가시다(gasida) 님이 진행하는 AEWS(Amazon EKS Workshop Study) 3기 과정으로 학습한 내용을 정리 또는 실습한 내용을 정리한 게시글입니다. 4주차는 EKS Observability 학습한 내용을 실습하면서 정리하였습니다.
💰 실습간 자원사용료를 줄이기 위해 Spot Instance를 사용하였습니다.
👉 1.5 비용절감을 위해 Spot으로 변경 참고하시면 됩니다.
CloudWatch Container Insight 사용 시 CloudWatch 비용이 비 정상적으로 증가하는지도 모니터링 필요합니다.
1. OneClick 실습환경 배포
1.1 사전준비
- AWS 계정, SSH Keypair, IAM 계정 생성 후 AccessKey
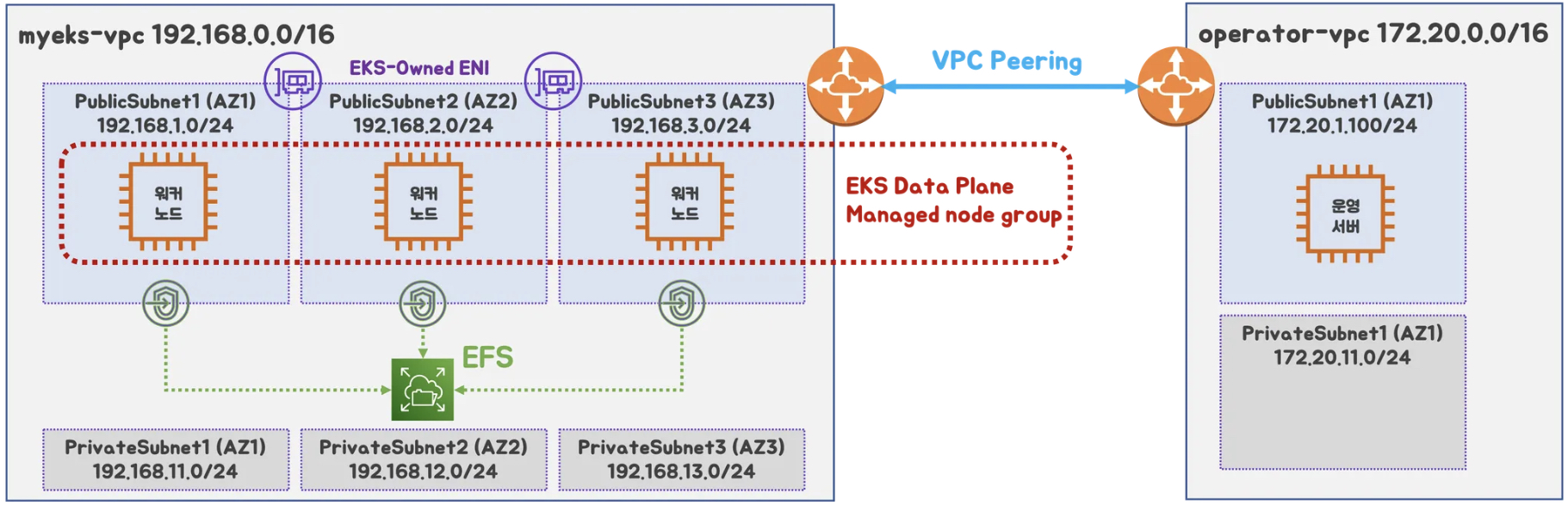
1.2 구성도
- 2개의 VPC(EKS 배포, 운영용), 운영서버 EC2, 워커노드 t3.xlarge
1.3 CloudFormation으로 EKS 생성
- 소스 Download & Run
# 소스 다운로드
git clone https://github.com/icebreaker70/aews.git
cd aews/4w
# 변수 지정
CLUSTER_NAME=myeks-sejkim
SSHKEYNAME=kp-sejkim
MYACCESSKEY=<IAM Uesr 액세스 키>
MYSECRETKEY=<IAM Uesr 시크릿 키>
WorkerNodeInstanceType=t3.xlarge # 워커노드 인스턴스 타입 변경 가능
# CloudFormation 스택 배포
aws cloudformation deploy --template-file myeks-4week.yaml --stack-name $CLUSTER_NAME --parameter-overrides KeyName=$SSHKEYNAME SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=$MYACCESSKEY MyIamUserSecretAccessKey=$MYSECRETKEY ClusterBaseName=$CLUSTER_NAME WorkerNodeInstanceType=$WorkerNodeInstanceType --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 작업용 EC2 IP 출력
aws cloudformation describe-stacks --stack-name myeks-sejkim --query 'Stacks[*].Outputs[0].OutputValue' --output text
13.209.18.170- (옵션) 배포 과정 살펴보기
# 운영서버 EC2 SSH 접속
ssh -i <SSH 키 파일 위치> ec2-user@$(aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text)
ssh -i ~/.ssh/kp-sejkim.pem ec2-user@$(aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text)
-------------------------------------------------
#
whoami
pwd
# cloud-init 실행 과정 로그 확인
tail -f /var/log/cloud-init-output.log
# eks 설정 파일 확인
cat myeks.yaml
# cloud-init 정상 완료 후 eksctl 실행 과정 로그 확인
tail -f /root/create-eks.log
2025-02-28 22:10:06 [▶] Setting credentials expiry window to 30 minutes
2025-02-28 22:10:06 [▶] role ARN for the current session is "arn:aws:iam::1**********3:user/sejkim@lgcns.com"
2025-02-28 22:10:06 [ℹ] eksctl version 0.204.0
2025-02-28 22:10:06 [ℹ] using region ap-northeast-2
2025-02-28 22:10:06 [✔] using existing VPC (vpc-0eb41de7d975ff702) and subnets (private:map[] public:map[ap-northeast-2a:{subnet-0d423a0a7d2984915 ap-northeast-2a 192.168.1.0/24 0 } ap-northeast-2b:{subnet-056d333fbfa400e9a ap-northeast-2b 192.168.2.0/24 0 } ap-northeast-2c:{subnet-044bb77b045bdfddb ap-northeast-2c 192.168.3.0/24 0 }])
2025-02-28 22:10:06 [!] custom VPC/subnets will be used; if resulting cluster doesn't function as expected, make sure to review the configuration of VPC/subnets
2025-02-28 22:10:06 [ℹ] nodegroup "ng1-sejkim" will use "" [AmazonLinux2023/1.31]
2025-02-28 22:10:06 [ℹ] using EC2 key pair "kp-sejkim"
2025-02-28 22:10:06 [ℹ] using Kubernetes version 1.31
2025-02-28 22:10:06 [ℹ] creating EKS cluster "myeks-sejkim" in "ap-northeast-2" region with managed nodes
2025-02-28 22:10:06 [▶] cfg.json = \
{
"kind": "ClusterConfig",
"apiVersion": "eksctl.io/v1alpha5",
"metadata": {
"name": "myeks-sejkim",
"region": "ap-northeast-2",
"version": "1.31"
},
"iam": {
"withOIDC": true,
"serviceAccounts": [
{
"metadata": {
"name": "aws-load-balancer-controller",
"namespace": "kube-system"
},
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": true,
"externalDNS": false,
"certManager": false,
"ebsCSIController": false,
"efsCSIController": false
}
}
],
"vpcResourceControllerPolicy": true
},
"accessConfig": {
"authenticationMode": "API_AND_CONFIG_MAP"
},
"vpc": {
"id": "vpc-0eb41de7d975ff702",
"cidr": "192.168.0.0/16",
"subnets": {
"public": {
"ap-northeast-2a": {
"id": "subnet-0d423a0a7d2984915",
"az": "ap-northeast-2a",
"cidr": "192.168.1.0/24"
},
"ap-northeast-2b": {
"id": "subnet-056d333fbfa400e9a",
"az": "ap-northeast-2b",
"cidr": "192.168.2.0/24"
},
"ap-northeast-2c": {
"id": "subnet-044bb77b045bdfddb",
"az": "ap-northeast-2c",
"cidr": "192.168.3.0/24"
}
}
},
"manageSharedNodeSecurityGroupRules": true,
"nat": {
"gateway": "Single"
},
"clusterEndpoints": {
"privateAccess": true,
"publicAccess": true
}
},
"addons": [
{
"name": "vpc-cni",
"version": "latest",
"attachPolicyARNs": [
"arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
],
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": false,
"externalDNS": false,
"certManager": false,
"ebsCSIController": false,
"efsCSIController": false
},
"configurationValues": "enableNetworkPolicy: \"true\""
},
{
"name": "kube-proxy",
"version": "latest",
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": false,
"externalDNS": false,
"certManager": false,
"ebsCSIController": false,
"efsCSIController": false
}
},
{
"name": "coredns",
"version": "latest",
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": false,
"externalDNS": false,
"certManager": false,
"ebsCSIController": false,
"efsCSIController": false
}
},
{
"name": "metrics-server",
"version": "latest",
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": false,
"externalDNS": false,
"certManager": false,
"ebsCSIController": false,
"efsCSIController": false
}
},
{
"name": "aws-ebs-csi-driver",
"version": "latest",
"wellKnownPolicies": {
"imageBuilder": false,
"autoScaler": false,
"awsLoadBalancerController": false,
"externalDNS": false,
"certManager": false,
"ebsCSIController": true,
"efsCSIController": false
}
}
],
"addonsConfig": {},
"privateCluster": {
"enabled": false,
"skipEndpointCreation": false
},
"managedNodeGroups": [
{
"name": "ng1-sejkim",
"amiFamily": "AmazonLinux2023",
"instanceType": "t3.xlarge",
"desiredCapacity": 3,
"minSize": 2,
"maxSize": 4,
"volumeSize": 60,
"ssh": {
"allow": true,
"publicKeyName": "kp-sejkim"
},
"labels": {
"alpha.eksctl.io/cluster-name": "myeks-sejkim",
"alpha.eksctl.io/nodegroup-name": "ng1-sejkim"
},
"privateNetworking": false,
"tags": {
"alpha.eksctl.io/nodegroup-name": "ng1-sejkim",
"alpha.eksctl.io/nodegroup-type": "managed"
},
"iam": {
"withAddonPolicies": {
"imageBuilder": false,
"autoScaler": false,
"externalDNS": true,
"certManager": true,
"appMesh": null,
"appMeshPreview": null,
"ebs": false,
"fsx": false,
"efs": false,
"awsLoadBalancerController": false,
"albIngress": false,
"xRay": false,
"cloudWatch": false
}
},
"securityGroups": {
"withShared": null,
"withLocal": null
},
"maxPodsPerNode": 60,
"volumeType": "gp3",
"volumeIOPS": 3000,
"volumeThroughput": 125,
"preBootstrapCommands": [
"dnf install nvme-cli links tree tcpdump sysstat ipvsadm ipset bind-utils htop -y"
],
"disableIMDSv1": true,
"disablePodIMDS": false,
"instanceSelector": {},
"releaseVersion": ""
}
],
"availabilityZones": [
"ap-northeast-2b",
"ap-northeast-2c",
"ap-northeast-2a"
]
}
2025-02-28 22:22:23 [▶] CreateStackInput = &cloudformation.CreateStackInput{StackName:(*string)(0xc000b7dd80), Capabilities:[]types.Capability{"CAPABILITY_IAM"}, ClientRequestToken:(*string)(nil), DisableRollback:(*bool)(0xc000249078), EnableTerminationProtection:(*bool)(nil), NotificationARNs:[]string(nil), OnFailure:"", Parameters:[]types.Parameter(nil), ResourceTypes:[]string(nil), RetainExceptOnCreate:(*bool)(nil), RoleARN:(*string)(nil), RollbackConfiguration:(*types.RollbackConfiguration)(nil), StackPolicyBody:(*string)(nil), StackPolicyURL:(*string)(nil), Tags:[]types.Tag{types.Tag{Key:(*string)(0xc000eb1c80), Value:(*string)(0xc000eb1c90), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000eb1ca0), Value:(*string)(0xc000eb1cb0), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000eb1cc0), Value:(*string)(0xc000eb1cd0), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc00047d400), Value:(*string)(0xc00047d410), noSmithyDocumentSerde:document.NoSerde{}}}, TemplateBody:(*string)(0xc00047d430), TemplateURL:(*string)(nil), TimeoutInMinutes:(*int32)(nil), noSmithyDocumentSerde:document.NoSerde{}}
2025-02-28 22:22:23 [ℹ] deploying stack "eksctl-myeks-sejkim-addon-vpc-cni"
2025-02-28 22:22:23 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-addon-vpc-cni"
2025-02-28 22:22:54 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-addon-vpc-cni"
2025-02-28 22:22:54 [ℹ] updating addon
2025-02-28 22:22:54 [▶] &{AddonName:0xc000a284b0 ClusterName:0xc000648870 AddonVersion:0xc000b7d140 ClientRequestToken:<nil> ConfigurationValues:0xc000a28540 PodIdentityAssociations:[] ResolveConflicts:OVERWRITE ServiceAccountRoleArn:0xc0005b3d60 noSmithyDocumentSerde:{}}
2025-02-28 22:22:54 [▶] &{CreatedAt:2025-02-28 13:22:54.357 +0000 UTC Errors:[] Id:0xc000e34fa0 Params:[{Type:AddonVersion Value:0xc000e34fb0 noSmithyDocumentSerde:{}} {Type:ServiceAccountRoleArn Value:0xc000e34fc0 noSmithyDocumentSerde:{}} {Type:ResolveConflicts Value:0xc000e34fd0 noSmithyDocumentSerde:{}} {Type:ConfigurationValues Value:0xc000e34fe0 noSmithyDocumentSerde:{}}] Status:InProgress Type:AddonUpdate noSmithyDocumentSerde:{}}
2025-02-28 22:23:04 [ℹ] addon "vpc-cni" active
2025-02-28 22:23:04 [▶] completed task: update VPC CNI to use IRSA if required
2025-02-28 22:23:04 [▶] completed task:
5 sequential sub-tasks: {
1 task: { create addons },
wait for control plane to become ready,
associate IAM OIDC provider,
2 sequential sub-tasks: {
create IAM role for serviceaccount "kube-system/aws-load-balancer-controller",
create serviceaccount "kube-system/aws-load-balancer-controller",
},
update VPC CNI to use IRSA if required,
}
2025-02-28 22:23:04 [▶] started task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:23:04 [▶] waiting for 1 parallel tasks to complete
2025-02-28 22:23:04 [▶] started task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:23:04 [▶] started task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:23:04 [▶] started task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:23:04 [ℹ] building managed nodegroup stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:23:04 [▶] CreateStackInput = &cloudformation.CreateStackInput{StackName:(*string)(0xc000a36b70), Capabilities:[]types.Capability{"CAPABILITY_IAM"}, ClientRequestToken:(*string)(nil), DisableRollback:(*bool)(0xc000b786f8), EnableTerminationProtection:(*bool)(nil), NotificationARNs:[]string(nil), OnFailure:"", Parameters:[]types.Parameter(nil), ResourceTypes:[]string(nil), RetainExceptOnCreate:(*bool)(nil), RoleARN:(*string)(nil), RollbackConfiguration:(*types.RollbackConfiguration)(nil), StackPolicyBody:(*string)(nil), StackPolicyURL:(*string)(nil), Tags:[]types.Tag{types.Tag{Key:(*string)(0xc000b60cb0), Value:(*string)(0xc000b60cc0), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b60cd0), Value:(*string)(0xc000b60ce0), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b60cf0), Value:(*string)(0xc000b60d00), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b606f0), Value:(*string)(0xc000b60700), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b60710), Value:(*string)(0xc000b60720), noSmithyDocumentSerde:document.NoSerde{}}}, TemplateBody:(*string)(0xc000b60730), TemplateURL:(*string)(nil), TimeoutInMinutes:(*int32)(nil), noSmithyDocumentSerde:document.NoSerde{}}
2025-02-28 22:23:05 [ℹ] deploying stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:23:05 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:23:35 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:24:31 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:25:44 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:26:50 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-nodegroup-ng1-sejkim"
2025-02-28 22:26:50 [▶] processing stack outputs
2025-02-28 22:26:50 [▶] completed task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:26:50 [▶] completed task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:26:50 [▶] completed task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:26:50 [▶] completed task: create managed nodegroup "ng1-sejkim"
2025-02-28 22:26:50 [▶] completed task:
2 sequential sub-tasks: {
5 sequential sub-tasks: {
1 task: { create addons },
wait for control plane to become ready,
associate IAM OIDC provider,
2 sequential sub-tasks: {
create IAM role for serviceaccount "kube-system/aws-load-balancer-controller",
create serviceaccount "kube-system/aws-load-balancer-controller",
},
update VPC CNI to use IRSA if required,
},
create managed nodegroup "ng1-sejkim",
}
2025-02-28 22:26:50 [ℹ] waiting for the control plane to become ready
2025-02-28 22:26:51 [▶] merging kubeconfig files
2025-02-28 22:26:51 [▶] setting current-context to sejkim@lgcns.com@myeks-sejkim.ap-northeast-2.eksctl.io
2025-02-28 22:26:51 [✔] saved kubeconfig as "/root/.kube/config"
2025-02-28 22:26:51 [ℹ] as you are using a GPU optimized instance type you will need to install NVIDIA Kubernetes device plugin.
2025-02-28 22:26:51 [ℹ] see the following page for instructions: https://github.com/NVIDIA/k8s-device-plugin
2025-02-28 22:26:51 [ℹ] no tasks
2025-02-28 22:26:51 [▶] no actual tasks
2025-02-28 22:26:51 [✔] all EKS cluster resources for "myeks-sejkim" have been created
2025-02-28 22:26:51 [ℹ] nodegroup "ng1-sejkim" has 3 node(s)
2025-02-28 22:26:51 [ℹ] node "ip-192-168-1-200.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [ℹ] node "ip-192-168-2-224.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [ℹ] node "ip-192-168-3-74.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [ℹ] waiting for at least 2 node(s) to become ready in "ng1-sejkim"
2025-02-28 22:26:51 [▶] event = watch.Event{Type:"ADDED", Object:(*v1.Node)(0xc000cfc008)}
2025-02-28 22:26:51 [▶] node "ip-192-168-1-200.ap-northeast-2.compute.internal" is ready in "ng1-sejkim"
2025-02-28 22:26:51 [▶] event = watch.Event{Type:"ADDED", Object:(*v1.Node)(0xc000cfc608)}
2025-02-28 22:26:51 [▶] node "ip-192-168-2-224.ap-northeast-2.compute.internal" is ready in "ng1-sejkim"
2025-02-28 22:26:51 [ℹ] nodegroup "ng1-sejkim" has 3 node(s)
2025-02-28 22:26:51 [ℹ] node "ip-192-168-1-200.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [ℹ] node "ip-192-168-2-224.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [ℹ] node "ip-192-168-3-74.ap-northeast-2.compute.internal" is ready
2025-02-28 22:26:51 [✔] created 1 managed nodegroup(s) in cluster "myeks-sejkim"
2025-02-28 22:26:51 [▶] started task: create addons
2025-02-28 22:26:52 [▶] resolve conflicts set to OVERWRITE
2025-02-28 22:26:52 [▶] addon: &{aws-ebs-csi-driver v1.40.0-eksbuild.1 [] map[] {false false false false false true false} map[] <nil> false true [] [] []}
2025-02-28 22:26:52 [ℹ] IRSA is set for "aws-ebs-csi-driver" addon; will use this to configure IAM permissions
2025-02-28 22:26:52 [!] the recommended way to provide IAM permissions for "aws-ebs-csi-driver" addon is via pod identity associations; after addon creation is completed, run `eksctl utils migrate-to-pod-identity`
2025-02-28 22:26:52 [ℹ] creating role using provided policies for "aws-ebs-csi-driver" addon
2025-02-28 22:26:52 [▶] CreateStackInput = &cloudformation.CreateStackInput{StackName:(*string)(0xc000e34040), Capabilities:[]types.Capability{"CAPABILITY_IAM"}, ClientRequestToken:(*string)(nil), DisableRollback:(*bool)(0xc000702d18), EnableTerminationProtection:(*bool)(nil), NotificationARNs:[]string(nil), OnFailure:"", Parameters:[]types.Parameter(nil), ResourceTypes:[]string(nil), RetainExceptOnCreate:(*bool)(nil), RoleARN:(*string)(nil), RollbackConfiguration:(*types.RollbackConfiguration)(nil), StackPolicyBody:(*string)(nil), StackPolicyURL:(*string)(nil), Tags:[]types.Tag{types.Tag{Key:(*string)(0xc000b7c7d0), Value:(*string)(0xc000b7c7e0), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b7c7f0), Value:(*string)(0xc000b7c800), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000b7c810), Value:(*string)(0xc000b7c820), noSmithyDocumentSerde:document.NoSerde{}}, types.Tag{Key:(*string)(0xc000e34a00), Value:(*string)(0xc000e34a10), noSmithyDocumentSerde:document.NoSerde{}}}, TemplateBody:(*string)(0xc000e34a20), TemplateURL:(*string)(nil), TimeoutInMinutes:(*int32)(nil), noSmithyDocumentSerde:document.NoSerde{}}
2025-02-28 22:26:53 [ℹ] deploying stack "eksctl-myeks-sejkim-addon-aws-ebs-csi-driver"
2025-02-28 22:26:53 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-addon-aws-ebs-csi-driver"
2025-02-28 22:27:23 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-addon-aws-ebs-csi-driver"
2025-02-28 22:28:12 [ℹ] waiting for CloudFormation stack "eksctl-myeks-sejkim-addon-aws-ebs-csi-driver"
2025-02-28 22:28:12 [ℹ] creating addon: aws-ebs-csi-driver
2025-02-28 22:28:12 [▶] EKS Create Addon output: {%!s(*string=0xc000102d90) %!s(*string=0xc000102d70) %!s(*string=0xc000102da0) %!s(*string=0xc000102d80) %!s(*string=<nil>) 2025-02-28 13:28:12.607 +0000 UTC %!s(*types.AddonHealth=&{[] {}}) %!s(*types.MarketplaceInformation=<nil>) 2025-02-28 13:28:12.621 +0000 UTC %!s(*string=<nil>) [] %!s(*string=<nil>) %!s(*string=0xc000102db0) CREATING map[] {}}
2025-02-28 22:29:47 [ℹ] addon "aws-ebs-csi-driver" active
2025-02-28 22:29:47 [▶] completed task: create addons
2025-02-28 22:29:47 [▶] found authenticator: aws
2025-02-28 22:29:47 [▶] kubectl: "/usr/local/bin/kubectl"
2025-02-28 22:29:47 [▶] kubectl version: v1.31.2-eks-94953ac
2025-02-28 22:29:48 [ℹ] kubectl command should work with "/root/.kube/config", try 'kubectl --kubeconfig=/root/.kube/config get nodes'
2025-02-28 22:29:48 [✔] EKS cluster "myeks-sejkim" in "ap-northeast-2" region is ready1.4 자신의 PC에서 AWS EKS 설치 확인
- 스택 생성 시작 후 20분 후 접속 할 것
- EKS 설치 확인 및 kubeconfig 업데이트
# 변수 지정
CLUSTER_NAME=myeks-sejkim
SSHKEYNAME=kp-sejkim
# cluster, nodegroup 확인
eksctl get cluster
NAME REGION EKSCTL CREATED
myeks-sejkim ap-northeast-2 True
eksctl get nodegroup --cluster $CLUSTER_NAME
CLUSTER NODEGROUP STATUS CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID ASG NAME TYPE
myeks-sejkim ng1-sejkim ACTIVE 2025-02-28T13:23:30Z 2 4 3 t3.xlarge AL2023_x86_64_STANDARD eks-ng1-sejkim-9acaa65c-f537-492c-4c19-27525061a1dd managed
eksctl get addon --cluster $CLUSTER_NAME
NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES POD IDENTITY ASSOCIATION ROLES
aws-ebs-csi-driver v1.40.0-eksbuild.1 ACTIVE 0 arn:aws:iam::1**********3:role/eksctl-myeks-sejkim-addon-aws-ebs-csi-driver-Role1-1CvINJuzjoup
coredns v1.11.4-eksbuild.2 ACTIVE 0
kube-proxy v1.31.3-eksbuild.2 ACTIVE 0
metrics-server v0.7.2-eksbuild.2 ACTIVE 0
vpc-cni v1.19.3-eksbuild.1 ACTIVE 0 arn:aws:iam::1**********3:role/eksctl-myeks-sejkim-addon-vpc-cni-Role1-71e9B3zp9z3P enableNetworkPolicy: "true"
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
NAMESPACE NAME ROLE ARN
kube-system aws-load-balancer-controller arn:aws:iam::1**********3:role/eksctl-myeks-sejkim-addon-iamserviceaccount-k-Role1-auqRBfeDeo0z
# kubeconfig 생성
aws sts get-caller-identity --query Arn
aws eks update-kubeconfig --name myeks-sejkim --user-alias <위 출력된 자격증명 사용자>
aws eks update-kubeconfig --name myeks-sejkim --user-alias admin
kubectl cluster-info
kubectl ns default
kubectl get node -v6
I0228 22:54:10.643493 53194 loader.go:402] Config loaded from file: /Users/sjkim/.kube/config
I0228 22:54:10.644945 53194 envvar.go:172] "Feature gate default state" feature="ClientsAllowCBOR" enabled=false
I0228 22:54:10.644953 53194 envvar.go:172] "Feature gate default state" feature="ClientsPreferCBOR" enabled=false
I0228 22:54:10.644956 53194 envvar.go:172] "Feature gate default state" feature="InformerResourceVersion" enabled=false
I0228 22:54:10.644958 53194 envvar.go:172] "Feature gate default state" feature="WatchListClient" enabled=false
I0228 22:54:11.448805 53194 round_trippers.go:560] GET https://21F59F962028C7F4B055D713C440B26F.gr7.ap-northeast-2.eks.amazonaws.com/api/v1/nodes?limit=500 200 OK in 796 milliseconds
NAME STATUS ROLES AGE VERSION
ip-192-168-1-200.ap-northeast-2.compute.internal Ready <none> 29m v1.31.5-eks-5d632ec
ip-192-168-2-224.ap-northeast-2.compute.internal Ready <none> 29m v1.31.5-eks-5d632ec
ip-192-168-3-74.ap-northeast-2.compute.internal Ready <none> 29m v1.31.5-eks-5d632ec
kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE CAPACITYTYPE ZONE
ip-192-168-1-200.ap-northeast-2.compute.internal Ready <none> 29m v1.31.5-eks-5d632ec t3.xlarge ON_DEMAND ap-northeast-2a
ip-192-168-2-224.ap-northeast-2.compute.internal Ready <none> 30m v1.31.5-eks-5d632ec t3.xlarge ON_DEMAND ap-northeast-2b
ip-192-168-3-74.ap-northeast-2.compute.internal Ready <none> 30m v1.31.5-eks-5d632ec t3.xlarge ON_DEMAND ap-northeast-2c
kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system aws-node-f5wvp 2/2 Running 0 30m
kube-system aws-node-mmsfl 2/2 Running 0 30m
kube-system aws-node-zzgph 2/2 Running 0 30m
kube-system coredns-86f5954566-2qnhg 1/1 Running 0 36m
kube-system coredns-86f5954566-ndk4w 1/1 Running 0 36m
kube-system ebs-csi-controller-844b978c49-ppbhm 6/6 Running 0 27m
kube-system ebs-csi-controller-844b978c49-xhktg 6/6 Running 0 27m
kube-system ebs-csi-node-8k4z5 3/3 Running 0 27m
kube-system ebs-csi-node-grbzd 3/3 Running 0 27m
kube-system ebs-csi-node-qnwgd 3/3 Running 0 27m
kube-system kube-proxy-bg9lx 1/1 Running 0 30m
kube-system kube-proxy-bqrt4 1/1 Running 0 30m
kube-system kube-proxy-qs7x6 1/1 Running 0 30m
kube-system metrics-server-6bf5998d9c-lgb55 1/1 Running 0 36m
kube-system metrics-server-6bf5998d9c-nzkld 1/1 Running 0 36m
kubectl get pdb -n kube-system
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
coredns N/A 1 1 37m
ebs-csi-controller N/A 1 1 28m
metrics-server N/A 1 1 37m
# krew 플러그인 확인
kubectl krew list
PLUGIN VERSION
df-pv v0.3.0
get-all v1.3.8
neat v2.0.4
stern v1.31.0
whoami v0.0.46
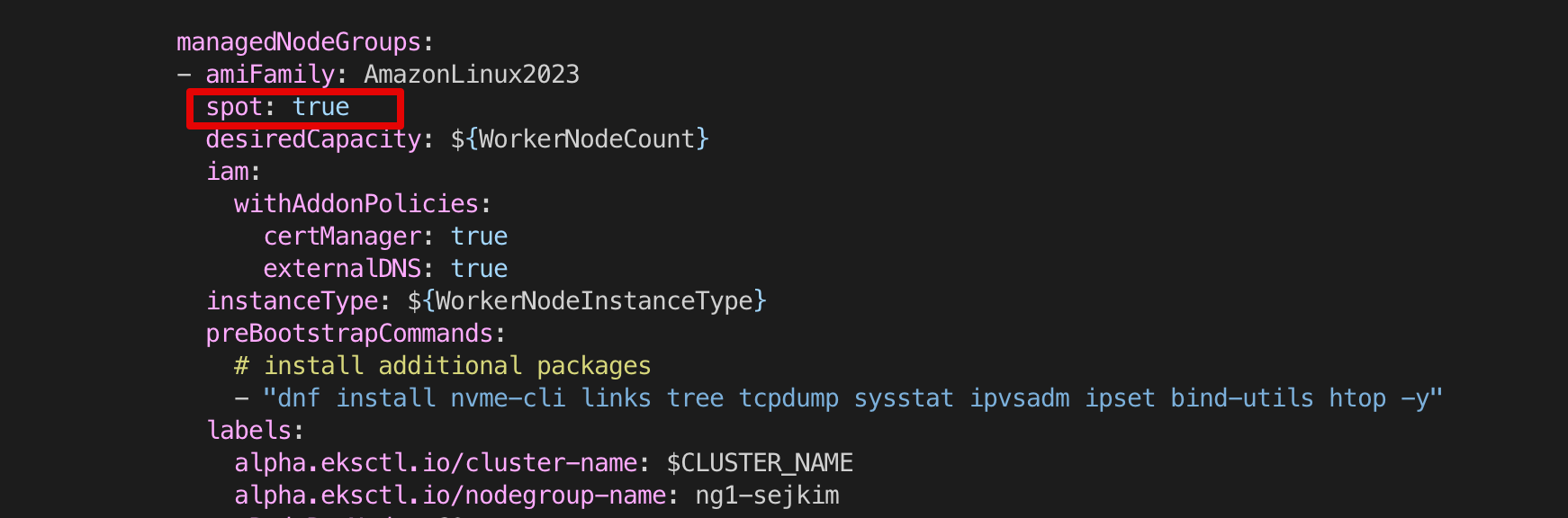
kubectl get-all1.5 비용절감을 위해 Spot으로 Node 변경
- 방법1: eksctl managedNodeGroup에 spot: true 추가
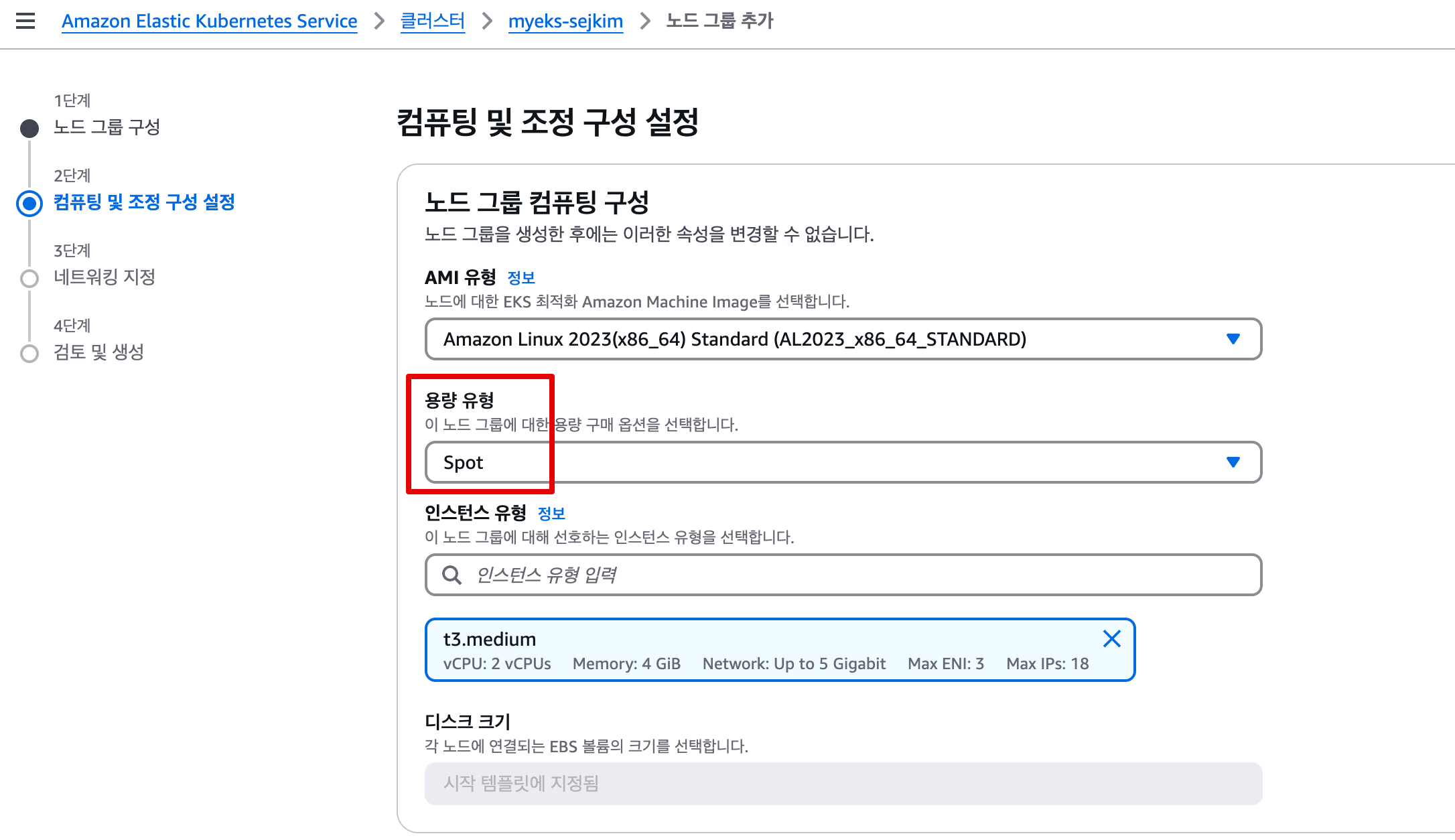
- 방법2: NodeGroup 콘솔에서 재 생성
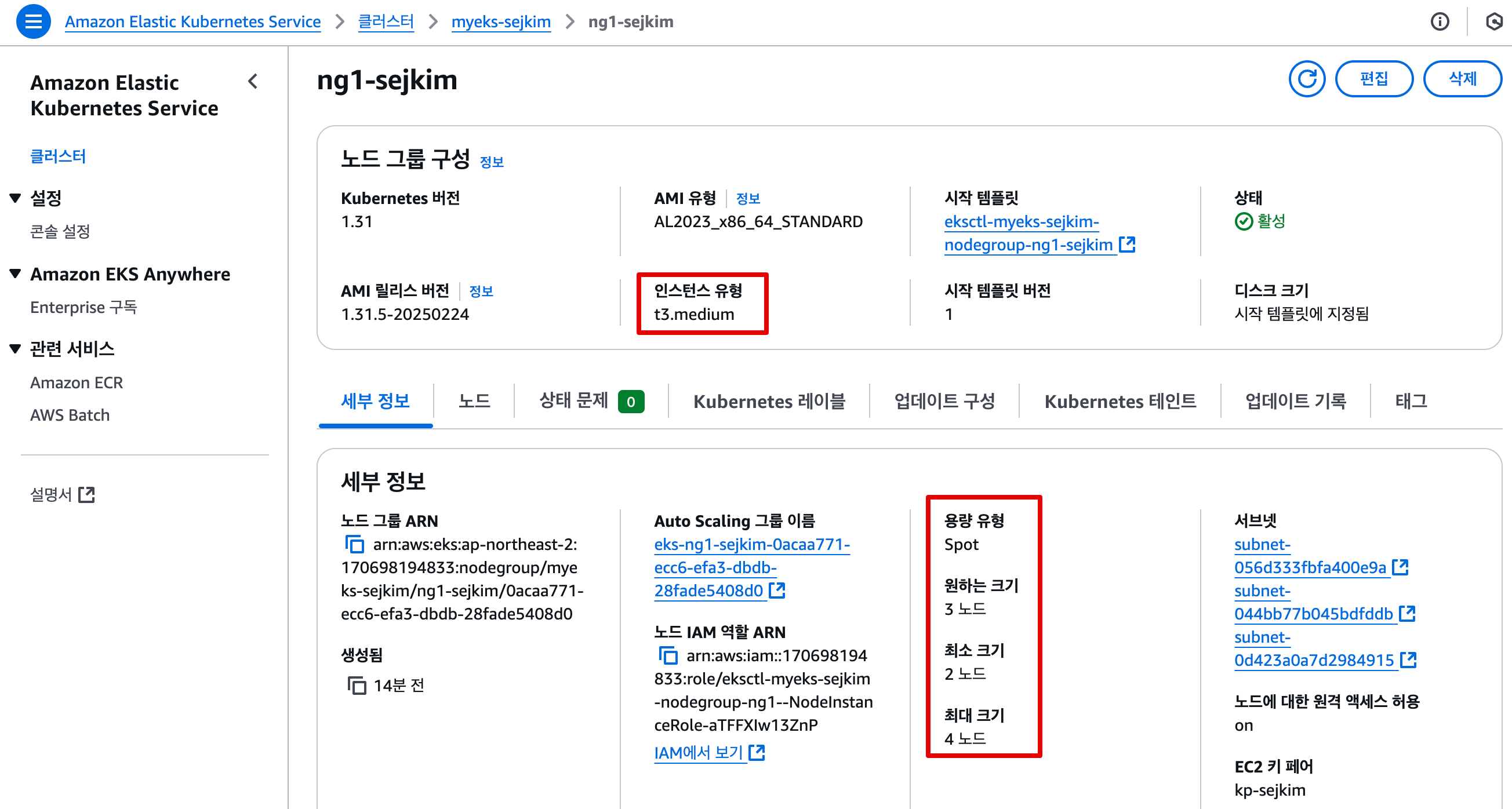
- NodeGroup 생성 결과
1.6 운영서버(operator-host) ssh 접속
- SSH 접속 후 기본 확인
# default 네임스페이스 적용
kubectl ns default
# 환경변수 정보 확인
(admin:default) [root@operator-sejkim-host ~]# export | egrep 'ACCOUNT|AWS_|CLUSTER|KUBERNETES|VPC|Subnet' | egrep -v 'KEY'
declare -x ACCOUNT_ID="1**********3"
declare -x AWS_DEFAULT_REGION="ap-northeast-2"
declare -x AWS_PAGER=""
declare -x CLUSTER_NAME="myeks-sejkim"
declare -x KUBERNETES_VERSION="1.31"
declare -x PubSubnet1="subnet-0d423a0a7d2984915"
declare -x PubSubnet2="subnet-056d333fbfa400e9a"
declare -x PubSubnet3="subnet-044bb77b045bdfddb"
declare -x VPCID="vpc-0eb41de7d975ff702"
# krew 플러그인 확인
(admin:default) [root@operator-sejkim-host ~]# kubectl krew list
PLUGIN VERSION
ctx v0.9.5
df-pv v0.3.0
get-all v1.3.8
krew v0.4.4
neat v2.0.4
ns v0.9.5
oomd v0.0.7
stern v1.32.0
view-secret v0.13.0- 노드 정보 확인 및 SSH 접속
# 인스턴스 정보 확인
aws ec2 describe-instances --query "Reservations[*].Instances[*].{InstanceID:InstanceId, PublicIPAdd:PublicIpAddress, PrivateIPAdd:PrivateIpAddress, InstanceName:Tags[?Key=='Name']|[0].Value, Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
-------------------------------------------------------------------------------------------------------
| DescribeInstances |
+---------------------+--------------------------------+----------------+-----------------+-----------+
| InstanceID | InstanceName | PrivateIPAdd | PublicIPAdd | Status |
+---------------------+--------------------------------+----------------+-----------------+-----------+
| i-0526223c5f29ce1e0| operator-sejkim-host | 172.20.1.100 | 13.209.18.170 | running |
| i-062fa2ad1251e461f| myeks-sejkim-ng1-sejkim-Node | 192.168.1.209 | 43.200.2.236 | running |
| i-09ca78d17c1a2f2fb| myeks-sejkim-ng1-sejkim-Node | 192.168.2.252 | 43.203.148.200 | running |
| i-0721c5648cfeae008| myeks-sejkim-ng1-sejkim-Node | 192.168.3.39 | 54.180.79.196 | running |
+---------------------+--------------------------------+-----------------+----------------+-----------+
# 노드 IP 확인 및 PrivateIP 변수 지정
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
N3=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
192.168.1.209, 192.168.2.252, 192.168.3.39
# 노드 IP 로 ping 테스트
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ping -c 1 $i ; echo; done- 🍎 자리 이동으로 인해 운영서버 EC2에 접속하는 공인IP가 변경 시 보안 그룹에 추가하는 방법
# 자신의 PC(맥 기준)에서 아래 명령어 실행
MYSGID=$(aws ec2 describe-security-groups --filters "Name=tag:Name,Values=operator-HOST-SG" --query "SecurityGroups[*].[GroupId]" --output text)
aws ec2 authorize-security-group-ingress --group-id $MYSGID --protocol '-1' --cidr $(curl -s ipinfo.io/ip)/321.7 EKS 배포 후 실습 편의를 위한 설정
- macOS ⇒ 실습 완료 후 삭제 할 것!
