
0. 시작
Facebook(현 Meta)에서 발표한 Transformer 기반 Self-supervised learning 논문. 2019년 MoCo와 2020년 SimCLR가 Self-supervised learning 분야에 굵직한 Impact를 준 다음, 2021년에 트랜스포머 기반의 새로운 Self-supervised learning method가 이 논문을 통해 세상에 공개되었다.
저자들은 CNN의 Self-supervised learning과 비교해서 Transformer의 Self-supervised learning이 어떤 새로운 특성을 발견해내고 어떤 성능을 보여줄지 궁금해했다.
1. 심상치 않은 Figure.1
논문을 처음 열어보면 Abstract를 들어가기도 전에 Self-attention map이 figure.1로 나와있다.
이 figure는 지도 없이(no-supervision) DINO를 훈련시켰을 때 Vision Transformer(ViT)에서 추출할 수 있는 Self-attention map이라고 소개된다.
마치 열화상 카메라로 물체를 촬영한 듯이 정말 디테일한 부분까지 모델이 Attention map에 잘 표현했다고 할 수 있다. Computer Vision의 분야 중 Weakly Supervised Sementic Segmentation(WSSS)라는 분야에서 다루는 Class Activation Map(CAM)과 비슷한 '시각화 맵(Visualization Map)'이라고 할 수 있는데, 정성적인 결과가 매우 뛰어나다고 할 수 있다.
참고 : Figure 1은 ViT의 CLS 토큰 부분의 벡터를(CLS 토큰이 Query이고 패치 토큰이 Key) 마지막 Layer의 모든 Head에서의 Attention weight를 시각화 한 것이다.
DINO의 정성적인(Qualitative) 결과(Figure 1)는 매우 뛰어나다. 객체의 디테일한 부분을 놓치지 않고 잡아내며 Computer Vision 분야에서의 Transformer의 위용을 다시 한번 보여줬다. 심지어 모델은 정답을 배우지 않은 no-supervision 훈련의 결과물이다.
2. 그래서 정확히 얼마나 뛰어난데?
보통의 논문 리뷰들을 보면 실제 논문의 Flow를 그대로 따라가는데(Abstact-Intro-Aproach-Experiments) 나는 두괄식으로 이 논문의 성능을(그 당시) 자세히 비교하고 왜 이러한 성능이 나올 수 있었는지에 대한 방법론에 대해서 설명하고자 한다.
2.1. Main Results (ImageNet Classification)
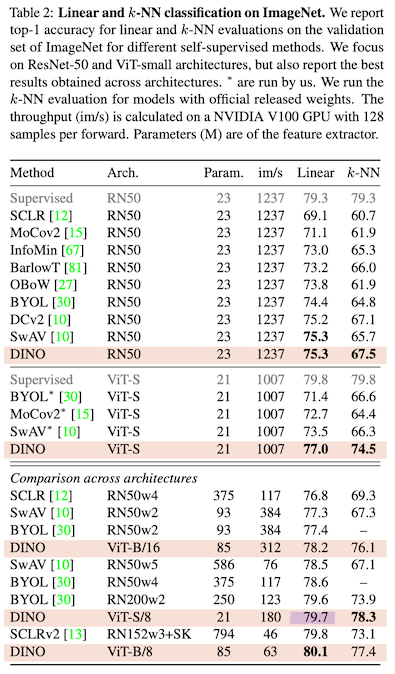
이 Table은 DINO 논문의 가장 핵심적인 성능 평가 표이다.
Self-Supervised Learning에서는 보통 Foundation Model(다운 스트림 태스크를 수행하는 사전훈련된 모델)을 만드는것에 주안점을 둔다. 그리고 그 모델의 Pretrained weight를 사용해서 MLP로 구성된 Linear Classifier 또는 kNN을 모델의 마지막 단에 달아주고 다운 스트림 태스크를 간단히 훈련-평가하는 과정을 거친다.
그래서 SSL 연구가 모델의 지능으로 Input data를 '알아서(self)' 어디까지 해석 할 수 있는지 그 끝을 보기 위한 연구로 해석된다.
