★ [학습목표]
공공데이터를 전처리하여 데이터 분석을 진행할 수 있다.
- T-money 지하철 유무임별 이용현황 (24.4.3기준 sheet 3번이용)
df.pay <- read.csv("subway_pay.csv", fileEncoding = "CP949")
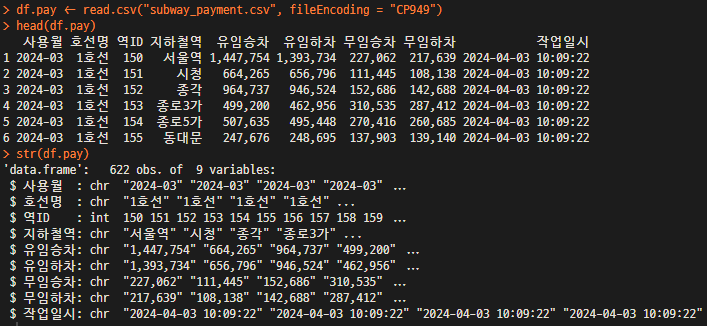
head(df.subway)
str(df.subway)
for(i in 5:8){
df.subway[, i] <- as.numeric(gsub(",", "", df.subway[, i]))
}
head(df.subway)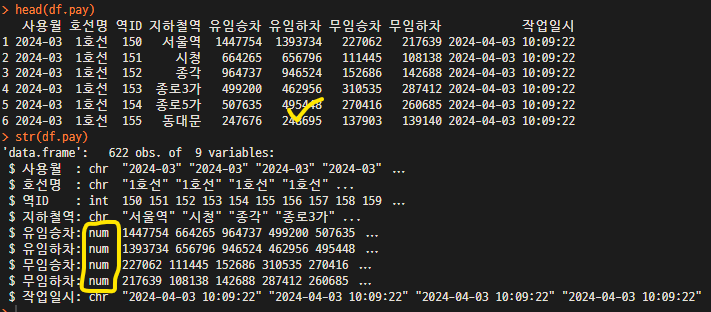
1. DATA 분석
가. 유무임 승차 비율 분석 : 소수점 처리
- 유임 승차 비율 높은 역
- 무임 승차 비율 높은 역
- 유임 하차 비율 높은 역
- 무임 하차 비율 높은 역
library(dplyr)
df.pay <- mutate(df.pay, ride=df.pay$유임승차+df.pay$무임승차) # 개별역 승차인원수 합계 추가
df.pay <- mutate(df.pay, getoff=df.pay$무임하차+df.pay$무임하차) # 하차인원수 합계추가
head(df.pay)
df.pay$paid_ride <- round(df.pay$유임승차/(sum(df.pay$유임승차)+sum(df.pay$무임승차))*100, 2)
# 전체 역에서 승차원원 합계에서 해당역에서의 유임승차 인원의 비율을 소수점 2자리로 표시
head(df.pay)
head(df.pay[order(df.pay$paid_ride, decreasing=T),], 5) # 조건없으면 오름차순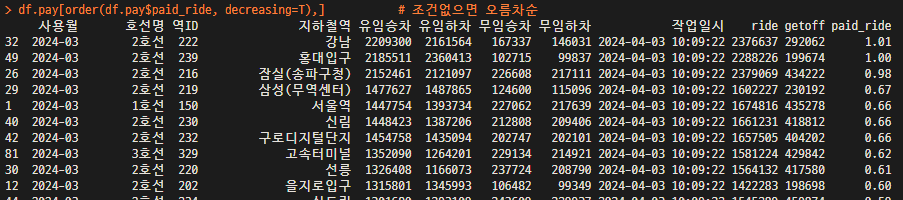
- 원하는 데이터의 분포를 확인 할 수 있다.
library(ggplot2)
ggplot(data = df.pay, aes(x = 호선명, y = 유임승차)) +
geom_boxplot()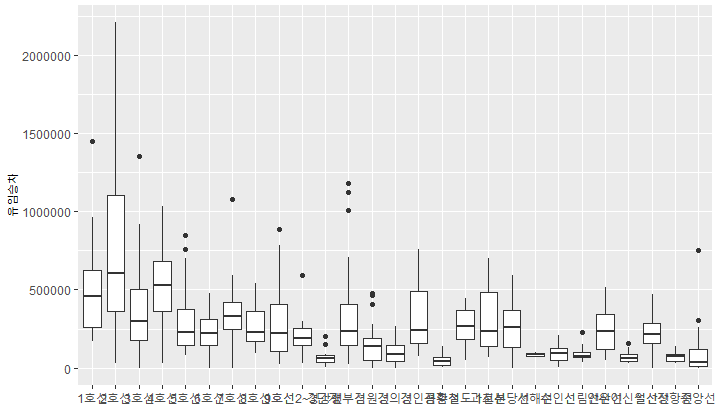
나. 최대값 찾기 : Data Normalization 하기 위해서 필요...
ex) 서울역에서 가장 붐비는 시간은 언제인가?
ex) 7~9사이에서 하차인원이 가장 많은 역?
- 특정역 최대 승/하차 시간대
- 최대값 위치 : which.max(df[행,])
- 최대값 컬럼명 : names(which.max(df[행,]))
- 최대값 인덱스 : as.vector(which.max(df[행,]))
- 최대값 : df[행,which.max(df[행,])]
max(df.pay[,5]) # 5번째 열에서 최대값을 Return
max(df.pay[,5], na.rm = T)
# na.rm=T:NA 결측치 처리 시 사용. na.rm이 TRUE -> max()함수는 최대값을 계산 시 NA 값 무시
df.pay[which.max(df.pay[,5]),] # 5번째 열에서 최댁값 index를 return하여 해당 행을 출력
