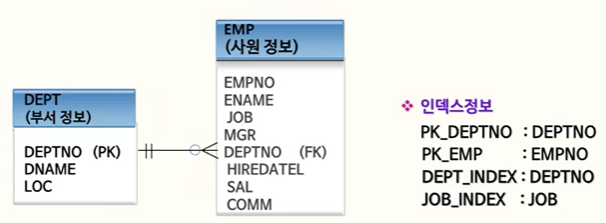
아래의 테이블 예제로 조인에 대해 알아볼 것이다.
1️⃣ NL(Nested Loops) 조인
Nested Loop 조인은 인덱스 사용을 기반으로 한 테이블에서 데이터를 먼저 찾고, 그 다음 테이블을 조인하는 방식이다. 먼저 조회되는 테이블 테이블을 외부 테이블 Outer Table(Driving)이라고 하고, 그 다음 조회되는 테이블은 내부 테이블 Inner Table(Driven) 이라고 한다.
👉선행 테이블의 조건을 만족하는 모든 행의 수만큼 반복 수행되기 때문에 외부 테이블의 크기가 작은 것을 먼저 찾는 것이 중요한데, 그래야 데이터 스캔 범위를 줄일 수 있기 때문이다.
즉 하나의 테이블 기준으로, 각 row를 추출할때마다 순차적으로 상대 테이블의 연관된 모든 row들을 조인에 의해 추출하는 연결 방식이다.
SELECT /*+ USE_NL(e d) */
e.ename, d.dname
FROM emp e INNER JOIN dept d
ON (e.deptno = d.deptno);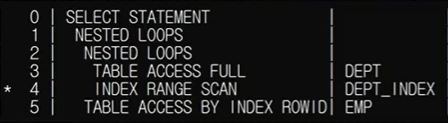
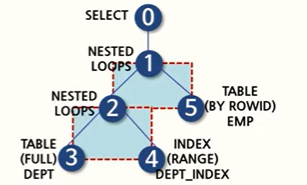
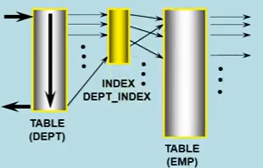
부서 테이블을 full table scan으로 데이터를 읽어들일 때마다, 사원 테이블이 갖는 부서 번호 인덱스를 통해 연결을 맺으면서 데이터가 추출되고 있음을 의미한다. 이후에도, 이 인덱스를 통해 EMP 테이블로 계속 접근을 하게 된다.
두 테이블이 index를 통해 연결이 행해짐 을 아래의 그림을 통해 봐보자.
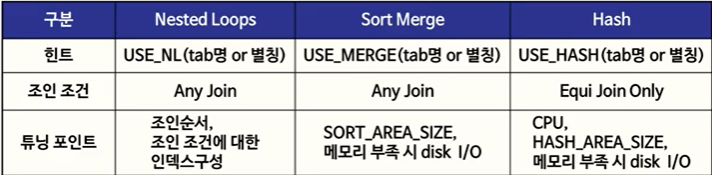
✅ 튜닝 포인트
1) 조인 횟수의 최소화를 위한 조인 순서 최적화
2) 조인 조건에 대한 인덱스 구성 및 사용
=> 조인 조건에 대한 인덱스가 구성되어 있어야 하고, 사용되어야 하는 것이 중요하다.
✅ NL 조인 특징
1) 인덱스에 의한 랜덤 액세스(Random Access) 에 기반을 두기 때문에, 대량의 데이터 처리 시 불리하다. 따라서, 데이터 양이 적을때 사용한다.
2) Driving 테이블(데이터를 먼저 읽어들일 테이블)은 row 수가 적거나, where절의 조건으로 적절하게 row를 제한 할 수 있는 것으로 선정 되어야 한다.
3) Driven(연결되는 테이블)은 조인 시 사용할 연결 고리 칼럼에 반드시 적절한 인덱스가 있어야 한다.