이전에 발표된 Work들과 비교해서 DINO는 모든 면에서 뛰어난 성능을 보인다. 신기한 점은 DINO의 주된 안건은 Transformer w/ SSL인데 성능 평가에서는 RN50(ResNet50)을 백본으로 사용했을때도 다른 이전 Work들 보다 뛰어난 성능을 보였다.
성능으로 봤을때 DINO의 눈에 띄는 장점으로는 학습이 필요없이 알고리즘으로 Clustering만 필요로 하는 kNN 방식의 Classifier만으로도 이전 Work에 비해 훌륭한 성능을 냈다는 점.
Table에는 훈련속도와 관련된 지표(im/s : 초당 처리하는 단일 이미지의 장수)도 주어지고 전체 Parameter 개수(Million 단위)도 주어져 있기 때문에 DINO의 성과를 여러 방향으로 평가할 수 있다.
- ResNet에 비해 ViT의 성능이 뛰어나다.
- ViT의 Parameter중에서 Patch size가 작을 수록 성능이 좋다.
- 당연한 얘기지만 ViT의 전체적인 모델 규모가 크면 클수록 성능이 좋다.
- 성능이 좋을수록 im/s는 예외없이 구려진다.
2.2. Transfer learning (vs. Supervised)
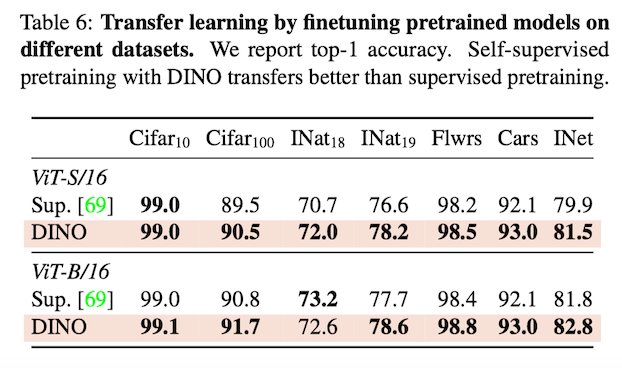
위 테이블은 지도학습 된 모델과의 전이 학습 성능을 평가한 표이다.
DINO는 Unsupervised Trainingd으로 Supervised Training을 앞지른다. 그만큼 모델이 개별 이미지의 특징이 되는 부분을 잘 이해하고 있다는 뜻. (e.g. Texture, Tactile과 같은 Properties)
2.3. etc
Copy detection, Image Retrieval, Video object segmentation에 관한 성능평가도 있는데 나는 잘 모르는 다운스트림 태스크이기도 해서 이 리뷰에서는 다루지 않는다.
3. Approach
DINO의 우수한 성능을 봤으니 이제 어떤 Flow로 모델이 Input부터 Objective Function까지 도달하는지 알아보자. 그리고 그 안에 숨은 디테일도 논문에 쓰인 내용을 바탕으로 분석할 예정이다.
3.1. Self-training and knowledge distillation.

Algorithm of DINO

Teacher와 Student로 구성되어 우수한 Teacher 모델의 지식(Knowledge)을 증류(Distillation)하는 기법인 KD(Knowledge Distillation) 방법에 대해서 알고 있으신가요?
DINO는 Self-supervised learning에 KD를 적용했다. (이 Self-supervised 훈련 방식은 DINO가 처음 제안한 방식은 아니다.)
3.1.1 Image Transformation
Input 이미지 를 , , ... , 으로 랜덤 Transformation한다. (Figure 2에는 설명을 위해 , 까지만 나와있다.)
코드 상으로는 다음과 같다.
with torch.cuda.amp.autocast(fp16_scaler is not None):
teacher_output = teacher(images[:2]) # only the 2 global views pass through the teacher
student_output = student(images)
loss = dino_loss(student_output, teacher_output, epoch)view의 종류로는 global view와 local view가 있는데 이는 transformation 방법에서 scale이 global(전역적)인지 local(지역적)인지에 대한 내용이다. images의 shape은 [10,B,3,w,h] 이며 10가지 view의 이미지 세트가 배치 개수만큼 들어있고 이중 [:2]에 해당하는 global view는 Teacher Network에 들어가고 나머지는 전부 Student Network에 들어간다.