# 실습 완료 후 삭제 할 것!
cat << EOF >> ~/.zshrc
# eksworkshop
export CLUSTER_NAME=myeks-sejkim
export VPCID=$(aws ec2 describe-vpcs --filters "Name=tag:Name,Values=$CLUSTER_NAME-VPC" --query 'Vpcs[*].VpcId' --output text)
export PubSubnet1=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet1" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet2=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet2" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet3=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-Vpc1PublicSubnet3" --query "Subnets[0].[SubnetId]" --output text)
export N1=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-sejkim-Node" "Name=availability-zone,Values=ap-northeast-2a" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N2=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-sejkim-Node" "Name=availability-zone,Values=ap-northeast-2b" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export N3=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$CLUSTER_NAME-ng1-sejkim-Node" "Name=availability-zone,Values=ap-northeast-2c" --query 'Reservations[*].Instances[*].PublicIpAddress' --output text)
export CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
MyDomain=ksj7279.click # 각자 자신의 도메인 이름 입력
MyDnzHostedZoneId=$(aws route53 list-hosted-zones-by-name --dns-name "$MyDomain." --query "HostedZones[0].Id" --output text)
EOF
# [신규 터미널] 확인
echo $CLUSTER_NAME $VPCID $PubSubnet1 $PubSubnet2 $PubSubnet3
echo $N1 $N2 $N3 $MyDomain $MyDnzHostedZoneId
tail -n 15 ~/.zshrc
# eksworkshop
export CLUSTER_NAME=myeks-sejkim
export VPCID=vpc-0eb41de7d975ff702
export PubSubnet1=subnet-0d423a0a7d2984915
export PubSubnet2=subnet-056d333fbfa400e9a
export PubSubnet3=subnet-044bb77b045bdfddb
export N1=43.200.2.236
export N2=43.203.148.200
export N3=54.180.79.196
export CERT_ARN=arn:aws:acm:ap-northeast-2:1**********3:certificate/415404eb-e2e2-4744-b2e4-1108735b5903
MyDomain=ksj7279.click # 각자 자신의 도메인 이름 입력
MyDnzHostedZoneId=/hostedzone/Z07567843J1EUFBDC36UV1.8 Controller 추가 설치
- kube-ops-view(Ingress), AWS LoadBalancer Controller, ExternalDNS, gp3 storageclass 설치
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=ClusterIP --set env.TZ="Asia/Seoul" --namespace kube-system
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:8080
# gp3 스토리지 클래스 생성
cat <<EOF | kubectl apply -f -
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: gp3
annotations:
storageclass.kubernetes.io/is-default-class: "true"
allowVolumeExpansion: true
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
allowAutoIOPSPerGBIncrease: 'true'
encrypted: 'true'
fsType: xfs # 기본값이 ext4
EOF
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 169m
gp3 (default) ebs.csi.aws.com Delete WaitForFirstConsumer true 66s
# ExternalDNS
curl -s https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml | MyDomain=$MyDomain MyDnzHostedZoneId=$MyDnzHostedZoneId envsubst | kubectl apply -f -
# AWS LoadBalancerController
helm repo add eks https://aws.github.io/eks-charts
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
# kubeopsview 용 Ingress 설정 : group 설정으로 1대의 ALB를 여러개의 ingress 에서 공용 사용
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
labels:
app.kubernetes.io/name: kubeopsview
name: kubeopsview
namespace: kube-system
spec:
ingressClassName: alb
rules:
- host: kubeopsview.$MyDomain
http:
paths:
- backend:
service:
name: kube-ops-view
port:
number: 8080
path: /
pathType: Prefix
EOF- 설치된 정보 확인
# 설치된 파드 정보 확인
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
aws-load-balancer-controller-86ff7688d-jgchz 1/1 Running 0 10m
aws-load-balancer-controller-86ff7688d-xnhrv 1/1 Running 0 10m
aws-node-8b6qf 2/2 Running 0 124m
aws-node-k5bxn 2/2 Running 0 49m
aws-node-npj25 2/2 Running 0 124m
coredns-86f5954566-5qrwz 1/1 Running 0 128m
coredns-86f5954566-j7hz4 1/1 Running 0 124m
ebs-csi-controller-844b978c49-2j5kw 6/6 Running 0 124m
ebs-csi-controller-844b978c49-t5vwb 6/6 Running 0 128m
ebs-csi-node-bc4qm 3/3 Running 0 124m
ebs-csi-node-dff9d 3/3 Running 0 49m
ebs-csi-node-tlg49 3/3 Running 0 124m
external-dns-7dd89bd9bc-7zdkt 1/1 Running 0 12m
kube-ops-view-657dbc6cd8-gc8lm 1/1 Running 0 16m
kube-proxy-x747m 1/1 Running 0 124m
kube-proxy-z9fzq 1/1 Running 0 124m
kube-proxy-zrbpw 1/1 Running 0 49m
metrics-server-6bf5998d9c-9x9jn 1/1 Running 0 123m
metrics-server-6bf5998d9c-qgnsm 1/1 Running 0 128m
# service, ep, ingress 확인
kubectl get ingress,svc,ep -n kube-system
NAME CLASS HOSTS ADDRESS PORTS AGE
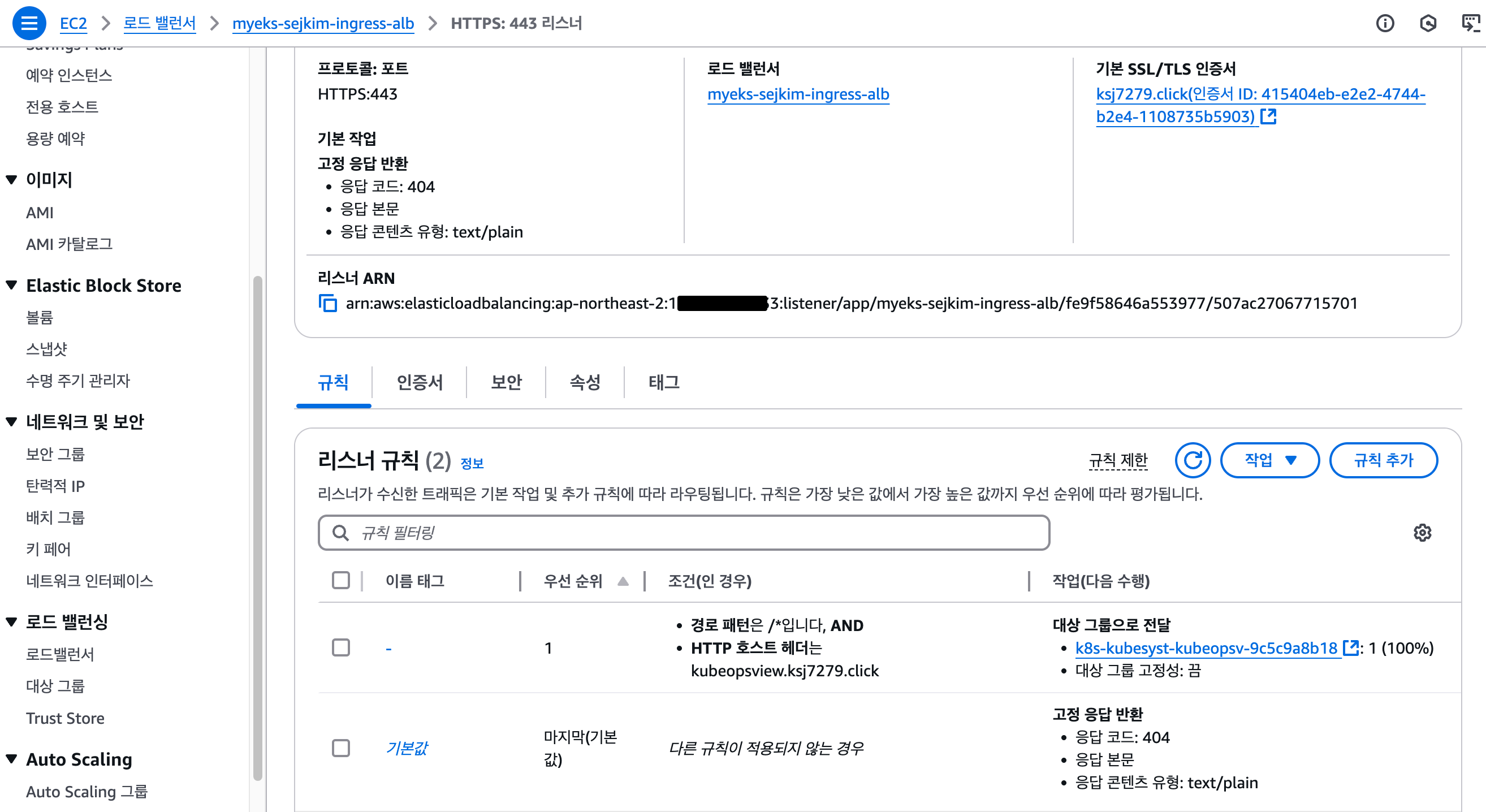
ingress.networking.k8s.io/kubeopsview alb kubeopsview.ksj7279.click myeks-sejkim-ingress-alb-1893285509.ap-northeast-2.elb.amazonaws.com 80 10m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/aws-load-balancer-webhook-service ClusterIP 10.100.11.174 <none> 443/TCP 10m
service/eks-extension-metrics-api ClusterIP 10.100.103.203 <none> 443/TCP 3h3m
service/kube-dns ClusterIP 10.100.0.10 <none> 53/UDP,53/TCP,9153/TCP 179m
service/kube-ops-view ClusterIP 10.100.58.214 <none> 8080/TCP 16m
service/metrics-server ClusterIP 10.100.109.204 <none> 443/TCP 179m
NAME ENDPOINTS AGE
endpoints/aws-load-balancer-webhook-service 192.168.2.241:9443,192.168.3.166:9443 10m
endpoints/eks-extension-metrics-api 172.0.32.0:10443 3h3m
endpoints/kube-dns 192.168.1.130:53,192.168.3.115:53,192.168.1.130:53 + 3 more... 179m
endpoints/kube-ops-view 192.168.2.94:8080 16m
endpoints/metrics-server 192.168.1.188:10251,192.168.3.113:10251 179m
# Kube Ops View 접속 정보 확인
echo -e "Kube Ops View URL = https://kubeopsview.$MyDomain/#scale=1.5"
Kube Ops View URL = https://kubeopsview.ksj7279.click/#scale=1.5
open "https://kubeopsview.$MyDomain/#scale=1.5" # macOS1.9 prometheus-stack 설치 by helm
- 참조 Link
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
service:
type: NodePort
nodePort: 30001
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
service:
type: NodePort
nodePort: 30002
defaultRules:
create: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
alertmanager:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
# 각각 웹 접속 실행
## Windows(WSL2) 사용자는 아래 주소를 자신의 웹 브라우저에서 기입 후 직접 접속, 이후에도 동일.
open http://127.0.0.1:30001 # macOS
open http://127.0.0.1:30002 # macOS
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2025-03-01 01:36:45.551385 +0900 KST deployed kube-prometheus-stack-69.3.1 v0.80.0
kubectl get pod,svc,ingress,pvc -n monitoring
NAME READY STATUS RESTARTS AGE
pod/kube-prometheus-stack-grafana-c844968cd-rf6xn 3/3 Running 0 11m
pod/kube-prometheus-stack-kube-state-metrics-5dbfbd4b9-st52s 1/1 Running 0 11m
pod/kube-prometheus-stack-operator-76bdd654bf-544qr 1/1 Running 0 11m
pod/kube-prometheus-stack-prometheus-node-exporter-kkjmd 1/1 Running 0 11m
pod/kube-prometheus-stack-prometheus-node-exporter-pjhkz 1/1 Running 0 11m
pod/kube-prometheus-stack-prometheus-node-exporter-pw2f8 1/1 Running 0 11m
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 11m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-grafana NodePort 10.100.195.242 <none> 80:30002/TCP 11m
service/kube-prometheus-stack-kube-state-metrics ClusterIP 10.100.202.31 <none> 8080/TCP 11m
service/kube-prometheus-stack-operator ClusterIP 10.100.179.61 <none> 443/TCP 11m
service/kube-prometheus-stack-prometheus NodePort 10.100.39.248 <none> 9090:30001/TCP,8080:32175/TCP 11m
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.78.209 <none> 9100/TCP 11m
service/prometheus-operated ClusterIP None <none> 9090/TCP 11m
kubectl get-all -n monitoring
kubectl get prometheus,servicemonitors -n monitoring
NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
prometheus.monitoring.coreos.com/kube-prometheus-stack-prometheus v3.1.0 1 1 True True 22m
NAME AGE
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-grafana 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-controller-manager 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-etcd 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-proxy 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-scheduler 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-state-metrics 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kubelet 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-operator 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus 22m
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus-node-exporter 22m
kubectl get crd | grep monitoring
alertmanagerconfigs.monitoring.coreos.com 2025-02-28T16:36:40Z
alertmanagers.monitoring.coreos.com 2025-02-28T16:36:41Z
podmonitors.monitoring.coreos.com 2025-02-28T16:36:41Z
probes.monitoring.coreos.com 2025-02-28T16:36:41Z
prometheusagents.monitoring.coreos.com 2025-02-28T16:36:41Z
prometheuses.monitoring.coreos.com 2025-02-28T16:36:42Z
prometheusrules.monitoring.coreos.com 2025-02-28T16:36:42Z
scrapeconfigs.monitoring.coreos.com 2025-02-28T16:36:43Z
servicemonitors.monitoring.coreos.com 2025-02-28T16:36:43Z
thanosrulers.monitoring.coreos.com 2025-02-28T16:36:44Z
# 참조 - 삭제 명령어
helm uninstall -n monitoring kube-prometheus-stack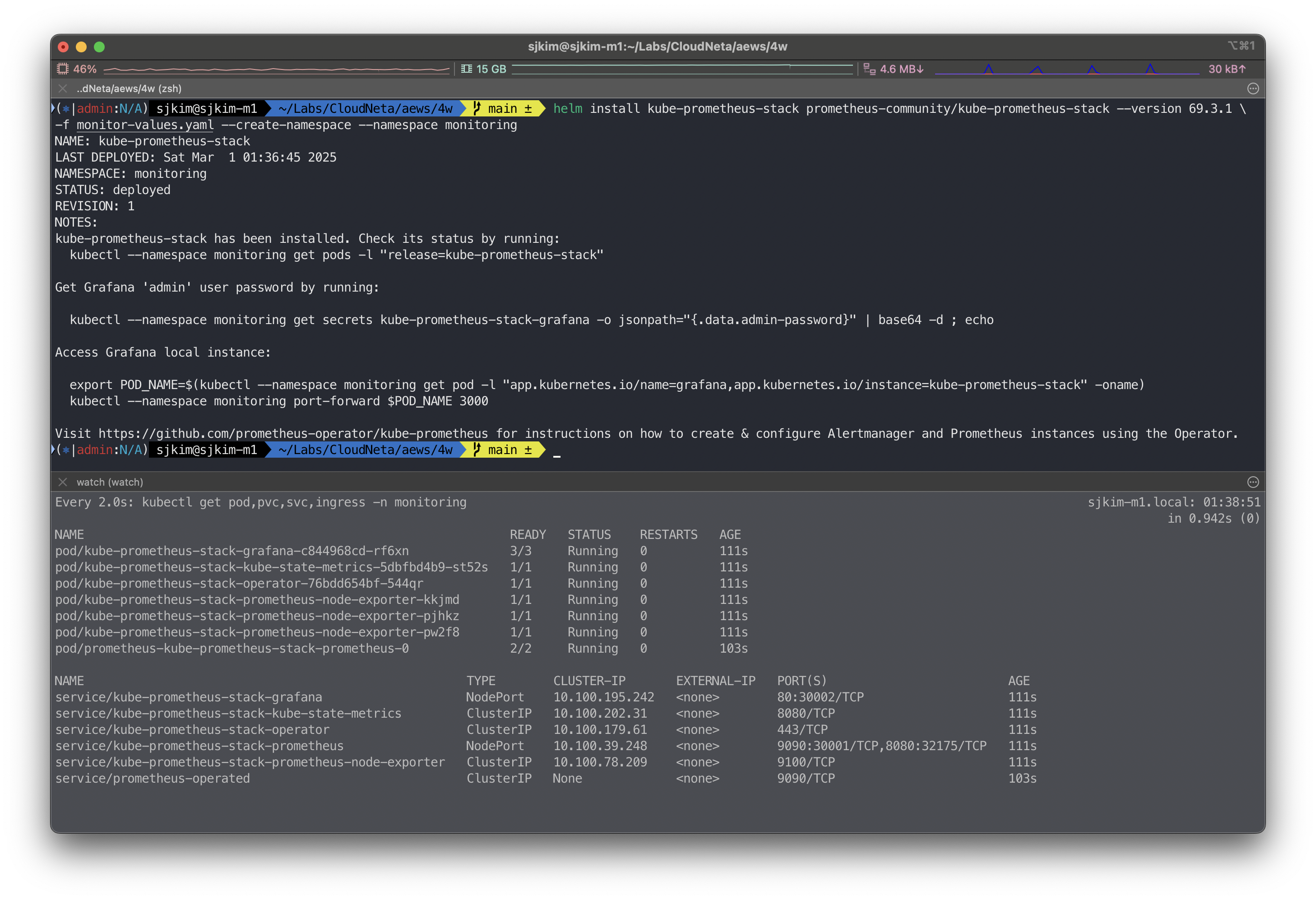
2. Observability 개념 정의
2.1 Monitoring vs 관측 가능성
- 정의와 차이점
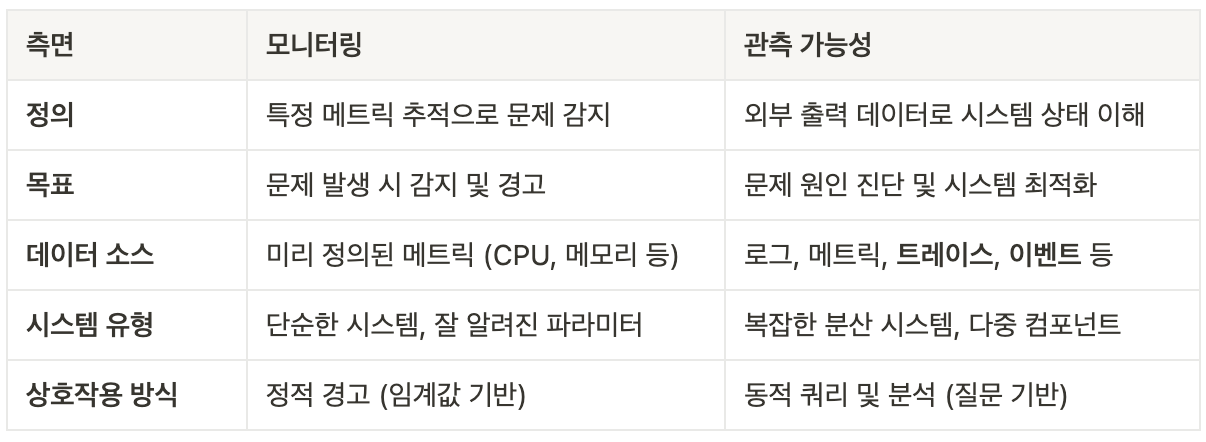
- 모니터링의 정의와 특징 : 사전에 정의된 기준을 기반으로 시스템의 상태를 감시에 중점
- 모니터링은 IT 시스템의 운영 상태를 추적하고, 성능 지표를 수집하며, 예상치 못한 문제를 조기에 감지하는 과정입니다. What is IT monitoring? | Definition from TechTarget에 따르면, 모니터링은 하드웨어와 소프트웨어의 메트릭을 수집하여 모든 것이 정상적으로 작동하는지 확인하고, 문제를 탐지하며 해결하는 데 사용됩니다.
- 주요 활동: CPU 사용량, 메모리 사용량, 응답 시간, 오류율 등 특정 지표를 지속적으로 측정.
- 목적: 시스템 다운타임을 방지하고, 경고를 통해 팀이 빠르게 대응할 수 있도록 함.
- 빈도: 연속적이거나 일정 간격(일간, 주간, 월간)으로 수행됨.
- 예시: Google의 SRE 책(What’s IT Monitoring? IT Systems Monitoring Explained | Splunk)에서는 모니터링을 "시스템에 대한 실시간 정량 데이터 수집, 처리, 집계, 표시"로 정의하며, 쿼리 수, 오류 수, 처리 시간 등을 포함한다고 설명합니다.
- 모니터링은 주로 단순하고 잘 알려진 시스템에 적합하며, 미리 설정된 임계값을 초과하면 알림을 발송하는 방식으로 작동합니다. 예를 들어, 서버의 CPU 사용량이 90%를 초과하면 경고가 발생할 수 있습니다.
- 모니터링은 IT 시스템의 운영 상태를 추적하고, 성능 지표를 수집하며, 예상치 못한 문제를 조기에 감지하는 과정입니다. What is IT monitoring? | Definition from TechTarget에 따르면, 모니터링은 하드웨어와 소프트웨어의 메트릭을 수집하여 모든 것이 정상적으로 작동하는지 확인하고, 문제를 탐지하며 해결하는 데 사용됩니다.
- 관측 가능성의 정의와 특징 : 수집된 다양한 데이터를 활용하여 예측되지 않은 문제까지 분석
- 관측 가능성은 시스템의 내부 상태를 외부 출력 데이터(로그, 메트릭, 트레이스)를 통해 이해할 수 있는 능력을 의미합니다. Observability (software) - Wikipedia에 따르면, 관측 가능성은 소프트웨어 엔지니어링에서 프로그램 실행, 모듈 내부 상태, 컴포넌트 간 통신 데이터를 수집하고 분석하는 능력을 말합니다.
- 핵심 데이터: 로그(이벤트 기록), 메트릭(수치 데이터), 트레이스(요청 흐름 추적), 그리고 일부 경우 이벤트가 포함됩니다.
- 목적: 복잡한 분산 시스템에서 문제를 진단하고, 새로운 문제를 탐지하며, 시스템 동작을 최적화.
- What Is Observability? | IBM에서는 관측 가능성을 "복잡한 시스템의 내부 상태를 외부 출력 데이터로 이해하는 능력"으로 정의하며, 특히 클라우드 환경에서 중요하다고 강조합니다.
- 예시: 애플리케이션이 느려진 이유가 특정 마이크로서비스의 데이터베이스 연결 문제 때문이라는 것을 로그와 트레이스를 통해 파악.
- 관측 가능성은 특히 현대의 분산 아키텍처(예: 마이크로서비스, 컨테이너)에서 필수적이며, 미리 정의되지 않은 질문에 답할 수 있는 유연성을 제공합니다. 예를 들어, "왜 이 특정 요청이 실패했는가?"라는 질문을 로그와 트레이스를 통해 분석할 수 있습니다. → 콘텍스트 context(문맥) 정보를 제공
- APM 대신 추적 tracing 이라고 부르며, 계측 instrumentation 과 텔레메트리 telemetry 라는 용어를 범용적으로 사용함.
- 관측 가능성은 시스템의 내부 상태를 외부 출력 데이터(로그, 메트릭, 트레이스)를 통해 이해할 수 있는 능력을 의미합니다. Observability (software) - Wikipedia에 따르면, 관측 가능성은 소프트웨어 엔지니어링에서 프로그램 실행, 모듈 내부 상태, 컴포넌트 간 통신 데이터를 수집하고 분석하는 능력을 말합니다.
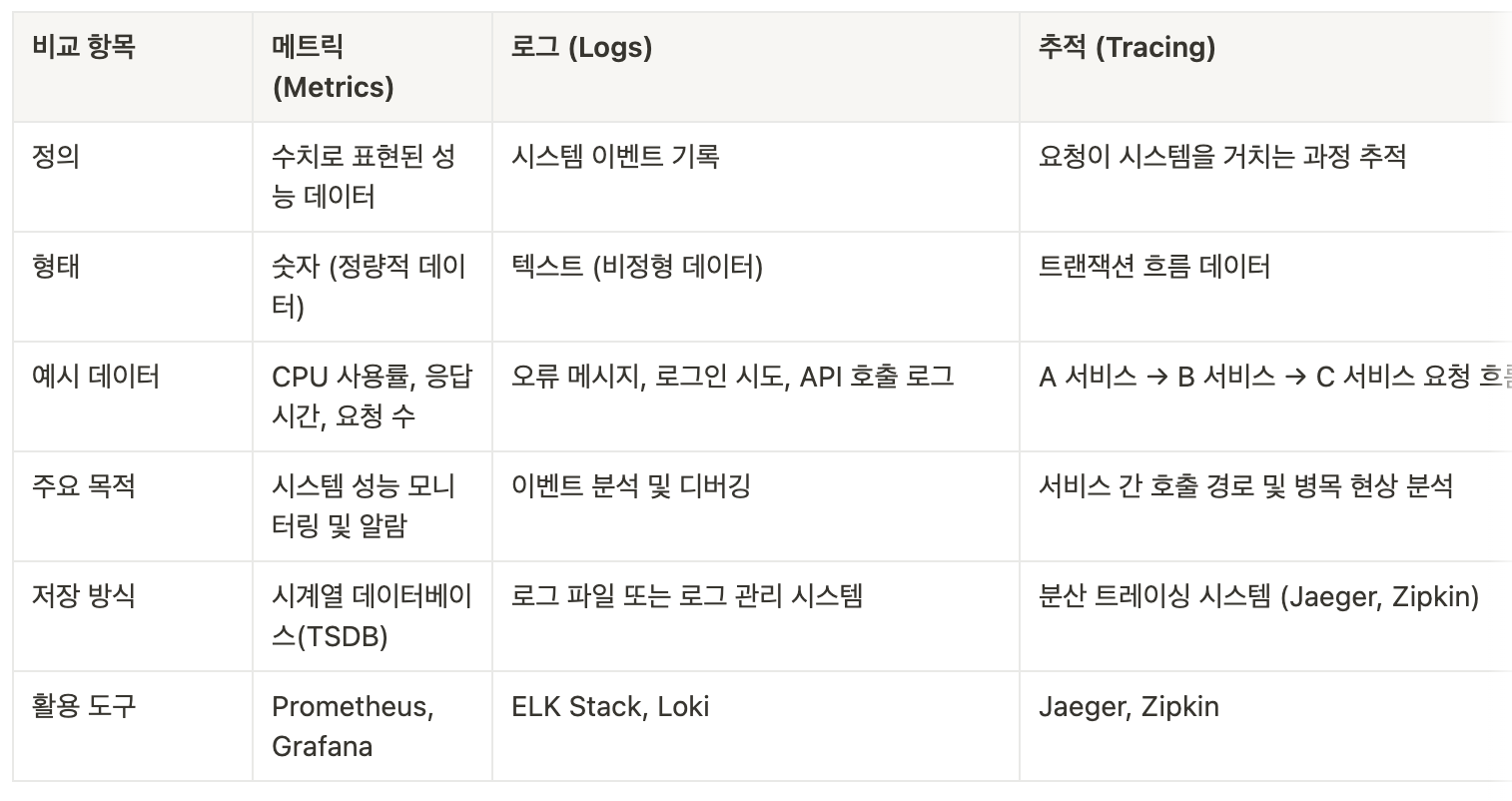
2.2 observability의 metric, log, tracing
- 메트릭(Metrics): 시스템의 성능을 정량적으로 모니터링
- 메트릭은 시스템의 성능과 건강 상태를 수치로 표현한 데이터입니다. 예를 들어, CPU 사용량, 메모리 사용량, 요청 지연 시간, 오류율 등이 있습니다. 이는 시스템의 전반적인 상태를 한눈에 볼 수 있게 도와주며, 이상 징후를 빠르게 감지할 수 있습니다. 놀라운 점은 메트릭이 시간에 따른 추세를 보여주며, 대시보드와 경고 시스템에 자주 사용된다는 것입니다.
- 로그(Logs): 이벤트 기반의 디버깅 및 문제 분석
- 로그는 시스템에서 발생한 이벤트를 기록한 텍스트나 구조화된 데이터입니다. 특정 행동이나 오류가 발생한 시점과 이유를 자세히 알 수 있어 디버깅에 유용합니다. 예를 들어, 애플리케이션이 오류를 낼 때 로그를 통해 그 원인을 찾을 수 있습니다.
- 추적(Tracing): 분산 시스템에서 요청 흐름을 파악하고 병목 현상 분석
- 추적, 특히 분산 추적은 요청이 분산 시스템의 여러 구성 요소를 통해 어떻게 이동하는지 추적하는 것입니다. 이는 요청의 흐름을 시각화하고, 성능 병목 현상을 찾거나 여러 서비스에 걸친 문제를 진단하는 데 도움을 줍니다. 예를 들어, 사용자가 웹사이트에서 버튼을 클릭하면 그 요청이 백엔드 서비스를 어떻게 거치는지 알 수 있습니다.
2.3 SLI, SLO, SLA
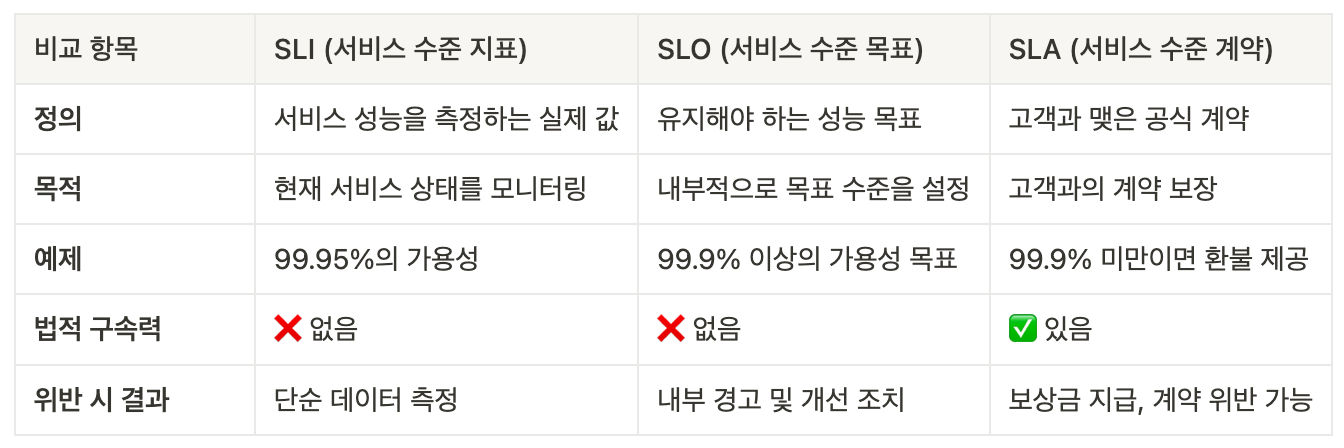
SLI (Service Level Indicator, 서비스 수준 지표)
- SLI는 서비스 품질을 정량적으로 측정하는 주요 성능 지표입니다.
