★ [학습목표]
Titanic 생존자 분석 데이터를 기반으로 데이터 전처리(preprocessing) 과정을 이해한다.
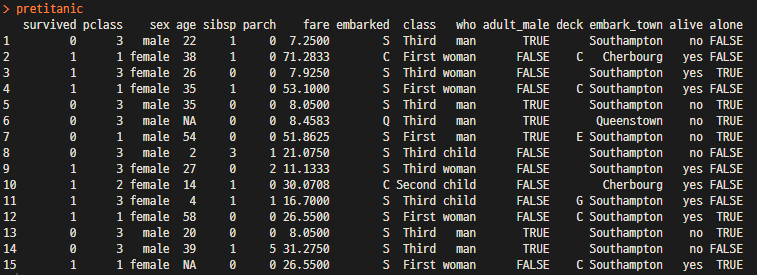
1) Titanic Data를 훑어보면 아래와 같은 정보를 확인할 수 있다.
- 데이터 Column에는 생존여부, 성별, 나이, 요금, 등급, 동반자 여부 등의 데이터가 포함되어 있음
- 일부 데이터는 NA, Null(blank)의 결측치가 있음
- 데이터는 숫자형, 문자형이 조합되어 있음.
- 등등
2) 데이터를 전처리 하기위해서는 R에서 제공하는 package를 이용할 수 있다.
- 대표적인 전처리 패키지는 dplyr a)이다.
- 파이프 연산자를 사용할 수 있다.
a) dplyr은 R 언어에서 데이터 조작을 위한 패키지 중 하나입니다. Hadley Wickham이 개발한 이 패키지는 데이터프레임을 다루는 작업을 간단하고 효율적으로 만들어 줍니다. dplyr은 데이터의 필터링, 정렬, 요약, 변형 등 다양한 작업을 수행할 수 있는 함수들을 제공합니다. 주요 기능으로는 다음과 같은 것들이 있습니다:
- filter(): 특정 조건을 만족하는 행을 선택합니다.
- select(): 특정 열을 선택하거나 제외합니다.
- mutate(): 새로운 열을 추가하거나 기존 열을 변형합니다.
- summarise(): 데이터를 요약합니다.
- group_by(): 그룹별로 데이터를 분리합니다.
- arrange(): 데이터를 정렬합니다.
- join(): 두 개 이상의 데이터프레임을 결합합니다.
이러한 함수들을 조합하여 데이터를 유연하게 처리하고 분석할 수 있습니다. dplyr은 데이터 과학 및 데이터 분석 작업에서 매우 인기가 있으며, tidyverse의 일부로 포함되어 있어 다른 tidyverse 패키지와도 호환성이 뛰어납니다.
## 전처리 preprocessing
library(dplyr) # Data Processing Package 호출
pretitanic <- read.csv("preprocess_titanic.csv") # Raw data를 호출하여 별도의 파일로 저장
head(pretitanic) # Raw data 규모를 모르므로 첫 몇열만 출력 후 review
is.na(pretitanic) # pretitanic(별도파일)의 NA 포함여부 확인
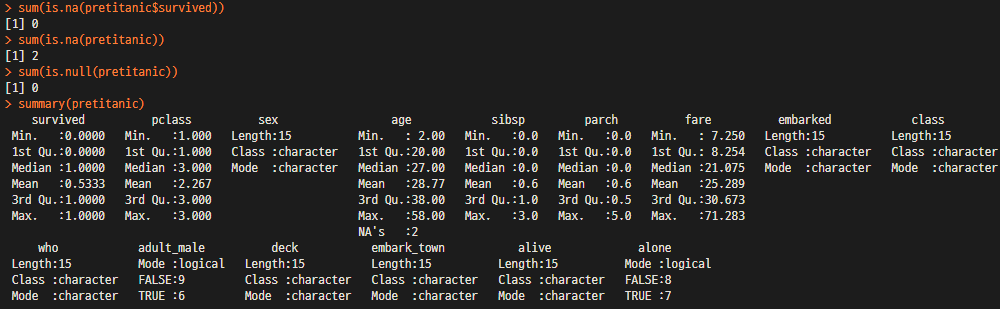
