3강 - 분할정복 알고리즘
분할 정복 방법의 원리
분할 정복 방법은, 순환적으로 (Recursive) 문제를 푸는 하향식 접근 방법
-
주어진 문제의 입력을 더 이상 나눌 수 없을 때까지 두 개 이상의 작은 문제로 순환적으로 분할한다.
-
1번 방법으로 분할한 작은 문제들을 각각 해결한 후, 이 해들을 결합하여 원래 문제에 해를 구하는 방법
분할 정복 방법의 특징
-
분할된 작은 문제들은 원래 문제와 동일하나, 입력 크기만 다르다.
-
분할된 작은 문제들은 서로 독립적이다.
분할 정복 방법 처리 단계
분할 : 주어진 문제들을 여러개의 작은 문제로 분할한다.
정복 : 작은 문제를 순서대로 분할하고, 작은 문제가 더 분할되지 않을 정도로 크기가 충분히 작다면 순환호출 없이 작은 문제의 해를 구한다.
결합 : 작은 문제에 대해 정복된 해를 결합하여, 원래 문제의 해를 구한다.
분할 정복 적용 알고리즘의 종류 및 분할 과정
- 이진 탐색
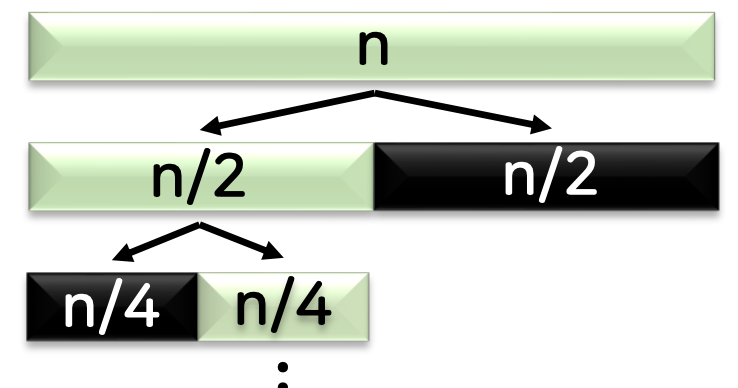
처리하고자 하는 데이터 n개를 n/2 n/2씩 쪼갠 후, 절반은 처리 대상에서 제외한다.
- 합병 정렬
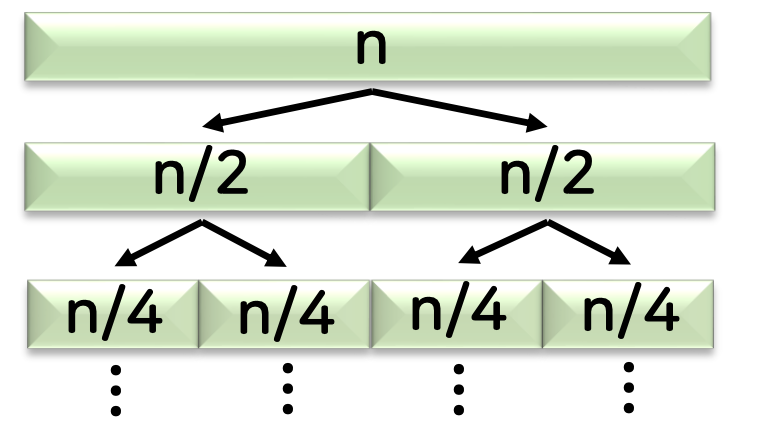
절반으로 쪼갠 후, 양쪽 piece를 모두 확인하고, 이를 다시 한 번 나누고 또 나눈다
- 퀵 정렬
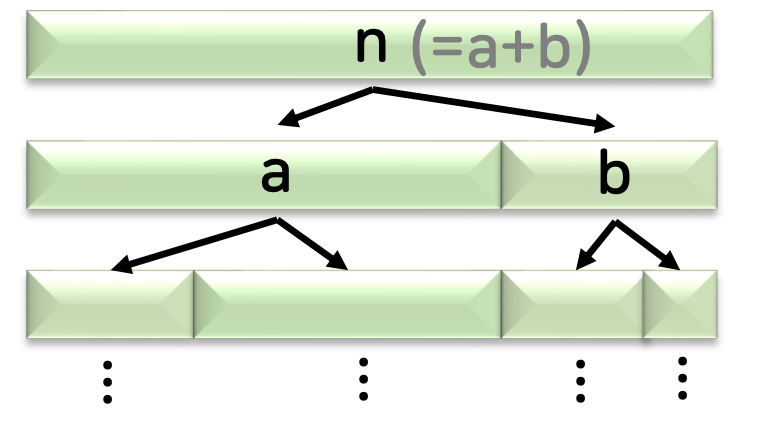
한 문제를 위와 같이 두 개로 나누되, 크기가 일정하지 않은 2개로 쪼갠 후 다시 한 번 일정하지 않은 크기로 쪼갠다.
- 선택 문제
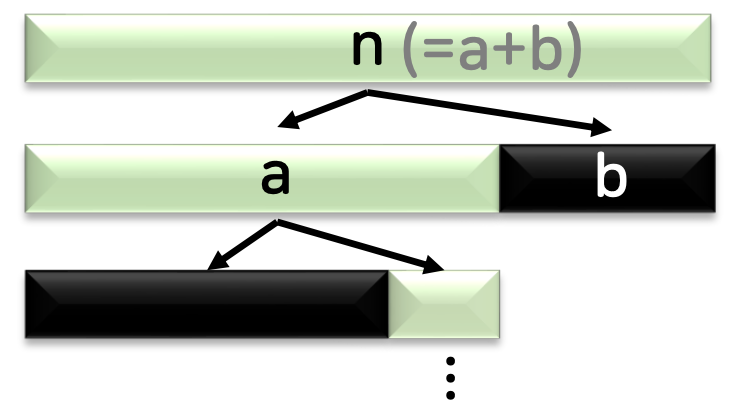
크기가 일정하지 않은 작은 문제들로 나눈 후, 버릴 것을 선택하여 버린다.
