문제
개요
트리의 최대 독립집합을 구하고 그 구성 노드들을 출력해야 하는 문제이다.
이 때 최대 독립집합은 독립집합의 구성 원소들이 그래프에서 인접하지 않아야 하며 원소들의 가중치의 합이 최대가 되어야 한다.
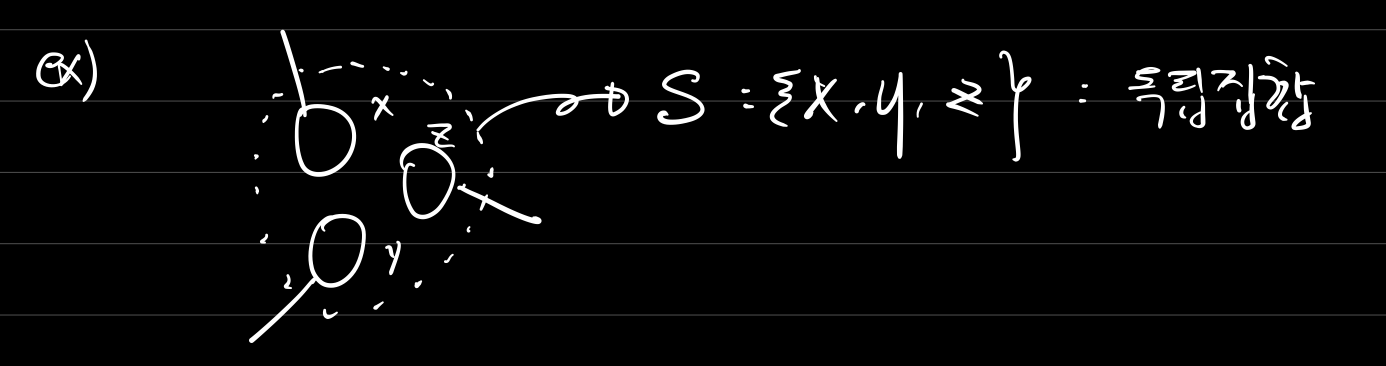
트리의 독립집합
문제풀이
접근 및 시간복잡도 계산
이 문제는 어떤식으로 접근해야할까?
먼저 모든 노드는 최대 독립집합에 포함될(1) 수도 있고 포함되지 않을(2) 수도 있다.
즉 모든 노드는 총 2가지 경우의 수를 갖는다.
가장 Naive한 풀이는 의 풀이를 생각할 수 있다. 이 커서 당연히 시간초과가 난다.)
이 상황에서 우리는 시간복잡도를 낮추는 방향을 고려해야한다.
이렇게 생각해보자 이기 때문에 보편적으로 , 의 시간복잡도를 생각할 수 있다.
은 정렬, 이분탐색, 정렬, 누적합, 자료의 세그먼트 트리화 등이 있다. 하지만 이 문제는 모든 경우의 수를 고려하는 문제라는 느낌이 강하고 따라서 풀이는 잠시 보류할 수 있다.
그럼 바로 풀이를 생각해보자.
루트 노드에서 리프 노드까지 위에서 아래방향으로 연산을 진행하면서 문제를 해결할 수 있어야 한다.
알고리즘 선택
이 문제의 Naive한 풀이를 다시 리마인드 해보자.
모든 경우의 수를 고려하고 그 중에서 최댓값을 골라야 하는 문제이기 때문에 이전에 사용한 기록을 사용하는 알고리즘을 생각할 수 있다.
선택할 수 있는 알고리즘은 Memoization/DP 이다. 그리고 이 문제의 풀이는 트리 상황에서의 DP로 생각해볼 수 있다.
문제 단순화
그럼 DP의 Properties에 대해 생각해보자
- 어떤 정점은 자신의 자식 또는 부모와 집합을 이룰 수 없다.
- 모든 정점에서 집합 S를 이루기 위한 경우의 수는 다음과 같다.
