
1️⃣ 옵티마이저란?
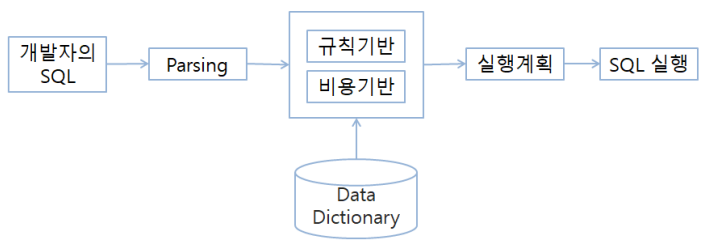
SQL 개발자가 SQL을 작성하여 실행할 때, 옵티마이저는 SQL을 어떻게 실행할 것인지 계획하게 된다. 즉, 옵티마이저는 최적의 실행 방법인 실행 계획(Execution Plan)을 수립하고 SQL을 실행하는 DBMS의 SW이다.
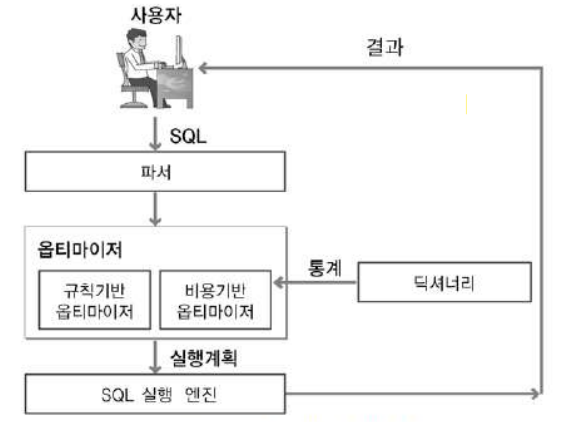
동일한 결과가 나오는 SQL도 어떻게 실행하느냐에 따라 성능이 달라지기 때문에, 따라서 옵티마이저의 실행 계획은 SQL 성능에 아주 중요한 역할 을 한다.
✅옵티마이저의 특징
1) 데이터 딕셔너리에 있는 오브젝트 통계, 시스템 통계 등의 정보를 사용해서 예상되는 비용을 산정한다.
2) 여러 개의 실행 계획 중 최저비용을 가진 계획을 선택해 SQL을 실행한다
옵티마이저가 최적의 실행 방법을 결정하는 방식에 따라 다음과 같이 규칙기반/비용기반 옵티마이저로 구분된다.
2️⃣ 규칙기반 옵티마이저
규칙기반 옵티마이저는, 규칙(우선 순위)을 가지고 실행계획을 생성한다. 옵티마이저가 실행계획을 생성할 때 참조하는 정보는 다음과 같다.
💡 참조 정보
1) SQL 문을 실행하기 위해서 이용 가능한 인덱스 유무와 (유일, 비유일, 단일, 복합 인덱스) 종류
2) SQL 문에서 사용하는 연산자(=, <, <>, LIKE, BETWEEN 등)의 종류
3) SQL 문에서 참조하는 객체(힙 테이블, 클러스터 테이블 등)의 종류 등이 있다.
이러한 정보에 따라 우선 순위(규칙)가 정해져 있고, 이 우선 순위를 기반으로 실행계획을 생성한다. 참고로, 규칙기반 옵티마이저는 해당 SQL 문에서 이용 가능한 인덱스가 존재한다면 전체 테이블 액세스 방식보다는 항상 인덱스를 사용하는 실행계획을 생성한다.(인덱스 > 테이블)
| 우선 순위 | 설명 |
|---|---|
| 1 | ROWID를 사용한 단일 행인 경우 |
| 2 | 클러스터 조인에 의한 단일 행인 경우 |
| 3 | 유일하거나 PK를 가진 해시 클러스터 키에 의한 단일 행인 경우 |
| 4 | 유일하거나 PK에 의한 단일 행인 경우 |
| 5 | 클러스터 조인인 경우 |
| 6 | 해시 클러스터 조인인 경우 |
| 7 | 클러스터 키인 경우 |
| 8 | 복합 칼럼 인 경우 |
| 9 | 단일 칼럼 인 경우 |
| 10 | 구성된 칼럼에서 제한된 범위를 검색하는 경우 |
| 11 | 구성된 칼럼에서 무제한 범위를 검색하는 경우 |
| 12 | 정렬-병합(Sort Merge) 조인인 경우 |
| 13 | 구성된 칼럼에서 MAX/MIN을 구하는 경우 |
| 14 | 구성된 칼럼에서 ORDER BY를 실행하는 경우 |
| 15 | 전체 테이블을 스캔(FULL TABLE SCAN)하는 경우 |
1) 규칙 1
ROWID 를 통해서 테이블에서 하나의 행을 액세스하는 방식이다.
