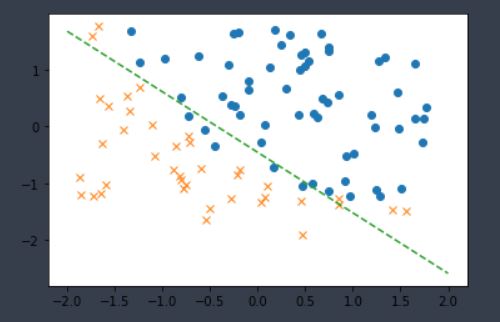
회귀(예측,Regression)에는 크게 두 가지가 있다. 하나는 앞에서 배운 선형 회귀(Linear Regression), 또 하나는 오늘 배울 로지스틱 회귀(Logistic Regression)이다. 이 둘은 이름만큼이나 뜻도 다르다. 선형 회귀는 기존의 데이터를 가지고 앞으로의 예측 값을 추정해 나가는 것이고, 분류(Classification)의 일종인 로지스틱 회귀는 분류의 일종인 만큼 0과 1 즉, 두 값을 가지고 데이터를 이진 분류 하는 것이다.
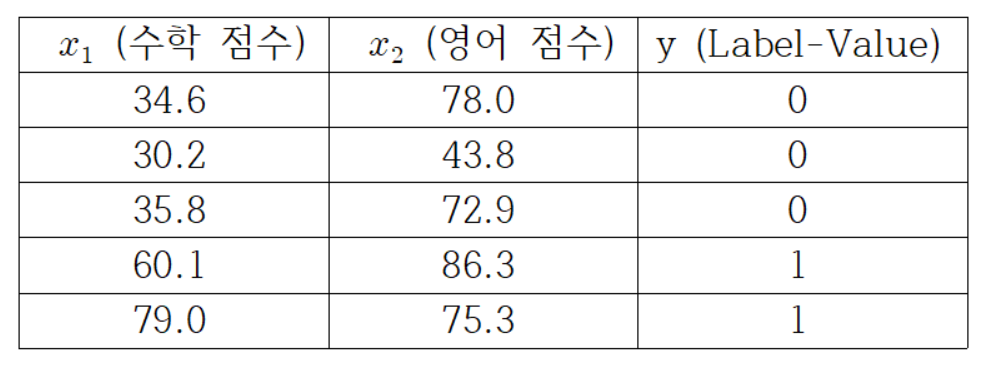
위의 데이터를 보면 입력 값 𝑥_1, 𝑥_2에 대해 y값이 0과 1 단 두 가지의 값으로 출력되는 것을 볼 수 있다. 로지스틱 회귀는 기존의 주어진 데이터에 할당되는 라벨 값(y)을 분류하는 회귀선을 가지고 앞으로 주어질 𝑥_1, 𝑥_2 값에 대한 라벨 값을 추정하는 회귀이다.
로지스틱 회귀 또한 회귀선이 선형(lined)으로 나오느냐 비선형(unlined)으로 나오느냐에 따라 선형 로지스틱 회귀, 비선형 로지스틱 회귀로 명칭과 그래프의 모양이 다르다. 선형 로지스틱 회귀는 1차 함수의 형태로 나타나고, 비선형 로지스틱 회귀는 2차 또는 3차 곡선, 삼각함수 곡선 형태를 하고 있다.
선형 로지스틱 회귀를 구할 수 있는 기법은 여기선 간단히 내리막 경사법(Gradient Descent Method)을 사용하여 구할 것이다. 물론 내리막 경사법 이외에도 오르막 경사법도 있다. 단지 둘의 차이는 가설 함수의 부호 차이인데 일단 필자는 내리막 경사법을 사용하여 주어진 데이터를 가지고 로지스틱 회귀를 구할 것이다.
