는 정도는, 단순히 웹 페이지를 만드는지 또는 웹 애플리케이션을 만드는지에 따라 크게 좌우됩니다.
요즘 대부분의 개발자는 DOM을 직접 다루는 일을 꺼립니다. 가끔 일부 순수주의자들이 다양한 JS 컴포넌트/템플릿 프레임워크보다 순수 DOM이 우수하다고 칭찬하기도 합니다. innerHTML과 같이 DOM 내의 선언적이지 않은 기능들은 최신 UI 패턴에 전혀 부합하지 않습니다. innerHTML과 같은 작업을 수행할 수 있는 여러 방법이 DOM에 있지만, 그 어느 것도 만족스럽지 않습니다.
connectedCallback() {
const
shadow = this.attachShadow({ mode: 'closed' }),
template = document.getElementById('hello-world')
.content.cloneNode(true),
hwMsg = `Hello ${ this.name }`;
Array.from(template.querySelectorAll('.hw-text'))
.forEach(n => n.textContent = hwMsg);
shadow.append(template);
}웹 컴포넌트는 JS 컴포넌트 라이브러리에 해당하는 웹 네이티브 기능이라는 점에서 언급할 가치가 있습니다. 하지만 너무 늦게 출시되었고, 인기도 없습니다. 새로운 중첩과 범위 지정 레이어를 도입한 Shadow DOM 때문에 API가 투박해 보입니다. 옹호자들의 주장은 다소 변명처럼 느껴집니다.
DOM의 치명적인 약점은 모든 것을 문자열로 타입화하는 SGML/XML입니다. 리액트는 구문이 XML처럼 보일 뿐이므로 문제가 없습니다. 개발자들은 이미 상태(state)를 문서 안에 두어서는 안 된다는 것을 배웠습니다. 문서는 상태 관리에 부적합하기 때문입니다.
![]()

HTML 자체는 지난 10-15년간 크게 바뀐게 없어서 비판할 것이 많지 않습니다. 그나마 ARIA(접근성)만이 주목할 만한데, 이는 단지 시맨틱 HTML이 해야 할 일인데 하지 않았기 때문입니다.
시맨틱 HTML은 결국 목표에 도달하지 못했습니다. 2011년 무렵부터 있었음에도, 당시 이미 널리 쓰이던 <thread>나 <comment>과 같은 태그는 존재하지 않습니다. 대신, <article>내에 <article>이 있다면 comment로 간주합니다. 가이드라인이.. 좀 이상합니다.
HTML은 늘 '종이 문서'를 부러워했던 것 같고, 하이퍼텍스트의 특성을 완전히 정의하거나 수용하지 못했습니다. 아마 사용자가 명확한 규칙을 따를 것이라고 믿지 못했던 것 같습니다.
이후 HTML에 대한 관리권은 WHATWG, 즉 브라우저 벤더에게 완전히 넘어갔고, 이들은 목표를 구체적으로 정의하지 못한 채 주변부에 복잡한 보조 장치를 덧붙이는 방식으로만 대응해 왔습니다.
모든 템플릿 언어는 프로그래밍 언어가 되기를 원하기 때문에, 이 과정에서 CSS도 표현식을 성장시켰습니다.
HTML의 편집 가능성은 여전히 아쉬운 부분입니다. 기술적으로 contentEditable을 통해 지원되지만, 실제로 이 기능을 애플리케이션에서 사용할 수 있는 형태로 만드는 것은 매우 까다로운 작업입니다. 아마 Google Docs와 Notion 개발자들은 끔찍한 경험을 했을 겁니다.
더 이상 점진적인 개선이나 마크업과 스타일의 분리라는 옛 신념을 이제는 아무도 진지하게 믿지 않습니다. 최소한 애플리케이션을 만드는 사람이라면 더더욱 그렇습니다.
