
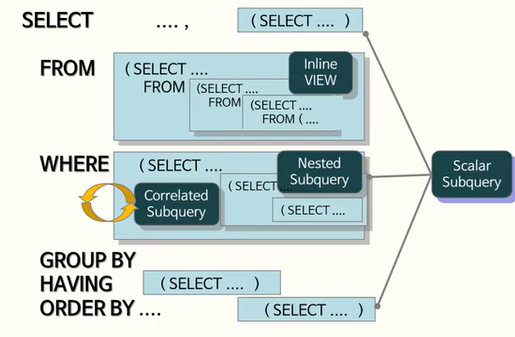
1️⃣서브 쿼리의 종류
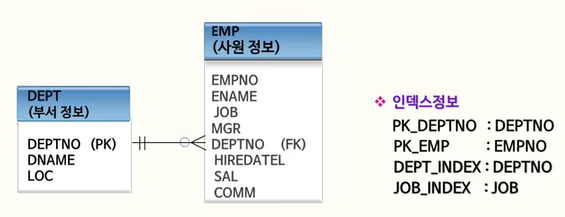
다음은 예시에 사용할 테이블과 인덱스이다.
2️⃣NESTED 서브 쿼리
메인 쿼리와는 별개로, 서브 쿼리 자체가 먼저 실행 가능한 유형이다. 서브 쿼리가 먼저 실행되어 데이터를 읽어들이고, 조건으로 해서 메인 쿼리가 실행된다.
SELECT
e.empno, e.ename
FROM emp e
WHERE e.deptno IN (SELECT d.deptno
FROM dept d
WHERE d.dame = 'SALES');서브 쿼리가 동작됨에 있어서 사용할 수 있는 인덱스가 없기에, 한건의 데이터를 읽어들인다. 이 읽어들인 데이터를 조건으로 하는 메인은 인덱스가 사용되므로,
쿼리에 대한 실행 계획이다.
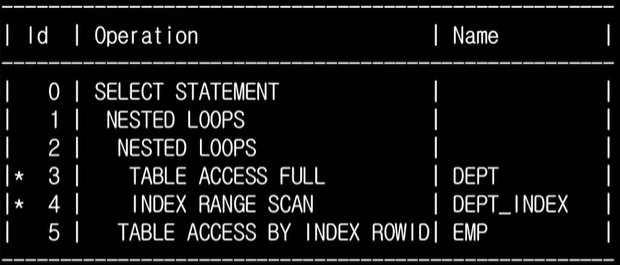
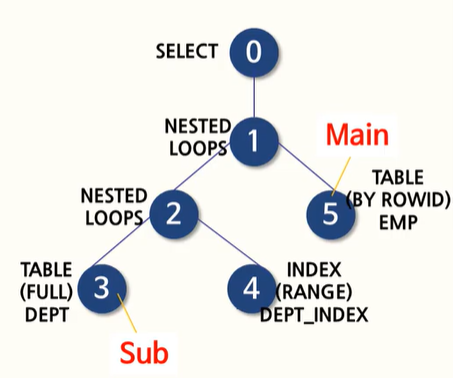
서브쿼리에서 결과를 읽어들이면서, 그 결과를 조건으로 하는 메인은 인덱스가 사용된다. 따라서, 서브 쿼리에 대한 데이터를 읽는 부분이 3번, 인덱스 사용을 나타내는게 4번이 된다(3->4 순으로 해석).
✅다중 행 서브 쿼리
다중행 서브 쿼리란, 읽어들인 데이터가 2개 이상 일때를 의미한다. 참고로 서브 쿼리의 결과가 다중 행일경우, 메인 쿼리와 조인을 하게 된다.
1)IN 서브쿼리
IN 서브쿼리는, 서브쿼리로 읽어들인 데이터들의 목록에 포함된다는 것을 나타낸다. 즉, 데이터들에 각각 EQUAL 을 사용한 의미와 같다.
2)ALL 서브쿼리
>ALL은 서브쿼리로 읽어들인 목록 중 "최댓값"보다 크다는 의미이다.