- 즉, 서비스의 신뢰성과 성능을 평가하는 데 사용되는 실제 측정된 값입니다.
- 예제
- 웹 서비스의 응답 시간: 100ms 이내의 응답률이 99.9%
- 가용성: 30일 동안 서비스 정상 작동 시간의 비율 (예: 99.99%)
- 오류율: 총 요청 중 오류 응답(5xx, 4xx)이 발생한 비율
- 트래픽 지연율: 네트워크 요청의 평균 응답 시간
📌 SLI는 측정값이므로, 실제 운영 데이터에서 계산됩니다.
SLO (Service Level Objective, 서비스 수준 목표)
- SLO는 서비스가 유지해야 하는 목표 수준을 정의하는 값으로, SLI(실제 측정값)에 대한 기준선(threshold)을 설정합니다.
- 즉, "이 정도의 성능을 유지해야 한다"는 목표를 의미합니다.
- 예제
- 가용성 SLO: "서비스 가용성 99.9% 이상 유지"
- 응답 시간 SLO: "모든 요청의 95%는 200ms 이내에 응답해야 한다"
- 오류율 SLO: "오류율 0.1% 이하 유지"
📌 SLO는 내부 목표이며, SLA(계약)와 다릅니다.
SLA (Service Level Agreement, 서비스 수준 계약)
- SLA는 서비스 제공자와 고객 간에 체결된 공식적인 계약으로, 서비스 품질을 보장하는 법적 문서입니다.
- SLA는 SLO와 달리 계약 위반 시 페널티(배상)가 존재할 수 있습니다.
- 예제
- 가용성 SLA: "서비스 가용성이 99.9% 미만이면, 고객에게 요금의 10% 환불"
- 응답 시간 SLA: "트랜잭션 응답 시간이 500ms를 초과하면, 서비스 제공자가 손해 배상"
📌 SLA는 법적 계약이므로, 위반 시 금전적 보상이 따를 수 있습니다.
3. EKS Console
- View Kubernetes resources in the AWS Management Console - 링크
- 요구되는 Permissions
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"eks:ListFargateProfiles",
"eks:DescribeNodegroup",
"eks:ListNodegroups",
"eks:ListUpdates",
"eks:AccessKubernetesApi",
"eks:ListAddons",
"eks:DescribeCluster",
"eks:DescribeAddonVersions",
"eks:ListClusters",
"eks:ListIdentityProviderConfigs",
"iam:ListRoles"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "ssm:GetParameter",
"Resource": "arn:aws:ssm:*:111122223333:parameter/*"
}
]
}- eks 관련 ClusterRole 조회
kubectl get ClusterRole | grep eks
eks:addon-manager 2025-02-28T13:15:10Z
eks:az-poller 2025-02-28T13:15:08Z
eks:certificate-controller-approver 2025-02-28T13:15:08Z
eks:certificate-controller-manager 2025-02-28T13:15:08Z
eks:certificate-controller-signer 2025-02-28T13:15:08Z
eks:cloud-controller-manager 2025-02-28T13:15:08Z
eks:cloud-provider-extraction-migration 2025-02-28T13:15:09Z
eks:cluster-event-watcher 2025-02-28T13:15:08Z
eks:coredns-autoscaler 2025-02-28T13:15:08Z
eks:extension-metrics-apiserver 2025-02-28T13:15:09Z
eks:fargate-manager 2025-02-28T13:15:10Z
eks:fargate-scheduler 2025-02-28T13:15:09Z
eks:k8s-metrics 2025-02-28T13:15:09Z
eks:kms-storage-migrator 2025-02-28T13:15:09Z
eks:network-policy-controller 2025-02-28T13:15:12Z
eks:network-webhooks 2025-02-28T13:15:09Z
eks:node-bootstrapper 2025-02-28T13:15:10Z
eks:node-manager 2025-02-28T13:15:08Z
eks:nodewatcher 2025-02-28T13:15:09Z
eks:pod-identity-mutating-webhook 2025-02-28T13:15:09Z
eks:service-operations 2025-02-28T13:15:09Z
eks:tagging-controller 2025-02-28T13:15:09Z-
Cluster Service Role
- EKS 클러스터 IAM 역할 ARN 정보(연결 정책) 확인
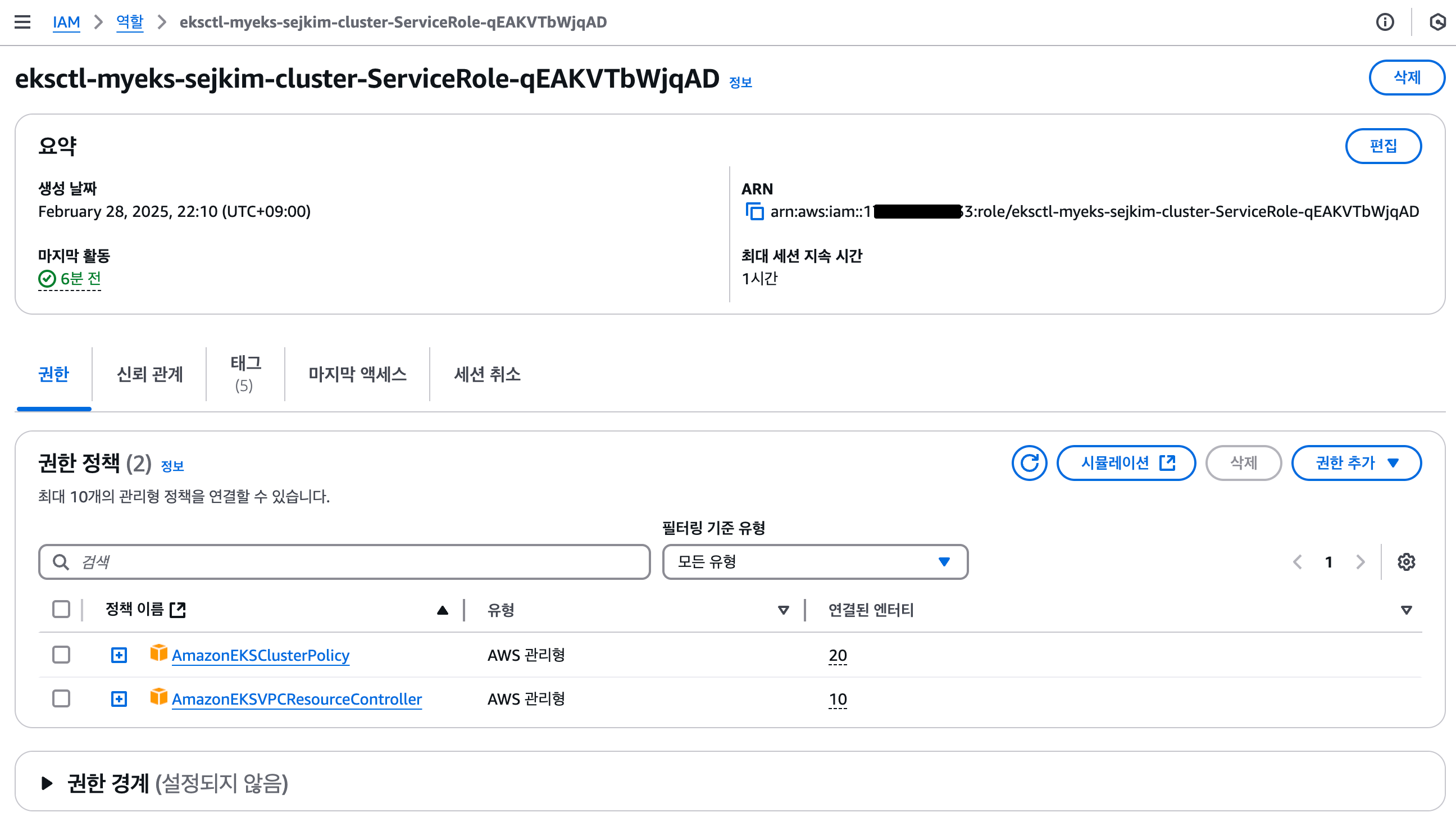
- EKS 클러스터 IAM 역할 ARN 정보(연결 정책) 확인
-
EKS Console 각 메뉴 확인
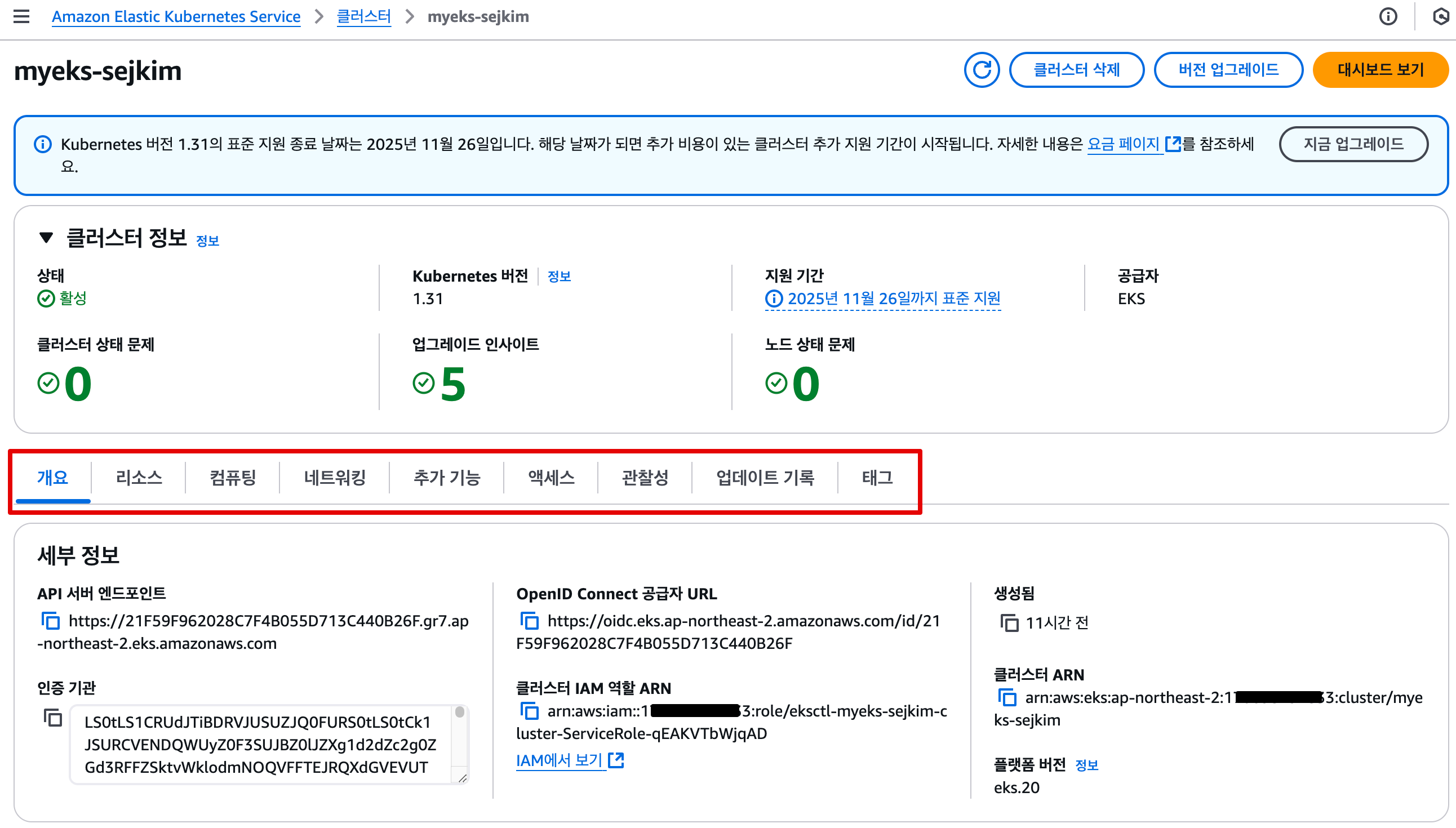
- Workloads : Pods, ReplicaSets, Deployments, and DaemonSets
- Pods : 네임스페이스 필터, 구조화된 보기 structured view vs 원시 보기 raw view
- Cluster : Nodes, Namespaces and API Services
- Nodes : 노드 상태 및 정보, Taints, Conditions, Labels, Annotations 등
- Service and Networking : Pods as Service, Endpoints and Ingresses
- Service : 서비스 정보, 로드 밸런서(CLB/NLB) URL 정보 등
- Config and Secrets : ConfigMap and Secrets
- ConfigMap & Secrets : 정보 확인, 디코드 Decode 지원
- Storage : PVC, PV, Storage Classes, Volume Attachments, CSI Drivers, CSI Nodes
- PVC : 볼륨 정보, 주석, 이벤트
- Volume Attachments : PVC가 연결된 CSI Node 정보
- Authentication : Service Account
- Service Account : IAM 역할 arn , add-on 연동
- Authorization : Cluster Roles, Roles, ClusterRoleBindings and RoleBindings
- Cluster Roles & Roles : Roles 에 규칙 확인
- Policy : Limit Ranges, Resource Quotas, Network Policies, Pod Disruption Budgets, Pod Security Policies
- Pod Security Policies : (기본값) eks.privileged 정보 확인
- Extensions : Custom Resource Definitions, Mutating Webhook Configurations, and Validating Webhook Configurations
- CRD 및 Webhook 확인
- Workloads : Pods, ReplicaSets, Deployments, and DaemonSets
4. Logging in EKS
4.1 Control Plane logging
- 컨트롤 플레인 로그 설정은 기본 Off, 활성화 하면 CloudWatch 로그그룹 >

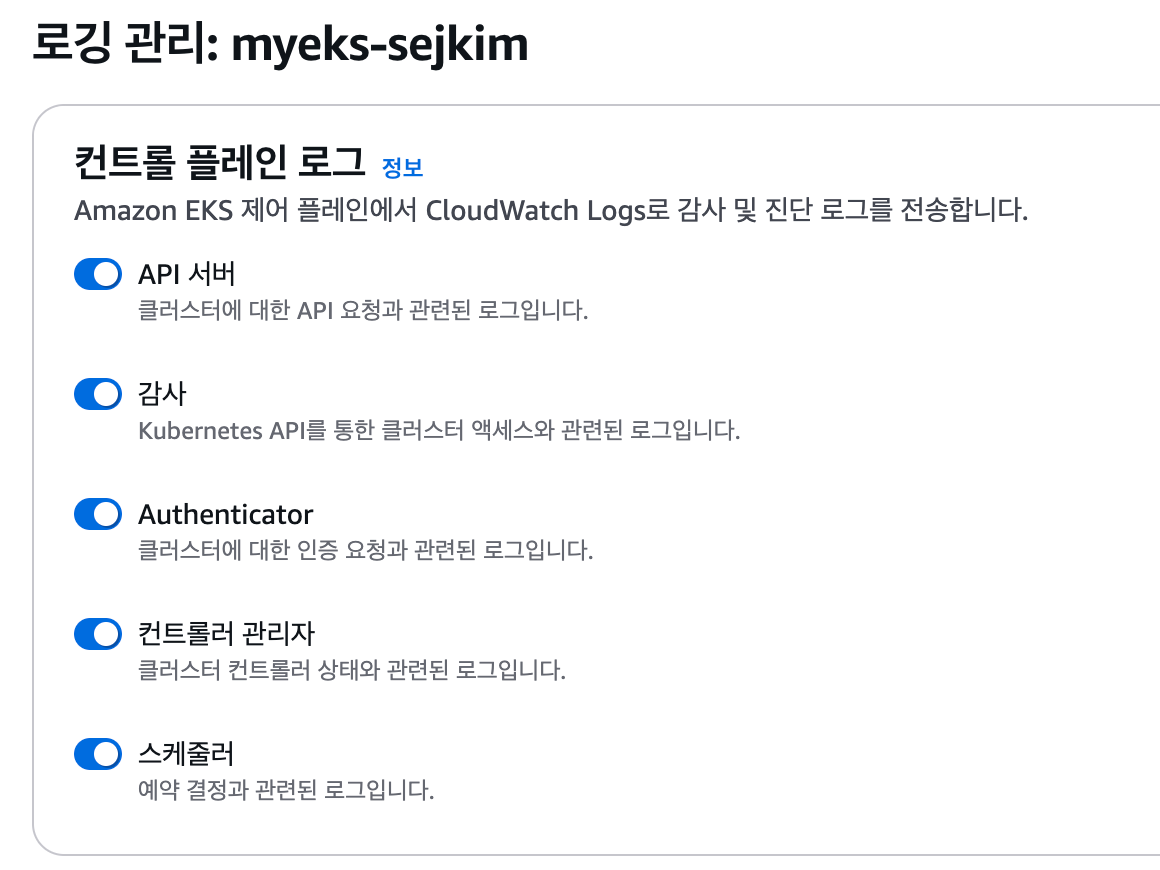
4.2 Logging 실습
# 모든 로깅 활성화
aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
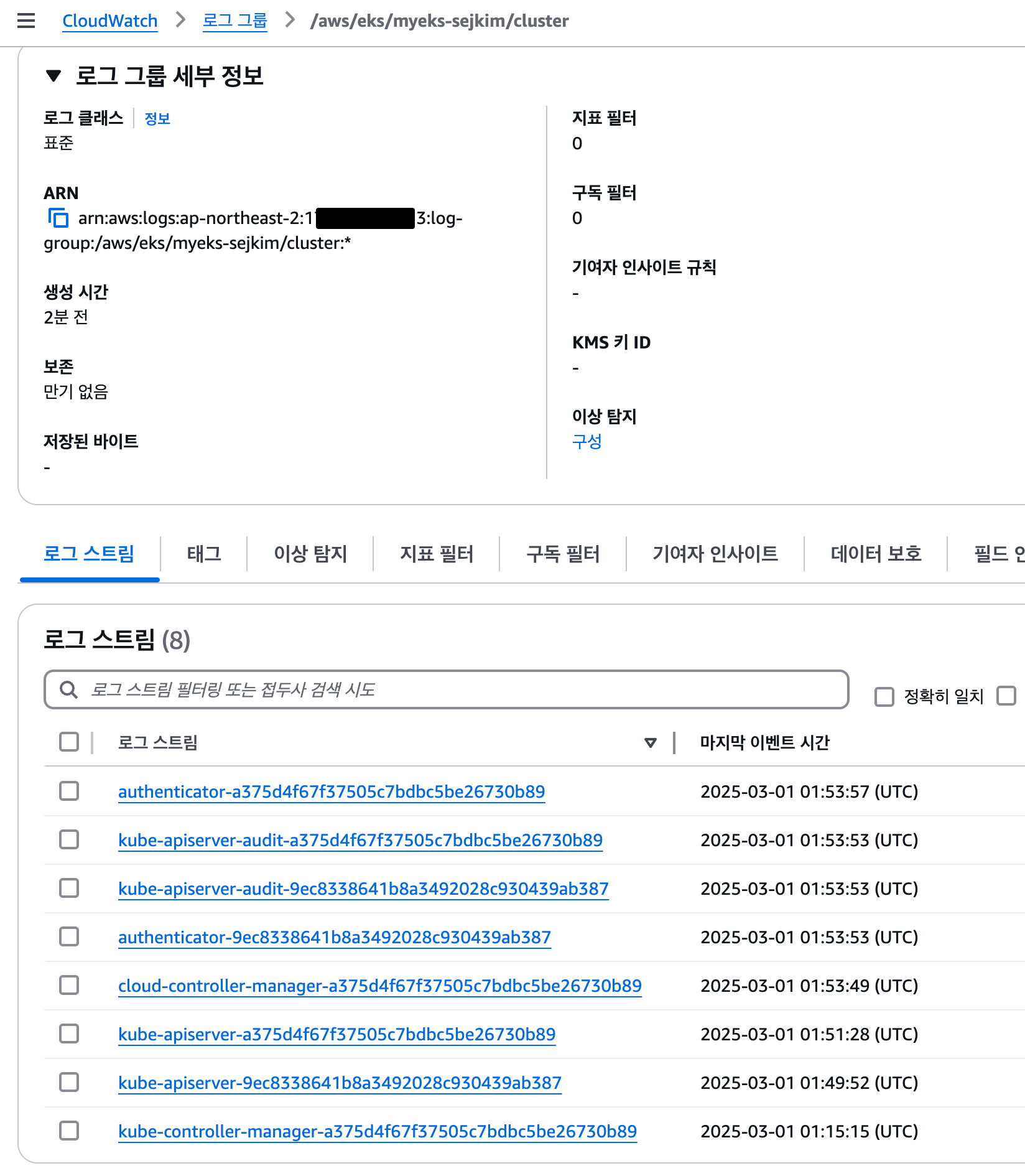
# 로그 그룹 확인
aws logs describe-log-groups | jq
"logGroupName": "/aws/eks/myeks-sejkim/cluster",
"arn": "arn:aws:logs:ap-northeast-2:1**********3:log-group:/aws/eks/myeks-sejkim/cluster:*",
"logGroupArn": "arn:aws:logs:ap-northeast-2:1**********3:log-group:/aws/eks/myeks-sejkim/cluster"
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-apiserver-audit --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-scheduler --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix authenticator --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix cloud-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short- CloudWatch Log Insights : 로그 그룹 선택 후 Run query - 링크
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
#
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc- 로깅 끄기
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region ap-northeast-2 --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster4.3 Control Plane metrics with Prometheus & CW Logs Insights 쿼리 - Docs
- 메트릭 패턴 정보
# 메트릭 패턴 정보 : metric_name{"tag"="value"[,...]} value
kubectl get --raw /metrics | more- Managing etcd database size on Amazon EKS clusters - 링크
# How to monitor etcd database size?
kubectl get --raw /metrics | grep "apiserver_storage_size_bytes"
apiserver_storage_size_bytes{cluster="etcd-0"} 4.919296e+06
# CW Logs Insights 쿼리
fields @timestamp, @message, @logStream
| filter @logStream like /kube-apiserver-audit/
| filter @message like /mvcc: database space exceeded/
| limit 10
# How do I identify what is consuming etcd database space?
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>50' |sort -g -k 2
apiserver_storage_objects{resource="clusterrolebindings.rbac.authorization.k8s.io"} 78
apiserver_storage_objects{resource="clusterroles.rbac.authorization.k8s.io"} 92
# CW Logs Insights 쿼리 : Request volume - Requests by User Agent:
fields userAgent, requestURI, @timestamp, @message
| filter @logStream like /kube-apiserver-audit/
| stats count(*) as count by userAgent
| sort count desc
# CW Logs Insights 쿼리 : Request volume - Requests by Universal Resource Identifier (URI)/Verb:
filter @logStream like /kube-apiserver-audit/
| stats count(*) as count by requestURI, verb, user.username
| sort count desc
# Object revision updates
fields requestURI
| filter @logStream like /kube-apiserver-audit/
| filter requestURI like /pods/
| filter verb like /patch/
| filter count > 8
| stats count(*) as count by requestURI, responseStatus.code
| filter responseStatus.code not like /500/
| sort count desc
#
fields @timestamp, userAgent, responseStatus.code, requestURI
| filter @logStream like /kube-apiserver-audit/
| filter requestURI like /pods/
| filter verb like /patch/
| filter requestURI like /name_of_the_pod_that_is_updating_fast/
| sort @timestamp4.4 NGINX 웹서버 배포 with Ingress(ALB)
- Nginx 배포 실습
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
# 도메인, 인증서 확인
echo $MyDomain $CERT_ARN
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
resourcesPreset: "nano"
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: "443"
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/target-type: ip
EOT
cat nginx-values.yaml
# 배포
helm install nginx bitnami/nginx --version 19.0.0 -f nginx-values.yaml
NAME: nginx
LAST DEPLOYED: Sat Mar 1 12:01:04 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: nginx
CHART VERSION: 19.0.0
APP VERSION: 1.27.4
Did you know there are enterprise versions of the Bitnami catalog? For enhanced secure software supply chain features, unlimited pulls from Docker, LTS support, or application customization, see Bitnami Premium or Tanzu Application Catalog. See https://www.arrow.com/globalecs/na/vendors/bitnami for more information.
** Please be patient while the chart is being deployed **
NGINX can be accessed through the following DNS name from within your cluster:
nginx.default.svc.cluster.local (port 80)
To access NGINX from outside the cluster, follow the steps below:
1. Get the NGINX URL and associate its hostname to your cluster external IP:
export CLUSTER_IP=$(minikube ip) # On Minikube. Use: `kubectl cluster-info` on others K8s clusters
echo "NGINX URL: http://nginx.ksj7279.click"
echo "$CLUSTER_IP nginx.ksj7279.click" | sudo tee -a /etc/hosts
WARNING: There are "resources" sections in the chart not set. Using "resourcesPreset" is not recommended for production. For production installations, please set the following values according to your workload needs:
- cloneStaticSiteFromGit.gitSync.resources
- resources
+info https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
⚠ SECURITY WARNING: Original containers have been substituted. This Helm chart was designed, tested, and validated on multiple platforms using a specific set of Bitnami and Tanzu Application Catalog containers. Substituting other containers is likely to cause degraded security and performance, broken chart features, and missing environment variables.
Substituted images detected:
- docker.io/bitnami/nginx:1.27.4-debian-12-r1
⚠ WARNING: Original containers have been retagged. Please note this Helm chart was tested, and validated on multiple platforms using a specific set of Tanzu Application Catalog containers. Substituting original image tags could cause unexpected behavior.
Retagged images:
- docker.io/bitnami/nginx:1.27.4-debian-12-r1
# 확인
kubectl get ingress,deploy,svc,ep nginx
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/nginx alb nginx.ksj7279.click myeks-sejkim-ingress-alb-1893285509.ap-northeast-2.elb.amazonaws.com 80 61s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 61s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx NodePort 10.100.92.18 <none> 80:30829/TCP,443:31919/TCP 61s
NAME ENDPOINTS AGE
endpoints/nginx 192.168.3.31:8443,192.168.3.31:8080 61s
kubectl describe deploy nginx # Resource - Limits/Requests 확인
Limits:
cpu: 150m
ephemeral-storage: 2Gi
memory: 192Mi
Requests:
cpu: 100m
ephemeral-storage: 50Mi
memory: 128Mi
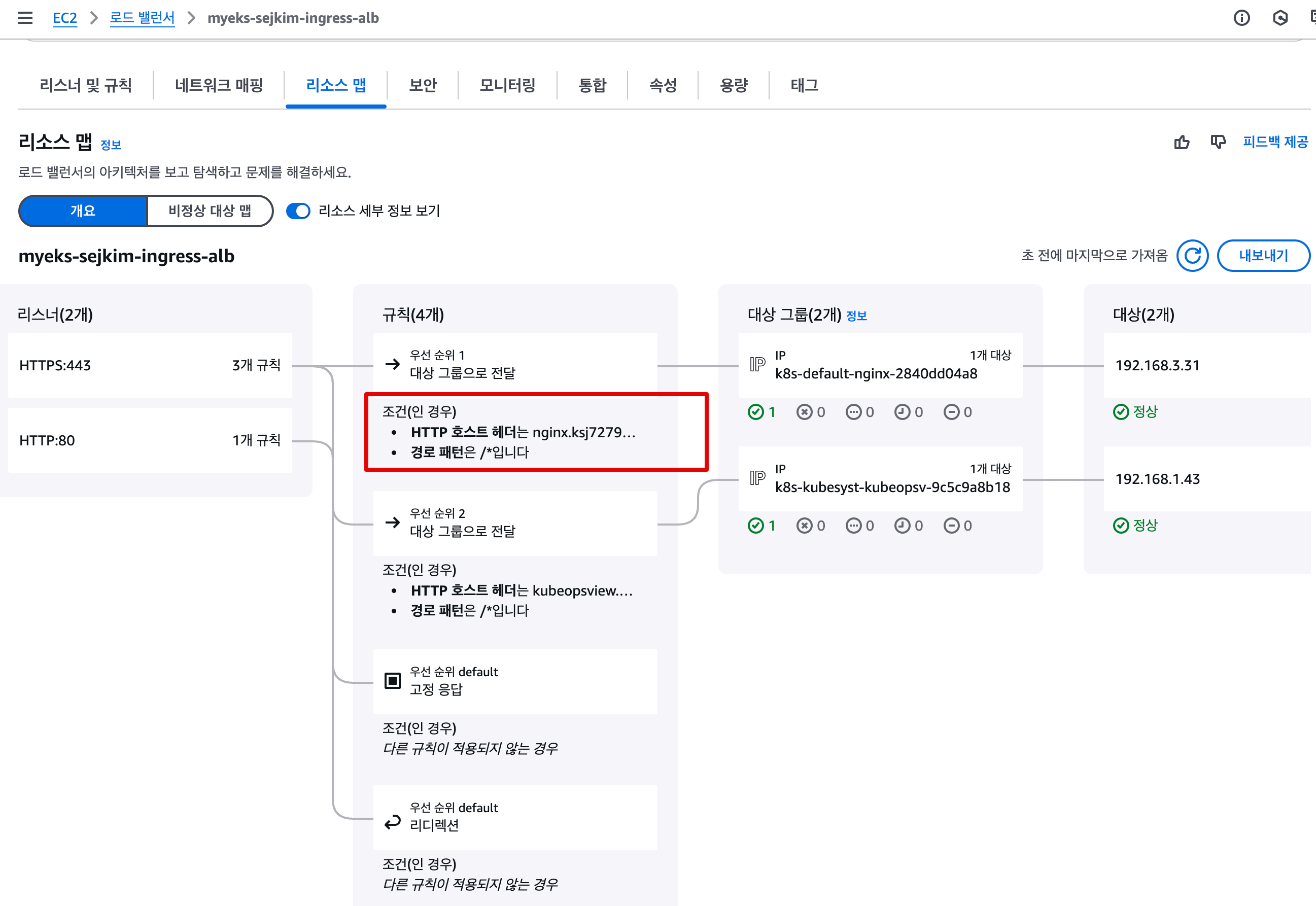
kubectl get targetgroupbindings # ALB TG 확인
NAME SERVICE-NAME SERVICE-PORT TARGET-TYPE AGE
k8s-default-nginx-2840dd04a8 nginx http ip 2m19s
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
Nginx WebServer URL = https://nginx.ksj7279.click
curl -s https://nginx.$MyDomain
kubectl stern deploy/nginx
혹은
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain | grep title; date; sleep 1; done
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done- Ingress 배포 후 기존 alb에 Rule 추가 구성 됨 (alb.ingress.kubernetes.io/group.name: study)
4.5 컨테이너 로그는 표준 출력과 에러로
- 컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고 - 링크
# 로그 모니터링
kubectl stern deploy/nginx
혹은
kubectl logs deploy/nginx -f
# nginx 웹 접속 시도
# 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
Defaulted container "nginx" out of: nginx, preserve-logs-symlinks (init)
total 0
lrwxrwxrwx. 1 1001 1001 11 Mar 1 03:01 access.log -> /dev/stdout
lrwxrwxrwx. 1 1001 1001 11 Mar 1 03:01 error.log -> /dev/stderr- (참고) nginx docker log collector 예시
- 또한 종료된 파드의 로그는 kubectl logs로 조회 할 수 없다
RUN ln -sf /dev/stdout /opt/bitnami/nginx/logs/access.log
RUN ln -sf /dev/stderr /opt/bitnami/nginx/logs/error.log- kubelet 기본 설정은 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하는 로그는 전체 로그 조회가 불가능함 (파일 갯수 5개)
# AL2 경우
cat /etc/kubernetes/kubelet-config.yaml
...
containerLogMaxSize: 10Mi- AL2 수정 예시
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: <cluster-name>
region: eu-central-1
nodeGroups:
- name: worker-spot-containerd-large-log
labels: { instance-type: spot }
instanceType: t3.large
minSize: 2
maxSize: 30
desiredCapacity: 2
amiFamily: AmazonLinux2
containerRuntime: containerd
availabilityZones: ["eu-central-1a", "eu-central-1b", "eu-central-1c"]
kubeletExtraConfig:
containerLogMaxSize: "50Mi" <-- 이부분 수정
containerLogMaxFiles: 10 <-- 이부분 수정5. Container Insights metrics
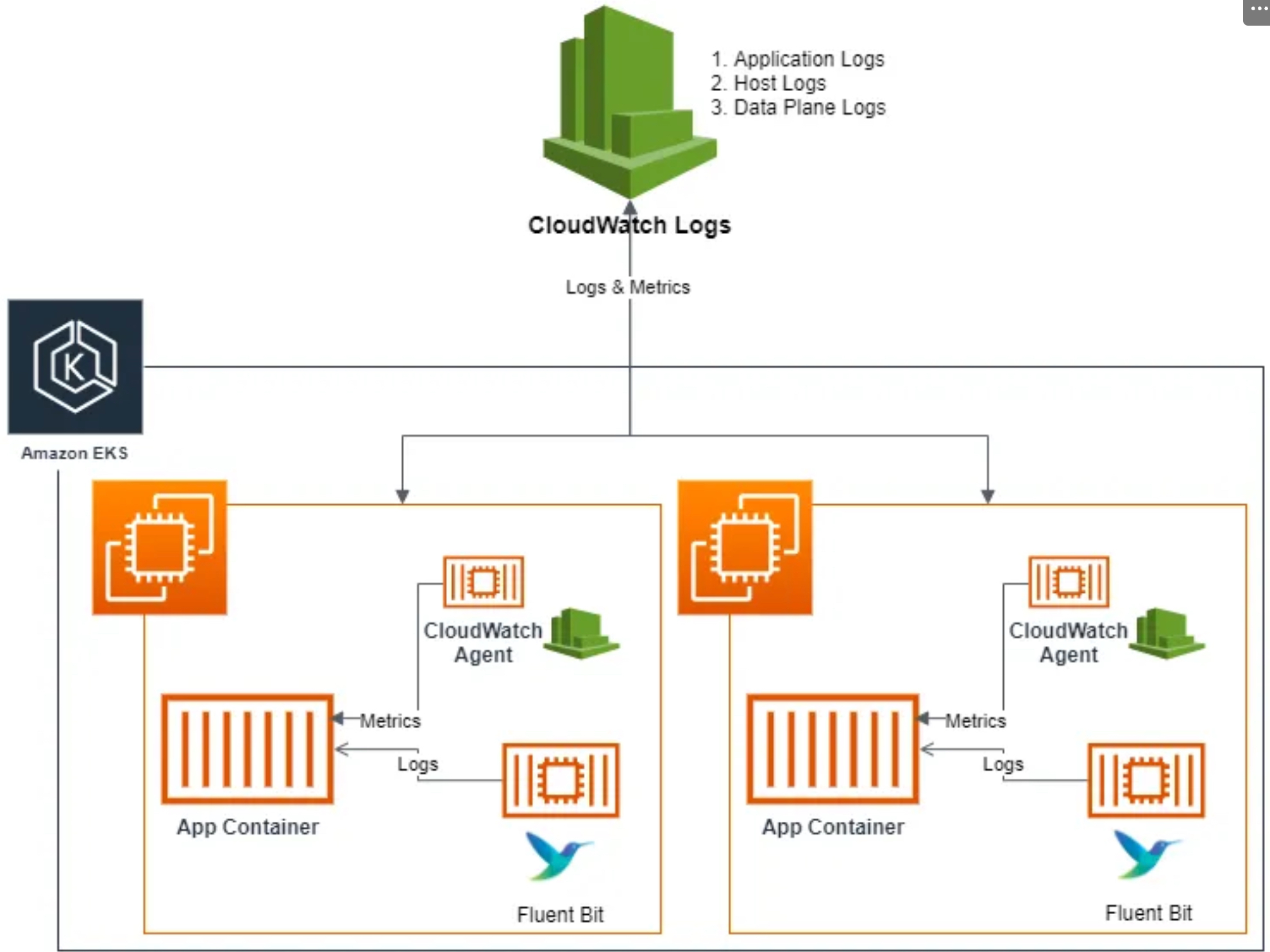
CloudWatch Container Observability : 노드에 CW Agent 파드와 Fluent Bit 파드가 데몬셋으로 배치되어 Metrics 와 Logs 수집 - Blog
5.1 Fluent Bit
-
Fluent Bit (as a DaemonSet to send logs to CloudWatch Logs) Integration in CloudWatch Container Insights for EKS - Docs, Blog, Fluentd, TS
-
[수집] 플루언트비트 Fluent Bit 컨테이너를 데몬셋으로 동작시키고, 아래 3가지 종류의 로그를 CloudWatch Logs 에 전송
- /aws/containerinsights/
*Cluster_Name*/application : 로그 소스(All log files in/var/log/containers), 각 컨테이너/파드 로그 - /aws/containerinsights/
*Cluster_Name*/host : 로그 소스(Logs from/var/log/dmesg,/var/log/secure, and/var/log/messages), 노드(호스트) 로그 - /aws/containerinsights/
*Cluster_Name*/dataplane : 로그 소스(/var/log/journalforkubelet.service,kubeproxy.service, anddocker.service), 쿠버네티스 데이터플레인 로그
- /aws/containerinsights/
-
[저장] : CloudWatch Logs 에 로그를 저장, 로그 그룹 별 로그 보존 기간 설정 가능
-
[시각화] : CloudWatch 의 Logs Insights 를 사용하여 대상 로그를 분석하고, CloudWatch 의 대시보드로 시각화한다
-
(참고) Fluent Bit is a lightweight log processor and forwarder that allows you to collect data and logs from different sources, enrich them with filters and send them to multiple destinations like CloudWatch, Kinesis Data Firehose, Kinesis Data Streams and Amazon OpenSearch Service.
