
이 글은 웹 엔지니어
Adams Rackis님이 작성하여 FrontendMasters.com 블로그에 기고한 다음의 글을 한국어로 옮긴 것입니다 : Combining React Server Components with react-query for Easy Data Management
리액트 서버 컴포넌트(React Server Components, RSC)는 웹 개발의 흥미로운 혁신입니다. 이번 글에서는 이를 간략하게 소개하고, 그 목적과 이점, 그리고 한계를 살펴볼 것입니다. 그리고 이러한 한계를 해결하는 데 도움이 될 수 있도록, react-query를 함께 사용하는 방법을 보여드리면서 마무리하겠습니다. 그럼 시작해 보겠습니다!
왜 RSC인가?
리액트 서버 컴포넌트는 그 이름에서 알 수 있듯 서버에서 실행되며, 서버에서만 실행될 수 있습니다. 이것이 왜 중요한 것인지 알아보기 위해, 지난 10여 년 동안 웹 개발이 어떻게 발전해왔는지 빠르게 살펴보도록 하겠습니다.
RSC 이전에는, 자바스크립트 프레임워크(React, Svelte, Vue, Solid 등)가 애플리케이션을 구축하기 위한 컴포넌트 모델을 제공했습니다. 이러한 컴포넌트는 서버에서 실행될 수 있었지만, 서버가 앱을 렌더링할 수 있도록 컴포넌트의 HTML을 문자열화하여 브라우저로 내려주는 동기식 작업으로만 가능한 것이었습니다. 그러면 앱은 브라우저에서 재차 렌더링되고, 이 시점에서 앱은 대화형(interactive)이 됩니다. 이러한 모델에서는 데이터를 로드하는 유일한 방법이란 클라이언트에서 발생하는 부수 효과(side-effect)뿐입니다. 앱이 사용자의 브라우저에 도달할 때까지 기다렸다가 데이터를 로드하는 것은 느리고 비효율적이었습니다.
이러한 비효율성을 해소하기 위해 Next, SvelteKit, Remix, Nuxt, SolidStart 등과 같은 메타 프레임워크가 만들어졌습니다. 메타 프레임워크들은 서버에서 데이터를 로드하는 다양한 방법을 제공하였으며, 데이터는 메타 프레임워크에 의해 컴포넌트 트리에 주입되었습니다. 이런 코드는 이식성이 떨어지고 대개 약간 어색했습니다. 특정 경로와 연관된 일종의 로더(loader) 함수를 정의하고 데이터를 로드한 다음, 사용하고 있는 메타 프레임워크의 규칙에 따라 데이터가 컴포넌트 트리에 적절히 표시되기를 기대해야 했습니다.
이러한 방식은 잘 동작하긴 했지만 문제가 없는 것은 아니었습니다. 프레임워크에 종속적일 뿐만 아니라, 구성(composition)에도 어려움을 겪었습니다. 일반적으로 컴포넌트는 자신을 렌더링하는 컴포넌트에 의해 명시적으로 props를 전달받는 반면, 이제는 로더에서 반환하는 내용에 따라 메타 프레임워크가 암묵적으로 props를 전달받게 됩니다. 또한 이러한 방식이 가장 유연한 것도 아니었습니다. 특정 페이지는 필요한 데이터를 미리 알고 모두 로더에 요청해야 했습니다. 클라이언트에서 렌더링되는 SPA에서는 필요한 컴포넌트를 렌더링하고, 필요한 데이터만 가져오도록 할 수 있었습니다. 비록 성능 측면에서는 끔찍했지만, 편의성 측면에서는 놀라운 것이었습니다.
RSC는 이러한 간극을 메우고 양측의 장점을 모두 제공합니다. 렌더링하는 어떤 컴포넌트에서도 필요한 데이터를 즉시 요청할 수 있으며, 브라우저로의 왕복을 기다릴 필요 없이 해당 코드가 서버에서 실행되도록 할 수 있습니다. 무엇보다도 RSC는 스트리밍, 더 정확히는 비순차적(out-of-order) 스트리밍도 지원합니다. 일부 데이터가 느리게 로드될 경우, 페이지의 나머지 부분을 먼저 보내고, 해당 데이터가 준비되는 대로 서버에서 브라우저로 푸시할 수 있습니다.
어떻게 사용할 수 있나요?
이 글을 작성하는 시점에서 RSC는 주로 Next.js에서만 지원되지만, 미니멀 프레임워크인 Waku에서도 지원합니다. Remix와 TanStack Router도 현재 구현 작업을 진행하고 있으니, 계속 관심을 기울여보시길 바랍니다. 그러면 이제 Next에서는 어떠한 형태로 RSC를 사용하는지 아주 간략하게 소개해 드릴 것이며, 추후 다른 프레임워크에서도 RSC가 지원될 때 이를 참고해 보시길 바라겠습니다. 구현 방식은 약간 다르더라도, 아이디어는 동일할 것이기 때문입니다.
