**The above picture is from Choosing clothes.
Effective Approaches to Attention-based Neural Machine Translation (a.k.a. Dot-Product Attention)
Effective Approaches to Attention-based Neural Machine Translation (a.k.a. Bahdanau Attention)
These papers result in the same performance, but they are different.
Contents
- Attention Overview
- Attention Architecture
Attention Overview
- seq2seq에서 "필요한 정보에만 주목(Attention)"하여 그 정보로부터 시계열(단어열) 변환을 수행하는 것

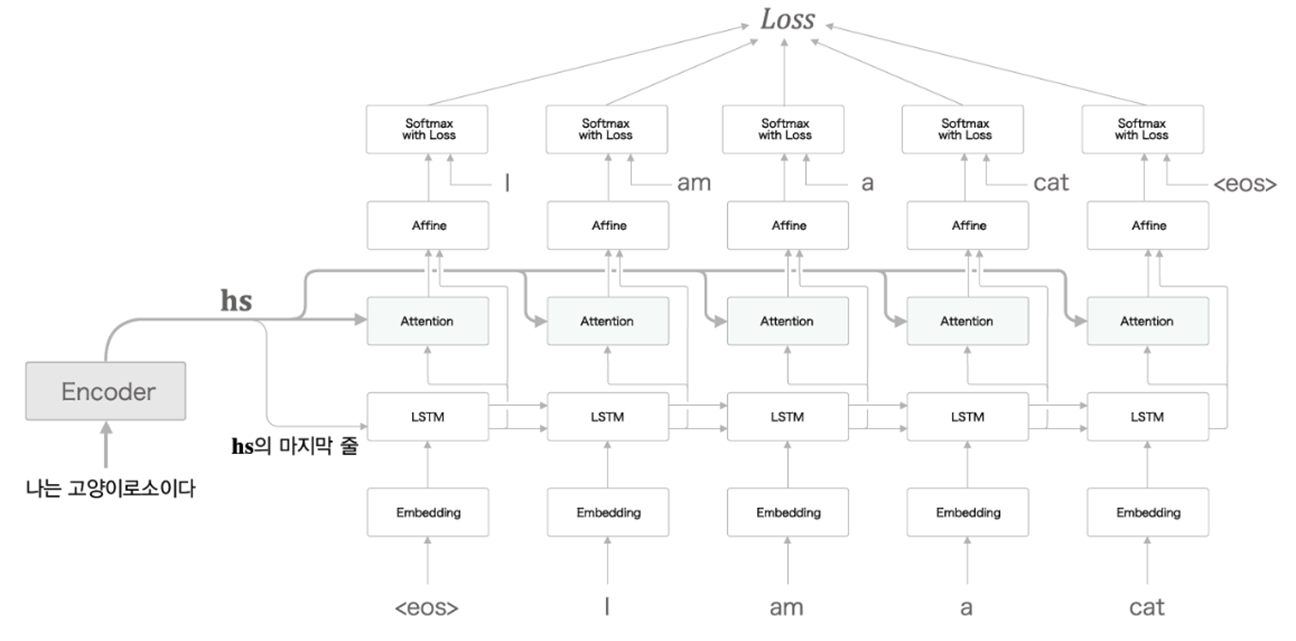
Attention Architecture
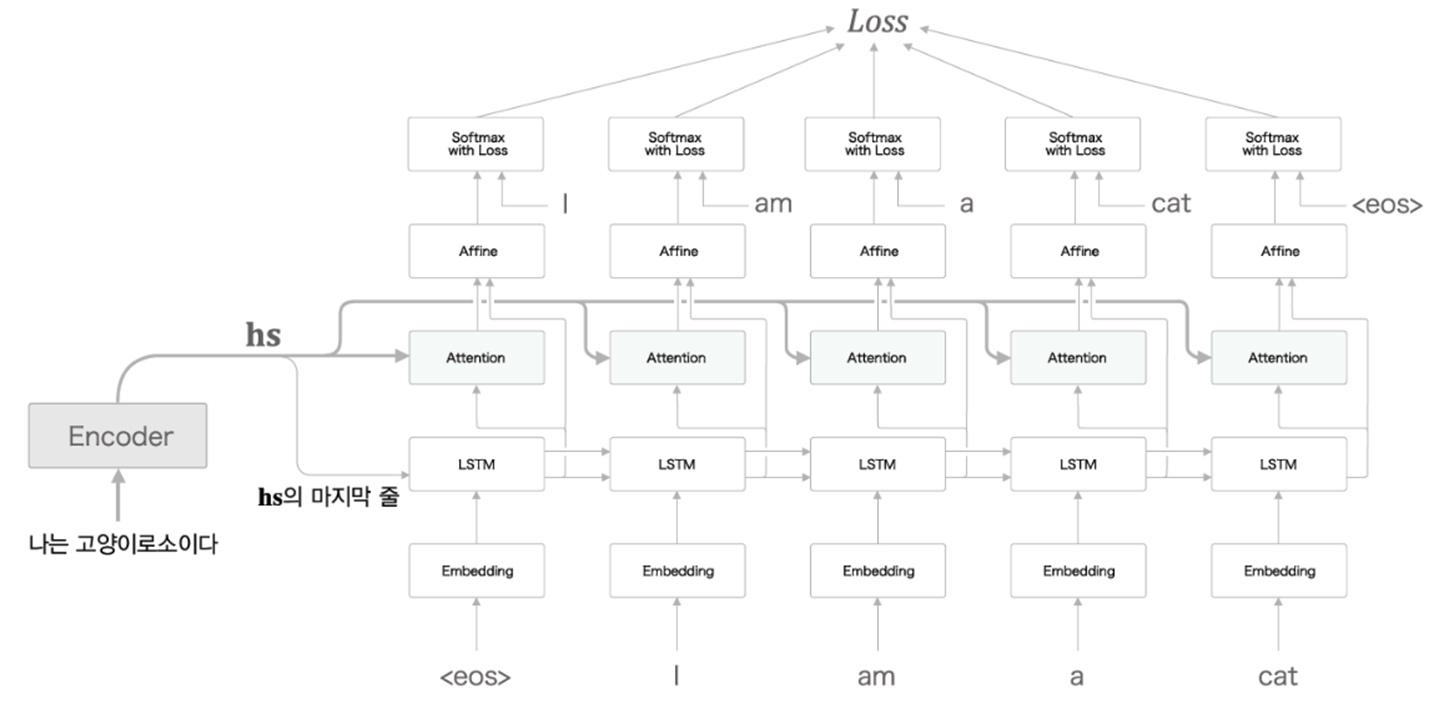
1. Overall structure
2. Encoder
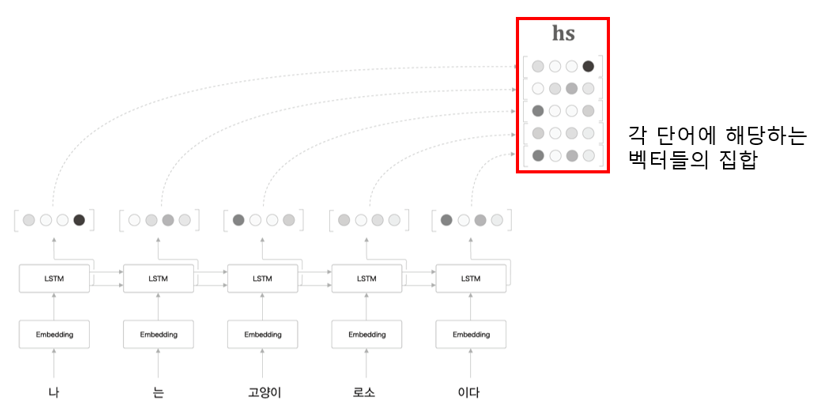
