
**The above picture is from article about movie 'Transformer'.
Attention Is All You Need (a.k.a. Transformer)
This paper was published by Google Brain / Research. Paper's model (Transformer) is based solely on attention mechanisms.
Abstract
Introduction
Prior Research (1) :
In seqeunce modeling and transduction problems such as language modeling and machine translation
Recurrent neural networks (RNN)
Long short-term memory (LSTM)
Gated Recurrent unit (GRU)
⇒ Fault: Precludes parallelization within training examples.
Prior Research (2) :
Attention mechanisms
- Allow modeling of dependencies without regard to their distance in the input or outout sequences.
- Such attention mechanisms are used in conjunction with a recurrent network.
Transformer :
Eschewing recurrence.
Relying entirely on an attention mechanism to draw global dependencies between input and output.
Effect :
⇒ Allows for significantly more parallelization.
⇒ Reach a new state of the art in translation (trained for as little as twelve hours on eight P100 GPUs.
Background
1. Multi-Head Attention
Reduce sequential computation.
Extended Neural GPU, ByteNet, ConvS2S is more difficult to learn dependencies between distant positions. Because they use convolutional neural networks.
2. Self-attention
Called 'intra-attention'
An attention mechanism relating defferent positions of a single sequence in order to compute a representation of the sequence.
Used reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations.
3. End-to-end memory networks
Recurrent attention mechanism.
Perform well on simple-language question answering and language modeling tasks.
So, Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output (without using sequence-aligned RNNs or convolution).
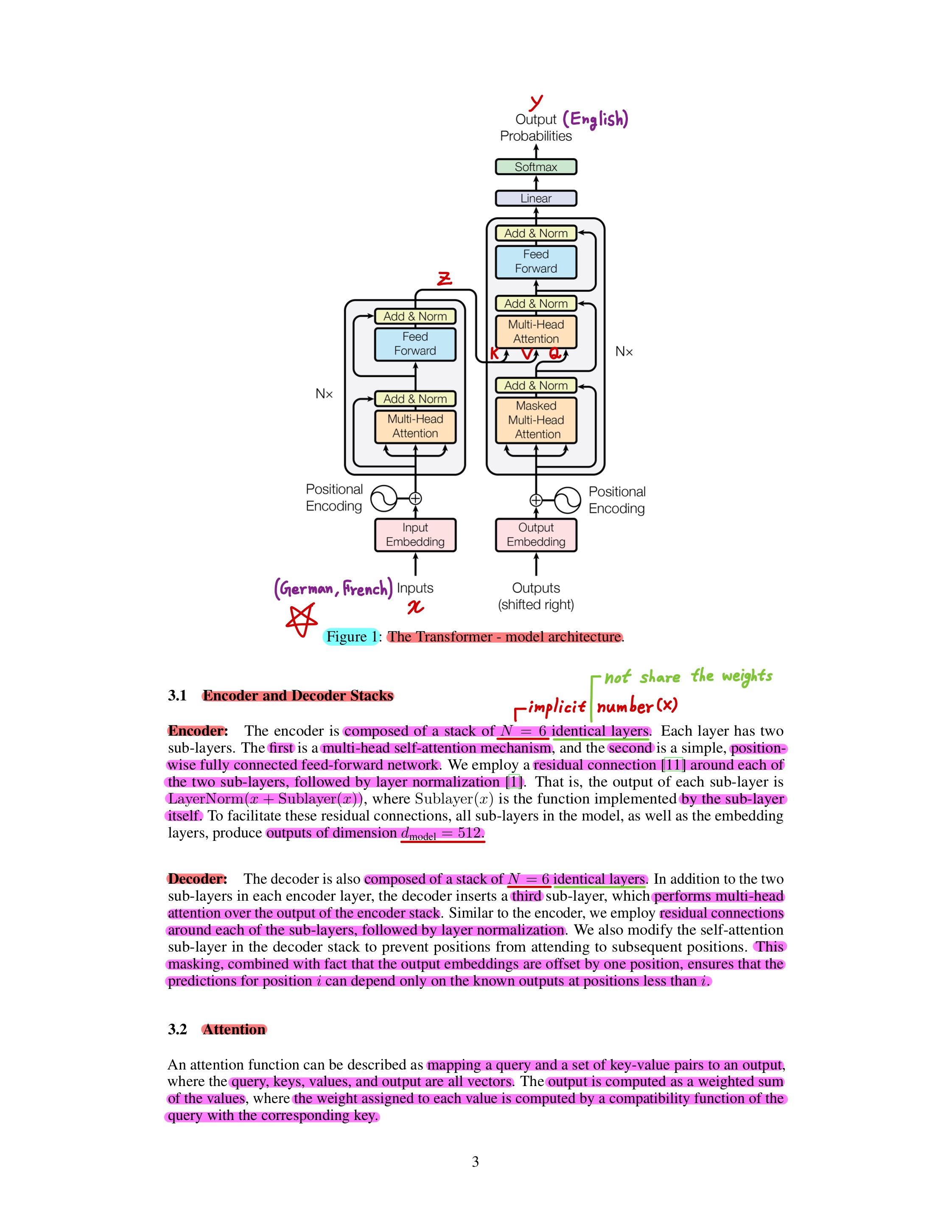
Model Architecture
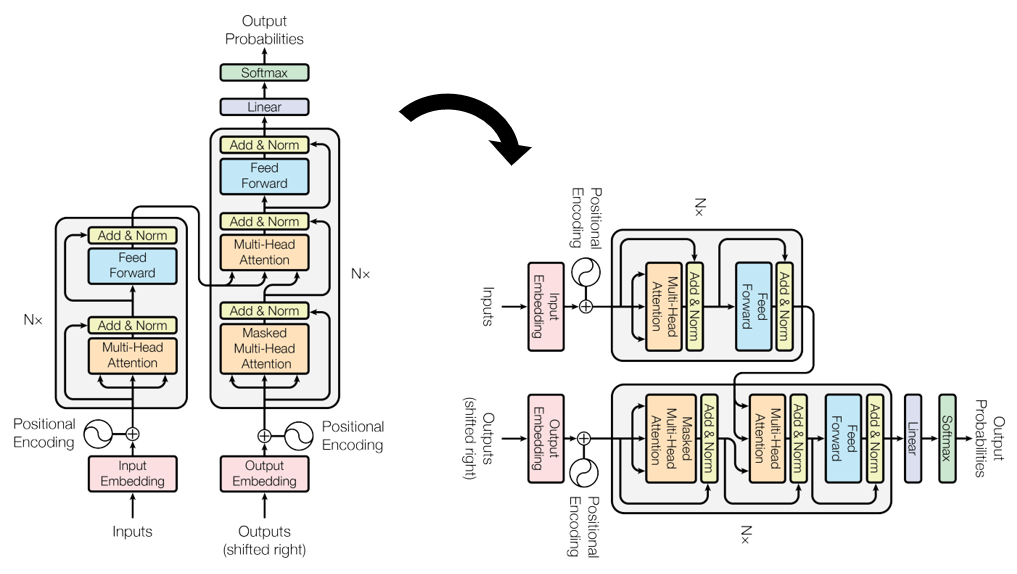
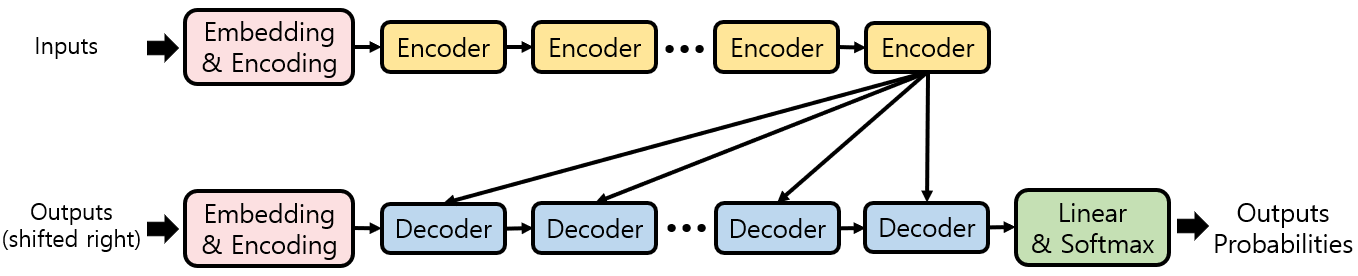
1. Overall architecture (1) - Briefly
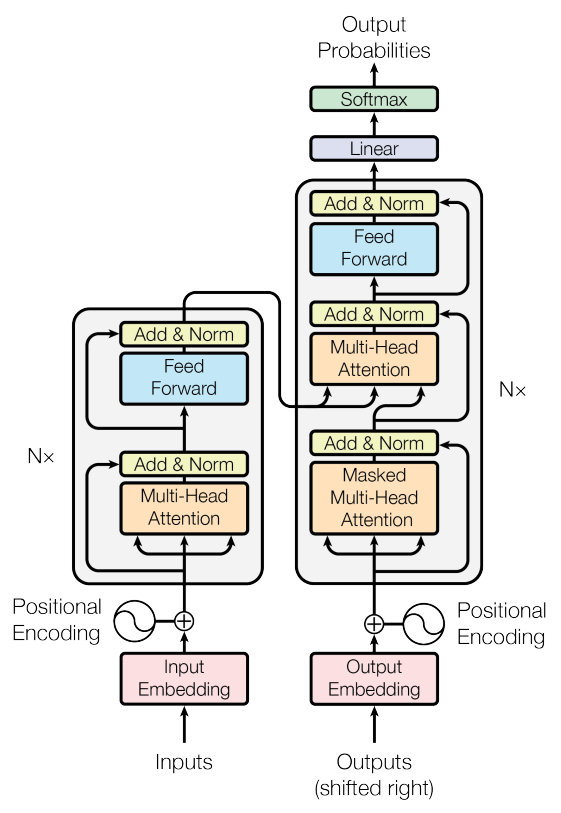
2. Overall architecture (2) - Details
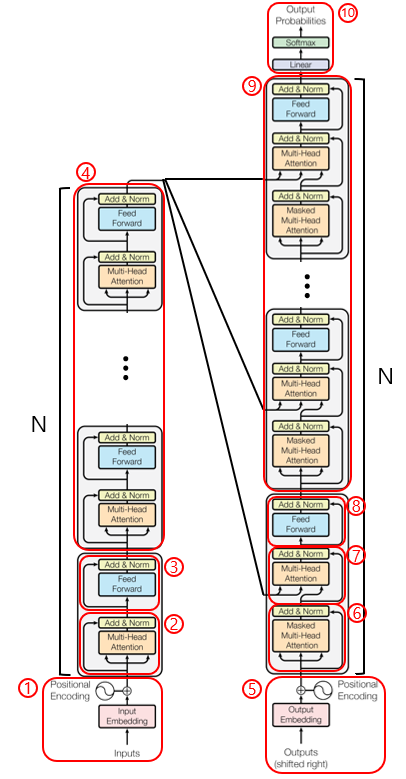
3. Step by step architecture
Attention is all you need.
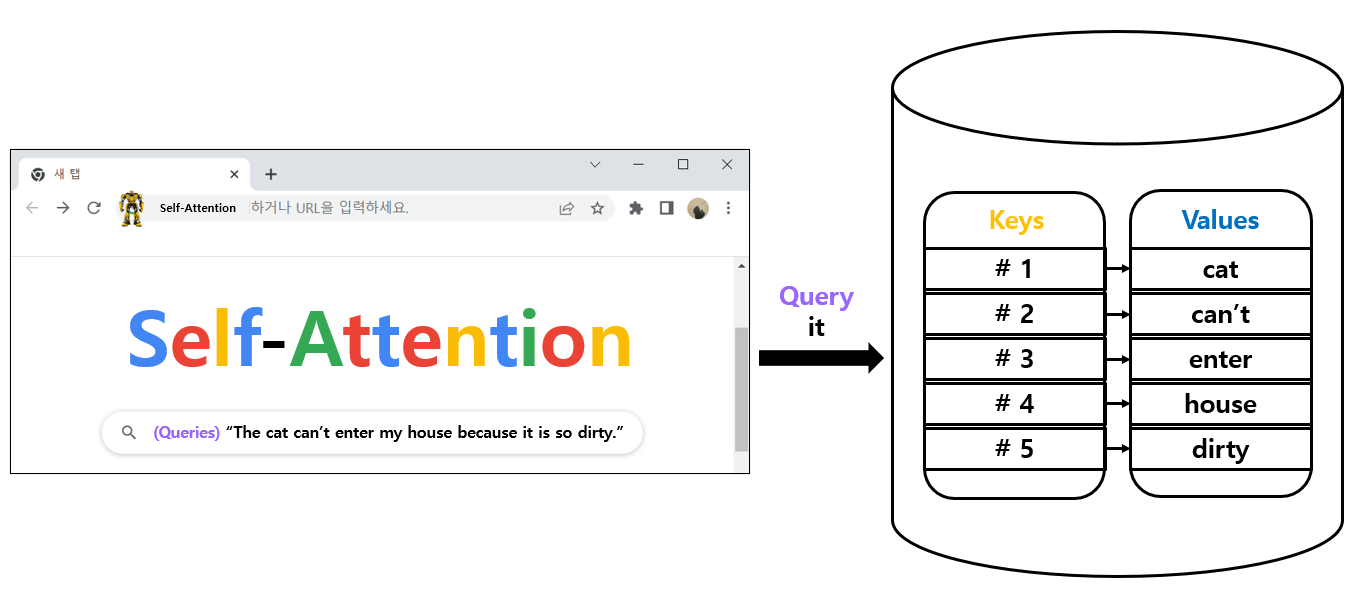
1) Why need the Self-Attention
