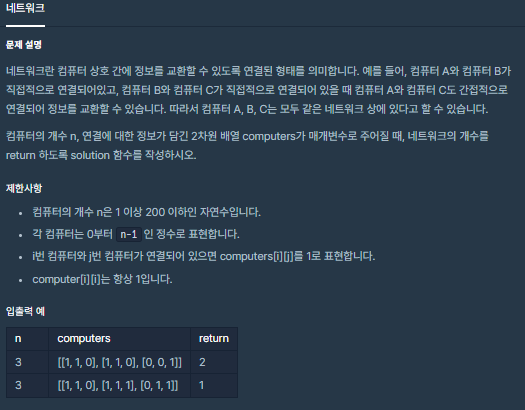
🧐 문제 설명
😍 나의 풀이
DFS(깊이우선탐색), BFS(너비우선탐색)을 모두 이용해서 풀어보았다. 나는 BFS보다 DFS가 더 쉬운 것 같다...
기본 로직
DFS, BFS 모두 시작은 아직 방문하지 않은 visited 리스트를 node의 수 만큼 False로 만들어준다. (→이 후 탐색을 진행하면서 방문한 node는 True로 바꿔줄 계획) 그리고 DFS나 BFS가 끝까지 진행 되고 나면 인접한 노드는 다 방문한(연결된) 것이기 때문에 위 문제의 네트워크 1개가 만들어지므로 그 때 마다 answer += 1하는 것이 문제의 큰 틀이다. 언제까지? 노드 수 만큼 반복!
DFS 풀이
def dfs(v, computers, visited):
visited[v] = True
for i in range(len(computers[v])):
if computers[v][i] == 1 and visited[i] == False:
dfs(i, computers, visited)
def solution(n, computers):
answer = 0
visited = [False] * n
for i in range(n):
if not visited[i]:
dfs(i, computers, visited)
answer += 1
return answerDFS 알고리즘은 스택 자료구조(재귀)를 사용한다. 방문한 노드는 visited를 True로 바꾸고 인접한 노드 중 방문하지 않은 노드를 다시 DFS로 재귀 호출하여 이를 반복한다.
BFS 풀이
from collections import deque
def bfs(start, computers, visited):
bfs = deque([start])
visited[start] = True
while bfs:
v = bfs.popleft()
for i in range(len(computers[v])):
if not visited[i] and computers[v][i] == 1:
bfs.append(i)
visited[i] = True
def solution(n, computers):
answer = 0
visited = [False] * n
for i in range(n):
if not visited[i]:
bfs(i, computers, visited)
answer += 1
return answerBFS 알고리즘은 큐 자료구조를 활용한다.(python에서는 덱 활용) 첫 번째 방문할 노드를 정해서 큐에 삽입한다. 방문 처리를 True로 하고 이를 빼내서 인접한 노드를 방문한다. 큐에 더 이상 원소가 없을 때까지 반복한다.
👏 다른 사람의 풀이
내가 bfs, dfs 둘 다 풀었으니 생략함 ㅋㅋㅎㅎ
알고리즘은 다른 사람 로직 보는 것도 귀찮아
🥇 Today I Learn
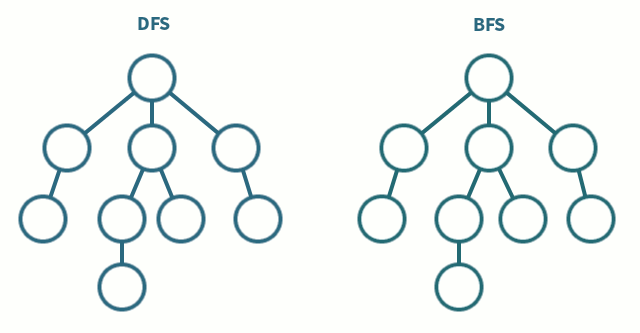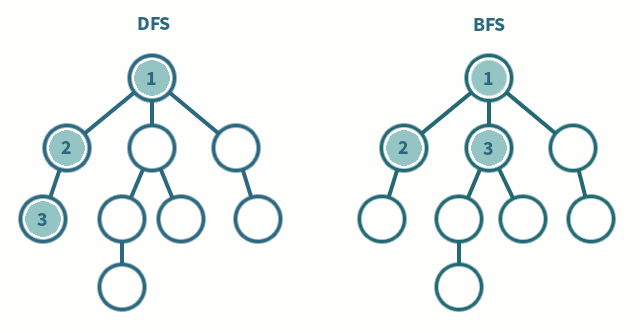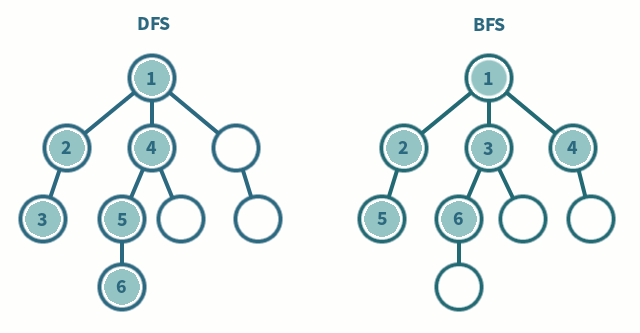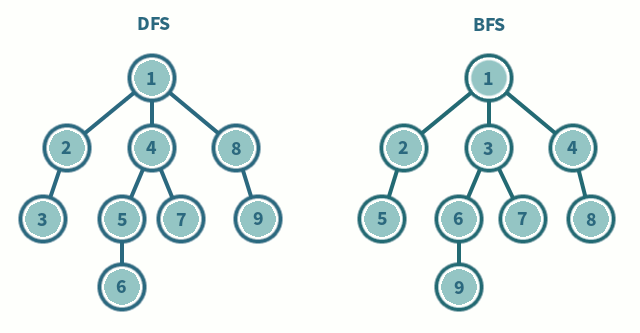
DFS (깊이 우선 탐색)
-
그래프에서 깊은 부분을 우선 탐색하는 알고리즘
-
스택 자료구조(혹은 재귀 함수)를 이용
1. 탐색 시작 노드를 스택에 삽입하고 방문 처리
2. 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리, 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄
3. 더 이상 2번 과정을 수행할 수 없을 때까지 반복
BFS (너비 우선 탐색)
-
그래프에서 가까운 노드부터 우선 탐색하는 알고리즘
-
큐 자료구조를 이용
1. 탐색 시작 노드를 큐에 삽입하고 방문 처리
2. 큐에서 노드를 꺼낸 뒤에 해당 노드의 인접 노드 중에 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리
3. 더 이상 2번 과정을 수행할 수 없을 때까지 반복