
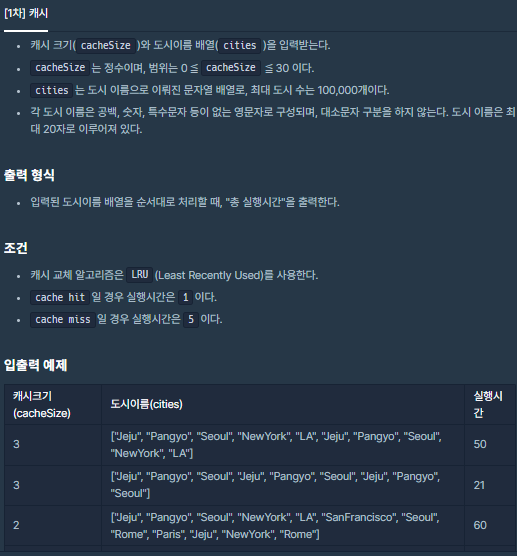
🧐 문제 설명
😍 나의 풀이
OS를 공부할 때 자주 나오는 페이지교체알고리즘 LRU가 나와서 반가웠다. LRU의 개념을 알고 있다면 쉽게 풀 수 있는 문제였다.
한 가지 실수한 점은 pop(0)를 사용해서 리스트를 큐처럼 먼저 들어온 요소를 처리하고자 했는데 이 때, 요소가 비어있는 경우(cacheSize가 처음부터 0)인 경우를 고려하지 않아서 Error가 발생했다는 점이다.
cache 적중률을 검사하는 반복문 동작 전에 cacheSize에 대한 조건문을 걸어주어서 바로 해결했다. 대소문자를 구분하지 않는다는 조건도 나중에 본 것도 실수ㅎㅎ
def solution(cacheSize, cities):
answer = 0
cache = []
cities = [i.lower() for i in cities]
if cacheSize != 0:
for city in cities:
#cache miss
if city not in cache:
if len(cache) < cacheSize:
cache.append(city)
else:
cache.pop(0)
cache.append(city)
answer += 5
#cache hit
else:
cache.pop(cache.index(city))
cache.append(city)
answer += 1
else:
answer = len(cities) * 5
return answer👏다른 사람의 풀이
이 사람은 덱으로 구현함과 동시에 maxlen을 사용해서 나의 풀이에서 현재 캐시안에 들어있는 요소의 수와 캐시 사이즈를 비교하는 조건을 쓸 필요가 없었다.
그리고 pop()으로 캐시를 최신화하지 않고 remove()를 사용하면서 cacheSize가 0이 되는 경우에 발생할 수 있는 indexError에서 벗어난 풀이를 작성한 것 같다.
def solution(cacheSize, cities):
import collections
cache = collections.deque(maxlen=cacheSize)
time = 0
for i in cities:
s = i.lower()
if s in cache:
cache.remove(s)
cache.append(s)
time += 1
else:
cache.append(s)
time += 5
return time🥇 Today I Learn
페이지(캐시) 교체 알고리즘 (LRU)
- 사용자에게 빠르게 정보를 제공하기 위해 사용하는 캐시에서 새로운 데이터가 발생했을 때, 가장 오래전에 사용된 데이터를 제거하고 새로운 데이터를 삽입하는 알고리즘
1. 새로운 데이터가 들어온 경우
① 캐시에 넣어준다.
② 캐시가 가득 차있다면, 가장 오래된 데이터를 제거하고 넣어준다.
2. 캐시에 존재하는 데이터가 들어온 경우
① 해당 데이터를 꺼낸 뒤,
② 가장 최근 데이터 위치로 보내준다.
for data in user_data:
# Miss!
if data not in cache:
if len(cache) < cacheSize:
cache.append(data)
else:
cache.pop(0)
cache.append(data)
# Hit!
else:
cache.pop(cache.index(data))
cache.append(data)
공부 쫌 해!!!😂