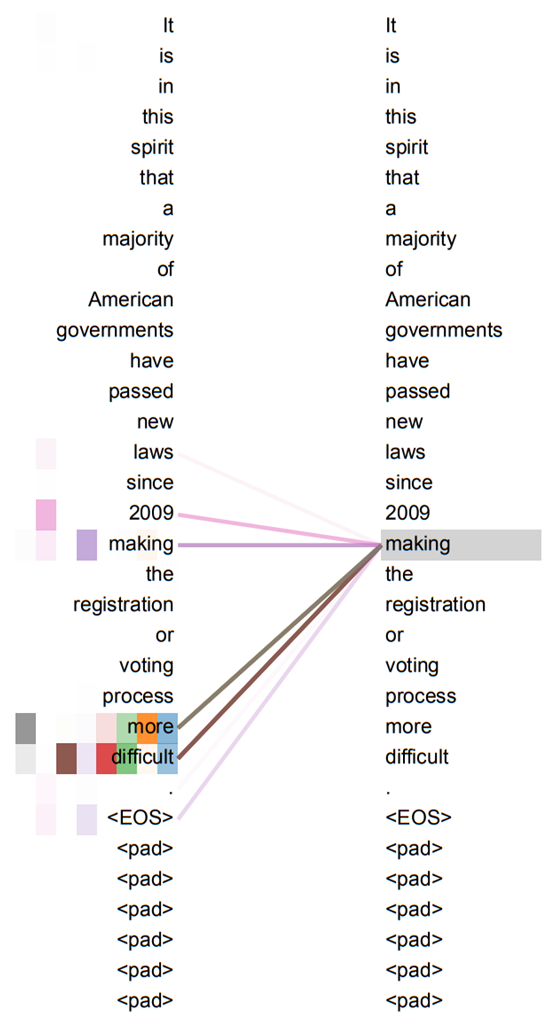
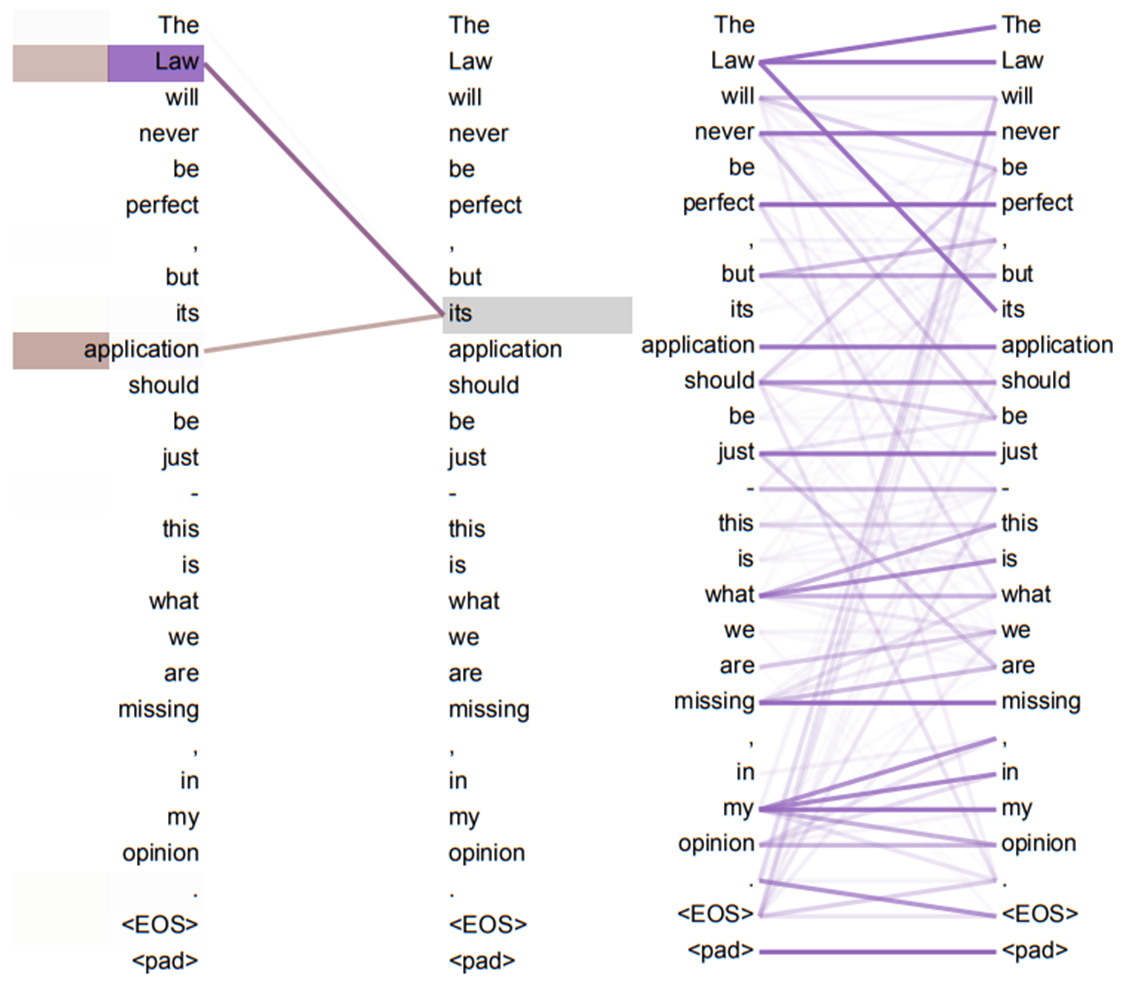
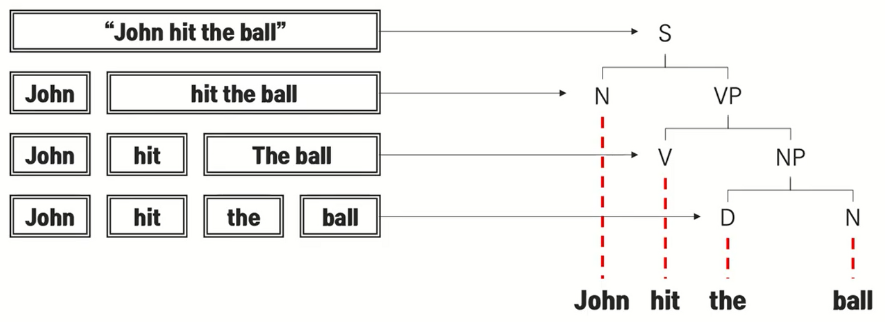
Input sentence (English) : "The cat can't enter my house because it is do dirty."
What does "it" refer to? cat ? my home ?
Human easily know that "the cat is so dirty". (* Never my house is dirty.)
Self-Attention of Attention mechanisms is the method that using the correlation of each word with the whole word, it is possible to know that 'it' means 'cat' and Transformer uses to "understand of other relevant words".
2) How to Self-Attention
Query : Representation of current word.
Key : Like label for relevant words.
Value : Actual word representations.
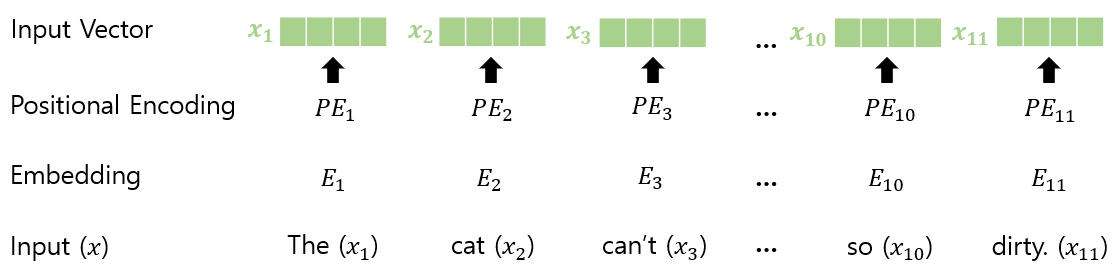
(1) Encoder Inputs
Input Embedding and Positional Encoding
Input token is vector of dimension 𝑑_𝑚𝑜𝑑𝑒𝑙 = 512
Input sentence (English) : "The cat can't enter my house because it is do dirty."
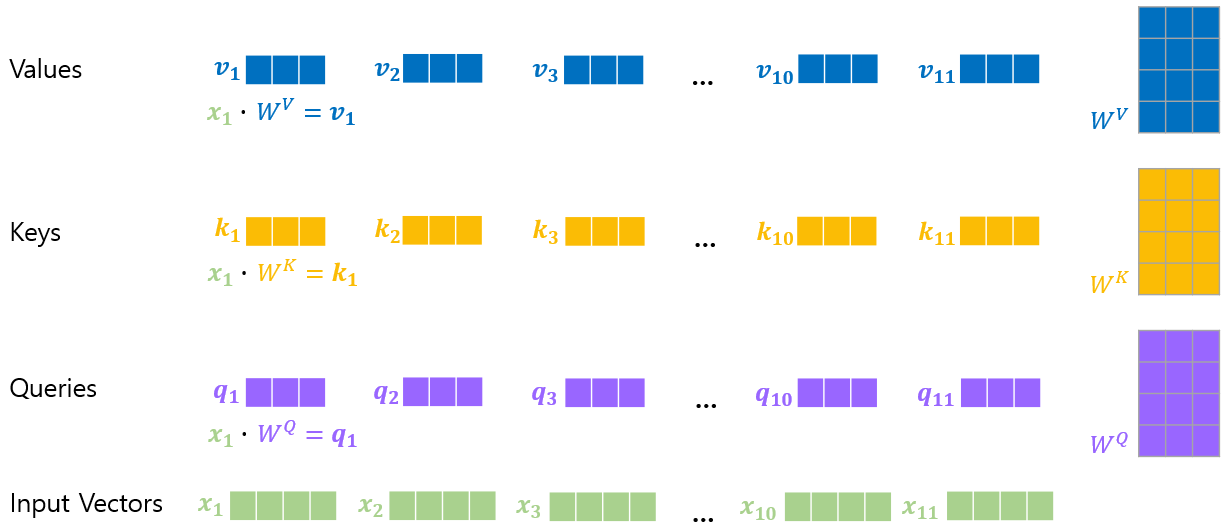
(2) Encoder Multi-Head Attention
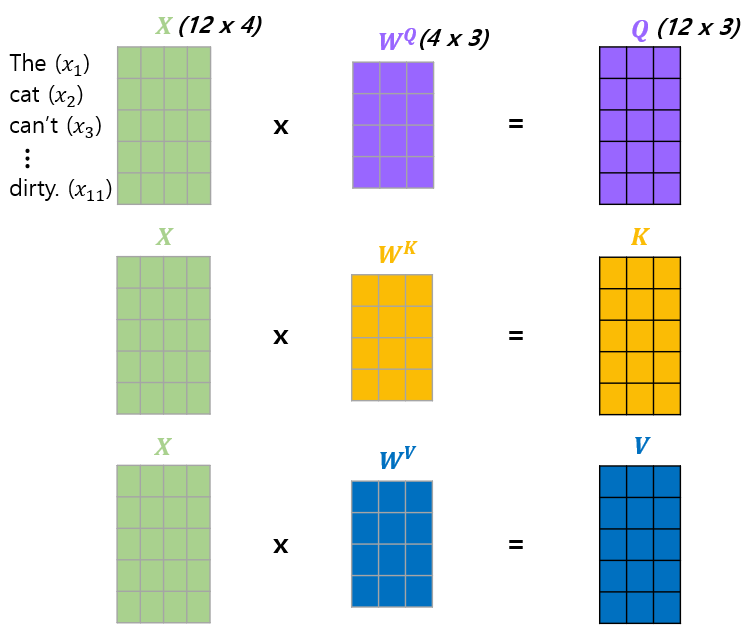
1) Query, Key, Value, and Weight
Weights (𝑊^𝑄, 𝑊^𝐾, 𝑊^𝑉) are trained during training process.