Next에서 새로운 "app 디렉토리" (실제로 "app"이라는 폴더로 여러 경로를 정의합니다)를 사용할 때, 페이지는 기본적으로 RSC입니다. 이러한 페이지에서 가져오는 모든 컴포넌트들은 물론, 해당 컴포넌트에서 가져오는 컴포넌트들 역시 RSC입니다. 서버 컴포넌트에서 "클라이언트 컴포넌트"로 전환하려면, 컴포넌트 상단에 "use client" 지시문을 추가하면 됩니다. 그러면 해당 컴포넌트와 해당 컴포넌트가 가져오는 모든 것들이 클라이언트 컴포넌트가 됩니다. 자세한 내용은 Next 문서를 확인하세요.
리액트 서버 컴포넌트는 어떻게 동작하나요?
리액트 서버 컴포넌트는 일반적인 리액트 컴포넌트와 비슷하지만, 몇 가지 차이점이 존재합니다. 먼저, 비동기 함수로 작성될 수 있습니다. 컴포넌트 내에서 바로 비동기 작업을 기다릴 수 있다는 점은 데이터 요청에 매우 적합합니다. 참고로, 비동기 클라이언트 컴포넌트가 곧 React에 도입될 예정이므로 이 차이가 오래 가지는 않을 것입니다. 또 다른 큰 차이점은, 컴포넌트가 오직 서버에서만 실행된다는 것입니다. 클라이언트 컴포넌트(즉, 일반 컴포넌트)는 서버에서 실행된 후 클라이언트에서 다시 실행되면서 "수화(hydrate)"됩니다. 이는 그동안 Next나 Remix와 같은 프레임워크가 작동해 온 방식이었습니다. 하지만 서버 컴포넌트는 서버에서만 실행됩니다.
재차 언급하지만, 서버 컴포넌트는 서버에서만 실행되기 때문에 수화가 이루어지지 않습니다. 이는 데이터베이스에 직접 연결한다거나 서버 전용 API를 사용하는 등의 작업을 수행할 수 있음을 의미합니다. 하지만 effects나 state를 사용할 수 없고, 이벤트 핸들러를 설정한다거나 localStorage 같은 브라우저 전용 API를 사용할 수 없는 등 RSC에서는 할 수 없는 것들이 많다는 것을 뜻하기도 합니다. 이러한 규칙들 중 하나라도 위반한다면 에러가 발생합니다.
RSC에 대한 더 자세한 소개는 Next의 app 디렉토리 문서나, 이 글을 읽는 시점에 따라 Remix 또는 TanStack Router의 문서를 참고해 보시기 바랍니다. 이 글의 길이를 적절한 수준으로 유지하기 위해, 상세한 내용은 문서에 남겨두고 여기서는 RSC를 어떻게 사용하는지 살펴보겠습니다.
RSC를 사용하여 아주 기본적인 개념 증명(proof of concept) 데모 앱을 만들고, 데이터 변경(mutations) 작업이 어떻게 동작하는지와 몇몇 한계점을 살펴보겠습니다. 그런 다음 동일한 앱(마찬가지로 RSC를 사용함)을 가지고 react-query를 사용해 보면서 어떻게 보이는지 확인해보겠습니다.
데모 앱
이전에 했던 것처럼, 도서를 검색하고 제목을 업데이트하는 아주 기본적이고 못생긴 웹 페이지를 만들어 보겠습니다. 이 페이지에는 이론적으로 도서에 적용할 수 있을 다양한 주제와 태그 같은 다른 데이터들도 표시됩니다(데모가 아니라, 실제 웹 앱이었다면 있었을).
핵심은 RSC와 react-query가 어떻게 동작하는지 보여주는 것이지, 유용하거나 화려한 페이지를 만드려는 것은 아니므로 기대치는 낮춰주시고🙂, 다음의 예시를 살펴보겠습니다:

이 페이지에는 검색어를 URL에 입력함으로써 노출되는 도서들을 필터할 수 있는 검색창이 존재합니다. 또한 각 도서에는 제목을 업데이트할 수 있는 입력 필드도 포함되어 있습니다. 상단의 내비게이션 링크는 RSC와 RSC + react-query 버전을 구분하기 위한 것입니다. 사용자 입장에서 볼 수 있는 페이지의 형태와 동작은 동일하지만 구현은 다른데, 이에 대해 자세히 살펴보겠습니다.
데이터는 모두 정적이지만, 도서들은 SQLite 데이터베이스에 저장되므로 데이터를 업데이트할 수 있습니다. SQLite 데이터베이스의 바이너리는 해당 저장소에 있어야 하지만, 언제든지 npm run create-db를 실행하여 다시 생성할 수 있습니다(그리고 업데이트한 내용을 초기화할 수 있습니다).
그럼 시작해 보겠습니다.
캐싱에 대한 참고 사항
이 글을 작성하는 시점에서, Next는 근본적으로 완전히 다른 새로운 버전의 캐싱 API를 곧 릴리즈할 예정입니다. 따라서 이 글에서는 이에 대한 내용은 다루지 않을 것입니다. 데모에서는 모든 캐싱을 비활성화했습니다. 각 페이지 또는 API 엔드포인트에 대한 요청은 항상 서버에서 새로 실행됩니다. 클라이언트 캐시는 계속 작동하므로, 두 페이지를 클릭하면 Next에서 방금 보았던 내용을 캐시하고 클라이언트에서 표시합니다. 하지만 페이지를 새로고침하는 경우에는 항상 서버에서 모든 것을 다시 생성합니다.