- 자기 자신을 포함
- 자기 자신을 미포함
따라서 DP의 Properties는 다음과 같이 정의할 수 있다.
- == i를 루트노드로 하는 서브트리에서 i를 포함하지 않을 때 트리의 독립집합의 최대값
== i를 루트노드로 하는 서브트리에서 i를 포함할 때 트리의 독립집합의 최대값 - 만약 자기 자신을 포함하는 상황에서는 자식노드를 반드시 포함하지 않아야 한다.
- 만약 자기 자신을 포함하지 않는 경우에는 두 가지 경우중 최댓값을 고른다.
- 다음 노드를 포함하는 경우
- 다음 노드를 포함하지 않는 경우
트리 상황에서의 DP는 보통 트리DP라고 부른다.
트리DP에서는 리프노드의 상황을 잘 파악하는것이 중요하다.
이 문제에서 리프노드의 상황은 다음과 같다.
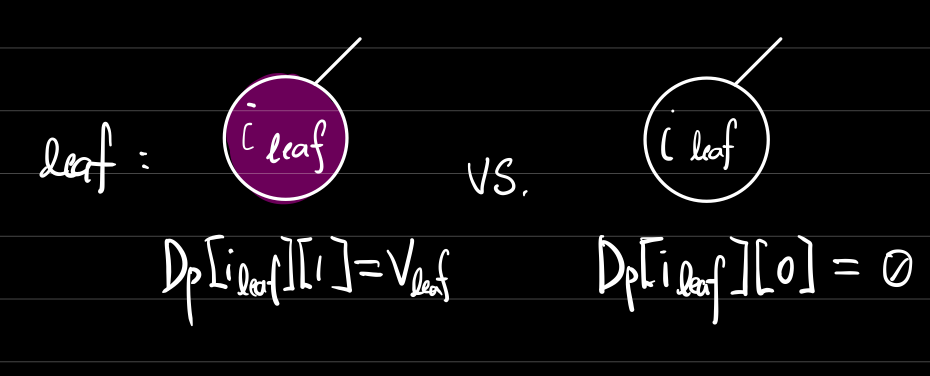
리프노드의 상황 : 포함되거나[1] 포함되지 않거나[0]
리프노드의 상황은 그림 그대로다. 그리고 각각의 상황에서 는 리프노드의 가중치와 같다.
그 다음으로 리프노드가 아닌 노드의 상황을 살펴보자
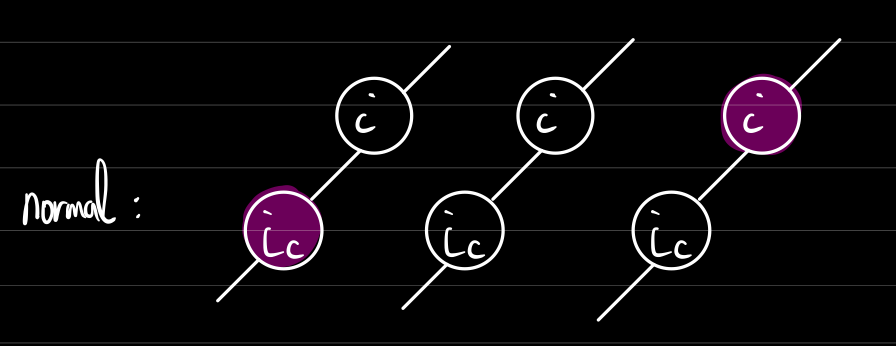
노드의 자식 노드
에서 가능한 경우의 수는 다음과 같다. 이는 이미 위에서 언급한 내용이다.
- 만약 자기 자신을 포함하는 상황에서는 자식노드를 반드시 포함하지 않아야 한다.
- 자기 자신이 포함되면 자식노드는 반드시 포함되지 않아야 한다.
- 만약 자기 자신을 포함하지 않는 경우에는 두 가지 경우중 최댓값을 고른다.