ROWID 는 행이 포함된 데이터 파일, 블록 등의 정보를 가지고 있기 때문에 다른 정보를 참조하지
않고도 바로 원하는 행을 액세스할 수 있다. 하나의 행을 액세스하는 가장 빠른 방법이다.
2) 규칙 4
유일 인덱스(Unique Index)를 통해서 하나의 행을 액세스하는 방식이다.
이 방식은 인덱스를 먼저 액세스하고 인덱스에 존재하는 ROWID 를 추출하여 테이블의 행을 액세스한다.
3) 규칙 8
복합 인덱스에 동등(‘=’ 연산자) 조건으로 검색하는 경우이다. 복합 인덱스 사이는 1)인덱스 구성 칼럼의 개수가 더많고 2)해당 인덱스의 모든 구성 칼럼에 대해 ‘=’로 값이 주어질 수록 우선순위가 더 높다.
4) 규칙 10
인덱스가 생성되어 있는 칼럼에 양쪽 범위를 한정하는 형태로 검색하는 방식이다. 이러한 연산자에는 BETWEEN, LIKE 등이 있다.
5) 규칙 11
인덱스가 생성되어 있는 칼럼에 한쪽범위만 한정하는 형태로 검색하는 방식이다. 이러한 연산자에는 >, >=, <, <= 등이 있다.
✅규칙기반 옵티마이저와 조인
규칙기반 옵티마이저가 조인 순서를 결정할 때는 1)조인 칼럼 인덱스의 존재 유무, 2)규칙에 다라 우선 순위가 높은 테이블을 선행 테이블로 선택한다.
예시를 들어 옵티마이저 최적화 과정을 알아보자.
SELECT ENAME
FROM EMP
WHERE JOB = 'SALESMAN'
AND SAL BETWEEN 3000 AND 6000
INDEX ------- EMP_JOB : JOB EMP_SAL : SAL PK_EMP : EMPNO (UNIQUE)JOB 칼럼의 조건은 ‘=’(규칙 9), SAL 칼럼의 조건은 ‘BETWEEN’(규칙 10)으로 값이 주어졌고, 각각의 칼럼에 단일 칼럼 인덱스가 존재한다. 따라서, 우선순위가 높은 EMP_JOB 인덱스를 이용해서 조건을 만족하는 행에 대해 EMP 테이블을 액세스하는 방식을 선택할 것이다.
Execution Plan ------------------------------------------------------------
SELECT STATEMENT
Optimizer=CHOOSE TABLE ACCESS (BY INDEX ROWID)
OF 'EMP' INDEX (RANGE SCAN)
OF 'EMP_JOB' (NON-UNIQUE)또한, 양쪽 조인 칼럼에 모두 인덱스가 없는 경우에는 Sort Merge Join 을, 둘 중하나라도 조인 칼럼에 인덱스가 존재한다면 일반적으로 NL Join 을 사용한다.
3️⃣ 비용기반 옵티마이저
비용 기반 옵티마이저는 ⭐SQL 문을 처리하는데 필요한 비용이 가장 적은 실행계획을 선택하는 방식이다. 여기서 비용이란, SQL 문을 처리하기 위해 예상되는 소요시간 또는 자원 사용량을 말한다.