오늘날 대부분의 애플리케이션은 HTML/CSS/SVG를 그럴듯한 형태로 조립합니다. 하지만 이는 엄청난 오버헤드를 수반하며, 점점 더 괜찮은 UI 툴킷의 모습과는 멀어져 갑니다.
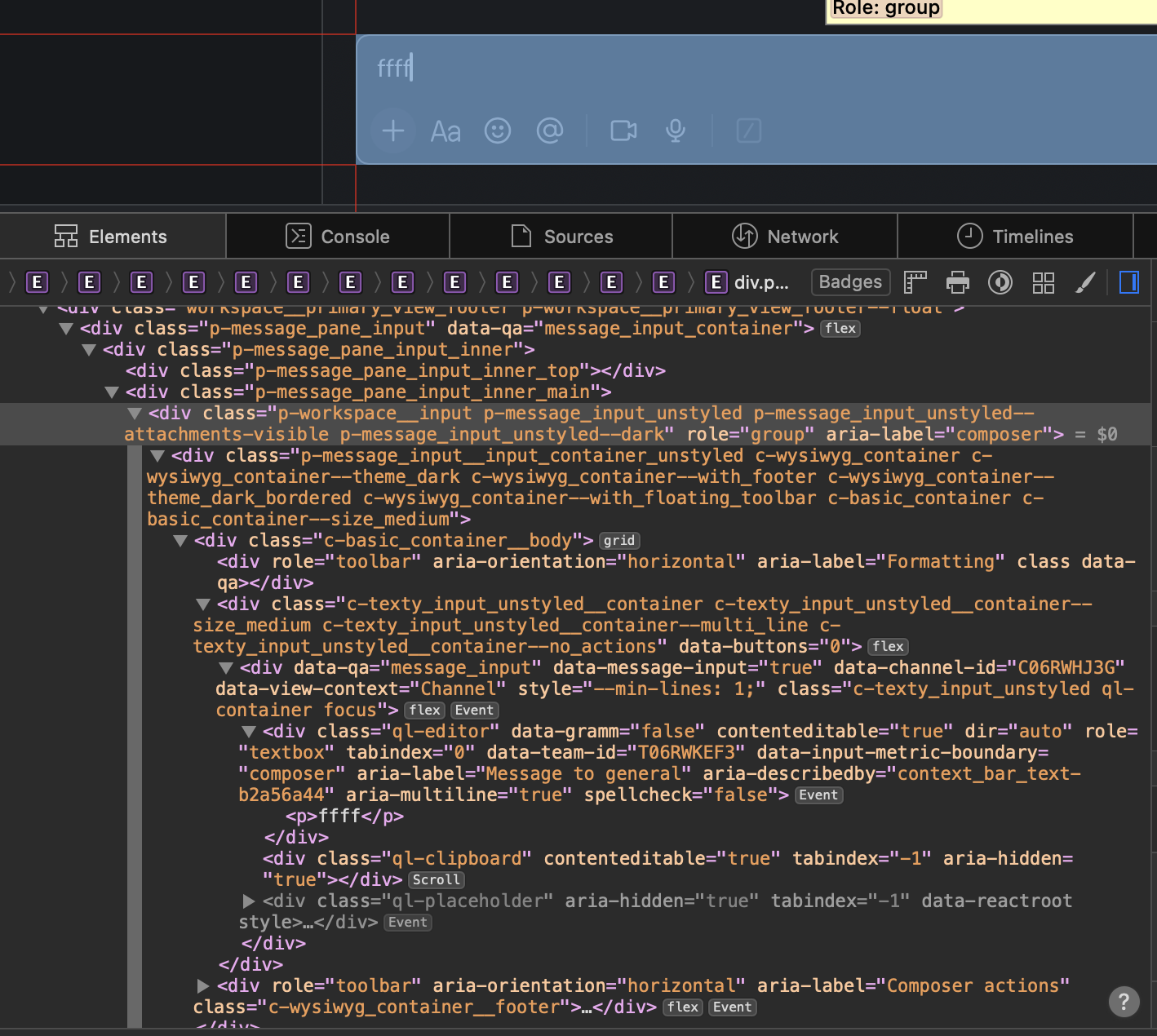 슬랙의 인풋 박스
슬랙의 인풋 박스
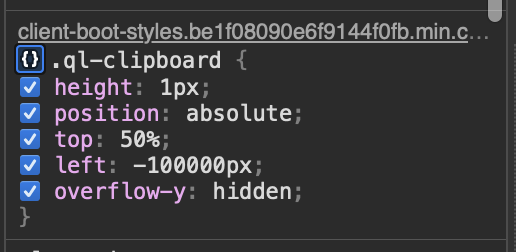 화면 밖의 클립보드 편법
화면 밖의 클립보드 편법
리스트와 표는 수작업으로 가상화하여 레이아웃, 크기 조정, 드래그 등의 작업을 수행해야 합니다. 채팅창의 스크롤바를 하단에 고정하는 것은 누군가가 해야 할 일입니다. 또한 가상화를 많이 할수록 페이지 내 찾기, 오른쪽 클릭 메뉴 등을 다시 만들어야 합니다.