분할 정복 응용 - 이진 탐색
입력된 상태가 정렬이 되어있는 상태(오름차순이든, 내림차순이든)일 때 효과적인 탐색 방법이다.
탐색 방법
- 배열의 가운데 A[mid]와 탐색 키 X를 비교한다.
탐색 키 = 가운데 원소일 경우에는 탐색을 성공한 것이고, mid를 반환 후 종료한다.

이진 탐색은 탐색을 반복할 때마다 대상 원소의 개수가 반으로 감소한다는 특징을 기억해야 한다.
분할 : 배열의 가운데 원소를 기준으로 왼쪽, 오른쪽 부분 배열로 분할, 탐색키와 가운데가 같으면 가운데 원소의 배열 인덱스를 반환 후 종료
정복 : 탐색키가 가운데 원소보다 작으면 왼쪽 부분배열을 대상으로 이진 탐색을 순환 호출, 크면 오른쪽 부분배열을 대상으로 이진 탐색을 순환 호출
결합 : 필요가 없다 (부분 배열에 대해 탐색 결과를 직접적으로 반환하게 된다.)

<순환 형태의 알고리즘, 반복 형태보다는 비효율적이나 코드를 이해하기는 쉬울 것이다.>

<반복 형태의 알고리즘 코드, 효율이 좋다.>
이진 탐색에서 분할 및 비교 횟수
- 입력 크기 n일 때 최대 분할 횟수? 최대 비교 횟수?
최대 분할 횟수
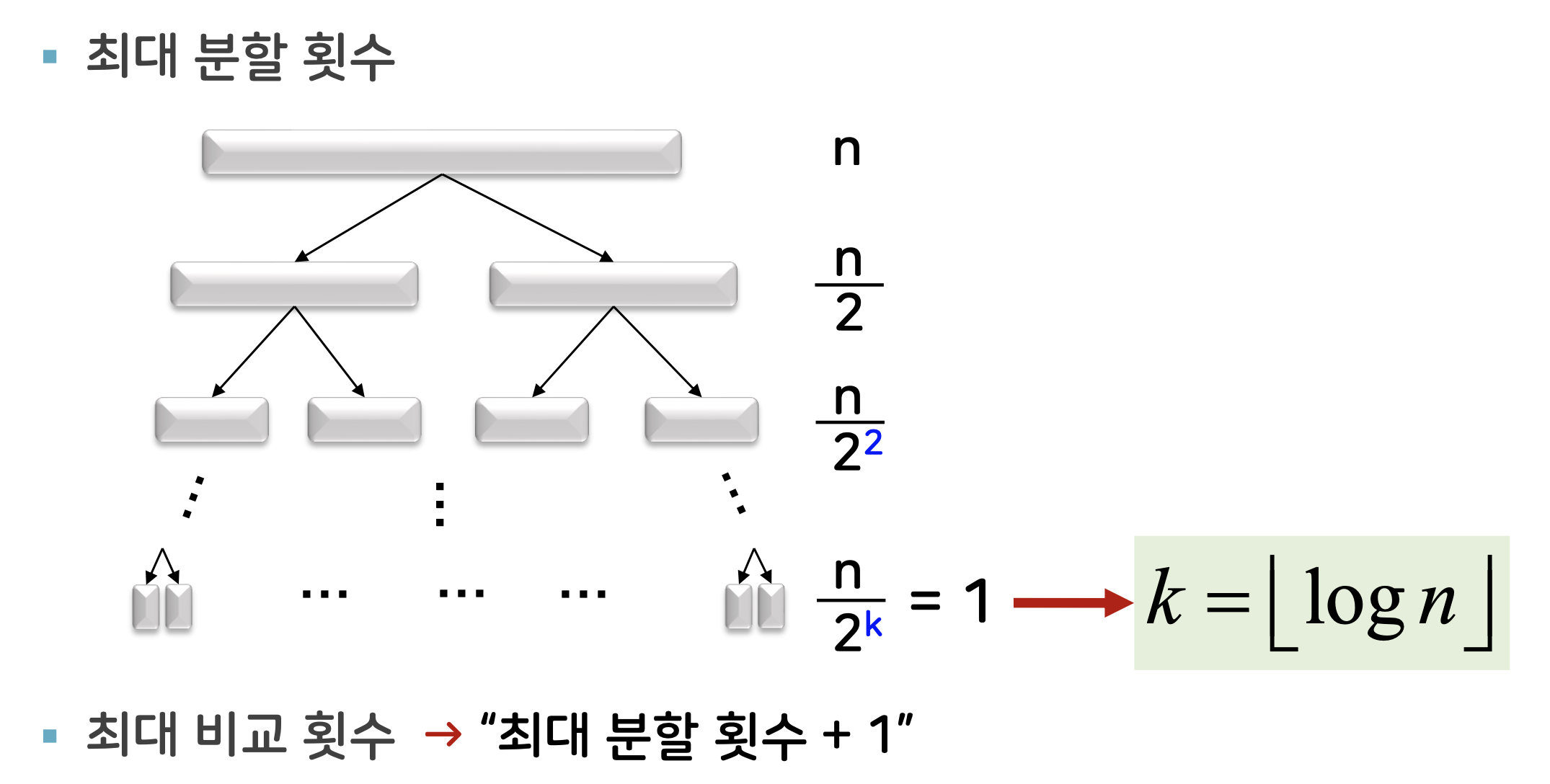
성능 분석

이진 탐색의 특징
-
입력 배열의 데이터가 정렬된 경우에 대해서만 적용이 가능하다
-
삽입 / 삭제 연산은 부가적인 데이터 이동을 수반한다.
데이터 정렬 상태 유지를 위해 평균적으로 n/2개의 데이터 이동이 발생하는데, 이에 따라 삽입/삭제가 빈번한 응용에서는 사용하기 부적합하다.
