
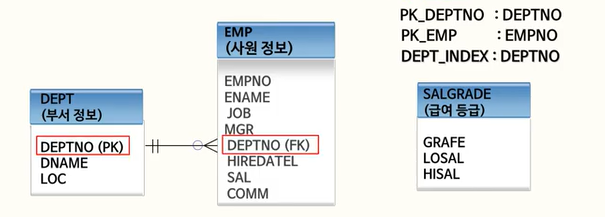
1️⃣ 표준 조인(ANSI JOIN)
표준 조인이란, FROM 절에서 table 사이에 바로 join을 명시적으로 정의하는 것을 말한다.
USING, ON 절등을 통해서 조인 조건을 기술 해줄 수 있다.
1) USING JOIN
조인할때 사용할 COLUMN을 지정해준다. 각 테이블이 공통으로 가지고 있는 COLUMN이어야 하며, COLUMN은 어디에서도 테이블 이름이나 별도로 별칭을 가질 수 없다.
SELECT e.ename, deptno, d.dename
FROM emp e
INNER JOIN dept d USING(deptno)
ORDER BY deptno, e.ename DESC;2) ON JOIN
각 테이블별 칼럼에 대해 구체적으로 조인 조건을 기술해준다. EQUAL 조인/ NOT-EQUAL 조인 둘다 가능하다.
SELECT a.col, b.col
FROM table1 a
INNER JOIN table2 b
ON (a.column = b.column);
# ON(e.sal BETWEEN s.losal AND s.hisal)3) OUTER JOIN
SELECT e.ename, e.sal, e.deptno, d.deptno, d.dname
FROM dept d
LEFT|RIGHT|FULL OUTER JOIN emp e
ON (e.deptno = d.deptno AND e.sal > 2000);4) CROSS JOIN
SELECT e.name, d.dname
FROM emp e
CROSS JOIN dept d;2️⃣ 집합 연산자
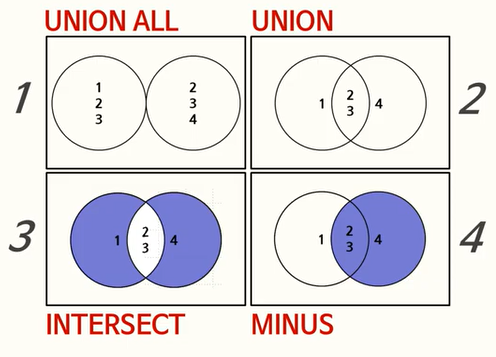
1)UNION(합집합) 구문
두 테이블을 하나로 만드는 연산이다.
👉주의사항은, 각 SELECT 문은 갖고 있는 컬럼의 순서, 개수, 데이터 타입(변환 가능)이 모두 같아야 성립이 된다는 것이다.
또한, 각 SELECT 문에 대해서 중복된 데이터의 여부에 상관없이 중복 데이터를 제거하기 때문에 정렬(SORT) 과정을 발생시키며, 첫번째 SELECT문이 갖고 있는 컬럼의 이름으로 출력 결과가 도출된다. (별칭 지정시, 첫번째 SELECT문에 대해서만 해줘도 가능)
💡 UNION ALL
UNION ALL도 두 테이블을 하나로 합치지만, UNION처럼 중복을 제거하거나 정렬을 유발하지는 않는다.
SELECT column_list
FROM table
[WHERE conditions]
UNION
SELECT column_list
FROM table
[WHERE conditions]
[ORDER BY columns [ASC|DESC];2)INTERSECT(교집합) 구문
각 SELECT 문이 갖고 있는 교집합에 대해서만 처리하기 때문에, 중복 데이터 처리가 수행된다.
SELECT column_list
FROM table
[WHERE conditions]
INTERSECT
SELECT column_list
FROM table
[WHERE conditions]
[ORDER BY columns [ASC|DESC];INTERSECT 구문은 INNER JOIN과 같은 연산 결과를 도출한다. 단, DISTINCT를 이용해 중복된 데이터를 제거해줘야 한다.