3.1.2 Stop gradient and EMA update(student->teacher)
DINO 모델의 특징으로는 Teacher 모델은 직접 Back Propagation을 통해 파라미터들을 업데이트 하지 않고 Student Parameter에서 Exponential Moving Average(EMA : 지수이동평균) 방식을 사용해 Parameter를 업데이트 한다. (MoCo에서 Momentum Update를 하는 방식과 유사하다.)
EMA에 대한 업데이트 규칙은 위의 식과 같으며 는 훈련 중 0.996에서 1까지의 코사인 스케쥴러를 따른다.
# EMA update for the teacher
with torch.no_grad(): # Stop gradient
m = momentum_schedule[it] # momentum parameter
for param_q, param_k in zip(student.module.parameters(), teacher_without_ddp.parameters()):
param_k.data.mul_(m).add_((1 - m) * param_q.detach().data)이렇게 하는 이유는 특별한 인과관계가 있다기 보단 귀납적으로 이 프레임워크에서 이 방법이 특히 잘 작동한다는 것을 발견했기 때문이라고 설명한다.
Teacher model이 EMA 방식으로 student의 parameter를 받아오기 때문에 이는 student의 시간의 변화에 따른 checkpoint를 부드럽게 ensemble을 하여 student model의 일반성을 체득할 수 있다고 한다.

위의 Figure 6은 왜 EMA 방식으로 Teacher network를 Student network로 부터 업데이트 해야하나에 대한 근거가 될 수 있는 실험결과이다. DINO 논문에서 발췌했다.
teacher network의 파라미터는 student의 평균이 되는데 이는 앙상블한 효과를 갖는다.
논문에서 실험 결과 teacher의 성능이 student보다 높다는 것을 보여준다.
Figure 상 오른쪽 Table에 모델의 Top-1 Accuracy를 측정한 자료가 나와있다. 단순 모델 복제(Student Copy), 직전의 이터레이션 모델 복제(Previous iter), 직전의 에폭 모델 복제(Previous epoch), 모멘텀 업데이트(Momentum)의 성능이 비교대상군이다.
Self-supervised Learning에서 가장 두려운 상황이 Model Collapse 상황이다. Model Collapse 상황이란 입력값과 상관없이 출력값이 하나의 차원이 dominate 하거나, 모든 차원에 대하여 uniform 한 상황을 말한다.
SG(Stop gradient)를 걸어놓고 가중치를 업데이트하는 상황에서 Teacher의 가중치가 매우 빠르게 업데이트 되면 Teacher와 Student의 앙상블 효과를 기대할 수 없게 되고 두 모델의 차이점이 없어지게 되면 자연스레 Model Collapse 문제가 일어나게 된다.
3.1.3 Cross-Entropy, Multi-Crop Strategy, Centering, Sharpening
Cross Entropy
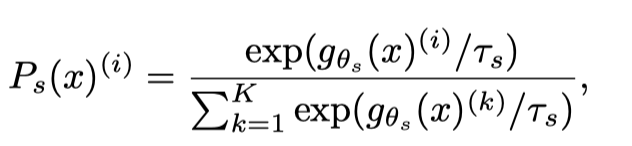
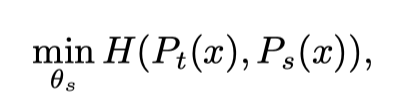
- : Teacher Network Probability
- : Student Network Probability
- : Teacher Network
- : Student Network
- : Temperature
- : Dimension of output
DINO는 SSL(self-supervised learning)에 사용되는 샴 네트워크를 지식 증류(Knowledge Distillation)의 한 형태로 구성한다. 여기에서 Student network는 더 나은 성능의 Teacher network의 출력을 모방하도록 훈련된다. 이를 달성하기 위해 DINO는 Teacher network와 Student network의 출력 사이에 Cross-Entropy를 사용하여 Student network를 교육하는 동시에 Teacher network에 Stop gradient를 적용하여 훈련 중에 업데이트되지 않도록 한다.