5.2 CloudWatch Container Insight
- CloudWatch Container Insight는 컨테이너형 애플리케이션 및 마이크로 서비스에 대한 모니터링, 트러블 슈팅 및 알람을 위한 완전 관리형 관측 서비스입니다.
- CloudWatch 콘솔에서 자동화된 대시보드를 통해 container metrics, Prometeus metrics, application logs 및 performance log events를 탐색, 분석 및 시각화할 수 있습니다.
- CloudWatch Container Insight는 CPU, 메모리, 디스크 및 네트워크와 같은 인프라 메트릭을 자동으로 수집합니다.
- EKS 클러스터의 crashloop backoffs와 같은 진단 정보를 제공하여 문제를 격리하고 신속하게 해결할 수 있도록 지원합니다.
- 이러한 대시보드는 Amazon ECS, Amazon EKS, AWS ECS Fargate 그리고 EC2 위에 구동되는 k8s 클러스터에서 사용 가능합니다.
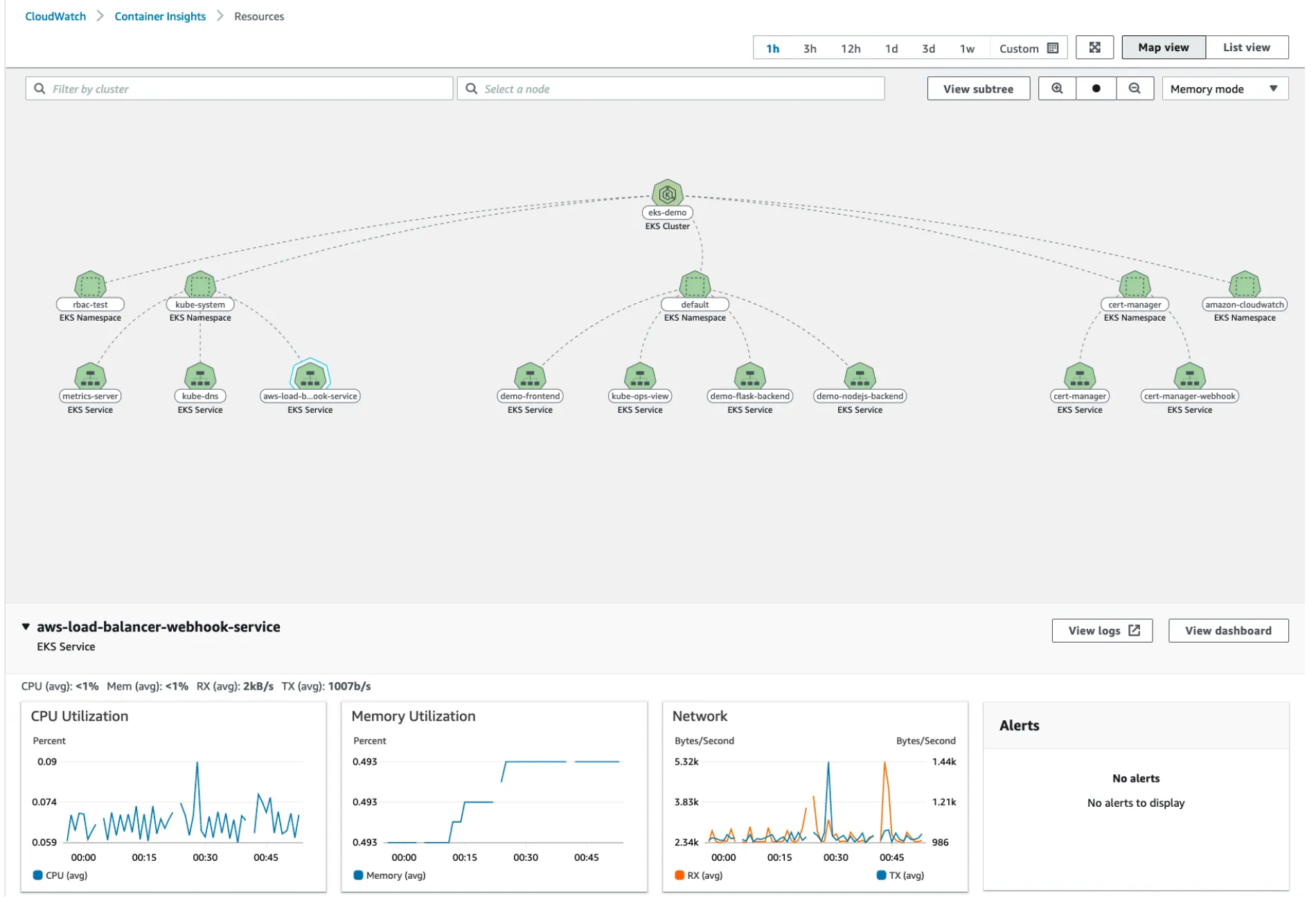
5.3 (사전 확인) 노드의 로그 확인
- application 로그 소스(All log files in /var/log/containers → 심볼릭 링크 /var/log/pods/<컨테이너>, 각 컨테이너/파드 로그
# 로그 위치 확인
#ssh ec2-user@$N1 sudo tree /var/log/containers
#ssh ec2-user@$N1 sudo ls -al /var/log/containers
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/containers; echo; done
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -al /var/log/containers; echo; done
# 개별 파드 로그 확인 : 아래 각자 디렉터리 경로는 다름
ssh ec2-user@$N3 sudo tail -f /var/log/pods/default_nginx-7c94c9bdcb-n7cwk_ae82d22f-bd7f-47a0-b925-9c5f3b7447bc/nginx/0.log
2025-03-01T06:19:10.930453848Z stdout F 192.168.3.30 - - [01/Mar/2025:06:19:10 +0000] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.31+" "-"
2025-03-01T06:19:13.349085513Z stdout F 192.168.1.90 - - [01/Mar/2025:06:19:13 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
2025-03-01T06:19:13.490827444Z stdout F 192.168.2.23 - - [01/Mar/2025:06:19:13 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
2025-03-01T06:19:13.534353203Z stdout F 192.168.3.235 - - [01/Mar/2025:06:19:13 +0000] "GET / HTTP/1.1" 200 409 "-" "ELB-HealthChecker/2.0" "-"
2025-03-01T06:19:15.930655293Z stdout F 192.168.3.30 - - [01/Mar/2025:06:19:15 +0000] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.31+" "-"
2025-03-01T06:19:20.930348369Z stdout F 192.168.3.30 - - [01/Mar/2025:06:19:20 +0000] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.31+" "-"
2025-03-01T06:19:25.931144952Z stdout F 192.168.3.30 - - [01/Mar/2025:06:19:25 +0000] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.31+" "-"- host 로그 소스(Logs from /var/log/dmesg, /var/log/secure, and /var/log/messages), 노드(호스트) 로그
# 로그 위치 확인
#ssh ec2-user@$N1 sudo tree /var/log/ -L 1
#ssh ec2-user@$N1 sudo ls -la /var/log/
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/ -L 1; echo; done
>>>>> 3.35.13.79 <<<<<
/var/log/
├── README -> ../../usr/share/doc/systemd/README.logs
├── amazon
├── audit
├── aws-routed-eni
├── btmp
├── btmp-20250301.gz
├── chrony
├── cloud-init-output.log
├── cloud-init.log
├── containers
├── dnf.librepo.log
├── dnf.log
├── dnf.rpm.log
├── hawkey.log
├── journal
├── lastlog
├── pods
├── private
├── sa
├── tallylog
└── wtmp
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo ls -la /var/log/; echo; done
>>>>> 3.35.13.79 <<<<<
total 1084
drwxr-xr-x. 11 root root 16384 Mar 1 00:00 .
drwxr-xr-x. 18 root root 251 Feb 24 18:02 ..
lrwxrwxrwx. 1 root root 39 Feb 20 21:10 README -> ../../usr/share/doc/systemd/README.logs
drwx------. 3 root root 17 Feb 28 23:29 amazon
drwx------. 2 root root 23 Feb 24 18:02 audit
drwxr-xr-x. 2 root root 121 Feb 28 23:30 aws-routed-eni
-rw-rw----. 1 root utmp 0 Mar 1 00:00 btmp
-rw-rw----. 1 root utmp 20 Feb 20 21:10 btmp-20250301.gz
drwxr-x---. 2 chrony chrony 174 Mar 1 00:00 chrony
-rw-r-----. 1 root adm 13443 Feb 28 23:29 cloud-init-output.log
-rw-r-----. 1 root adm 149068 Feb 28 23:29 cloud-init.log
drwxr-xr-x. 2 root root 16384 Feb 28 23:30 containers
-rw-r--r--. 1 root root 570875 Feb 28 23:30 dnf.librepo.log
-rw-r--r--. 1 root root 229396 Feb 28 23:30 dnf.log
-rw-r--r--. 1 root root 59764 Feb 28 23:30 dnf.rpm.log
-rw-r--r--. 1 root root 3919 Feb 28 23:29 hawkey.log
drwxr-sr-x+ 4 root systemd-journal 86 Feb 28 23:29 journal
-rw-rw-r--. 1 root utmp 292292 Mar 1 06:08 lastlog
drwxr-x---. 12 root root 16384 Feb 28 23:30 pods
drwx------. 2 root root 6 Feb 20 21:10 private
drwxr-xr-x. 2 root root 6 May 31 2023 sa
-rw-------. 1 root root 0 Feb 20 21:10 tallylog
-rw-rw-r--. 1 root utmp 3072 Mar 1 06:08 wtmp
# 호스트 로그 확인 <-- Amazon Linux 2023에선 Journalctl로 대체 됨
#ssh ec2-user@$N1 sudo tail /var/log/dmesg
#ssh ec2-user@$N1 sudo tail /var/log/secure
#ssh ec2-user@$N1 sudo tail /var/log/messages
for log in dmesg secure messages; do echo ">>>>> Node1: /var/log/$log <<<<<"; ssh ec2-user@$N1 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node2: /var/log/$log <<<<<"; ssh ec2-user@$N2 sudo tail /var/log/$log; echo; done
for log in dmesg secure messages; do echo ">>>>> Node3: /var/log/$log <<<<<"; ssh ec2-user@$N3 sudo tail /var/log/$log; echo; done
>>>>> Node1: /var/log/dmesg <<<<<
tail: cannot open '/var/log/dmesg' for reading: No such file or directory
>>>>> Node1: /var/log/secure <<<<<
tail: cannot open '/var/log/secure' for reading: No such file or directory
>>>>> Node1: /var/log/messages <<<<<
tail: cannot open '/var/log/messages' for reading: No such file or directory
==>
ssh ec2-user@$N1 sudo journalctl -u kubelet | head -n 10
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal systemd[1]: Starting kubelet.service - Kubernetes Kubelet...
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal systemd[1]: Started kubelet.service - Kubernetes Kubelet.
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950269 2468 flags.go:64] FLAG: --address="0.0.0.0"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950354 2468 flags.go:64] FLAG: --allowed-unsafe-sysctls="[]"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950363 2468 flags.go:64] FLAG: --anonymous-auth="true"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950369 2468 flags.go:64] FLAG: --application-metrics-count-limit="100"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950376 2468 flags.go:64] FLAG: --authentication-token-webhook="false"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950381 2468 flags.go:64] FLAG: --authentication-token-webhook-cache-ttl="2m0s"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950388 2468 flags.go:64] FLAG: --authorization-mode="AlwaysAllow"
Feb 28 23:29:57 ip-192-168-1-60.ap-northeast-2.compute.internal kubelet[2468]: I0228 23:29:57.950394 2468 flags.go:64] FLAG: --authorization-webhook-cache-authorized-ttl="5m0s"- dataplane 로그 소스(/var/log/journal for kubelet.service, kubeproxy.service, and docker.service), 쿠버네티스 데이터플레인 로그
# 로그 위치 확인
ssh ec2-user@$N1 sudo tree /var/log/journal -L 1
/var/log/journal
├── ec214238e85a5c1abe19192c408f1a35
└── ec2c14dbc1bd0989b089a8f0b2db4c6b
ssh ec2-user@$N1 sudo ls -la /var/log/journal
drwxr-sr-x+ 2 root systemd-journal 53 Feb 24 18:03 ec214238e85a5c1abe19192c408f1a35
drwxr-sr-x+ 2 root systemd-journal 53 Mar 1 06:08 ec2c14dbc1bd0989b089a8f0b2db4c6b
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/journal -L 1; echo; done
# 저널 로그 확인 - 링크
ssh ec2-user@$N3 sudo journalctl -x -n 200
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal sshd[132813]: Disconnected from user ec2-user 125.187.158.81 port 50969
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal audit[132799]: CRYPTO_KEY_USER pid=132799 uid=0 auid=1000 ses=15 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=destroy kind=server fp=SHA256:d2:e5:77:1c:a8:7b:3e:fd:48:88:c9:47:c5:a6:f0:f3:a1:58:20:d2:45:b7:7f:bb:fa:c4:af:1d:6f:3f:29:ce direction=? spid=132813 suid=1000 exe="/usr/sbin/sshd" hostname=? addr=? terminal=? res=success'
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal sshd[132799]: pam_unix(sshd:session): session closed for user ec2-user
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal audit[132799]: USER_END pid=132799 uid=0 auid=1000 ses=15 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=PAM:session_close grantors=pam_selinux,pam_loginuid,pam_selinux,pam_namespace,pam_keyinit,pam_keyinit,pam_limits,pam_systemd,pam_unix,pam_umask,pam_lastlog acct="ec2-user" exe="/usr/sbin/sshd" hostname=125.187.158.81 addr=125.187.158.81 terminal=ssh res=success'
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal audit[132799]: CRED_DISP pid=132799 uid=0 auid=1000 ses=15 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=PAM:setcred grantors=pam_env,pam_unix acct="ec2-user" exe="/usr/sbin/sshd" hostname=125.187.158.81 addr=125.187.158.81 terminal=ssh res=success'
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal audit[132799]: USER_END pid=132799 uid=0 auid=1000 ses=15 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=login id=1000 exe="/usr/sbin/sshd" hostname=? addr=125.187.158.81 terminal=ssh res=success'
Mar 01 06:22:00 ip-192-168-3-30.ap-northeast-2.compute.internal audit[132799]: USER_LOGOUT pid=132799 uid=0 auid=1000 ses=15 subj=system_u:system_r:sshd_t:s0-s0:c0.c1023 msg='op=login id=1000 exe="/usr/sbin/sshd" hostname=? addr=125.187.158.81 terminal=ssh res=success'
ssh ec2-user@$N3 sudo journalctl -f5.4 CloudWatch Container observability 설치
# IRSA 설정
eksctl create iamserviceaccount \
--name cloudwatch-agent \
--namespace amazon-cloudwatch --cluster $CLUSTER_NAME \
--role-name $CLUSTER_NAME-cloudwatch-agent-role \
--attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy \
--role-only \
--approve
# addon 배포
aws eks create-addon --addon-name amazon-cloudwatch-observability --cluster-name myeks-sejkim --service-account-role-arn arn:aws:iam::<IAM User Account ID직접 입력>:role/myeks-cloudwatch-agent-role
# addon 확인
aws eks list-addons --cluster-name myeks --output table
---------------------------------------
| ListAddons |
+-------------------------------------+
|| addons ||
|+-----------------------------------+|
|| amazon-cloudwatch-observability ||
|| aws-ebs-csi-driver ||
|| coredns ||
|| kube-proxy ||
|| metrics-server ||
|| vpc-cni ||
|+-----------------------------------+|
# 설치 확인
kubectl get crd | grep -i cloudwatch
amazoncloudwatchagents.cloudwatch.aws.amazon.com 2025-03-01T06:43:37Z
dcgmexporters.cloudwatch.aws.amazon.com 2025-03-01T06:43:38Z
instrumentations.cloudwatch.aws.amazon.com 2025-03-01T06:43:38Z
neuronmonitors.cloudwatch.aws.amazon.com 2025-03-01T06:43:38Z
kubectl get-all -n amazon-cloudwatch
NAME NAMESPACE AGE
configmap/cloudwatch-agent amazon-cloudwatch 112s
configmap/cloudwatch-agent-windows amazon-cloudwatch 111s
configmap/cloudwatch-agent-windows-container-insights amazon-cloudwatch 111s
configmap/cwagent-clusterleader amazon-cloudwatch 100s
configmap/dcgm-exporter-config-map amazon-cloudwatch 112s
configmap/fluent-bit-config amazon-cloudwatch 118s
configmap/fluent-bit-windows-config amazon-cloudwatch 118s
configmap/kube-root-ca.crt amazon-cloudwatch 2m
configmap/neuron-monitor-config-map amazon-cloudwatch 112s
endpoints/amazon-cloudwatch-observability-webhook-service amazon-cloudwatch 117s
endpoints/cloudwatch-agent amazon-cloudwatch 112s
endpoints/cloudwatch-agent-headless amazon-cloudwatch 112s
endpoints/cloudwatch-agent-monitoring amazon-cloudwatch 112s
endpoints/cloudwatch-agent-windows amazon-cloudwatch 111s
endpoints/cloudwatch-agent-windows-container-insights-monitoring amazon-cloudwatch 111s
endpoints/cloudwatch-agent-windows-headless amazon-cloudwatch 111s
endpoints/cloudwatch-agent-windows-monitoring amazon-cloudwatch 111s
endpoints/dcgm-exporter-service amazon-cloudwatch 112s
endpoints/neuron-monitor-service amazon-cloudwatch 112s
pod/amazon-cloudwatch-observability-controller-manager-6f768542h5r6 amazon-cloudwatch 116s
pod/cloudwatch-agent-6rtzq amazon-cloudwatch 112s
pod/cloudwatch-agent-qm9s6 amazon-cloudwatch 112s
pod/cloudwatch-agent-xfl6f amazon-cloudwatch 112s
pod/fluent-bit-hsqpr amazon-cloudwatch 117s
pod/fluent-bit-ktbpw amazon-cloudwatch 117s
pod/fluent-bit-zntvl amazon-cloudwatch 117s
secret/amazon-cloudwatch-observability-agent-cert amazon-cloudwatch 118s
secret/amazon-cloudwatch-observability-agent-client-cert amazon-cloudwatch 118s
secret/amazon-cloudwatch-observability-agent-server-cert amazon-cloudwatch 118s
secret/amazon-cloudwatch-observability-controller-manager-service-cert amazon-cloudwatch 118s
serviceaccount/amazon-cloudwatch-observability-controller-manager amazon-cloudwatch 118s
serviceaccount/cloudwatch-agent amazon-cloudwatch 118s
serviceaccount/dcgm-exporter-service-acct amazon-cloudwatch 112s
serviceaccount/default amazon-cloudwatch 2m
serviceaccount/neuron-monitor-service-acct amazon-cloudwatch 112s
service/amazon-cloudwatch-observability-webhook-service amazon-cloudwatch 117s
service/cloudwatch-agent amazon-cloudwatch 112s
service/cloudwatch-agent-headless amazon-cloudwatch 112s
service/cloudwatch-agent-monitoring amazon-cloudwatch 112s
service/cloudwatch-agent-windows amazon-cloudwatch 111s
service/cloudwatch-agent-windows-container-insights-monitoring amazon-cloudwatch 111s
service/cloudwatch-agent-windows-headless amazon-cloudwatch 111s
service/cloudwatch-agent-windows-monitoring amazon-cloudwatch 111s
service/dcgm-exporter-service amazon-cloudwatch 112s
service/neuron-monitor-service amazon-cloudwatch 112s
controllerrevision.apps/cloudwatch-agent-8fc89b895 amazon-cloudwatch 112s
controllerrevision.apps/cloudwatch-agent-windows-8589b945fc amazon-cloudwatch 111s
controllerrevision.apps/cloudwatch-agent-windows-container-insights-5884cd974d amazon-cloudwatch 111s
controllerrevision.apps/dcgm-exporter-5c49d58f79 amazon-cloudwatch 112s
controllerrevision.apps/fluent-bit-567b8fb676 amazon-cloudwatch 117s
controllerrevision.apps/fluent-bit-windows-86c4656799 amazon-cloudwatch 117s
controllerrevision.apps/neuron-monitor-576b8bb68b amazon-cloudwatch 111s
controllerrevision.apps/neuron-monitor-67f58c7476 amazon-cloudwatch 112s
controllerrevision.apps/neuron-monitor-d56877b6 amazon-cloudwatch 112s
daemonset.apps/cloudwatch-agent amazon-cloudwatch 112s
daemonset.apps/cloudwatch-agent-windows amazon-cloudwatch 112s
daemonset.apps/cloudwatch-agent-windows-container-insights amazon-cloudwatch 111s
daemonset.apps/dcgm-exporter amazon-cloudwatch 112s
daemonset.apps/fluent-bit amazon-cloudwatch 117s
daemonset.apps/fluent-bit-windows amazon-cloudwatch 117s
daemonset.apps/neuron-monitor amazon-cloudwatch 112s
deployment.apps/amazon-cloudwatch-observability-controller-manager amazon-cloudwatch 116s
replicaset.apps/amazon-cloudwatch-observability-controller-manager-6f7685455d amazon-cloudwatch 116s
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent amazon-cloudwatch 116s
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent-windows amazon-cloudwatch 116s
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent-windows-container-insights amazon-cloudwatch 116s
dcgmexporter.cloudwatch.aws.amazon.com/dcgm-exporter amazon-cloudwatch 116s
neuronmonitor.cloudwatch.aws.amazon.com/neuron-monitor amazon-cloudwatch 115s
endpointslice.discovery.k8s.io/amazon-cloudwatch-observability-webhook-service-b67jf amazon-cloudwatch 117s
endpointslice.discovery.k8s.io/cloudwatch-agent-headless-fzsjl amazon-cloudwatch 112s
endpointslice.discovery.k8s.io/cloudwatch-agent-monitoring-n2wfv amazon-cloudwatch 112s
endpointslice.discovery.k8s.io/cloudwatch-agent-rrgz8 amazon-cloudwatch 112s
endpointslice.discovery.k8s.io/cloudwatch-agent-windows-container-insights-monitoring-r7bvh amazon-cloudwatch 111s
endpointslice.discovery.k8s.io/cloudwatch-agent-windows-headless-f686k amazon-cloudwatch 111s
endpointslice.discovery.k8s.io/cloudwatch-agent-windows-monitoring-ntdzf amazon-cloudwatch 111s
endpointslice.discovery.k8s.io/cloudwatch-agent-windows-p4g4h amazon-cloudwatch 111s
endpointslice.discovery.k8s.io/dcgm-exporter-service-8vpjc amazon-cloudwatch 112s
endpointslice.discovery.k8s.io/neuron-monitor-service-gfxd6 amazon-cloudwatch 112s
rolebinding.rbac.authorization.k8s.io/dcgm-exporter-role-binding amazon-cloudwatch 117s
rolebinding.rbac.authorization.k8s.io/neuron-monitor-role-binding amazon-cloudwatch 117s
role.rbac.authorization.k8s.io/dcgm-exporter-role amazon-cloudwatch 117s
role.rbac.authorization.k8s.io/neuron-monitor-role amazon-cloudwatch 117s
kubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatch
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/cloudwatch-agent 3 3 3 3 3 kubernetes.io/os=linux 2m46s
daemonset.apps/cloudwatch-agent-windows 0 0 0 0 0 kubernetes.io/os=windows 2m46s
daemonset.apps/cloudwatch-agent-windows-container-insights 0 0 0 0 0 kubernetes.io/os=windows 2m45s
daemonset.apps/dcgm-exporter 0 0 0 0 0 kubernetes.io/os=linux 2m46s
daemonset.apps/fluent-bit 3 3 3 3 3 kubernetes.io/os=linux 2m51s
daemonset.apps/fluent-bit-windows 0 0 0 0 0 kubernetes.io/os=windows 2m51s
daemonset.apps/neuron-monitor 0 0 0 0 0 <none> 2m46s
NAME READY STATUS RESTARTS AGE
pod/amazon-cloudwatch-observability-controller-manager-6f768542h5r6 1/1 Running 0 2m50s
pod/cloudwatch-agent-6rtzq 1/1 Running 0 2m46s
pod/cloudwatch-agent-qm9s6 1/1 Running 0 2m46s
pod/cloudwatch-agent-xfl6f 1/1 Running 0 2m46s
pod/fluent-bit-hsqpr 1/1 Running 0 2m51s
pod/fluent-bit-ktbpw 1/1 Running 0 2m51s
pod/fluent-bit-zntvl 1/1 Running 0 2m51s
NAME DATA AGE
configmap/cloudwatch-agent 1 2m46s
configmap/cloudwatch-agent-windows 1 2m45s
configmap/cloudwatch-agent-windows-container-insights 1 2m45s
configmap/cwagent-clusterleader 0 2m34s
configmap/dcgm-exporter-config-map 2 2m46s
configmap/fluent-bit-config 5 2m52s
configmap/fluent-bit-windows-config 5 2m52s
configmap/kube-root-ca.crt 1 2m54s
configmap/neuron-monitor-config-map 1 2m46s
NAME SECRETS AGE
serviceaccount/amazon-cloudwatch-observability-controller-manager 0 2m52s
serviceaccount/cloudwatch-agent 0 2m52s
serviceaccount/dcgm-exporter-service-acct 0 2m46s
serviceaccount/default 0 2m54s
serviceaccount/neuron-monitor-service-acct 0 2m46s
NAME MODE VERSION READY AGE IMAGE MANAGEMENT
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent daemonset 0.0.0 2m50s managed
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent-windows daemonset 0.0.0 2m50s managed
amazoncloudwatchagent.cloudwatch.aws.amazon.com/cloudwatch-agent-windows-container-insights daemonset 0.0.0 2m50s managed
kubectl describe clusterrole cloudwatch-agent-role amazon-cloudwatch-observability-manager-role # 클러스터롤 확인
kubectl describe clusterrolebindings cloudwatch-agent-role-binding amazon-cloudwatch-observability-manager-rolebinding # 클러스터롤 바인딩 확인
kubectl -n amazon-cloudwatch logs -l app.kubernetes.io/component=amazon-cloudwatch-agent -f # 파드 로그 확인
kubectl -n amazon-cloudwatch logs -l k8s-app=fluent-bit -f # 파드 로그 확인
# cloudwatch-agent 설정 확인
kubectl describe cm cloudwatch-agent -n amazon-cloudwatch
kubectl get cm cloudwatch-agent -n amazon-cloudwatch -o jsonpath="{.data.cwagentconfig\.json}" | jq
{
"agent": {
"region": "ap-northeast-2"
},
"logs": {
"metrics_collected": {
"application_signals": {
"hosted_in": "myeks-sejkim"
},
"kubernetes": {
"cluster_name": "myeks-sejkim",
"enhanced_container_insights": true
}
}
},
"traces": {
"traces_collected": {
"application_signals": {}
}
}
}
#Fluent bit 파드 수집하는 방법 : Volumes에 HostPath를 살펴보자! >> / 호스트 패스 공유??? 보안상 안전한가? 좀 더 범위를 좁힐수는 없을까요?
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent
...
Volumes:
...
rootfs:
Type: HostPath (bare host directory volume)
Path: /
HostPathType:
# Fluent Bit 로그 INPUT/FILTER/OUTPUT 설정 확인 - 링크
## 설정 부분 구성 : application-log.conf , dataplane-log.conf , fluent-bit.conf , host-log.conf , parsers.conf
kubectl describe cm fluent-bit-config -n amazon-cloudwatch
...
application-log.conf:
----
[INPUT]
Name tail
Tag application.*
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*, /var/log/containers/aws-node*, /var/log/containers/kube-proxy*
Path /var/log/containers/*.log
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_container.db
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
Rotate_Wait 30
storage.type filesystem
Read_from_Head ${READ_FROM_HEAD}
...
[FILTER]
Name kubernetes
Match application.*
Kube_URL https://kubernetes.default.svc:443
Kube_Tag_Prefix application.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
Labels Off
Annotations Off
Use_Kubelet On
Kubelet_Port 10250
Buffer_Size 0
[OUTPUT]
Name cloudwatch_logs
Match application.*
region ${AWS_REGION}
log_group_name /aws/containerinsights/${CLUSTER_NAME}/application
log_stream_prefix ${HOST_NAME}-
auto_create_group true
extra_user_agent container-insights
...
# Fluent Bit 파드가 수집하는 방법 : Volumes에 HostPath를 살펴보자!
kubectl describe -n amazon-cloudwatch ds fluent-bit
...
ssh ec2-user@$N1 sudo tree /var/log
ssh ec2-user@$N2 sudo tree /var/log
ssh ec2-user@$N3 sudo tree /var/log- Fluent bit 파드가 수집하는 방법 : Volumes에 HostPath - 링크
- host에서 사용하는 docker.sock가 Pod에 mount 되어있는 상태에서 악의적인 사용자가 해당 Pod에 docker만 설치할 수 있다면, mount된 dock.sock을 이용하여 host의 docker에 명령을 보낼 수 있게 된다(docker가 client-server 구조이기 때문에 가능).이는 container escape라고도 할 수 있다.

- observability/aws-for-fluent-bit:2.32.5 에선 docker.sock 마운트 안함

- host에서 사용하는 docker.sock가 Pod에 mount 되어있는 상태에서 악의적인 사용자가 해당 Pod에 docker만 설치할 수 있다면, mount된 dock.sock을 이용하여 host의 docker에 명령을 보낼 수 있게 된다(docker가 client-server 구조이기 때문에 가능).이는 container escape라고도 할 수 있다.