테이블/인덱스 등의 오브젝트 통계 및 시스템 통계를 사용해서 총 비용을 계산하기 때문에, 정확한 통계 정보를 유지하는 것이 비용기반 최적화에서 중요하다.
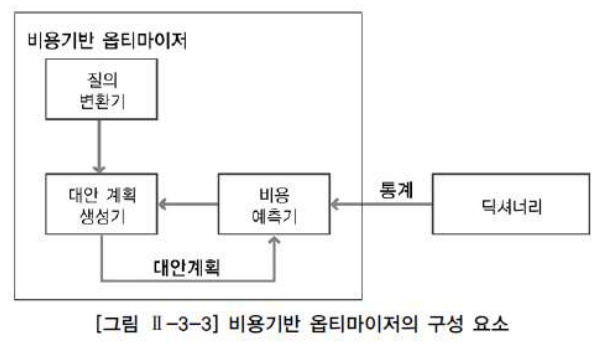
비용기반 옵티마이저는 질의 변환기, 대안 계획 생성기, 비용 예측기 등의 모듈로 구성되어 있다.
질의 변환기는 사용자가 작성한 SQL 문을 처리하기에 보다 용이한 형태로 변환하는 모듈이며, 대안 계획 생성기는 동일한 결과를 생성하는 다양한 대안 계획을 생성하는 모듈이다.
하지만 대한 계획 생성이 너무 많아지면 성능 저하를 나으므로 대부분의 상용기는 비용 예측기를 통해 대안 계획의 수를 제약한다. 비용 예측기는, 대안 계획 생성기에 의해서 생성된 대안 계획의 비용을 예측하는 모듈이다. 또한 보다 나은 예측을 위해 옵티마이저는 정확한 통계 정보를 필요로 한다.
4️⃣ 실행 계획
실행 계획이란, 요구한 사항을 처리하기 위한 절차와 방법을 의미한다. 즉 실행계획을 생성한다는 것은 SQL 을 어떤 순서로 어떻게 실행할 지를 결정하는 작업이다.
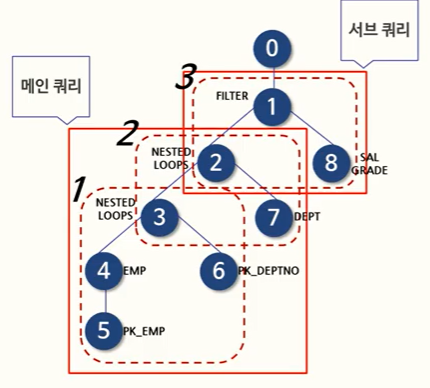
✅ 생성된 실행계획 보는 법(Oracle)
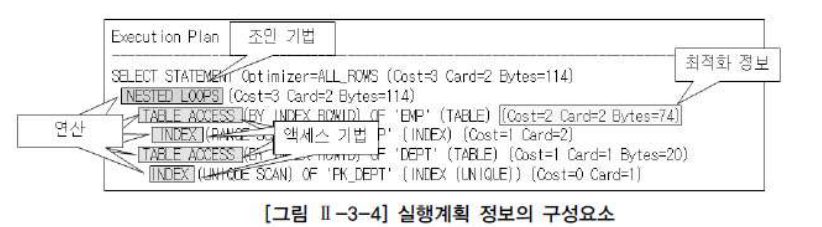
1) 조인 순서
조인 순서는, 조인작업을 수행할 때 참조하는 테이블의 순서이다. 위 그림에서의 조인 순서는 EMP -> DEPT 인 것을 볼 수 있다.
2) 조인 기법
조인 기법은 두개의 테이블을 조인할 때 사용할 수 있는 방법으로서 여기에는 NL(Nested Loops) Join, Hash Join, Sort Merge Join 등이 있다.
3) 액세스 기법
하나의 테이블을 액세스할 때 사용할 수 있는 방법이다. 1)인덱스를 이용하여 테이블을 액세스하는 인덱스 스캔(Index Scan) 과 2)테이블 전체를 모두 읽으면서 조건을 만족하는 행을 찾는 전체 테이블 스캔(Full Table Scan) 등이 있다.