<All은 서브쿼리로 읽어들인 목록 중 "최솟값"보다 작다는 의미이다.
3)ANY 서브쿼리
>ANY는 서브쿼리로 읽어들인 목록 중 "최솟값"보다 크다는 의미이다.
<ANY는 서브쿼리로 읽어들인 목록 중 "최댓값"보다 작다는 의미이다.
=ANY는 IN 서브쿼리와 동일한 의미이다.
✅ NESTED 서브 쿼리 예제
1) ANY와 MIN
SELECT ename, sal, job
FROM emp
WHERE job != 'SALESMAN'
AND sal > ANY (SELECT sal
FROM emp
WHERE job = 'SALESMAN');서브 쿼리의 3건의 데이터와, 메인에 있는 테이블에 조인이 행해진다. 하지만, 조인에 사용할 연산자가 !=이므로 해시 조인은 불가능하며 조인에 사용할 컬럼인 sal에 인덱스가 없어서 NL도 불가능하므로 SM 조인이 수행되게 된다.
아래의 그림은 실행계획과 도식도를 나타낸 것이다.
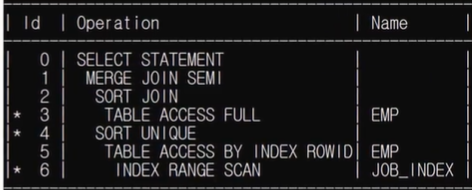
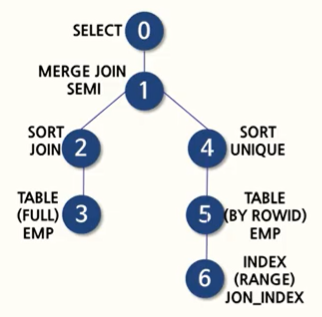
ANY는 값의 목록 중 최솟값보다 크다는 뜻이므로, 아래와 같이 변경해도 결과값은 같지만 서브 쿼리 결과가 단행이므로 ⭐조인이 발생하지 않고 서브쿼리 데이터를 조건으로 메인 쿼리가 동작되는 특징이 있다. 따라서 메인 쿼리가 동작될때는, FULL TABLE SCAN이 될 것이다.(!= 과 sal 칼럼에 인덱스가 존재하지 않으므로)
SELECT ename, sal, job
FROM emp
WHERE job != 'SALESMAN'
AND sal > (SELECT MIN(sal)
FROM emp
WHERE job = 'SALESMAN');아래는 실행계획과 도식표이다.
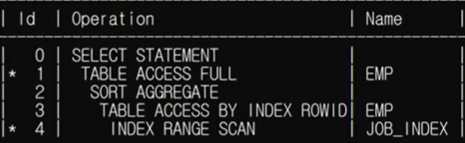
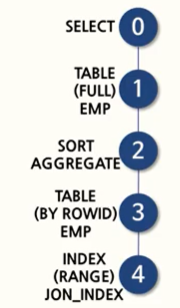
서브쿼리가 먼저 실행될때, job 칼럼에 인덱스가 있었기 때문에 인덱스 사용을 통해 테이블로 액세스를 하고, MIN값을 구해야 하기 때문에 SORTING이 일어나게 된다. 이후 그 조건을 가지고 메인에서 데이터를 찾게 되는 것이다(인덱스 사용 X).
2) ALL과 MAX
SELECT ename, sal, job
FROM emp
WHERE job != 'SALESMAN'
AND sal > ALL (SELECT sal
FROM emp
WHERE job = 'SALESMAN');ANY는 읽어들인 데이터 중 하나라도 최종 값의 목록에 포함되므로 긍적적이지만, ALL은 읽어들인 값의 목록 전체가 출력 값에 포함될 수 없으므로 부정적이므로 nt 조인이 실행된다.