- 로깅 확인 : CW → 로그 그룹
- Container Insights 확인 : CW → Container Insights → myeks-sejkim 클러스터 선택
5.5 [운영섭 EC2] 로그 확인 : nginx 웹서버
# 부하 발생
curl -s https://nginx.$MyDomain
yum install -y httpd
ab -c 500 -n 30000 https://nginx.$MyDomain/
# 파드 직접 로그 모니터링
kubectl stern deploy/nginx- 로그 그룹 - Link → application → 로그 스트림 : nginx 필터링 ⇒ 클릭 후 확인 ⇒ ApacheBench 필터링 확인
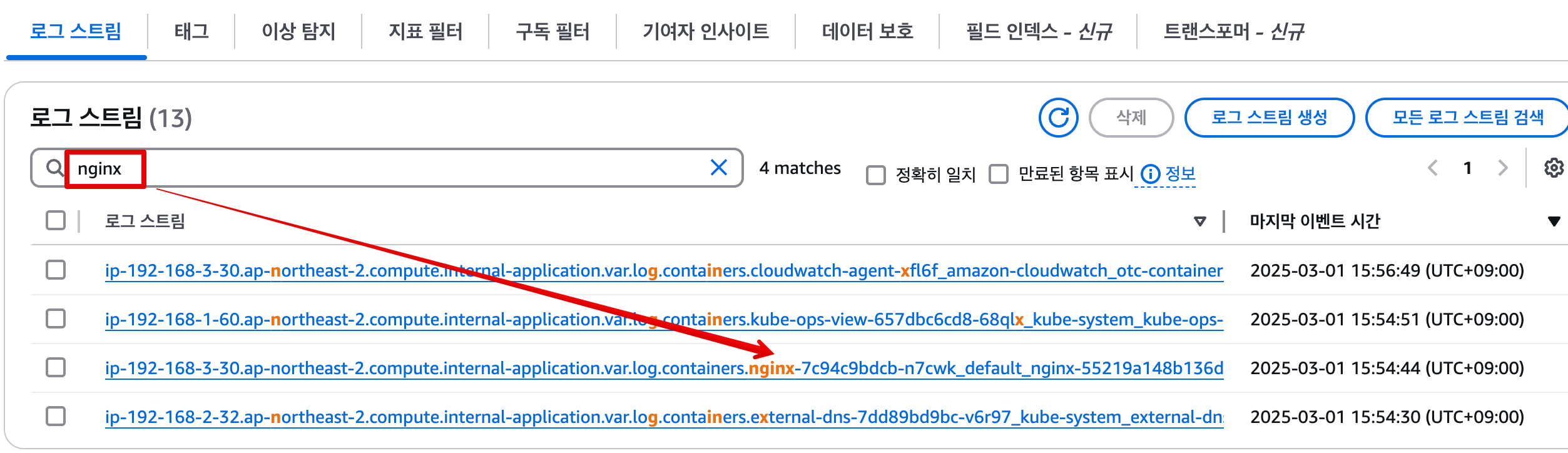
- Logs Insights - Link
# Application log errors by container name : 컨테이너 이름별 애플리케이션 로그 오류
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/application
stats count() as error_count by kubernetes.container_name
| filter stream="stderr"
| sort error_count desc
# All Kubelet errors/warning logs for for a given EKS worker node
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/ and ec2_instance_id="<YOUR INSTANCE ID>"
| sort @timestamp desc
# Kubelet errors/warning count per EKS worker node in the cluster
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/dataplane
fields @timestamp, @message, ec2_instance_id
| filter message =~ /.*(E|W)[0-9]{4}.*/
| stats count(*) as error_count by ec2_instance_id
# performance 로그 그룹
# 로그 그룹 선택 : /aws/containerinsights/<CLUSTER_NAME>/performance
# 노드별 평균 CPU 사용률
STATS avg(node_cpu_utilization) as avg_node_cpu_utilization by NodeName
| SORT avg_node_cpu_utilization DESC
# 파드별 재시작(restart) 카운트
STATS avg(number_of_container_restarts) as avg_number_of_container_restarts by PodName
| SORT avg_number_of_container_restarts DESC
# 요청된 Pod와 실행 중인 Pod 간 비교
fields @timestamp, @message
| sort @timestamp desc
| filter Type="Pod"
| stats min(pod_number_of_containers) as requested, min(pod_number_of_running_containers) as running, ceil(avg(pod_number_of_containers-pod_number_of_running_containers)) as pods_missing by kubernetes.pod_name
| sort pods_missing desc
# 클러스터 노드 실패 횟수
stats avg(cluster_failed_node_count) as CountOfNodeFailures
| filter Type="Cluster"
| sort @timestamp desc
# 파드별 CPU 사용량
stats pct(container_cpu_usage_total, 50) as CPUPercMedian by kubernetes.container_name
| filter Type="Container"
| sort CPUPercMedian desc5.6 CloudWatch Container Observability 삭제
- aws eks delete-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observability
- CloudWatch 로그 그룹 삭제
6. Metrics-server
6.1 Metrics-server 확인
- kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계하는 클러스터 애드온 구성 요소 - EKS, Github, Docs, CMD
- cAdvisor : kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬 - https://kubernetes.io/ko/docs/tasks/debug/debug-cluster/resource-metrics-pipeline/
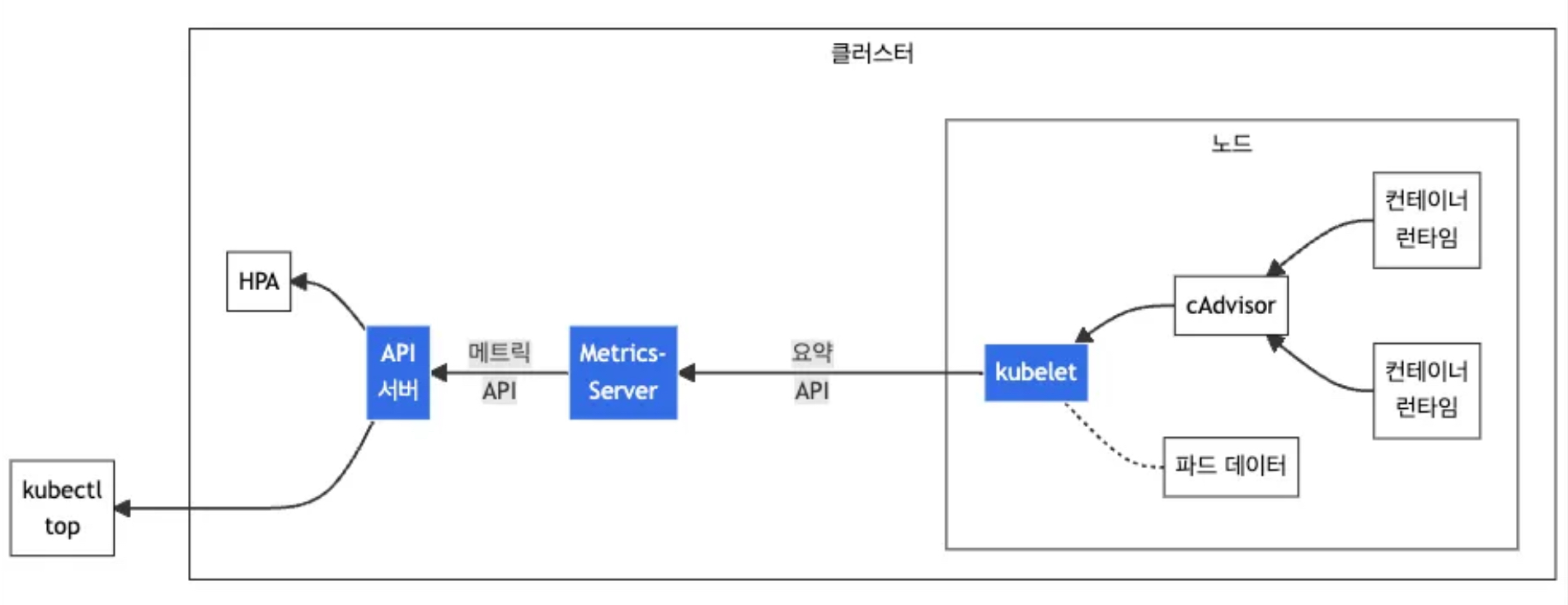
# addon 으로 배포되어 있음 (배포 생략)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l app.kubernetes.io/name=metrics-server
kubectl api-resources | grep metrics
NAME READY STATUS RESTARTS AGE
metrics-server-6bf5998d9c-qnt79 1/1 Running 0 14h
metrics-server-6bf5998d9c-x54jj 1/1 Running 0 14h
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
NAME SERVICE AVAILABLE AGE
v1.metrics.eks.amazonaws.com kube-system/eks-extension-metrics-api True 18h
v1beta1.metrics.k8s.io kube-system/metrics-server True 18h
# 노드 메트릭 확인
kubectl top node
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
ip-192-168-1-60.ap-northeast-2.compute.internal 101m 5% 744Mi 22%
ip-192-168-2-32.ap-northeast-2.compute.internal 84m 4% 1215Mi 37%
ip-192-168-3-30.ap-northeast-2.compute.internal 82m 4% 1018Mi 30%
# 파드 메트릭 확인
kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
default nginx-7c94c9bdcb-n7cwk 1m 3Mi
kube-system aws-load-balancer-controller-86ff7688d-9twwv 2m 24Mi
kube-system aws-load-balancer-controller-86ff7688d-tgrcw 1m 21Mi
kube-system aws-node-5l8wk 3m 115Mi
kube-system aws-node-kwsx9 4m 117Mi
kube-system aws-node-pbbf5 4m 116Mi
kube-system coredns-86f5954566-8zlgz 2m 18Mi
kube-system coredns-86f5954566-fzdlz 2m 18Mi
kube-system ebs-csi-controller-844b978c49-7n8bt 4m 55Mi
kube-system ebs-csi-controller-844b978c49-jjddf 3m 50Mi
kube-system ebs-csi-node-qlkmv 1m 19Mi
kube-system ebs-csi-node-wgmr9 1m 19Mi
kube-system ebs-csi-node-wstnv 1m 19Mi
kube-system external-dns-7dd89bd9bc-v6r97 1m 20Mi
kube-system kube-ops-view-657dbc6cd8-68qlx 20m 36Mi
kube-system kube-proxy-59xxb 1m 17Mi
kube-system kube-proxy-b7nbw 1m 16Mi
kube-system kube-proxy-dgk45 1m 17Mi
kube-system metrics-server-6bf5998d9c-qnt79 3m 22Mi
kube-system metrics-server-6bf5998d9c-x54jj 4m 22Mi
monitoring kube-prometheus-stack-grafana-c844968cd-m9s2t 9m 288Mi
monitoring kube-prometheus-stack-kube-state-metrics-5dbfbd4b9-69xpp 2m 14Mi
monitoring kube-prometheus-stack-operator-76bdd654bf-wnvmv 2m 20Mi
monitoring kube-prometheus-stack-prometheus-node-exporter-bf9m2 1m 9Mi
monitoring kube-prometheus-stack-prometheus-node-exporter-mm887 2m 9Mi
monitoring kube-prometheus-stack-prometheus-node-exporter-wf5cg 2m 10Mi
monitoring prometheus-kube-prometheus-stack-prometheus-0 17m 232Mi
kubectl top pod -n kube-system --sort-by='cpu'
NAME CPU(cores) MEMORY(bytes)
kube-ops-view-657dbc6cd8-68qlx 12m 36Mi
ebs-csi-controller-844b978c49-jjddf 4m 50Mi
aws-node-kwsx9 4m 117Mi
aws-node-pbbf5 4m 116Mi
ebs-csi-controller-844b978c49-7n8bt 4m 55Mi
aws-node-5l8wk 4m 115Mi
metrics-server-6bf5998d9c-x54jj 4m 22Mi
metrics-server-6bf5998d9c-qnt79 3m 21Mi
coredns-86f5954566-8zlgz 2m 18Mi
coredns-86f5954566-fzdlz 2m 18Mi
aws-load-balancer-controller-86ff7688d-9twwv 2m 24Mi
ebs-csi-node-wstnv 1m 19Mi
external-dns-7dd89bd9bc-v6r97 1m 20Mi
aws-load-balancer-controller-86ff7688d-tgrcw 1m 21Mi
kube-proxy-59xxb 1m 17Mi
kube-proxy-b7nbw 1m 16Mi
kube-proxy-dgk45 1m 17Mi
ebs-csi-node-wgmr9 1m 19Mi
ebs-csi-node-qlkmv 1m 19Mi
kubectl top pod -n kube-system --sort-by='memory'
NAME CPU(cores) MEMORY(bytes)
aws-node-kwsx9 4m 118Mi
aws-node-pbbf5 3m 116Mi
aws-node-5l8wk 4m 115Mi
ebs-csi-controller-844b978c49-7n8bt 4m 55Mi
ebs-csi-controller-844b978c49-jjddf 3m 50Mi
kube-ops-view-657dbc6cd8-68qlx 13m 36Mi
aws-load-balancer-controller-86ff7688d-9twwv 2m 24Mi
metrics-server-6bf5998d9c-x54jj 4m 22Mi
metrics-server-6bf5998d9c-qnt79 3m 21Mi
aws-load-balancer-controller-86ff7688d-tgrcw 2m 21Mi
external-dns-7dd89bd9bc-v6r97 1m 20Mi
ebs-csi-node-qlkmv 1m 19Mi
ebs-csi-node-wgmr9 1m 19Mi
ebs-csi-node-wstnv 1m 19Mi
coredns-86f5954566-8zlgz 2m 18Mi
coredns-86f5954566-fzdlz 2m 18Mi
kube-proxy-59xxb 1m 17Mi
kube-proxy-dgk45 1m 17Mi
kube-proxy-b7nbw 1m 16Mi6.2 kwatch 소개 및 설치/사용
- kwatch helps you monitor all changes in your Kubernetes(K8s) cluster, detects crashes in your running apps in realtime, and publishes notifications to your channels (Slack, Discord, etc.) instantly - 링크, Helm, Blog
# 닉네임
NICK=<각자 자신의 닉네임>
NICK=sejkim
# configmap 생성
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/T*****Z/B*****O'
title: $NICK-eks
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOF
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml- 잘못된 이미지 파드 배포 및 확인
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: nginx-19
spec:
containers:
- name: nginx-pod
image: nginx:1.19.19 # 존재하지 않는 이미지 버전
EOF
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
# 삭제
kubectl delete pod nginx-19
# (옵션) 노드1번 강제 재부팅 해보기
ssh $N1 sudo reboot
- kwatch 삭제: kubectl delete -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.5/deploy/deploy.yaml
6.3 ChatGPT 활용
- k8sgpt, 당신이 누구던 쿠버네티스를 사용한다면 k8sgpt 가 당신을 도와줄 수 있습니다 (손주형)
7. Prometheus-Stack
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud
7.1 소개
-
제공 기능
- a multi-dimensional data model with time series data(=TSDB, 시계열 데이터베이스) identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous - Docs
- time series collection happens via a pull model over HTTP - Q&A
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
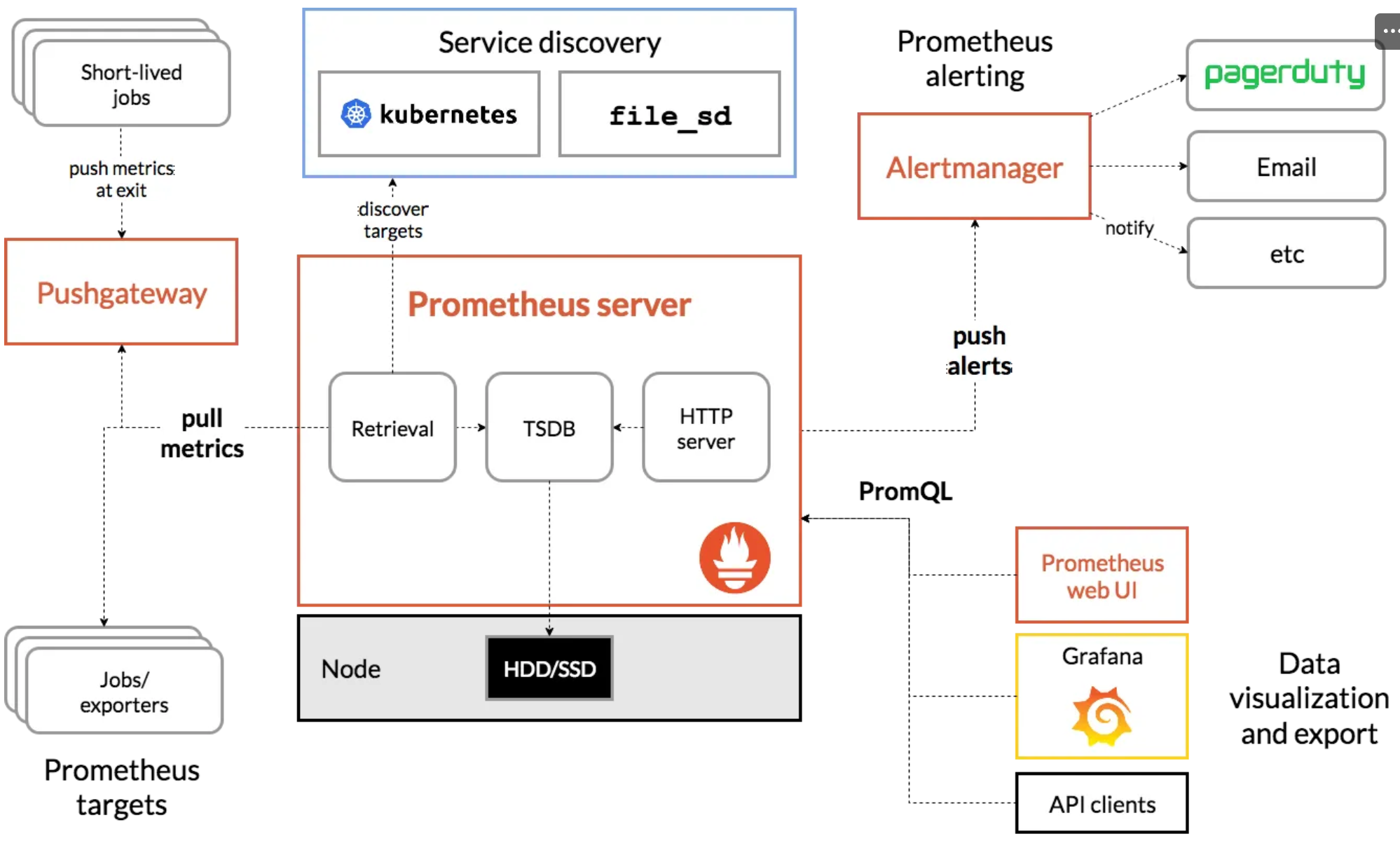
[출처] https://prometheus.io/docs/introduction/overview/
-
구성 요소
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
-
Metrics?
- 메트릭은 일반인이 이해하기 쉬운 수치적 측정입니다. 시계열이라는 용어는 시간에 따른 변화를 기록하는 것을 말합니다. 사용자가 측정하고자 하는 것은 애플리케이션마다 다릅니다. 웹 서버의 경우 요청 시간이 될 수 있고, 데이터베이스의 경우 활성 연결 또는 활성 쿼리 수가 될 수 있습니다.
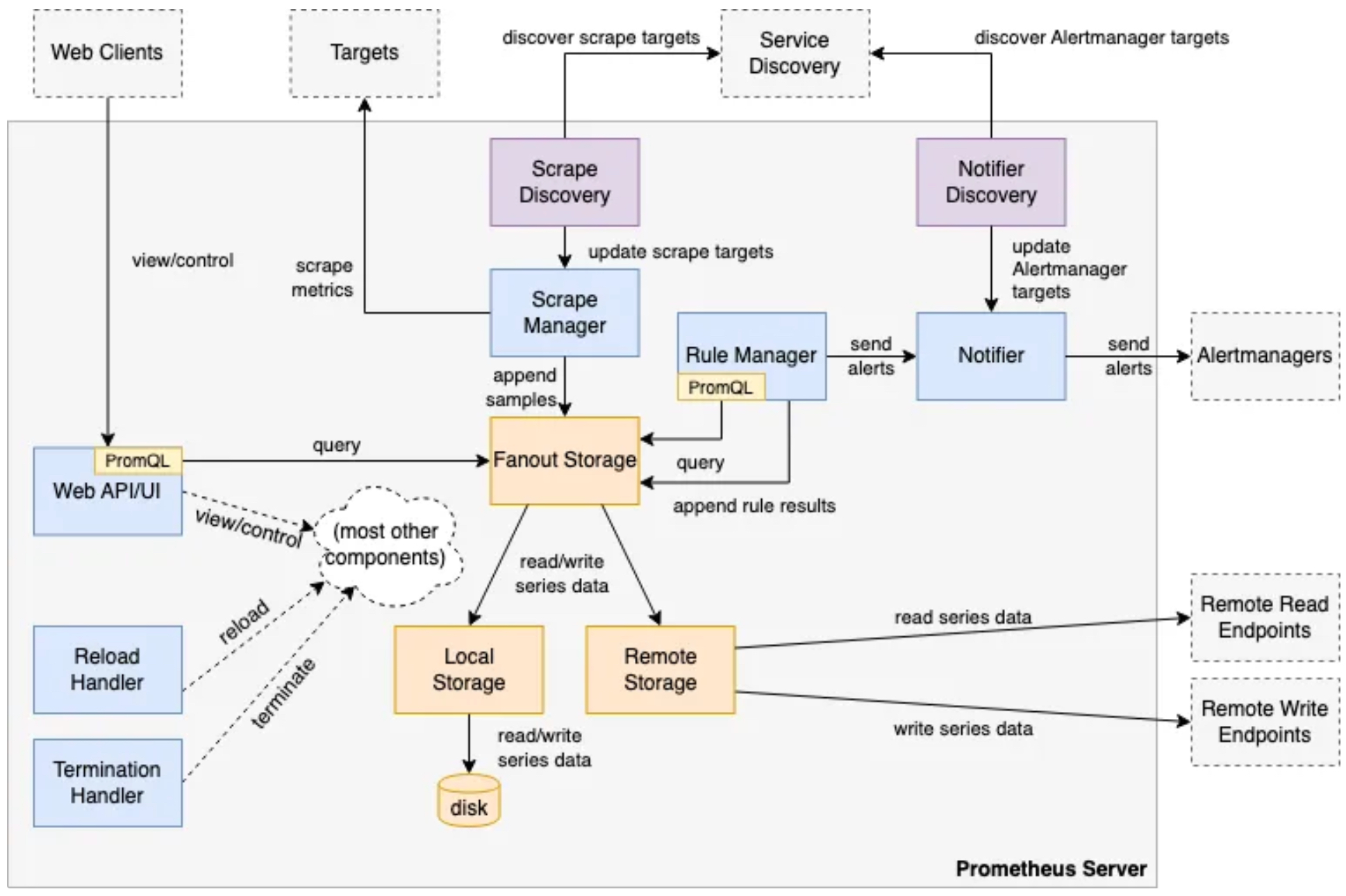
- 메트릭은 일반인이 이해하기 쉬운 수치적 측정입니다. 시계열이라는 용어는 시간에 따른 변화를 기록하는 것을 말합니다. 사용자가 측정하고자 하는 것은 애플리케이션마다 다릅니다. 웹 서버의 경우 요청 시간이 될 수 있고, 데이터베이스의 경우 활성 연결 또는 활성 쿼리 수가 될 수 있습니다.
-
프로메테우스 3.0 출시 : 2.0, 2.18 버전 대비 처리 성능(CPU/Mem) 향상 - Blog, DevOcean, GeekNews, Youtube
7.2 EC에 Prometheus 직접 설치
- Prometheus 설치
# 최신 버전 다운로드
wget https://github.com/prometheus/prometheus/releases/download/v3.2.0/prometheus-3.2.0.linux-amd64.tar.gz
# 압축 해제
tar -xvf prometheus-3.2.0.linux-amd64.tar.gz
cd prometheus-3.2.0.linux-amd64
ls -l
#
mv prometheus /usr/local/bin/
mv promtool /usr/local/bin/
mkdir -p /etc/prometheus /var/lib/prometheus
mv prometheus.yml /etc/prometheus/
cat /etc/prometheus/prometheus.yml
#
useradd --no-create-home --shell /sbin/nologin prometheus
chown -R prometheus:prometheus /etc/prometheus /var/lib/prometheus
chown prometheus:prometheus /usr/local/bin/prometheus /usr/local/bin/promtool
#
tee /etc/systemd/system/prometheus.service > /dev/null <<EOF
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus \
--web.listen-address=0.0.0.0:9090
[Install]
WantedBy=multi-user.target
EOF
#
systemctl daemon-reload
systemctl enable --now prometheus
systemctl status prometheus
ss -tnlp
#
curl localhost:9090/metrics
echo -e "http://$(curl -s ipinfo.io/ip):9090"
http://3.35.141.47:9090
- node_exporter 설치 - Github
# Node Exporter 최신 버전 다운로드
cd ~
wget https://github.com/prometheus/node_exporter/releases/download/v1.9.0/node_exporter-1.9.0.linux-amd64.tar.gz
tar xvfz node_exporter-1.9.0.linux-amd64.tar.gz
cd node_exporter-1.9.0.linux-amd64
cp node_exporter /usr/local/bin/
#
groupadd -f node_exporter
useradd -g node_exporter --no-create-home --shell /sbin/nologin node_exporter
chown node_exporter:node_exporter /usr/local/bin/node_exporter
#
tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
Documentation=https://prometheus.io/docs/guides/node-exporter/
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
Restart=on-failure
ExecStart=/usr/local/bin/node_exporter \
--web.listen-address=:9200
[Install]
WantedBy=multi-user.target
EOF
# 데몬 실행
systemctl daemon-reload
systemctl enable --now node_exporter
systemctl status node_exporter
ss -tnlp
#
curl localhost:9200/metrics- Prometheus 설정에 수집 대상 target (node_exporter) 추가
# prometheus.yml 수정
cat << EOF >> /etc/prometheus/prometheus.yml
- job_name: 'node_exporter'
static_configs:
- targets: ["127.0.0.1:9200"]
labels:
alias: 'myec2'
EOF
# prometheus 데몬 재기동
systemctl restart prometheus.service
systemctl status prometheus- prometheus 웹에서 target 확인 및 node 로 시작되는 메트릭 쿼리 해보기
rate(node_cpu_seconds_total{mode="system"}[1m])
node_filesystem_avail_bytes
rate(node_network_receive_bytes_total[1m])
7.3 프로메테우스-스택 설치
- 모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값/수준) 등 - Helm
- kube-prometheus-stack collects Kubernetes manifests, Grafana dashboards, and Prometheus rules combined with documentation and scripts to provide easy to operate end-to-end Kubernetes cluster monitoring with Prometheus using the Prometheus Operator.
# 모니터링
watch kubectl get pod,pvc,svc,ingress -n monitoring
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-sejkim-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-sejkim-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
alertmanager:
enabled: false
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
cat monitor-values.yaml
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 69.3.1 \
-f monitor-values.yaml --create-namespace --namespace monitoring
Release "kube-prometheus-stack" has been upgraded. Happy Helming!
NAME: kube-prometheus-stack
LAST DEPLOYED: Sat Mar 1 22:17:11 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 3
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
Get Grafana 'admin' user password by running:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Access Grafana local instance:
export POD_NAME=$(kubectl --namespace monitoring get pod -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=kube-prometheus-stack" -oname)
kubectl --namespace monitoring port-forward $POD_NAME 3000
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana-0 : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2025-03-01 01:36:45.551385 +0900 KST deployed kube-prometheus-stack-69.3.1 v0.80.0
kubectl get sts,ds,deploy,pod,svc,ep,ingress,pvc,pv -n monitoring
NAME
NAME READY AGE
statefulset.apps/kube-prometheus-stack-grafana 1/1 79s
statefulset.apps/prometheus-kube-prometheus-stack-prometheus 1/1 77s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prometheus-stack-prometheus-node-exporter 3 3 3 3 3 kubernetes.io/os=linux 20h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prometheus-stack-kube-state-metrics 1/1 1 1 20h
deployment.apps/kube-prometheus-stack-operator 1/1 1 1 20h
NAME READY STATUS RESTARTS AGE
pod/kube-prometheus-stack-grafana-0 3/3 Running 0 79s
pod/kube-prometheus-stack-kube-state-metrics-5dbfbd4b9-69xpp 1/1 Running 2 (4h42m ago) 19h
pod/kube-prometheus-stack-operator-76bdd654bf-wnvmv 1/1 Running 0 19h
pod/kube-prometheus-stack-prometheus-node-exporter-bf9m2 1/1 Running 0 13h
pod/kube-prometheus-stack-prometheus-node-exporter-mm887 1/1 Running 2 (4h41m ago) 13h
pod/kube-prometheus-stack-prometheus-node-exporter-wf5cg 1/1 Running 0 13h
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 77s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-grafana ClusterIP 10.100.195.242 <none> 80/TCP 20h
service/kube-prometheus-stack-grafana-headless ClusterIP None <none> 9094/TCP 79s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 10.100.202.31 <none> 8080/TCP 20h
service/kube-prometheus-stack-operator ClusterIP 10.100.179.61 <none> 443/TCP 20h
service/kube-prometheus-stack-prometheus ClusterIP 10.100.39.248 <none> 9090/TCP,8080/TCP 20h
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.78.209 <none> 9100/TCP 20h
service/prometheus-operated ClusterIP None <none> 9090/TCP 20h
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-grafana 192.168.3.144:3000 20h
endpoints/kube-prometheus-stack-grafana-headless 192.168.3.144:9094 79s
endpoints/kube-prometheus-stack-kube-state-metrics 192.168.1.159:8080 20h
endpoints/kube-prometheus-stack-operator 192.168.3.191:10250 20h
endpoints/kube-prometheus-stack-prometheus 192.168.2.6:9090,192.168.2.6:8080 20h
endpoints/kube-prometheus-stack-prometheus-node-exporter 192.168.1.60:9100,192.168.2.32:9100,192.168.3.30:9100 20h
endpoints/prometheus-operated 192.168.2.6:9090 20h
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.ksj7279.click 80 79s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.ksj7279.click 80 79s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 Bound pvc-47968a03-8ae9-4a76-87cc-0796525ec525 30Gi RWO gp3 <unset> 77s
persistentvolumeclaim/storage-kube-prometheus-stack-grafana-0 Bound pvc-4fdee80a-5e45-4e64-8b7b-8619fdaf16f2 20Gi RWO gp3 <unset> 79s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/pvc-47968a03-8ae9-4a76-87cc-0796525ec525 30Gi RWO Delete Bound monitoring/prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 gp3 <unset> 75s
persistentvolume/pvc-4fdee80a-5e45-4e64-8b7b-8619fdaf16f2 20Gi RWO Delete Bound monitoring/storage-kube-prometheus-stack-grafana-0 gp3 <unset> 76s
kubectl get-all -n monitoring
NAME NAMESPACE AGE
configmap/kube-prometheus-stack-apiserver monitoring 20h
configmap/kube-prometheus-stack-cluster-total monitoring 20h
configmap/kube-prometheus-stack-grafana monitoring 20h
configmap/kube-prometheus-stack-grafana-config-dashboards monitoring 20h
configmap/kube-prometheus-stack-grafana-datasource monitoring 20h
configmap/kube-prometheus-stack-grafana-overview monitoring 20h
configmap/kube-prometheus-stack-k8s-coredns monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-cluster monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-multicluster monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-namespace monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-node monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-pod monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-workload monitoring 20h
configmap/kube-prometheus-stack-k8s-resources-workloads-namespace monitoring 20h
configmap/kube-prometheus-stack-kubelet monitoring 20h
configmap/kube-prometheus-stack-namespace-by-pod monitoring 20h
configmap/kube-prometheus-stack-namespace-by-workload monitoring 20h
configmap/kube-prometheus-stack-node-cluster-rsrc-use monitoring 20h
configmap/kube-prometheus-stack-node-rsrc-use monitoring 20h
configmap/kube-prometheus-stack-nodes monitoring 20h
configmap/kube-prometheus-stack-nodes-aix monitoring 20h
configmap/kube-prometheus-stack-nodes-darwin monitoring 20h
configmap/kube-prometheus-stack-persistentvolumesusage monitoring 20h
configmap/kube-prometheus-stack-pod-total monitoring 20h
configmap/kube-prometheus-stack-prometheus monitoring 20h
configmap/kube-prometheus-stack-proxy monitoring 20h
configmap/kube-prometheus-stack-workload-total monitoring 20h
configmap/kube-root-ca.crt monitoring 20h
configmap/prometheus-kube-prometheus-stack-prometheus-rulefiles-0 monitoring 20h
endpoints/kube-prometheus-stack-grafana monitoring 20h
endpoints/kube-prometheus-stack-grafana-headless monitoring 4m52s
endpoints/kube-prometheus-stack-kube-state-metrics monitoring 20h
endpoints/kube-prometheus-stack-operator monitoring 20h
endpoints/kube-prometheus-stack-prometheus monitoring 20h
endpoints/kube-prometheus-stack-prometheus-node-exporter monitoring 20h
endpoints/prometheus-operated monitoring 20h
persistentvolumeclaim/prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 monitoring 4m50s
persistentvolumeclaim/storage-kube-prometheus-stack-grafana-0 monitoring 4m52s
pod/kube-prometheus-stack-grafana-0 monitoring 4m52s
pod/kube-prometheus-stack-kube-state-metrics-5dbfbd4b9-69xpp monitoring 19h
pod/kube-prometheus-stack-operator-76bdd654bf-wnvmv monitoring 19h
pod/kube-prometheus-stack-prometheus-node-exporter-bf9m2 monitoring 13h
pod/kube-prometheus-stack-prometheus-node-exporter-mm887 monitoring 13h
pod/kube-prometheus-stack-prometheus-node-exporter-wf5cg monitoring 13h
pod/prometheus-kube-prometheus-stack-prometheus-0 monitoring 4m50s
secret/kube-prometheus-stack-admission monitoring 20h
secret/kube-prometheus-stack-grafana monitoring 20h
secret/prometheus-kube-prometheus-stack-prometheus monitoring 20h
secret/prometheus-kube-prometheus-stack-prometheus-thanos-prometheus-http-client-file monitoring 20h
secret/prometheus-kube-prometheus-stack-prometheus-tls-assets-0 monitoring 20h
secret/prometheus-kube-prometheus-stack-prometheus-web-config monitoring 20h
secret/sh.helm.release.v1.kube-prometheus-stack.v1 monitoring 20h
secret/sh.helm.release.v1.kube-prometheus-stack.v2 monitoring 5m5s
serviceaccount/default monitoring 20h
serviceaccount/kube-prometheus-stack-grafana monitoring 20h
serviceaccount/kube-prometheus-stack-kube-state-metrics monitoring 20h
serviceaccount/kube-prometheus-stack-operator monitoring 20h
serviceaccount/kube-prometheus-stack-prometheus monitoring 20h
serviceaccount/kube-prometheus-stack-prometheus-node-exporter monitoring 20h
service/kube-prometheus-stack-grafana monitoring 20h
service/kube-prometheus-stack-grafana-headless monitoring 4m52s
service/kube-prometheus-stack-kube-state-metrics monitoring 20h
service/kube-prometheus-stack-operator monitoring 20h
service/kube-prometheus-stack-prometheus monitoring 20h
service/kube-prometheus-stack-prometheus-node-exporter monitoring 20h
service/prometheus-operated monitoring 20h
controllerrevision.apps/kube-prometheus-stack-grafana-5d4b798f7f monitoring 4m52s
controllerrevision.apps/kube-prometheus-stack-prometheus-node-exporter-89f764479 monitoring 20h
controllerrevision.apps/prometheus-kube-prometheus-stack-prometheus-54fff4d756 monitoring 4m50s
daemonset.apps/kube-prometheus-stack-prometheus-node-exporter monitoring 20h
deployment.apps/kube-prometheus-stack-kube-state-metrics monitoring 20h
deployment.apps/kube-prometheus-stack-operator monitoring 20h
replicaset.apps/kube-prometheus-stack-kube-state-metrics-5dbfbd4b9 monitoring 20h
replicaset.apps/kube-prometheus-stack-operator-76bdd654bf monitoring 20h
statefulset.apps/kube-prometheus-stack-grafana monitoring 4m52s
statefulset.apps/prometheus-kube-prometheus-stack-prometheus monitoring 4m50s
endpointslice.discovery.k8s.io/kube-prometheus-stack-grafana-headless-rf4kn monitoring 4m52s
endpointslice.discovery.k8s.io/kube-prometheus-stack-grafana-qmmwn monitoring 20h
endpointslice.discovery.k8s.io/kube-prometheus-stack-kube-state-metrics-k7xgc monitoring 20h
endpointslice.discovery.k8s.io/kube-prometheus-stack-operator-299mk monitoring 20h
endpointslice.discovery.k8s.io/kube-prometheus-stack-prometheus-node-exporter-9hcq9 monitoring 20h
endpointslice.discovery.k8s.io/kube-prometheus-stack-prometheus-tqtgk monitoring 20h
endpointslice.discovery.k8s.io/prometheus-operated-plpq8 monitoring 20h
prometheus.monitoring.coreos.com/kube-prometheus-stack-prometheus monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-grafana monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-proxy monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-state-metrics monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kubelet monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-operator monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus monitoring 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus-node-exporter monitoring 20h
ingress.networking.k8s.io/kube-prometheus-stack-grafana monitoring 4m52s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus monitoring 4m52s
rolebinding.rbac.authorization.k8s.io/kube-prometheus-stack-grafana monitoring 20h
role.rbac.authorization.k8s.io/kube-prometheus-stack-grafana monitoring 20h
kubectl get prometheus,servicemonitors -n monitoring
NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
prometheus.monitoring.coreos.com/kube-prometheus-stack-prometheus v3.1.0 1 1 True True 20h
NAME AGE
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-apiserver 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-coredns 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-grafana 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-proxy 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kube-state-metrics 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-kubelet 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-operator 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus 20h
servicemonitor.monitoring.coreos.com/kube-prometheus-stack-prometheus-node-exporter 20h
alertmanagerconfigs.monitoring.coreos.com 2025-02-28T16:36:40Z
alertmanagers.monitoring.coreos.com 2025-02-28T16:36:41Z
podmonitors.monitoring.coreos.com 2025-02-28T16:36:41Z
probes.monitoring.coreos.com 2025-02-28T16:36:41Z
prometheusagents.monitoring.coreos.com 2025-02-28T16:36:41Z
prometheuses.monitoring.coreos.com 2025-02-28T16:36:42Z
prometheusrules.monitoring.coreos.com 2025-02-28T16:36:42Z
scrapeconfigs.monitoring.coreos.com 2025-02-28T16:36:43Z
servicemonitors.monitoring.coreos.com 2025-02-28T16:36:43Z
thanosrulers.monitoring.coreos.com 2025-02-28T16:36:44Z
PV NAME PVC NAME NAMESPACE NODE NAME POD NAME VOLUME MOUNT NAME SIZE USED AVAILABLE %USED IUSED IFREE %IUSED
pvc-4fdee80a-5e45-4e64-8b7b-8619fdaf16f2 storage-kube-prometheus-stack-grafana-0 monitoring ip-192-168-3-30.ap-northeast-2.compute.internal kube-prometheus-stack-grafana-0 storage 19Gi 196Mi 19Gi 0.96 85 10485675 0.00
pvc-47968a03-8ae9-4a76-87cc-0796525ec525 prometheus-kube-prometheus-stack-prometheus-db-prometheus-kube-prometheus-stack-prometheus-0 monitoring ip-192-168-2-32.ap-northeast-2.compute.internal prometheus-kube-prometheus-stack-prometheus-0 prometheus-kube-prometheus-stack-prometheus-db 29Gi 262Mi 29Gi 0.86 9 15728631 0.00
# 프로메테우스 버전 확인
echo -e "https://prometheus.$MyDomain/api/v1/status/buildinfo"
https://prometheus.ksj7279.click/api/v1/status/buildinfo
open https://prometheus.$MyDomain/api/v1/status/buildinfo # macOS
kubectl exec -it sts/prometheus-kube-prometheus-stack-prometheus -n monitoring -c prometheus -- prometheus --version
prometheus, version 3.1.0 (branch: HEAD, revision: 7086161a93b262aa0949dbf2aba15a5a7b13e0a3)
build user: root@74c225e2044f
build date: 20250102-13:52:43
go version: go1.23.4
platform: linux/amd64
tags: netgo,builtinassets,stringlabels-
프로메테우스 웹 접속
echo -e "https://prometheus.$MyDomain"
https://prometheus.ksj7279.click
open "https://prometheus.$MyDomain" # macOS
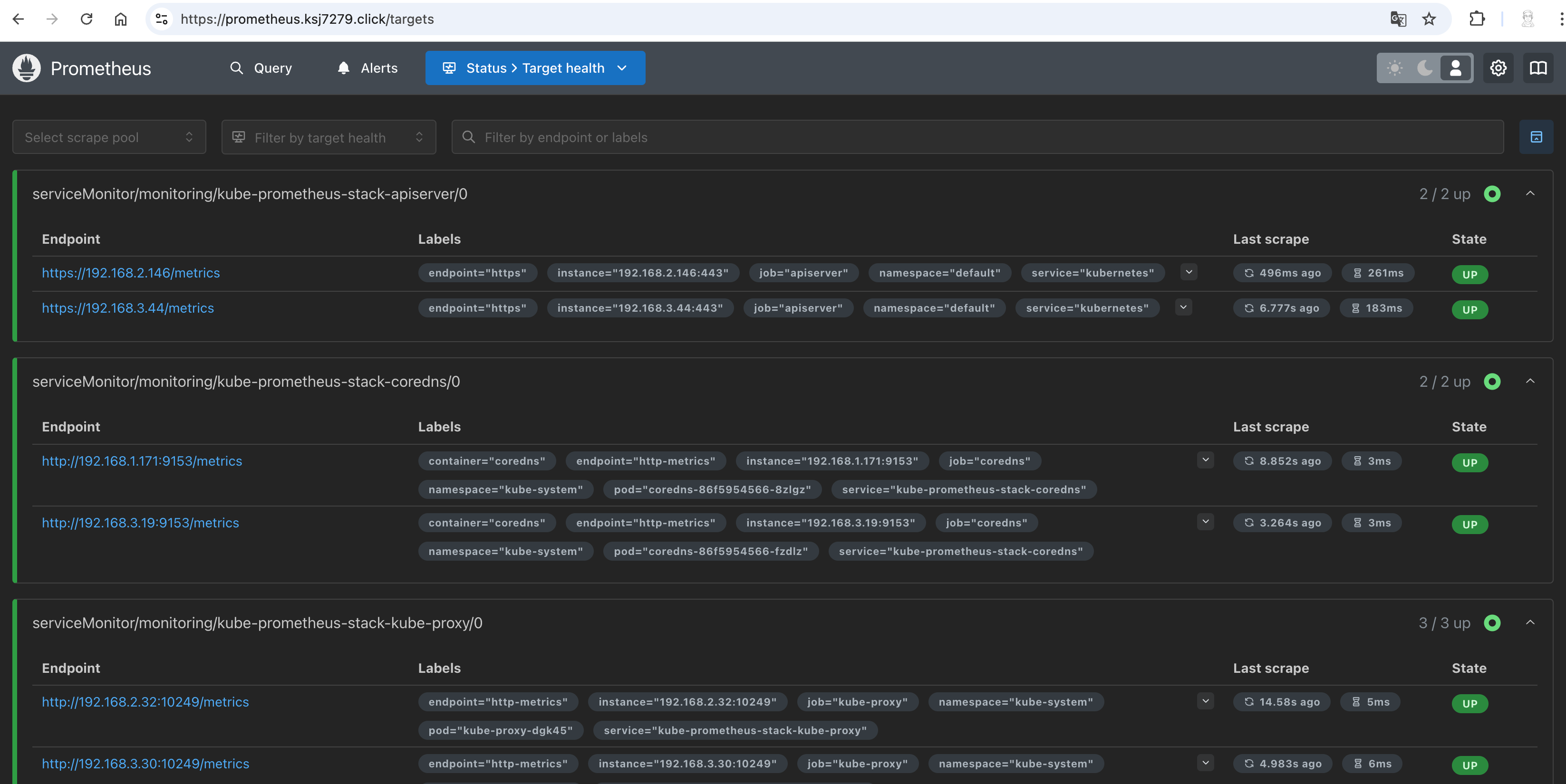
-
그라파나 웹 접속
echo -e "https://grafana.$MyDomain"
open "https://grafana.$MyDomain" # macOS
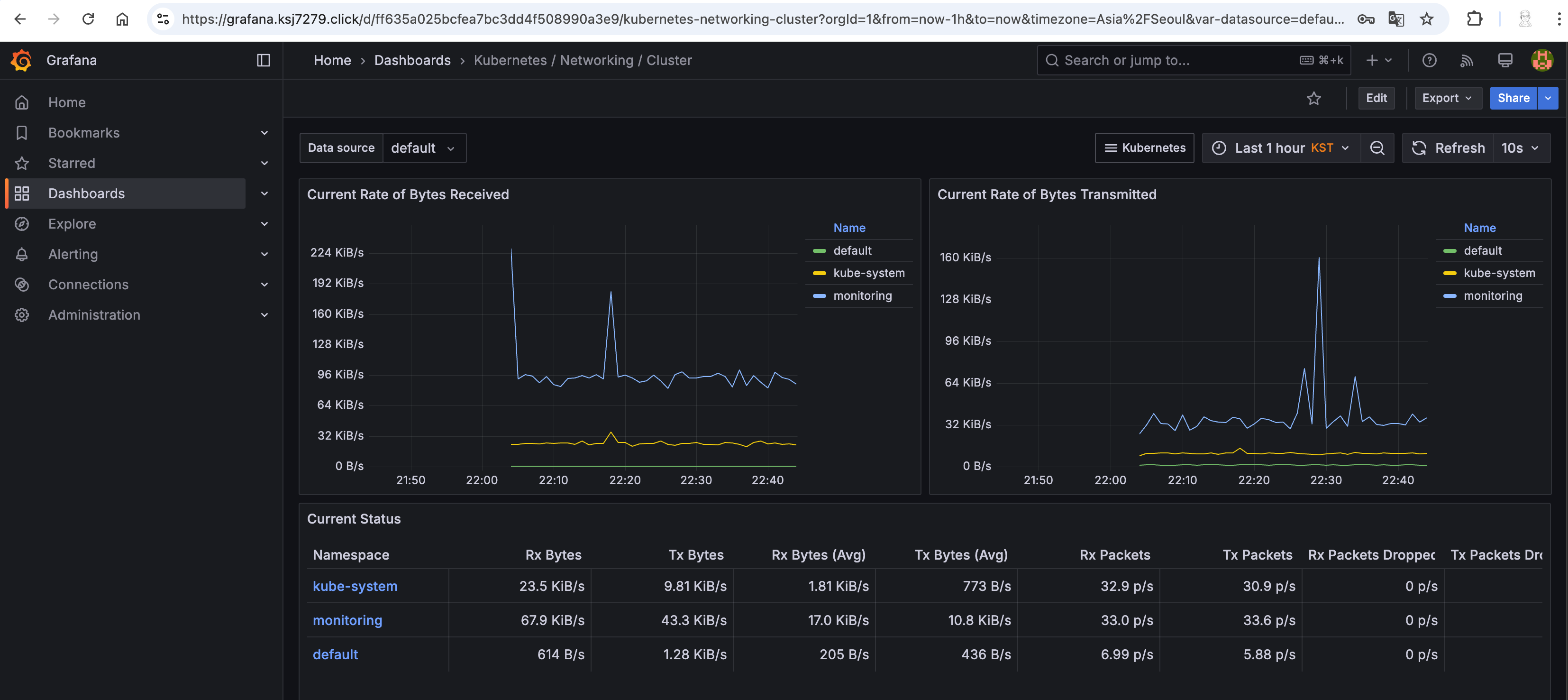
-
AWS ELB(ALB) 갯수 확인 → Rule 확인(어떻게 여러 도메인 처리를 하는 걸까?) ⇒ HTTP(80) 인입 시 어떻게 처리하나요?