Step 1. 가설 함수 설정
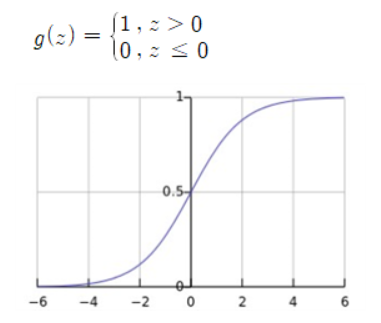
로지스틱 회귀는 선형 회귀와 달리 추정값이 ‘0’보다 작거나 ‘1’보다 클 필요가 없기 때문에 가설 함수는 시그모이드 함수를 사용한다.
주어진 데이터는 입력 값(𝑥_1, 𝑥_2) 두 개, 출력 값(y) 한 개 이므로
※ 시그모이드 함수
라고 정의할 수 있다.
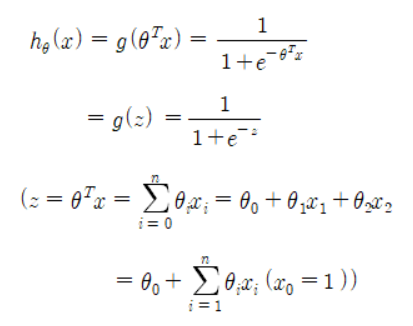
Step 2. 확률분포 가정
로지스틱 회귀의 손실함수는 확률분포를 기반으로 만들어진 함수이기 때문에 라벨 값이 0일 때와 1일 때의 확률을 각각 생각해 주어야 한다.
i) 라벨 값이 1일 때
ii) 라벨 값이 0일 때
iii) 두 확률이 서로 상대적이다.
iv) x가 “1” 클래스에 속할 경우, P(y = 1|x) 크고, P(y = 0|x) 작아짐.
x가 “0” 클래스에 속할 경우, P(y = 1|x) 작고, P(y = 0|x) 커짐.
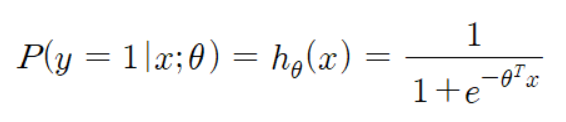
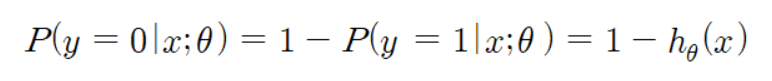
Step 3. 손실함수 정하기
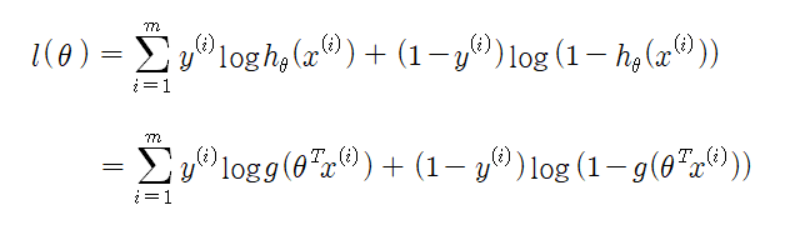
Step 4. 내리막 경사법을 이용하여 손실함수 미분
< 내리막 경사법(Gradient Descent Method) >
해를 반복 개선하는 수치적 방법의 일종으로 미분계수(평균변화율)(즉, 미분)을 이용하여 도함수의 부호에 따라 자연스럽게 경사가 가장 급격하게 떨어지는 방향을 찾아 x값을 옯기면서 함수의 최솟값을 찾는 방법이다.
내리막 경사법을 식으로 써보면
이다. 여기서, 𝛼는 학습률(learning rate)이다. 이것은 손실 함수 𝐽(𝜃)가 최솟값에 도달하게 하는데 가장 가파른 감소 방향으로 반복적으로 걸리는 매우 자연스러운 알고리즘이다.