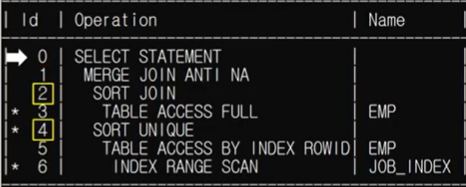
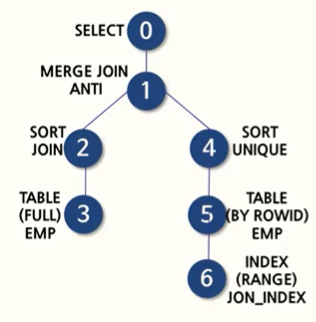
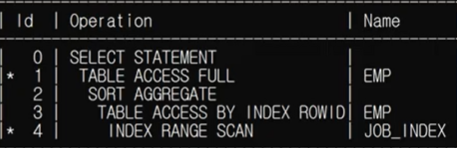
ALL도 마찬가지로, MAX()로 대체하게 되면 조인을 사용하지 않고 서브 쿼리의 결과값을 조건으로 메인 쿼리를 결과값을 찾게 된다.
✅ Multiple column(다중 열) 서브 쿼리
서브 쿼리 결과 값으로 2개 이상의 칼럼을 사용하는 것을 의미한다. 서브 쿼리의 비교 방식은 아래와 같이 2가지가 존재한다.
1)NON-PAIRWISE 비교
SELECT ename, mgr, deptno
FROM emp
WHERE mgr IN (SELECT mgr
FROM emp
WHERE ename IN ('FORD', 'BLAKE'))
AND deptno IN (SELECT deptno
FROM emp
WHERE ename IN ('FORD', 'BLAKE'))
AND ename NOT IN ('FORD', 'BLAKE');서브쿼리로 사용하고자 하는 칼럼 2가지를 각각 읽어들이고 나서, 메인 쿼리와 비교하는 것을 NON-PAIRWISE 비교라고 한다. 또한 메인 쿼리와 서브 쿼리 간의 조인이 발생하게 된다.
1)첫번째 서브쿼리는 비교되는 칼럼의 인덱스가 없으므로 SM/HASH 조인만 가능하다. 2)두번째 서브쿼리는 비교되는 칼럼의 인덱스가 있으므로 세가지 조인 방식이 다 가능하다. 다만, 얼마 안되는 데이터라면 NL 조인이 선택될 가능성이 높다.
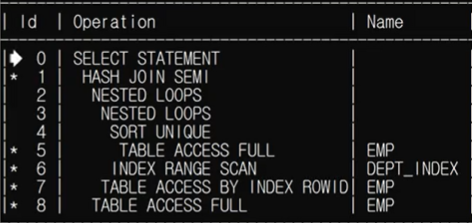
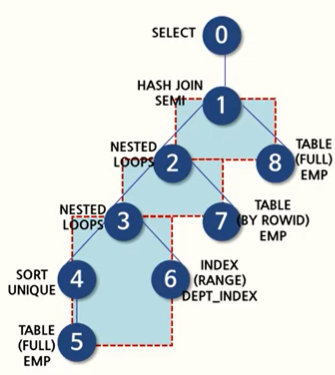
2)PAIRWISE 비교
SELECT ename, mgr, deptno
FROM emp
WHERE (mgr, deptno) IN (SELECT mgr, deptno
FROM emp
WHERE ename IN ('FORD', 'BLAKE'))
AND ename NOT IN ('FORD', 'BLAKE');사용할 컬럼 2가지를 하나의 서브 쿼리로 해결하는 것을 PAIRWISE 비교라고 한다. 즉, 하나의 서브쿼리에서 매니저와 부서를 동시에 읽어들이고 있다. 또한, deptno 컬럼에 인덱스가 있고 처리할 데이터의 양이 적으므로 NL 조인이 사용될 가능성이 높다.
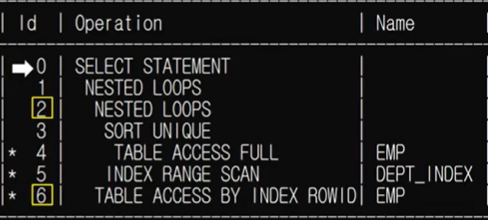
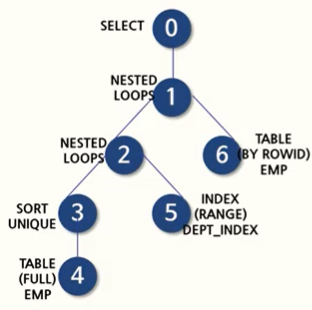
이 예제는 앞의 NON-PAIRWISE를 통한 쿼리와 다른 결과값을 나타나게 된다. 매니저와 부서 정보가 한 쌍식 짝으로 제공되었기 때문이다.
