가시다(gasida) 님이 진행하는 AEWS(Amazon EKS Workshop Study) 3기 과정으로 학습한 내용을 정리 또는 실습한 내용을 정리한 게시글입니다. 11주차는 최영락님께서 ML Infra(GPU) on EKS 주제로 강의를 해주셨습니다. GenAI with Inferentia & FSx Workshop 환경을 제공해 주어 실습한 내용을 정리하였습니다.
1. GenAI with Inferentia & FSx Workshop
1.1 개요
본 워크숍에서는 vLLM(모델 서빙)과 오픈소스 기반의 파운데이션 모델을 활용하여 Generative AI 기반의 인터랙티브 챗 애플리케이션을 구축합니다. 사용되는 AWS 서비스 스택은 다음과 같습니다:
- Amazon EKS: 오케스트레이션 계층 (Kubernetes 클러스터 관리)
- Amazon FSx for Lustre & Amazon S3: AI 모델과 데이터를 저장
- AWS Inferentia: AI 추론을 위한 고속 컴퓨팅 계층
워크숍을 통해 다음과 같은 내용을 실습하였습니다:
- Amazon EKS, FSx, S3, Inferentia에 구성 요소를 배포 및 설정
- 본인만의 Generative AI 챗 애플리케이션을 구축 및 테스트
- 성능, 확장성, 데이터 계층과의 통합 테스트 수행
- AWS 리전 간 생성된 데이터를 효율적으로 공유하는 방법 학습
이 패턴을 활용해 자신만의 GenAI 및 ML 워크로드를 손쉽게 구축하고 테스트할 수 있는 방법을 익히게 되었습니다.
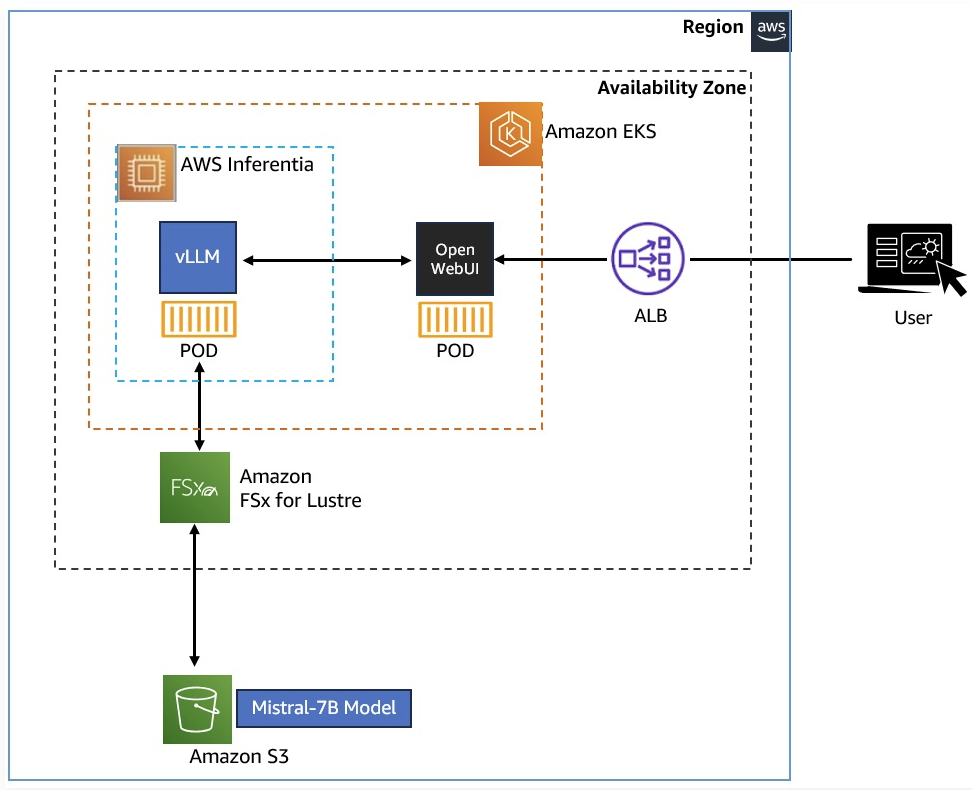
1.2 워크숍 목표 (Workshop Objective)
Amazon EKS 클러스터에 vLLM과 WebUI Pod를 배포하여 Generative AI 챗봇 애플리케이션을 Kubernetes 환경에서 구축
Mistral-7B 모델을 Amazon FSx for Lustre와 Amazon S3를 통해 저장 및 액세스
AWS Inferentia 가속기를 활용하여 AI 추론 워크로드의 성능을 높이기
주요 학습 내용:
- Karpenter를 사용하여 Pod 요청 증가 시 자동으로 EKS 노드를 확장 → 확장성 및 운영 효율성 확보
- Amazon EKS 클러스터에서 AWS Inferentia 가속 노드풀을 구성하여 고성능 AI 애플리케이션 실행
- FSx for Lustre + S3를 사용한 확장 가능하고 빠른 데이터 계층 구성 (모델과 데이터 저장소)
운영 효율성 향상:
- 컨테이너 Pod 간에 동일 모델 데이터를 공유하여 중복 저장 없이 접근
- 리전 간 데이터 공유 및 재해 복구(Disaster Recovery) 시나리오에 대비한 구성
1.3 Generative AI 및 머신러닝
✅ Generative AI와 머신러닝이란?
- Generative AI는 프롬프트(입력)를 기반으로 텍스트, 이미지, 오디오, 코드 등 새로운 콘텐츠를 생성하는 인공지능 기술입니다. 머신러닝(ML)과 함께 비즈니스 혁신에 활발히 활용되고 있습니다.
✅ LLM (Large Language Model) 이란?
- LLM은 대규모 텍스트 데이터를 학습하여 자연어 처리 작업(텍스트 생성, 질의응답, 번역 등)을 수행하는 AI 모델입니다.
- 워크숍에서는 Mistral-7B-Instruct 모델을 사용하며, 이는 70억 개의 파라미터를 가진 오픈소스 LLM으로, 지시어(Instruct)에 따라 다양한 작업 수행이 가능해 챗봇에 적합합니다.
✅ vLLM이란?
- vLLM(Virtual Large Language Model)은 LLM 추론 및 서빙을 위한 오픈소스 프레임워크입니다.
특징:
- OpenAI API와 호환되는 추론 API 제공 → 애플리케이션 연동 쉬움
- 고성능 처리: 지속적인 배치, GPU 최적화(CUDA/HIP), PagedAttention 구조 등
- HuggingFace 모델과의 통합, Neuron/AWS Inferentia, NVIDIA GPU 등 다양한 하드웨어 지원
✅ Amazon EKS에서 Mistral-7B-Instruct 배포
- Amazon EKS 클러스터에서 vLLM Pod를 생성하고, AWS Inferentia 기반의 Inf2 인스턴스에 배포
- Karpenter로 확장 필요 시 자동으로 노드 추가
✅ Amazon EKS란?
- Amazon Elastic Kubernetes Service (EKS)는 Kubernetes를 AWS에서 손쉽게 운영할 수 있게 해주는 완전관리형 서비스입니다.
- GenAI 및 ML 워크로드에 적합한 대규모 컨테이너 오케스트레이션 기능 제공
✅ Inference 서비스 사용법
- Open WebUI 애플리케이션을 배포해, vLLM 기반 OpenAI API와 연결
- 사용자들은 브라우저에서 접속해 채팅 형태로 LLM과 상호작용 가능
✅ 모델과 데이터 저장 및 접근
- 모델은 Amazon S3에 저장되고, Amazon FSx for Lustre를 통해 EKS 내 vLLM 컨테이너가 접근
- FSx for Lustre는 고성능 파일시스템으로, 지연이 짧고 수백 GB/s 처리량을 지원
- S3와 통합되어 대용량 데이터 처리와 공유가 용이
✅ 고속 컴퓨팅을 위한 AWS Inferentia
- Inferentia2 기반 EC2 Inf2 인스턴스는 LLM 같은 복잡한 모델에 최적화
- AWS Neuron SDK를 통해 PyTorch, TensorFlow와 연동해 기존 코드 그대로 Inferentia에서 실행 가능
- 고성능 + 저비용으로 대규모 추론 워크로드 실행에 적합
aws cloud9 update-environment --environment-id ${C9_PID} --managed-credentials-action DISABLE
rm -vf ${HOME}/.aws/credentials
aws sts get-caller-identity
TOKEN=`curl -s -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"`
export AWS_REGION=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/placement/region)
export CLUSTER_NAME=eksworkshop
echo $AWS_REGION
us-west-2
echo $CLUSTER_NAME
eksworkshop
# Update the kube-config file:
aws eks update-kubeconfig --name $CLUSTER_NAME --region $AWS_REGION
# Amazon EKS Cluster 조회
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-0-121-15.us-west-2.compute.internal Ready <none> 33h v1.30.9-eks-5d632ec
ip-10-0-67-80.us-west-2.compute.internal Ready <none> 33h v1.30.9-eks-5d632ec
1.4 실습환경 확인
1.4.1 Amazon EKS 클러스터 자동화 구성
Amazon EKS 클러스터 자동화 구성 – 한국어 요약
이 워크숍에서 사용하는 Amazon EKS 클러스터는 Terraform을 활용하여 자동 생성되었으며, EKS Blueprints for Terraform을 기반으로 구축되었습니다.
✅ Terraform이란?
Terraform은 Infrastructure as Code (IaC) 도구로, AWS 인프라를 코드로 작성하고 관리할 수 있게 해줍니다. 효율적인 인프라 변경 및 버전 관리를 지원합니다.
✅ EKS Blueprints for Terraform이란?
EKS Blueprints는 다음을 가능하게 하는 IaC 템플릿 모음입니다:
EKS 클러스터 구성요소 전체를 코드로 정의 (컨트롤 플레인, 워커 노드, Kubernetes 애드온 등)
운영에 필요한 소프트웨어가 자동으로 포함된 상태로 클러스터 부트스트랩
여러 AWS 계정 및 리전에서 일관된 환경 생성 가능
CI/CD와 연계하여 지속적 배포 자동화에 활용
1.4.2 Karpenter 설치 확인
✅ Karpenter란?
Karpenter는 Kubernetes에서 Pod 수요에 따라 자동으로 노드를 프로비저닝하는 자동 확장 컨트롤러입니다.
Custom Resource Definition(CRD) 기반으로 구성 → Kubernetes API 확장
선언형 구성 원칙을 따르므로 설정이 간단함
본 환경에서는 기본 NodePool CRD가 설정되어 있음
✅ Karpenter 설정 확인 방법
Cloud9 터미널에 아래 명령어 입력:
kubectl -n karpenter get deploy/karpenter -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
meta.helm.sh/release-name: karpenter
meta.helm.sh/release-namespace: karpenter
creationTimestamp: "2025-04-17T01:42:51Z"
generation: 1
labels:
app.kubernetes.io/instance: karpenter
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: karpenter
app.kubernetes.io/version: 1.0.1
helm.sh/chart: karpenter-1.0.1
name: karpenter
namespace: karpenter
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/instance: karpenter
app.kubernetes.io/name: karpenter
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app.kubernetes.io/instance: karpenter
app.kubernetes.io/name: karpenter
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: DoesNotExist
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app.kubernetes.io/instance: karpenter
app.kubernetes.io/name: karpenter
topologyKey: kubernetes.io/hostname
containers:
- env:
- name: KUBERNETES_MIN_VERSION
value: 1.19.0-0
- name: KARPENTER_SERVICE
value: karpenter
- name: WEBHOOK_PORT
value: "8443"
- name: WEBHOOK_METRICS_PORT
value: "8001"
- name: DISABLE_WEBHOOK
value: "false"
- name: LOG_LEVEL
value: info
- name: METRICS_PORT
value: "8080"
- name: HEALTH_PROBE_PORT
value: "8081"
- name: SYSTEM_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MEMORY_LIMIT
valueFrom:
resourceFieldRef:
containerName: controller
divisor: "0"
resource: limits.memory
- name: FEATURE_GATES
value: SpotToSpotConsolidation=false
- name: BATCH_MAX_DURATION
value: 10s
- name: BATCH_IDLE_DURATION
value: 1s
- name: CLUSTER_NAME
value: eksworkshop
- name: CLUSTER_ENDPOINT
value: https://7BB1B863D9B67218B746FF8413AB355E.gr7.us-west-2.eks.amazonaws.com
- name: VM_MEMORY_OVERHEAD_PERCENT
value: "0.075"
- name: INTERRUPTION_QUEUE
value: karpenter-eksworkshop
- name: RESERVED_ENIS
value: "0"
image: public.ecr.aws/karpenter/controller:1.0.1@sha256:fc54495b35dfeac6459ead173dd8452ca5d572d90e559f09536a494d2795abe6
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: http
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
name: controller
ports:
- containerPort: 8080
name: http-metrics
protocol: TCP
- containerPort: 8001
name: webhook-metrics
protocol: TCP
- containerPort: 8443
name: https-webhook
protocol: TCP
- containerPort: 8081
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: http
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
resources: {}
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65532
seccompProfile:
type: RuntimeDefault
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
fsGroup: 65532
serviceAccount: karpenter
serviceAccountName: karpenter
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
topologySpreadConstraints:
- labelSelector:
matchLabels:
app.kubernetes.io/instance: karpenter
app.kubernetes.io/name: karpenter
maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
status:
availableReplicas: 2
conditions:
- lastTransitionTime: "2025-04-17T01:43:11Z"
lastUpdateTime: "2025-04-17T01:43:11Z"
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: "2025-04-17T01:42:51Z"
lastUpdateTime: "2025-04-17T01:43:11Z"
message: ReplicaSet "karpenter-6f4f89f94b" has successfully progressed.
reason: NewReplicaSetAvailable
status: "True"
type: Progressing
observedGeneration: 1
readyReplicas: 2
replicas: 2
updatedReplicas: 2- CLUSTER_ENDPOINT: 신규 노드가 연결할 Kubernetes 클러스터 외부 엔드포인트
- 생략 시 DescribeCluster API를 통해 자동 탐색
- INTERRUPTION_QUEUE: Spot 인스턴스 중단 알림 및 AWS Health 이벤트 처리를 위한 SQS 큐 엔드포인트
- 이 큐는 Terraform Blueprint 생성 시 자동으로 구성됨
✅ Karpenter 실행 상태 확인
- Karpenter 관련 Pod가 최소 2개 이상 실행 중이면 정상적으로 동작 중임을 의미합니다.
kubectl get pods -n karpenter
NAME READY STATUS RESTARTS AGE
karpenter-6f4f89f94b-42cn5 1/1 Running 0 33h
karpenter-6f4f89f94b-sfwsx 1/1 Running 0 33halias kl='kubectl -n karpenter logs -l app.kubernetes.io/name=karpenter --all-containers=true -f --tail=20'
kl
{"level":"ERROR","time":"2025-04-17T01:42:57.914Z","logger":"webhook.ConversionWebhook","message":"Reconcile error","commit":"62a726c","knative.dev/traceid":"46388bac-c5ef-4fee-83dd-f9ef863cc44a","knative.dev/key":"nodeclaims.karpenter.sh","duration":"12.713µs","error":"secret \"karpenter-cert\" is missing \"ca-cert.pem\" key"}
{"level":"INFO","time":"2025-04-17T01:42:57.961Z","logger":"controller","message":"Starting workers","commit":"62a726c","controller":"lease.garbagecollection","controllerGroup":"coordination.k8s.io","controllerKind":"Lease","worker count":10}
{"level":"INFO","time":"2025-04-17T01:42:57.962Z","logger":"controller","message":"Starting workers","commit":"62a726c","controller":"nodepool.readiness","controllerGroup":"karpenter.sh","controllerKind":"NodePool","worker count":10}
{"level":"INFO","time":"2025-04-17T01:42:57.962Z","logger":"controller","message":"Starting workers","commit":"62a726c","controller":"state.daemonset","controllerGroup":"apps","controllerKind":"DaemonSet","worker count":10}
...2. 스토리지 구성 – Amazon FSx for Lustre에 모델 데이터 호스팅
2.1 📌 모듈 개요
이 워크숍에서는 Mistral-7B-Instruct 모델이 Amazon S3 버킷에 저장되어 있으며, 이 S3 버킷은 Amazon FSx for Lustre 파일 시스템과 연결되어 있습니다.
vLLM 컨테이너는 Generative AI 챗봇 애플리케이션을 위해 이 FSx for Lustre 파일 시스템을 사용합니다.