2) Scaled Dot-Product Attention
Mapping a query and a set of key-value pairs to an output.
Query(Q), Key(K), Value(V), and output are all vectors.
Query (d_k), Key (d_k), Value (d_v), and in this paper, d_k = d_v = d_model / h = 64. (h = 8)
Output is computed as a weighted sum of the values
The weight assigned to each value is computed by a compatibility fuction of the query with the corresponding key.
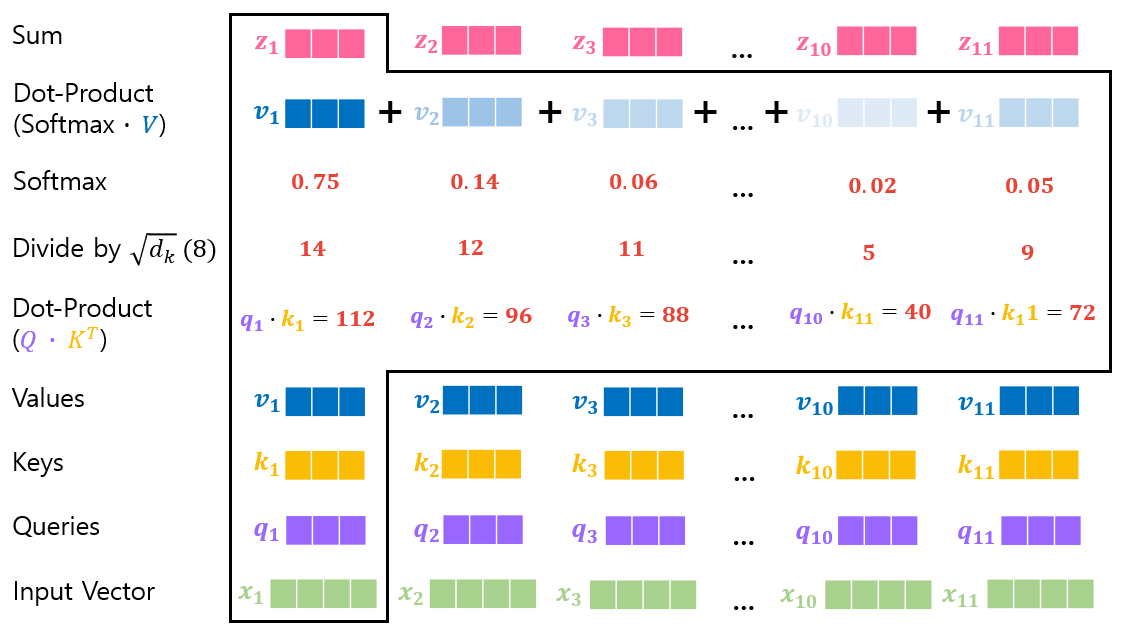
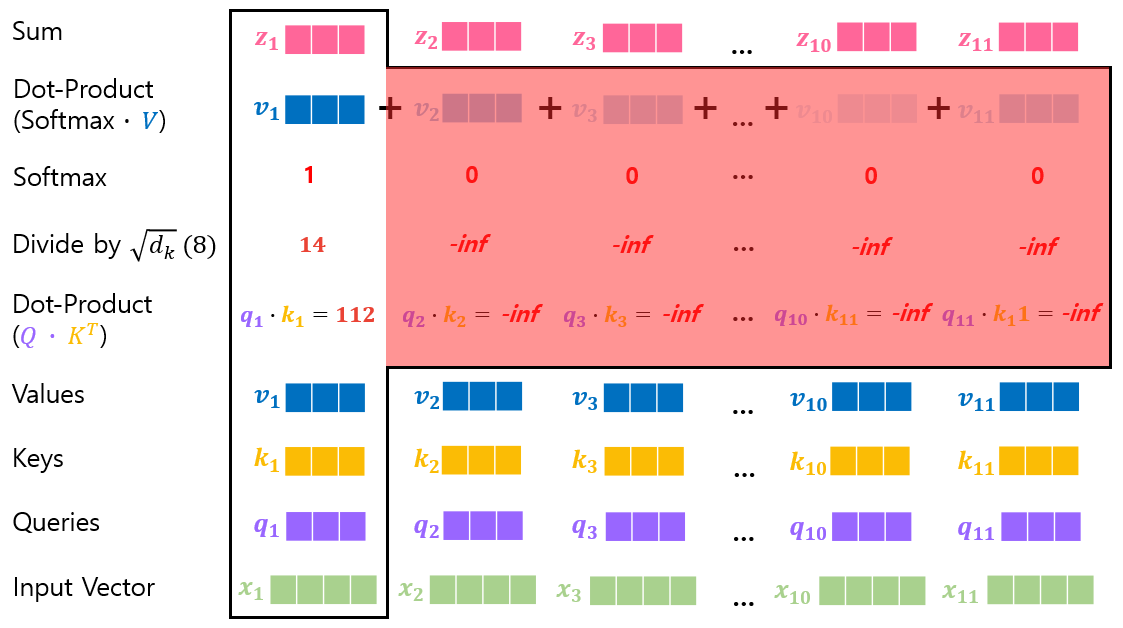
(Detailed process of Self-Attention)
Step 1. Dot-product of the query vector with the key vector of the respective word.
• Calculate how much focus to place on other parts of the input sequence as encoding a word at a certain position.
Step 2. Divide the Dot-Product by √(𝑑_𝑘) (= 8).
• For small gradients
Step 3. Encoder's Multi-Head Attention is not Making.
Step 4. Softmax function
• Calculate how much each word will be expressed at this position.
Step 5. Dot-product of the result of softmax calculation with the each value vector.
• To keep intact the values of the words want to focus on.
• To reduce the attention of irrelevant words.
Step 6. Sum up the weighted value vector which produces the output of the self-attention layer at this position.
Step 7. Do the same operation for each path to end up with a vector representing each token containing appropriate context of that token.