데이터 로드하기
api 폴더 내에는 데이터를 로드하고 도서 정보를 업데이트하는 API 엔드포인트가 있습니다. 이러한 엔드포인트들은 정적인 데이터를 로드하거나 SQLite에서 간단한 쿼리를 실행하기 때문에, 인위적인 몇 백 ms의 지연을 추가했습니다. 또한 이러한 데이터에 대한 콘솔 로깅이 있으므로, 언제 어떤 것이 로드되는지 확인할 수 있습니다. 이는 잠시 후에 유용할 것입니다.
아래는 터미널 콘솔에서 RSC 또는 RSC + react-query 버전에서 통상적인 페이지 로드시 표시되는 내용입니다.
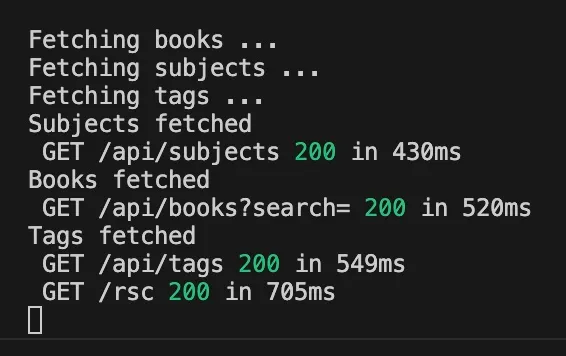
RSC 버전을 살펴보겠습니다.
RSC 버전
export default function RSC(props: { searchParams: any }) {
const search = props.searchParams.search || "";
return (
<section className="p-5">
<h1 className="text-lg leading-none font-bold">Books page in RSC</h1>
<Suspense fallback={<h1>Loading...</h1>}>
<div className="flex flex-col gap-2 p-5">
<BookSearchForm />
<div className="flex">
<div className="flex-[2] min-w-0">
<Books search={search} />
</div>
<div className="flex-1 flex flex-col gap-8">
<Subjects />
<Tags />
</div>
</div>
</div>
</Suspense>
</section>
);
}간단한 페이지 헤더가 있습니다. 그리고 Suspense 경계가 보입니다. 이는 Next 및 RSC에서 비순차적 스트리밍이 동작하는 방식을 나타냅니다. Suspense 경계 상단의 모든 것들은 즉시 렌더링되고, 하위의 여러 컴포넌트의 데이터들은 로딩이 완료될 때까지 Loading... 메시지가 표시됩니다. React는 대기된(awaited) 내용을 기반으로 대기(pending) 상태를 파악합니다. Books, Subjects 및 Tags 컴포넌트들에는 모두 내부에서 대기 중인 fetch들이 있습니다. 이 중 하나를 잠시 살펴보겠지만, 그 전에 먼저 세 개의 서로 다른 컴포넌트가 모두 데이터를 요청하더라도 React는 이를 병렬로 실행한다는 점에 주목하시기 바랍니다. 컴포넌트 트리의 형제 노드들은 데이터를 병렬로 로드할 수 있습니다.
하지만 부모/자식 컴포넌트 둘 다 데이터를 로드하는 경우, 부모 컴포넌트가 로드를 완료될 때까지 자식 컴포넌트는 데이터 로드를 시작하지 않습니다(할 수도 없습니다). 자식의 데이터가 부모가 로드하는 데이터에 의존한다면 불가피한 문제이겠지만(백엔드를 수정해야 합니다), 데이터가 서로 의존하지 않는다면 컴포넌트 트리의 상위로 올려 데이터를 로드한 다음 아래로 전달하여 워터폴을 해결할 수 있습니다.
데이터 로딩
Books 컴포넌트를 보겠습니다.
import { FC } from "react";
import { BooksList } from "../components/BooksList";
import { BookEdit } from "../components/BookEditRSC";
export const Books: FC<{ search: string }> = async ({ search }) => {
const booksResp = await fetch(`http://localhost:3000/api/books?search=${search}`, {
next: {
tags: ["books-query"],
},
});
const { books } = await booksResp.json();
return (
<div>
<BooksList books={books} BookEdit={BookEdit} />
</div>
);
};컴포넌트에서 바로 데이터를 가져와서 기다립니다! RSC 이전에는 전혀 불가능한 것이었습니다. 그런 다음 이를 BooksList 컴포넌트로 전달합니다. 그리고 두 버전 모두에서 기본 BookList 컴포넌트를 재사용할 수 있도록 분리했습니다. 전달하는 BookEdit prop은 제목을 수정하는 텍스트 박스를 렌더링하고 업데이트를 수행하는 React 컴포넌트입니다. 이는 RSC와 react-query 버전 간에 차이가 발생하는 부분입니다. 이에 대해서는 잠시 후에 자세히 설명하겠습니다.
fetch에서의 next 프로퍼티는 Next에 특화된 것으로, 곧 데이터를 무효화하는 데 사용될 것입니다. 경험 많은 Next 개발자들은 여기서 문제가 있을 수 있다는 것을 알아챌 수 있을 것입니다. 곧 그 문제에 대해 다룰 것입니다.