- 443 Port로 Redirection 함
- 규칙에 의해 HTTP 호스트 헤더의 도메인을 참조하여 해당 TargetGroup으로 Routing 함
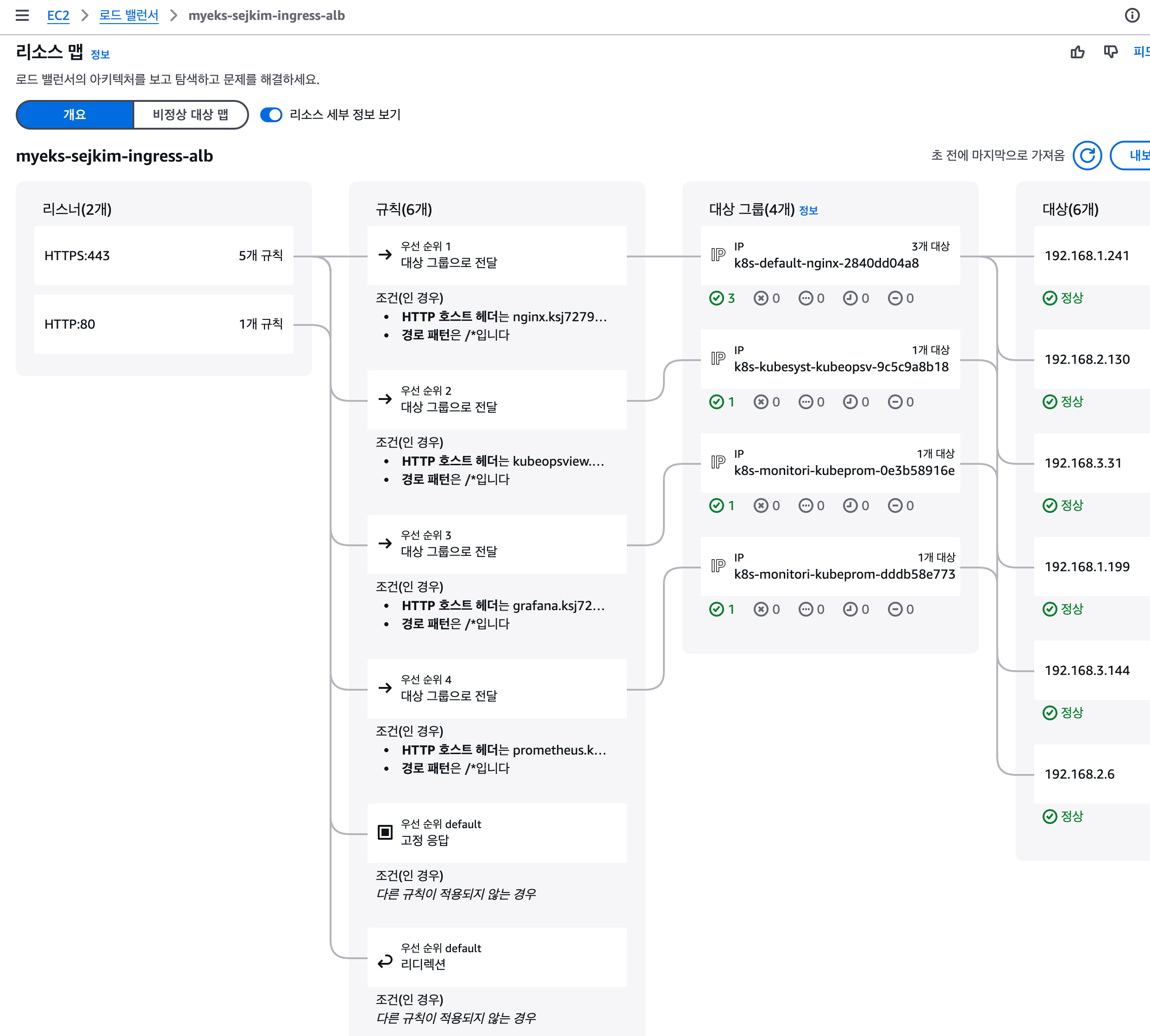
- 443 Port로 Redirection 함
-
(참고) kube-controller-manager, etcd, kube-scheduler 수집 불가? - 구글링 , AWS_Docs
- 프로메테우스 웹 → Status → Targets 확인 : kube-controller-manager, etcd, kube-scheduler 확인
- kubectl get --raw /metrics
- kubectl get --raw "/apis/metrics.eks.amazonaws.com/v1/kcm/container/metrics"
- 프로메테우스 웹 → Status → Targets 확인 : kube-controller-manager, etcd, kube-scheduler 확인
-
(참고) 삭제 시
# helm 삭제
helm uninstall -n monitoring kube-prometheus-stack
# crd 삭제
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd probes.monitoring.coreos.com
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd thanosrulers.monitoring.coreos.com7.4 [Amazon EKS] AWS CNI Metrics 수집을 위한 사전 설정 - 링크
- PodMonitor 배포
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat
# metrics url 접속 확인
curl -s $N1:61678/metrics | grep '^awscni'
awscni_add_ip_req_count 8
awscni_assigned_ip_addresses 8
awscni_assigned_ip_per_cidr{cidr="192.168.1.104/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.119/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.159/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.171/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.199/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.226/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.241/32"} 1
awscni_assigned_ip_per_cidr{cidr="192.168.1.67/32"} 1
awscni_assigned_ip_per_eni{eni="eni-00525a881c42b4dce"} 5
awscni_assigned_ip_per_eni{eni="eni-0923f1ecc592c14cd"} 1
awscni_assigned_ip_per_eni{eni="eni-0af0ca45364300df7"} 2
awscni_aws_api_latency_ms_sum{api="DescribeNetworkInterfaces",error="false",status="200"} 328
awscni_aws_api_latency_ms_count{api="DescribeNetworkInterfaces",error="false",status="200"} 1
awscni_aws_api_latency_ms_sum{api="GetMetadata",error="false",status="200"} 3121
awscni_aws_api_latency_ms_count{api="GetMetadata",error="false",status="200"} 9244
awscni_aws_api_latency_ms_sum{api="GetMetadata",error="true",status="404"} 352
awscni_aws_api_latency_ms_count{api="GetMetadata",error="true",status="404"} 1065
awscni_aws_api_latency_ms_sum{api="ModifyNetworkInterfaceAttribute",error="false",status="200"} 1161
awscni_aws_api_latency_ms_count{api="ModifyNetworkInterfaceAttribute",error="false",status="200"} 3
awscni_build_info{goversion="go1.22.12",version=""} 1
awscni_del_ip_req_count{reason="PodDeleted"} 7
awscni_ec2api_req_count{fn="DescribeNetworkInterfaces"} 7
awscni_ec2api_req_count{fn="ModifyNetworkInterfaceAttribute"} 3
awscni_eni_allocated 3
awscni_eni_max 3
awscni_force_removed_enis 0
awscni_force_removed_ips 0
awscni_ip_max 15
awscni_ipamd_action_inprogress{fn="nodeIPPoolReconcile"} 0
awscni_ipamd_action_inprogress{fn="nodeInit"} 0
awscni_no_available_ip_addresses 0
awscni_reconcile_count{fn="eniDataStorePoolReconcileAdd"} 5310
awscni_total_ip_addresses 15
awscni_total_ipv4_prefixes 0- 프로메테우스 Target , job (aws-cni 검색)
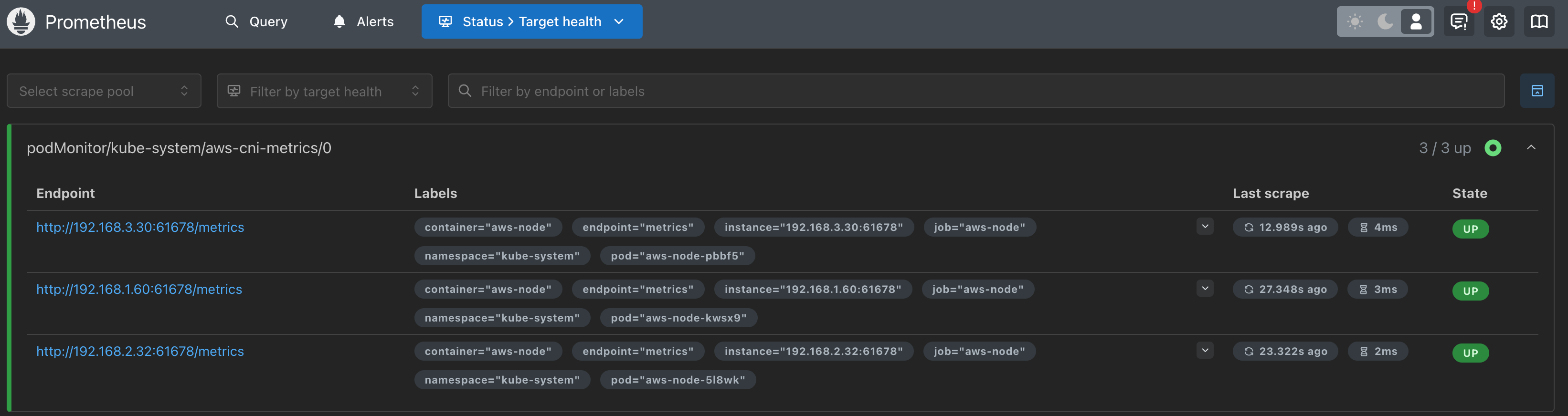
7.5 프로메테우스 기본사용
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 포트 접속하여 메트릭 정보를 수집
kubectl get node -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ip-192-168-1-60.ap-northeast-2.compute.internal Ready <none> 14h v1.31.5-eks-5d632ec 192.168.1.60 3.35.13.79 Amazon Linux 2023.6.20250218 6.1.128-136.201.amzn2023.x86_64 containerd://1.7.25
ip-192-168-2-32.ap-northeast-2.compute.internal Ready <none> 14h v1.31.5-eks-5d632ec 192.168.2.32 3.35.15.208 Amazon Linux 2023.6.20250218 6.1.128-136.201.amzn2023.x86_64 containerd://1.7.25
ip-192-168-3-30.ap-northeast-2.compute.internal Ready <none> 14h v1.31.5-eks-5d632ec 192.168.3.30 43.200.178.41 Amazon Linux 2023.6.20250218 6.1.128-136.201.amzn2023.x86_64 containerd://1.7.25
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.100.78.209 <none> 9100/TCP 21h
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus-node-exporter 192.168.1.60:9100,192.168.2.32:9100,192.168.3.30:9100 21h
# (노드 익스포터 경우) 노드의 9100번 포트의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh ec2-user@$N1 curl -s localhost:9100/metrics- 프로메테우스 ingress 도메인으로 웹 접속
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-prometheus alb prometheus.ksj7279.click myeks-sejkim-ingress-alb-1893285509.ap-northeast-2.elb.amazonaws.com 80 85m
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$MyDomain"
open "https://prometheus.$MyDomain" macOS
# 웹 상단 주요 메뉴 설명
1. 쿼리(Query) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
2. 경고(Alerts) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전 정보
- Use local time : 출력 시간을 로컬 타임으로 변경
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
- Enable linter : 문법 오류 감지, 자동 코스 스타일 체크-
Statues → 프로메테우스 설정(Configuration) 확인 : Status → Runtime & Build Information 클릭
- Storage retention : 5d or 10GiB → 메트릭 저장 기간이 5일 경과 혹은 10GiB 이상 시 오래된 것부터 삭제 ⇒ helm 파라미터에서 수정 가능
-
Statues → 프로메테우스 설정(Configuration) 확인 : Status → Command-Line Flags 클릭
- -log.level : info
- -storage.tsdb.retention.size : 10GiB
- -storage.tsdb.retention.time : 5d
-
Statues → 프로메테우스 설정(Configuration) 확인 : Status → Configuration
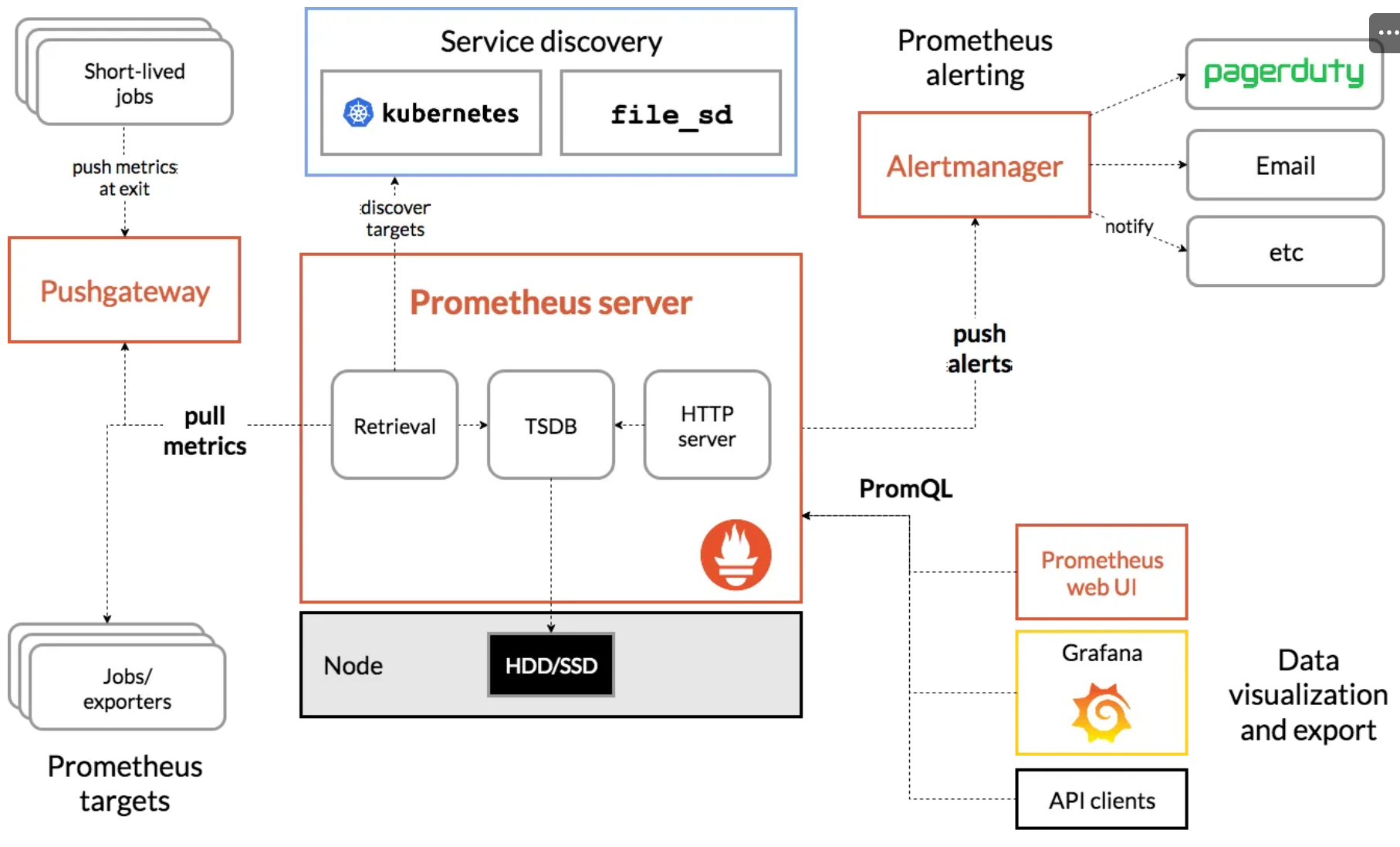
-
job name 을 기준으로 scraping
global:
scrape_interval: 15s # 메트릭 가져오는(scrape) 주기
scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃
evaluation_interval: 15s # alert 보낼지 말지 판단하는 주기
...
- job_name: serviceMonitor/monitoring/kube-prometheus-stack-prometheus-node-exporter/0
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
...
relabel_configs:
- source_labels: [job]
separator: ;
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_instance, __meta_kubernetes_service_labelpresent_app_kubernetes_io_instance]
separator: ;
regex: (kube-prometheus-stack);true
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name, __meta_kubernetes_service_labelpresent_app_kubernetes_io_name]
separator: ;
regex: (prometheus-node-exporter);true
replacement: $1
action: keep
...
kubernetes_sd_configs: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영
- role: endpoints # 서비스에 연결된 엔드포인트(Pod IP + Port) 탐색
kubeconfig_file: "" # Prometheus가 실행 중인 환경의 기본 kubeconfig 사용
follow_redirects: true # 엔드포인트를 변경할 경우 이를 따라감
enable_http2: true
namespaces:
own_namespace: false # 자신이 실행 중인 네임스페이스가 아닌 곳에서도 탐색 가능
names:
- monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정 : monitoring 네임스페이스에 있는 서비스만 타겟팅, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
...
- job_name: podMonitor/kube-system/aws-cni-metrics/0
honor_timestamps: true
...
relabel_configs:
- source_labels: [job]
separator: ;
target_label: __tmp_prometheus_job_name
replacement: $1
action: replace # job 라벨 값을 __tmp_prometheus_job_name에 저장
- source_labels: [__meta_kubernetes_pod_label_k8s_app, __meta_kubernetes_pod_labelpresent_k8s_app]
separator: ;
regex: (aws-node);true
replacement: $1
action: keep # Pod의 k8s_app 라벨 값이 aws-node인 경우만 유지
...
kubernetes_sd_configs:
- role: pod # 클러스터 내 모든 개별 Pod 탐색
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- kube-system
...- 전체 메트릭 대상(Targets) 확인 : Status → Target health
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함
- 현재 각 Target 클릭 시 메트릭 정보 확인 : 아래 예시
# serviceMonitor/monitoring/kube-prometheus-stack-kube-proxy/0 (3/3 up) 중 노드1에 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
ssh $N1 curl -s http://localhost:10249/metrics
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="4.194304e+06"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="1.6777216e+07"} 1
rest_client_response_size_bytes_bucket{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST",le="+Inf"} 1
rest_client_response_size_bytes_sum{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 626
rest_client_response_size_bytes_count{host="006fc3f3f0730a7fb3fdb3181f546281.gr7.ap-northeast-2.eks.amazonaws.com",verb="POST"} 1
...
# [운영서버 EC2] serviceMonitor/monitoring/kube-prometheus-stack-api-server/0 (2/2 up) 중 Endpoint 접속 확인 (접속 주소는 실습 환경에 따라 다름)
>> 해당 IP주소는 어디인가요?, 왜 apiserver endpoint는 2개뿐인가요? , 아래 메트릭 수집이 되게 하기 위해서는 어떻게 하면 될까요?
curl -s https://192.168.1.53/metrics | tail -n 5
...
# [운영서버 EC2] 그외 다른 타켓의 Endpoint 로 접속 확인 가능 : 예시) 아래는 coredns 의 Endpoint 주소 (접속 주소는 실습 환경에 따라 다름)
curl -s http://192.168.1.75:9153/metrics | tail -n 5
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.79350016e+08
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19-
프로메테우스 설정(Configuration) 확인 : Status → Service Discovery : 모든 endpoint 로 도달 가능 시 자동 발견!, 도달 규칙은 설정Configuration 파일에 정의
- 예) serviceMonitor/monitoring/kube-prometheus-stack-apiserver/0 경우 해당 address="192.168.1.53:443" 도달 가능 시 자동 발견됨
-
메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
(node_cpu_seconds_total{mode="idle"}[1m])# 노드 메트릭
node 입력 후 자동 출력되는 메트릭 확인 후 선택
node_boot_time_seconds
# kube 메트릭
kube 입력 후 자동 출력되는 메트릭 확인 후 선택7.6 [중급] 쿼리 : node-exporter , kube-state-metrics , kube-proxy
- node-exporter : /proc, /sys 정보 - Link Docs
https://www.opsramp.com/guides/prometheus-monitoring/prometheus-node-exporter/
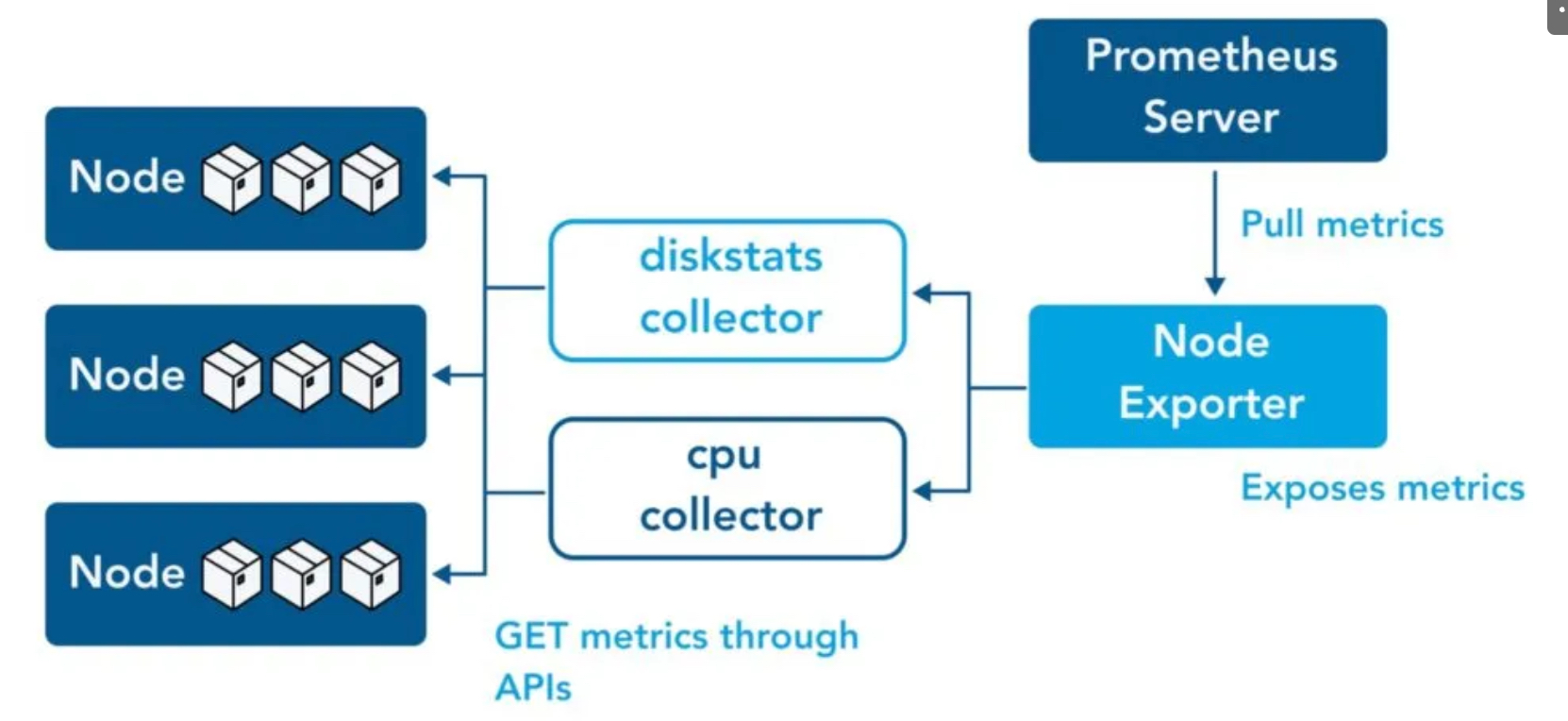
# Table 아래 쿼리 입력 후 Execute 클릭 -> Graph 확인
## 출력되는 메트릭 정보는 node-exporter 를 통해서 노드에서 수집된 정보
node_memory_Active_bytes
# 특정 노드(인스턴스) 필터링 : 아래 IP는 출력되는 자신의 인스턴스 PrivateIP 입력 후 Execute 클릭 -> Graph 확인
node_memory_Active_bytes{instance="192.168.1.60:9100"}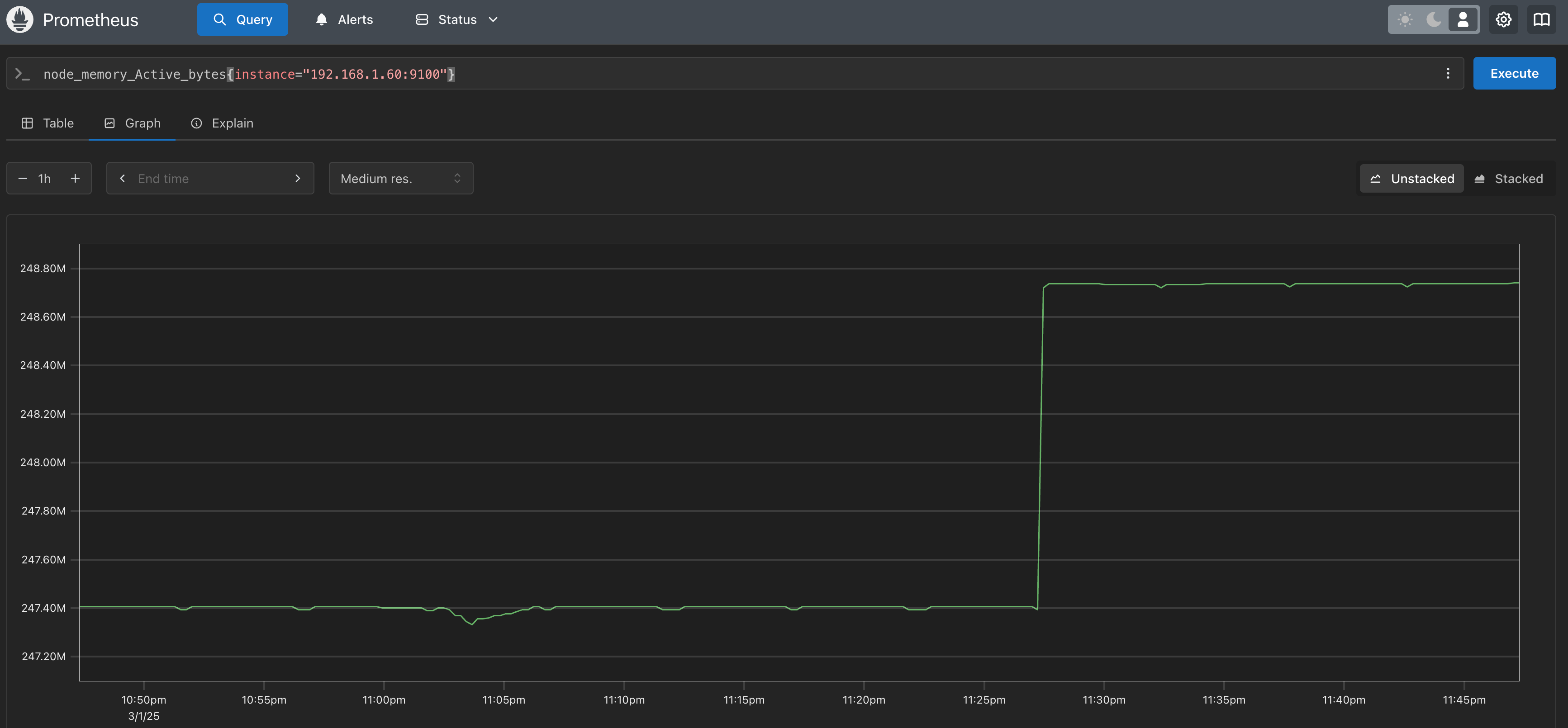
- kube-state-metrics (ksm) : k8s api 통해 k8s 오브젝트 정보 수집 - Link
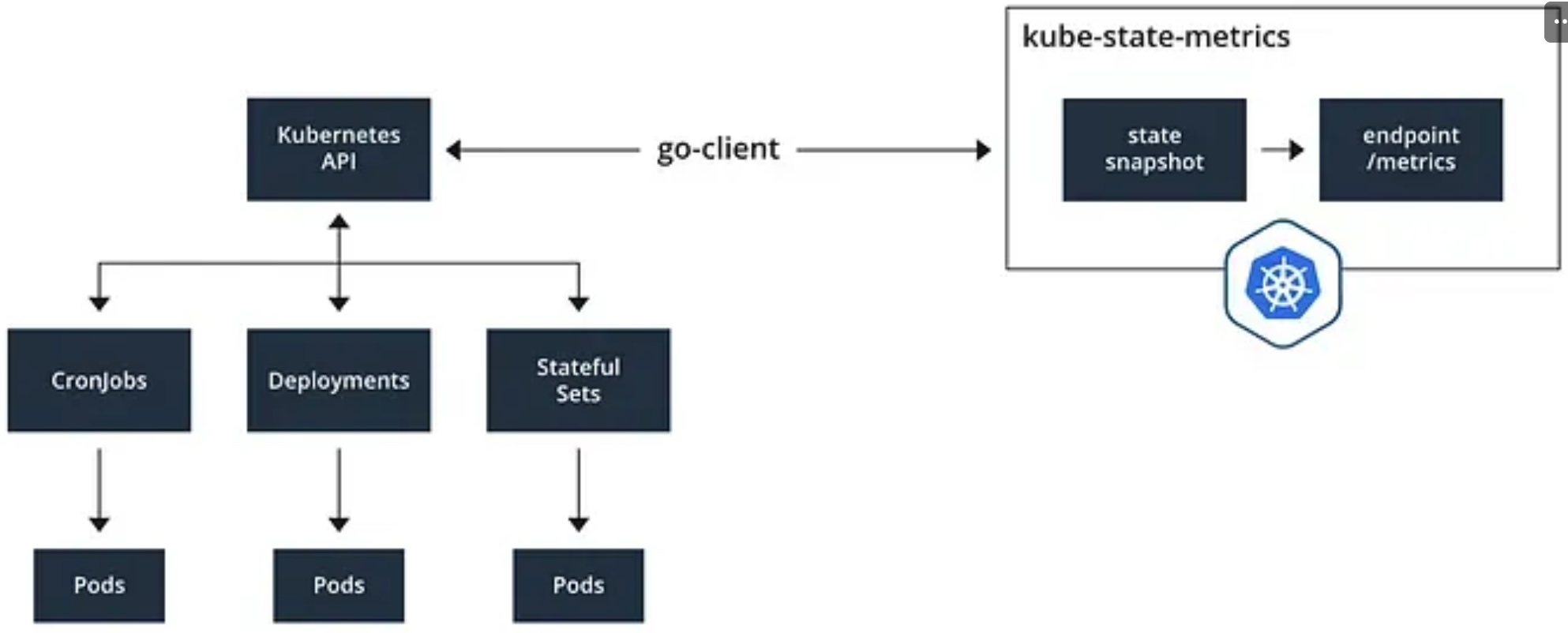
# replicas's number
kube_deployment_status_replicas
kube_deployment_status_replicas_available
kube_deployment_status_replicas_available{deployment="coredns"}
# scale out
kubectl scale deployment -n kube-system coredns --replicas 3
# 확인
kube_deployment_status_replicas_available{deployment="coredns"}
# scale in
kubectl scale deployment -n kube-system coredns --replicas 1
- kube-proxy : Github → 이미 애플리케이션 내장으로 메트릭 노출 준비 설정됨! (아래 코드 설명 by ChatGPT) → coredns 도? https://coredns.io/plugins/metrics/
- Kubernetes의 kube-proxy에서 사용되는 성능 및 상태 모니터링을 위한 메트릭을 정의하는 코드이다.