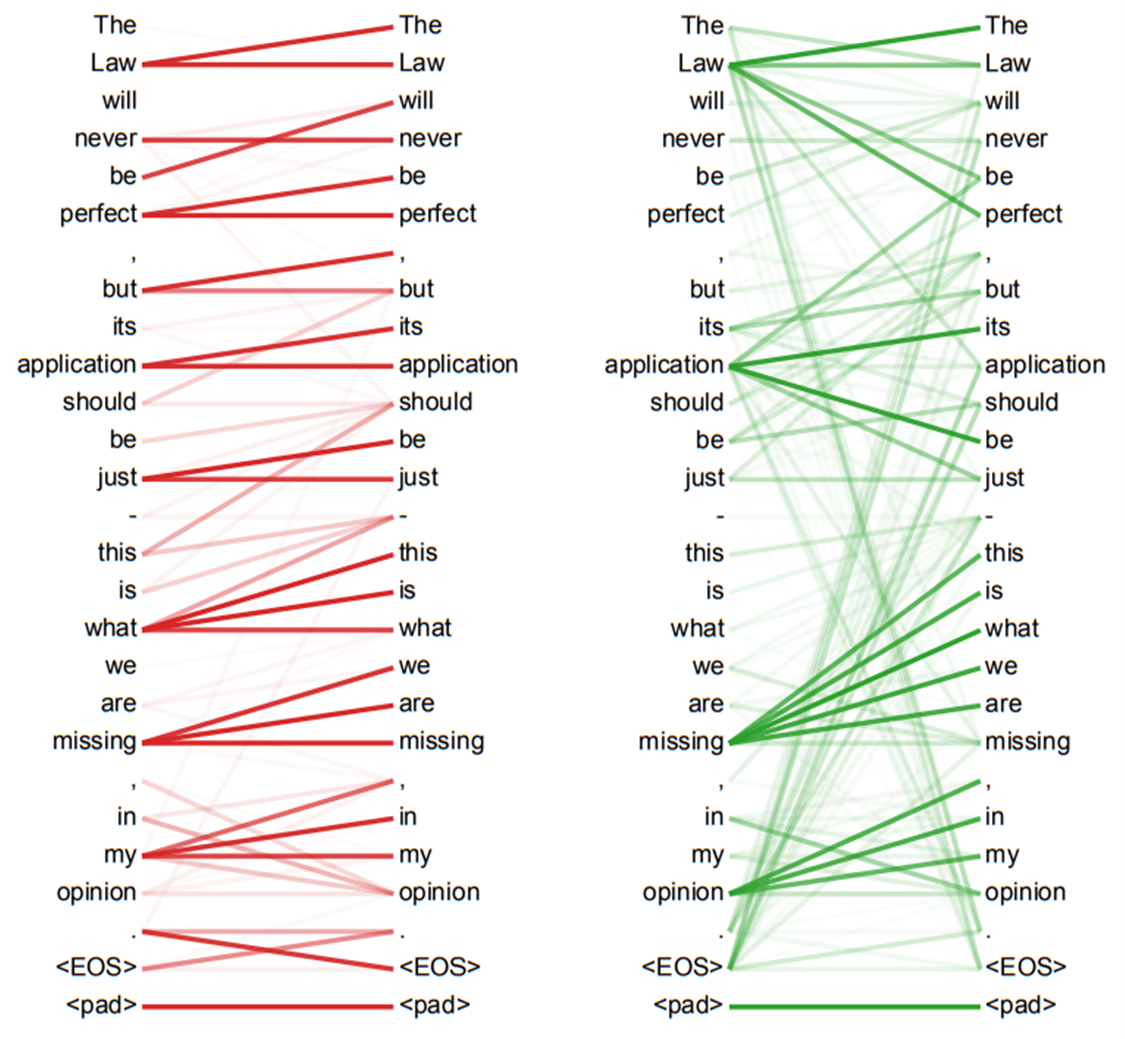
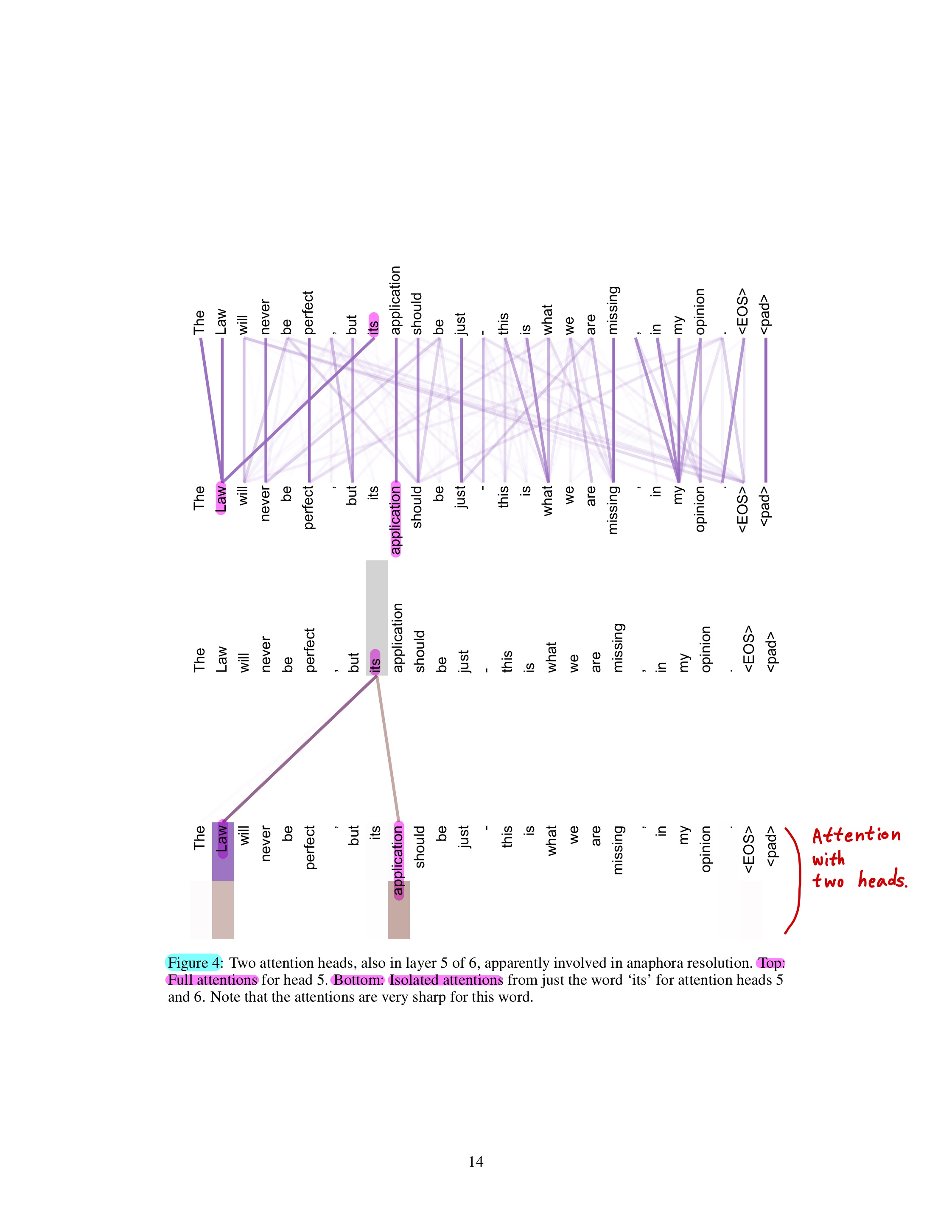
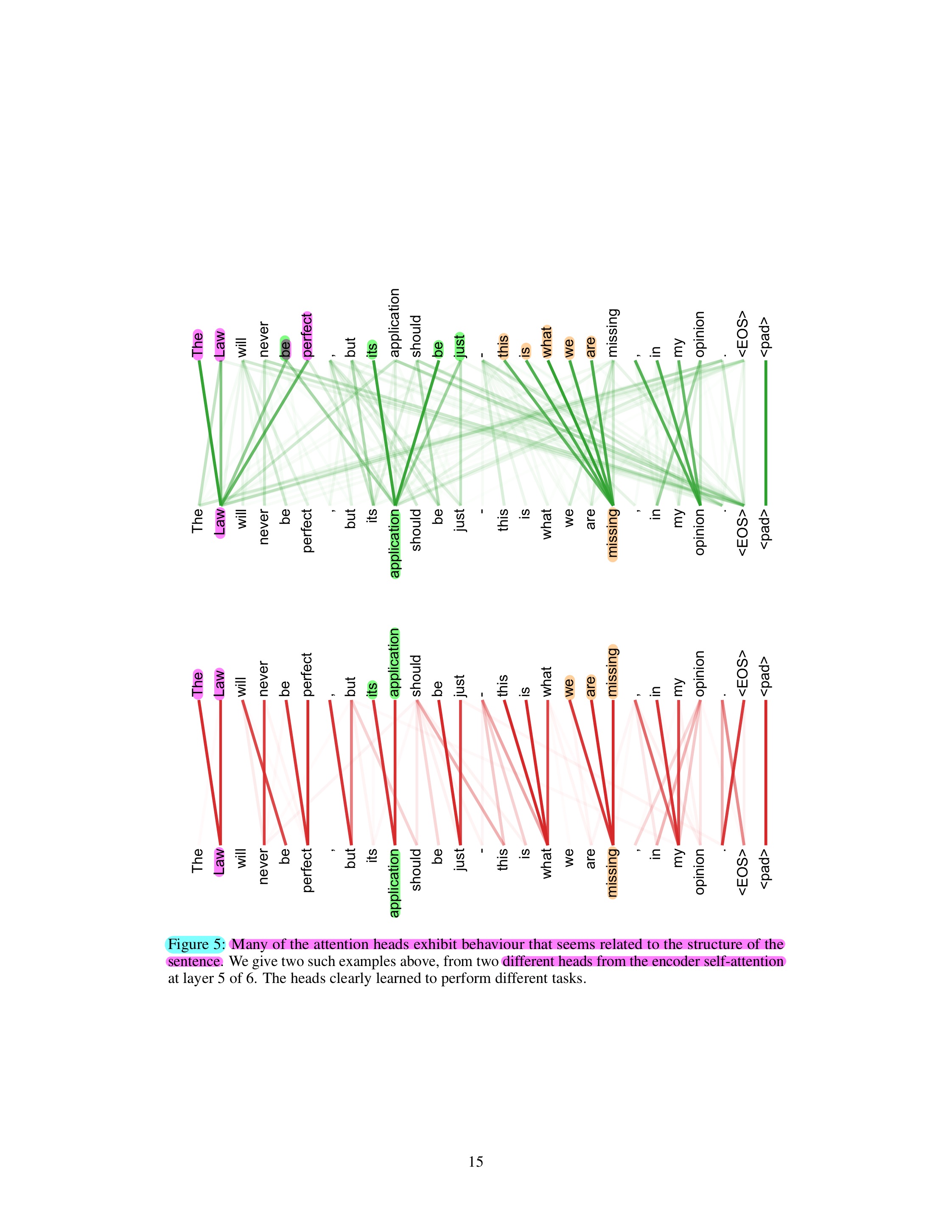
(Attention result visualization (1))
(Attention result visualization (2))
(Matrix calculation of Self-Attention)
Step 1.