데이터를 로드했습니다. 이제 무엇을 해야 할까요?
데이터를 로드하고 렌더링하는 세 개의 서로 다른 RSC가 있는 페이지가 있습니다. 이제 무엇을 해야 할까요? 페이지에 정적인 콘텐츠만 존재하는 경우였다면 더 할 것이 없었을 것입니다. 데이터를 로드했고, 표시했습니다. 이것이 여러분의 사례였다면, 완료된 것입니다. RSC는 완벽하게 적합했던 것이고, 이 글의 나머지 부분들은 필요하지 않았을 것입니다.
하지만 사용자가 데이터와 상호 작용하고, 데이터를 업데이트할 수 있도록 하려면 어떻게 해야 할까요?
서버 액션으로 데이터 업데이트하기
RSC로 데이터를 변경하려면 서버 액션이라는 것을 사용합니다. 자세한 내용은 문서에서 확인하시기 바라며, 서버 액션이란 아래와 같습니다.
"use server";
import { revalidateTag } from "next/cache";
export const saveBook = async (id: number, title: string) => {
await fetch("http://localhost:3000/api/books/update", {
method: "POST",
body: JSON.stringify({
id,
title,
}),
});
revalidateTag("books-query");
};상단의 "use server" 지시문에 주목하세요. 이는 내보내는 함수가 서버 액션이라는 것을 의미합니다. saveBook은 id와 title을 가져오고, 엔드포인트를 호출하여 SQLite에서 도서 정보를 업데이트한 다음, 이전의 fetch에서 전달했었던 tag와 동일한 값으로 revalidateTag를 호출합니다.
실제로는 books/update 엔드포인트가 필요하지 않을 것입니다. 서버 액션에서 작업을 직접 수행할 것이기 때문입니다. 그러나 나중에 서버 액션 없이 데이터를 업데이트할 때 이 엔드포인트를 재사용할 것이므로, 이 코드 샘플을 깨끗하게 유지하는 것이 좋습니다. books/update 엔드포인트는 SQLite를 열고 UPDATE를 실행합니다.
RSC와 함께 사용하는 BookEdit 컴포넌트를 살펴보겠습니다:
"use client";
import { FC, useRef, useTransition } from "react";
import { saveBook } from "../serverActions";
import { BookEditProps } from "../types";
export const BookEdit: FC<BookEditProps> = (props) => {
const { book } = props;
const titleRef = useRef<HTMLInputElement>(null);
const [saving, startSaving] = useTransition();
function doSave() {
startSaving(async () => {
await saveBook(book.id, titleRef.current!.value);
});
}
return (
<div className="flex gap-2">
<input className="border rounded border-gray-600 p-1" ref={titleRef} defaultValue={book.title} />
<button className="rounded border border-gray-600 p-1 bg-blue-300" disabled={saving} onClick={doSave}>
{saving ? "Saving..." : "Save"}
</button>
</div>
);
};이것은 클라이언트 컴포넌트입니다. 서버 액션을 가져온 다음 버튼의 이벤트 핸들러에서 호출하고, 트랜지션으로 감싸서 상태를 저장할 수 있도록 합니다.
잠시 멈추고 이것이 얼마나 급진적인지, 그리고 React와 Next가 내부에서 무엇을 하고 있는지 고민해 보세요. 우리가 한 일은 바닐라 함수를 만드는 것뿐이었습니다. 그런 다음 그 함수를 가져와서 버튼의 이벤트 핸들러에서 호출했습니다. 그러나 내부에서는 우리를 위해 합성된 엔드포인트로 네트워크 요청이 전송됩니다. 그런 다음 revalidateTag는 변경된 내용을 Next에 알려주고, RSC가 다시 실행되면서 데이터를 다시 요청하고 업데이트된 마크업을 내려주도록 합니다.
뿐만 아니라, 이 모든 것은 서버를 통해 한 번의 왕복으로 이루어집니다.
이는 놀라운 엔지니어링 성취이며 또한 유용합니다! 도서 제목 중 하나를 업데이트하고 저장을 클릭하면, 잠시 후 업데이트된 데이터가 표시됩니다(로컬 SQLite 인스턴스에서만 업데이트하므로 인위적인 지연이 있습니다).

문제는 무엇일까요?