분할 정복 응용 - 퀵 정렬
특정 원소를 기준으로 주어진 배열을 두 부분배열로 분할하고, 각 부분배열에 대해서 퀵 정렬을 순환적으로 적용하는 방식
- 오름차순으로 정렬한다고 가정한다.
피봇 (Pivot)
주어진 배열을 두 부분배열로 분할할 때 기준이 되는 특정 원소
✓ 보통 주어진 배열의 첫 번째 원소로 지정한다. / A[0]
퀵 정렬의 개념과 원리
- 피벗이 제자리를 잡도록 하여 정렬하는 방식이다.
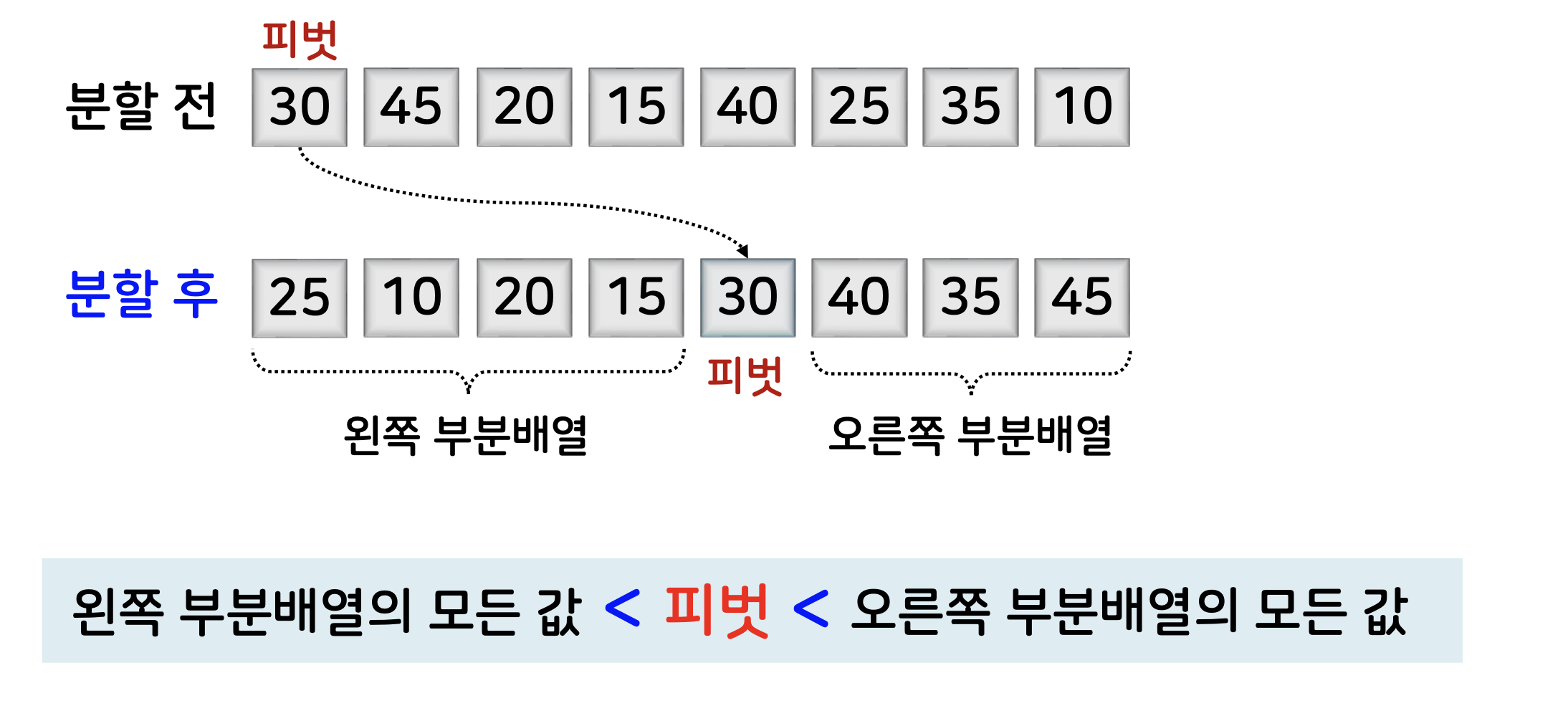
왼쪽 부분배열에 있는 모든 값 < 피벗 < 오른쪽 부분배열을 계속 반복한다.