3️⃣ CORRELATED 서브 쿼리
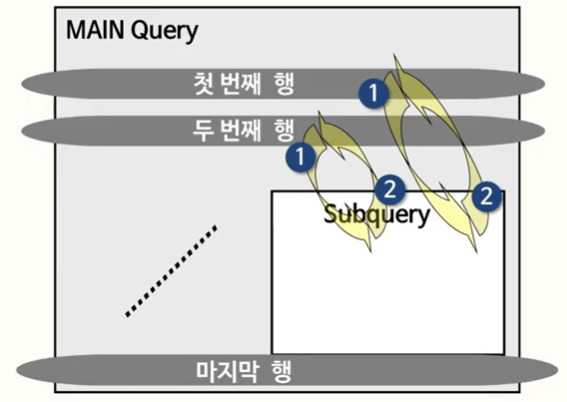
상호연관 서브쿼리란, 서브쿼리에서 갖고 있는 where 절에서 메인 테이블의 컬럼을 조건으로 사용하고 있는 쿼리를 말한다.
그로 인해 1)메인에서 데이터를 먼저 찾고, 2)조건으로 사용될 컬럼의 데이터를 서브쿼리로 넘겨준 후 3)서브쿼리가 처리한 데이터를 다시 메인에 넘겨주게 된다.
예제와 그에 따른 실행계획을 봐보자.
SELECT /*+ QB_NAME(main) */ e.empno, e.ename
FROM emp e
WHERE EXISTS (SELECT /*QB_NAME(sub) NO_UNNEST */ 1
FROM dept d
WHERE d.deptno = e.deptno
AND d.dname = 'SALES');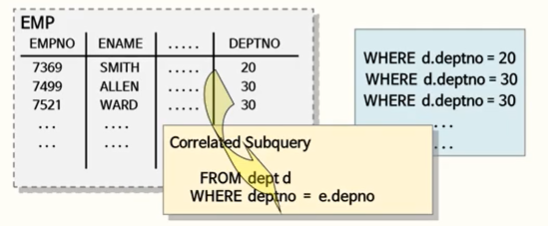
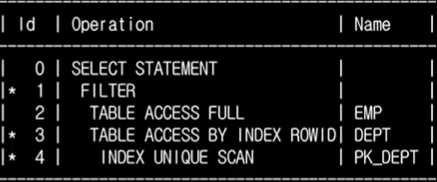
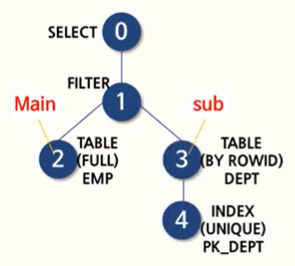
2 -> 3 -> 4 -> 1 순서로 해석이 된다. CORRELATED 서브쿼리에서는 1)서브쿼리가 반복적으로 수행되게 되는 FILTER 이나, 2)JOIN 둘중에 하나게 선택되게 된다.
예를 들어, JOIN 이 선택된 예시를 봐보자.
SELECT d.deptno, d.dname
FROM dept d
WHERE NOT EXISTS
(SELECT 'x'
FROM emp e
WHERE e.deptno = d.deptno);메인과 서브 쿼리 간의 NESTED LOOPS ANTI 조인이 수행되고 있음을 알 수 있다.