이는 사실이라고 하기엔 너무 좋아 보입니다. 그렇다면 문제는 무엇일까요? 도서 정보를 업데이트할 때 터미널에 무엇이 표시되는지 보겠습니다:
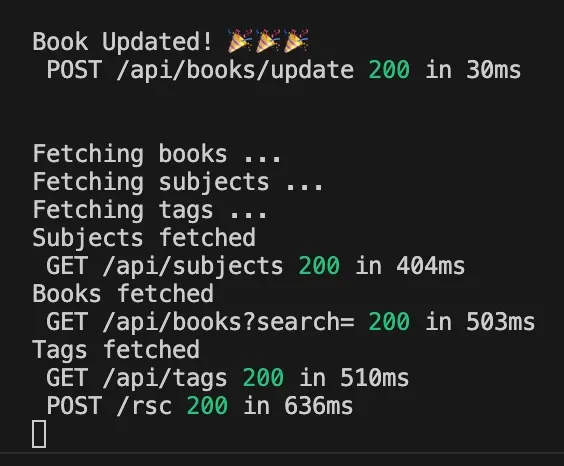
왜 모든 데이터가 다시 로드되었을까요? 우리는 subjects나 tags가 아닌, books에 대해서만 revalidateTag를 호출했습니다. 문제는 revalidateTag가 Next에게 무엇을 다시 로드할지를 알려주는 것이 아니라, 캐시에서 제거할 것을 알려주기 때문입니다. 즉, revalidateTag를 호출하면 Next는 현재 페이지의 모든 내용을 다시 로드해야 합니다. 이는 실제로 어떤 일이 일어나는지를 생각해 보면 이해가 됩니다. 서버 컴포넌트는 상태를 가지지 않습니다. 서버에서 실행되지만, 서버에 상주하지는 않습니다. 요청이 서버에서 실행되고, RSC가 렌더링하고, 마크업을 내려주는 것이 전부입니다. 컴포넌트 트리는 서버에서 무한정 살아 있지 않습니다. 그렇게 되면 서버의 확장성이 떨어질 것입니다!
그렇다면 이 문제를 어떻게 해결할 수 있을까요? 이와 같은 사례의 경우에는 캐싱을 비활성화하지 않는 것이 해결책입니다. 현재 이 글을 읽는 시점에서, 어떤 형태로든 Next의 캐싱 메커니즘에 의존하고 있을 것입니다. 각각의 데이터를 서로 다른 태그로 캐시하고, 방금 업데이트한 데이터와 관련된 태그를 무효화하면 됩니다.
이렇게 하면 전체 RSC 트리는 여전히 다시 렌더링되겠지만, 캐시된 데이터에 대한 요청은 빠르게 실행될 것입니다. 개인적으로 캐싱은 필요에 따라 추가하는 성능 최적화이지, 느린 업데이트를 회피하기 위한 필수 요소가 되어서는 안 된다고 생각합니다.
안타깝게도 서버 액션에는 또 다른 문제가 있는데, 바로 순차적으로 실행된다는 점입니다. 한 번에 하나의 서버 액션만 실행될 수 있으며, 이 제약 조건을 위반하려고 하면 대기열에 들어가게 될 것입니다.
정말 믿을 수 없는 이야기처럼 들리지만, 이는 사실입니다. 인위적으로 업데이트 속도를 극도로 느리게 만든 다음, 5개의 저장 버튼을 빠르게 클릭하면 네트워크 탭에 끔찍한 현상이 나타납니다. 업데이트 엔드포인트에서의 극단적인 지연이 부당하다고 느껴진다면, 네트워크가 빠르거나 안정적일 것이라고 절대 가정해서는 안 된다는 점을 기억하세요. 종종 느린 네트워크 요청은 불가피하며, 이러한 상황에서 서버 액션은 최악의 상황을 초래할 것입니다.

이는 이미 알려진 문제이며, 언젠가는 해결될 것으로 보입니다. 하지만 캐싱 없이 다시 로드되는 문제는 Next의 app 디렉토리의 설계 디자인상 피할 수 없는 문제입니다.
명확히 말씀드리자면, 이러한 한계에도 불구하고 서버 액션은 여전히 탁월합니다(일부 사용 사례의 경우). form과 submit 버튼이 있는 웹 페이지의 경우 서버 액션은 여전히 매우 유용합니다. form이 여러 데이터 소스에 의존하지 않는다는 가정 하에, 이러한 제한은 문제가 되지 않습니다. 실제로 서버 액션은 form과 특히 잘 어울립니다. Next에서는 form의 "action"을 서버 액션으로 직접 설정할 수도 있습니다. 자세한 내용은 문서와 관련 훅(useFormStatus hook)을 참고해 보세요.
다시 앱으로 돌아와 보겠습니다. 우리는 단일 form과 데이터 소스가 없는 페이지를 가지고 있는 상황이 아닙니다. 많은 데이터 소스가 있는 페이지에 작은 form들이 많이 있습니다. 이런 상황에서는 서버 액션이 제대로 동작할 수 없으므로 대안을 살펴보겠습니다.
react-query
React Query는 React 생태계에서 가장 성숙하고 잘 관리된 데이터 관리 라이브러리일 것입니다. 당연히 RSC와도 잘 작동합니다.
react-query를 사용하려면 두 개의 패키지를 설치해야 합니다: npm i @tanstack/react-query @tanstack/react-query-next-experimental. 이름에 "experimental"이 포함돼 있다고 겁먹지 마세요. 이미 출시된 지 꽤 오래되었고, 잘 작동합니다.