웹은 한때 새로웠던 UI와 유동적인 콘텐츠 사이의 경계를 모호하게 만들었습니다. 하지만 UI 부분은 10년 이상 낡았고, 콘텐츠 자체도 대체로 획일화되어 점점 더 의미가 없어졌습니다.

CSS는 inside-out 입니다
CSS도 그다지 좋은 평판을 갖고 있지는 않습니다. 다만, 그 이유를 아는 사람은 거의 없습니다.
대부분의 사람이 잘못하는 부분은, 잘못된 멘탈 모델로 시작하여 제약 조건의 해결사처럼 접근하는 것입니다. 예제를 통해 쉽게 보여드리겠습니다.
<div>
<div style="height: 50%">...</div>
<div style="height: 50%">...</div>
</div><div>
<div style="height: 100%">...</div>
<div style="height: 100%">...</div>
</div>첫 번째 예제는 상위 요소를 수직 방향으로 이등분하여 그럴듯해 보입니다. 그럼 두 번째 예제는 어떨까요?
제약 조건의 관점에서 보면 상위 div의 높이가.. 자기 자신보다 두 배나 높기 때문에 모순입니다. 대신 두 경우 모두 height값이 무시됩니다. 부모의 높이는 알 수 없으므로 CSS는 여기서 되돌아가거나 반복하지 않습니다. 단지 콘텐츠에 맞춰 높이를 결정할 뿐입니다.
예를 들어 부모 요소를 height: 300px으로 설정한다면 위 코드는 동작하지만, 두 번째 경우는 콘텐츠가 밖으로 넘치게 됩니다.
 outside-in과 inside-out 레이아웃 모드
outside-in과 inside-out 레이아웃 모드
대신, CSS를 이해하기 위한 멘탈 모델은 먼저 outside-in(밖에서 안으로), 그리고 inside-out(안에서 밖으로) 두 번의 제약 조건을 적용해야 합니다.
애플리케이션 프레임을 만들 때, 사용 가능한 공간이 분할되고 내부 콘텐츠가 패널 크기에 영향을 주지 않는 outside-in 방식입니다.
반면, 단락이 페이지에 쌓이는 것은 inside-out방식입니다. 텍스트는 부모 요소를 확장합니다. 이것이 HTML이 자연스럽게 하려는 방식입니다.
이처럼 구조를 잡으면, CSS 레이아웃은 계산 측면에서 꽤 간단합니다. 부모의 제약 조건을 자식에게 전달하고, 반대로 자식의 크기를 모아 부모에 반영할 수 있습니다. 이는 매력적이며, 요소와 텍스트 콘텐츠 측면에서 웹페이지를 잘 확장할 수 있게 해줍니다.