이 모듈에서는 다음을 수행하게 됩니다:
- Amazon FSx for Lustre 인스턴스를 배포하고 Amazon EKS 클러스터와 통합
- Kubernetes의 스토리지 개념 학습 (CSI 드라이버, Persistent Volume, StorageClass, 정적 vs 동적 프로비저닝 등)
이 모듈에서 사용하는 인프라 구성:
- Amazon EKS 클러스터 (EC2 워커 노드 2개 포함)
- Amazon FSx for Lustre 파일 시스템
- Amazon S3 버킷
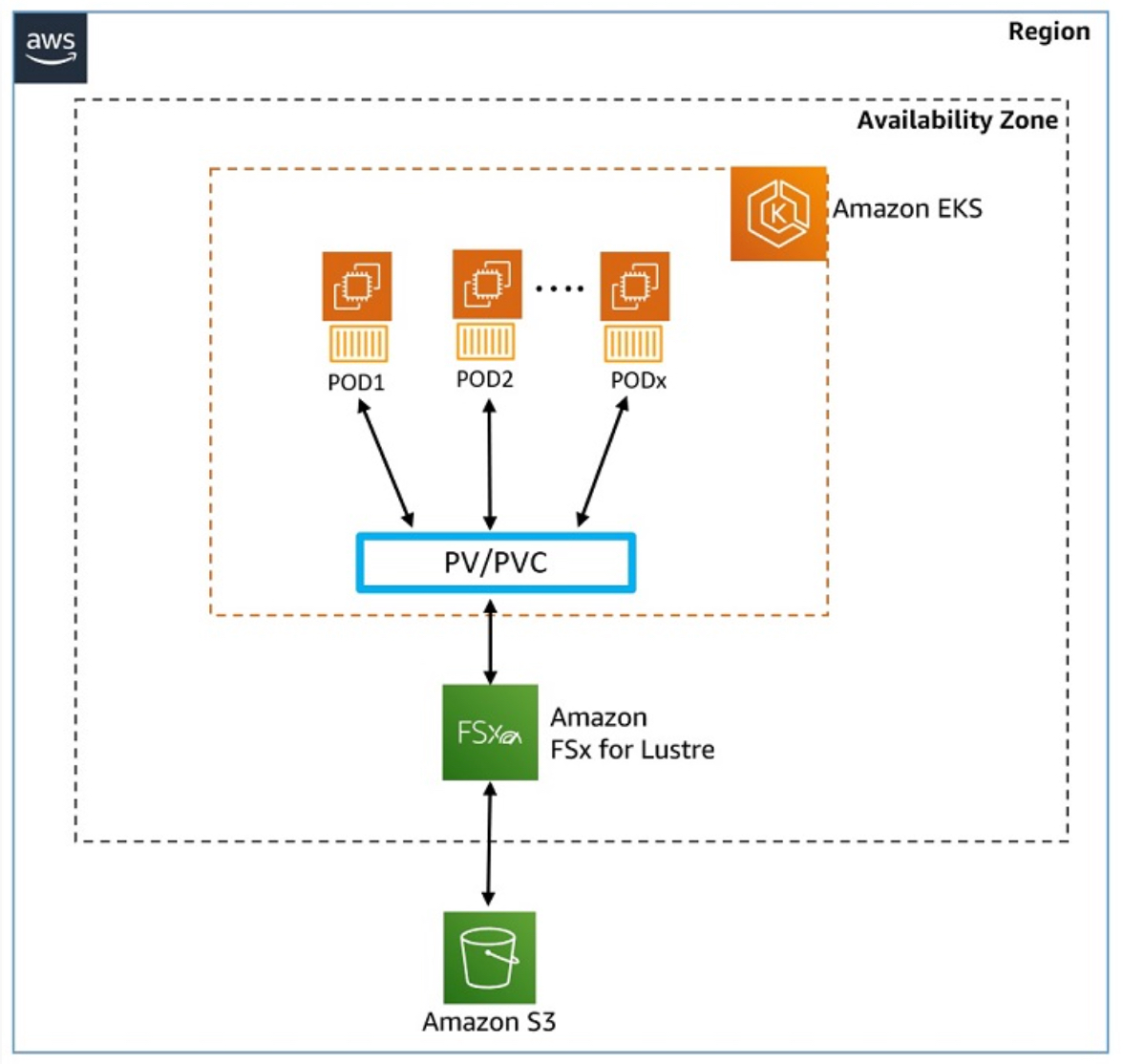
2.2 📁 Amazon FSx for Lustre란?
- 고성능 병렬 파일 시스템을 제공하는 완전관리형 서비스
- 머신러닝, 분석, 고성능 컴퓨팅 등 속도가 중요한 워크로드에 최적
- 서브 밀리초(latency)로 데이터 접근 가능, TB/s급 처리량과 수백만 IOPS 지원
- Amazon S3와 통합되어, S3 객체를 파일처럼 사용할 수 있고, Lustre에서 변경 시 S3로 자동 동기화
2.2.1 📦 Kubernetes 스토리지 개념 및 FSx for Lustre 통합
-
CSI 드라이버 (Container Storage Interface)
→ Kubernetes에서 블록/파일 스토리지를 네이티브하게 관리할 수 있게 해주는 표준 인터페이스
→ FSx for Lustre CSI 드라이버를 사용하면 EKS에서 FSx 스토리지 생명주기 관리 가능 -
StorageClass
→ EKS 관리자가 제공하는 스토리지 유형의 "클래스"를 정의
→ 예: Amazon FSx, Amazon EBS, Amazon EFS 등 다양한 스토리지 백엔드와 연결 가능
→ 백업 정책, 성능 특성 등도 StorageClass로 구분 가능 -
Persistent Volume (PV)
→ 클러스터에 사전 프로비저닝된 스토리지 볼륨
→ Pod의 생명주기와는 별도로 존재하므로 데이터를 지속적으로 공유 및 보존 가능 -
Persistent Volume Claim (PVC)
→ 사용자가 요청하는 스토리지 볼륨
→ 요청 시 크기, 접근 모드(ReadWriteOnce, ReadOnlyMany, ReadWriteMany 등)를 지정 가능
2.2.2 ⚙️ 정적 vs 동적 스토리지 프로비저닝
-
정적 프로비저닝 (Static Provisioning)
- 관리자가 먼저 FSx for Lustre 인스턴스를 생성하고, 해당 인스턴스에 대한 PV를 정의
- 개발자가 PVC를 제출하여 해당 PV를 Pod에서 사용
-
동적 프로비저닝 (Dynamic Provisioning)
- 관리자가 미리 볼륨을 만들 필요 없이, PVC 요청 시 자동으로 FSx 인스턴스와 PV가 생성됨
- 더 유연하고 빠르게 스토리지를 온디맨드 방식으로 프로비저닝 가능
이 모듈을 통해 FSx for Lustre 기반 고성능 스토리지를 Kubernetes 환경에서 직접 연동하고 활용하는 법을 익히게 됩니다.
2.3 CSI 드라이버 배포
이 섹션에서는 Amazon FSx for Lustre용 CSI 드라이버를 EKS 클러스터에 배포하기 위한 절차를 수행합니다. 환경 변수 설정, IAM 정책 및 서비스 계정 생성, 그리고 CSI 드라이버 배포까지 단계별로 진행합니다.
✅ Step 1: 사전 조건 – 환경 변수 설정
Cloud9 터미널에 아래 명령어를 입력하여 AWS 계정 ID를 환경 변수에 저장합니다:
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)⚠️ 참고: AWS에서 제공하는 워크숍의 경우, 보안 그룹(Security Group) 및 S3 버킷은 사전 생성되어 있습니다.
✅ Step 2: IAM 정책 및 서비스 계정 생성
아래 명령어를 실행하여 fsx-csi-driver.json 파일을 생성합니다:
cat << EOF > fsx-csi-driver.json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"iam:CreateServiceLinkedRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy"
],
"Resource":"arn:aws:iam::*:role/aws-service-role/s3.data-source.lustre.fsx.amazonaws.com/*"
},
{
"Action":"iam:CreateServiceLinkedRole",
"Effect":"Allow",
"Resource":"*",
"Condition":{
"StringLike":{
"iam:AWSServiceName":[
"fsx.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:ListBucket",
"fsx:CreateFileSystem",
"fsx:DeleteFileSystem",
"fsx:DescribeFileSystems",
"fsx:TagResource"
],
"Resource":[
"*"
]
}
]
}
EOF✅ Step 3: IAM 정책 생성
aws iam create-policy \
--policy-name Amazon_FSx_Lustre_CSI_Driver \
--policy-document file://fsx-csi-driver.json
{
"Policy": {
"PolicyName": "Amazon_FSx_Lustre_CSI_Driver",
"PolicyId": "ANPASRSOCATZABXDVQADF",
"Arn": "arn:aws:iam::1**********6:policy/Amazon_FSx_Lustre_CSI_Driver",
"Path": "/",
"DefaultVersionId": "v1",
"AttachmentCount": 0,
"PermissionsBoundaryUsageCount": 0,
"IsAttachable": true,
"CreateDate": "2025-04-18T11:37:49+00:00",
"UpdateDate": "2025-04-18T11:37:49+00:00"
}
} ✅ Step 4: Kubernetes 서비스 계정 생성 및 정책 연결
⏳ 약 30~60초간 기다리세요. 출력 결과의 마지막 줄에서 서비스 계정이 생성되었는지 확인할 수 있습니다.
eksctl create iamserviceaccount \
--region $AWS_REGION \
--name fsx-csi-controller-sa \
--namespace kube-system \
--cluster $CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::$ACCOUNT_ID:policy/Amazon_FSx_Lustre_CSI_Driver \
--approve
2025-04-18 11:39:35 [ℹ] 1 iamserviceaccount (kube-system/fsx-csi-controller-sa) was included (based on the include/exclude rules)
2025-04-18 11:39:35 [!] serviceaccounts that exist in Kubernetes will be excluded, use --override-existing-serviceaccounts to override
2025-04-18 11:39:35 [ℹ] 1 task: {
2 sequential sub-tasks: {
create IAM role for serviceaccount "kube-system/fsx-csi-controller-sa",
create serviceaccount "kube-system/fsx-csi-controller-sa",
} }2025-04-18 11:39:35 [ℹ] building iamserviceaccount stack "eksctl-eksworkshop-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa"
2025-04-18 11:39:35 [ℹ] deploying stack "eksctl-eksworkshop-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa"
2025-04-18 11:39:35 [ℹ] waiting for CloudFormation stack "eksctl-eksworkshop-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa"
2025-04-18 11:40:05 [ℹ] waiting for CloudFormation stack "eksctl-eksworkshop-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa"
2025-04-18 11:40:05 [ℹ] created serviceaccount "kube-system/fsx-csi-controller-sa" ✅ Step 5: 생성된 Role ARN 저장
export ROLE_ARN=$(aws cloudformation describe-stacks --stack-name "eksctl-${CLUSTER_NAME}-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa" --query "Stacks[0].Outputs[0].OutputValue" --region $AWS_REGION --output text)
echo $ROLE_ARN
arn:aws:iam::1**********6:role/eksctl-eksworkshop-addon-iamserviceaccount-ku-Role1-BPJqotZQ9cyL✅ Step 6: FSx for Lustre CSI 드라이버 배포
kubectl apply -k "github.com/kubernetes-sigs/aws-fsx-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.2"
# Warning: 'bases' is deprecated. Please use 'resources' instead. Run 'kustomize edit fix' to update your Kustomization automatically.
Warning: resource serviceaccounts/fsx-csi-controller-sa is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
serviceaccount/fsx-csi-controller-sa configured
serviceaccount/fsx-csi-node-sa created
clusterrole.rbac.authorization.k8s.io/fsx-csi-external-provisioner-role created
clusterrole.rbac.authorization.k8s.io/fsx-csi-node-role created
clusterrole.rbac.authorization.k8s.io/fsx-external-resizer-role created
clusterrolebinding.rbac.authorization.k8s.io/fsx-csi-external-provisioner-binding created
clusterrolebinding.rbac.authorization.k8s.io/fsx-csi-node-getter-binding created
clusterrolebinding.rbac.authorization.k8s.io/fsx-csi-resizer-binding created
deployment.apps/fsx-csi-controller created
daemonset.apps/fsx-csi-node created
csidriver.storage.k8s.io/fsx.csi.aws.com created
# 배포가 완료되었는지 아래 명령어로 확인합니다:
kubectl get pods -n kube-system -l app.kubernetes.io/name=aws-fsx-csi-driver
NAME READY STATUS RESTARTS AGE
fsx-csi-controller-6f4c577bd4-9d28n 4/4 Running 0 55s
fsx-csi-controller-6f4c577bd4-x6xjw 4/4 Running 0 55s
fsx-csi-node-hn2nc 3/3 Running 0 55s
fsx-csi-node-q2wjz 3/3 Running 0 55s✅ Step 7: 서비스 계정에 IAM Role 주석(annotation) 추가
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa \
eks.amazonaws.com/role-arn=$ROLE_ARN --overwrite=true
serviceaccount/fsx-csi-controller-sa annotated
# 아래 명령어로 주석이 잘 반영되었는지 확인합니다:
kubectl get sa/fsx-csi-controller-sa -n kube-system -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::1**********6:role/eksctl-eksworkshop-addon-iamserviceaccount-ku-Role1-BPJqotZQ9cyL
labels:
app.kubernetes.io/managed-by: eksctl
app.kubernetes.io/name: aws-fsx-csi-driver
name: fsx-csi-controller-sa
namespace: kube-system2.4 EKS 클러스터에 Persistent Volume 생성
✅ 두 가지 PV 생성 방식
-
정적 프로비저닝 (Static Provisioning)
관리자가 백엔드 스토리지를 생성하고 PV를 정의한 후, 사용자가 해당 PV를 참조하는 PVC를 생성하여 Pod에서 사용합니다. -
동적 프로비저닝 (Dynamic Provisioning)
사용자가 PVC를 요청하면, CSI 드라이버가 자동으로 백엔드 스토리지와 PV를 생성해줍니다. 관리자가 사전에 PV를 만들어 둘 필요가 없습니다.
🧪 본 실습에서는 정적 프로비저닝 방식을 사용합니다.
Amazon S3 버킷과 연결된 FSx for Lustre 인스턴스가 사전에 생성되어 있으며, 이 인스턴스는 Mistral-7B 모델 데이터를 저장합니다. 이제 EKS 클러스터에 PV 정의와 PVC를 생성하여, vLLM 컨테이너가 해당 모델 데이터에 접근할 수 있도록 설정합니다.