- iptables, IPVS, NFTables 등 프록시 모드별로 적절한 메트릭을 등록 및 관리한다.
- Netfilter 기반의 패킷 통계(nfacct)도 지원하여 패킷 드롭 및 로컬 트래픽 모니터링 기능을 포함한다.
#
kubeproxy_sync_proxy_rules_iptables_total
kubeproxy_sync_proxy_rules_iptables_total{table="filter"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="192.168.1.188:10249"}7.7 [중급] PromQL
-
프로메테우스 메트릭 종류 (4종) : Counter, Gauge, Histogram, Summary - Link Blog
- 게이지 Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- 카운터 Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- 서머리 Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- 히스토그램 Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
-
PromQL Query - Docs ,Operator ,Example
-
Label Matchers : = , ! = , =~ 정규표현식
# 예시 node_memory_Active_bytes node_memory_Active_bytes{instance="192.168.1.188:9100"} node_memory_Active_bytes{instance!="192.168.1.188:9100"} # 정규표현식 node_memory_Active_bytes{instance=~"192.168.+"} node_memory_Active_bytes{instance=~"192.168.1.+"} # 다수 대상 node_memory_Active_bytes{instance=~"192.168.1.188:9100|192.168.2.170:9100"} node_memory_Active_bytes{instance!~"192.168.1.188:9100|192.168.2.170:9100"} # 여러 조건 AND kube_deployment_status_replicas_available{namespace="kube-system"} kube_deployment_status_replicas_available{namespace="kube-system", deployment="coredns"} -
Binary Operators 이진 연산자 - Link
- 산술 이진 연산자 : + - / ^
- 비교 이진 연산자 : = = ! = > < > = < =
- 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
# 산술 이진 연산자 : + - * / * ^ node_memory_Active_bytes node_memory_Active_bytes/1024 node_memory_Active_bytes/1024/1024 # 비교 이진 연산자 : = = ! = > < > = < = nginx_http_requests_total nginx_http_requests_total > 100 nginx_http_requests_total > 10000 # 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합 kube_pod_status_ready kube_pod_container_resource_requests kube_pod_status_ready == 1 kube_pod_container_resource_requests > 1 kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1 kube_pod_status_ready == 1 and kube_pod_container_resource_requests > 1 -
Aggregation Operators 집계 연산자 - Link
sum(calculate sum over dimensions) : 조회된 값들을 모두 더함min(select minimum over dimensions) : 조회된 값에서 가장 작은 값을 선택max(select maximum over dimensions) : 조회된 값에서 가장 큰 값을 선택avg(calculate the average over dimensions) : 조회된 값들의 평균 값을 계산group(all values in the resulting vector are 1) : 조회된 값을 모두 ‘1’로 바꿔서 출력stddev(calculate population standard deviation over dimensions) : 조회된 값들의 모 표준 편차를 계산stdvar(calculate population standard variance over dimensions) : 조회된 값들의 모 표준 분산을 계산count(count number of elements in the vector) : 조회된 값들의 갯수를 출력 / 인스턴스 벡터에서만 사용 가능count_values(count number of elements with the same value) : 같은 값을 가지는 요소의 갯수를 출력bottomk(smallest k elements by sample value) : 조회된 값들 중에 가장 작은 값들 k 개 출력topk(largest k elements by sample value) : 조회된 값들 중에 가장 큰 값들 k 개 출력quantile(calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions) : 조회된 값들을 사분위로 나눠서 (0 < $ < 1)로 구성하고, $에 해당 하는 요소들을 출력
# node_memory_Active_bytes # 출력 값 중 Top 3 topk(3, node_memory_Active_bytes) # 출력 값 중 하위 3 bottomk(3, node_memory_Active_bytes) bottomk(3, node_memory_Active_bytes>0) # node 그룹별: by node_cpu_seconds_total node_cpu_seconds_total{mode="user"} node_cpu_seconds_total{mode="system"} avg(node_cpu_seconds_total) avg(node_cpu_seconds_total) by (instance) avg(node_cpu_seconds_total{mode="user"}) by (instance) avg(node_cpu_seconds_total{mode="system"}) by (instance) # nginx_http_requests_total sum(nginx_http_requests_total) sum(nginx_http_requests_total) by (instance) # 특정 내용 제외하고 출력 : without nginx_http_requests_total sum(nginx_http_requests_total) without (instance) sum(nginx_http_requests_total) without (instance,container,endpoint,job,namespace) -
Time series selectors : Instant/Range vector selectors, Time Durations, Offset modifier, @ modifier - Link
- 인스턴스 벡터 Instant Vector : 시점에 대한 메트릭 값만을 가지는 데이터 타입
- 레인지 벡터 Range Vector : 시간의 구간을 가지는 데이터 타입
- 시간 단위 : ms, s, m(주로 분 사용), h, d, w, y
-
# 시점 데이터
node_cpu_seconds_total
# 15초 마다 수집하니 아래는 지난 4회차/8회차의 값 출력
node_cpu_seconds_total[1m]
node_cpu_seconds_total[2m]- 활용
# 서비스 정보 >> 네임스페이스별 >> cluster_ip 별
kube_service_info
count(kube_service_info)
count(kube_service_info) by (namespace)
count(kube_service_info) by (cluster_ip)
# 컨테이너가 사용 메모리 -> 파드별
container_memory_working_set_bytes
sum(container_memory_working_set_bytes)
sum(container_memory_working_set_bytes) by (pod)
topk(5,sum(container_memory_working_set_bytes) by (pod))
topk(5,sum(container_memory_working_set_bytes) by (pod))/1024/1024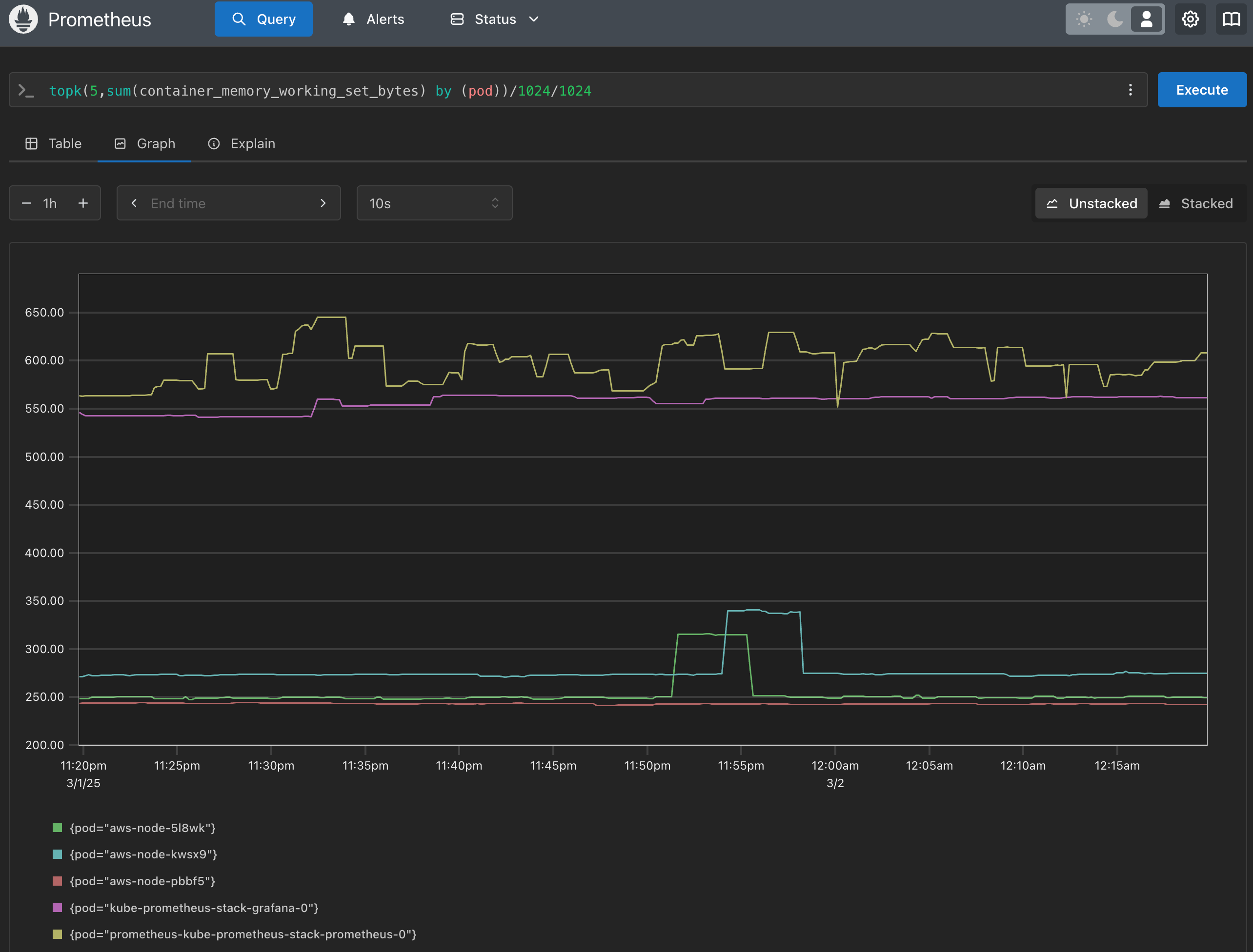
8. Grafana
8.1 소개
- TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등) - Docs , Blog , Toturials ,
- **Grafana open source software** enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
- Grafana OSS provides you with tools to turn your time-series database (TSDB) data into insightful graphs and visualizations.
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
- 접속 정보 확인 및 로그인 : 기본 계정 - admin / prom-operator
- **Grafana open source software** enables you to query, visualize, alert on, and explore your metrics, logs, and traces wherever they are stored.
# 그라파나 버전 확인
kubectl exec -it -n monitoring sts/kube-prometheus-stack-grafana -- grafana cli --version
grafana version 11.5.1
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-grafana alb grafana.ksj7279.click myeks-sejkim-ingress-alb-1893285509.ap-northeast-2.elb.amazonaws.com 80 142m
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"
Grafana Web URL = https://grafana.ksj7279.click- 우측 상단 : admin 사용자의 개인 설정
- 기본 대시보드 확인
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Connections : 설정, 예) 데이터 소스 설정 등
- Administartor : 사용자, 조직, 플러그인 등 설정
- Connections → Your connections : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인
# 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 10.100.39.248 <none> 9090/TCP,8080/TCP 23h
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 192.168.2.6:9090,192.168.2.6:8080 23h- 해당 데이터 소스 접속 확인
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring
Server: 10.100.0.10
Address: 10.100.0.10#53
Name: kube-prometheus-stack-prometheus.monitoring.svc.cluster.local
Address: 10.100.39.248
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo
* Host kube-prometheus-stack-prometheus.monitoring:9090 was resolved.
* IPv6: (none)
* IPv4: 10.100.39.248
* Trying 10.100.39.248:9090...
* Connected to kube-prometheus-stack-prometheus.monitoring (10.100.39.248) port 9090
> GET /graph HTTP/1.1
> Host: kube-prometheus-stack-prometheus.monitoring:9090
> User-Agent: curl/8.7.1
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 302 Found
< Content-Type: text/html; charset=utf-8
< Location: /query?
< Date: Sat, 01 Mar 2025 15:50:26 GMT
< Content-Length: 30
<
<a href="/query?">Found</a>.
* Connection #0 to host kube-prometheus-stack-prometheus.monitoring left intact
# 삭제
kubectl delete pod netshoot-pod8.2 대시보드 사용
- 기본 대시보드와 공식 대시보드 가져오기
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster
- 공식 대시보드 가져오기 - 링크 추천
- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
- 아래 값 출력되게 수정해보자!
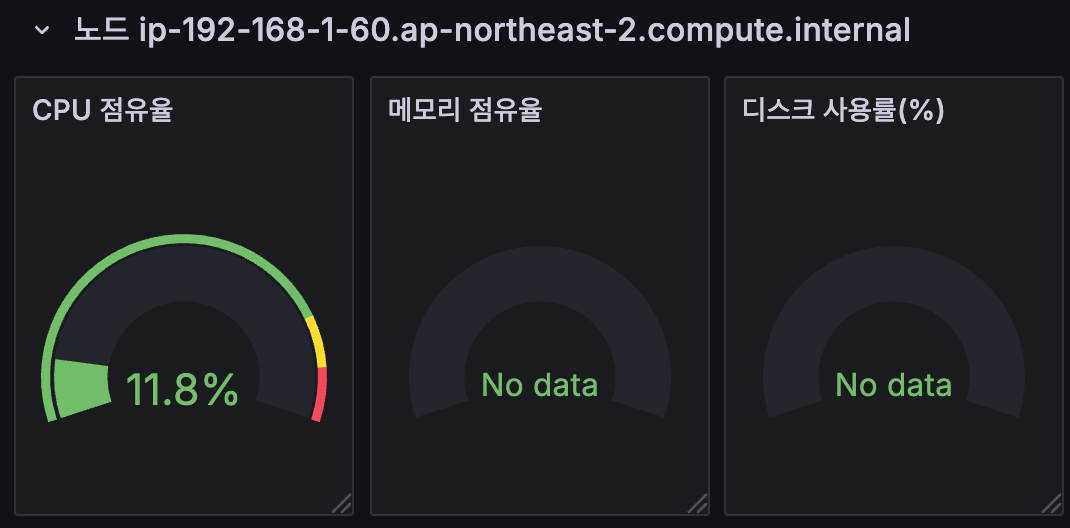
- 해당 패널에서 Edit → 아래 수정 쿼리 입력 후 Run queries 클릭 → 상단 Save 후 Apply
sum by (node) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m])) node_cpu_seconds_total
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (node)
avg(node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}) by (instance)
# 수정
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))# 수정 : 메모리 점유율
(node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"}
# 수정 : 디스크 사용률
sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (instance) / sum(node_filesystem_size_bytes{instance="$instance"}) by (instance)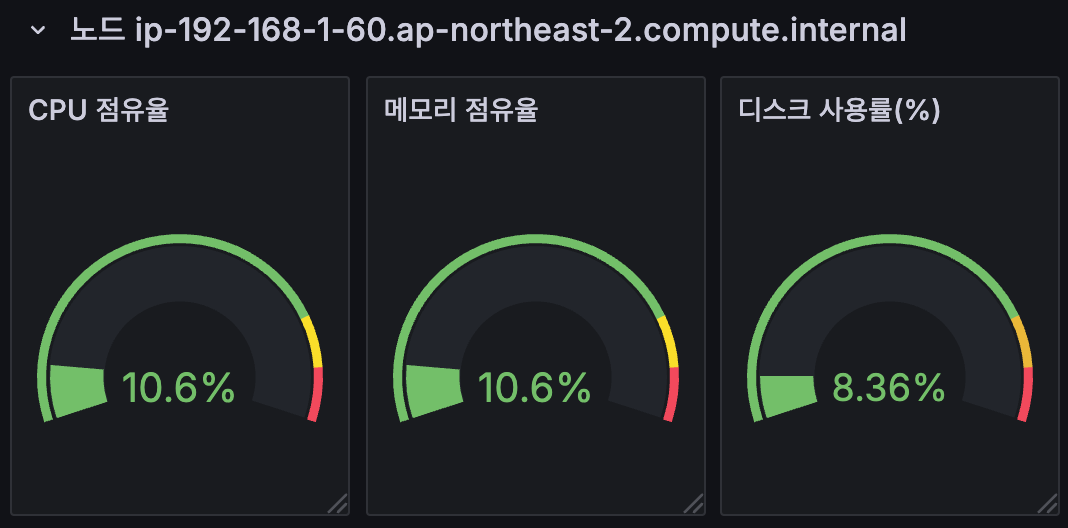
- 상단 네임스페이스와 파드 정보 필터링 출력되게 수정해보자!
- 오른쪽 상단 Edit → Settings → Variables 아래 namesapce, pod 값 수정 ⇒ 수정 후 Save dashboard 클릭
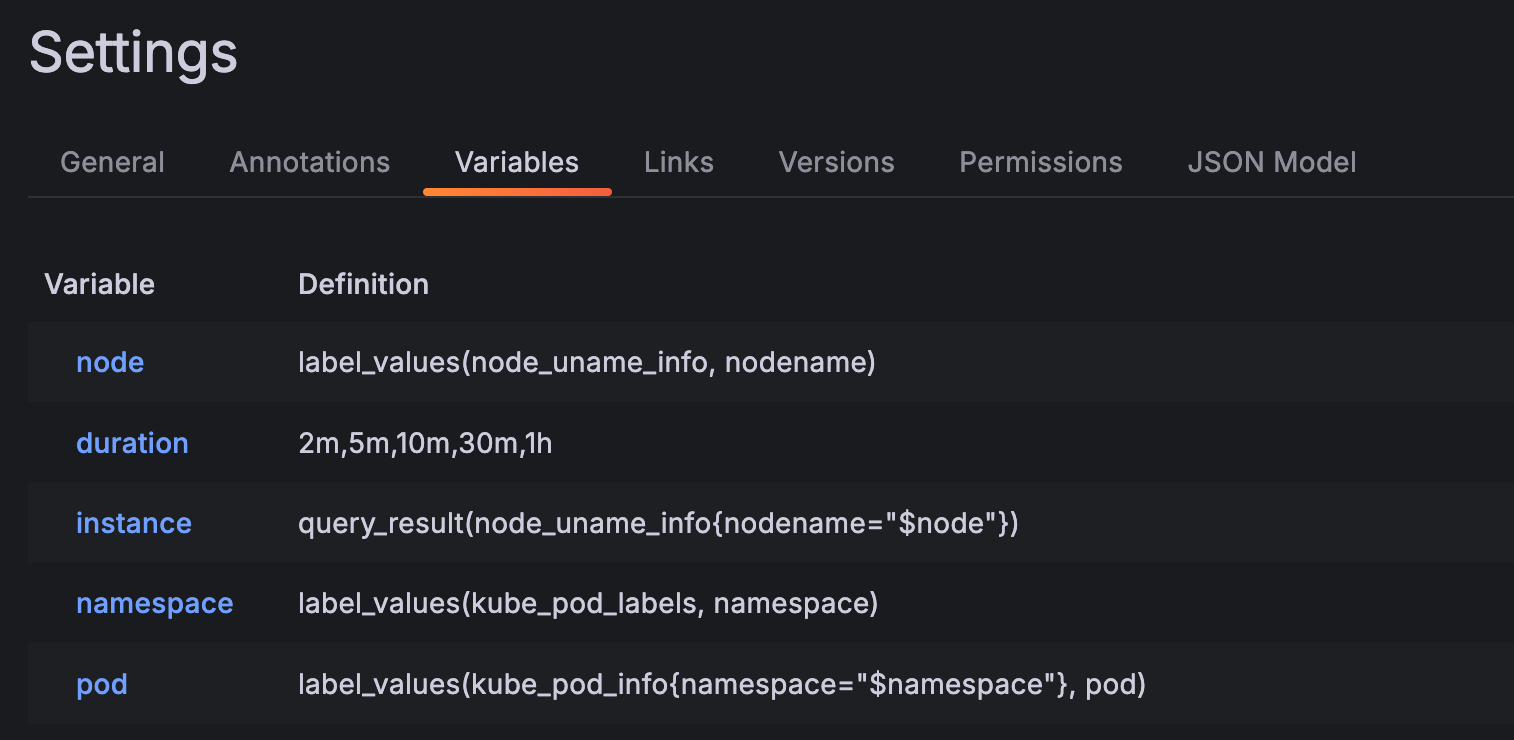
- namespace 경우 : kube_pod_info 로 수정
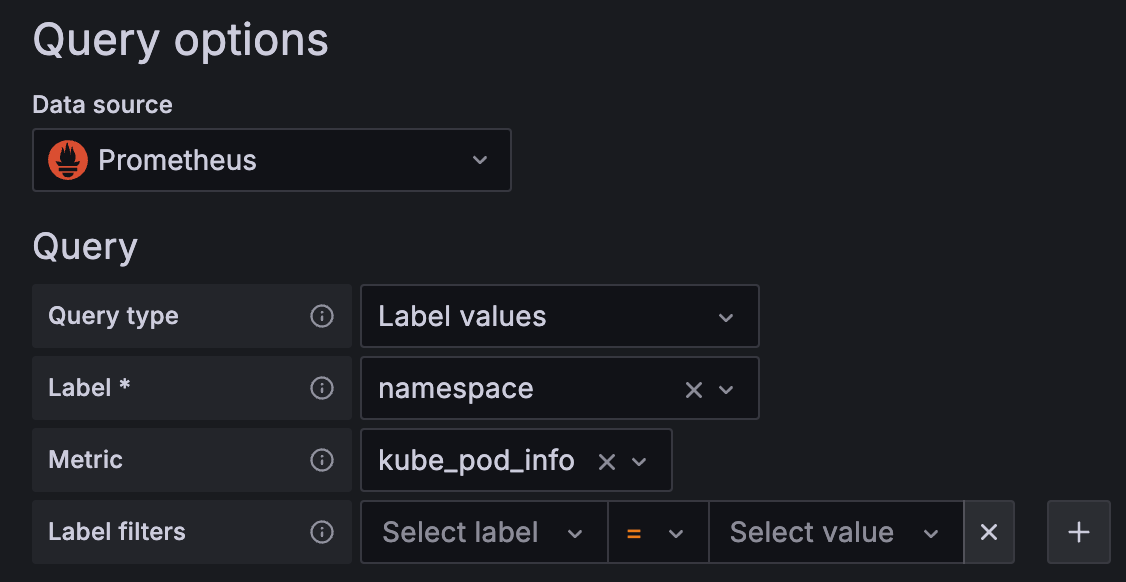
- namespace 오른쪽 Showing usages for 클릭 시 → 맨 하단에 pod variable 가 namespace 를 하위에 종속? 관계 확인
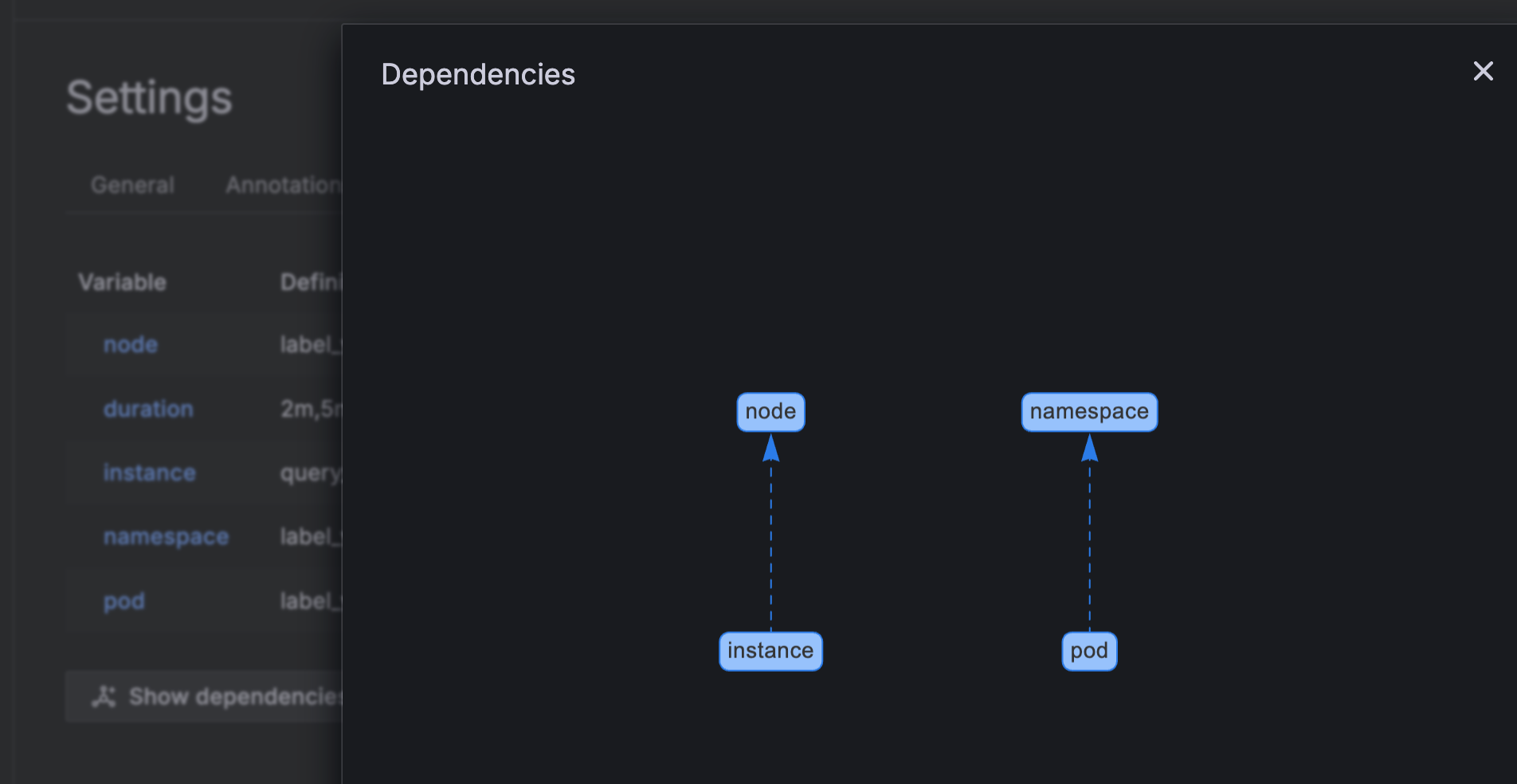
- 오른쪽 상단 Edit → Settings → Variables 아래 namesapce, pod 값 수정 ⇒ 수정 후 Save dashboard 클릭
- 파드의 리소스 할당 제한 제대로 표시 해보자!
- 리소스 할당 제한 패널 edit → Save dashboard
- CPU
- 리소스 할당 제한 패널 edit → Save dashboard
CPU
# 기존
sum(kube_pod_container_resource_limits_cpu_cores{pod="$pod"})
# 변경 전 쿼리 시도
kube_pod_container_resource_limits_cpu_cores
kube_pod_container_resource_limits
kube_pod_container_resource_limits{resource="cpu"}
# 변경
sum(kube_pod_container_resource_limits{resource="cpu", pod="$pod"})
- Memory
# 기존
sum(kube_pod_container_resource_limits_memory_bytes{pod="$pod"})
# 변경
sum(kube_pod_container_resource_limits{resource="memory", pod="$pod"})-
default 네임스페이스에 nginx 파드 정보 확인 : 쿼리 수정 후 바로 적용 안되니, 파드를 선택 후 재선택 하자..
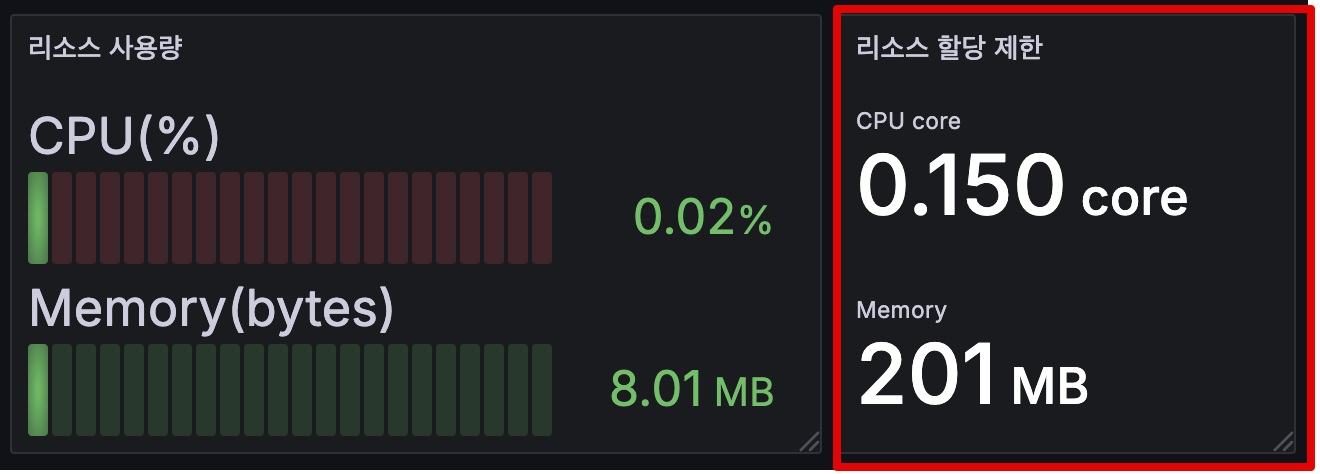
-
[Node Exporter Full] Dashboard → New → Import → 1860 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
-
[**Node Exporter for Prometheus Dashboard based on 11074] 15172**
-
kube-state-metrics-v2 가져와보자 : Dashboard ID copied! (13332) 클릭 - 링크
- [kube-state-metrics-v2] Dashboard → New → Import → 13332 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭
-
[Amazon EKS] AWS CNI Metrics 16032 - 링크
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system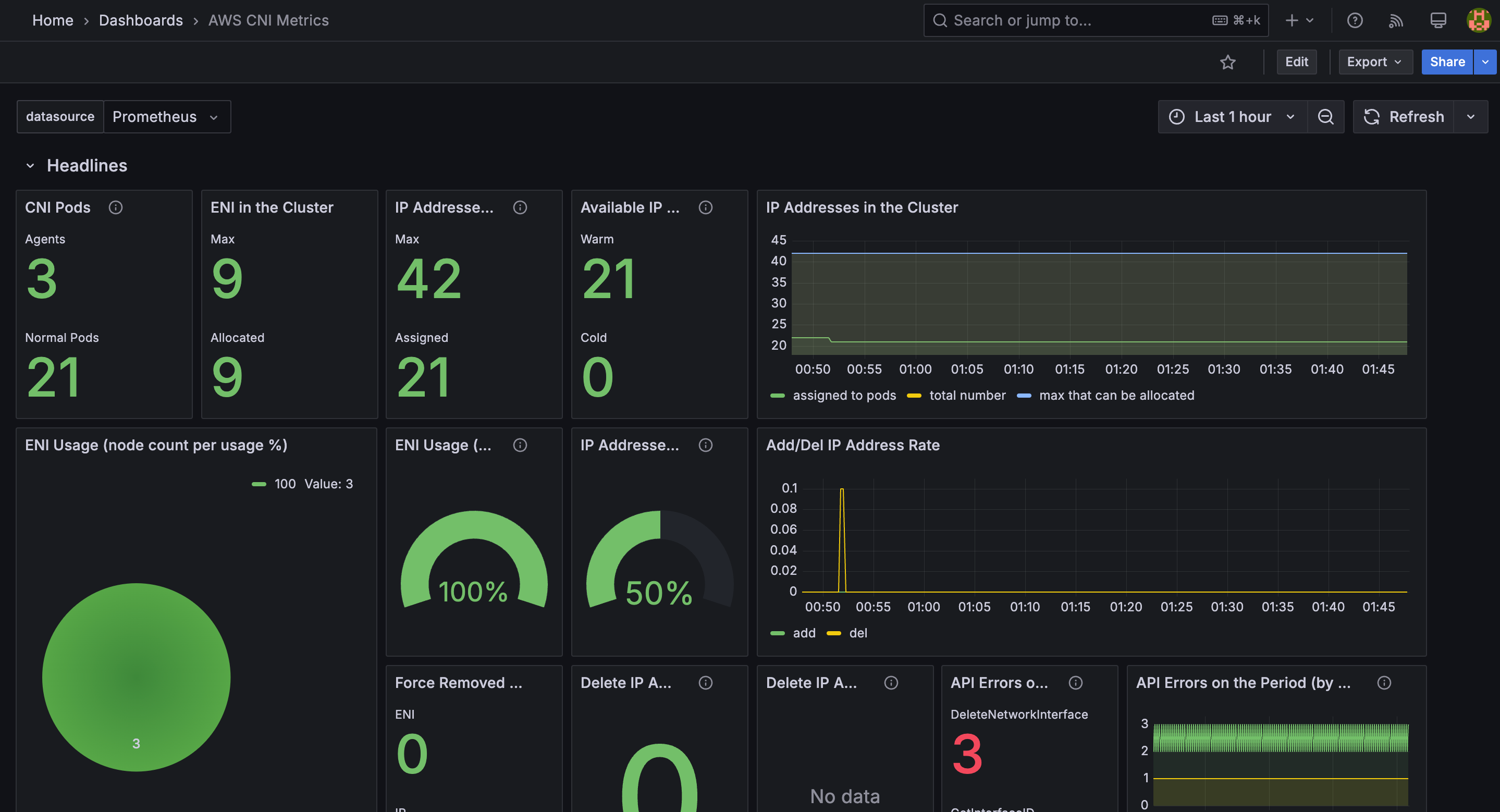
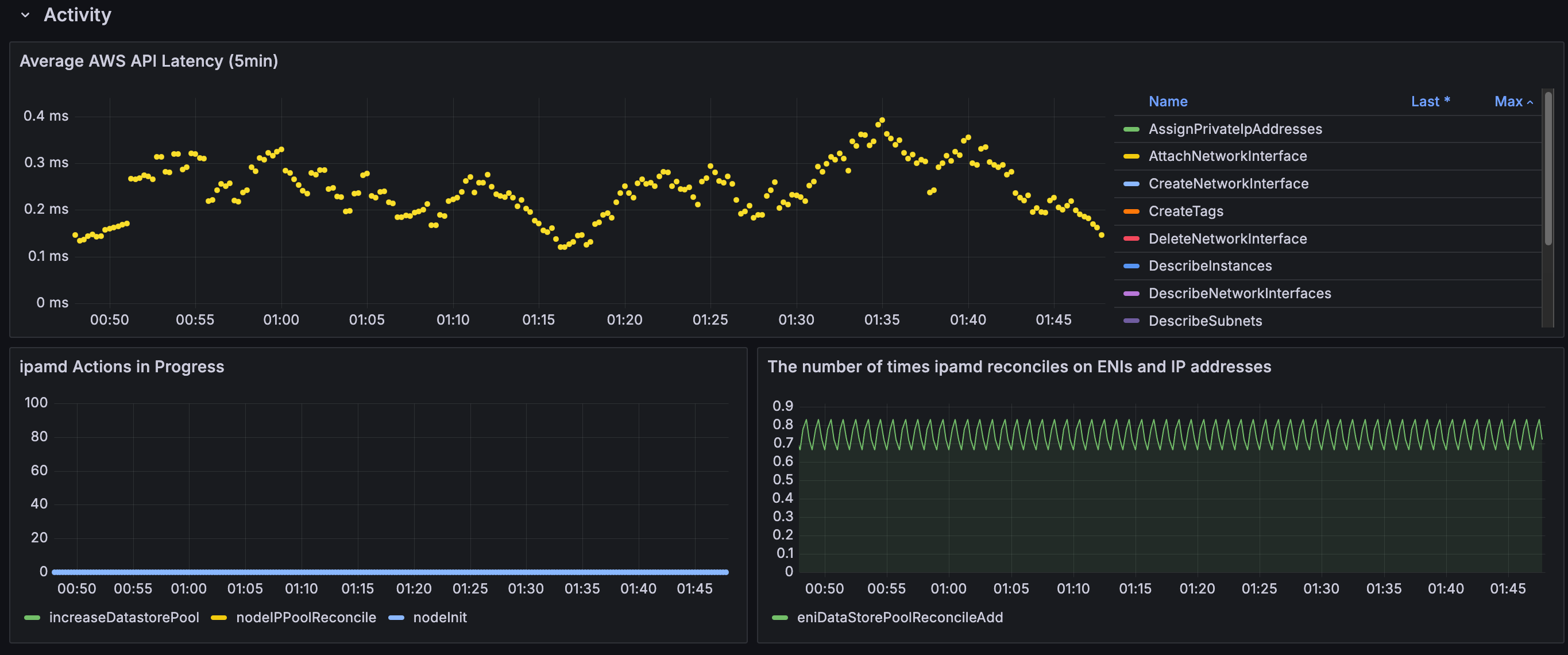
8.3 NGINX 애플리케이션 모니터링 대시보드 추가
- 그라파나에 12708 대시보드 추가 - Link
# scale out
kubectl scale deployment nginx --replicas 9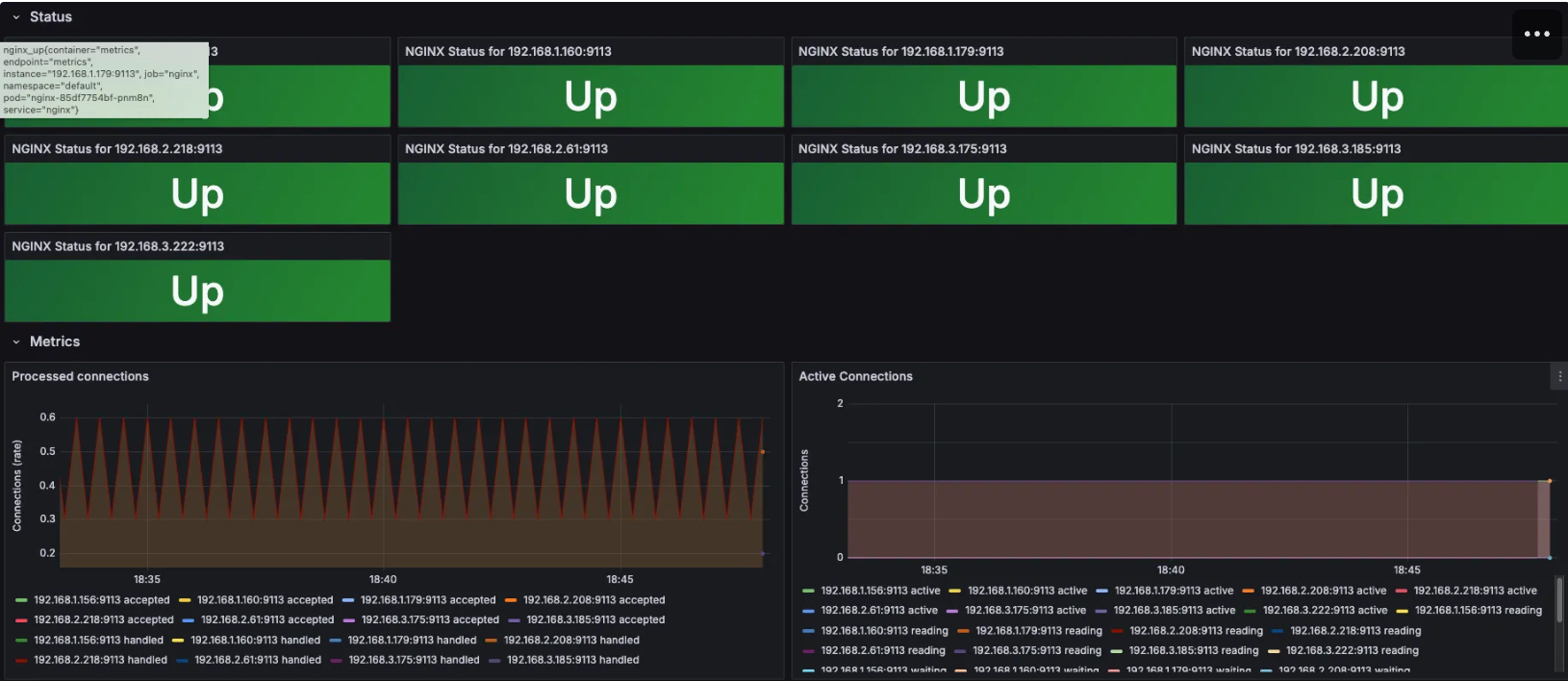
8.4 [중급] Panel 패널 - Link
https://grafana.com/docs/grafana/latest/panels-visualizations/visualizations/
-
Graphs & charts
- Time series is the default and main Graph visualization.