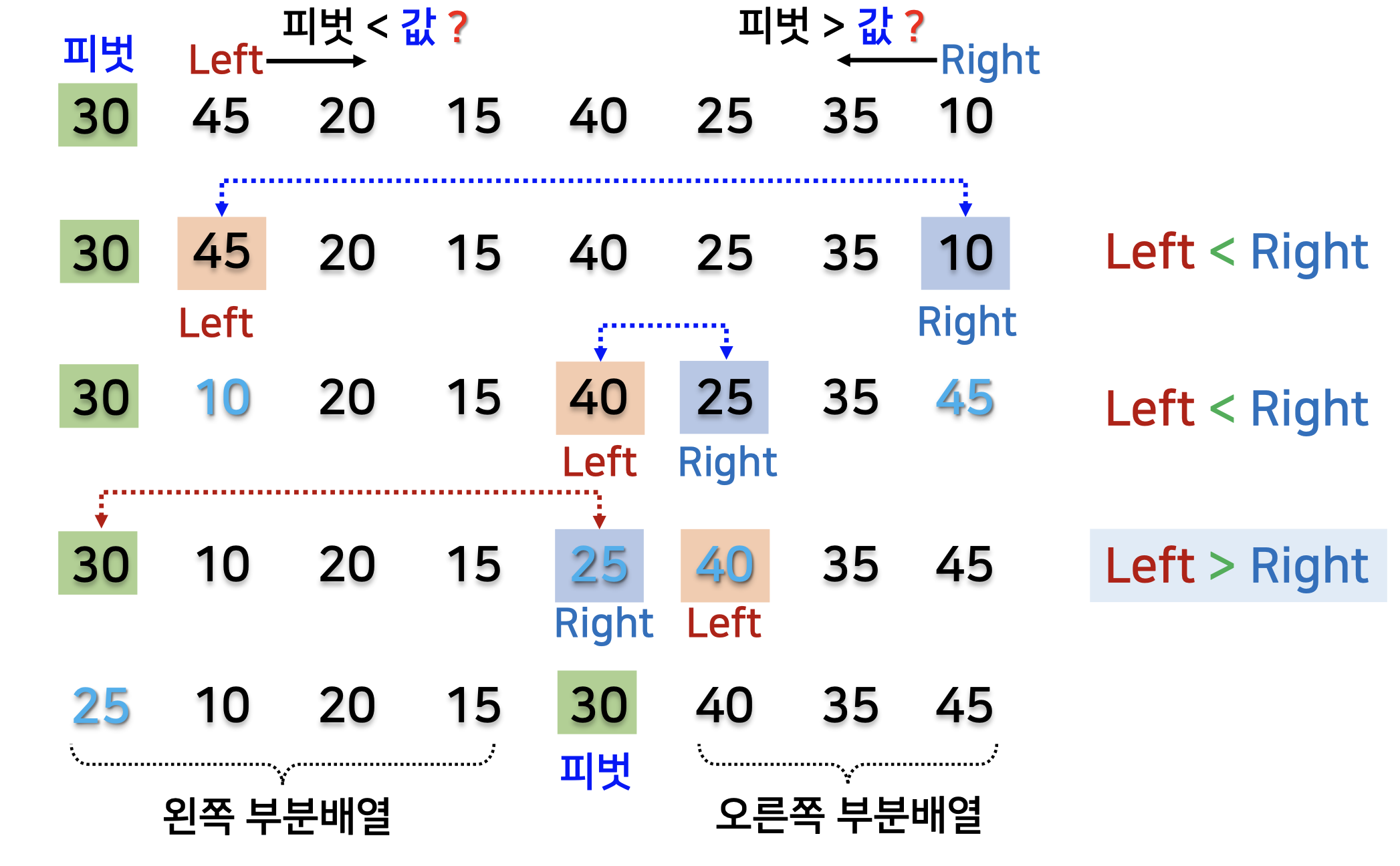
퀵 정렬의 분할, 정복, 결합
분할 : 피벗을 기준으로 주어진 배열을 두 부분배열로 분할한다.
정렬 : 두 부분배열에 대해서 퀵 정렬을 순환적으로 적용하여 각 부분배열을 적용한다.
결합 : 필요 없다.
예시
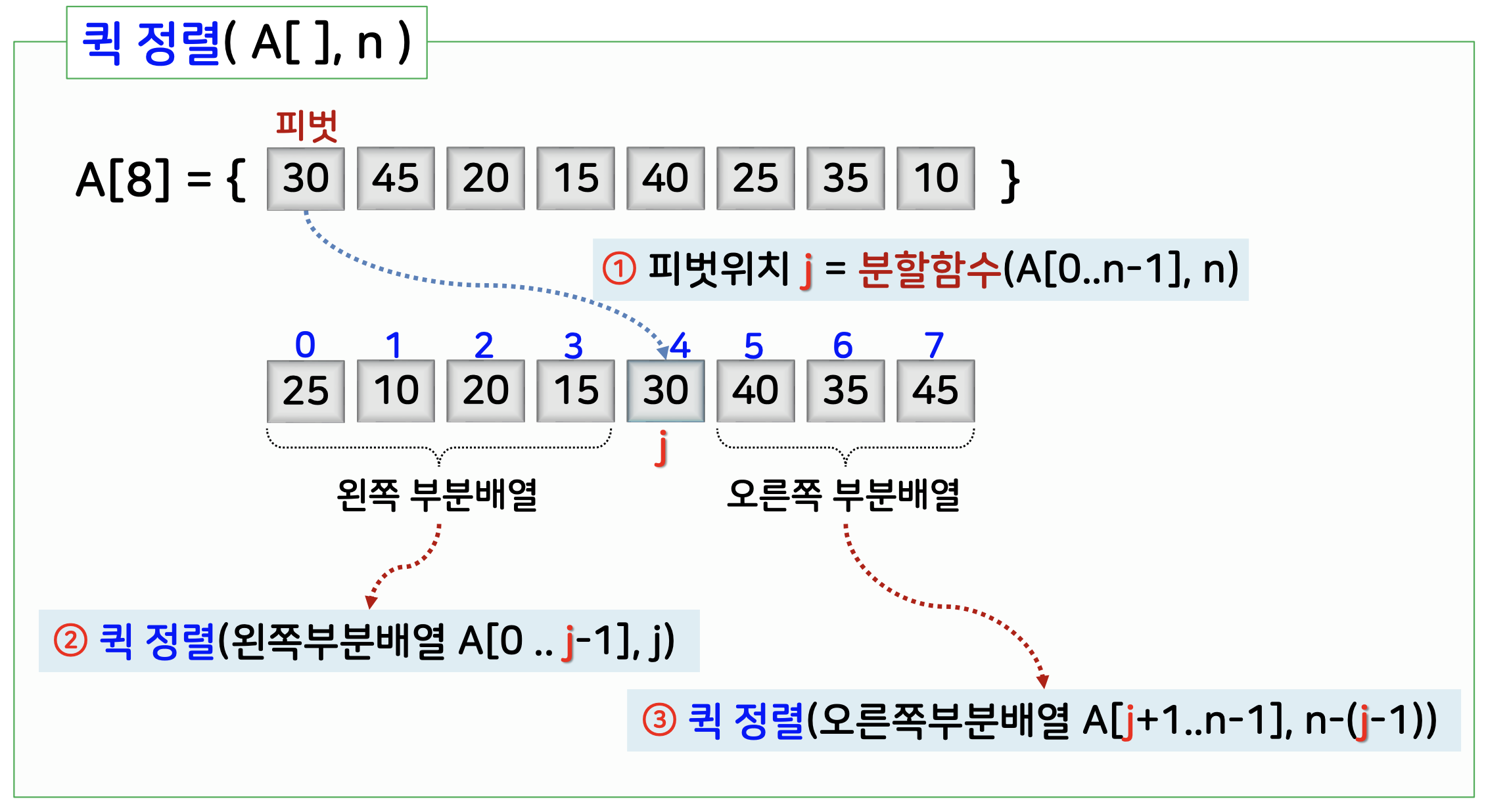

pivot = partition // partition 함수는 2개의 부분배열로 분할해주는 함수이다.왼쪽 부분배열을 순환 호출해주는 Quicksort
오른쪽 부분배열을 순환 호출해주는 Quicksort
전체적인 수행 과정
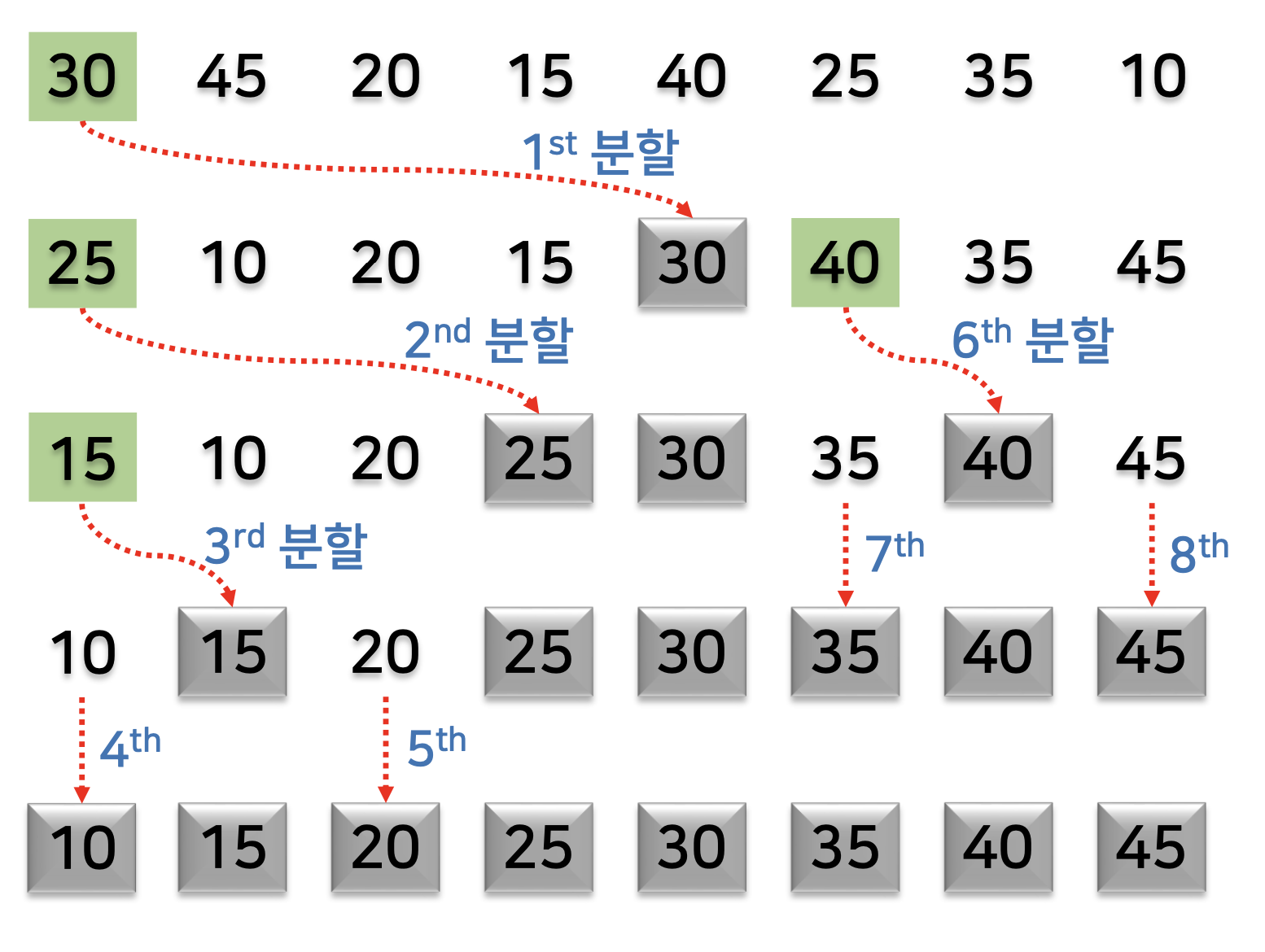
왼쪽과 오른쪽으로 나눈 후, 피벗이 제자리를 잡고 왼쪽 퀵정렬, 오른쪽 퀵정렬을 반복하는 것이다!
Partition(분할 함수)
그러기 위해, partition 함수를 이해해야 한다.

이를 이해하는 것이 퀵 정렬에서 가장 중요하다.
분할함수는 어떻게 동작할까? 를 이해해야 한다.
A라는 배열에서, A[0]을 피벗으로 했을 때 1번째 인덱스를 Left(왼쪽 부분배열), n - 1값을 right(오른쪽 부분배열)로 나눈다.
left는 오른쪽으로 이동하면서, pivot보다 큰 값을 찾는다. (값이 pivot보다 작으면 계속 이동한다.)
right는 왼쪽으로 이동하면서, pivot보다 작은 값을 찾는다. (값이 pivot보다 크면 계속 이동한다.)
필요하다면 원소를 계속 교환하면서, pivot과 오른쪽이 가리키는 원소를 서로 교환 및 반환한다.
