[RL] Mastering the game of Go with deep neural networks and tree search
Reinforcement Learning
목록 보기
1/6

** 위 사진은, 제가 고2때, 생명과학 시간에 선생님께서 보여주신 알파고와 이세돌 선수의 대결을 보고 영감을 받아 선택한 사진입니다. [출처]
Paper Name: Mastering the game of Go with deep neural networks and tree search (Google DeepMind(2016.10.)) (Read to Go)
Contents :
- Go
- Abstract
- Introduction
- Methods
- Result
- Conclusion
- Future Research
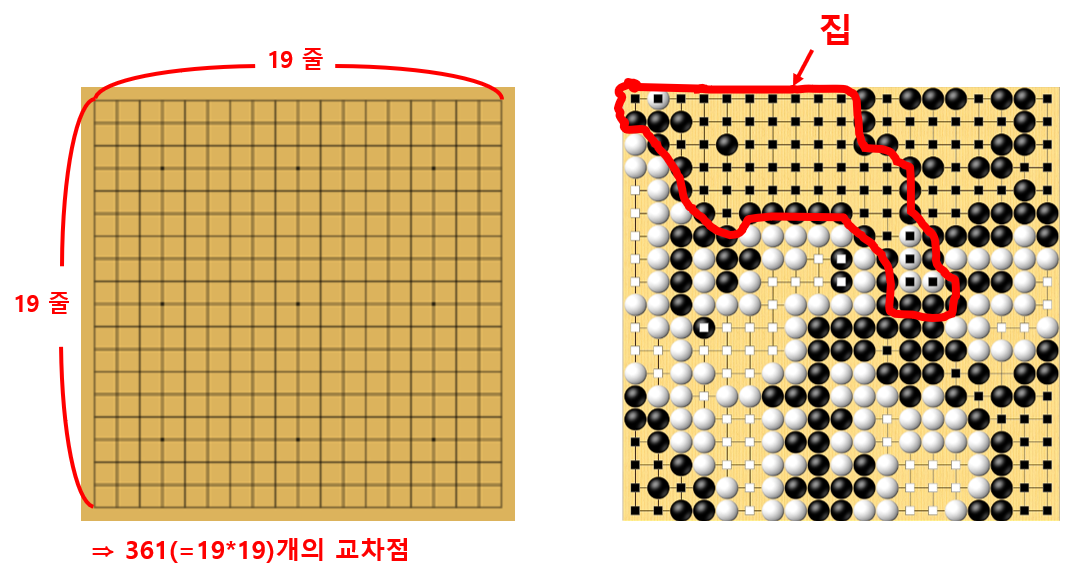