✅ Step 0: 작업 디렉토리 이동
cd /home/ec2-user/environment/eks/FSxL✅ Step 0.5: FSx for Lustre 정보 변수에 저장
FSXL_VOLUME_ID=$(aws fsx describe-file-systems --query 'FileSystems[].FileSystemId' --output text)
DNS_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].DNSName' --output text)
MOUNT_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].LustreConfiguration.MountName' --output text)✅ Step 1: Persistent Volume 정의 생성
fsxL-persistent-volume.yaml 파일을 사용하여 PV를 정의합니다. 이 파일은 다음과 같은 내용을 포함하고 있습니다:
# fsxL-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
csi:
driver: fsx.csi.aws.com
volumeHandle: FSXL_VOLUME_ID
volumeAttributes:
dnsname: DNS_NAME
mountname: MOUNT_NAME📌 변수 치환 명령어를 사용하여 실제 값으로 바꿉니다:
sed -i'' -e "s/FSXL_VOLUME_ID/$FSXL_VOLUME_ID/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/DNS_NAME/$DNS_NAME/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/MOUNT_NAME/$MOUNT_NAME/g" fsxL-persistent-volume.yaml📄 PV 정의 확인:
cat fsxL-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
csi:
driver: fsx.csi.aws.com
volumeHandle: fs-062ecab1ae67f2867
volumeAttributes:
dnsname: fs-062ecab1ae67f2867.fsx.us-west-2.amazonaws.com
mountname: gmzdbb4v📦 PV를 EKS 클러스터에 생성:
kubectl apply -f fsxL-persistent-volume.yaml
persistentvolume/fsx-pv created🔍 PV 생성 여부 확인:
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
fsx-pv 1200Gi RWX Retain Available <unset> 18s
pvc-4af7a876-f81f-4456-bbea-ca90aca34256 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 34h✅ Step 2: Persistent Volume Claim 생성
이제 위에서 생성한 PV에 바인딩되는 PVC를 생성합니다:
# fsxL-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv📦 PVC를 EKS 클러스터에 배포:
kubectl apply -f fsxL-claim.yaml
persistentvolumeclaim/fsx-lustre-claim created🔍 PVC 바인딩 확인:
kubectl get sc,pv,pvc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 34h
storageclass.storage.k8s.io/gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 34h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/fsx-pv 1200Gi RWX Retain Bound default/fsx-lustre-claim <unset> 2m6s
persistentvolume/pvc-4af7a876-f81f-4456-bbea-ca90aca34256 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 34h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/fsx-lustre-claim Bound fsx-pv 1200Gi RWX <unset> 58sPVC가 Bound 상태로 fsx-pv에 연결되어 있어야 합니다.
2.5 Amazon FSx 콘솔에서 옵션 및 성능 상세 정보 보기
앞선 단계에서 우리는 실습용으로 미리 생성된 FSx for Lustre 인스턴스를 사용해 Persistent Volume (PV) 을 구성했습니다.
이제 콘솔에서 해당 FSx for Lustre 인스턴스의 설정 및 옵션을 확인해보겠습니다.
⚠️ 참고: 이후 단계에서는 직접 FSx for Lustre 인스턴스를 생성하고 EKS 클러스터에 연결해보는 실습도 진행됩니다.
✅ Amazon FSx 콘솔로 이동
- Amazon FSx 콘솔 에 접속합니다.
- 우측 상단에서 실습에 제공된 AWS 리전(aws_region) 을 선택합니다.
✅ 미리 생성된 FSx 인스턴스 확인

콘솔 화면에는 현재 계정에 존재하는 FSx 인스턴스 목록이 표시됩니다.
여기서 실습을 위해 미리 생성된 FSx for Lustre 인스턴스를 확인할 수 있으며, 이 인스턴스를 앞서 EKS 클러스터에 PV로 구성한 것입니다.
✅ 새로운 FSx for Lustre 인스턴스 생성 옵션 살펴보기
-
우측 상단의 [Create file system] 버튼 클릭
-
[Amazon FSx for Lustre] 선택 후 [Next] 클릭
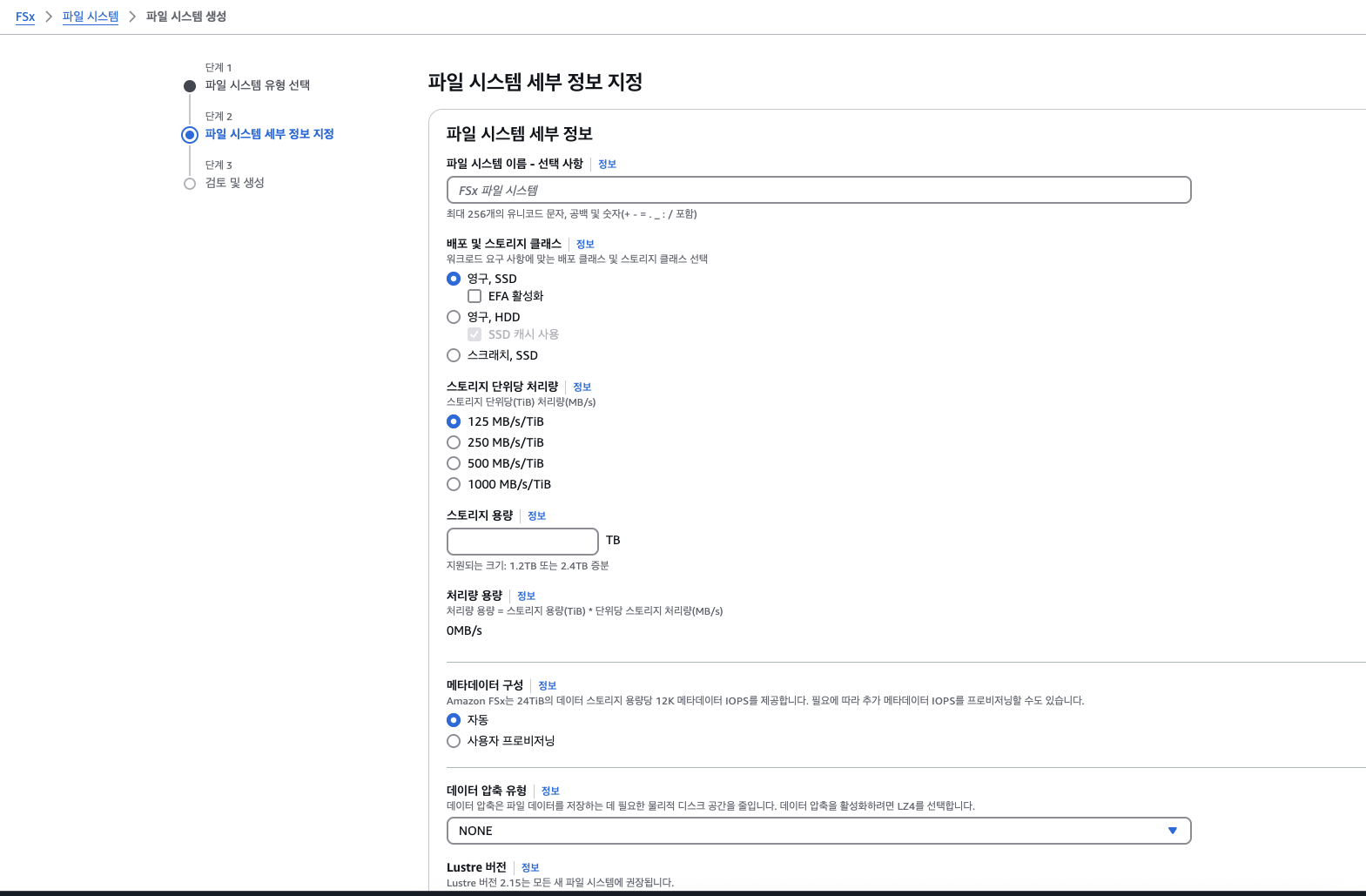
이 화면에서는 Lustre 파일 시스템의 다양한 배포 옵션을 확인할 수 있습니다:
- 스토리지 타입: Persistent SSD / Scratch SSD
- Throughput 단위당 속도 구성
- Metadata IOPS 성능 설정
- 압축 설정
- S3와 연동된 자동 데이터 가져오기/내보내기 구성 (Data Repository Import/Export)
👇
옵션들을 살펴본 후, Cancel 버튼을 눌러 화면을 닫고 FSx 콘솔로 돌아옵니다.
✅ 기존 FSx 인스턴스 세부 정보 확인
- FSx 콘솔에서 File system ID 를 클릭하면 해당 인스턴스의 구성 정보를 확인할 수 있습니다.
- 여기서 다음 항목들을 실시간으로 수정할 수 있습니다:
- 스토리지 용량 증가
- Throughput 용량 증가 (단위당 MB/s)
💡 참고사항:
- 스토리지 용량을 늘리면 Throughput도 함께 증가합니다.
- Throughput만 독립적으로 증가시킬 수도 있습니다 (저장 공간은 그대로 두고 속도만 증가 필요 시).
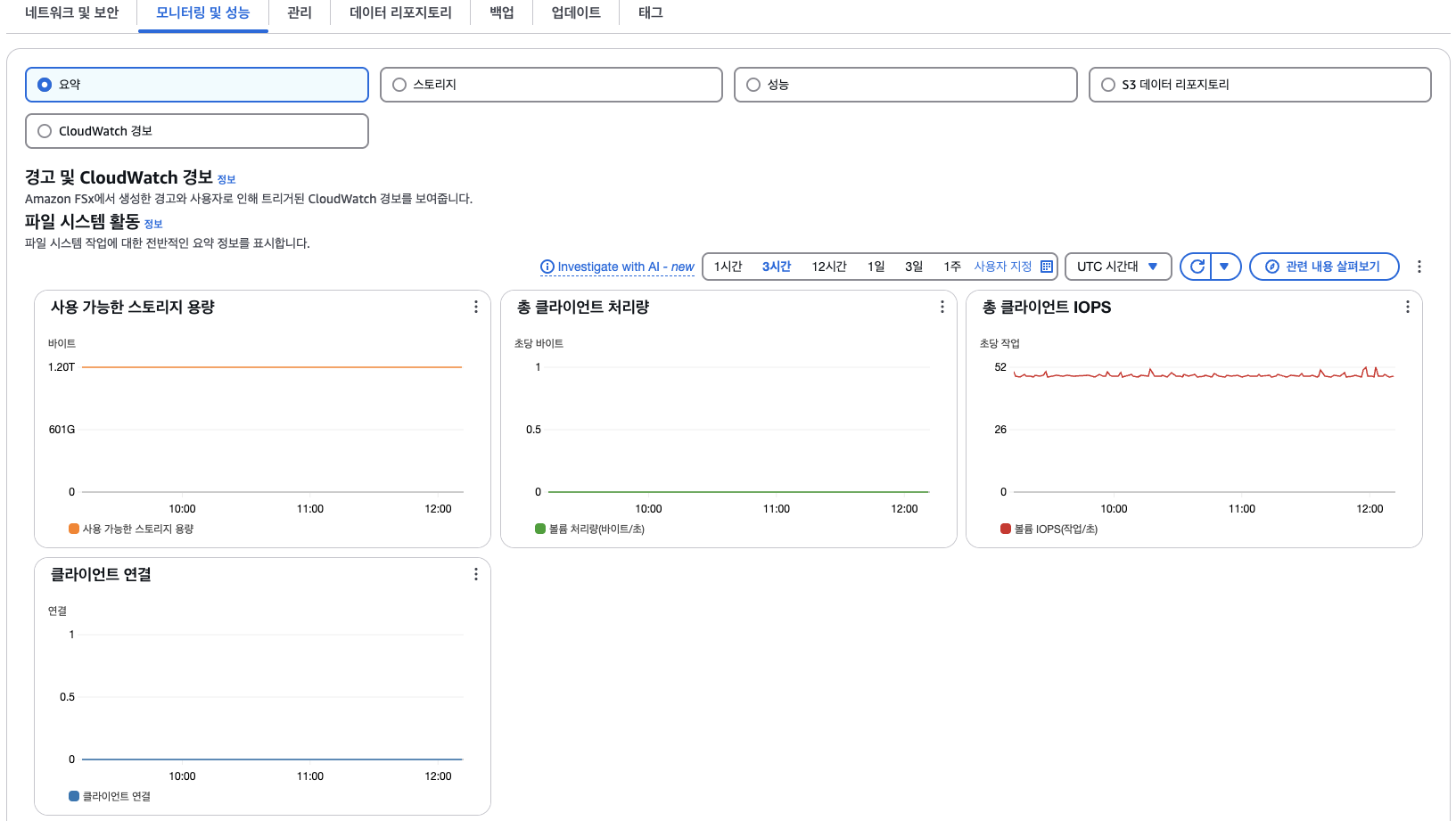
✅ 성능 모니터링 보기
- 화면 하단의 [Monitoring & performance] 탭 클릭
- 다음과 같은 다양한 성능 지표 확인 가능:
- 용량 (Capacity)
- Throughput
- IOPS
- 메타데이터 처리 성능
- 네트워크 성능 등
3. 생성형 AI 챗봇 애플리케이션 배포
3.1 개요
📦 모듈 개요 (Module Overview)
이 모듈에서는 Amazon EKS 클러스터에 vLLM Pod와 WebUI Pod를 배포하여 생성형 AI 챗봇 애플리케이션을 구성합니다.
또한, Amazon FSx for Lustre와 Amazon S3를 사용하여 Mistral-7B 모델을 저장 및 액세스하고, AWS Inferentia Accelerator를 생성형 AI 워크로드의 가속 컴퓨팅으로 활용합니다.
3.1.1 🤖 생성형 AI와 머신러닝 (Generative AI and Machine Learning)
생성형 AI(Generative AI) 와 머신러닝(ML) 은 비즈니스 운영 및 혁신 방식을 혁신적으로 변화시키고 있습니다.
생성형 AI는 대규모 언어 모델(LLM) 을 활용해 텍스트, 이미지, 오디오, 코드 등 새로운 콘텐츠를 생성할 수 있는 인공지능 기술입니다.
3.1.2 📚 대규모 언어 모델(LLM)이란?
LLM (Large Language Model) 은 방대한 텍스트 데이터로 학습되어 자연어의 패턴과 구조를 이해하고 다양한 자연어 처리 작업을 수행할 수 있는 머신러닝 모델입니다.
이 실습에서는 오픈소스 LLM인 Mistral-7B-Instruct 모델을 사용합니다.
- Mistral-7B: 약 70억 개의 파라미터를 가진 모델
- Instruct: 명령어를 이해하고 다양한 작업을 수행할 수 있도록 학습됨 → 챗봇 애플리케이션에 적합
3.1.3 🚀 vLLM 이란?
vLLM (Virtual Large Language Model) 은 LLM 추론 및 서빙을 위한 오픈소스 라이브러리입니다.
Mistral-7B-Instruct 같은 모델을 OpenAI API와 호환되는 API로 제공하는 추론 서버로 쉽게 배포할 수 있도록 해줍니다.
🏎️ vLLM의 장점:
- 최신 서빙 처리량 지원
- 효율적인 Attention 키/값 메모리 관리 (PagedAttention)
- 연속적인 요청 배치 처리
- 빠른 모델 실행 (CUDA/HIP Graph)
🧩 vLLM의 유연성:
- HuggingFace 모델과의 통합 지원
- OpenAI API 호환 서버 제공
- 프리픽스 캐싱(Prefix Caching) 지원
- 다양한 하드웨어 지원: AWS Neuron, NVIDIA GPU 등
3.1.4 📦 Mistral-7B-Instruct 모델을 Amazon EKS에 vLLM으로 배포
이 실습에서는 OpenAI API 호환 엔드포인트를 제공하기 위해 Amazon EKS에 vLLM 프레임워크 기반 Mistral-7B 모델을 배포합니다.
이를 위해 Karpenter를 사용하여 AWS Inferentia2 기반 EC2 인스턴스를 자동으로 생성하고, 해당 인스턴스에 vLLM Pod를 실행합니다.
3.1.5 ⚡ AWS Inferentia 가속기란?
AWS Inferentia 는 AWS에서 설계한 생성형 AI 및 딥러닝 추론을 위한 전용 칩셋입니다.