분할 함수의 수행 과정
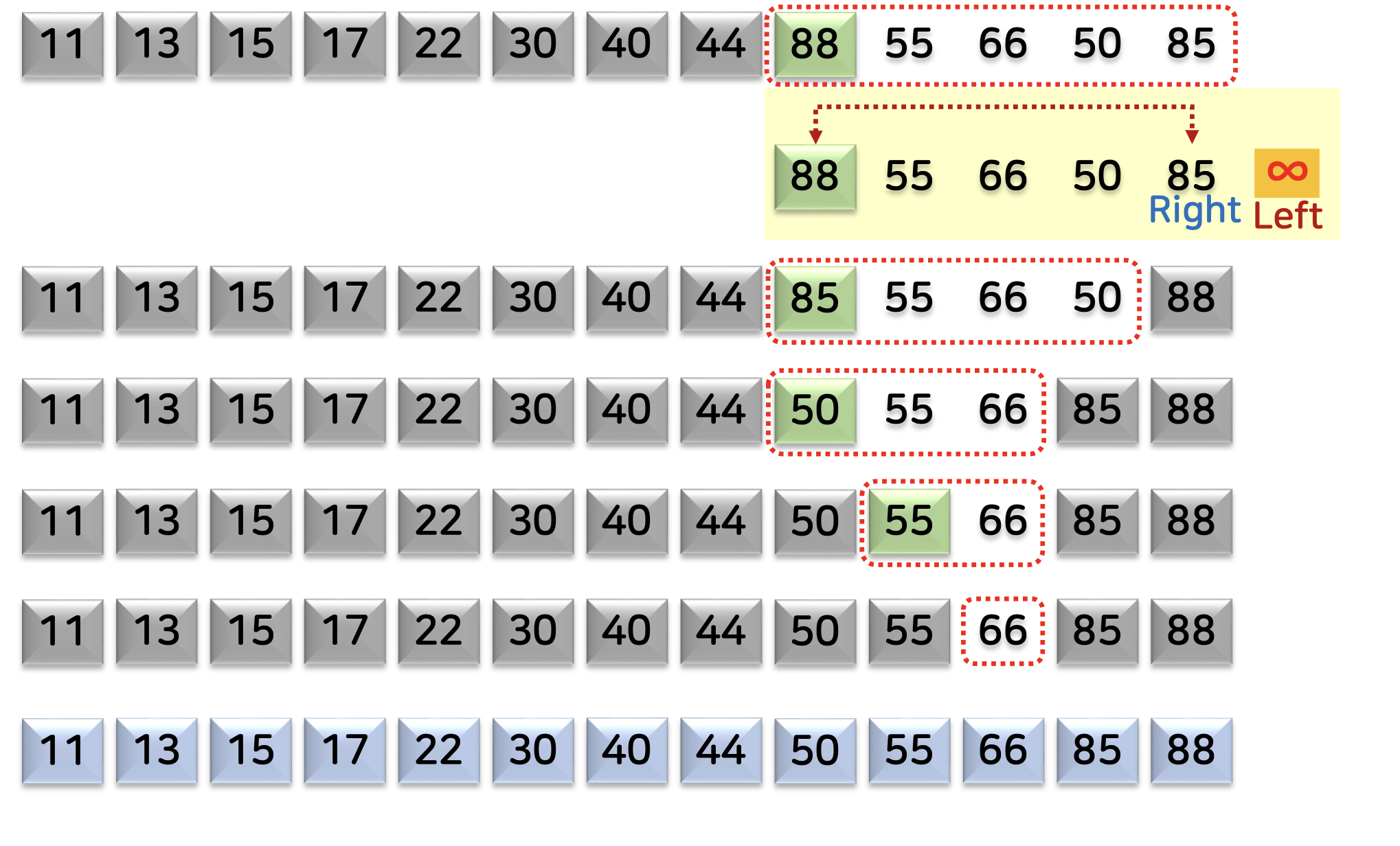
두 번째 그림에서 피벗이 88일 때, 피벗의 왼쪽에 있는 모든 수들이 다 피벗보다 작기 때문에 이동하지 않는다.
따라서, 무한대와 비교해야 적절히 정렬을 수행할 수 있다.