SELECT DISTINCT tb1.id
FROM tb1
INNER JOIN tb2
ON (tb1.id = tb2.id);3)MINUS(차집합) 구문
두 테이블에서 차집합을 조회하는 연산이다. 첫번째 SELECT문에서 추출한 결과로부터 두번째 SELECT문에서 추출한 결과를 제거한다. 따라서, 두 SELECT문 사이에 중복된 데이터가 제거된다.
SELECT column_list
FROM table
[WHERE conditions]
MINUS
SELECT column_list
FROM table
[WHERE conditions]
[ORDER BY columns [ASC|DESC];MINUS 구문은 OUTER JOIN과 같은 결과를 도출한다. 단, WHERE 조건에 NULL 조건을 추가해야한다.
SELECT DISTINCT tb1.id
FROM tb1
LEFT OUTER JOIN tb2
ON (tb1.id = tb2.id)
WHERE tb2.id iS NULL;3️⃣계층형 질의와 셀프 조인
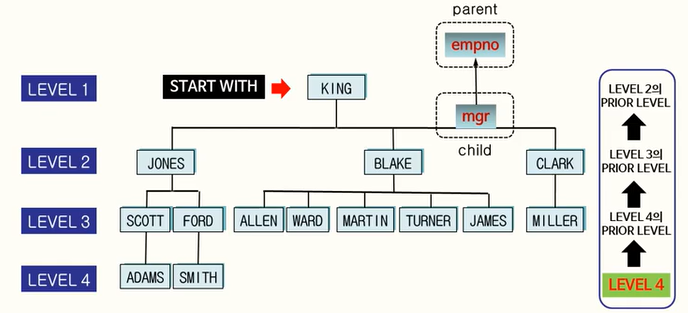
계층형 조회에는 CONNECT BY 질의를 사용한다. CONNECT BY는 ⭐트리(Tree) 형태의 구조로 쿼리를 실행한다.
SELECT ~, [LEVEL, CONNECY_BY_ISLEAF]
FROM table
[WHERE conditions]
START WITH condition
CONNECY BY [NOCYCLE] PRIOR conditions
[ORDER SIBILNGS BY column1, ...]START WITH구는 시작 조건(각 계층의 시작점)을, CONNECT BY PRIOR는 조인 조건(각 레벨 간 연결)을 의미한다. PRIOR는 각 하위 레벨의 직전 상위 레벨을 나타내는 값이다.
이렇게 루트 노드부터 하위 노드의 질의를 실행하며, LEVEL은 1로 시작해 하위 레벨로 갈 수록 2,3,4 등 값이 커지게 된다.
각 계층에 있어서 마지막 레벨인지 알고 싶을때는, CONNECT_BY_ISLEAF를 사용하면 된다. CONNECT_BY_ISLEAF는 마지막 레벨이면 1, 그렇지 않으면 0 값이 주어진다.
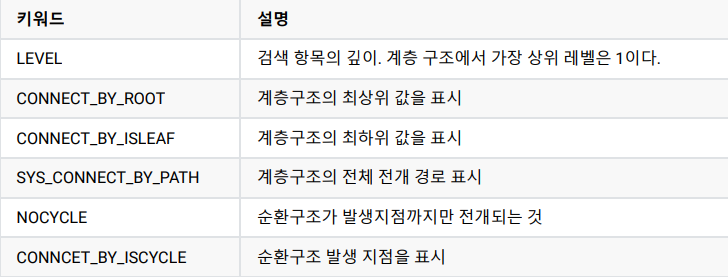
EX) 예시를 들어 자세히 알아보자.