CSS는 기본적으로 항상 inside-out 방식이며, 이는 문서 지향적인 특성을 반영합니다. body { height: 100% }부터 시작하여 모든 제약 조건을 전달하는 것은 개발자의 몫이기 때문에 outside-in 방식은 명확하지 않습니다. 바로 이러한 이유때문에 CSS에서 세로 정렬이 항상 어렵다고 말하는 것입니다.
 spill-free 자동 레이아웃과 완전히 합리적인 간격을 위해 flex grow와 shrink를 사용
spill-free 자동 레이아웃과 완전히 합리적인 간격을 위해 flex grow와 shrink를 사용
위의 상황은 공간 분할 방법을 명확히 통제할 방법을 제공하는 CSS3 플렉스 박스 (display: flex)로 더 잘 다룰 수 있습니다.
안타깝게도 플렉스 박스를 사용하면 단순한 CSS 모델이 더 복잡해집니다. 자동으로 플렉스 처리를 하려면, 레이아웃 알고리즘은 모든 자식의 "본래 크기"를 반드시 측정해야 합니다. 이는 처음엔 대략 추측하여 배치하고, 그다음 크기에 맞게 늘리거나 줄이는 방식으로 한 번 더 배치하는 것을 의미합니다.
이 방식이 합리적으로 느껴질 수 있지만, 재귀적이기 때문에 숨겨진 문제를 동반할 수 있습니다. 부모 요소를 추측적으로 레이아웃하는 작업은 종종 크기가 정해지지 않은 자식 요소에 대한 전체 레이아웃 계산을 필요로 합니다. 예를 들어, 텍스트가 어떻게 감싸지는지 알아야 합니다. 중첩을 제대로 하면, 이론적으로는 기하급수적으로 계산량이 늘어날 수 있지만, 실제로 문제가 된 사례는 들어본 적이 없습니다.
대신 누군가가 큰 콘텐츠를 어디선가 삽입했을 때, 갑자기 모든 레이아웃이 뒤죽박죽이 되어야만 이 문제가 드러납니다. 이는 앞서 언급한 머그잔의 예시와는 정반대입니다.
재귀적 의존성을 피하려면, 자식의 콘텐츠를 외부로부터 격리하여 추측적 레이아웃 작업을 중요성을 낮춰야 합니다. 이는 contain: size 또는 수동으로 flex-basis 크기를 설정하여 수행할 수 있습니다.
CSS는 레이아웃 시스템에 직접 연동되는 contain 또는 will-change와 같은 일부 구문을 확보하여 모두 하나의 큰 레이아웃이라는 전제를 버리게 해줍니다. 이는 내부의 레이어 지향적 특성을 일부 드러내며, position: absolute와 같은 래퍼 사용을 대체할 수 있습니다.
이는 일부 시맨틱을 벗겨내고, DOM 전반의 제약조건을 없앱니다. 기본적으로 범위가 너무 넓고, 단순한 경우에는 문서 지향적 성격이 강합니다.
이는 실제로 모든 DOM API에 대한 은유라고 볼 수 있습니다.
좋은 점은 없을까요?
그렇지만 위에서 언급한 주의 사항을 이해하고 있다면, 플렉스 박스는 꽤 괜찮은 기능입니다. 직관적으로 중첩된 행과 열에 간격을 두고 레이아웃을 만들고, 다양한 크기에 맞게 조정할 수 있습니다. 충분한 애정을 통해 인체공학적으로 만들 수 있는 "CSS의 좋은 점"이 있습니다. CSS 그리드 또한 유사하게 동작하지만, 문법적으로 매우 CSS스럽기 때문에 고통스럽습니다.
하지만 CSS 레이아웃을 처음부터 설계한다면 이러한 방식으로 할 필요가 없습니다. 추가적인 containment 장벽 힌트와 함께 subtractive API를 사용하지 않을 것입니다. 대신에 동작을 구성 요소 단위로 나누고, 필요에 따라 선택적으로 이용할 것입니다. Outside-in과 Inside-out은 모두 다른 두 종류의 컨테이너와 배치 모델로 볼 수 있습니다.
inline-block과 inline-flex 디스플레이 모델이 이를 잘 보여줍니다. 내부적으로는 block또는 flex이지만, 외부적으로는 inline 요소입니다. 이는 대부분 박스 모델에서 박스의 두 가지 직교하는 측면입니다.
