R 을 이용해 Raw Data를 탐색(EDA)하고, 분석을 위한 전처리과정을 거친 후 유의미한 결과를 얻기위해 데이터를 가시화할 수 있는 방법을 활용할 수 있다.
오늘은 R에서 제공하는 Data visualization 방법을 일부 다루도록 한다.
기본적으로 그래프는 독립변수(X축, 제어변수)와 종속변수(Y축)로 구분된다.
1) 그룹(A,B,C,D)별, 판매실적을 막대그래프로 표현방법
a <- matrix(c(3,5,2,6,7,2,3,6),4,2)
barplot(a) # 누적 막대그래프
barplot(a, beside = T, main = "통계량", legend = c('A그룹','B그룹','C그룹','D그룹') ) # 그룹 막대그래프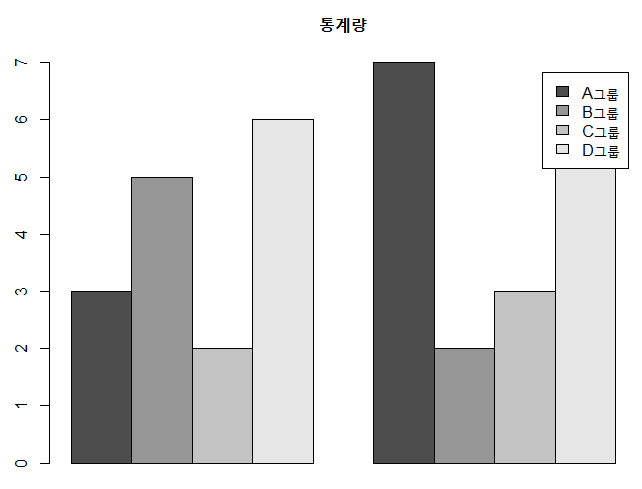
2) 실험시 독립변수에 대한 종속변수의 평균값의 Error Bar 표현방법
# Most basic error bar
ggplot(data) +
geom_bar( aes(x=name, y=value), stat="identity", fill="lightgray", alpha=0.7) +
geom_errorbar( aes(x=name, ymin=value-sd, ymax=value+sd), width=0.3, colour="orange", alpha=0.9, size=2)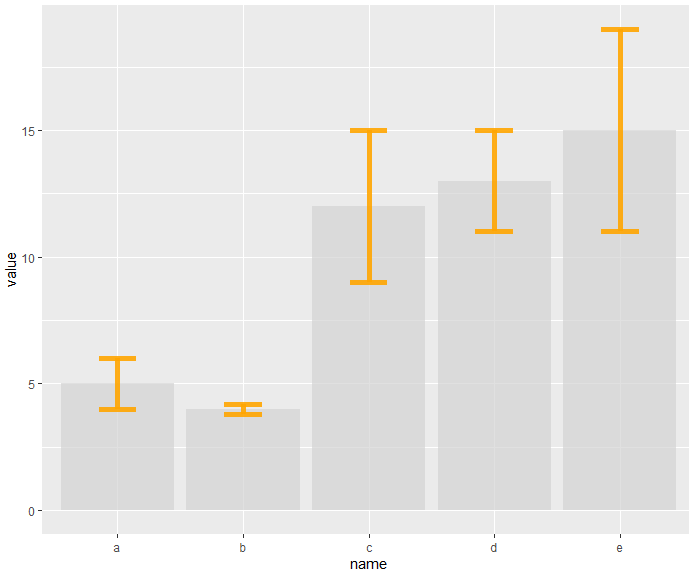
3) 데이터 산점도 표현방법
# 4.2
# 산점도 : plot(x = x축데이터, y = y축데이터, main = "제목", sub = "부제목", xlab = "x축명", ylab = "y축명", axes = "테두리", type = "Plot타입", col = "색상값", lty = "선종류", pch = "점모양")
# - Plot 타입 : p(점) l(선) b(점-선) c(점이없는 선) o(점을 통과하는 선) h(수직선 히스토그램) s(계단형/왼쪽값기초) S(상위 계단형/오른쪽값기초) n(그래프 미표시)
# - 선종류 : 0("blank",투명선) 1("solid",실선) 2("dashed",대쉬선) 3("dotted",점선) 4("dotdash",점선과 대쉬선) 5("longdash",긴 대쉬선) 6("twodash",2개의 대쉬선)
# - 색상값 : 0(white,희색) 1(black,검정) 2(red,빨강) 3(green,초록) 4(blue,파랑) 5(turquoise,연파랑) 6(magenta,보라) 7(yellow,노랑) 8(gray,회색)
# - 점모양 : 0(사각형) 1(원) 2(삼각형) 3(십자) 4(X) 5(다이아) 6(역삼각형) ~ 24(회색삼각형) 25(회색역삼각형)
plot(2,1)