< 오르막 경사법(Gradient Ascent Method) >
해를 반복 개선하는 수치적 방법의 일종으로 미분계수(평균변화율)(즉, 미분)을 이용하여 도함수의 부호에 따라 자연스럽게 경사가 가장 급격하게 올라가는 방향을 찾아 x값을 옯기면서 함수의 최댓값을 찾는 방법이다.
오르막 경사법을 식으로 써보면
이다. 여기서, 𝛼는 학습률(learning rate)이다. 이것은 손실 함수 𝐽(𝜃)가 최댓값에 도달하게 하는데 가장 가파른 감소 방향으로 반복적으로 걸리는 매우 자연스러운 알고리즘이다.
이제 미분을 해 줄 거다.
여기서 잠깐!!
함수 𝑔(𝜃^𝑇 𝑥)는 시그모이드 함수 이기 때문에 따로 미분을 해서 구해 준 다음 𝑔(𝜃^𝑇 𝑥)를 미분하는 곳에 그대로 대입해 준다.
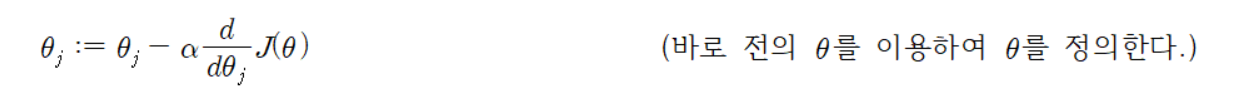
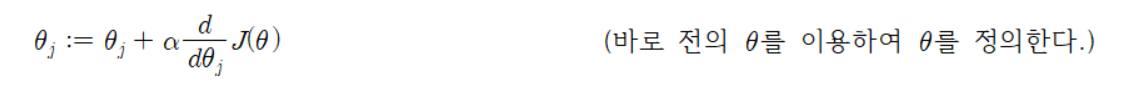
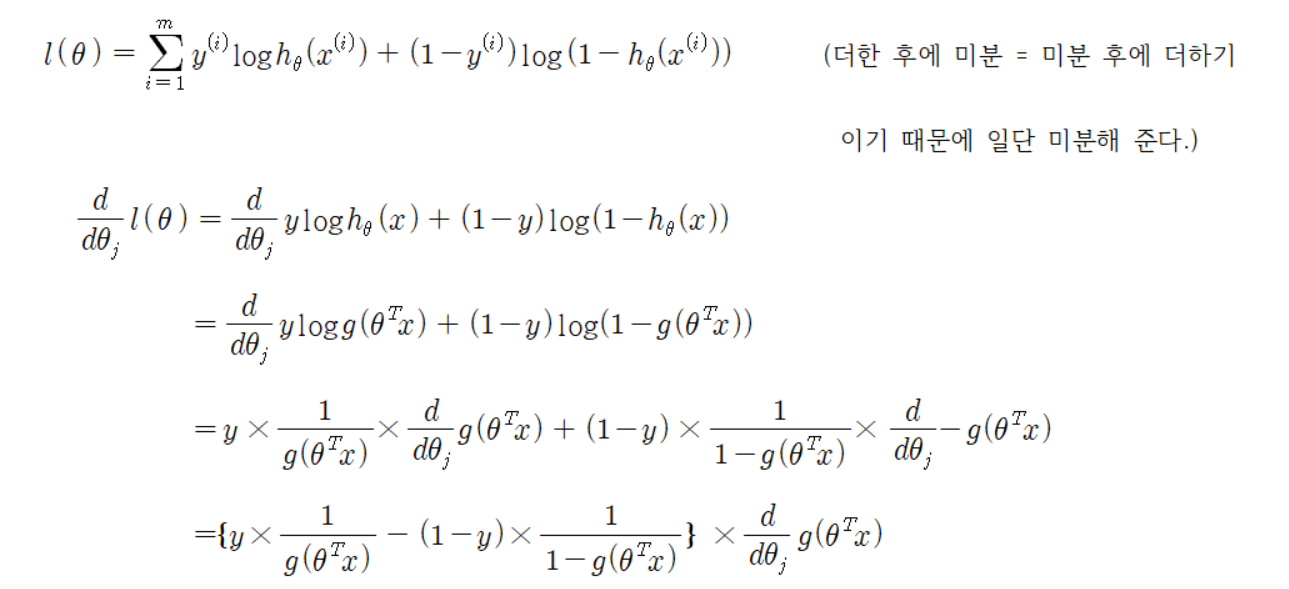
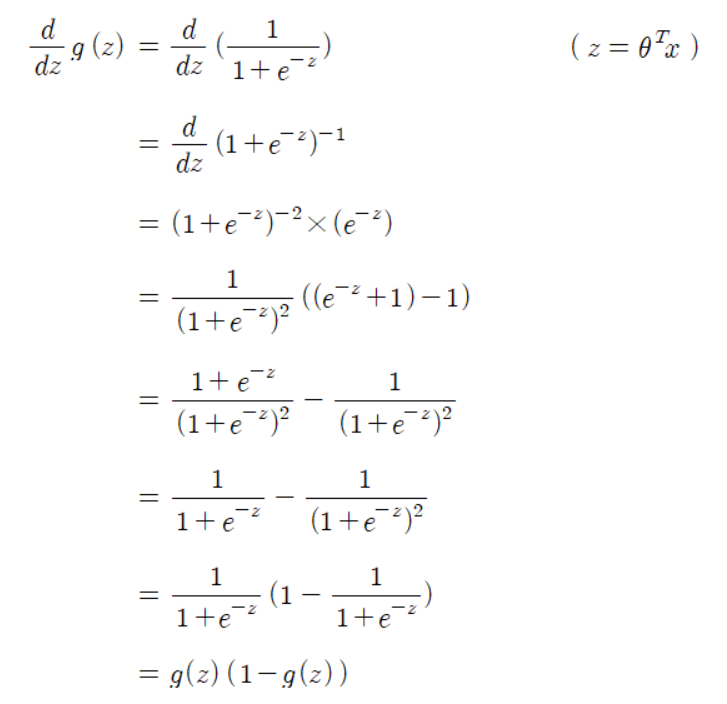
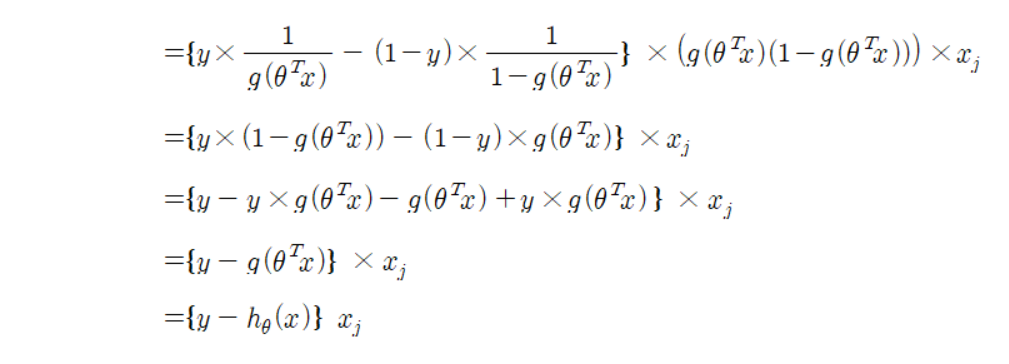
Step 5. 코딩
Step 1.부터 Step 4.까지를 이용하여 코딩을 해준다.