✅ NL 조인 절차
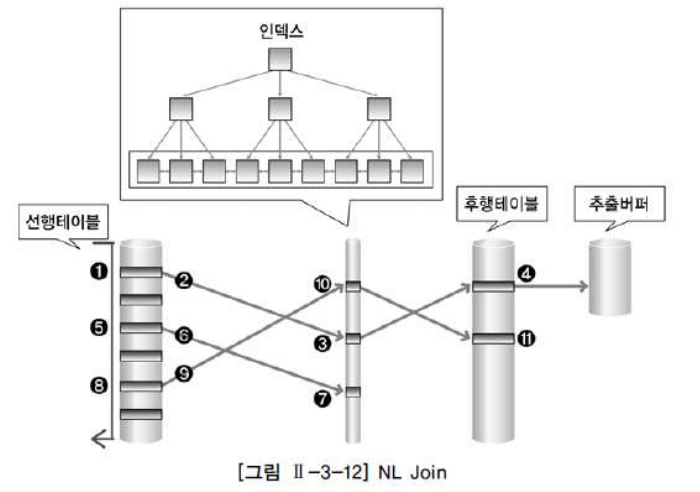
1) 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾는다.
2) 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾으러 가서 조인을 시도한다.
3) 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인한다.
4) 인덱스에서 추출한 레코드 식별자를 이용해 후행 테이블을 액세스한다
💡 NL 조인은 인덱스 사용에 따른 랜덤 액세스로 인한 오버헤드 존재
참고 자료
https://schatz37.tistory.com/2
2️⃣ SM(Sort Merge) 조인
만약, 두 테이블의 연결 고리 칼럼에 대한 인덱스가 없는 경우나 데이터의 규모가 큰 경우 NL 조인이 불가능하다. 왜냐하면, 인덱스 사용 자체가 I/O를 많이 발생시켜서 성능 저하를 야기 하기 때문이다. 이럴때 사용 가능한 것이 ⭐조인 칼럼의 인덱스를 사용하지 않는 SM 조인 이다.
SM조인은 1)각 테이블로부터 동시에 독립적으로 데이터를 SORT_AREA라는 메모리 공간에 읽어 들인 후, 2)연결고리 칼럼을 대상으로 정렬 작업을 수행한다. 정렬이 모두 끝나게 되면, 3)그때 조인을 수행함으로써 두 테이블을 병합한다.
SELECT /*+ USE_MERGE(e d) */
e.ename, d.dname
FROM emp e INNER JOIN dept d
ON (e.deptno = d.deptno);해당 sql에 대한 실행계획과 분석도이다.
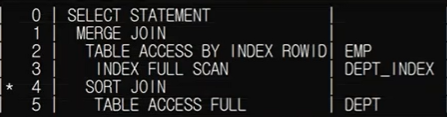
2,3,4,5번의 작업이 모두 동시에 진행되는 조인이다.
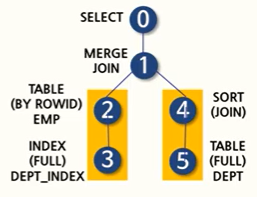
즉, emp테이블로부터는 부서 번호 인덱스 사용을 통해 INDEX FULL 스캔을 하기 때문에 부서 번호에 대해 정렬된 데이터를 갖게 된다. 마찬가지로, dept 테이블도 TABLE FULL 스캔을 통해 읽어들인 데이터를 부서 번호에 대해 정렬하게 된다. 이 작업이 모두 끝이 나면, equal로 조인을 한다.
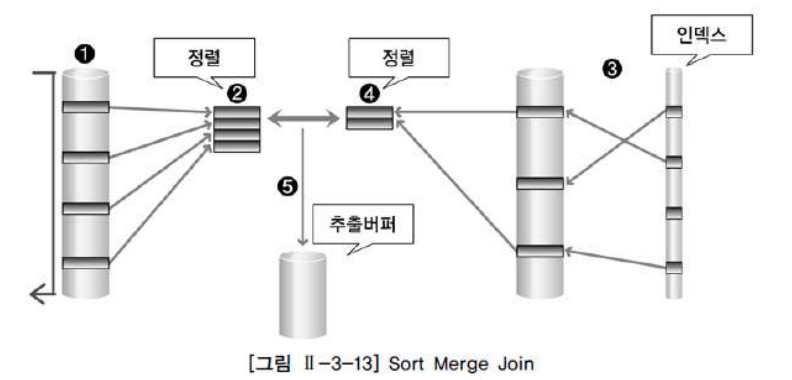
✅ SM 조인 튜닝 포인트
1) 각 테이블로부터 데이터를 빨리 처리하도록 한다.
2) 연결 고리 칼럼 기준으로 정렬 작업을 위한 메모리(SORT_AREA_SIZE) 공간을 최적화 해야한다.