4) 최적화 정보
최적화 정보란, 옵티마이저가 실행계획의 각 단계마다 예상되는 비용 사항을 표시한 것이다. 최적화 정보에는 Cost, Card, Bytes 가 있다.
Cost : 상대적인 비용 정보
Card : Cardinality 의 약자, 주어진 조건을 만족한 결과 집합 혹은 조인 조건을 만족한 결과 집합의
건수
Bytes : 결과 집합이 차지하는 메모리 양을 바이트로 표시
이러한 비용 정보는 실제로 SQL 을 실행하고 얻은 결과가 아니라, 통계 정보를 바탕으로 옵티마이저가 계산한 예상치이다. 따라서 이러한 사항이 실행계획에 없으면, 규칙 기반 최적화 방식으로 생성한 것이다.
5) 연산
연산(Operation)은 여러 가지 조작을 통해서 원하는 결과를 얻어내는 일련의 작업이다. 연산에는 조인 기법(NL Join, Hash Join, Sort Merge Join 등), 액세스 기법(인덱스 스캔, 전체 테이블 스캔 등), 필터, 정렬, 집계, 뷰 등 다양한 종류가 존재한다.
예시를 봐보자.
SELECT e.ename, e.job, e.sal, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND e.empno > 7800
AND EXISTS (SELECT 'x'
FROM salgrade sg
WHERE e.sal
BETWEEM sg.losal
AND sg.hisal)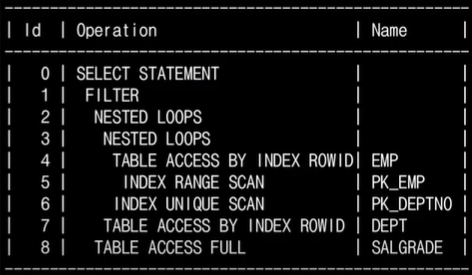
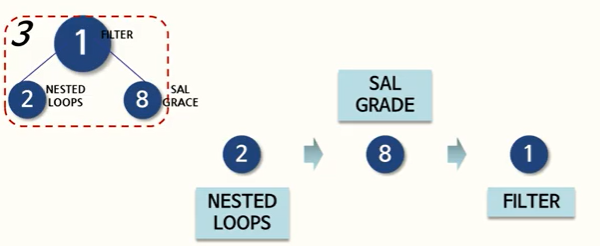
각 작업에 ID가 부여되고, 들여쓰기 깉이가 같은 작업을 찾으면 아래와 같이 트리 형태로 나타낼 수 있다. 주의할 점은 ⭐""해석은 가장 왼쪽 밑에서부터 시작해야 된다는 것이다!""
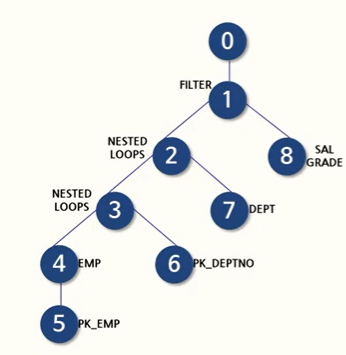
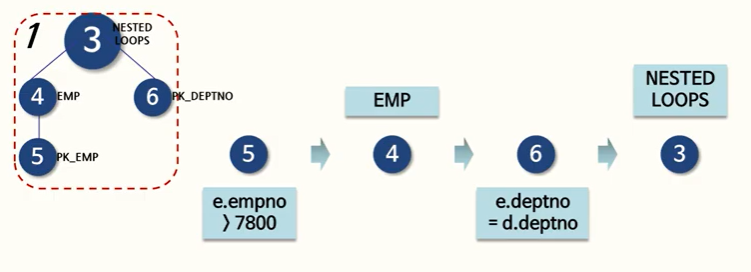
첫번째 파트를 봐보자.