📌 주요 특징:
- 고성능, 저비용 추론 제공
- PyTorch, TensorFlow, MXNet 등과 호환
- 복잡한 모델(Large Language Models, Diffusion Models 등)에 최적화
- Inf2 인스턴스에 최대 12개의 Inferentia2 가속기 장착 가능
- 각 Inferentia2:
- 2개의 2세대 NeuronCore 탑재
- FP16 기준 초당 최대 190 TFLOPS
- 32GB 고대역폭 메모리(HBM)
3.1.6 🧰 AWS Neuron SDK
Neuron SDK 는 AWS Inferentia 가속기에서 딥러닝 모델을 최적 성능으로 실행할 수 있게 해주는 SDK입니다.
🛠️ 구성요소:
- 컴파일러
- 런타임
- 프로파일링 도구
💡 특징:
- PyTorch, TensorFlow 등 인기 프레임워크와 자연스럽게 통합
- 코드 수정 최소화
- 다양한 AI 추론 작업에 활용:
- 자연어 처리/이해
- 번역, 요약
- 이미지/비디오 생성
- 음성 인식
- 사기 탐지 등
3.2 AWS Inferentia 노드에서 vLLM을 배포하여 모델 추론 수행
✅ Step 1: AWS Inferentia 가속기를 위한 Karpenter NodePool 및 EC2 NodeClass 생성
Karpenter 구성은 NodePool이라는 Custom Resource(CR)의 형태로 정의됩니다.
NodePool은 생성될 노드와 해당 노드에서 실행 가능한 파드에 제약 조건을 설정합니다.
예를 들어, 특정 아키텍처만 사용하거나, 다양한 파드 형태를 유연하게 처리할 수 있습니다.
이번 단계에서는 Generative AI 애플리케이션 (vLLM Pod) 을 위한 Inferentia NodePool 을 구성합니다.
📁 작업 디렉토리로 이동:
cd /home/ec2-user/environment/eks/genai📄 Inferentia 노드 풀 정의 파일 확인:
cat inferentia_nodepool.yaml
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: inferentia
labels:
intent: genai-apps
NodeGroupType: inf2-neuron-karpenter
spec:
template:
spec:
taints:
- key: aws.amazon.com/neuron
value: "true"
effect: "NoSchedule"
requirements:
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["inf2"]
- key: "karpenter.k8s.aws/instance-size"
operator: In
values: [ "xlarge", "2xlarge", "8xlarge", "24xlarge", "48xlarge"]
- key: "kubernetes.io/arch"
operator: In
values: ["amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: inferentia
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmpty
# expireAfter: 720h # 30 * 24h = 720h
consolidateAfter: 180s
weight: 100
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: inferentia
spec:
amiFamily: AL2
amiSelectorTerms:
- alias: al2@v20240917
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
deleteOnTermination: true
volumeSize: 100Gi
volumeType: gp3
role: "Karpenter-eksworkshop"
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "eksworkshop"
tags:
intent: apps
managed-by: karpenter📦 Karpenter NodePool 배포:
kubectl apply -f inferentia_nodepool.yaml
nodepool.karpenter.sh/inferentia created
ec2nodeclass.karpenter.k8s.aws/inferentia created🔍 NodePool 및 EC2NodeClass 확인:
kubectl get nodepool,ec2nodeclass inferentia예시 출력:
NAME NODECLASS NODES READY AGE
nodepool.karpenter.sh/inferentia inferentia 0 True 18s
NAME READY AGE
ec2nodeclass.karpenter.k8s.aws/inferentia True 18s✅ Step 2: Neuron 디바이스 플러그인 및 스케줄러 설치
💡 주의: 이 워크샵에서는 시간 절약을 위해 Mistral-7B 모델이 이미 AWS Neuron SDK로 다운로드 및 컴파일 되어 있습니다.
📌 Neuron Device Plugin 이란?
Neuron 디바이스 플러그인은 Kubernetes에서 Neuron 코어 및 디바이스를 리소스로 노출시켜주는 역할을 합니다.
🔧 Neuron Device Plugin 설치:
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin-rbac.yml
Warning: resource clusterroles/neuron-device-plugin is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
clusterrole.rbac.authorization.k8s.io/neuron-device-plugin configured
Warning: resource serviceaccounts/neuron-device-plugin is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
serviceaccount/neuron-device-plugin configured
Warning: resource clusterrolebindings/neuron-device-plugin is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
clusterrolebinding.rbac.authorization.k8s.io/neuron-device-plugin configured
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin.yml
daemonset.apps/neuron-device-plugin-daemonset created📌 Neuron Scheduler란?
Neuron Scheduler 확장은 다수의 Neuron 코어나 디바이스가 필요한 파드를 연속된 코어/디바이스 ID에 배치되도록 합니다.
🔧 Neuron Scheduler 설치:
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-scheduler-eks.yml
clusterrole.rbac.authorization.k8s.io/k8s-neuron-scheduler created
serviceaccount/k8s-neuron-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/k8s-neuron-scheduler created
Warning: spec.template.metadata.annotations[scheduler.alpha.kubernetes.io/critical-pod]: non-functional in v1.16+; use the "priorityClassName" field instead
deployment.apps/k8s-neuron-scheduler created
service/k8s-neuron-scheduler created
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/my-scheduler.yml
serviceaccount/my-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-kube-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler-as-volume-scheduler created
clusterrole.rbac.authorization.k8s.io/my-scheduler created
clusterrolebinding.rbac.authorization.k8s.io/my-scheduler created
configmap/my-scheduler-config created
deployment.apps/my-scheduler created✅ Step 3: vLLM 애플리케이션 파드 배포
이제 vLLM Pod를 배포하여 Mistral-7B 모델 추론 서비스를 제공합니다.
vLLM 파드가 실행되면 FSx for Lustre 기반의 Persistent Volume에서 모델(약 29GB)을 메모리로 로드합니다.
📦 vLLM 파드 배포:
# 파드 배포전 전체 Pod 확인
WSParticipantRole:~/environment/eks/genai $ kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default kube-ops-view-5d9d967b77-tgh6n 1/1 Running 0 34h
karpenter karpenter-6f4f89f94b-42cn5 1/1 Running 0 34h
karpenter karpenter-6f4f89f94b-sfwsx 1/1 Running 0 34h
kube-prometheus-stack kube-prometheus-stack-grafana-68ff66d7c-xcppw 3/3 Running 0 34h
kube-prometheus-stack kube-prometheus-stack-kube-state-metrics-6b7844d7f7-lhz8t 1/1 Running 0 34h
kube-prometheus-stack kube-prometheus-stack-operator-86f8df994b-kvhr6 1/1 Running 0 34h
kube-prometheus-stack kube-prometheus-stack-prometheus-node-exporter-gfwgp 1/1 Running 0 34h
kube-prometheus-stack kube-prometheus-stack-prometheus-node-exporter-wf7m4 1/1 Running 0 34h
kube-prometheus-stack prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 34h
kube-system aws-load-balancer-controller-594fbfbbc6-6pwzn 1/1 Running 0 34h
kube-system aws-load-balancer-controller-594fbfbbc6-6q2vq 1/1 Running 0 34h
kube-system aws-node-d9x8w 2/2 Running 0 34h
kube-system aws-node-vqrp7 2/2 Running 0 34h
kube-system coredns-86f597cb5-llfn8 1/1 Running 0 34h
kube-system coredns-86f597cb5-wgpgp 1/1 Running 0 34h
kube-system ebs-csi-controller-7b5dc8b6c7-6sjq6 6/6 Running 0 34h
kube-system ebs-csi-controller-7b5dc8b6c7-tkw6w 6/6 Running 0 34h
kube-system ebs-csi-node-9mh4g 3/3 Running 0 34h
kube-system ebs-csi-node-r9fmh 3/3 Running 0 34h
kube-system eks-pod-identity-agent-2tpsh 1/1 Running 0 34h
kube-system eks-pod-identity-agent-zqklj 1/1 Running 0 34h
kube-system fsx-csi-controller-6f4c577bd4-9d28n 4/4 Running 0 45m
kube-system fsx-csi-controller-6f4c577bd4-x6xjw 4/4 Running 0 45m
kube-system fsx-csi-node-hn2nc 3/3 Running 0 45m
kube-system fsx-csi-node-q2wjz 3/3 Running 0 45m
kube-system k8s-neuron-scheduler-8674f545bb-csjfj 1/1 Running 0 67s
kube-system kube-proxy-4vhw7 1/1 Running 0 34h
kube-system kube-proxy-gjtgf 1/1 Running 0 34h
kube-system metrics-server-7577444cf8-t9ctb 1/1 Running 0 34h
kube-system my-scheduler-7f97569db-8kg44 1/1 Running 0 50s
nvidia-device-plugin nvidia-device-plugin-node-feature-discovery-master-695f7b9rcgth 1/1 Running 0 34h
nvidia-device-plugin nvidia-device-plugin-node-feature-discovery-worker-5zp7f 1/1 Running 0 34h
nvidia-device-plugin nvidia-device-plugin-node-feature-discovery-worker-h7pmw 1/1 Running 0 34h
kubectl apply -f mistral-fsxl.yaml
deployment.apps/vllm-mistral-inf2-deployment created
service/vllm-mistral7b-service created⚠️ vLLM 배포에는 약 7~8분이 소요됩니다. 다음 단계로 바로 진행해도 됩니다.
📄 vLLM 배포 파일 내용 확인:
cat mistral-fsxl.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-mistral-inf2-deployment
spec:
replicas: 1
selector:
matchLabels:
app: vllm-mistral-inf2-server
template:
metadata:
labels:
app: vllm-mistral-inf2-server
spec:
tolerations:
- key: "aws.amazon.com/neuron"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: inference-server
image: public.ecr.aws/u3r1l1j7/eks-genai:neuronrayvllm-100G-root
resources:
requests:
aws.amazon.com/neuron: 1
limits:
aws.amazon.com/neuron: 1
args:
- --model=$(MODEL_ID)
- --enforce-eager
- --gpu-memory-utilization=0.96
- --device=neuron
- --max-num-seqs=4
- --tensor-parallel-size=2
- --max-model-len=10240
- --served-model-name=mistralai/Mistral-7B-Instruct-v0.2-neuron
env:
- name: MODEL_ID
value: /work-dir/Mistral-7B-Instruct-v0.2/
- name: NEURON_COMPILE_CACHE_URL
value: /work-dir/Mistral-7B-Instruct-v0.2/neuron-cache/
- name: PORT
value: "8000"
volumeMounts:
- name: persistent-storage
mountPath: "/work-dir"
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: fsx-lustre-claim
---
apiVersion: v1
kind: Service
metadata:
name: vllm-mistral7b-service
spec:
selector:
app: vllm-mistral-inf2-server
ports:
- protocol: TCP
port: 80
targetPort: 8000- AWS Inferentia Neuron 코어 요청
- FSx Lustre PVC(
fsx-lustre-claim) 사용 - 모델 파라미터 포함
📡 vLLM 파드 상태 모니터링 (주기적으로 실행):
kubectl get pod
NAME READY STATUS RESTARTS AGE
kube-ops-view-5d9d967b77-tgh6n 1/1 Running 0 34h
vllm-mistral-inf2-deployment-7d886c8cc8-766tf 0/1 ContainerCreating 0 99s
...
kubectl get pod
NAME READY STATUS RESTARTS AGE
kube-ops-view-5d9d967b77-tgh6n 1/1 Running 0 34h
vllm-mistral-inf2-deployment-7d886c8cc8-766tf 1/1 Running 0 7m44s🖥️ EKS 콘솔에서 확인
1. Amazon EKS 콘솔로 이동
2. eksworkshop 클러스터 클릭
3. Compute 탭 클릭 → inf2.xlarge 인스턴스 확인 가능
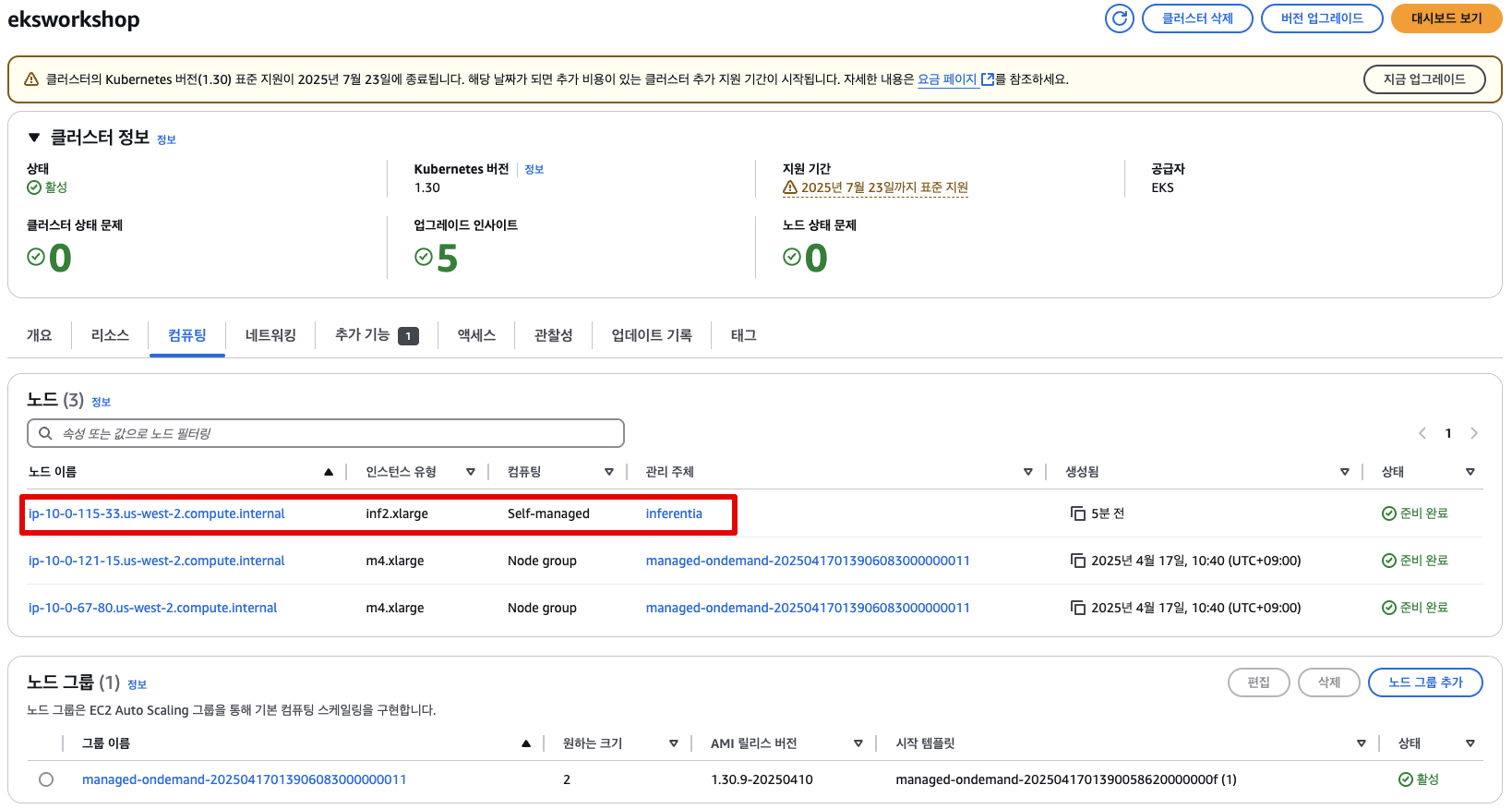
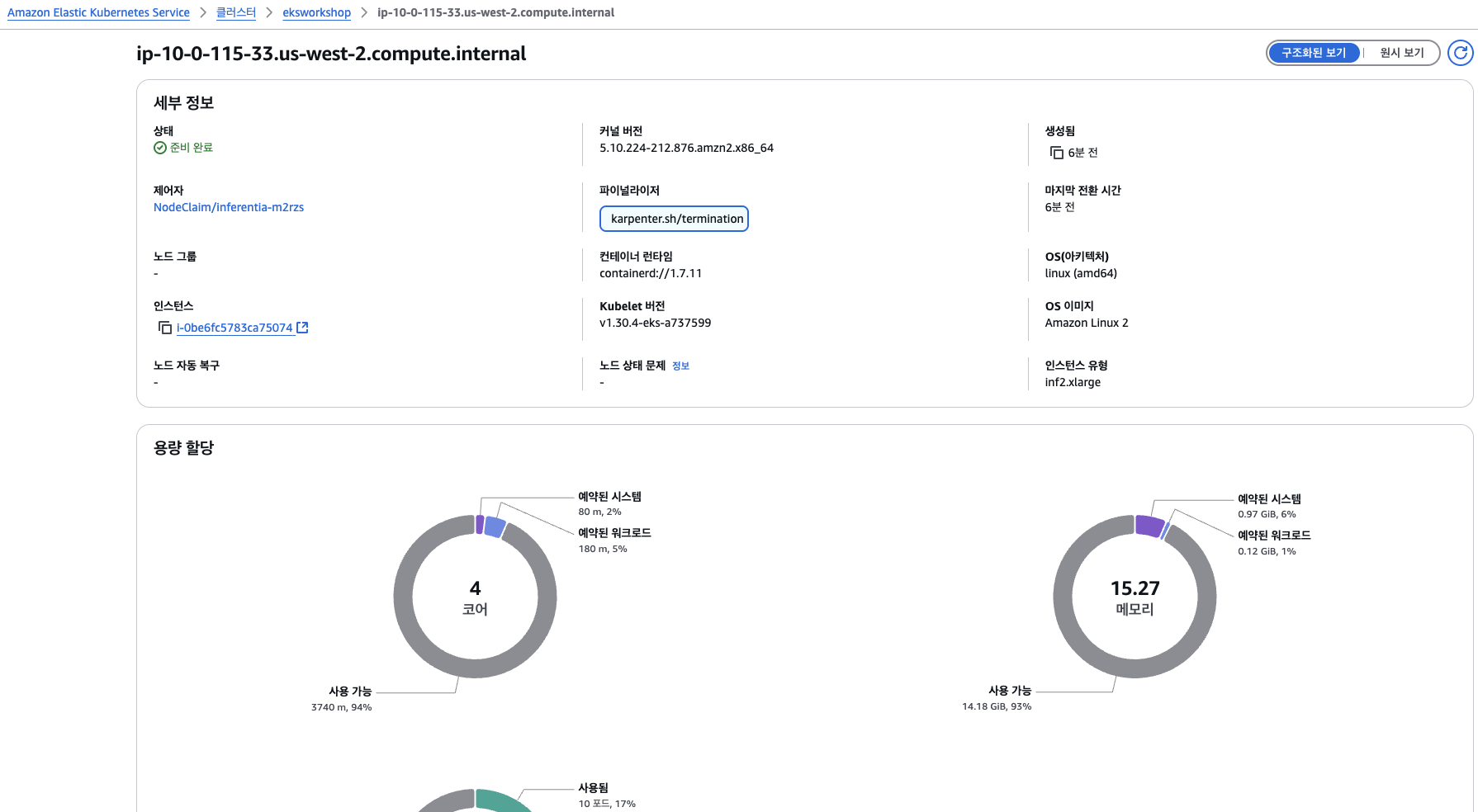
4. 인스턴스 이름 클릭 → 해당 노드의 할당 리소스 및 파드 정보 확인
3.3 WebUI 채팅 애플리케이션 배포 및 모델과 상호작용하기
✅ 모델 추론 서비스와 상호작용하는 방법
이제 Open WebUI 애플리케이션을 사용하여 vLLM에서 호스팅 중인 Mistral-7B-Instruct 모델에 접속할 수 있습니다.