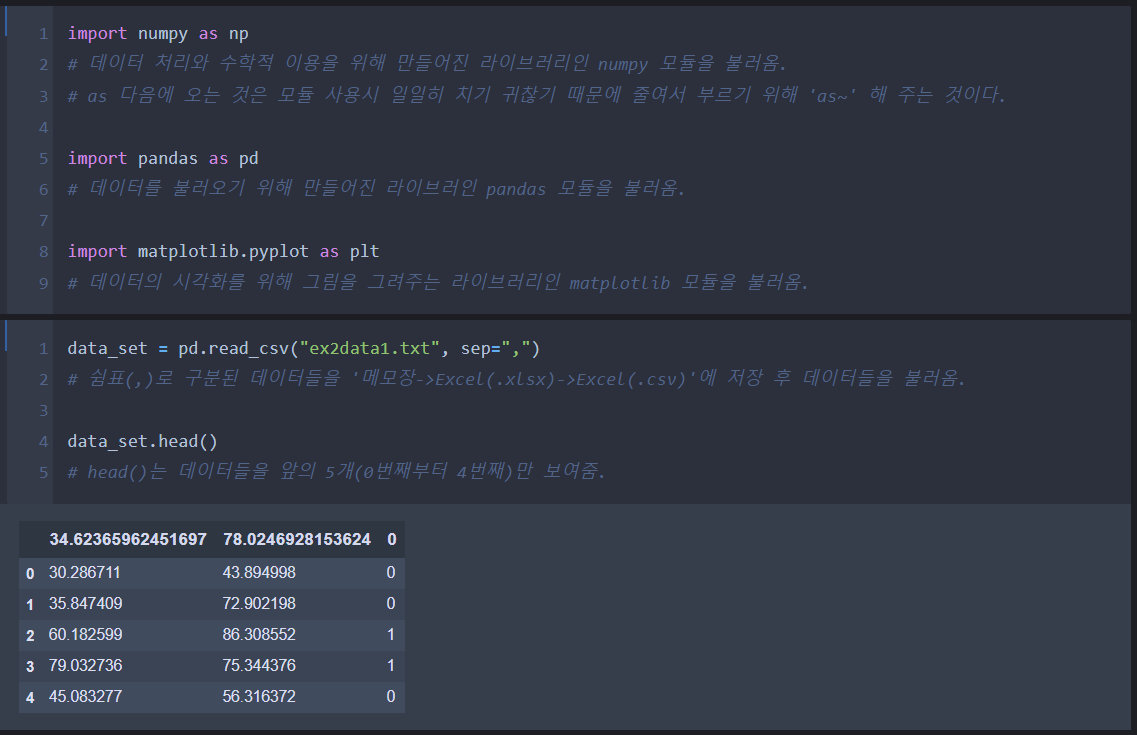
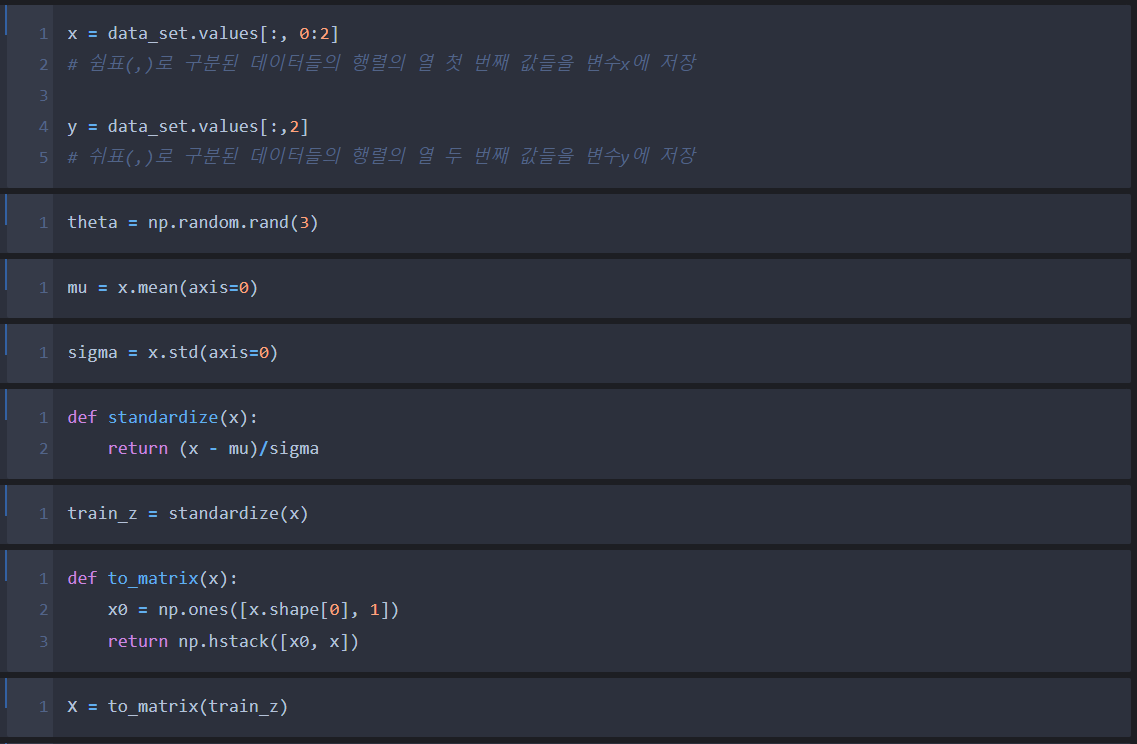
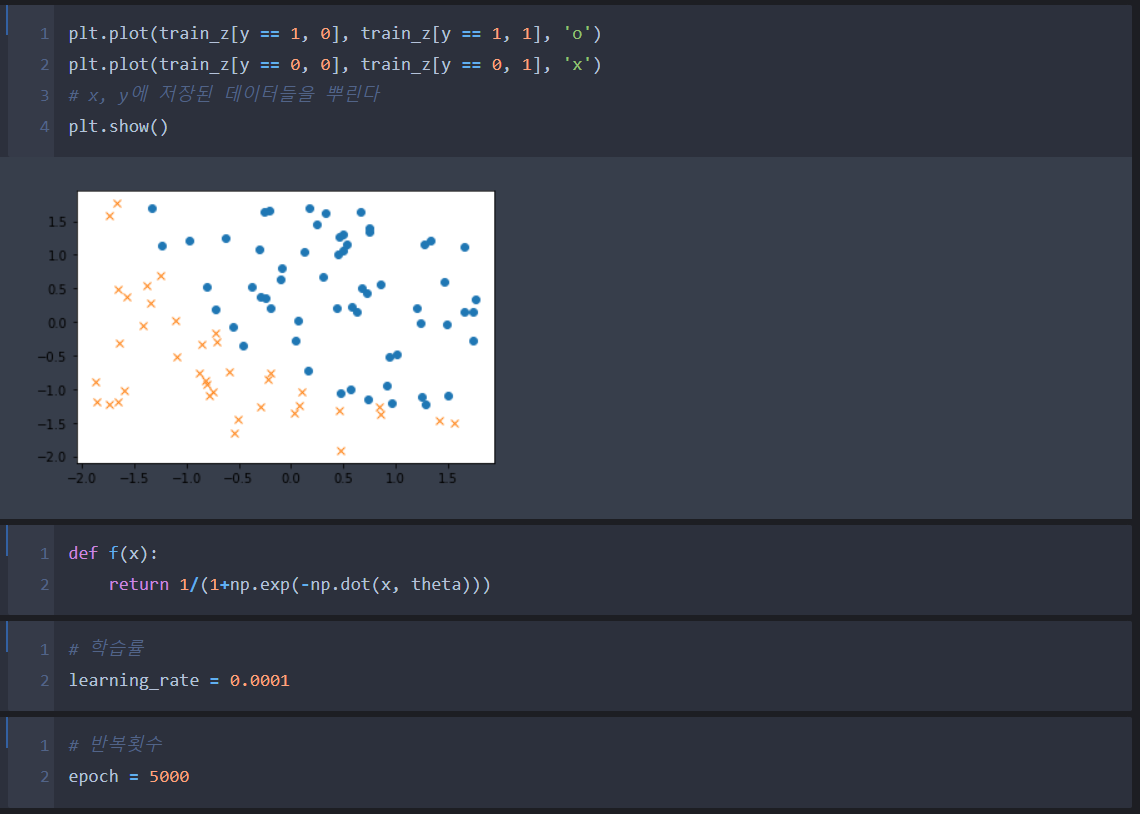
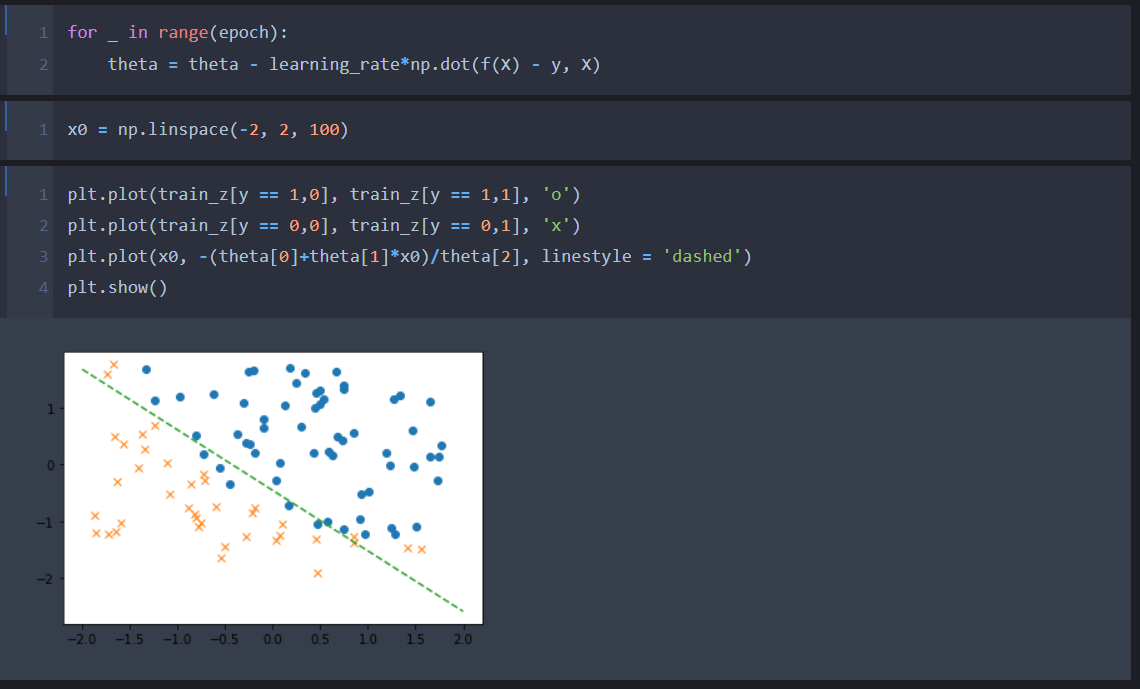
Step 6. 코드 결과 및 분석
내리막 경사법(Gradient Descent Method)을 이용하여 주어진 데이터를 가지고 로지스틱 회귀를 만들어 보았다. 로지스틱 회귀는 기존의 주어진 데이터에 할당되는 라벨 값(y)을 분류하는 회귀선을 가지고 앞으로 주어질 값에 대한 라벨 값을 추정하는 회귀이기 때문에 정확한 값을 기대 해서는 안 된다. 다만 로지스틱 회귀를 직접 이해하면서 느낀 거 중 로지스틱 회귀를 이용한다면 최상의 분류는 할 수 있을 것으로 보인다.
Reference (Source Code)

Soli Deo Gloria. / Sapere Aude.