Step 2.
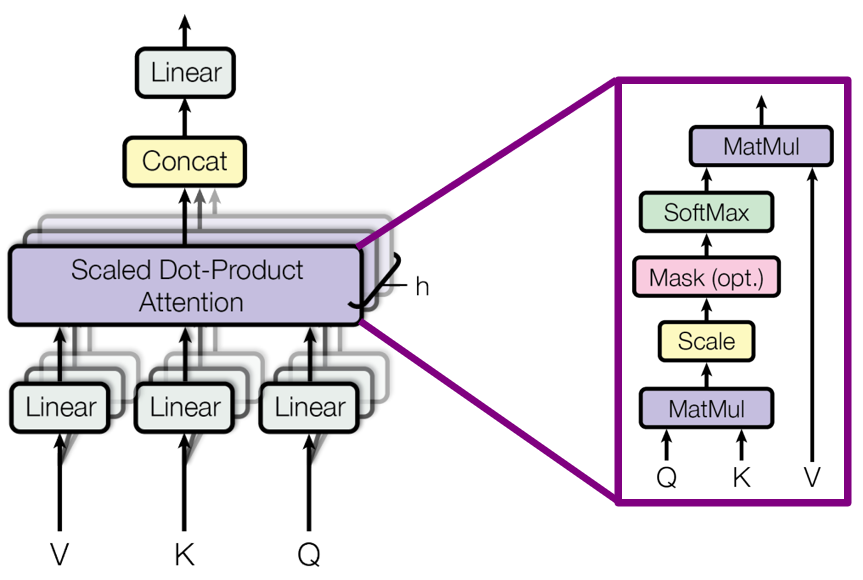
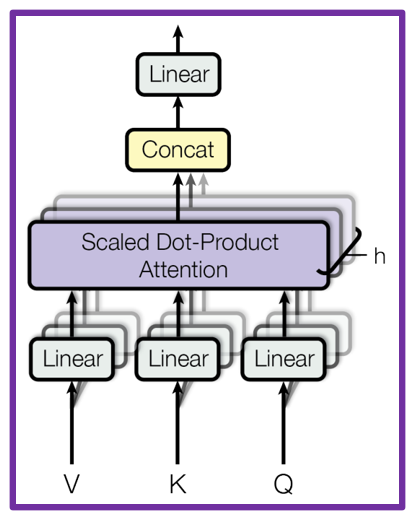
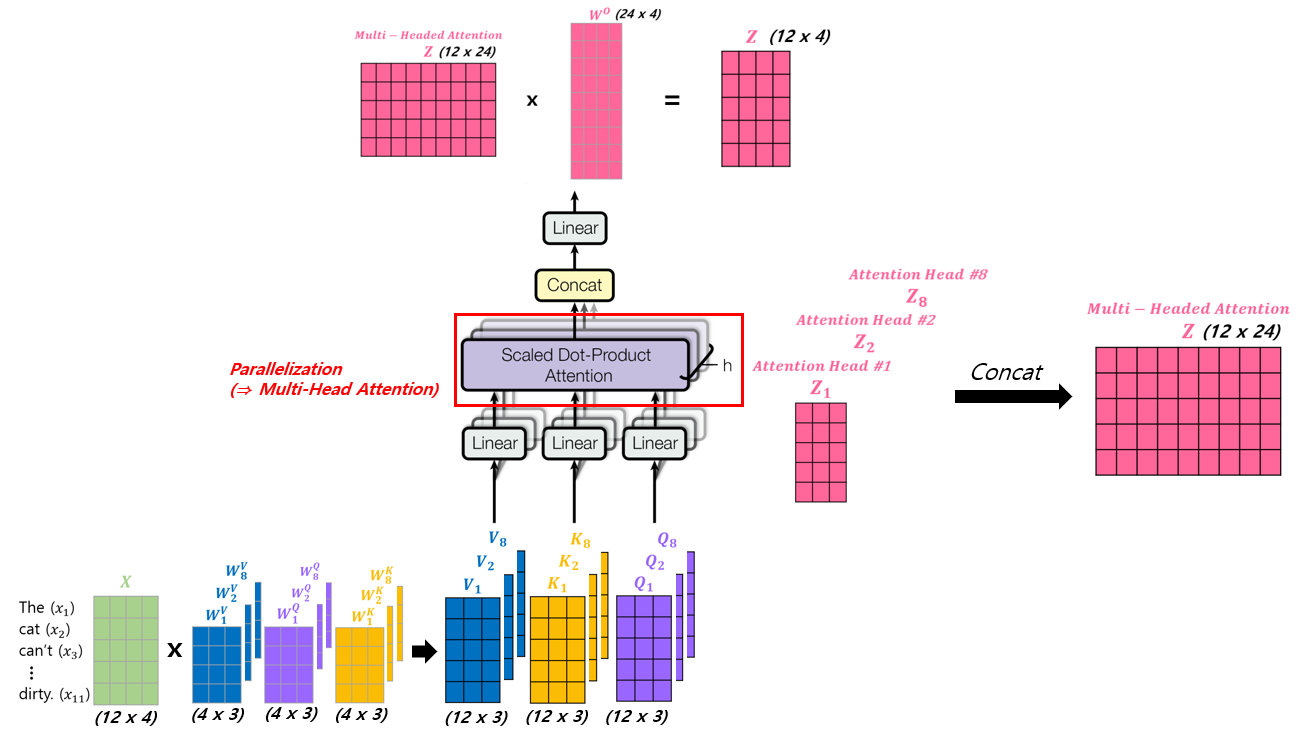
3) Multi-Head Attention
(Detailed process of Multi-Head Attention)
Weight (𝑊^O) is trained during training process.
(Each Self-Attention(Scaled Dot-Product Attention) result of Multi-Head Attention)
4) Add & Norm
Residual connection : 𝑥 + 𝑆𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥)
(𝑆𝑢𝑏𝑙𝑎𝑦𝑒𝑟( ) = s𝑢𝑏-𝑙𝑎𝑦𝑒𝑟 itself (here, Mmulti-head self-attention))
Layer normalization : 𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚()
𝐿𝑎𝑦𝑒𝑟𝑁𝑜𝑟𝑚(𝑥+𝑆𝑢𝑏𝑙𝑎𝑦𝑒𝑟(𝑥))
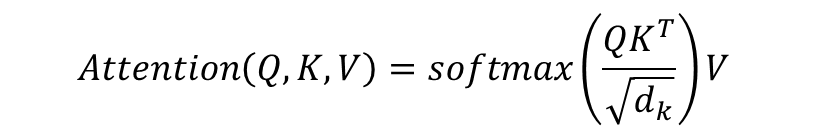
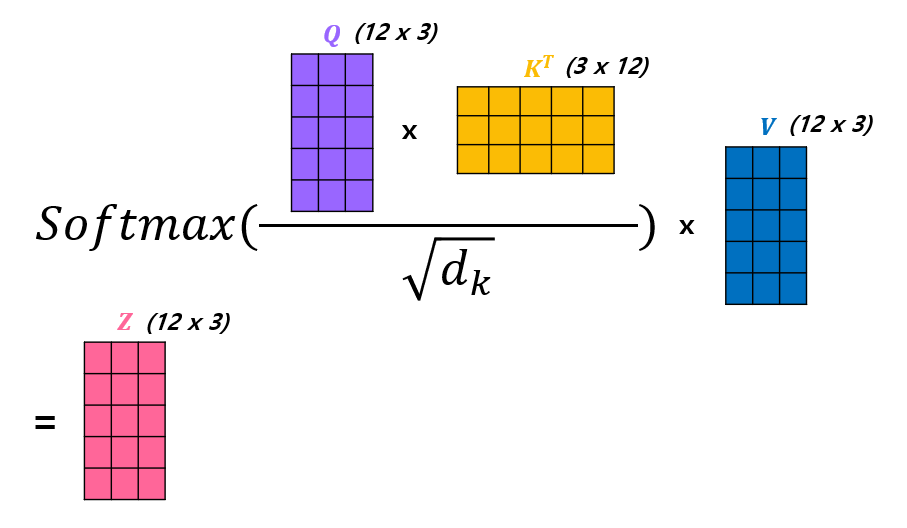

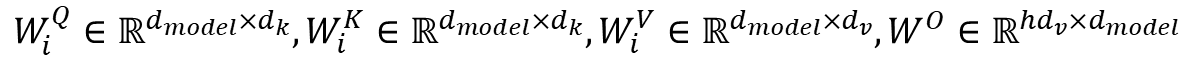
(3) Encoder Feed Forward
1) Position-wise fully connected feed-forward network (FFN)
𝐹𝐹𝑁(𝑥) = max(0, 𝑥𝑊_1+𝑏_1 ) 𝑊_2+𝑏_2 (with ReLU activation)
Dimensionality of input and output is 𝑑_𝑚𝑜𝑑𝑒𝑙 = 512.