- 자식노드는 포함되는 경우
- 자식노드는 포함되지 않는 경우
이 때 Dp라는 점을 생각해서 조금 수정해보면
- 만약 자기 자신을 포함하는 상황에서는 자식노드를 반드시 포함하지 않아야 한다.
- 자식노드가 루트노드인 서브트리에서 자식노드가 포함되지 않는 상황의 최대 독립집합 value
- 만약 자기 자신을 포함하지 않는 경우에는 두 가지 경우중 최댓값을 고른다.
- 자식노드가 루트노드인 서브트리에서 자식노드가 포함되는 상황의 최대 독립집합 value
정리하자면
- 각 노드의 경우의 수를 해당 노드의 자식노드와 엮어서 생각한다.
- 자식노드에서의 최대값은 부모노드에서의 최대값에 영향을 미친다. (DP의 개념)
- 자식노드 상황에서의 최대값을 부모노드에서 활용한다.
DP 경로 역추적
그럼 가중치는 구현할 수 있게 되고 경로는 어떻게 찾을까?
이미 만들어진 DP Table을 활용하면 된다.
경로는 1번 노드(트리의 루트노드)에서 출발하여 를 구한다.
만약 이면 해당 노드를 포함하지 않는 경우가 최대값인 경우이다.
이면 해당 노드를 포함하는 경우가 최대값인 경우이다.
경로를 구할 때도 다음 상황과 이미 만들어진 DP Table 을 활용해서 역추적으로 구해낼 수 있다.
- 만약 자기 자신을 포함하는 상황에서는 자식노드를 반드시 포함하지 않아야 한다.
- 자식노드가 루트노드인 서브트리에서 자식노드가 포함되지 않는 상황의 최대 독립집합 value
- 만약 자기 자신을 포함하지 않는 경우에는 두 가지 경우중 최댓값을 고른다.
- 자식노드가 루트노드인 서브트리에서 자식노드가 포함되는 상황의 최대 독립집합 value
구현
import sys
sys.setrecursionlimit(10 ** 6)
In = lambda: sys.stdin.readline().rstrip()
def init():
nodes = int(In())
vals = list(map(int, In().split())) # 가중치
vals.insert(0, 0) # dummy value
tree = []
check = [0] * (nodes + 1)
dp = [[-1, -1] for i in range(nodes + 1)]
for i in range(nodes - 1):
nodeX, nodeY = list(map(int, In().split()))
tree[nodeX].append(nodeY)
tree[nodeY].append(nodeX)
return tree, dp, vals
def dynamicProgramming(cur, prev):
dp[cur][1] = vals[cur]
dp[cur][0] = 0
for nextnode in tree[cur]: # 자식노드 탐색, # 리프노드의 경우 for문 X
if nextnode != prev:
dynamicProgramming(nextnode, cur)
dp[cur][1] += dp[nextnode][0]
dp[cur][0] += max(dp[nextnode][0], dp[nextnode][1])
def findRoute(cur, prev, isVisited):
if isVisited:
answr.append(cur)
for nextnode in tree[cur]:
if nextnode != prev:
findRoute(nextnode, cur, 0) # 현재 노드를 포함 -> 자식 노드 포함 X
else:
for nextnode in tree[cur]:
if nextnode != prev:
if dp[nextnode][0] > dp[nextnode][1]:
findRoute(nextnode, cur, 0) # 현재 노드 포함 X-> 자식노드 포함 X
else:
findRoute(nextnode, cur, 1) # 현재 노드 포함 X -> 자식노드 포함 O
if __name__ == "__main__":
tree, dp, vals = init()
dynamicProgramming(1, -1)
answr = []
if dp[1][0] > dp[1][1]:
findRoute(1, -1, 0)
else:
findRoute(1, -1, 1)
answr.sort()
print(dp[1][0] if dp[1][0] > dp[1][1] else dp[1][1])
print(*answr).JPG)