사실 하이퍼텍스트에서 텍스트와 글꼴 스타일은 조금 특이합니다. 글꼴 크기와 같은 속성은 부모에서 자식으로 상속되므로, <b>와 같은 서식 태그가 동작합니다. 그러나 대부분의 660개 CSS 속성은 그렇지 않습니다. 예를 들어, 요소에 테두리를 설정한다고 해서 그 자식들에게도 재귀적으로 같은 테두리가 적용되지는 않습니다. 이는 어리석은 동작입니다.
CSS는 상속을 기반으로 리치 텍스트를 스타일링하는 시스템과, 상속 없이 재귀적으로 중첩되는 block과 inline 요소를 위한 레이아웃 시스템, 이 두 가지가 적어도 섞여 있음을 보여줍니다. 이들은 동일한 구문과 API를 사용하지만, 실제 동일한 방식으로 계단식 스타일 규칙이 적용되지는 않습니다. 이 두 가지를 하나의 스타일 체계 아래 합친 것은 실수였습니다.
덧붙이자면, 초기의 상대적인 em 스케일링 아이디어는 이제 거의 무의미해졌습니다. 이제는 논리적 픽셀과 디바이스 픽셀을 비교하는 것이 훨씬 더 합리적이며, 사용자들이 실제로 기대하는 바에 더 가깝습니다.

SVG도 네이티브로 통합되어 있습니다. DOM 내에 <img> 대신 SVG를 넣는 것이 동적으로 생성된 모형과 아이콘 스타일을 조정하는데 유용합니다.
SVG는 강력하지만, CSS의 부분 집합도 아니고 상위 집합도 아닙니다. 일부 기능이 겹치더라도, 예를 들어 아핀 변환(affine transform)처럼 미묘한 차이가 있습니다. 또한 모든 좌표를 문자열로 직렬화하는 등의 문제점도 있습니다.
CSS도 이제 모서리 둥글림, 그라데이션, 임의의 클리핑 마스크를 지원합니다. 분명 SVG를 부러워하는 기능이지만, 아직 많이 부족합니다. 예를 들어, SVG는 마우스 이벤트에 대한 다각형 히트 테스팅(hit-testing)이 가능하지만 CSS는 불가하며, SVG에는 자체 그래픽 레이어 효과 세트를 갖고 있습니다.
HTML/CSS와 SVG는 모두 백엔드에서 확장 가능한 벡터일지라도, 특정 요소를 렌더링하기 위해 둘 중 어느 것을 사용할지는 성가신 트레이드오프에 기반합니다.
어느 쪽이든 몇 가지 장애물이 있는데, 그중 세 가지만 언급하겠습니다.
text-ellipsis는 전체 단락이 아닌 줄 바꿈되지 않은 텍스트를 말 줄임하는 데만 사용할 수 있습니다. 말 줄임 된 텍스트를 감지하는 것은 텍스트를 측정하는 것과 마찬가지로 API가 적절하지 않기 때문에 훨씬 더 어렵습니다. 모두가 글자 수만 계산합니다.position: sticky는 스크롤 하는 동안 요소가 흔들림 없이 제자리에 유지될 수 있도록 합니다. 이 목적을 위해 맞춤 제작되었지만, 미묘하게 깨졌습니다. 요소가 무조건 고정된 상태로 유지하려면 사소한 상황에서도 터무니없는 중첩 해킹이 필요합니다.z-index프로퍼티는 절대적인 인덱스 값으로 레이어 순서를 결정합니다. 이에 따라 필연적으로 모든 사람이 레이어 순서를 위해 새로운 숫자 +1 또는 -1을 입력하는z-index-war.css로 이어집니다. 상대적인 Z 위치 지정이라는 개념은 없습니다.