Dimensionality of inner-layer is 𝑑_𝑚𝑜𝑑𝑒𝑙 = 2048.
Each position separately and identically (different parameters from layer to layer).
The structure of FFN is the same within the same encoder. But, it is able to the different within the different encoder.
2) Add & Norm
Same as 'Encoder Multi-Head Attention'
(4) Encoder Layers & Encoder Layers Output
1) In this paper, encoder layers are composed of a stack of N = 6 identical layers. But, N = 6 is not implicit number. N is custom number.
2) Each layer don't share the weights.
3) Set of Key-Value pairs of 'Encoder Layers Output' is input of 'Encoder-Decoder Multi-Head Attention' of each Decoder Layer.
4) Produce outputs of dimension 𝑑_𝑚𝑜𝑑𝑒𝑙 = 512.
(5) Decoder Inputs
Enter to the Transformer model in the same way as 'Encoder Inputs'
Translated sentence of input sentence of Encoder (In this paper, German sentence or French sentence)
(Ex.) Output sentence (German) : "Die Katze kann mein Haus nicht betreten, weil sie schmutzig ist."
(Ex.) Output sentence (French) : "Le chat ne peut pas entrer dans ma maison car il est sale."
(6) Decoder Masked Multi-Head Attention
In the same way as 'Encoder Multi-Head Attention', but except part of 'Masking' of 'Scaled Dot-Product Attention'.
(Detailed process of Masked Self-Attention)
Self attention layers in the decoder is only allowed to attend to earlier positions in the output sequence, which is done by masking future positions (setting them to -inf) before the softmax step in the self attention calculation.
This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less that i.
(7) Encoder-Decoder Multi-Head Attention
Input of 'Encoder-Decoder Multi-Head Attention' of each Decoder Layer are Set of Key-Value pairs of 'Encoder Layers Output' and Queries of 'Decoder Masked Multi-Head Attention'.
In the same way as 'Encoder Multi-Head Attention'.
(8) Decoder Feed Forward
Same as 'Encoder Feed Forward'
(9) Decoder Layers
1) In this paper, encoder layers are composed of a stack of N = 6 identical layers. But, N = 6 is not implicit number. N is custom number.
2) Each layer don't share the weights.
(10) Decoder Outputs
1) At each step the model is auto-regressive, consuming the previously generated symbols as addiional input when generating the next.
2) Linear layer : a simple fully connected neural network that projects the vector produced by the stack of decoders into a much larger vector called a logits vector.
3) Softmax layer : output of Linear layer turn those scores into probability.
The cell with the highest probability is chosen, the word associated with it is produced as the output of this time step.
4. In Addition...
I think that ... this model (Transformer) is similar to Backdirectional Model.
Why Self-Attention
1. Total computational complexity per layer.
2. Parallelized computation.
3. Path length between long-range dependencies in the network.

Training
1. Training Data and Batching
(1) Training Data
WMT 2014 English-German dataset
WMT 2014 English-French dataset
(2) Batching
Sentence pairs were batched together by approximate sequence length.
2. Hardware and Schedule
(1) Hardware
8 NVIDIA P100 GPUs
(2) Schedule
Base model
- Step time : 0.4 seconds
- Total : 100,000 steps / 12 hours
Big model
- Step time : 1.0 seconds
- Total : 300,000 steps / 3.5 days
3. Optimizer
Adam oprimizer with 𝛽_1=0.9,𝛽_2=0.98, and 𝜖=10^(−9)
Learning rate (warmup_steps = 4000) :
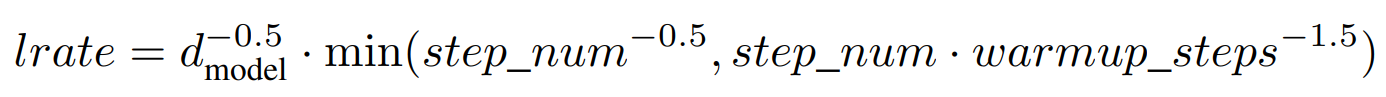
4. Regularization
Residual Dropout
Label Smoothing
Results
1. Machine translation
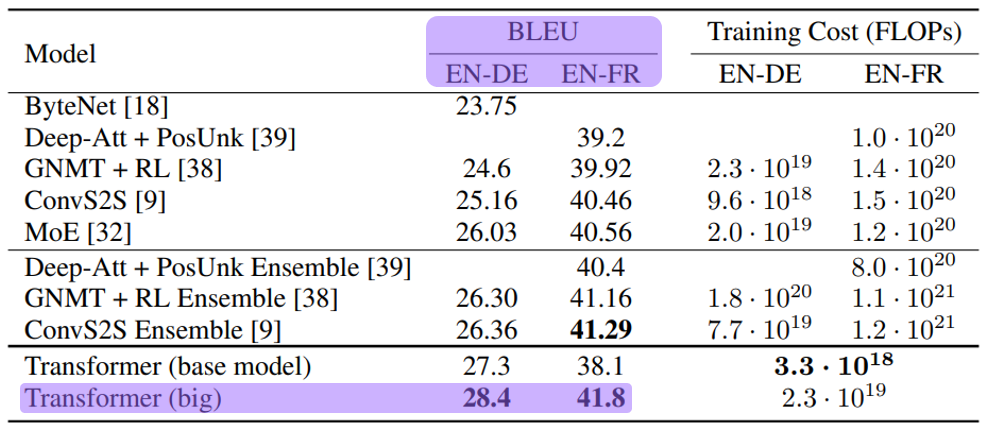
- Tranformer established a new state-of-the-art BLEU score in WMT 2014 English-to-German translation task and WMT 2014 English-to-French translation task.