Multi-Crop Stratedy
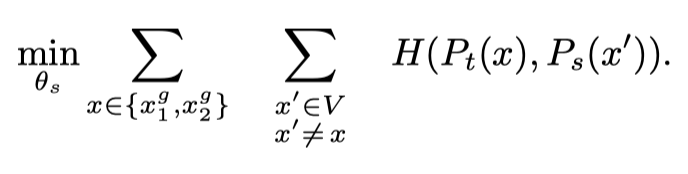
- : Global view of (only )
- : Local view of (user setting; default : )
- : Local view set of
DINO는 특이하게도 Teacher과 Student에 적용하는 Transformation의 종류가 다르다.
Teacher에는 사이즈의 Global View를 적용하고 Student에는 사이즈의 Local View를 적용한다.
따라서 Teacher network의 Input과 Student network의 Input은 같은 이미지지만 Resolution이 다른 Augmentated Image가 들어간다.
이는 “local-to-global” 개념과 일맥상통하게 한다.
class DataAugmentationDINO(object):
def __init__(self, global_crops_scale, local_crops_scale, local_crops_number):
flip_and_color_jitter = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply(
[transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.2, hue=0.1)],
p=0.8
),
transforms.RandomGrayscale(p=0.2),
])
normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
# first global crop
self.global_transfo1 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(1.0),
normalize,
])
# second global crop
self.global_transfo2 = transforms.Compose([
transforms.RandomResizedCrop(224, scale=global_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(0.1),
utils.Solarization(0.2),
normalize,
])
# transformation for the local small crops
self.local_crops_number = local_crops_number
self.local_transfo = transforms.Compose([
transforms.RandomResizedCrop(96, scale=local_crops_scale, interpolation=Image.BICUBIC),
flip_and_color_jitter,
utils.GaussianBlur(p=0.5),
normalize,
])Centering and Sharpening
Model Collapse를 피하기 위해 고안된 방법이다.
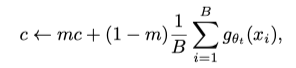
이전 Work들의 Avoiding Collapse의 해결책으로 Contrastive loss, Clustering constraints, Predictor, Batch Normalization 등이 있는데, DINO에서는 Teacher output의 Centering과 Sharpening을 해주는 것만으로 모델을 안정화(Stablization)할 수 있다고 설명한다.
Centering은 Output이 한개의 차원에 지배적인(dominated) 상황을 억제하지만 Output이 Uniform distribution이 되도록 하는 특성을 가지고 있고 Sharpening은 그 반대의 특성을 가지고 있다.
결론은 둘 다 사용해야 Model Collapse를 방지하는것에 효과적이라는 말
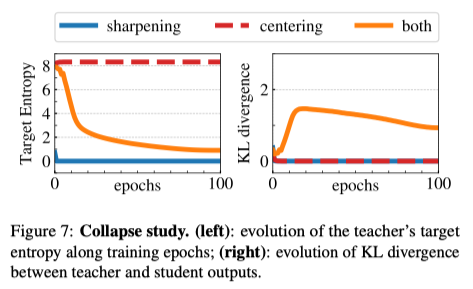
- Target Entropy : Teacher output의 target entropy이다.
both의 경우에 target entropy가 예쁘게 수렴함을 알 수 있다. - KL divergence : 쿨백-라이블러 발산; Teacher와 Student outputs 간의 KL-divergence를 의미한다. 두 outputs간의 분포 차이를 설명한다. 분포 차이란 정보 엔트로피의 차이이다.
both의 경우에 적절한 분포 차이가 생김을 알 수 있다.
4.마치며
대기업 논문이라 그런지 Git 코드 관리도 굉장히 잘 되어 있고 방법론을 여기저기에 쓸 만 할 것으로 생각된다.
굉장히 디테일한 Ablation Study가 있는데 그만큼 실험적 증명이 탄탄하고 우연의 일치로 좋은 결과가 나왔다는 반박을 할 수 없게 만든다.