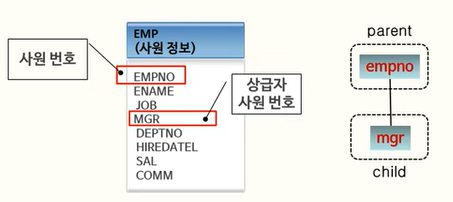
EMP 테이블의 칼럼인 mgr과 empno에 대해 mgr을 "parent", empno를 "child"와 같이 구분했다.(그림이 잘못 되었다..!!!)
mgr (parent)
↓ ↑
empno (child)
여기서 ↓ top-down을 순방향 전개라고 하며 ↑ bottom-up을 역방향 전개라고 부른다.
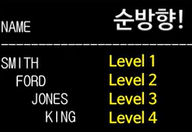
1) 순방향 계층 조회
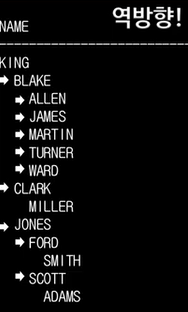
그림에서 역방향 -> 순방향
SELECT LPAD(' ', 2* (LEVEL - 1)) || ename as name
FROM emp
START WITH ename = 'KING'
CONNECT BY PRIOR empno = mgr #PRIOR 자식 = 부모
ORDER SIBLINGS BY ename ASC ;각 LEVEL이 갖는 EMPNO 정보는, PRIOR LEVEL의 MGR과 일치할 것이기 때문에 PRIOR empno = mgr이 된다.
💡 LPAD()
계층형 조회 결과를 명확히 보기 위해 사용한다.
ex. LPAD(' ', 4): 왼쪽 공백 4칸을 화면에 찍어 트리 형태처럼 출력
ex. LPAD(' ', 2* (LEVEL - 1)) : 각 계층 마다 왼쪽으로 공백 2칸을 화면에 찍어 출력
2)역방향 계층 조회
아래와 같은 결과를 나타내기 위해서는, 다음과 같이 질의를 작성해주면 된다.(그림에서 순방향 -> 역방향)
SELECT LPAD(' ', 2 * (LEVEL - 1)) || ename as name
FROM emp
START WITH ename = 'SMITH'
CONNECT BY PRIOR mgr = emp; #PRIROR 부모 = 자식각 LEVEL이 갖는 MGR 정보는, PRIOR LEVEL의 EMPNO와 일치할 것이기 때문에, PRIOR mgr = emp가 된다.
3)셀프 조인 사용
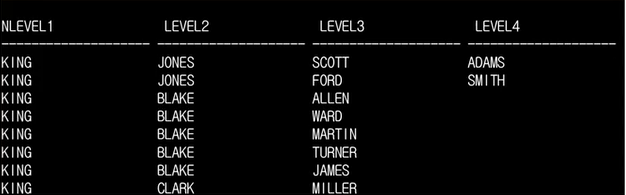
SELECT t1.ename as level1,
nvl(t2.ename, '') level 2,
nvl(t2.ename, '') level 3,
nvl(t2.ename, '') level 4
FROM emp t1
LEFT OUTER JOIN emp t2 ON (t1.empno = t2.mgr)
LEFT OUTER JOIN emp t3 ON (t2.empno = t3.mgr)
LEFT OUTER JOIN emp t4 ON (t3.empno = t4.mgr)
WHERE t1.ename = 'KING'
ORDER BY t1.empno, t2.empno, t3.empno;🧐가장 마지막 계층(하위 레벨)의 정보를 탐색하려면?
CONNECT BY 구문을 사용하면 CONNECT_BY_ISLEAF = 1을 사용하면 되지만, 예시에서는 CONNECT BY 구문을 사용하지 않고 SELF JOIN을 통해 탐색해볼것이다.

SELECT t1.ename as name
FROM emp t1
LEFT OUTER JOIN emp t2
ON (t1.empno = t2.mgr)
WHERE t2.ename IS NULL; //하위 레벨 테이블에 대해 연결했을때 NULL이 되는 데이터