plot(c(2,2), c(4,3))
plot(iris$Sepal.Length, iris$Sepal.Width)
plot(Sepal.Width ~ Sepal.Length, data = iris)
plot(Sepal.Width ~ Sepal.Length + Petal.Length, data = iris)
plot(Sepal.Width ~ ., data = iris)
plot(Sepal.Width ~ Species, data = iris)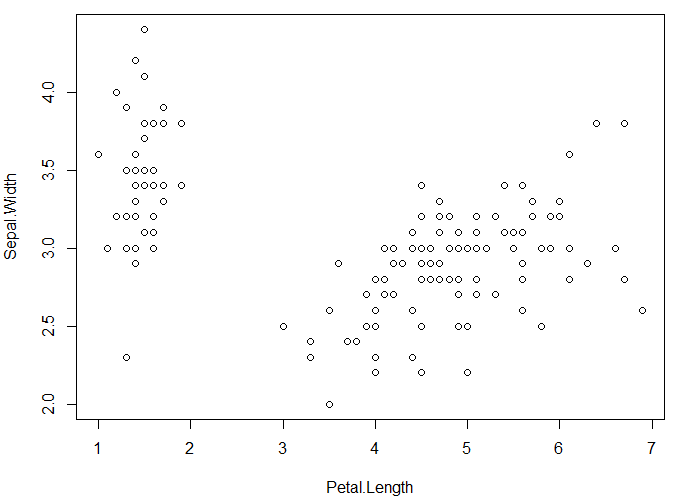
4) 산점도 행렬 (데이터 간 상관성 분석시 활용가능)
# 4.3
# 산점도 행렬 : pairs(데이터)
pairs(iris)
install.packages("psych")
library(psych)
pairs.panels(iris)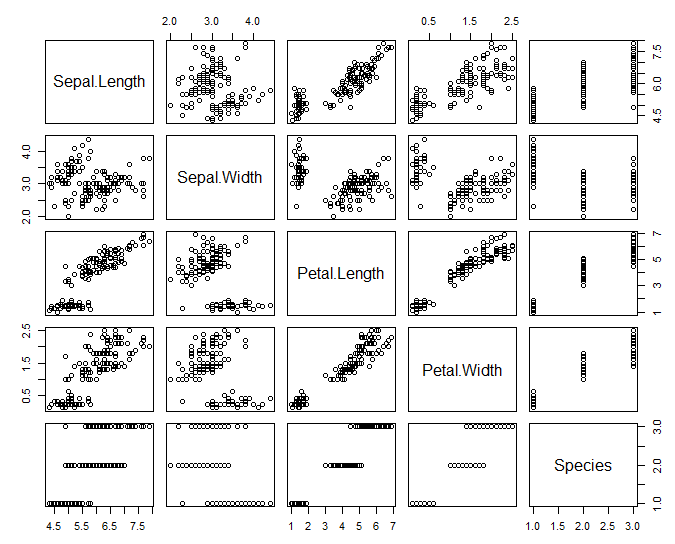
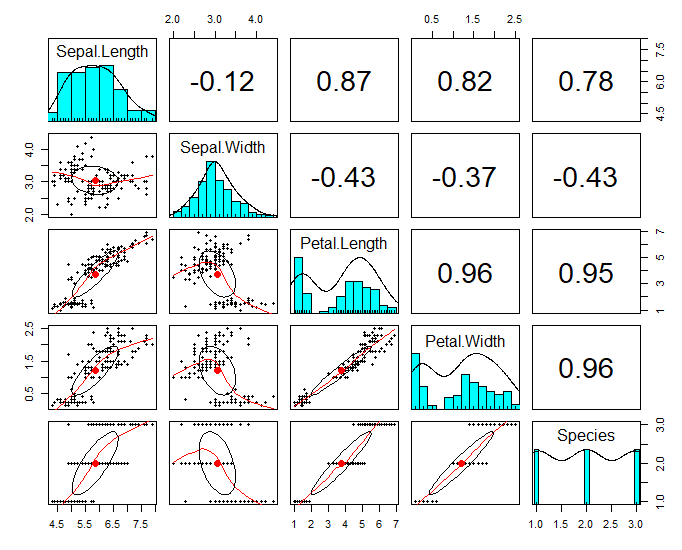
5) 등고선도
install.packages("plotly")
library(plotly)
ff <- list(family = "Courier New, monospace", size = 12, color = "black")
x <- list(title = "Sepal.Length", titlefont = ff)
y <- list(title = "Sepal.Width", titlefont = ff)
p <- plot_ly(x = sort(x.grid), y = sort(y.grid), z = t(z.grid), contours = list(start = 0, end = 8, size = 0.5),type = "contour") %>% layout(xaxis = x, yaxis = y) #x, y축 라벨
p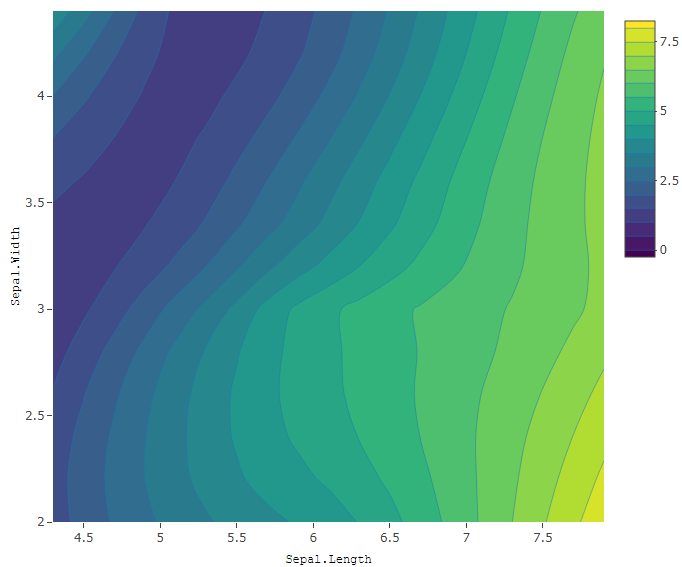
- 데이터 가시화 기법은 여러가지 방법이 있음을 확인하고, 필요할때 호출하여 사용하는 전략...