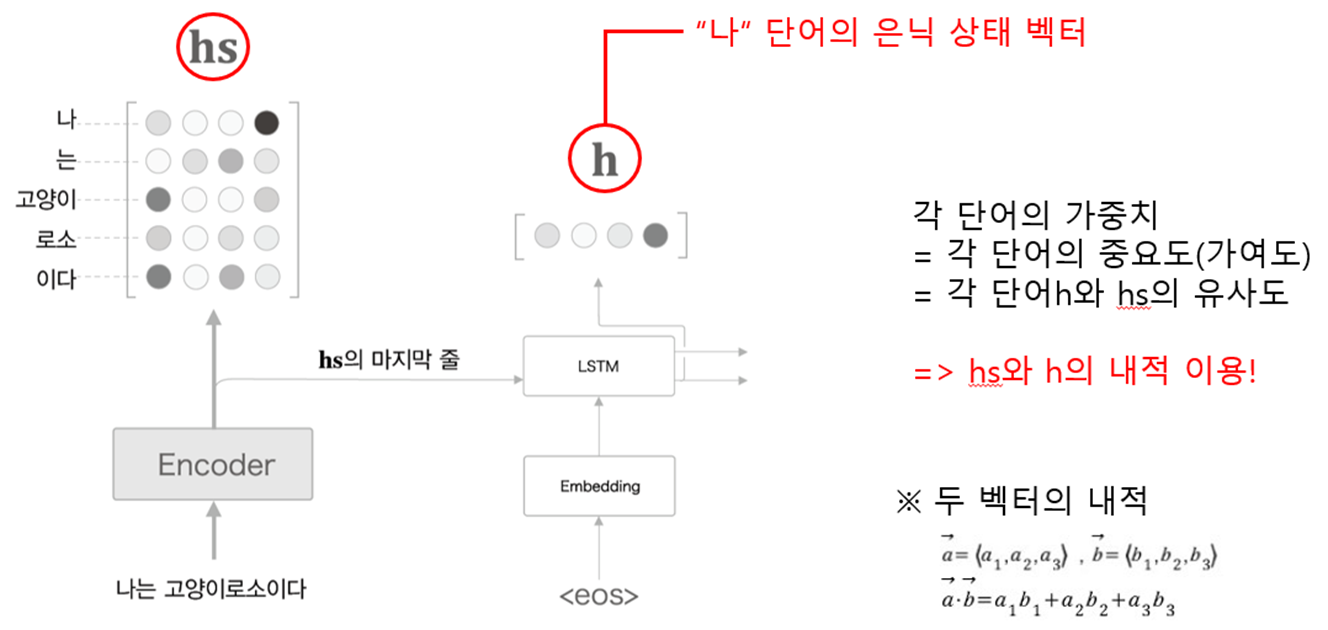
각 단어에 대응하는 LSTM 계층의 은닉 상태 벡터를 hs(벡터)로 모아 출력
Encoder의 출력 hs는 단어 수만큼의 벡터를 포함하며, 각각의 벡터는 해당 단어에 대한 정보를 많이 포함
3. Decoder
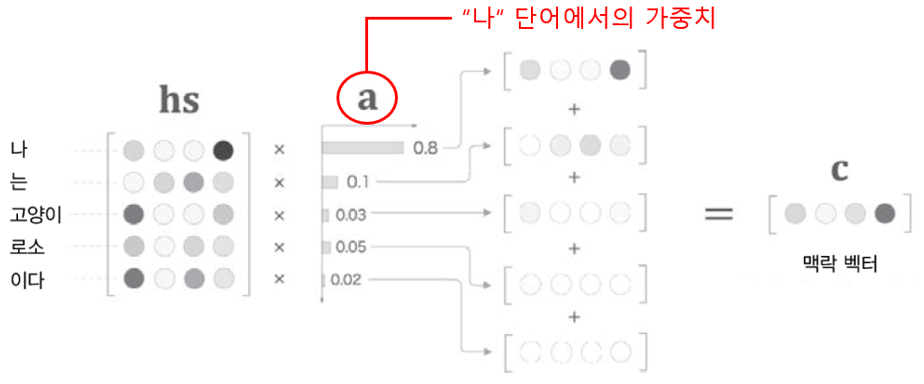
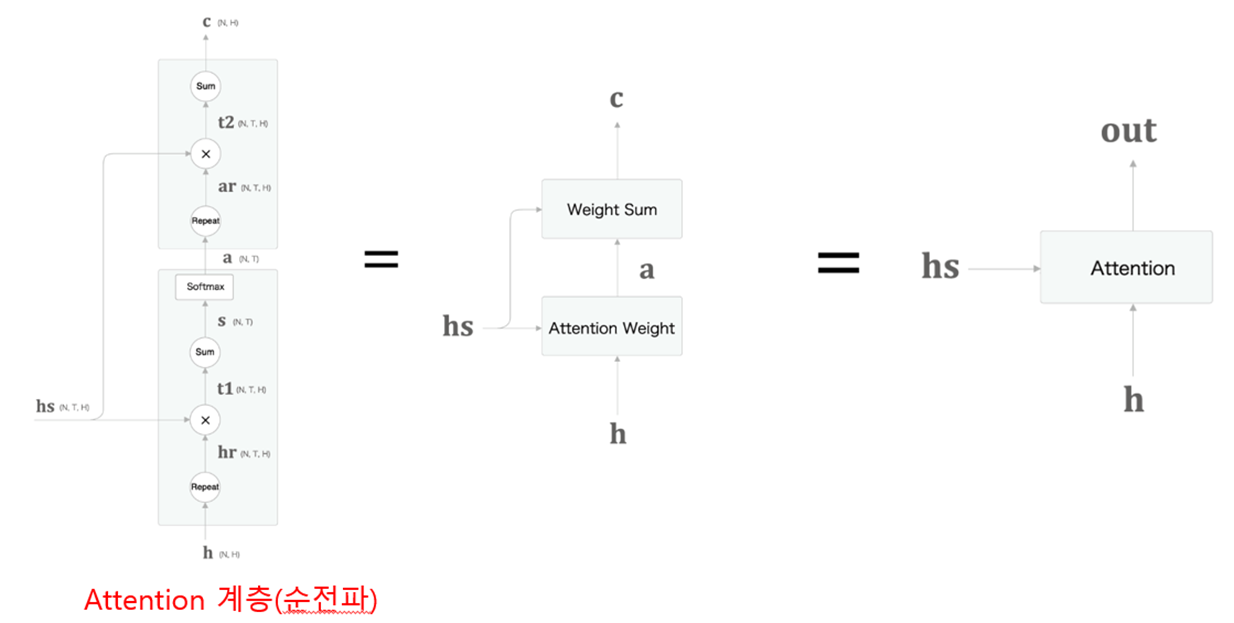
각 단어의 중요도(가중치)(-> 뒤에서 계산)를 알 수 있다는 가정 하에, 각 단어의 벡터(행렬 hs) * 각 단어의 가중치(복제본 ar) = 가중합(c) (:맥락벡터) 계산 (for. 문장을 벡터화)