Providers 컴포넌트를 만들고, 루트 레이아웃에서 렌더링하겠습니다.
"use client";
import { QueryClient, QueryClientProvider } from "@tanstack/react-query";
import { ReactQueryStreamedHydration } from "@tanstack/react-query-next-experimental";
import { FC, PropsWithChildren, useEffect, useState } from "react";
export const Providers: FC<PropsWithChildren<{}>> = ({ children }) => {
const [queryClient] = useState(() => new QueryClient());
return (
<QueryClientProvider client={queryClient}>
<ReactQueryStreamedHydration>{children}</ReactQueryStreamedHydration>
</QueryClientProvider>
);
};이제 준비되었습니다.
react-query로 데이터 로드하기
간단히 말하자면 클라이언트 컴포넌트 내부에서 useSuspenseQuery 훅을 사용할 것입니다. 코드를 살펴보겠습니다. 다음은 react-query 버전의 Books 컴포넌트입니다.
"use client";
import { FC } from "react";
import { useSuspenseQuery } from "@tanstack/react-query";
import { BooksList } from "../components/BooksList";
import { BookEdit } from "../components/BookEditReactQuery";
import { useSearchParams } from "next/navigation";
export const Books: FC<{}> = () => {
const params = useSearchParams();
const search = params.get("search") ?? "";
const { data } = useSuspenseQuery({
queryKey: ["books-query", search],
queryFn: async () => {
const booksResp = await fetch(`http://localhost:3000/api/books?search=${search}`);
const { books } = await booksResp.json();
return { books };
},
});
const { books } = data;
return (
<div>
<BooksList books={books} BookEdit={BookEdit} />
</div>
);
};"use client" 지시어에 속지 마세요. 이 컴포넌트는 여전히 서버에서 렌더링되며, 초기 페이지 로드 중에 서버에서 데이터를 가져옵니다.
URL이 변경되면 useSearchParams 결과가 변경되고, 브라우저에서 useSuspenseQuery 훅에 의해 새로운 쿼리가 실행됩니다. 이렇게 하면 일반적으로 페이지가 일시 중단되지만, startTransition에서 router.push 호출을 래핑하여 기존 콘텐츠가 화면에 유지되도록 합니다. 자세한 내용은 저장소를 확인하세요.
react-query로 데이터 업데이트하기
도서 정보를 업데이트하기 위한 /books/update가 이미 있습니다. 해당 데이터에 연결된 쿼리를 다시 실행하려면 react-query에게 어떻게 지시해야 할까요? 그 답은 바로 queryClient.invalidateQueries API입니다. react-query의 BookEdit 컴포넌트를 살펴봅시다.
"use client";
import { FC, useRef, useTransition } from "react";
import { BookEditProps } from "../types";
import { useQueryClient } from "@tanstack/react-query";
export const BookEdit: FC<BookEditProps> = (props) => {
const { book } = props;
const titleRef = useRef<HTMLInputElement>(null);
const queryClient = useQueryClient();
const [saving, startSaving] = useTransition();
const saveBook = async (id: number, newTitle: string) => {
startSaving(async () => {
await fetch("/api/books/update", {
method: "POST",
body: JSON.stringify({
id,
title: newTitle,
}),
});
await queryClient.invalidateQueries({ queryKey: ["books-query"] });
});
};
return (
<div className="flex gap-2">
<input className="border rounded border-gray-600 p-1" ref={titleRef} defaultValue={book.title} />
<button className="rounded border border-gray-600 p-1 bg-blue-300" disabled={saving} onClick={() => saveBook(book.id, titleRef.current!.value)}>
{saving ? "Saving..." : "Save"}
</button>
</div>
);
};saveBook 함수는 이전과 동일한 도서 정보 업데이트 엔드포인트를 호출합니다. 그런 다음 쿼리 키의 첫 번째 부분인 books-query를 사용하여 invalidateQueries를 호출합니다. 쿼리 훅에서 사용한 실제 queryKey는 queryKey: ["books-query", search] 였다는 점을 기억하시길 바랍니다. 해당 키의 첫 번째 부분으로 무효화 쿼리를 호출하면 해당 키로 시작하는 모든 쿼리가 무효화되고 페이지에 남아 있는 모든 쿼리가 즉시 다시 실행됩니다. 따라서 빈 검색으로 시작한 다음 X, Y, Z를 검색하고 업데이트한 경우, 이 코드는 해당 항목의 캐시를 모두 지운 다음 즉시 Z 쿼리를 다시 실행하고 UI를 업데이트합니다.
그리고 잘 동작합니다.
문제는 무엇일까요?
여기서 단점은 브라우저에서 서버까지 두 번의 왕복이 필요하다는 것입니다. 첫 번째 왕복은 도서 정보를 업데이트하고, 이 작업이 완료되면 브라우저에서 invalidateQueries를 호출하여 react-query가 업데이트된 데이터에 대한 새로운 네트워크 요청을 보냅니다.