sum(is.na(pretitanic$survived)) # pretitanic의 survived 열 NA 갯수 확인
sum(is.na(pretitanic)) # pretitanic 모든 열 NA 갯수 확인
sum(is.null(pretitanic)) # pretitanic 모들 열 Null 갯수 확인
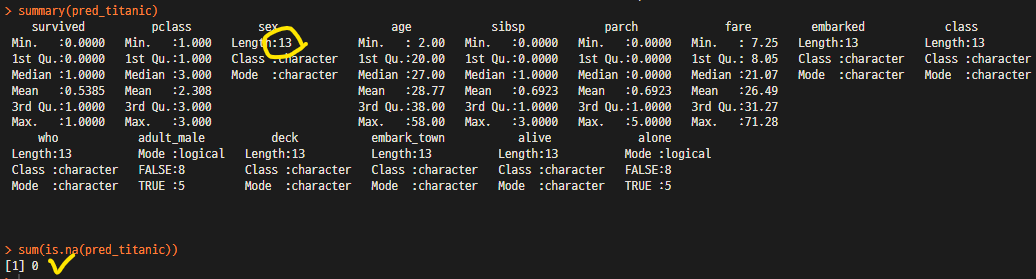
summary(pretitanic) # pretitanic 모든 열 기술 통계치 확인
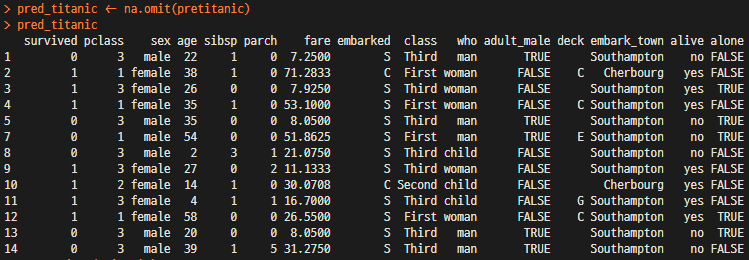
pred_titanic <- na.omit(pretitanic) # pretitanic 모든 NA 제거후 pred_titanic에 재저장
pred_titanic # 결측치가 제거된 pred_titanic 호출후 확인
summary(pred_titanic) # pretitanic 모든 열 기술 통계치 확인
sum(is.na(pred_titanic)) # 결측치 제거결과 최종확인1단계) Raw data 규모를 모르므로 첫 몇 열만 출력 후 review

2단계) pretitanic(별도파일)의 NA 포함여부 확인
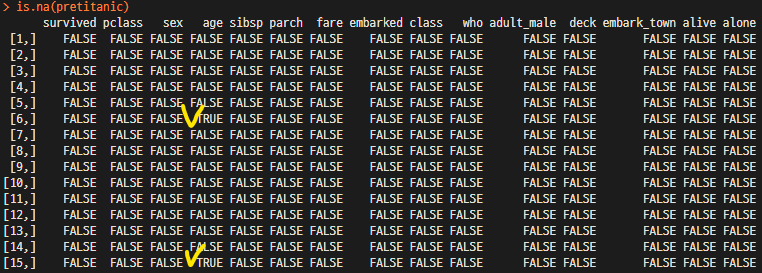
3단계) pretitanic의 survived 열 NA 갯수 확인
4단계) pretitanic 모든 열 NA 갯수 확인
5단계) pretitanic 모든 열 기술 통계치 확인
6단계) pretitanic 모든 NA 제거후 pred_titanic에 재저장
7단계) 결측치가 제거된 pred_titanic 호출후 확인
8단계) 결측치 제거결과 최종확인
-
2개의 NA 데이터가 제거되어 13개의 행(row)으로 구성
-
NA 갯수 확인 후 "0" 임을 확인함.
-
이제부터 pred_titanic으로 분석을 시작할 수 있다.
A단계) 필요한 Column 만 추출한다.
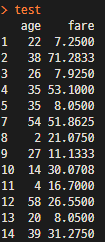
select(pred_titanic, age, fare)
test<-select(pred_titanic, age, fare)
test※ 같은 요령인데 아래도 select 와 같은 개념이다.
# 데이터 분석을 위한 컬럼 삭제
test <- pred_titanic[name(pred_titanic) %in% c("age","fare")]
B단계) 나이와 요금과의 관계를 비교해본다.
install.packages("psych")
library(psych)
pairs.panels(test)