Go (바둑)
- 두 사람이 흑과 백의 돌을 사각의 판 위에 번갈아 놓으며 집을 차지하는 것을 겨루는 놀이
- 가로와 세로 각각 19줄이 그어진 바둑판 위의 361개 교차점에 돌을 둘 수 있음(⇒ 경우의 수 굉장히 많음, 250^120)
- 게임 목표: 상대 보다 더 많은 공간을 자신의 돌로 둘러 싸는 것
Abstract
AlphaGo
- 바둑에서, 세계 챔피언을 물리친 최초의 프로그램
- 심층신경망(DNN)을 이용해, 몬테카를로 트리 탐색(MCTS) 기술 적용 후, 위치 평가 및 동작 선택 진행
- DNN = 지도학습(SL, Expert moves) + 강화학습(RL, Self-Play)
- MCTS: 확률 게임에서 트리 형태로 모든 경우를 만들고, 랜덤으로 트리의 가지를 선택하여 탐색하는 것 (Policy Network & Value Network)
Introduction
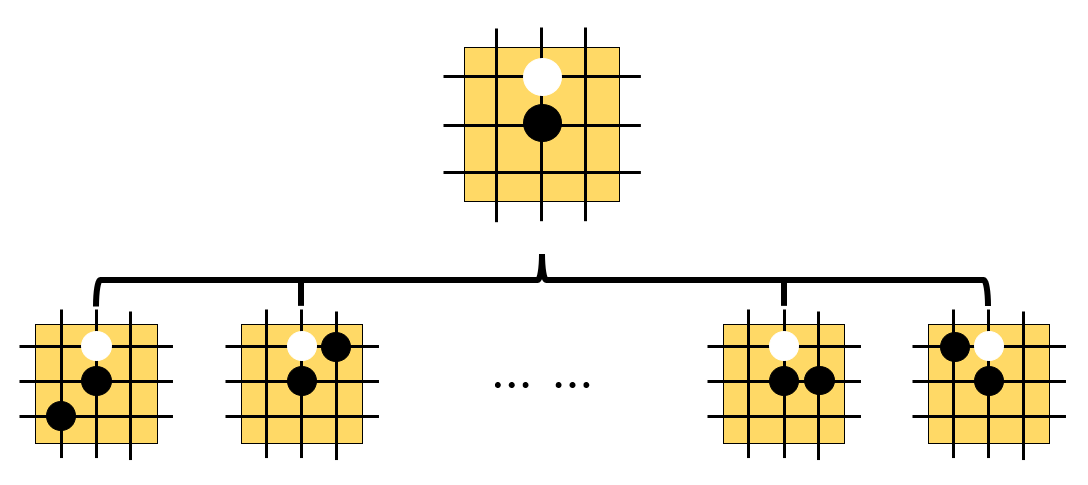
MC(Monte-Carlo)
MCTS(Monte-Carlo Tree Search)
- 확률 게임에서 트리 형태로 모든 경우를 만들고 랜덤으로 트리의 가지를 선택하여 탐색해 보는 것
- 단계 설명 (1)
- 단계 설명 (2)
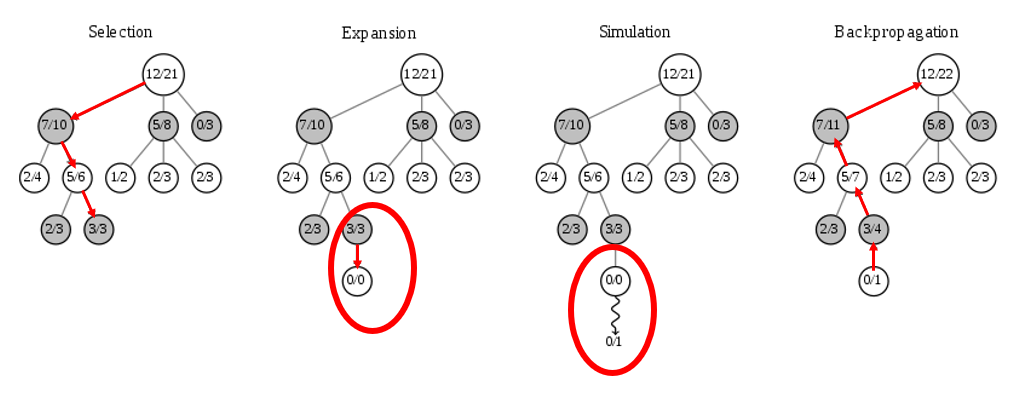
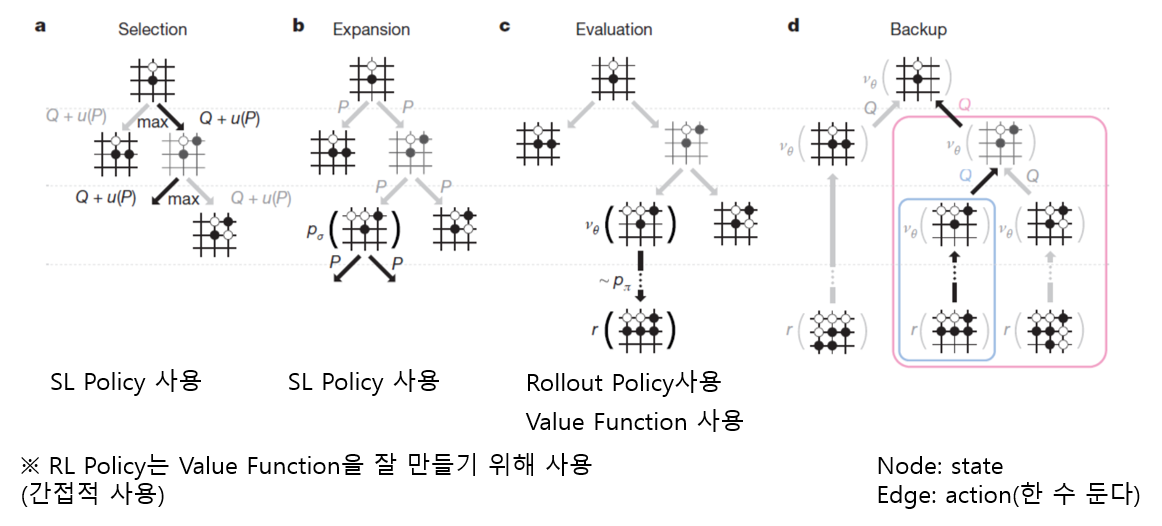
Methods
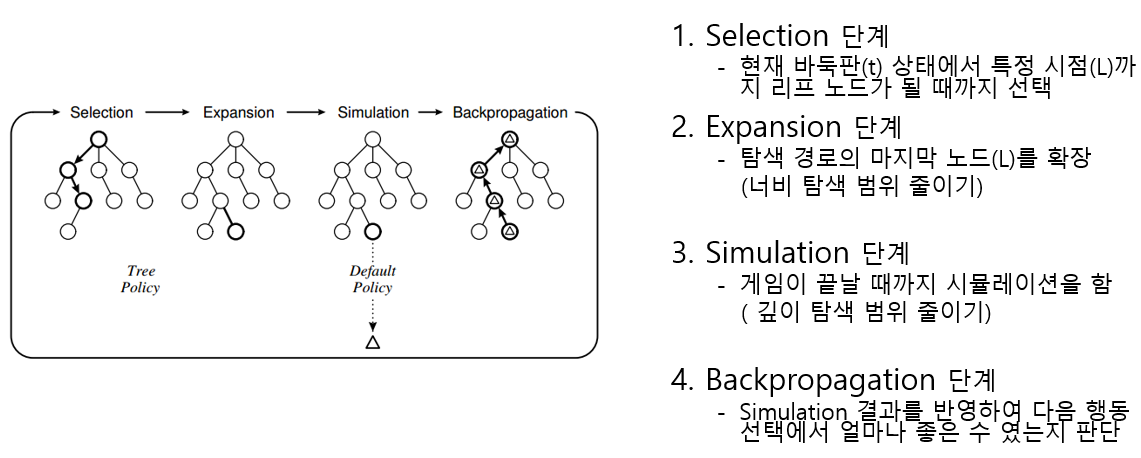
MCTS(Monte-Carlo Tree Search)
Policy Network (= Policy Function)
Value Network (= Value Function)
Policy Network & Value Network
