
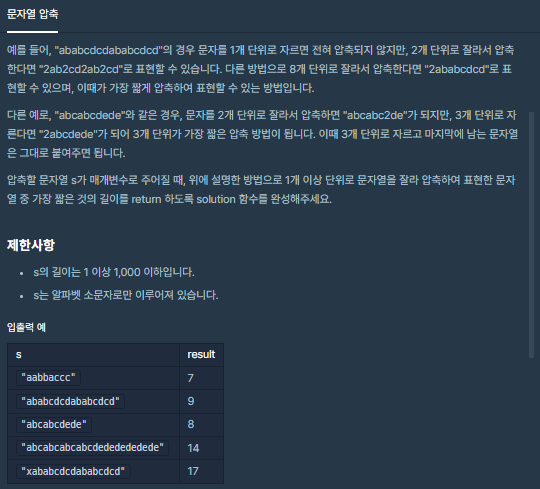
🧐 문제 설명
😍 나의 풀이
문자열 s를 1부터 단위를 크게 하며 잘라서 비교를 계속 하려고 했다. 이전에도 풀이하다 느꼈는데 대부분 이런 완전 탐색의 경우 len(s)까지 굳이 다 할 필요 없이 len(s)//2까지만 탐색해도 모든 경우의 수를 확인할 수 있기 때문에 실행 시간을 단축할 수 있다. 그런데 단순해보이지만 상당히 시간을 많이 쓰고 머리도 복잡했다. 그 이유는 for문이 중첩되는데
- 첫 번째 바깥쪽 for는 문자열 s를 끊어보는 단위(1, 2, 3...글자씩)
- 그 안에 두 번째 for는 첫 번째 for에서 끊는 글자 만큼 s를 직접 도는 반복문
그런데 이 두가지가 중첩되면서 인자가 헷갈려서 string이 너무 길게 나오거나 원하지 않는 결과가 나와서 버벅였다.
def solution(s):
answer = len(s)
for i in range(1, len(s)//2+1): #나누는 문자열 수의 단위
string = ''
count = 1
tmp = s[:i]
for slice in range(i, len(s), i):
if tmp == s[slice:slice+i]: # 문자열이 반복되는 경우
count += 1
else: # 더 이상 압축 못하는 경우
if count == 1: # 앞에서 압축된 게 없음
string += tmp
tmp = s[slice:slice+i]
else: # 앞에 압축된 것 count 표현
string += (str(count) + tmp)
count = 1
tmp = s[slice: slice+i]
if count == 1: # 비교할 문자가 없는 마지막 문자의 경우 처리
string += tmp
else:
string += (str(count) + tmp)
answer = min(answer, len(string)) # 최소 길이 계산
return answer👏 다른 사람의 풀이
스택을 이용한 풀이.
Stack 자료 구조를 생각해보긴 했는데 이렇게 풀이하면 되는구나
def solution(s):
LENGTH = len(s)
STR, COUNT = 0, 1
cand = [LENGTH] # 1~len까지 압축했을때 길이 값
for size in range(1, LENGTH):
compressed = ""
# string 갯수 단위로 쪼개기 *
splited = [s[i:i+size] for i in range(0, LENGTH, size)]
stack = [[splited[0], 1]]
for unit in splited[1:]:
if stack[-1][STR] != unit: # 이전 문자와 다르다면
stack.append([unit, 1])
else: # 이전 문자와 다르다면
stack[-1][COUNT] += 1
compressed += ('').join([str(cnt) + w if cnt > 1 else w for w, cnt in stack])
cand.append(len(compressed))
return min(cand) # 최솟값 리턴🥇 Today I Learn
특별히 배운 스킬은 없지만 완전탐색, DFS, BFS 문제들을 좀 많이 풀어봐야할 것 같다.

공부 쫌 해!!!😂