이 WebUI는 OpenAI 호환 API 엔드포인트를 소비하도록 설계된 채팅 인터페이스를 제공합니다.
🧠 사용자는 웹 브라우저를 통해 간편하게 LLM과 대화를 주고받을 수 있으며, Open WebUI가 백엔드의 vLLM과 통신을 자동으로 처리합니다.
✅ Open WebUI 파드 및 로드 밸런서 배포
다음 명령어를 실행하여 Open WebUI 애플리케이션 파드를 배포합니다.
이 작업은 웹 기반 채팅 인터페이스와 이를 위한 애플리케이션 로드 밸런서(ALB) 도 함께 생성합니다.
kubectl apply -f open-webui.yaml
deployment.apps/open-webui-deployment created
service/open-webui-service created
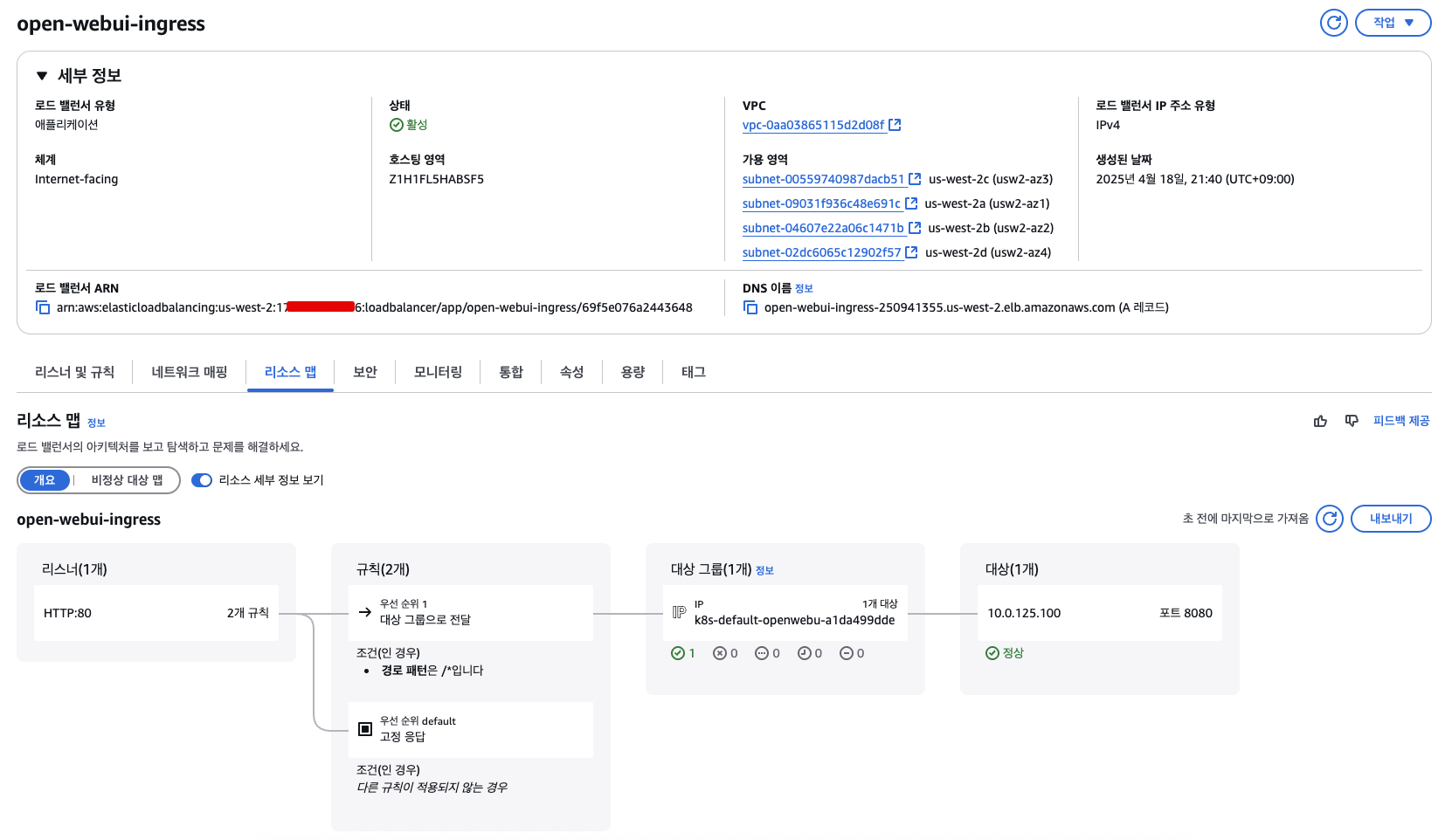
ingress.networking.k8s.io/open-webui-ingress created🌐 WebUI 주소 확인
아래 명령어로 WebUI 접속 주소(URL) 를 확인합니다.
kubectl get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
open-webui-ingress alb * open-webui-ingress-250941355.us-west-2.elb.amazonaws.com 80 22sALB가 생성되는 데 1~2분 소요될 수 있습니다. 잠시 기다린 뒤 출력된 주소(URL) 를 복사하여 웹 브라우저에 붙여넣으세요.
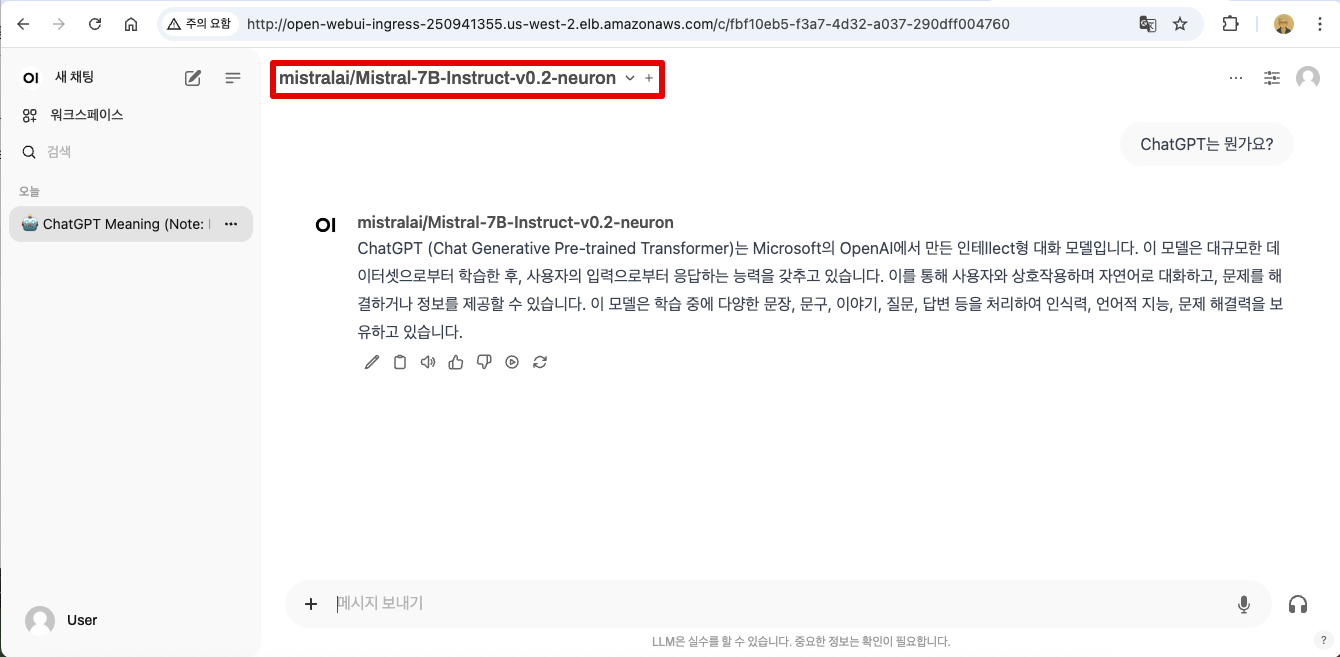
💬 WebUI에서 모델 선택 및 채팅 시작
- WebUI에 접속하면 상단 메뉴 바에 드롭다운이 있습니다.
- 이 드롭다운에서 Mistral-7B 모델을 선택하세요.
- 이후 모델과 채팅을 시작할 수 있습니다.
⚠️ 드롭다운에 Mistral-7B 모델이 보이지 않는다면, 페이지를 새로고침(F5) 하세요.
(앞서 배포한 vLLM 파드가 모델을 메모리에 적재하는 데 약 7~8분이 소요됩니다.)
🎉 완료!
여기까지 완료하셨다면:
✅ Amazon FSx for Lustre에 캐시된 Mistral-7B 모델
✅ AWS Inferentia 가속기로 구동되는 vLLM 파드
✅ Amazon EKS 위에 컨테이너로 배포된 Open WebUI
✅ 웹 브라우저에서 사용할 수 있는 Generative AI 채팅 앱을 모두 성공적으로 배포 및 연결한 것입니다!
4. Mistral-7B 데이터 확인 및 생성된 데이터 자산 공유 & 복제하기
4.1 📦 모듈 개요
이 모듈에서는 다음을 수행하게 됩니다:
-
vLLM 파드에 직접 접속하여
- Mistral-7B 모델 데이터가 어떻게 저장되어 있는지 확인하고,
- FSx for Lustre로 백업된 Persistent Volume (PV) 를 통해 S3 버킷의 데이터를 어떻게 접근하는지도 살펴봅니다.
-
EKS 파드 내에서 테스트 파일을 생성하여
- 해당 파일이 S3 버킷으로 자동 export 되는 것을 확인하고,
- 다른 리전에 있는 S3 버킷으로의 자동 복제(S3 Replication) 까지 실습하게 됩니다.
✅ 이를 통해 AI 모델이나 학습 데이터를 여러 팀 또는 리전에서 중앙 집중식으로 공유하고,
✅ 재해 복구(Disaster Recovery) 또는 분산 처리(Distributed Processing)에 대응하는 구조를 만들 수 있습니다.
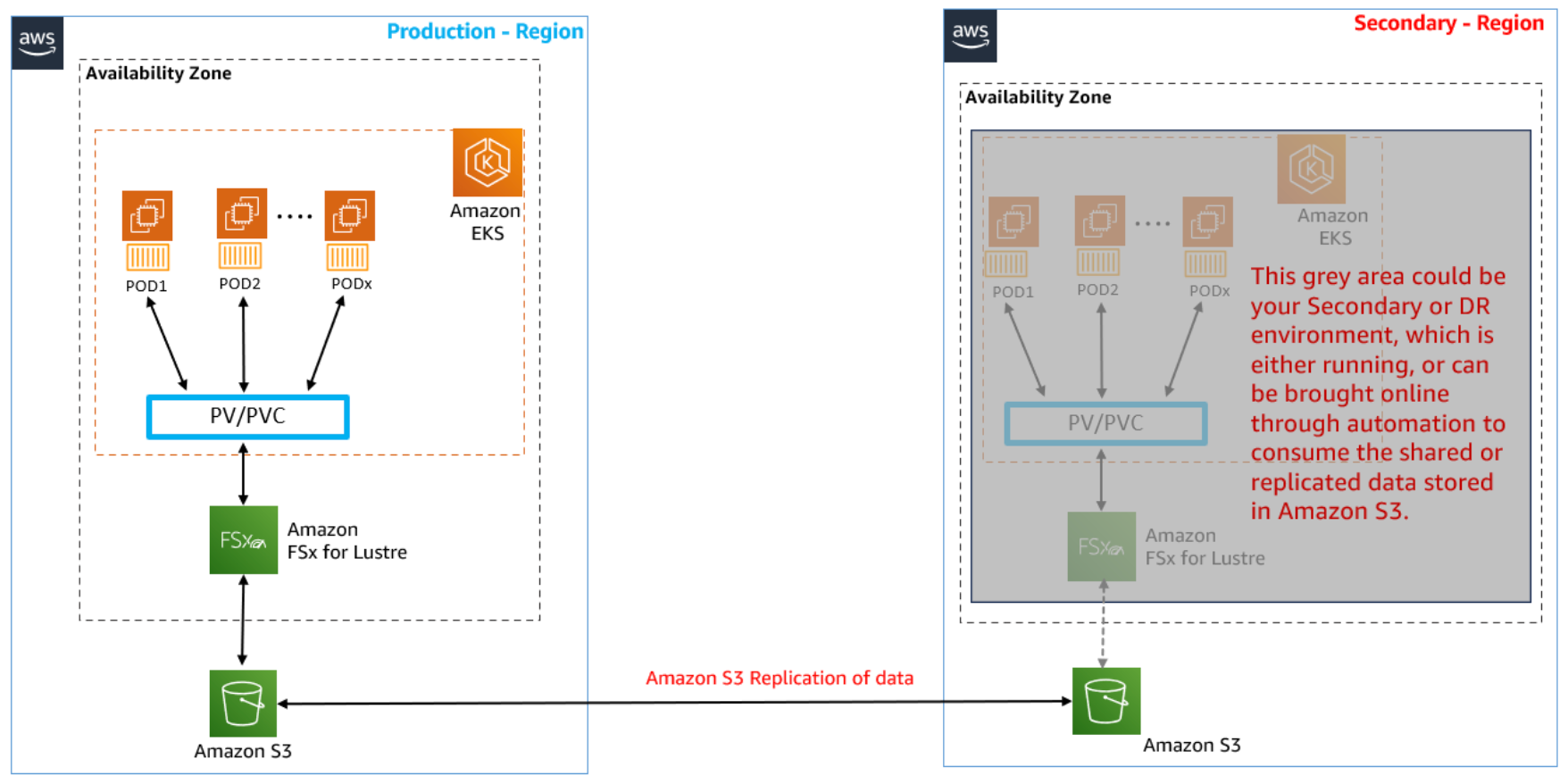
4.1.1 📁 공유 PV 하나로 여러 파드 지원하기
- 수많은 AI 모델 또는 방대한 학습 데이터를 다양한 파드가 접근해야 하는 경우,
- FSx for Lustre로 백업된 하나의 Persistent Volume + PVC 조합만 있으면 됩니다.