분할 함수의 수행 시간
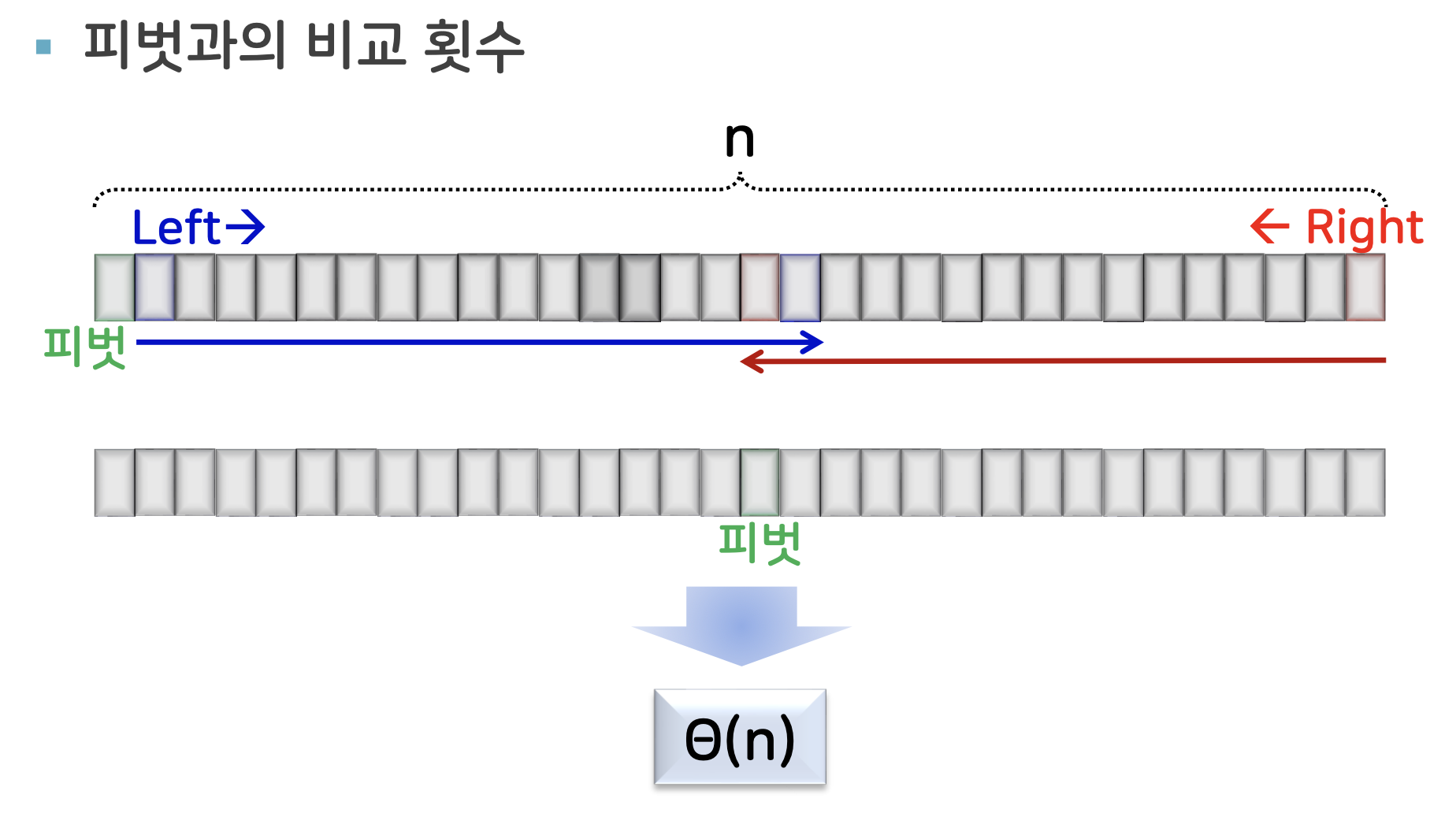
세타, 빅오엔 (O(n))
퀵 정렬의 수행 시간

데이터 n개를 정렬하는데 걸리는 시간은, 왼쪽을 정리하는데 걸리는 시간 + 오른쪽을 정리하는데 걸리는 시간
하지만, 왼쪽과 오른쪽 크기가 항상 같지 않을 텐데?
그림의 오른쪽 표를 보면, 왼쪽과 오른쪽의 크기가 서로 다르다. 따라서, 퀵정렬은 두 분할 배열의 크기에 따라서 달라진다.
퀵 정렬 최악의 경우
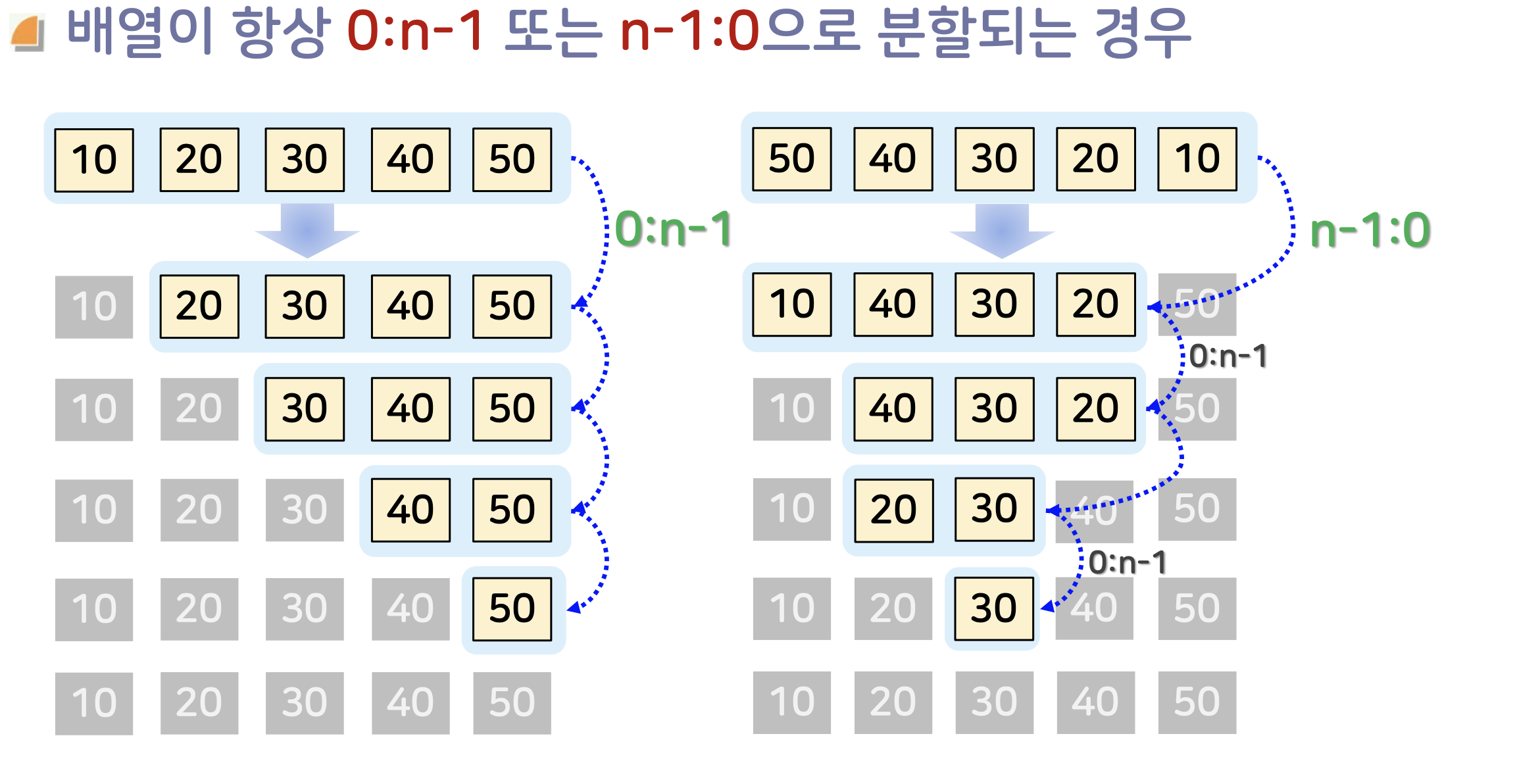
배열을 두 개로 나누었는데, 왼쪽이 없고 오른쪽이 없거나 오른쪽이 없고 왼쪽이 없는 경우 최악의 효율을 보인다.