이러한 기능에 대해 우리는 올바른 프리미티브를 제공받는 대신, 어떻게든 동작하도록 만드는 v1 버전에 갇혀버렸습니다.
이 문제를 제대로 해결하는 것은 쉽지 않습니다. API 설계의 가장 어려운 부분입니다. 최종적으로 완성하기 전에 실제로 사용해보면서 부족한 부분을 찾아내는 방식으로 반복적으로 개선해 나가야 합니다.
캔버스의 오일
자 그래서 DOM은 형편없고, CSS는 겨우 한자리 숫자 X% 수준이며, SVG는 못생겼지만 필요한데.. 이걸 고치려는 사람이 아무도 없는 걸까요?
그렇지 않습니다. 중간 계층은 이제 누구에게도 적합하지 않다는 결론입니다. 단순히 불필요한 요소를 제거하는 HTML6만 나오더라도 좋은 출발점이 될 수 있습니다.
하지만 가장 먼저 해야 할 일은 이미 존재하는 기능을 해방시키는 것입니다. 이는 잘못된 방법으로도, 올바른 방법으로도 수행될 수 있습니다. 사용자 정의 용도를 위한 "탈출구"가 사용자가 쓰는 API와 동일한 구조를 갖도록 시스템을 설계하는 것이 이상적입니다. 이것이 바로 도그푸딩(dogfooding)이며 좋은 커널을 얻는 방법이기도 합니다.
최근 제안된 방식 중 하나는 HTML 콘텐츠를 <canvas>에 그려서 시각적 결과물을 완전히 제어할 수 있는 HTML in Canvas입니다. 하지만 그다지 좋지 않아 보입니다.
유용해 보일 수는 있지만, API가 지금과 같은 형태를 갖는 이유는 DOM에 억지로 맞춰졌기 때문입니다. 레이아웃과 스타일링에 완전히 관여하고, 접근성을 동작하게 하기 위해서는 요소가 반드시 <canvas>의 하위 요소여야 합니다. 또한 화면 밖에서 사용하는 데에는 "기술적인 문제"도 있습니다.
한 가지 예로 회전하는 큐브를 들 수 있습니다.

상호작용을 하도록 만들기 위해서, 히트 테스팅 직사각형을 부착하여 페인트 이벤트에 응답하도록 하였습니다. 이는 새로운 형태의 히트 테스팅 API입니다. 그러나 2D에서만 동작합니다... 그럼 3D 용도는 사실상 겉치레에 불과한 걸까요? 궁금한 점이 많습니다.
다시 말하지만, 만약 처음부터 설계했다면 이런 식으로 하지 않았을 겁니다! 특히, 렌더링과 같이 단지 어떻게 보이는지를 사용자화하기 위해 요소와 그 하위 요소에 대한 모든 상호작용 책임을 맡아야 하는 것은 정말 어처구니 없는 일입니다. 특히 브라우저가 CSS 3D 투영을 지원하는 상황에서 말이죠.
곡선형 재투영과 같이 여기에 포함되지 않는 사용 사례는 직사각형보다 더 복잡한 히트 테스팅이 필요합니다. 이 부분을 충분히 고려했을까요? 만약 드롭다운을 넣으면 어떻게 될까요?
제 생각에는 CSS와 SVG 필터를 통합하거나 CSS에 셰이더(shader)를 추가하는 방법을 제대로 찾지 못한 것 같습니다. 남아있는 유일한 방법은 캔버스를 통해 전달하는 것입니다. "적어도 프로그래밍은 가능하다."고 하지만, 과연 그럴까요? DOM 콘텐츠를 스크린샷으로 찍는 건 좋은 사용 사례일 뿐, 이 기능의 목적에는 전혀 부합하지 않습니다.