이는 의외로 작은 대가입니다. 서버 액션을 사용하면 revalidateTag를 호출할 때 전체 컴포넌트 트리가 다시 렌더링되고, 더 나아가 모든 다양한 데이터를 다시 요청하게 된다는 점을 기억해야 합니다. 모든 것이 (서버에) 적절하게 캐시되어 있지 않다면, 이 한 번의 왕복이 react-query가 필요로 하는 두 번의 왕복 시간보다도 더 오래 걸릴 수 있습니다. 이는 경험을 토대로 한 말입니다. 최근에 친구/창업자의 금융 대시보드 앱 구축을 도운 적이 있습니다. 지금과 같이 react-query를 설정하고 데이터를 업데이트하는 서버 액션도 구현했습니다. 그리고 동일한 데이터가 RSC에서 한 번, 그리고 나머지 한 번은 클라이언트 컴포넌트의 useSuspenseQuery 훅에서 인접하게 두 번 렌더링되었습니다. 사실 서버 액션이 먼저 업데이트될 것이라고 확신했었는데, react-query가 승리하는 것을 보고 충격을 받았습니다. 이유를 깨닫기 전까지는 제가 무언가를 잘못한 줄 알았습니다(그리고 서둘러 서버 액션 작업을 롤백했습니다).
하드 모드로 플레이 중
불쾌한 결함이 한 가지 숨어 있습니다. 이를 찾고, 고쳐보겠습니다.
react-query를 사용할 때 라우팅 고치기
도서를 검색할 때, URL에 쿼리스트링을 추가하는 router.push를 호출한다는 점을 기억하세요. 이는 useSearchParams()를 업데이트하고, 이로 인해 react-query가 새로운 데이터를 쿼리하게 됩니다. 이때 네트워크 탭을 살펴봅시다.

books 엔드포인트를 호출하기 전에 무언가 다른 일들이 발생하는 것으로 보입니다. 이는 router.push를 호출했을 때 발생한 이동(navigation)입니다. Next는 기본적으로 새 페이지로 렌더링하고 있습니다. 새로운 쿼리스트링이 있다는 점을 제외하면, 이는 이미 존재하는 페이지입니다. Next가 이 작업을 수행해야 한다고 가정하는 것이 옳겠지만, 실제로는 react-query가 데이터를 처리하고 있습니다. Next는 새 페이지를 렌더링할 필요도 없고, 원하지도 않습니다. 그저 URL이 업데이트되어 react-query가 새로운 데이터를 요청할 수 있기를 원합니다. 새 페이지로 두 번 이동하는 이유가 궁금하시다면, 저 역시 그렇다고 말씀드리고 싶습니다. 분명히 RSC 식별자가 변경되고 있지만, 그 이유는 모르겠습니다. 아는 분이 계시다면 제게 연락해 주세요.
Next는 이에 대한 해결책이 없습니다.
Next가 가장 해결책에 근접할 수 있는 방법은 window.history.pushState를 사용할 수 있도록 하는 것입니다. 그러면 이전 버전의 Next에서 사용되던 얕은 라우팅(shallow routing)과 유사한 클라이언트 측 URL 업데이트가 트리거됩니다. 이는 실제로도 잘 동작하지만, 어떤 이유에서인지 트랜지션과 통합되어 있지 않습니다. 따라서 이 호출이 발생하고, useSuspenseQuery 훅이 업데이트되면 현재 UI가 일시 중지되고 가장 인접한 Suspense 경계가 fallback을 표시합니다. 이는 정말 끔찍한 UI입니다. 이 버그를 여기에 신고했으니 곧 수정될 것을 기대합니다.
Next에는 해결책이 없을 수도 있지만, react-query에는 있습니다. 생각해 보면 우리는 이미 어떤 쿼리를 실행해야 하는지 알고 있으며, 단지 Next가 변경되지 않는 RSC 페이지로 이동을 완료하기를 기다리고 있을 뿐입니다. 그렇다면 이 새로운 엔드포인트 요청을 미리 가져와서 Next가 새로운(변경되지 않은) 페이지 렌더링을 완료할 때 이미 실행되어 있도록 하면 어떨까요? react-query에는 이를 위한 API가 있으므로 가능합니다. 방법을 살펴보겠습니다.
react-query의 검색 form 컴포넌트를 살펴보겠습니다. 특히 새로운 이동을 트리거하는 부분에 주목해 보겠습니다:
startTransition(() => {
const search = searchParams.get("search") ?? "";
queryClient.prefetchQuery({
queryKey: ["books-query", search],
queryFn: async () => {
const booksResp = await fetch(`http://localhost:3000/api/books?search=${search}`);
const { books } = await booksResp.json();
return { books };
},
});
router.push(currentPath + (queryString ? "?" : "") + queryString);
});queryClient.prefetchQuery 호출입니다. prefetchQuery는 useSuspenseQuery와 동일한 옵션을 사용하여 해당 쿼리를 실행합니다. 이후 Next가 이를 완료하고 react-query가 동일한 쿼리를 실행하려고 시도하면, 요청이 이미 진행 중이라는 것을 스마트하게 감지하여 활성화된 프로미스에 끼어들어 그 결과를 사용합니다.
