[R] Data Processing
- 데이터분석 실무과정에서 내부터이터의 특징을 확인하고, 처리하고, 순위, 빈도 등을 확인하는 과정에 대해 알아본다. 단, 오늘은 내부데이터인 "iris"를 활용하는 것을 전제로 설명한다.
1) iris 데이터의 기본 통계량을 확인할 때 summary 함수 사용
summary(iris) # 컬럼별 통계치 확인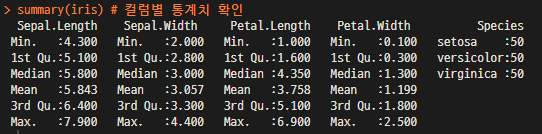
2) iris 데이터의 기본 구조를 확인하는 glimpse 함수 사용
install.packages("dplyr")
library(dplyr)
glimpse(iris) # dplyr 패키지 : 데이터 구조 확인
3) iris 데이터의 기본 구조를 확인하는 str 함수 사용
str(iris) # 데이터 구조 확인
4) data 의 빈도를 표시할때 사용하는 table 함수 사용
- 컴퓨터가 임의로 2(2이상 2.1미만), 2.2(2.1이상 2.2미만) 등으로 지정하여 빈도를 표시해준다.
table(iris$Sepal.Width)
- data 의 빈도수를 종류별로 크키별로 2차원으로 표현할때도 사용가능
table(iris$Sepal.Width, iris$Species)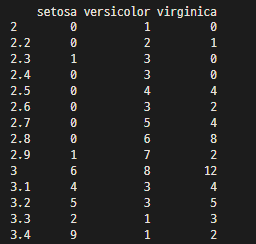
5) data 의 문자열의 고유값을 확인하는 unique 함수 사용
- 예시) 게임회사에서 당일 로그인했던 사람이 몇명인지 알고 싶을때. 몇명이 다수접속을 했을 수 있다. 실제 접속한 사람의 정보가 필요할때 유용함.
unique(iris$Species)
unique(subset.data.frame(iris, select = c("Sepal.Width","Species" )))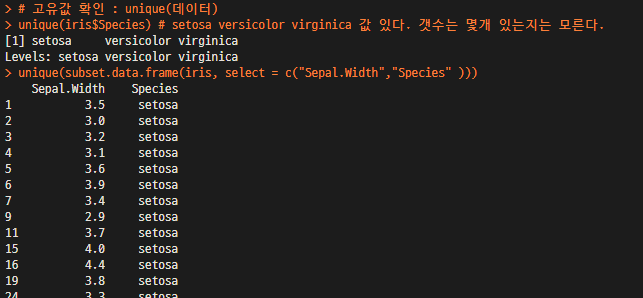
6) data의 오름차순 정렬 ( sort vs order )
# 값의 오름차순 정렬 : sort(데이터)
sort(table(iris$Sepal.Width))- sort는 오름차순으로 column을 정렬한다. 단, 다른 column과의 연계는 되지않는다. 그래서 2차원 table data를 오름/내림 차순으로 정리할 경우에는 Order 함술를 사용한다.
head(iris)
order(iris$Petal.Length)
head(iris[order(iris$Petal.Length),])
head(iris[order(iris$Petal.Length, decreasing=T),])- iris data를 상위 6개 행만 확인하고, petal.length기준으로 오름차순으로 나머지 열을 같이 묶어서 정렬하되 6개만 뿌린결과이다. 단, petal.length로 정렬했지만, sepal.length로 재정열할 때는 data를 덮어써야 한다. 이럴때는 pipe operator 를 주로 사용한다.
7) data의 일부 열만 추출하는 subset 함수 사용
- 특정변수 추출 : subset.data.frame(데이터프레임, select = c("컬럼명1","컬럼명2", ... ))
subset.data.frame(iris, select = c("Petal.Length","Sepal.Width"))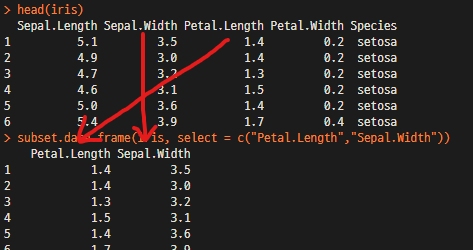
Raw data의 5개의 column중 2개의 column을 원하는 순서에 맞게 추출이 가능하다.
- 특정변수 내에서 값의 범위를 설정하고 그 data만 추출 할 때도 사용가능
예) iris data 중 petal.length 가 1.5이상인 data만 추출할 경우- subset.data.frame(데이터프레임, subset = c(조건))
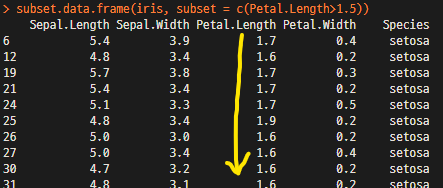
# 조건에 만족하는 데이터프레임 추출 : subset.data.frame(iris, subset = c(Petal.Length>1.5))
- subset.data.frame(데이터프레임, subset = c(조건))