"캔버스에서 복잡한 UI"를 만드는 이유는 콘텐츠 가상화, just-in-time 레이아웃과 스타일링, 시각 효과, 사용자 정의 제스쳐, 히트 테스팅 등과 같이 DOM이 하지 않는 모든 작업을 수행하기 위해서입니다. 이는 모두 핵심 기능입니다. 사운드를 그리기 위해 모든 DOM 콘텐츠를 미리 준비해야 하는 것은... 매우 비생산적입니다.
반응성의 관점에서도 옵서버와 잠재적인 사이클을 만듭니다. 때문에 이를 동일한 문서 트리를 통해 다시 전달하는 것은 좋지 않습니다. DOM 콘텐츠를 렌더링하는 캔버스는 이제 더 이상 문서 요소가 아니라, 완전히 다른 일을 하고 있는 셈입니다.
 전체적으로 DOM을 생략하는 캔버스 기반의 스프레드시트
전체적으로 DOM을 생략하는 캔버스 기반의 스프레드시트
캔버스의 치명적인 약점은 시스템 글꼴, 텍스트 레이아웃 API 또는 UI 유틸리티에 실제로 접근할 수 없다는 것입니다. 얼마나 기본적인 기능들인지를 생각하면 정말 황당한 일입니다. 단지 줄 바꿈된 텍스트를 얻기 위해서 유니코드 단어 분할을 포함한 모든 기능을 처음부터 구현해야 합니다.
제안된 방식은 "DOM을 콘텐츠의 블랙박스로만 사용하라."는 것입니다. 하지만 우리는 이 방식으로 CSS/SVG 조립 외에는 아무것도 할 수 없다는 것을 이미 알고 있습니다. text-ellipsis와 같은 기능은 깨져 있고, 이를 해결하려면 1990년대식 UI를 처음부터 다시 구현해야 합니다.
실제로 중간 수준의 기능을 원할 땐 도 아니면 모입니다. 그러므로 하위 수준이 열려 있어야 합니다.
향후 방향
‘HTML in Canvas’의 목표는 공감할 만합니다. HTML 조각을 자유롭게 조각처럼 사용할 수 있다는 개념은 이미 내부적으로 존재해 왔습니다. 이는 다룰 수 있는 복합적인 값 유형입니다. 그러나 동시에 20년간 쌓인 불필요한 짐을 끌어안으면서, 실제로 혁신적인 기능을 제공하지 않는 방식이어서는 안 됩니다.
웹의 조립으로 인해 거대한 정체와 일반적인 UI의 정교함을 잃게 되었습니다. UI 동작을 div에서 가져와야 할 경우, 고려할 수 있는 선택지의 종류가 제한됩니다. 내부에 많은 혼란이 있기 때문에 DOM/HTML에서 이 문제를 해결하는 것은 현명한 선택지가 아닙니다. 대신 외부에 새로운 표면을 열어야 합니다.

 WebGPU 기반의 박스 모델
WebGPU 기반의 박스 모델
제가 자주 언급하는 것은 복잡한 코드나 코드의 일부로 X/Y 플렉스 모델을 수행하는 Use.GPU의 HTML-like renderer입니다. 제가 만든 것이 아주 훌륭하다는 뜻이 아니라, 꽤 기본적이고 틈새 시장용이지만 확실히 더 편리하다는 뜻입니다. 세로 정렬도 쉽고, 위치 지정도 직관적입니다.
여기엔 시맨틱 HTML 또는 CSS는 없고, 일급 레이아웃만 있습니다. border*용 61개의 접근자가 필요하지도 않습니다. 그냥 div에 셰이더를 추가하면 됩니다. 이게 사람들이 원했던 거 아닐까요? 여기 청사진이 있는데, 대부분 SDF입니다.
글꼴과 마크업 문제는 텍스트가 위치하는 트리의 리프 수준에만 나타납니다. HTML/CSS/SVG의 복잡성 없이 DOM이 하는 일의 90%를 수행할 수 있다는 것은 놀랍습니다. 심지어 한 사람이 해냈습니다. 그리고 나머지 90%도 있다는 걸 알고 있습니다.