즉, 피벗만 제자리를 잡고 나머지 모든 원소가 왼쪽에 있거나, 오른쪽에 있는 경우이다. (피벗이 부분배열에서 가장 큰 값이거나 가장 작은 값일 경우)
즉, 극심하게 불균형적으로 분할되었을 때 가장 나쁜 경우라고 할 수 있다.

퀵 정렬 최선의 경우
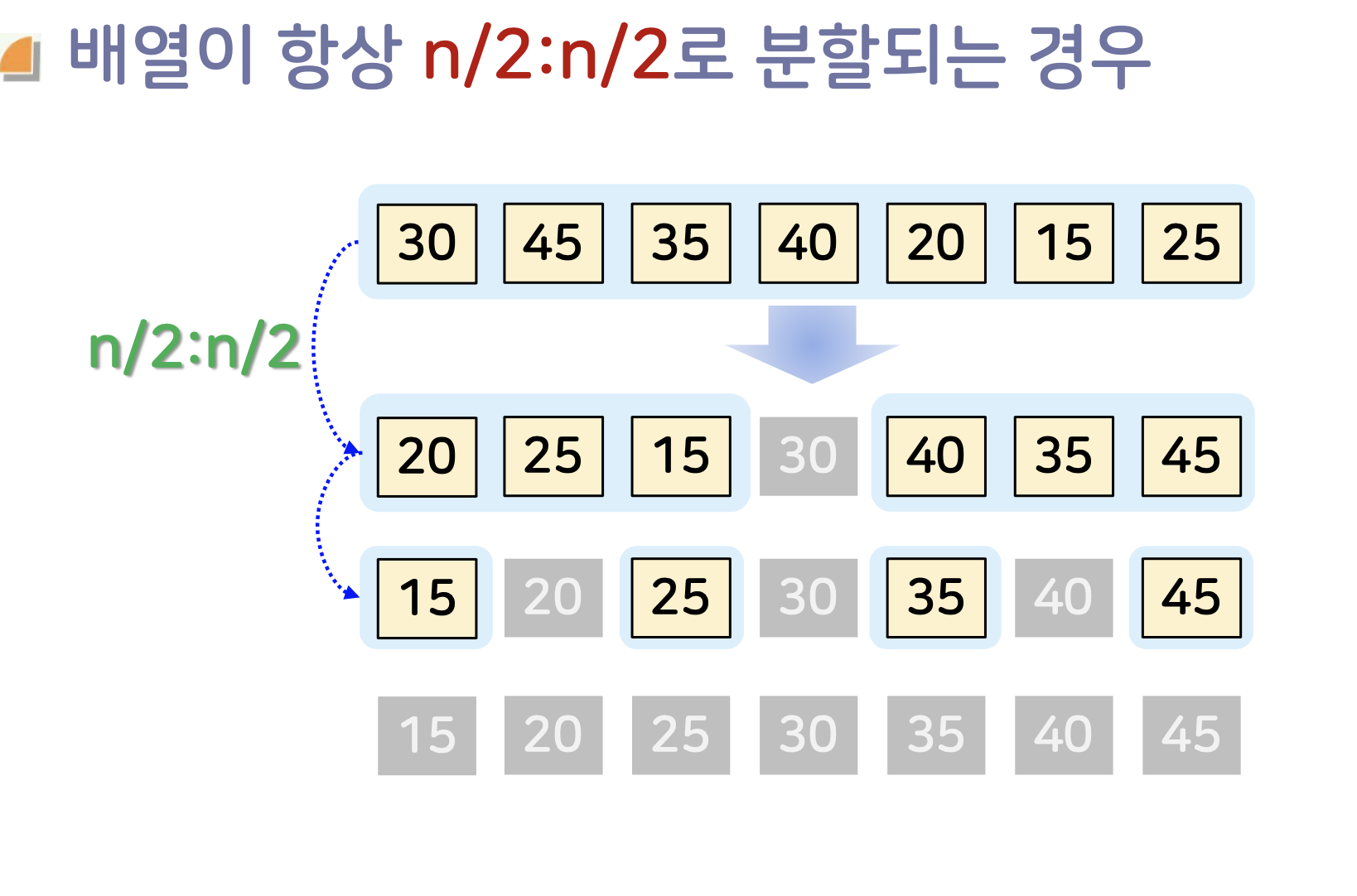
피벗을 잡았는데, 이상적으로 (균형적으로) 분할되는 경우 최선의 효율을 보인다.
따라서, 피벗이 중간값일 경우에 가장 효율이 좋다.
- 점화식

피벗 성능의 임의성만 보장된다면, 평균 성능을 보일 가능성이 매우 높다.
교재의 예시에는 배열의 첫 번째 부분을 피벗으로 선택했지만, 피벗을 잘 선택하면 최악의 경우가 거의 발생할 경우가 없다.
✓ 배열에서 임의의 값 선택 후, 배열의 처음 원소와 서로 교환 후 정렬을 수행하도록 한다.