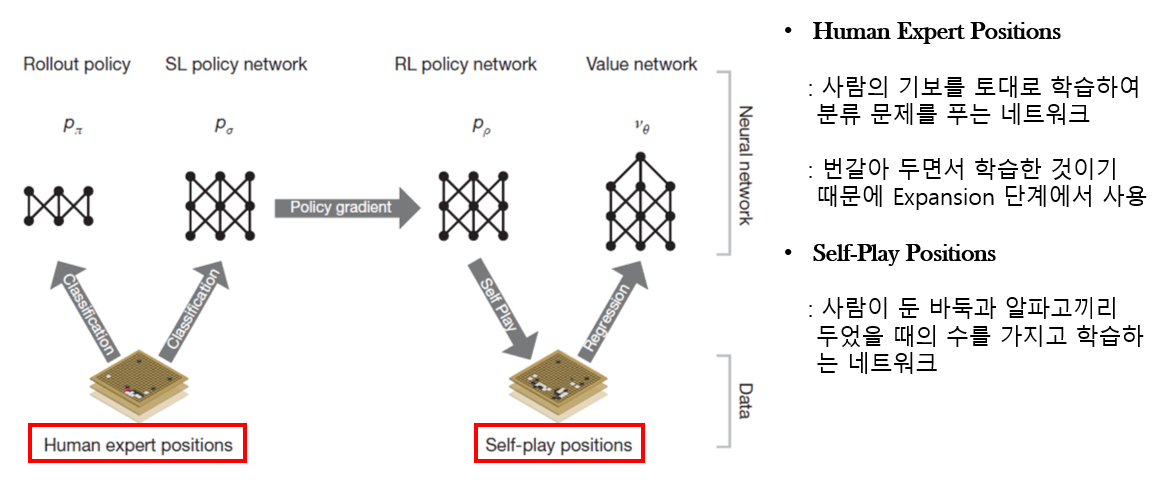
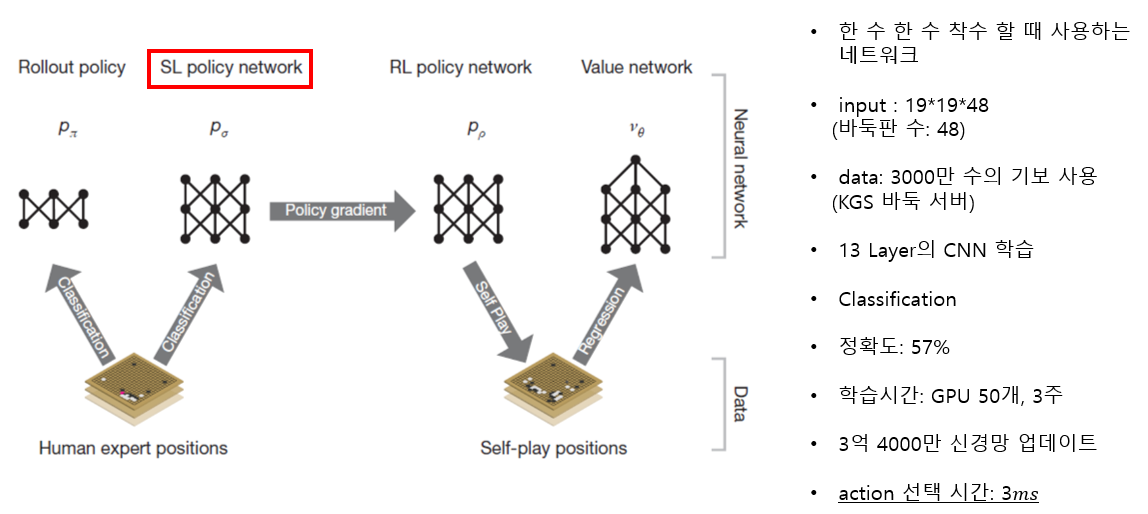
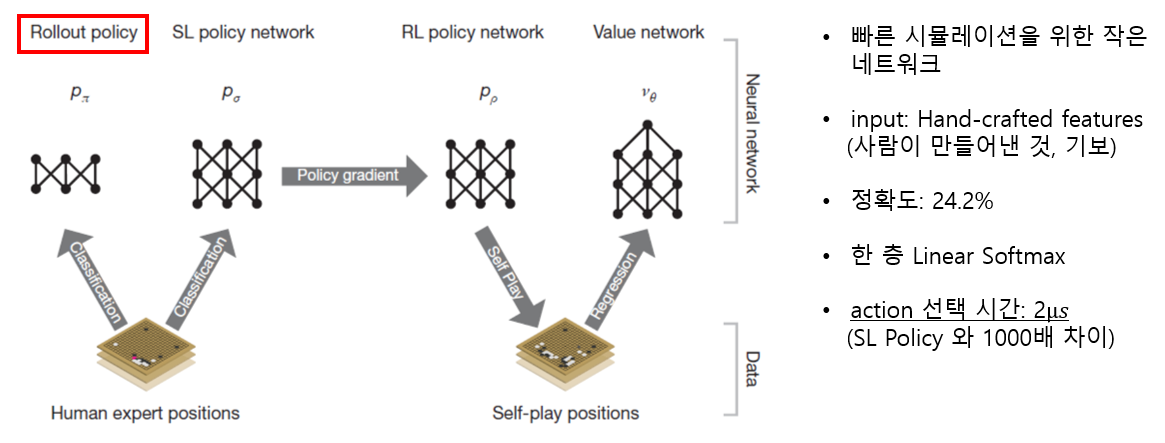
1. SL Policy Network (Human Expert Positions)
2. Rollout Policy (Human Expert Positions)
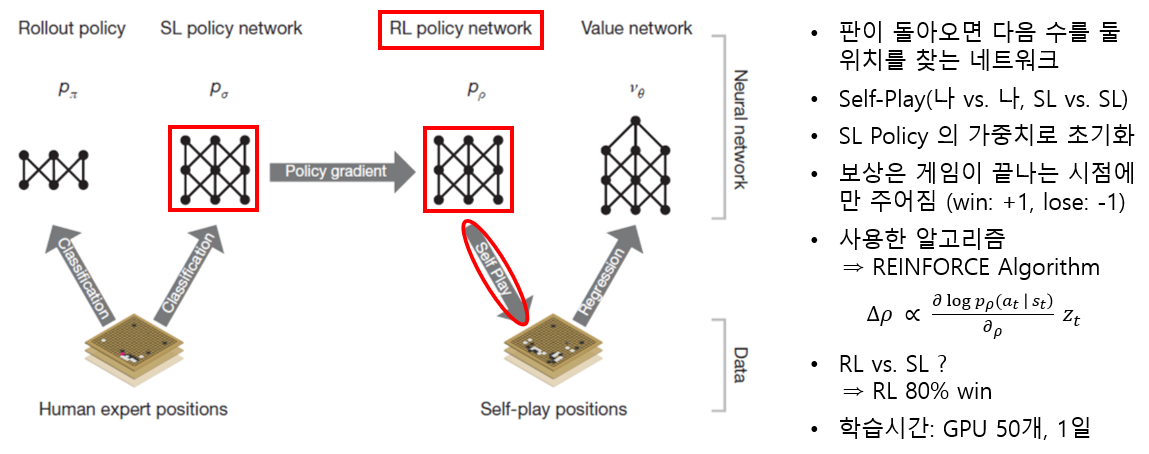
3. RL Policy Network (Self-Play Positions)
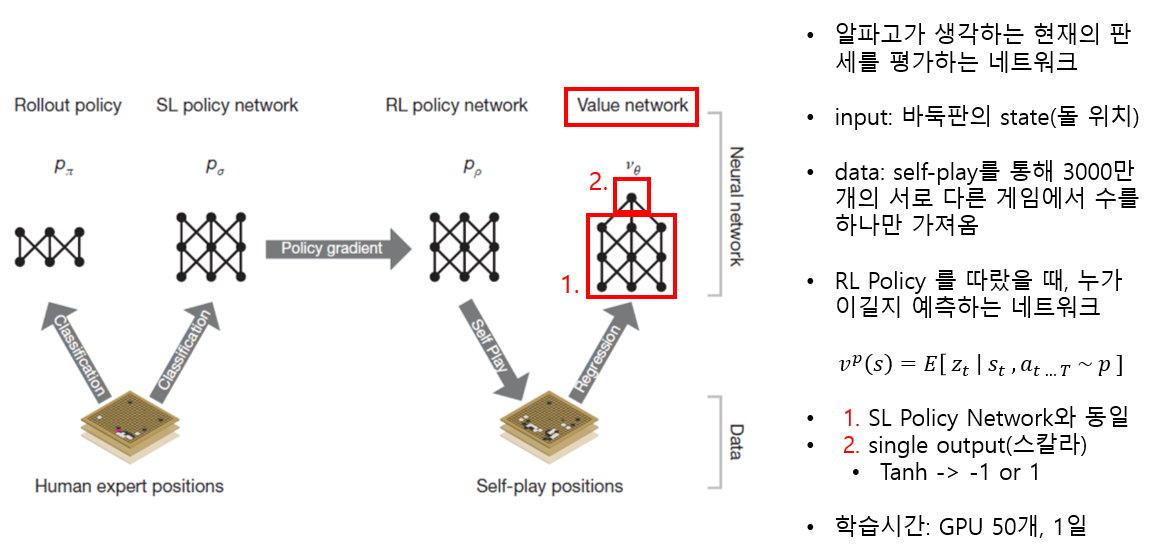
4. Value Network (Self-Play Positions)
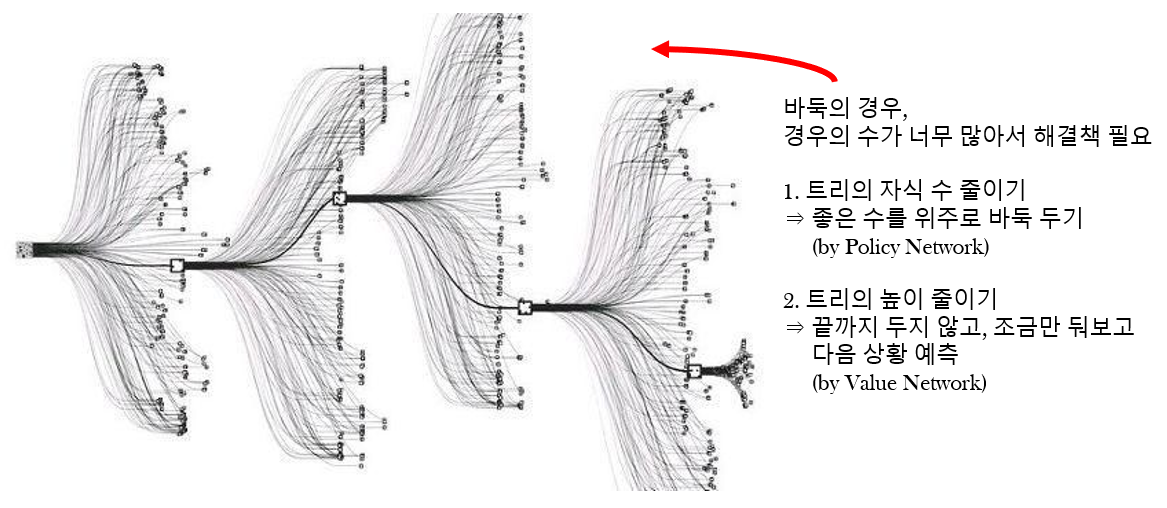