이제 네트워크 차트는 다음과 같습니다:

이제 엔드포인트 요청을 지연시키는 것은 없습니다. 그리고 모든 데이터 로딩이 react-query에서 이루어지기 때문에, RSC 페이지로의 이동(또는 두 번의 이동)은 매우 매우 빨라야 합니다.
중복 제거하기
prefetch와 쿼리 자체 사이의 중복이 지저분하고 취약하다고 생각하신다면, 그 말이 맞습니다. 그러니 그냥 헬퍼 함수로 옮기면 됩니다. 실제 앱에서는 이 보일러플레이트를 다음과 같은 함수로 옮길 것입니다:
export const makeBooksSearchQuery = (search: string) => {
return {
queryKey: ["books-query", search ?? ""],
queryFn: async () => {
const booksResp = await fetch(`http://localhost:3000/api/books?search=${search}`);
const { books } = await booksResp.json();
return { books };
},
};
};그런 다음 사용하세요:
const { data } = useSuspenseQuery(makeBooksSearchQuery(search));필요에 따라:
queryClient.prefetchQuery(makeBooksSearchQuery(search));하지만 이 데모에서는 중복과 단순함을 선택했습니다.
계속하기 전에, 잠시 시간을 내어 이 모든 것들이 데이터 로딩이 URL과 연결되어 있었기 때문에 필요했다는 점을 짚고 넘어가겠습니다. 클라이언트의 상태를 설정하는 버튼을 클릭하고 새 데이터 요청을 트리거하기만 하면, 이러한 문제는 전혀 발생하지 않았을 것입니다. Next는 어느 곳으로도 라우팅하지 않고, 클라이언트 상태 업데이트가 새로운 react-query를 트리거했을 것입니다.
번들 사이즈는 어떨까요?
react-query를 구현할 때, "use client" 지시문을 추가하여 Books 컴포넌트를 클라이언트 컴포넌트로 변경했었습니다. 이로 인해 번들 사이즈가 증가하지 않을까 궁금하시다면, 맞습니다. RSC 버전에서는 해당 컴포넌트가 서버에서만 실행되었습니다. 클라이언트 컴포넌트로 변경되면 이제는 양 측에서 모두 실행되어야 하므로, 번들 사이즈가 약간 증가할 것입니다.
솔직히 이를 우려할 필요는 없습니다. 특히 대화형이고 업데이트되는 다양한 데이터 소스들이 많은 앱의 경우라면 그렇습니다. 이번 데모에서는 단 하나의 뮤테이션만 존재했지만, 이는 어디까지나 데모일 뿐입니다. 실제로 이 앱을 구축한다면 많은 뮤테이션 지점들이 있을 것이고, 각각에는 무효화가 필요한 쿼리가 잠재적으로 여러 개 있을 것입니다.
기술적으로 양 측의 장점을 모두 취하는 것도 가능합니다. RSC에서 데이터를 로드한 다음 initialData prop을 통해 해당 데이터를 일반 useQuery 훅으로 전달할 수 있습니다. 자세한 내용은 문서에서 확인하시기 바랍니다. 그러나 솔직히 그만한 가치가 있다고 생각하지는 않습니다. 이제 데이터 로드(fetch 호출)를 두 곳에서 정의하거나 동형의 fetch 헬퍼 함수를 수동으로 빌드하여 양측 간에 공유해야 합니다. 그리고 실제 데이터 로딩이 RSC에서 발생하고 같은 페이지로 다시 이동하면(가령, 쿼리스트링의 경우) 해당 쿼리가 다시 실행되는데, 클라이언트에서는 이미 react-query가 해당 쿼리를 실행하고 있을 때입니다. 이 문제를 해결하려면 앞서 설명한 것처럼 window.history.pushState만 사용해야 합니다. useQuery 훅은 중단되지 않으므로, 이러한 URL 변경에 대한 트랜지션은 필요하지 않습니다. pushState는 콘텐츠를 중단시키지 않으므로 좋지만, 모든 로딩 상태를 수동으로 추적해야 합니다. UI를 표시하기 전에 로드하려는 데이터가 세 개 있는 경우, (위에서 한 것처럼) 이 세 가지의 로딩 상태를 수동으로 추적해야 합니다. 잘 동작은 하겠지만 그 복잡성을 감당할 만한 가치가 있을지는 의문입니다. 매우 미미한 번들 사이즈의 증가를 감수하세요.
그냥 클라이언트 컴포넌트를 사용하고, react-query가 useSuspenseHook으로 복잡성을 제거하시길 바랍니다.
마무리
긴 글이었습니다만 도움이 되셨기를 바랍니다. Next의 app 디렉토리는 서버에 데이터를 요청하고, 렌더링하고, 그 데이터에서 컴포넌트 콘텐츠를 스트리밍할 수도 있게 해주는 놀라운 인프라로, 이 모든 것을 익숙한 단일 React 컴포넌트 모델을 사용하여 수행할 수 있도록 합니다.
몇 가지 올바르게 설정해야 할 사항도 있지만, 구축하려는 앱의 유형에 따라 react-query가 많은 것을 단순화할 수 있습니다.