✅ SM 조인 특징
1) 연결고리 칼럼에 인덱스가 전혀 없어도 빠른 조인을 수행한다.
2) where 절의 조건으로 주어진 범위를 줄이지 못하는 경우에 효율적이다.
3) 조인이 되는 두 집합은 모두 연결 고리 칼럼에 기준으로 정렬되어야 하고, 정렬을 위한 메모리 사용도 부가적으로 존재한다.
4) Sort Merge 조인은 정렬이 발생하므로 데이터 양이 많으면 성능이 떨어진다.(임시 영역에서 수행된되는데 이는 디스크에 있기 때문)
5) PK와 FK 관계에서 FK 인덱스가 없을 때 Sort Merge 방식으로 옵티마이저가 동작한다.
💡 SM 조인은 정렬 작업으로 인한 오버헤드 존재
3️⃣ Hash 조인
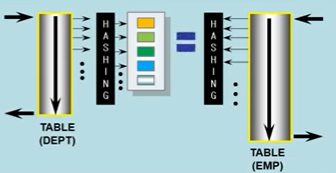
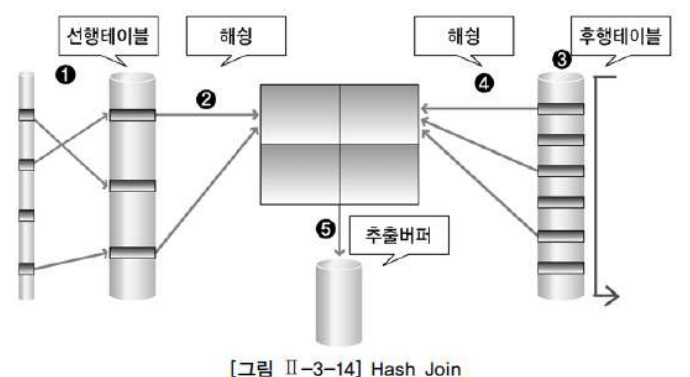
위 두 조인의 문제점을 해결하기 위해서 사용 가능한 것이 해시 조인이다. 두 테이블 중에서 작은 테이블을 HASH 메모리에 로딩하고 두 테이블의 조인 키를 사용해서 해시 테이블을 생성 한다.
해시 조인은 1)Driving 테이블로 하나를 선택해서 데이터를 먼저 읽어 들인 후, hashing을 통해 해시 값을 만들어 메모리에 올린다. 2)다음으로, 조인해야할 테이블로부터 데이터를 읽어서 hashing을 통해 해시 값을 만든다. 3)이렇게 만든 해시 값으로 EQUAL 조인을 한다.
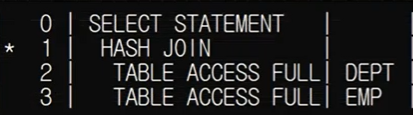
SELECT /*+ USE_HASH(e d) */
e.ename, d.dname
FROM emp e INNER JOIN dept d
ON (e.deptno = d.deptno);해당 sql에 대한 실행계획과 도식도를 살펴보자.
먼저, 부서 테이블로부터 FULL TABLE SCAN을 통해 데이터를 읽어들인후, 부서 번호에 대해 해싱을 통해 해시 VALUE를 만들고 메모리에 올린다. 다음으로, 연결 테이블(EMP)로부터 FULL TABLE SCAN을 통해 데이터 읽은 후 부서 번호에 대해 해싱을 통해 해시 VALUE를 만든다. 마지막으로, EQUAL로 해시 VALUE 끼리 조인을 맺게 된다.
✅ 해시 조인 튜닝 포인트
1) Driving 테이블이 중요하다(규모가 작은 테이블).
2) 각 테이블로부터 데이터를 빨리 처리하도록 한다.
3) 조인 작업을 위한 메모리(HAS_AREA_SIZE, SORT_AREA_SIZE의 2배) 최적화 한다.
✅ 해시 조인 특징
1) 조인을 위해 만든 해시 값을 저장하기 위해 has bucket이 구성되는데, 이를 위해 많은 메모리와 CPU 연산을 필요로 한다.
2) 하드웨어 자원이 넉넉한 상황에서는 다른 조인보다 효율적일 수 있지만, 부족한 상황에서는 오히려 다른 조인보다 비효율 적이다.
3) 다른 조인과 달리 EQUAL 조인만 가능하다.
세가지 조인 총정리