이 구조의 장점은 다음과 같습니다:
| ✅ 이점 | 설명 |
|---|---|
| 고성능 캐시 제공 | FSx for Lustre는 고속 I/O를 제공하여, 대규모 데이터에 빠르게 접근 가능 |
| 데이터 중복 방지 | 각 파드마다 데이터를 복사할 필요 없음 (공유 볼륨 사용) |
| 파드 시작 시간 단축 | 새 파드가 뜰 때마다 데이터를 복사하지 않아도 됨 |
| 모델 및 데이터 중앙화 | 다양한 파드가 동일한 위치에서 동일한 데이터에 접근 가능 |
📌 실습에서는 EKS 파드에서 생성한 테스트 파일이
- S3로 자동 이동되고,
- S3 복제를 통해 다른 리전(us-east-2) 으로도 전파되는 흐름을 확인할 수 있습니다.
4.1.2 🧪 실습 시나리오 요약
-
vLLM 파드에 접속하여,
- Mistral-7B 모델 구조 확인
/mnt/fsx/경로 아래의 PV를 통해 S3에 접근 확인
-
/mnt/fsx/디렉터리에 테스트 파일 생성- 이 파일은 자동으로 S3에 export 됨
-
S3 복제 기능(S3 Cross Region Replication)을 통해
- 해당 파일이 자동으로 us-east-2 리전의 S3 버킷에도 복제됨
4.2 FSx for Lustre 인스턴스와 연결된 S3 버킷에 대해 S3 교차 리전 복제(Cross-Region Replication) 구성하기
🧭 S3 교차 리전 복제 구성
🎯 이 단계에서는 Amazon S3의 복제(Replication) 기능을 이용해,
한 리전에 있는 소스 S3 버킷의 데이터를 다른 리전(us-east-2)에 있는 대상 S3 버킷으로 자동으로 복제되도록 구성합니다.
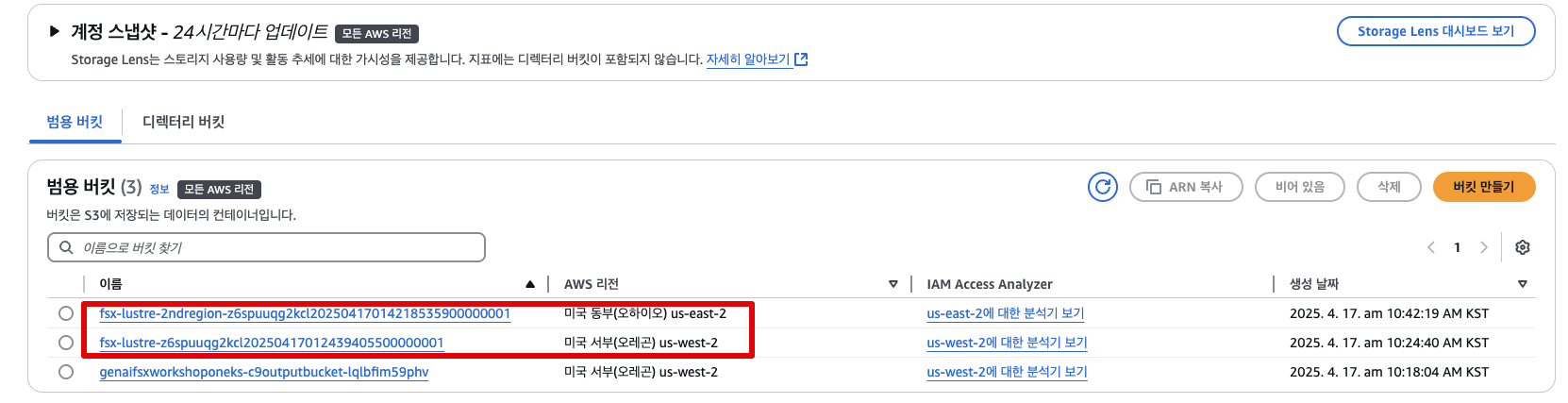
✅ 실습 환경에서는 이미 아래 두 개의 버킷이 생성되어 있습니다:
- 소스(Source) S3 버킷 – 여러분이 선택한 리전에 위치
- 대상(Destination) S3 버킷 –
us-east-2리전에 있으며 이름은 다음과 비슷한 형식:
fsx-lustre-bucket-2ndregion-xxxx
🛠 구성 단계
- Amazon S3 콘솔 접속
-
AWS 콘솔에서 S3 서비스 페이지로 이동하세요.
-
자신이 선택한 리전에 있는 S3 버킷을 클릭합니다.
⚠️ "2ndregion"이라는 단어가 포함된 대상 버킷은 클릭하지 마세요!
- Replication Rule 생성
Management탭으로 이동- 아래로 스크롤하여 Replication rules 섹션 찾기
- Create replication rule 버튼 클릭
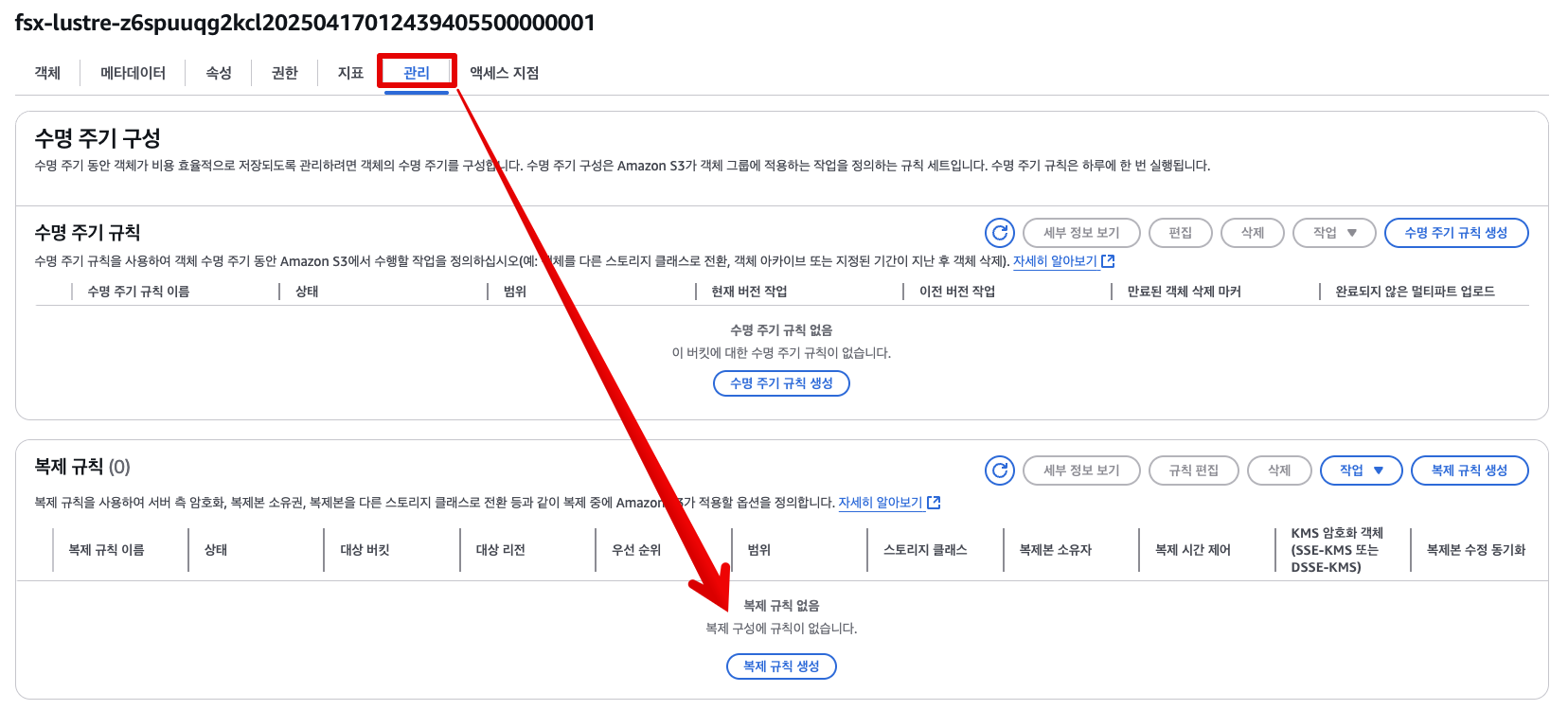
- 버전 관리 활성화
- 화면 상단 빨간색 팝업 박스에서 Enable Bucket Versioning 클릭
Rule name에 규칙 이름을 입력 (예:fsx-replication-rule)Status는 기본값으로 Enabled 상태 확인
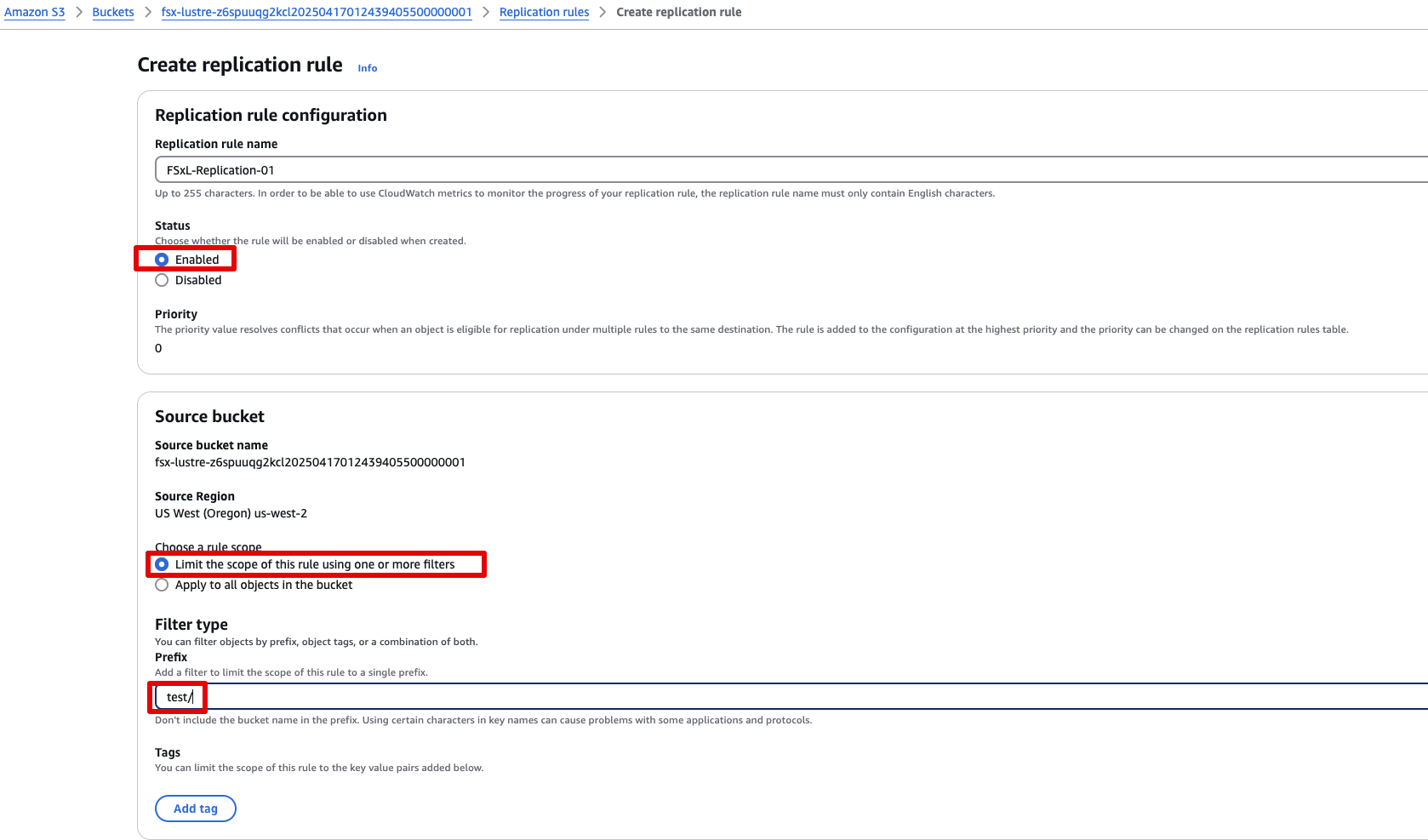
- 복제 범위 설정 (Prefix 필터)
Source bucket항목에서
limit the scope of this rule using one or more filters 선택- Prefix 값으로
test/입력해당 경로로 저장된 객체만 복제 대상이 됩니다.
