🧐 문제 설명

😍 나의 풀이
문제의 핵심 로직은 이 순서인 것 같다.
1. HEAD, NUMBER, TAIL 적절히 파싱
2. 우선 순위대로 파일명 정렬해서 출력
① HEAD(문자)는 사전 순으로 정렬(대소문자 구분X)
② NUMBER(숫자)는 숫자 순으로 정렬(숫자 앞의 0은 무시됨)
③ HEAD와 NUMBER가 같다면 원래 입력에 주어진 순서 유지
HEAD, NUMBER, TAIL 파싱
파일명을 한 글자씩 isdigit()으로 확인하다가 최초로 숫자가 나오면, 그 이전은 무조건 HEAD가 된다. (→ HEAD는 앞에 위치하고, 문자로만 이루어져 있기 때문)
우선순위 정렬 ... stable?
이후 NUMBER와 TAIL을 구분하는 것이 문제였는데 처음에는 TAIL이 어차피 .png, .jpg이든 TAIL을 고려하는 상황은 조건에서 없다고 생각했다. 왜냐하면, HEAD와 NUMBER의 우선순위가 같을 때도 TAIL은 관계없이 입력된 순서가 유지되기 때문이다. 그래서 따로 인덱스 값을 기억해서 정렬한 후에 인덱스 값을 기준으로 files 입력을 재출력할 계획이었는데 이는 반복문의 중첩 때문인지 런타임 에러가 발생했다.
그러던 중, 파이썬에서 제공하는 sort() 함수는 stable 정렬인 것을 알게 되었고(stable은 중복된 값을 입력된 순서와 동일하게 정렬) 인덱스 값은 고려할 필요 없이 HEAD와 NUMBER의 우선순위만 고려해서 정렬한다음 출력해주면 되었다. 그래서 TAIL도 HEAD와 HEAD가 아닌 부분을 구분하는 방식과 같은 방식으로 NUMBER와 TAIL을 구분했다.
아쉬운 점
테스트 케이스를 통과하고 나서, Q&A 게시판을 확인해보니 이 문제의 테스트 케이스가 조금 부족하다는 생각이 들었다. 왜냐하면, NUMBER의 제한 조건은 00000~99999까지의 최대 5자리의 숫자라고 명시되어 있는데 그렇다면 예를들어 IMG00000123.jpg라는 파일이 있다고 하면 HEAD는 'IMG', NUMBER는 '00000', TAIL은 '123.jpg'가 되어야 한다. 이 경우 지금 작성한 코드대로는 NUMBER가 '00000123', TAIL은 '.jpg'가 되기 때문에 제한 조건에 위배된다. 그래서 코드에서도 NUMBER에 대한 제한을 두는 방식으로 했어야 하는데 그렇게 구현하지 않았음에도 모든 TC를 통과했다...
def solution(files):
tmp = []
head, number, tail = '', '', ''
for file in files:
for i in range(len(file)):
if file[i].isdigit(): # 숫자가 나오면 그 이전은 무조건 HEAD, 이후는 NUMBER, TAIL로 다시 구분
head = file[:i]
number = file[i:]
for j in range(len(number)): # NUMBER와 TAIL 구분 (숫자 안나오면 TAIL)
if not number[j].isdigit():
tail = number[j:]
number = number[:j]
break
tmp.append([head, number, tail])
head, number, tail = '', '', ''
break
tmp = sorted(tmp, key=lambda x:(x[0].lower(), int(x[1])))
return [''.join(i) for i in tmp]👏 다른 사람의 풀이
정규 표현식은 진짜 코드가 간결하게 나오는구나... 정규 표현식을 공부해야할 것 같다...
import re
def solution(files):
temp = [re.split(r"([0-9]+)", s) for s in files]
sort = sorted(temp, key = lambda x: (x[0].lower(), int(x[1])))
return [''.join(s) for s in sort]🥇 Today I Learn
정렬의 Stable
정렬의 Stable 이란 정렬되지 않은 상태에서 같은 키 값을 가진 원소의 순서가 정렬 후에도 유지되는가?
- Stable Sort(안정 정렬) → 중복된 값의 경우 입력 순서와 동일하게 유지해서 정렬 하는 것
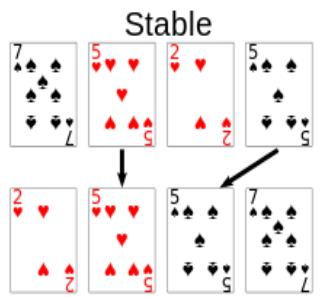
- Unstable Sort(불안정 정렬) → 중복된 값의 경우 입력 순서를 무작위로 뒤섞은 상태에서 정렬 하는 것

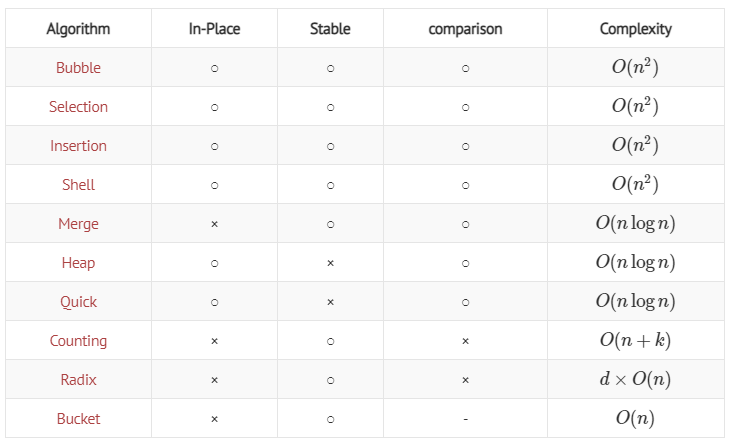
정렬의 In-Place
정렬의 In-Place란 입력 리스트 내부에서 정렬이 이뤄지는가? 아니면 별도의 저장공간이 필요한가?
-
합병정렬의 경우 입력리스트를 분할해 이를 정렬하고 다시 합치는 과정에서 분할된 리스트를 별도로 저장해 두어야 함
-
카운팅정렬과 래딕스정렬은 입력값의 빈도를 세어서 저장해 두는 변수, 결과리스트를 저장해 둘 변수가 필요함
-
버킷정렬은 버킷이라는 변수를 만들 공간이 있어야 함
정렬의 Comparison
정렬의 Comparison은 값을 비교하는 정렬 알고리즘인가?
-
카운팅정렬의 경우 값을 비교하지 않고도 정렬을 수행할 수 있어 comparson sort가 아님
-
래딕스정렬은 카운팅정렬을 기본으로 사용
-
버킷정렬의 경우 각 버킷에 대해 어떤 정렬 알고리즘을 쓰느냐에 따라 comparison 유무가 달라질 수 있음
정리