Weight Sum 계층 계산 그래프
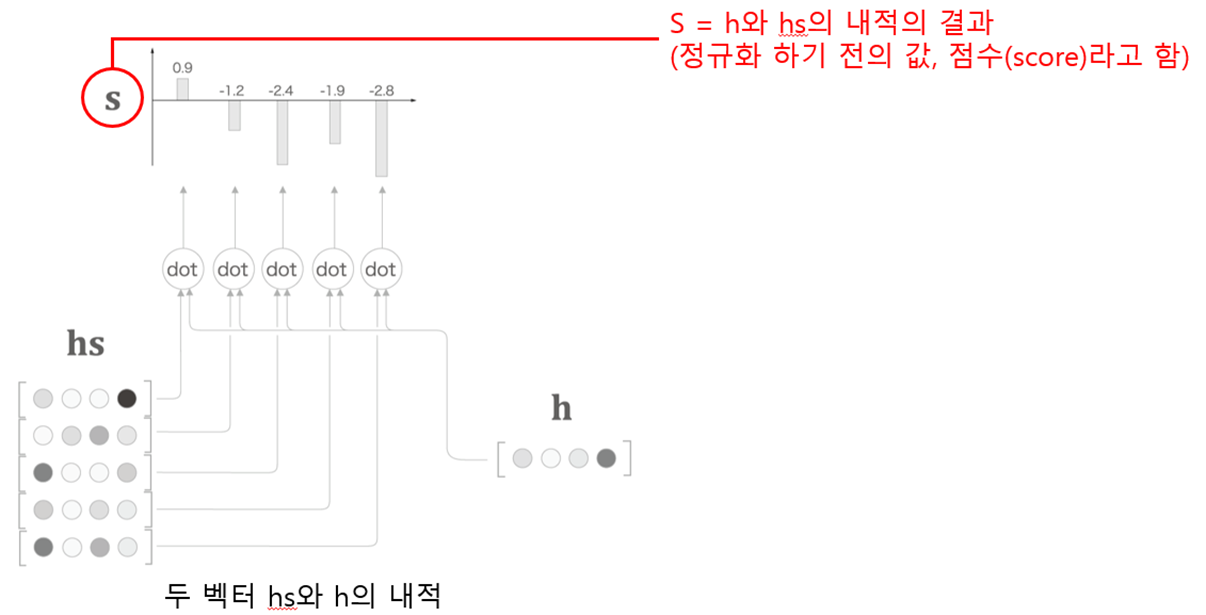
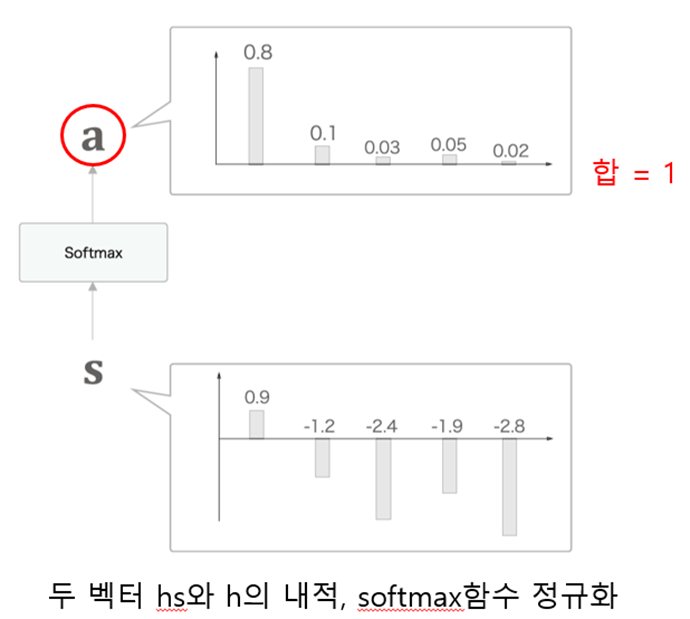
softmax{각 단어의 벡터(행렬 hs) * 은닉 상태 벡터(복제본 hr) } = 가중치(a) 계산
Attention Weight 계층 계산 그래프
가중치 계층 + 가중합 계층 = Attention 계층




Reference
- 밑바닥부터 시작하는 딥러닝2 (사이토 고키 저서, 한빛미디어)

Generative AI
정보 감사합니다.