전통적인 데이터 모델은 뷰 트리와 렌더 트리로 구성되어 있습니다. 뷰 트리는 실제로 어떤 모습이어야 할까요? 그리고 무엇을 더 낮출 수 있을까요? 거대한 레거시 더미에 의해 지금 무엇이 낮춰지고 있을까요?


Servo나 Ladybird와 같은 대체 브라우저 프로젝트는 여기에 좋은 제안을 할 수 있는 위치에 있습니다. 이들은 가장 최신 구현을 갖고 있으며, 가장 필수적인 기능부터 목표로 삼고 있습니다. 대형 브라우저 벤더도 가능하지만, 결국 맛이 중요합니다. 크고 좋은 시스템은 작고 좋은 시스템으로부터 성장하는 것이지, 크고 나쁜 시스템에서 성장하는 게 아닙니다. 모질라가 망하지 않았다면 어땠을지.. 참 아쉽습니다.
플랫폼 네이티브 UI 툴킷은 아직 선언형과 반응형의 UI를 따라잡고 있습니다. Tauri와 같은 네이티브 Electron 대체 도구는 도움이 될 수 있지만, 오리진(origin) 격리를 설계 제약으로 삼지 않아 보안팀을 불안하게 합니다.
하지만 프로세스 격리 개선이라는 유인책을 제시할 수 있습니다. Spectre와 같은 CPU 착취 도구로 인해 SharedArrayBuffer와 웹 워커를 통한 멀티 스레딩은 진작에 유명무실해졌고, 이는 모두 WASM에 영향을 미칩니다. 세부 사항은 지루하지만, 현재로서 웹 사이트에 OAuth 및 Zendesk와 같은 기능이 통합되어야 하는 상황에서는 불가합니다.
모든 레거시 문제를 해결하기 위해 DOM을 다시 개발하는 것은 멀티 스레드, 멀티 오리진, 비동기 웹을 위해 재설계하는 것과 같을 수 있습니다. 브라우저 엔진은 이미 멀티 프로세스인데,, 그들은 무엇을 배웠을까요? 넷스케이프 이후 구조적 동시성, 소유권 시맨틱, FP 효과 등 많은 발전이 있었고, 이 모든 것이 유용하게 사용될 수 있습니다.
첫 번째 단계는 노드당 350개 이상의 속성이 없는 데이터 모델을 만드는 것입니다.
그리고 이 문제를 완전히 해결하는 것은 불가능하다고 착각하지 마세요.


8개의 댓글


A sharp, thoughtful riff on why the DOM often feels like a legacy API — part rant, part prescription. Saved it to my architecture pile; when I need a quick breather from browser debates I relax with a round at https://www.royaledlegame.online
.

Reading about “HTML은 죽었다” got me thinking, wow, a web without DOM sounds super futuristic but also kinda confusing. I’m curious how fast developers will adapt. Had this tool(https://www.growagardencalculator.click/calculators/grow-a-garden-pet-age-calculator) open too while scrolling, so my brain’s juggling random stuff right now.

Interesting thoughts on HTML and DOM evolution. It reminds me of how games like Coin Master keep updating too. I love getting coin master daily free spins to play with my daughter—it's a fun break from coding!


I strongly recommend several very useful AI websites!
1:Unlock your creative potential with Flux AI. Generate images, videos, and content from text using advanced AI. Fast, intuitive, and totally free to start.https://www.fluxaicreate.org/
2:Upload a selfie and preview thousands of styles before you visit the salon—no regrets, just great hair.Visualize any haircut or hair color on your own photo.https://www.ai-hairstyle.art/
따라서 저는 이제 DOM과 DOM 관련 API를 계속 제공해야 하는 이유와, 그것을 가능하게 할 방법에 대해 몇 가지 아이디어를 제시하려 합니다. PerYourHealth