- State timeline for state changes over time.
- Status history for periodic state over time.
- Bar chart shows any categorical data.
- Histogram calculates and shows value distribution in a bar chart.
- Heatmap visualizes data in two dimensions, used typically for the magnitude of a phenomenon.
- Pie chart is typically used where proportionality is important.
- Candlestick is typically for financial data where the focus is price/data movement.
- Gauge is the traditional rounded visual showing how far a single metric is from a threshold.
-
Stats & numbers
-
Misc
- Table is the main and only table visualization.
- Logs is the main visualization for logs.
- Node graph for directed graphs or networks.
- Traces is the main visualization for traces.
- Flame graph is the main visualization for profiling.
- Canvas allows you to explicitly place elements within static and dynamic layouts.
- Geomap helps you visualize geospatial data.
-
Widgets
- Dashboard list can list dashboards.
- Alert list can list alerts.
- Text can show markdown and html.
- News can show RSS feeds.
-
실습 준비 : 신규 대시보스 생성 → 패널 생성(Code 로 변경) → 쿼리 입력 후 Run queries 클릭 후 오른쪽 상단 Apply 클릭 → 대시보드 상단 저장
-
Time series : 아래 쿼리 입력 후 오른쪽 입력 → Title(노드별 5분간 CPU 사용 변화율)
node_cpu_seconds_total **rate**(node_cpu_seconds_total[**5m**]) **sum**(rate(node_cpu_seconds_total[5m])) sum(rate(node_cpu_seconds_total[5m])) **by (instance)**- 상단 : 최근 30분, 5초 간격 Auto 쿼리
-
Bar chart : Add → Visualization 오른쪽(Bar chart) ⇒ 쿼리 Options : Legend(Auto), Format(Table), Type(Instance) → Title(네임스페이스 별 디플로이먼트 갯수)
kube_deployment_status_replicas_available **count**(kube_deployment_status_replicas_available) **by (namespace)** -
Stat : Add → Visualization 오른쪽(Stat) → Title(nginx 파드 수)
kube_deployment_spec_replicas kube_deployment_spec_replicas{deployment="nginx"} # scale out kubectl scale deployment nginx --replicas 6 -
Gauge : Add → Visualization 오른쪽(Gauge) → Title(노드 별 1분간 CPU 사용률)
**node_cpu_seconds_total** node_cpu_seconds_total{mode="idle"} node_cpu_seconds_total{mode="idle"}[1m] rate(node_cpu_seconds_total{mode="idle"}[1m]) avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) **by (instance)** **1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))** -
Table : Add → Visualization 오른쪽(Table) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(노드 OS 정보)
node_os_info- Transform data → Organize fields by name : id_like, instance, name, pretty_name
-
원하는 위치로 배치
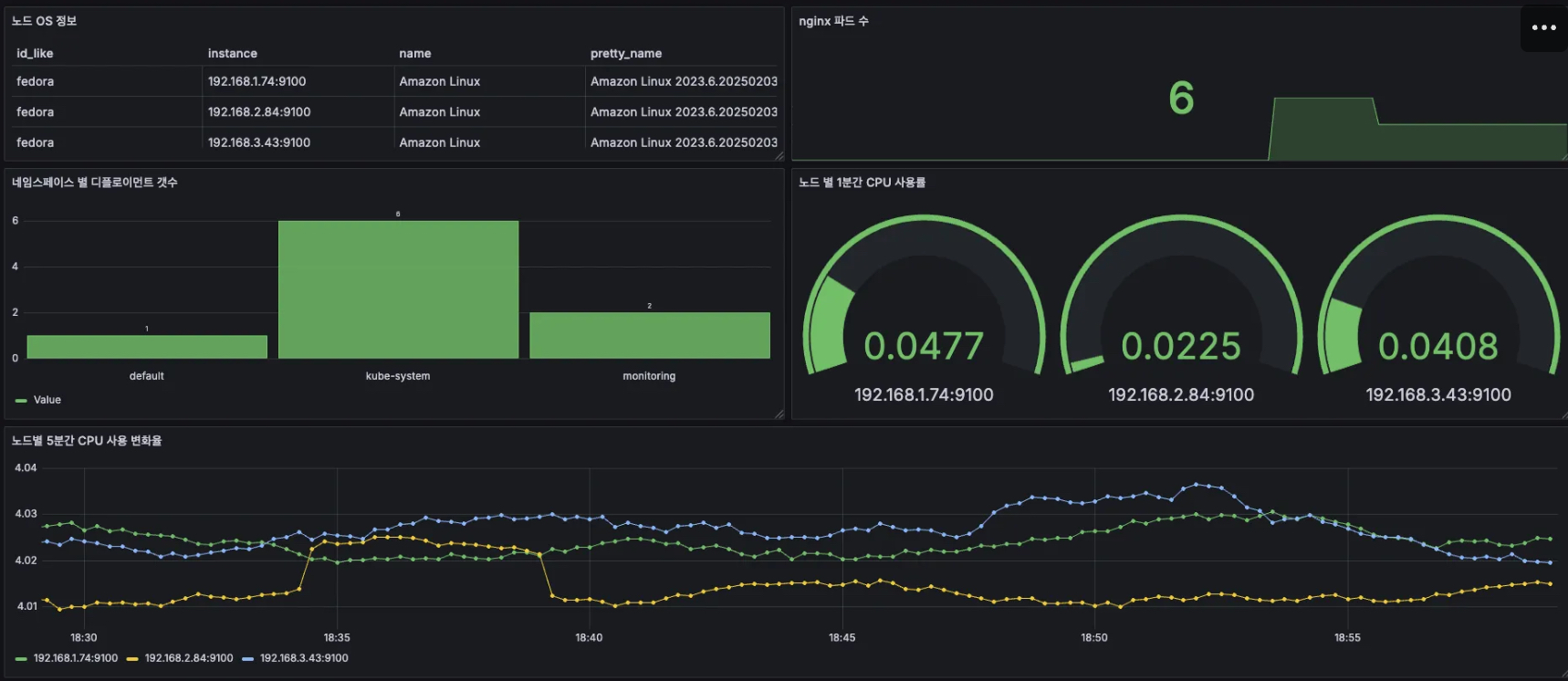
9. Grafana Alert
그라파나 9.4 버전이 2월 28일 출시 - 링크 ⇒ Alerting 기능이 강화되었고, 이미지 알람 기능도 제공 - 링크
그라파나 9.5 버전이 Alerting 기능 업데이트 - 링크
- 그라파나 얼럿 Docs - 링크, Workshop
https://grafana.com/docs/grafana/latest/alerting/
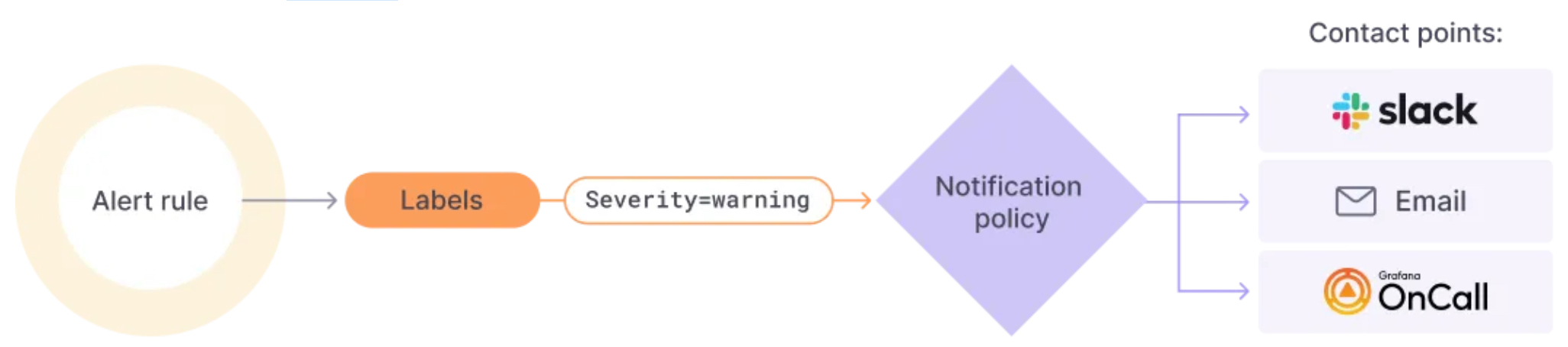
-
Contact points → Add contact point 클릭
- Integration : 슬랙
- Webhook URL : 아래 주소 입력```bash **https://hooks.slack.com/services/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** ``` - Optional Slack settings → Username : 메시지 구분을 위해서 각자 자신의 닉네임 입력 - 오른쪽 상단 : Test 해보고 저장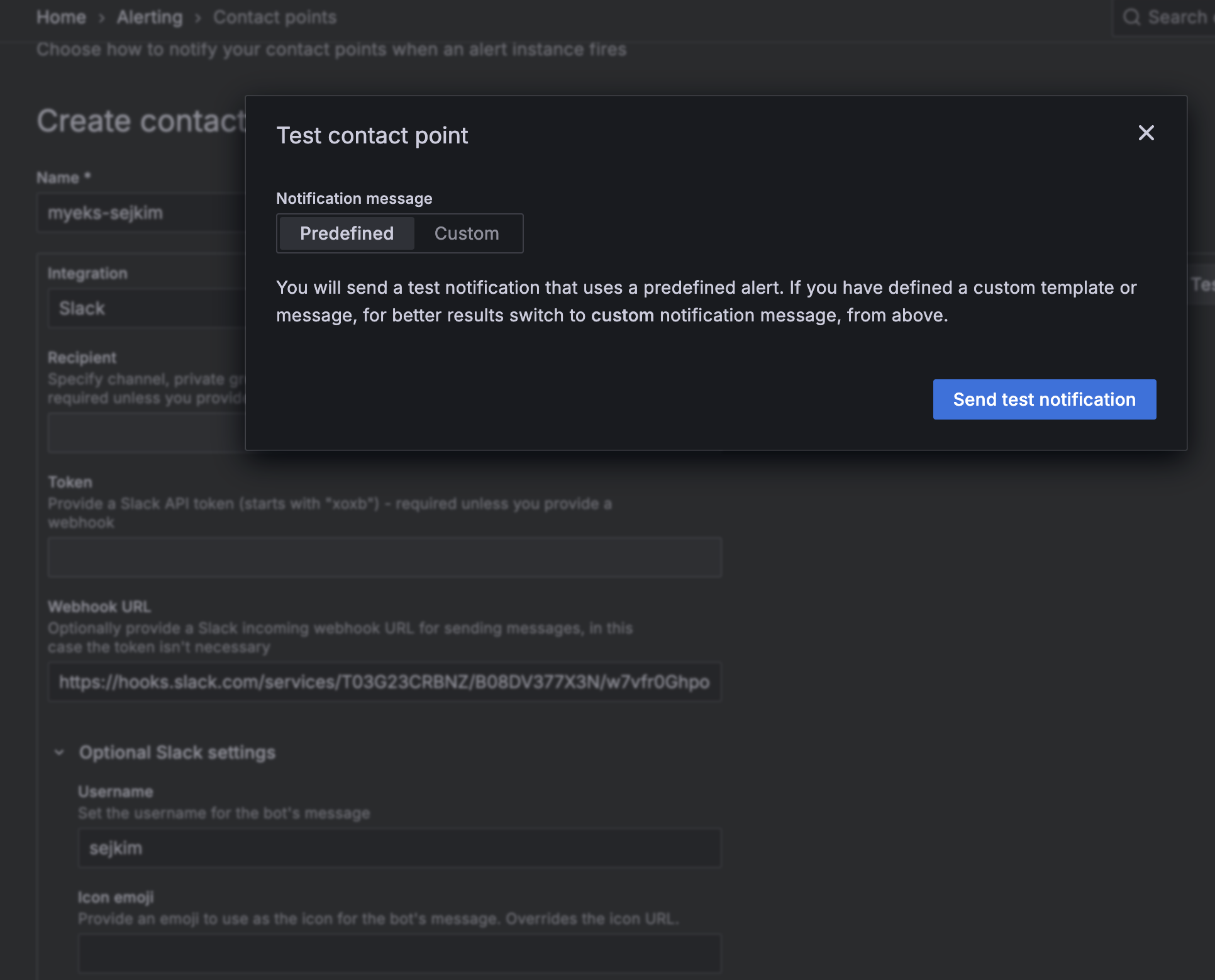
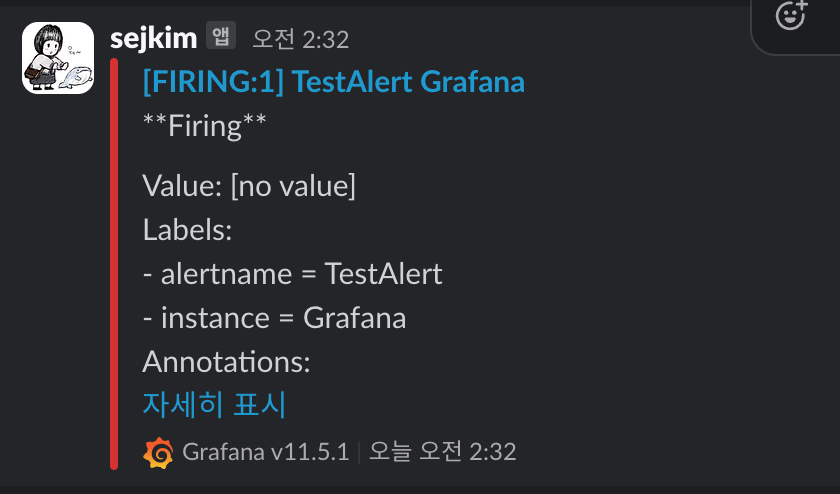
-
Notification policies : 기본 정책 수정 Edit - Default contact point(slack)
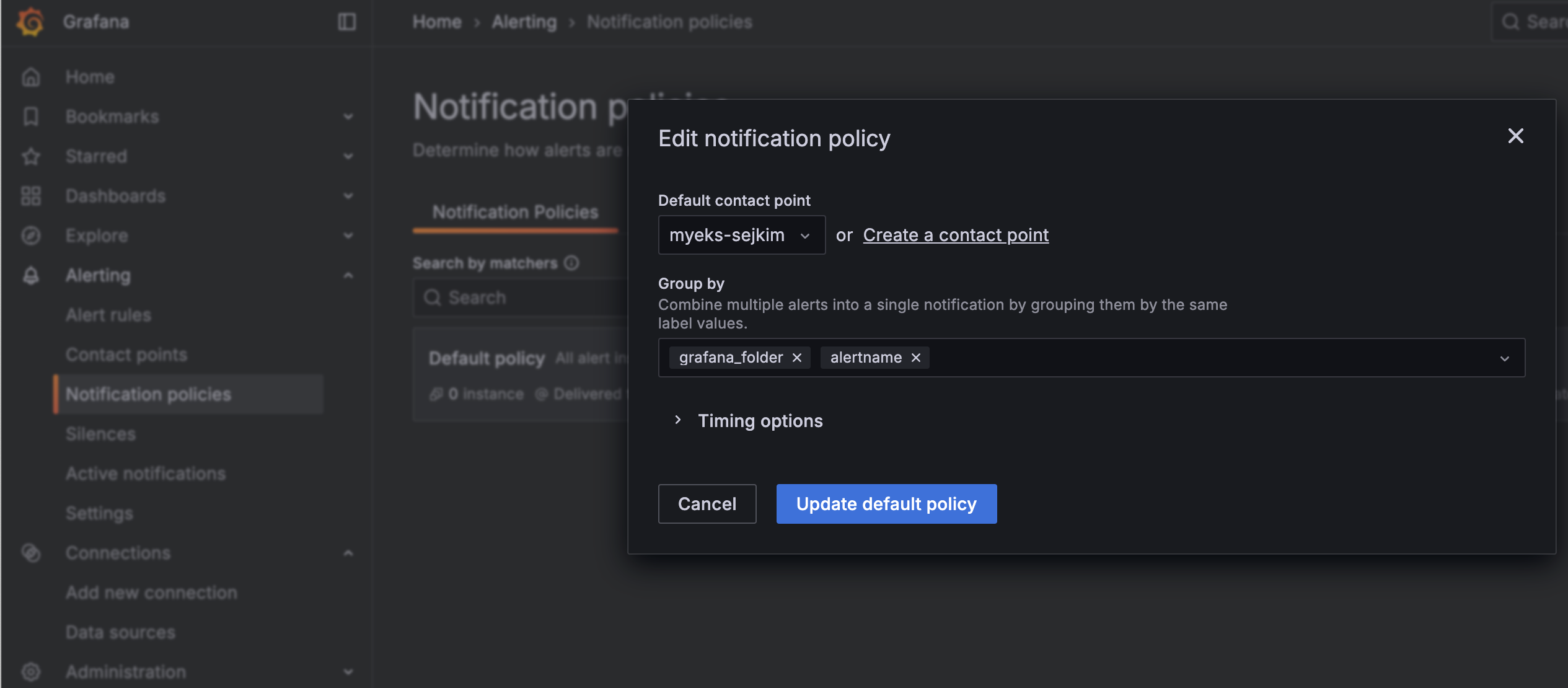
-
그라파나 → Alerting → Alert ruels → Create alert rule : Name(nginx alert) - nginx 웹 요청 1분 동안 누적 60 이상 시 Alert 설정
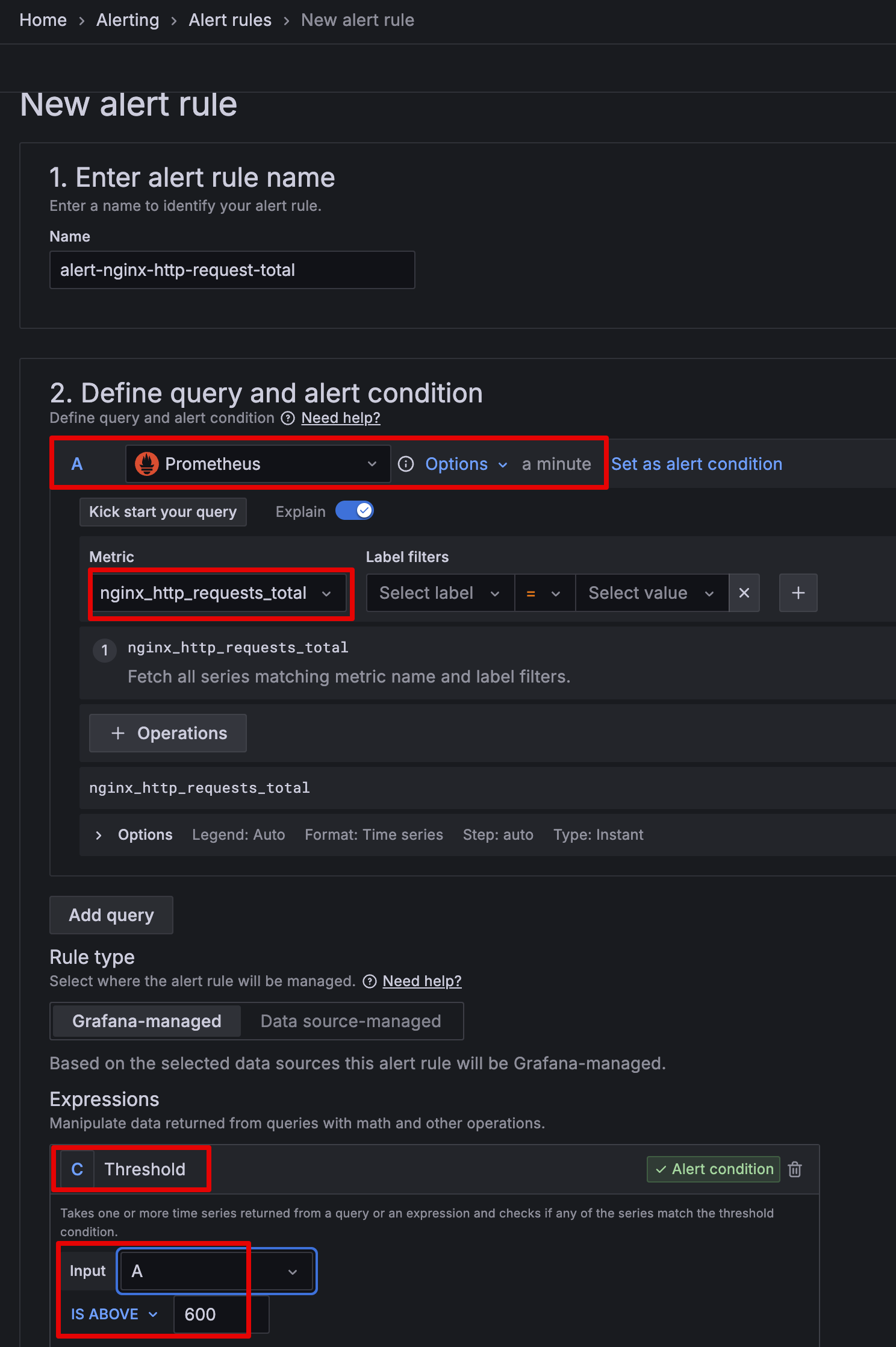
- 아래 Folder 과 Evaluation group(1m), Pending period(1m) 은 +Add new 클릭 후 신규로 만들어 주자
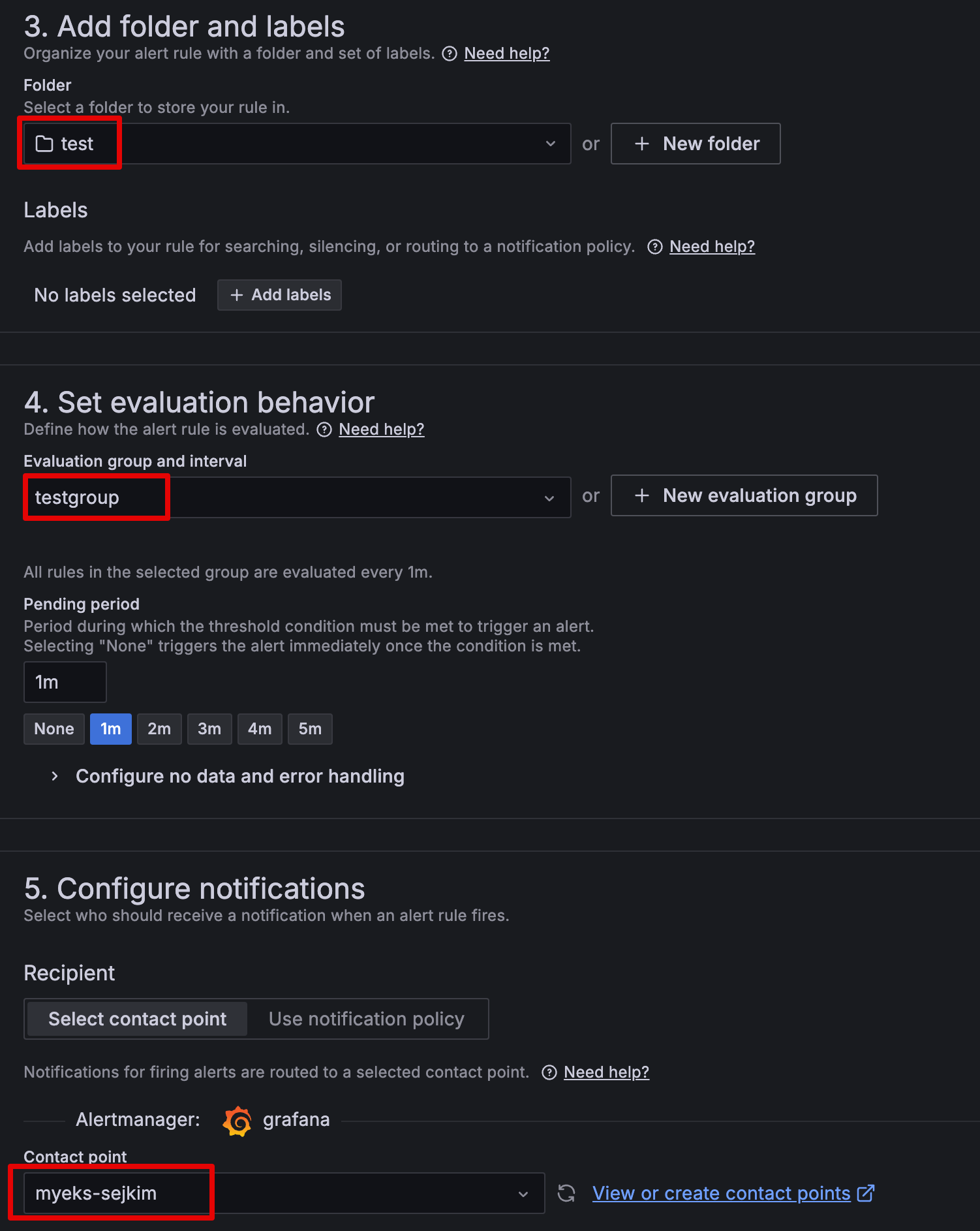
- Configure notifications : Contack point(slack)
⇒ 오른쪽 상단Save and exit클릭
- nginx 반복 접속 실행 후 슬랙 채널 알람 확인
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done- Grafana에서 Alert 발생
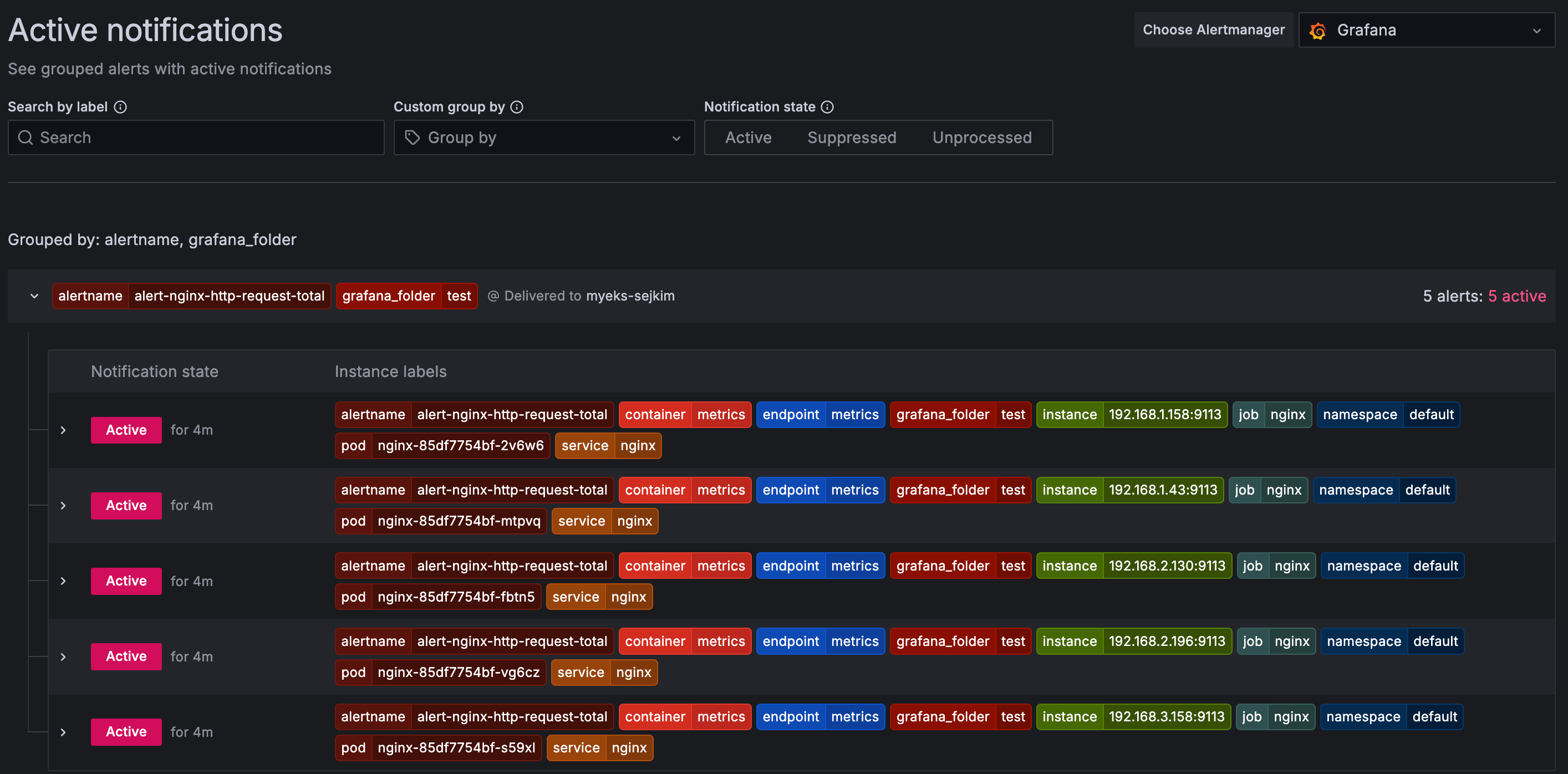
- slack에서 Noti 옴
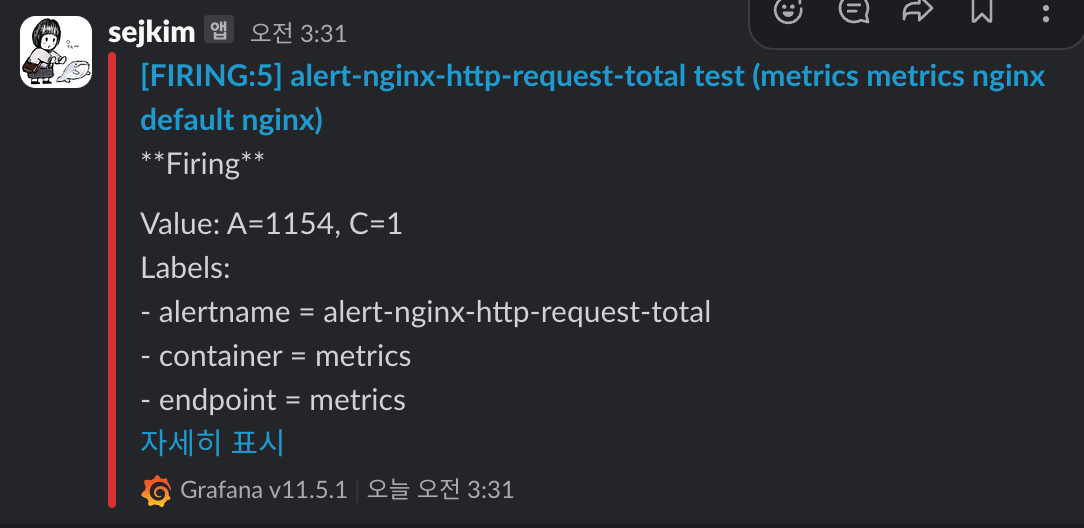
10. 자원 삭제
삭제 : [운영서버 EC2]에서 원클릭 삭제 진행
# eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME
**nohup sh -c "eksctl delete cluster --name $CLUSTER_NAME && aws cloudformation delete-stack --stack-name $CLUSTER_NAME" > /root/delete.log 2>&1 &**
# (옵션) 삭제 과정 확인
**tail -f delete.log**- *AWS EC2 → 볼륨 : 남아 있는 볼륨(프로메테우스, 그라파나용 PVC/PV로 생성된) 삭제하자! ⇒ 다음 기수부터는 추후 실습 편리를 위해서 삭제 정책으로 변경 해둘것!*
(옵션) 로깅 삭제 : 위에서 삭제 안 했을 경우 삭제
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
# 로그 그룹 삭제 : 컨트롤 플레인
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
---
# 로그 그룹 삭제 : 데이터 플레인
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/application
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/dataplane
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/host
aws logs delete-log-group --log-group-name /aws/containerinsights/$CLUSTER_NAME/performance💎💎💎💎💎 긴글 읽어 주셔서 감사합니다 💎💎💎💎💎