- BLEU score (Bilingual Evaluation Understudy Score)
Go to know
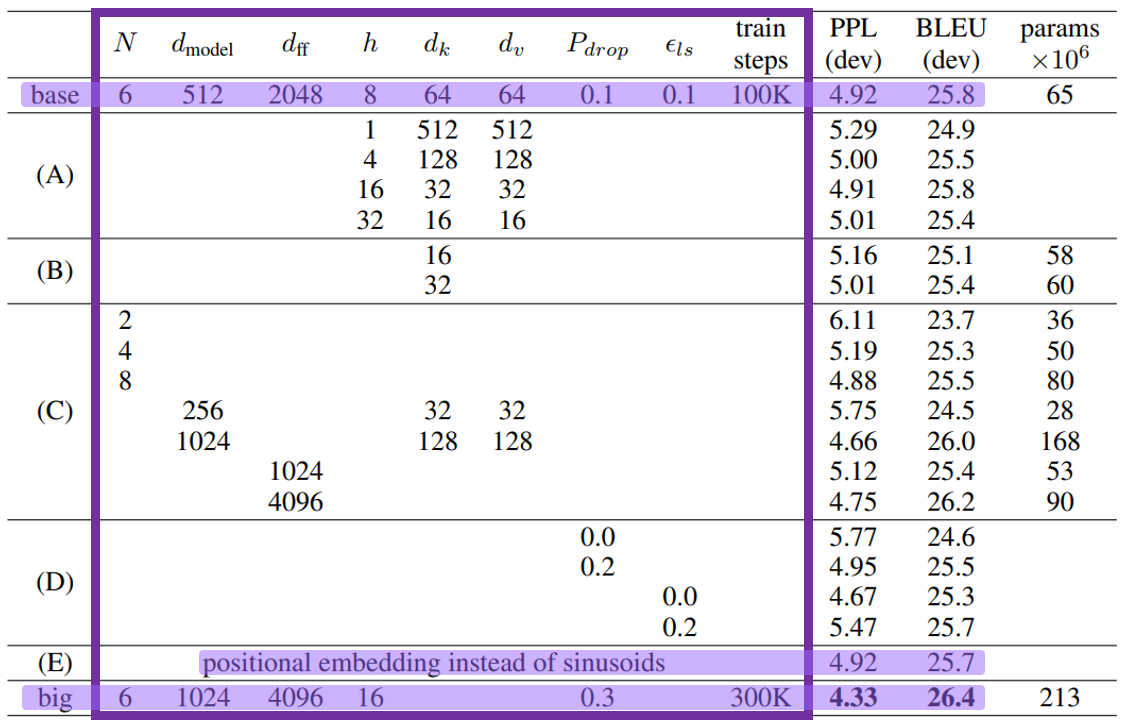
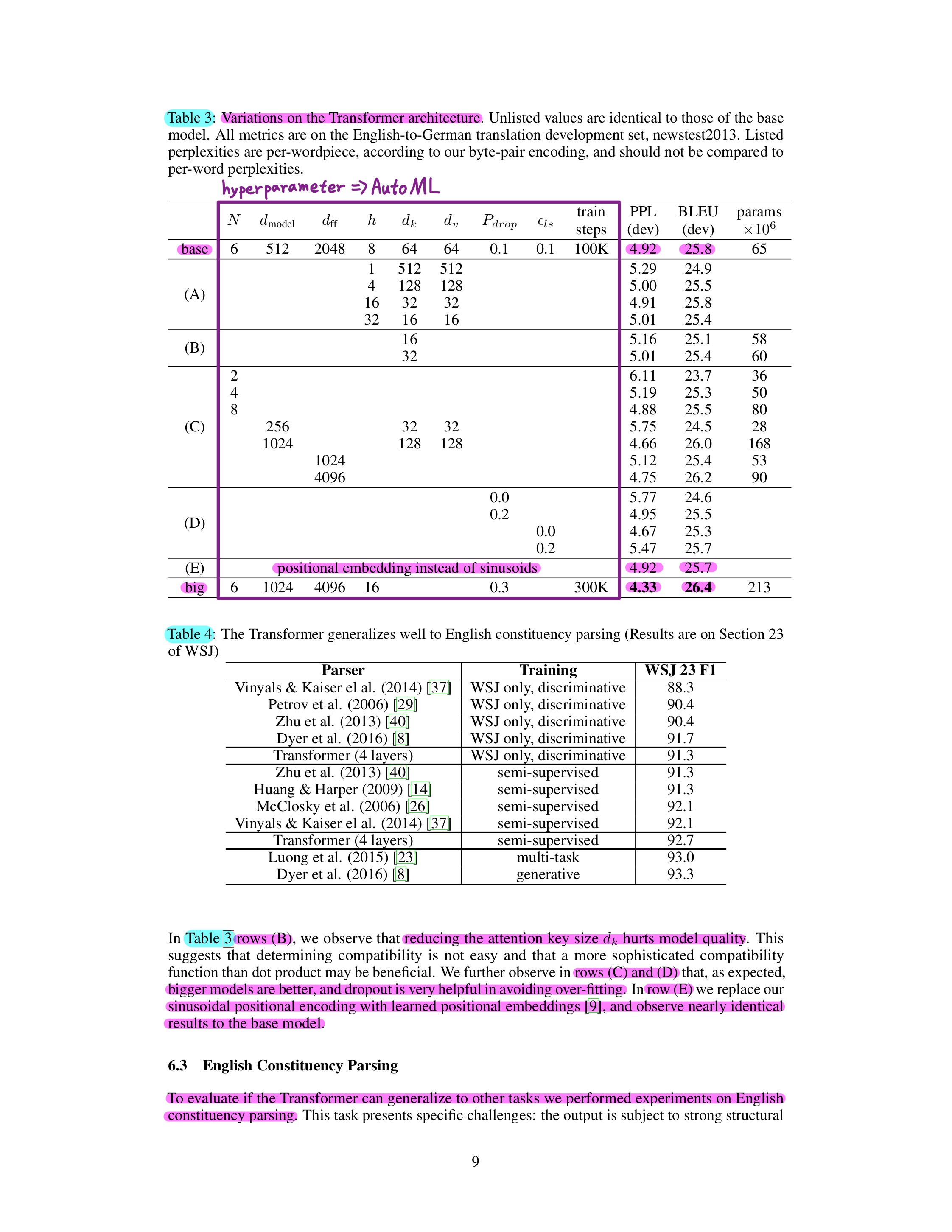
2. Model Variations
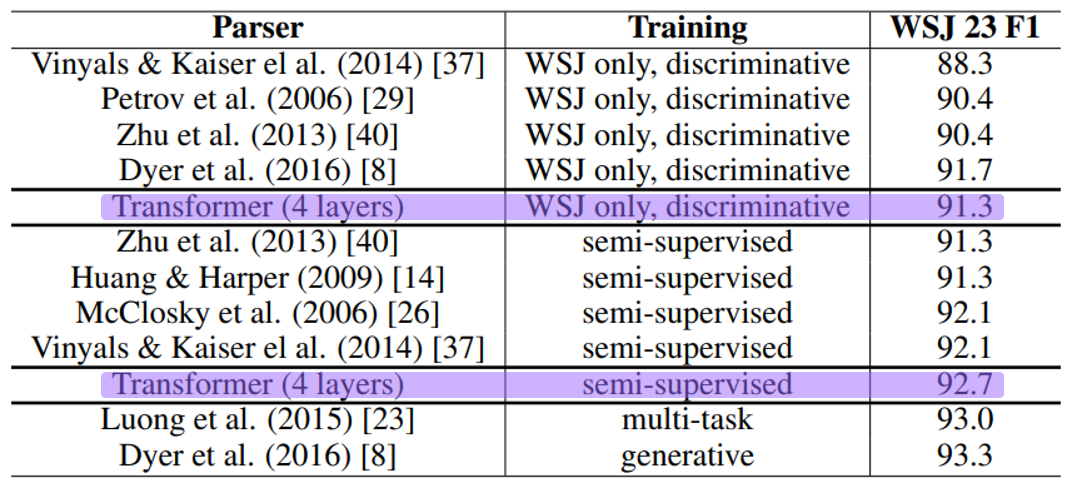
3. English Constituency Parsing
- This Experiment is Tranfer Learning with Transformer.
- Constituency Parsing (phrase parsing)
- Goal : understand the structure of a sentence.
- Used inlanguage where word order is fixed such as English.
Conclusion
- Transformer is the first sequence transduction model based entirely on attention and used in encoder-decoder architectures with multi-headed self-attention.
- Also, for translation tasks, is parallelly trained self-attention in multi-head attention faster than architectures based on recurrent or convolutional layers .
- Transformer advanced the state of the art at that time in translation tasks.
- Transformer can be extended problems involving input and output modalities such as images, audio and video other than text
References
1. Background References
- Extended Neural GPU ([16] Kaiser et al., 2016), ByteNet ([18] Kalchbrenner et al., 2017), ConvS2S ([9] Gehring et al., 2017)
- Self-attention related tasks ([4] Cheng et al., 2016, [27] Parikh et al., 2016, [28] Paulus et al., 2017, [22] Lin et al., 2017)
- End-to-end memory networks ([34] Sukhbaatar et al., 2015)
2. Data References
Training Data
- WMT 2014 English-German dataset (Go to Site)
- WMT 2014 English-French dataset (Go to Site)
3. Review References
- Transformer paper (Go to Site)
- KU DSBA LAB (Go to Site)
- 집현전 자연어처리 모임 (Go to Site)
- BLEU (Go to Site)
- Constituency Parsing (Go to Site)












Generative AI
Snow Peak Titanium Kettle: This is a great option for those looking for a lightweight, durable, and easy to use backpacking kettle. It is made of titanium and is designed to last. https://myteakettle.com/best-camping-kettle/