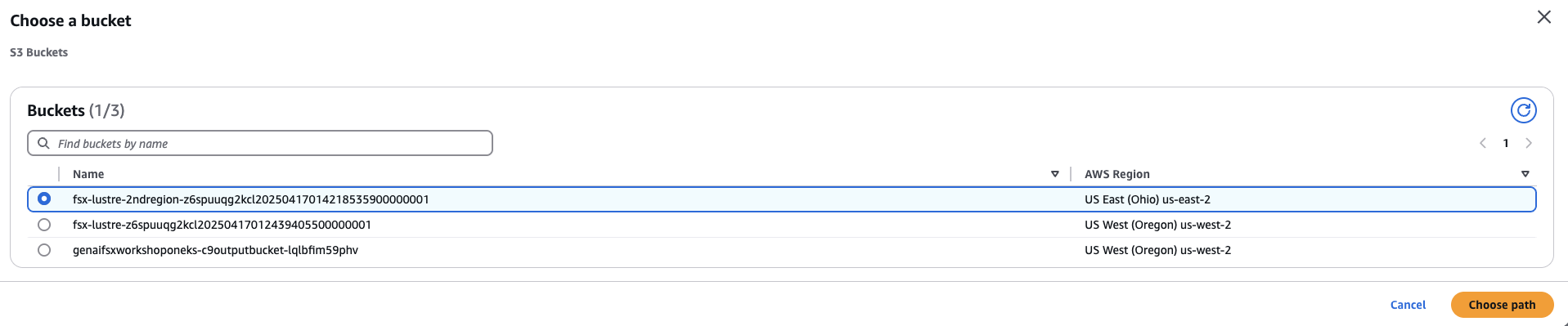
- 대상 S3 버킷 선택
Destination항목에서 Browse S3 클릭- 대상 버킷
fsx-lustre-bucket-2ndregion-xxxx선택 - Choose path 클릭하여 대상 버킷 경로 선택 완료
- 대상 버킷에 버전 관리 활성화
- 다시 빨간색 팝업이 뜨면 Enable Bucket Versioning 클릭
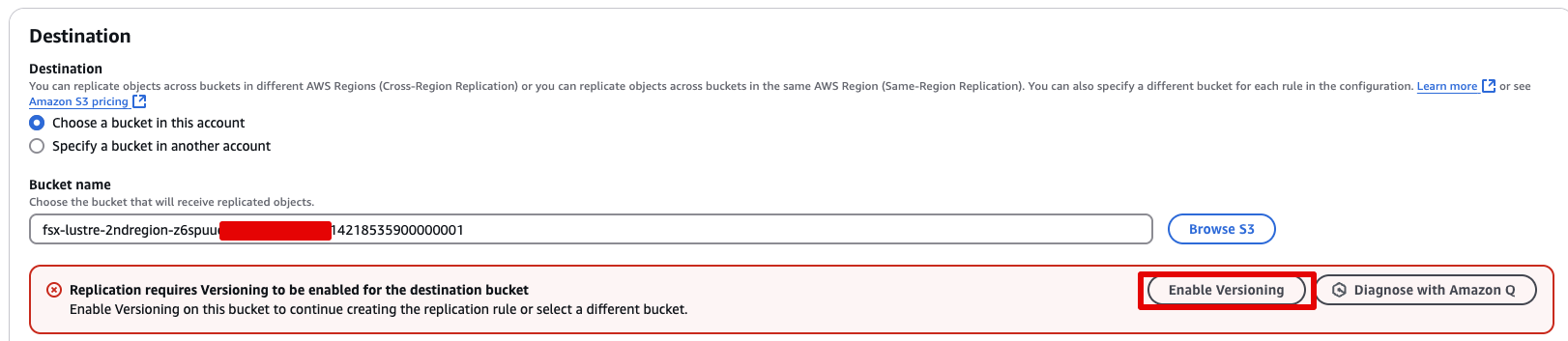
- IAM 역할 설정
- 복제를 수행할 수 있도록 S3가 사용할 IAM 역할을 지정해야 합니다.
- 사전 생성된 역할을 선택하세요:
이름은s3-cross-region-replication-role로 시작

- 암호화 설정
Encryption항목에서
Replicate objects encrypted with AWS KMS 체크- Available AWS KMS keys 클릭
- 표시되는 키 하나를 선택합니다.
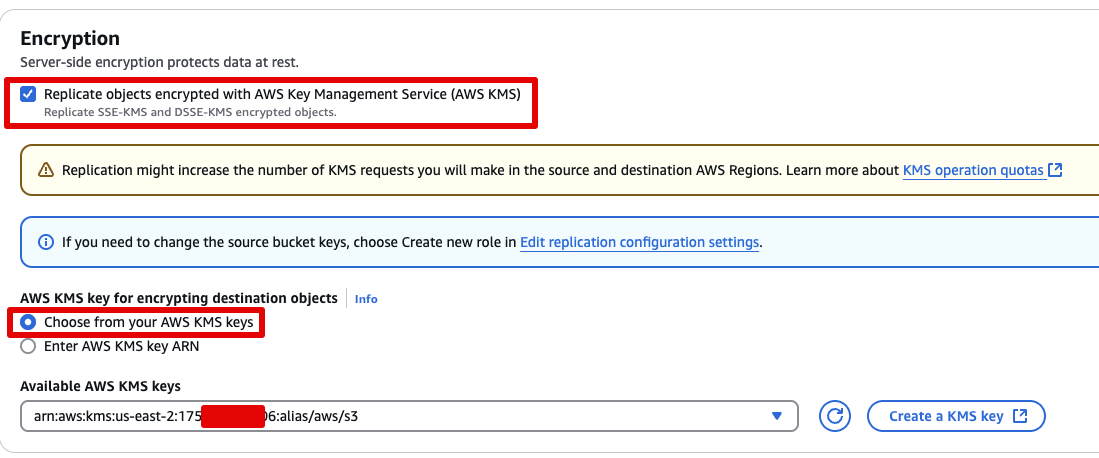
- 표시되는 키 하나를 선택합니다.
- 구성 저장 및 완료
- 나머지는 기본값 유지
- Save 클릭하여 설정 저장
- 기존 객체 복제 여부
- 팝업창이 뜨면 "기존 객체 복제 여부" 확인
- No, do not replicate existing objects 선택
- Submit 클릭
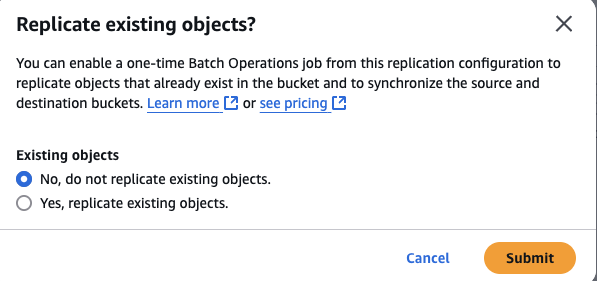
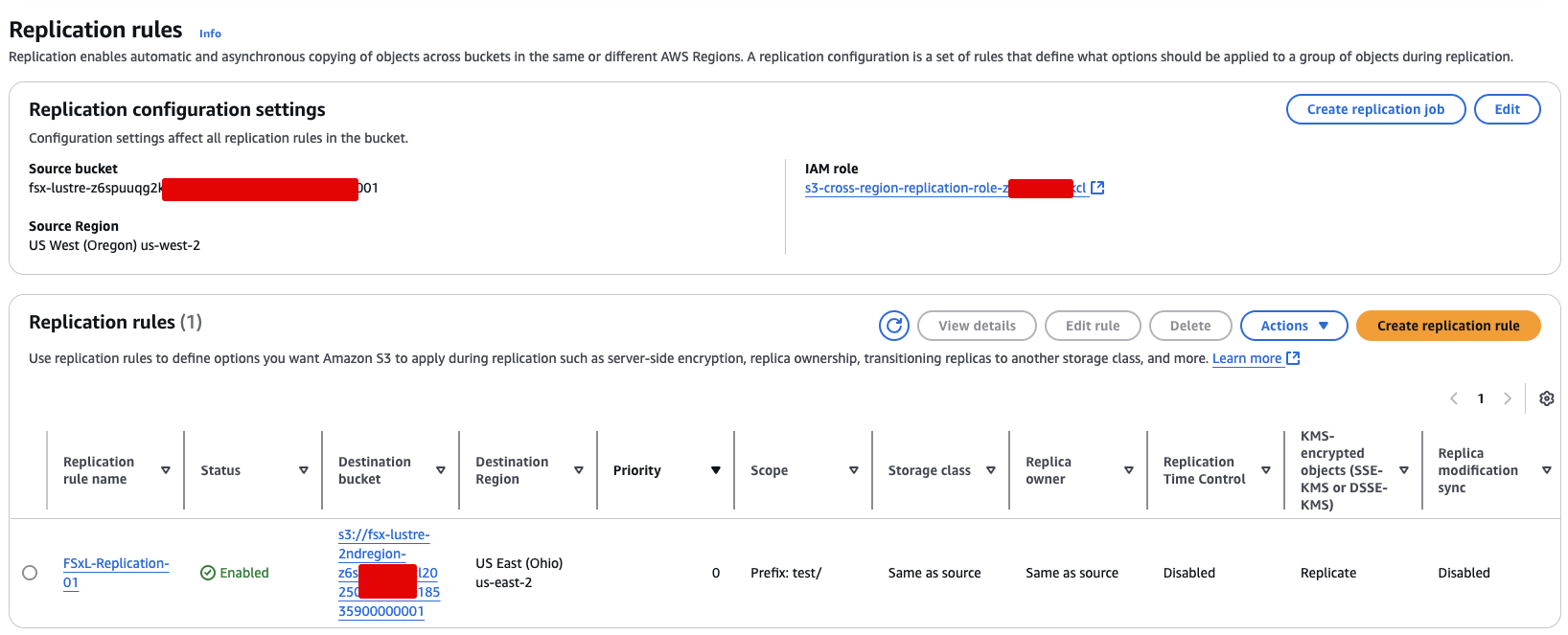
- 구성 확인
Replication rules목록으로 돌아오면
새 규칙이 성공적으로 생성된 것을 확인할 수 있습니다.
📝 요약
✅ 소스 버킷에서 특정 Prefix(test/)에 저장되는 파일이
✅ us-east-2 리전의 대상 S3 버킷으로 자동 복제 되도록 설정함
✅ 버킷 버전 관리, IAM 역할, KMS 암호화, Prefix 필터링 포함된 S3 복제 구성 완성
📌 다음 단계
이제 파드에 연결된 Persistent Volume (FSx for Lustre) 에
/mnt/fsx/test/ 경로에 파일을 만들면 —
그 파일은 S3에 자동으로 export → us-east-2 리전으로 자동 복제됩니다.
이 기능은 모델 및 데이터 자산의 공유,
재해 복구(Disaster Recovery) 및 비즈니스 연속성(BCP) 구성에 아주 유용합니다.
4.3 Mistral-7B 데이터 확인 및 테스트 파일 생성 → S3 자동 Export 및 리전 간 복제
🔹 Step 1: Pod에 접속하여 모델 데이터 확인 및 테스트 파일 생성
1. Cloud9 터미널에서 작업 디렉토리로 이동
cd /home/ec2-user/environment/eks/FSxL- vLLM Pod 이름 확인
kubectl get pods
NAME READY STATUS RESTARTS AGE
kube-ops-view-5d9d967b77-tgh6n 1/1 Running 0 36h
open-webui-deployment-5d7ff94bc9-zl6pb 1/1 Running 0 91m
vllm-mistral-inf2-deployment-7d886c8cc8-766tf 1/1 Running 0 101m
# vllm으로 시작하는 Pod 이름을 복사합니다.- vLLM Pod에 접속
kubectl exec -it vllm-mistral-inf2-deployment-7d886c8cc8-766tf -- bash- 마운트된 FSx for Lustre 파일 시스템 확인
df -h
Filesystem Size Used Avail Use% Mounted on
overlay 100G 23G 78G 23% /
tmpfs 64M 0 64M 0% /dev
tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup
10.0.52.188@tcp:/gmzdbb4v 1.2T 28G 1.1T 3% /work-dir
/dev/nvme0n1p1 100G 23G 78G 23% /etc/hosts
shm 64M 0 64M 0% /dev/shm
tmpfs 15G 12K 15G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 7.7G 0 7.7G 0% /proc/acpi
tmpfs 7.7G 0 7.7G 0% /sys/firmware
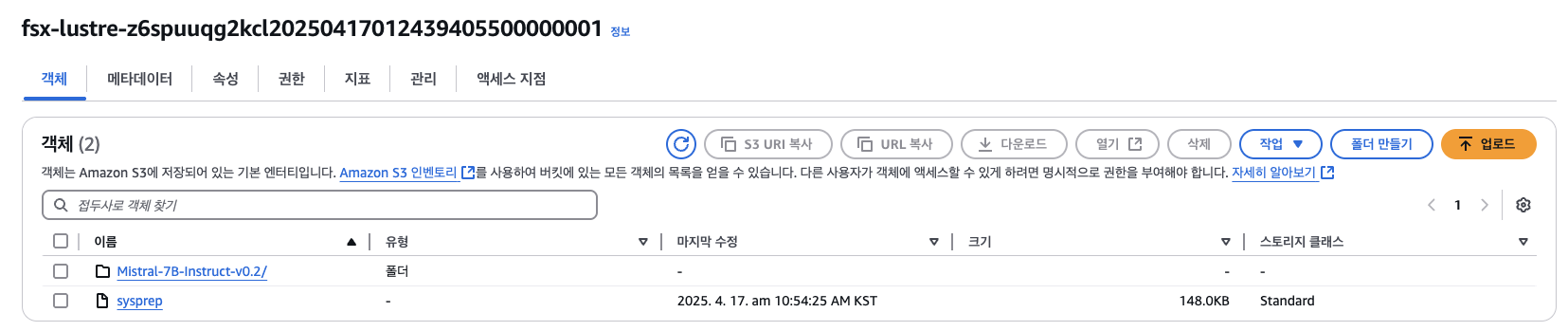
# work-dir가 Persistent Volume Claim이 마운트된 위치입니다.- 모델 데이터 디렉토리 확인
cd /work-dir/
ls -ll
total 297
drwxr-xr-x 5 root root 33280 Apr 16 18:51 Mistral-7B-Instruct-v0.2
-rw-r--r-- 1 root root 151586 Apr 16 18:52 sysprep
# Mistral-7B-Instruct-v0.2/ 디렉토리가 존재해야 합니다.- 테스트 파일 생성 (testfile)
cd /work-dir
mkdir test
cd test
cp /work-dir/Mistral-7B-Instruct-v0.2/README.md /work-dir/test/testfile
ls -ll /work-dir/test
total 1
-rwxr-xr-x 1 root root 5471 Apr 18 07:16 testfile✅ 위 작업으로 test/testfile 파일이 생성되며, FSx for Lustre의 auto-export 기능에 의해 자동으로 연결된 S3 버킷으로 업로드됩니다.
또한, 이전 단계에서 구성한 S3 복제 규칙에 따라 us-east-2 리전의 S3 버킷으로 자동 복제됩니다.
🔹 Step 2: S3 버킷에서 Export 및 Replication 확인
1. Amazon S3 콘솔 접속
AWS 콘솔에서 S3 서비스 페이지로 이동합니다.
- 본 리전의 소스 S3 버킷 클릭
본인의 FSx for Lustre와 연결된 S3 버킷을 클릭합니다.
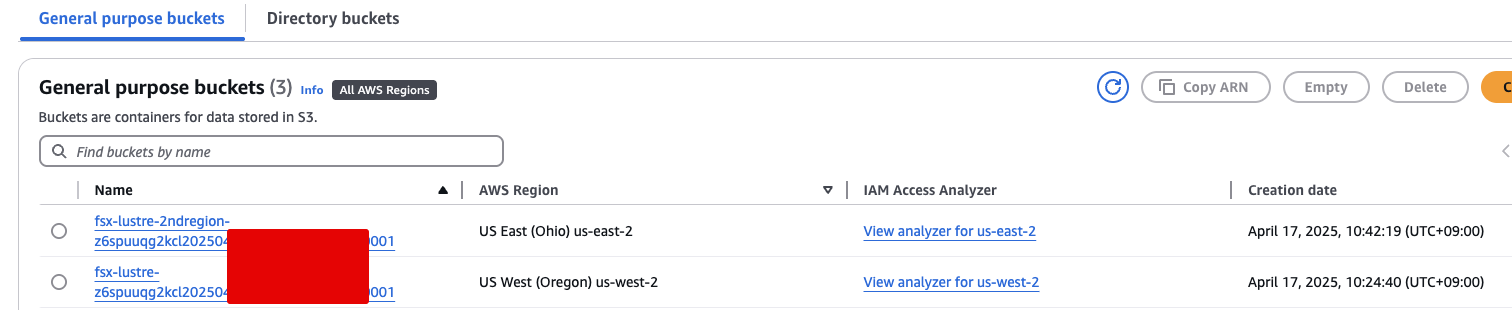
❗ 2ndregion이라는 단어가 포함되지 않은 버킷을 선택해야 합니다.
- test/ 폴더 존재 여부 확인
test/ 폴더가 자동 생성된 것을 확인하고 클릭합니다.

그 안에 testfile 이 존재하는지 확인합니다.