끝으로 시각자료들을 첨부하고 논문리뷰를 마친다.🔜
4.1 대략의 전체 학습 과정

4.2 Supervised 와의 Self-attention Map 결과물 비교
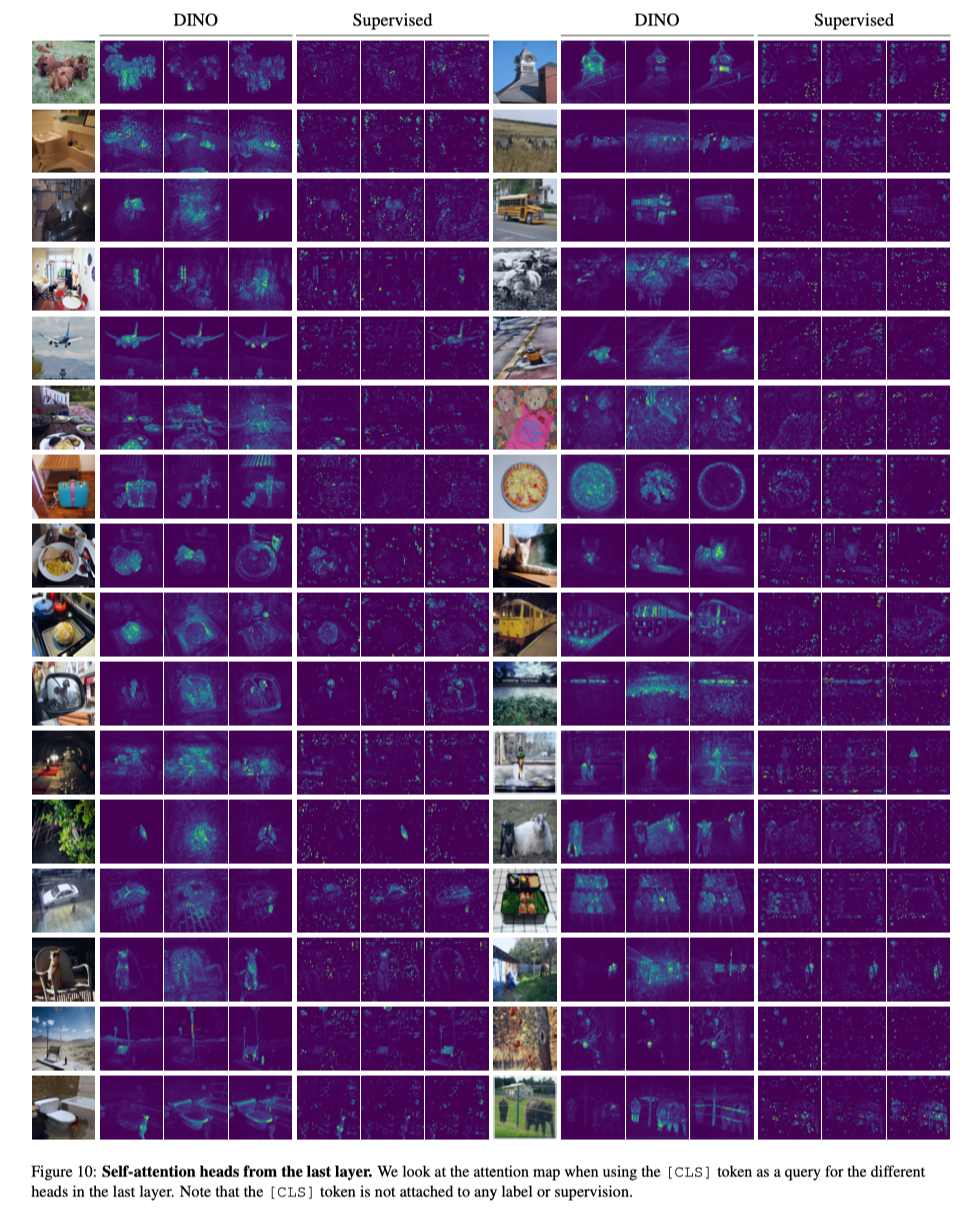
4.3 Attention Map of Video

.JPG)