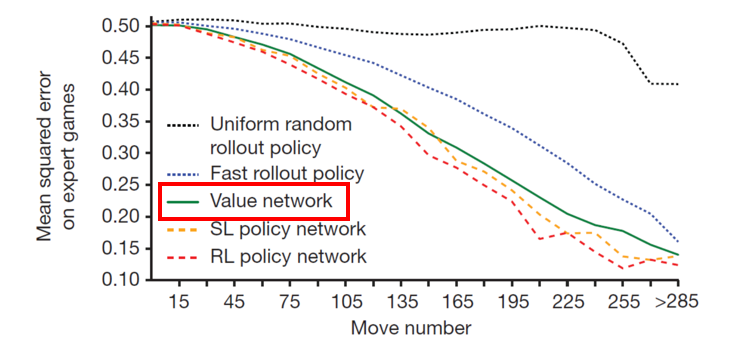
MCTS의 깊이를 줄이기 위한 승률예측 정확도
- Value Network를 이용하면, RL Policy를 이용한 거 보다 약 1만 5000배 빠르고, 비슷한 정확도를 보임
AlphaGo’s MCTS
Searching with policy and value networks
- RL Policy Network
- Policy Gradient Reinforcement Learning을 통해 알파고 기보도 고려함
- 이긴 판 reward: +1, 진 판 reward: -1
- Value Network
- 사람의 기보만 있을 경우, Overfitting이 일어날 수 있기 때문에 알파고의 기보(RL Policy Network)가 추가됨
- Distributed AlphaGo의 성능이 더 좋음