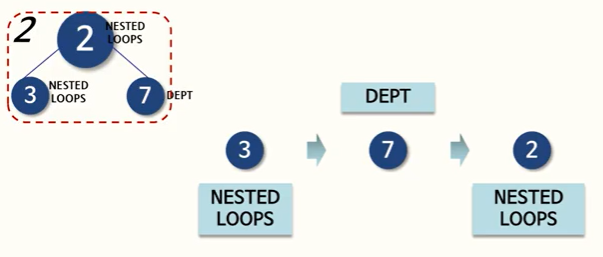
메인 쿼리 마지막인 두번째 파트를 봐보자.
세번째 파트는 서브 쿼리 부분이다.
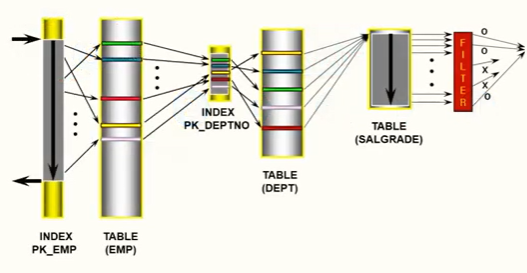
5️⃣ SQL 처리 흐름도
SQL 처리 흐름도(Access Flow Diagram)란 SQL 의 내부적인 처리 절차를 시각적으로 표현한 도
표이다. 즉, 이것은 실행계획을 시각화한 것이다.
성능적인 관점을 살펴보기 위해서 SQL 처리 흐름도에 일량을 함께 표시할 수 있다. 아래 그림과 같이 액세스 건수, 조인 시도 건수, 테이블 액세스 건수, 성공 건수를 함께 표시 할 수 있다.
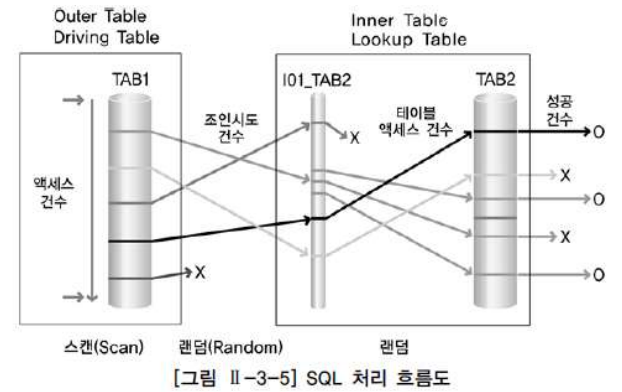
예를 들어, 아래 그림이 다음 SQL문에 대한 처리 흐름도라고 해보자.
SELECT …
FROM TAB1 A, TAB2 B
WHERE A.KEY = B.KEY #(2)
AND A.COL1 = :condition1 #(1)
AND B.COL2 = :condition2 #(3)조인을 할때 테이블 접근 순서는 A테이블 => B의 인덱스 테이블 => B테이블이 된다.
1)액세스 건수
SQL 처리를 위해 TAB1 을 액세스한 건수이다. 여기서는 TAB1 의 A.COL1 칼럼에 이용 가능한 인덱스가 존재하지 않아 전체 테이블 스캔을 수행하였기 때문에, 액세스 건수는 TAB1 테이블의 총 건수와 동일하다.
2)조인 시도 건수
TAB1 테이블에서 읽은 해당 건에 대해 A.COL1 = :condition1 조건을 만족한 건만이 TAB2 와 조인을 시도하게 된다. 따라서 조인 시도 건수는 TAB1 에 주어진 조건인 A.COL1 = :condition1 을 만족한 건수가 된다.
3)테이블 액세스 건수
B.KEY 칼럼만으로 구성된 인덱스인 I01_TAB2 에서 B.KEY = A.KEY 조건을 만족한 건만이 TAB2 테이블을 액세스한다. 즉, 조인 시도한 건들 중에서 B.KEY = A.KEY 조건 까지 만족한 건과 같다.
4)성공 건수
SQL 실행을 통해 사용자에게 답으로서 보여지는 결과 건수이다. TAB2 테이블을 액세스해서 B.COL2 = :condition2 조건까지 만족해야 비로서 사용자에게 보여질 수 있다
참고자료.
https://www.youtube.com/c/전광철OCP
SQLD 전문가 가이드