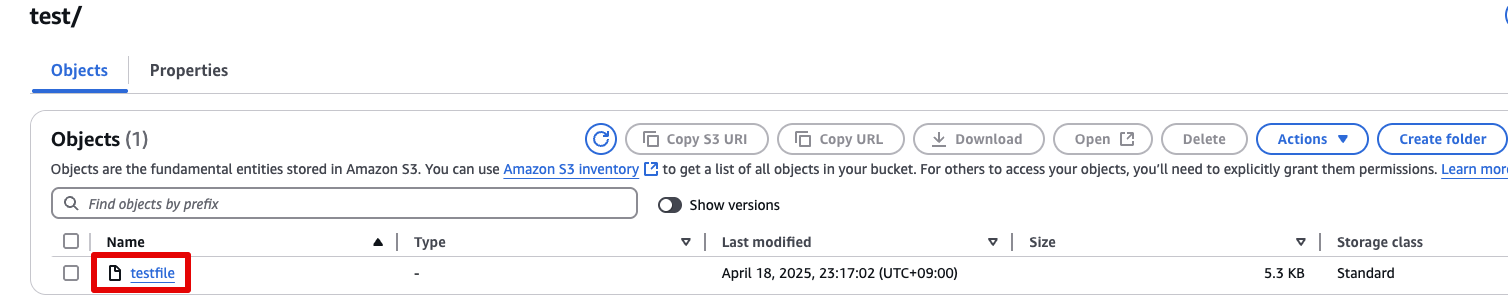
🧾 요약
✅ Pod 내에서 생성한 데이터가 FSx for Lustre를 통해 S3로 자동 Export됨
✅ S3 복제 규칙을 통해 다른 리전의 S3 버킷으로 자동 복제됨
✅ 데이터는 재해 복구(DR) 시나리오, 여러 리전에서의 분산 접근, 팀 간 공유 등에 활용 가능
📌 참고: 대규모 AI 모델/데이터 공유 시의 베스트 프랙티스
수백 개의 Pod에서 공유해야 하는 대규모 AI 모델 혹은 훈련 데이터가 있을 경우:
FSx for Lustre로 연결된 단일 Persistent Volume(PV) 사용
여러 Pod가 공유하는 고성능 캐시 저장소 역할
각 Pod에 로컬로 데이터를 복사하는 비효율 제거
5. 데이터 레이어 테스트를 위한 사용자 전용 환경 만들기
5.1 📌 모듈 개요
이전 모듈에서는 관리자가 미리 생성한 FSx for Lustre 스토리지 인스턴스를 사용하는 정적 프로비저닝 방식을 통해 EKS 클러스터에서 Persistent Volume(PV)과 Persistent Volume Claim(PVC) 를 생성하고 사용하는 방법을 배웠습니다.
이번 섹션에서는 사용자 본인이 직접 테스트용 환경을 구축하게 되며, 다음을 실습합니다:
✅ 주요 학습 내용
- Pod 배포
- Dynamic Provisioning 활용
- FSx for Lustre 인스턴스를 자동 생성
- 별도 관리자 사전 작업 없이 PV와 PVC를 즉시 프로비저닝
- PVC를 Pod에 마운트
- 데이터 쓰기/읽기 테스트
💡 Dynamic Provisioning 은 실제 운영 환경에서도 매우 유용하며, 유저 주도형 자동 스토리지 할당 시나리오를 지원합니다.
5.2 📦 FSx for Lustre 동적 프로비저닝을 사용한 PV 및 스토리지 생성 실습
✅ 모듈 목표
이 섹션에서는 CSI 드라이버의 동적 프로비저닝(Dynamic Provisioning) 기능을 사용하여,
- Persistent Volume (PV)
- Persistent Volume Claim (PVC)
- FSx for Lustre 파일 시스템 인스턴스 를 자동으로 생성하는 방법을 실습합니다.
※ 관리자의 사전 준비 없이도 스토리지를 생성할 수 있는 사용자 중심의 방식입니다.
📌 1단계: 환경 변수 설정
VPC_ID,SUBNET_ID,SECURITY_GROUP_ID환경 변수 설정- 해당 값을
.yaml파일에서 사용할 수 있도록 치환
VPC_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.vpcId" --output text)
SUBNET_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.subnetIds[0]" --output text)
SECURITY_GROUP_ID=$(aws ec2 describe-security-groups --filters Name=vpc-id,Values=${VPC_ID} Name=group-name,Values="FSxLSecurityGroup01" --query "SecurityGroups[*].GroupId" --output text)
echo $SUBNET_ID
subnet-0be9679133f087446
echo $SECURITY_GROUP_ID
sg-009d3e037c7fd6d12📌 2단계: StorageClass 정의 및 생성
# 디렉토리 이동
cd /home/ec2-user/environment/eks/FSxL
# fsxL-storage-class.yaml 파일
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fsx-lustre-sc
provisioner: fsx.csi.aws.com
parameters:
subnetId: SUBNET_ID
securityGroupIds: SECURITY_GROUP_ID
deploymentType: SCRATCH_2
fileSystemTypeVersion: "2.15"
mountOptions:
- flock
# 변수값 치환
sed -i'' -e "s/SUBNET_ID/$SUBNET_ID/g" fsxL-storage-class.yaml
sed -i'' -e "s/SECURITY_GROUP_ID/$SECURITY_GROUP_ID/g" fsxL-storage-class.yaml
cat fsxL-storage-class.yaml
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fsx-lustre-sc
provisioner: fsx.csi.aws.com
parameters:
subnetId: subnet-0be9679133f087446
securityGroupIds: sg-009d3e037c7fd6d12
deploymentType: SCRATCH_2
fileSystemTypeVersion: "2.15"
mountOptions:
- flock
# FSx Lustre 동적 스토리지 생성을 위한 StorageClass 정의
kubectl apply -f fsxL-storage-class.yaml 로 StorageClass 생성
storageclass.storage.k8s.io/fsx-lustre-sc created
# StorageClass 조회
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fsx-lustre-sc fsx.csi.aws.com Delete Immediate false 24s
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 36h
gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 36h📌 3단계: PVC 정의 및 생성
- fsxL-dynamic-claim.yaml
→fsx-lustre-scStorageClass 를 참조하여 1200GiB 요청
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-dynamic-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: fsx-lustre-sc
resources:
requests:
storage: 1200Gi kubectl apply -f fsxL-dynamic-claim.yaml로 PVC 생성
kubectl apply -f fsxL-dynamic-claim.yaml
persistentvolumeclaim/fsx-lustre-dynamic-claim created📌 4단계: 생성 확인
kubectl get pvc명령으로 PVC 상태 확인
→ 약 15분 이내에Bound상태로 전환- PVC가
Bound상태가 되면 FSx Lustre 인스턴스도 생성 완료됨
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
fsx-lustre-claim Bound fsx-pv 1200Gi RWX <unset> 156m
fsx-lustre-dynamic-claim Pending fsx-lustre-sc <unset> 42s🧠 요약
- 동적 프로비저닝으로 스토리지 관리자 없이도 FSx Lustre 인스턴스와 PV/PVC 생성 가능
- 사용자가 필요한 만큼의 용량을 PVC 요청으로 정의
- FSx Lustre는 Amazon S3와 연결되어 있어 성능 + 데이터 공유 모두 충족
➡️ 다음 실습에서는 이 스토리지를 활용한 성능 테스트용 Pod 배포를 진행하게 됩니다.
5.3 FSx for Lustre 성능 테스트 실습
🎯 목표
이번 섹션에서는 FSx for Lustre 파일 시스템의 성능을 측정합니다.
EKS에 배포한 Pod에서 다음 도구들을 사용해 성능 테스트를 수행합니다:
- FIO: 디스크 I/O 부하 테스트 도구
- IOping: 디스크 지연(latency)을 실시간으로 측정하는 도구
📌 1단계: 성능 테스트용 Pod 배포
1. 작업 디렉토리 이동
cd /home/ec2-user/environment/eks/FSxL- FSx Lustre 인스턴스의 가용 영역(AZ) 확인
aws ec2 describe-subnets --subnet-id $SUBNET_ID --region $AWS_REGION | jq .Subnets[0].AvailabilityZone
"us-west-2c"pod_performance.yaml파일 열기
vi pod_performance.yamlnodeSelector와topology.kubernetes.io/zone주석 해제us-east-2c→ 위에서 확인한 AZ 값으로 수정
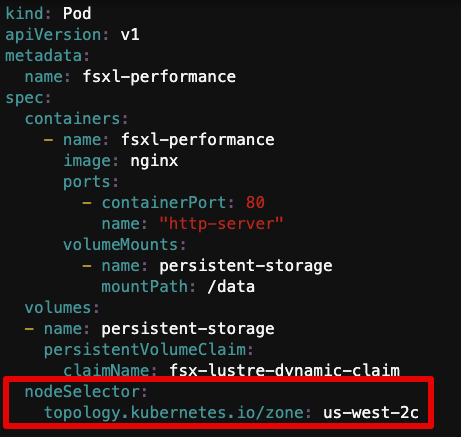
- Pod 생성
kubectl apply -f pod_performance.yaml
kubectl get pod
NAME READY STATUS RESTARTS AGE
fsxl-performance 1/1 Running 0 27s
kube-ops-view-5d9d967b77-tgh6n 1/1 Running 0 37h
open-webui-deployment-5d7ff94bc9-zl6pb 1/1 Running 0 125m
vllm-mistral-inf2-deployment-7d886c8cc8-766tf 1/1 Running 0 135m- pv, pvc 확인
참고: FSx Lustre PVC가 아직
Bound상태가 아니면, Pod은 Pending 상태로 남아 있음 (최대 15분 소요)
kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/fsx-pv 1200Gi RWX Retain Bound default/fsx-lustre-claim <unset> 167m
persistentvolume/pvc-4af7a876-f81f-4456-bbea-ca90aca34256 50Gi RWO Delete Bound kube-prometheus-stack/data-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 37h
persistentvolume/pvc-583e1f2b-af7f-4275-9bec-1452bfc3ec41 1200Gi RWX Delete Bound default/fsx-lustre-dynamic-claim fsx-lustre-sc <unset> 4m41s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/fsx-lustre-claim Bound fsx-pv 1200Gi RWX <unset> 166m
persistentvolumeclaim/fsx-lustre-dynamic-claim Bound pvc-583e1f2b-af7f-4275-9bec-1452bfc3ec41 1200Gi RWX fsx-lustre-sc <unset> 10m📌 2단계: Pod 접속 및 성능 테스트 수행
- Pod에 접속
kubectl exec -it fsxl-performance -- bash- 성능 측정 도구 설치
apt-get update
Get:1 http://deb.debian.org/debian bookworm InRelease [151 kB]
Get:2 http://deb.debian.org/debian bookworm-updates InRelease [55.4 kB]
Get:3 http://deb.debian.org/debian-security bookworm-security InRelease [48.0 kB]
Get:4 http://deb.debian.org/debian bookworm/main amd64 Packages [8792 kB]
Get:5 http://deb.debian.org/debian bookworm-updates/main amd64 Packages [512 B]
Get:6 http://deb.debian.org/debian-security bookworm-security/main amd64 Packages [255 kB]
93% [4 Packages store 0 B]
Fetched 9303 kB in 1s (6585 kB/s)
Reading package lists... Done
apt-get install fio ioping -y- IOping 실행 (지연 시간 측정)
- 평균 지연 시간: 0.5ms 이하가 일반적
ioping -c 20 .
4 KiB <<< . (overlay overlay 19.9 GiB): request=1 time=588.2 us (warmup)
4 KiB <<< . (overlay overlay 19.9 GiB): request=2 time=681.7 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=3 time=553.7 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=4 time=741.1 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=5 time=782.9 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=6 time=825.4 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=7 time=748.8 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=8 time=840.6 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=9 time=1.36 ms
4 KiB <<< . (overlay overlay 19.9 GiB): request=10 time=855.5 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=11 time=715.7 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=12 time=796.5 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=13 time=753.6 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=14 time=1.28 ms
4 KiB <<< . (overlay overlay 19.9 GiB): request=15 time=765.8 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=16 time=826.6 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=17 time=777.4 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=18 time=1.29 ms
4 KiB <<< . (overlay overlay 19.9 GiB): request=19 time=764.8 us
4 KiB <<< . (overlay overlay 19.9 GiB): request=20 time=747.9 us
--- . (overlay overlay 19.9 GiB) ioping statistics ---
19 requests completed in 16.1 ms, 76 KiB read, 1.18 k iops, 4.61 MiB/s
generated 20 requests in 19.0 s, 80 KiB, 1 iops, 4.21 KiB/s
min/avg/max/mdev = 553.7 us / 847.2 us / 1.36 ms / 209.4 us- FIO 테스트 실행 (처리량 측정)
- 블록 크기: 1MB (Throughput 테스트용)
- 작업 방식: 랜덤 읽기/쓰기 (50:50)
- 동시 작업: 8개
mkdir -p /data/performance
cd /data/performance
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 \
--name=fiotest --filename=testfio8gb --bs=1MB --iodepth=64 \
--size=8G --readwrite=randrw --rwmixread=50 \
--numjobs=8 --group_reporting --runtime=10
fiotest: (g=0): rw=randrw, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=64
...
fio-3.33
Starting 8 processes
fiotest: Laying out IO file (1 file / 8192MiB)
Jobs: 6 (f=6): [m(2),_(1),m(4),_(1)][38.9%][r=65.0MiB/s,w=61.0MiB/s][r=65,w=61 IOPS][eta 00m:22s]
fiotest: (groupid=0, jobs=8): err= 0: pid=724: Fri Apr 18 14:55:32 2025
read: IOPS=99, BW=99.4MiB/s (104MB/s)(1406MiB/14142msec)
bw ( KiB/s): min=18432, max=354373, per=100.00%, avg=108034.34, stdev=10132.29, samples=174
iops : min= 18, max= 345, avg=104.26, stdev= 9.88, samples=174
write: IOPS=98, BW=98.6MiB/s (103MB/s)(1394MiB/14142msec); 0 zone resets
bw ( KiB/s): min=22514, max=393182, per=100.00%, avg=108002.36, stdev=10302.95, samples=174
iops : min= 20, max= 382, avg=104.13, stdev=10.06, samples=174
cpu : usr=0.07%, sys=0.72%, ctx=5341, majf=0, minf=53
IO depths : 1=0.3%, 2=0.6%, 4=1.1%, 8=2.3%, 16=4.6%, 32=9.1%, >=64=82.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=99.7%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.3%, >=64=0.0%
issued rwts: total=1406,1394,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: bw=99.4MiB/s (104MB/s), 99.4MiB/s-99.4MiB/s (104MB/s-104MB/s), io=1406MiB (1474MB), run=14142-14142msec
WRITE: bw=98.6MiB/s (103MB/s), 98.6MiB/s-98.6MiB/s (103MB/s-103MB/s), io=1394MiB (1462MB), run=14142-14142msec- Pod에서 종료
exit📈 성능 요약
- 처리량(Throughput): 파일 시스템 크기에 비례 (1.2TiB → 240MB/s)
- 지연 시간(Latency): 일반적으로 0.5ms 이하
- IOPS: 작업 설정에 따라 달라짐 (블록 크기, IO패턴 등)
✅ 최종 정리
- FSx for Lustre는 고성능, 저지연의 공유 스토리지 제공
- CSI 드라이버 + 동적 프로비저닝을 통해 간편하게 활용 가능
- 성능 테스트 도구(FIO, IOping)로 실제 워크로드 조건 시뮬레이션 가능
🎉 워크숍 종료!
이제 FSx for Lustre를 EKS 환경에서 성능 테스트 및 실무 적용할 수 있습니다.
❤️❤️❤️ 좋은 실습 할 수 있도록 환경 제공해 주신 최영락님께 감사드립니다. ❤️❤️❤️