AlphaGo’s Training PipeLine




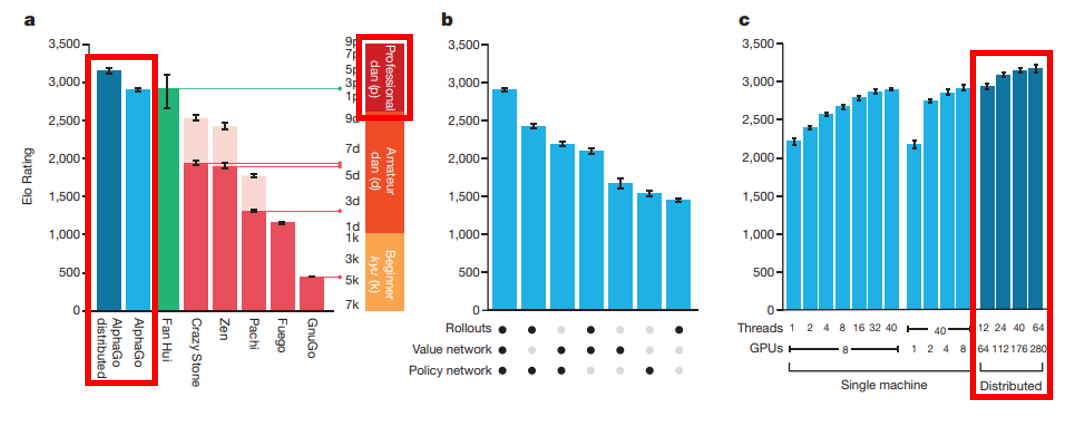
Result
- 제한 시간내에서 다른 인공지능과 비교했을 때, 네 점 핸디캡을 두고 시작하여도 모두 이김
- Distributed AlphaGo: 런타임할 때 사용
- Game Result Prediction: 100번 롤아웃해서 얻어지는 결과로 평가함
Conclusion
AlphaGo 연구의 의의
- 딥러닝 기술의 성능 향상
- 실용적인 연구
- MCTS를 이용해서도 바둑을 풀 수 있음
- 인공지능의 대중화
Future Research
AlphaGo Zero
- 게임 규칙을 넘어선(인적데이터, 지침 또는 도메인지식 없이), 오직 강화학습만 기반한 알고리즘 사용
- 신경망 = AlphaGo 움직임 선택 + AlphaGo 게임의 승자 예측
- 트리 검색 강도 향상을 통해 정확한 이동 선택을 하게 함
- 기존의 AlphaGo와의 경기에서 100 대 0으로 이김
Existing AI (vs. RL)
- Supervised Learning System(지도학습 시스템)
- Expert data sets
- expensive(비쌈), unreliable(무신뢰성) or simply unavailable(복잡한 사용)
- if, Reliable data sets
- 훈련된 시스템의 성능에 제한점을 줄 수 있음
(Existing AI vs.) Reinforcement Learning (RL)
- 사람의 능력을 뛰어넘음
- 사람의 전문 지식이 부족한 영역에서 작동 할 수 있도록 자신의 경험을 통해 훈련
- Atari 및 3D 가상 환경과 같은 컴퓨터 게임에서 사람보다 성능이 뛰어남

Generative AI