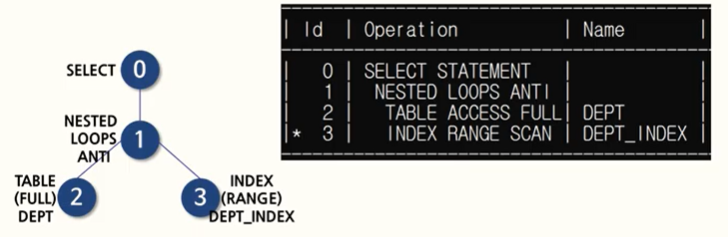
💡 EXISTS 연산자
단순히 데이터가 존재하는지 찾고자 할때 사용하는 연산자이다. ⭐조건을 만족하는 최초의 데이터가 찾아지면, 해당 작업을 끝내므로 단 한 건만 확인하는 선에서 작업을 수행하게 된다. 주의할점은, 서브쿼리에 count(*) 를 쓰게 되면 EXISTS를 사용할 이유가 없어지니 문자 리터럴을 사용하는 것을 권장한다!SELECT 1 FROM dual WHERE EXISTS (SELECT 'x' //문자 리터럴 FROM emp e WHERE deptno = 30);
💡 SEMI/ANTI 조인
서브 쿼리를 사용할때 이를 메인 쿼리와 연결하기 위해 적용되는 조인을 의미한다.
1)=,IN,EXISTS등과 같이 긍정 : SEMI
2)!=,NOT IN,NOT EXISTS등과 같이 부정 : ANTI
4️⃣ SCALAR 서브 쿼리
SELECT 문에 서브쿼리를 사용하는 방식을 스칼라 서브쿼리라고 한다.
한번에 리턴할 수 있는 최대 칼럼 개수(데이터)가 하나이고, 데이터가 없을 경우 NUll 값을, 두건 이상의 데이터를 찾게 하는 경우는 에러를 발생시킨다.
스칼라 서브쿼리는 한번 읽은 데이터는 캐시에 올려놓기 때무에, 후에 필요할때 재활용할 수 있다는 장점이 있다. 하지만 그만큼 메모리 자원을 사용하기 때문에 메인에서 찾은 데이터가 많은 경우 자원 사용량이 많아질 수 있다는 단점이 존재한다.
SELECT e.empno, e.ename, d.dname
FROM emp e JOIN dept d
ON (e.deptno = d.deptno);위의 sql문을 아래의 scalar 서브 쿼리로 바꿔보면 다음과 같다.
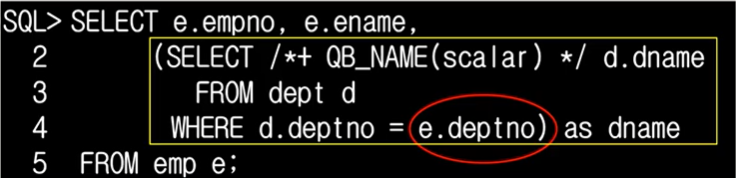
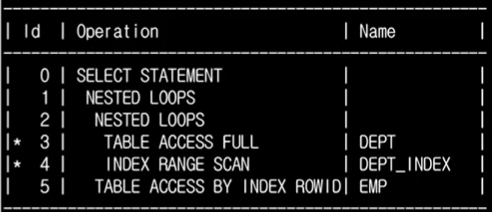
메인 에서 데이터를 읽어 조건으로 하는 칼럼에 값을 전달해야만 동작되기 때문에 왼쪽부터 읽으면 안된다.(서브쿼리 스스로 실행 X)
5️⃣ INLINE VIEW
다음과 같은 작업을 순서에 따라 수행하려고 한다. 이때, 인라인뷰를 사용할 수 있다(FROM 절).
- 직종별로, 평균 급여를 구한다.
- 개인 급여 > 평균 급여인 사원을 찾는다.
- 10%를 초과하는 사원은 5% 차감한다.
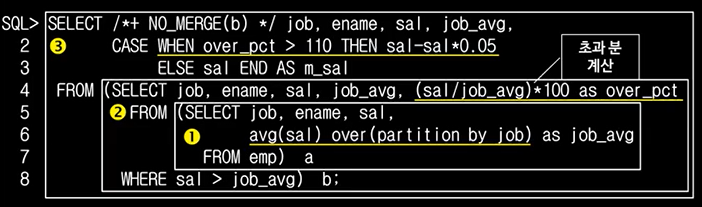
실행계획과 도식표이다. 뷰가 2차례 나타난 것을 볼 수 있다.
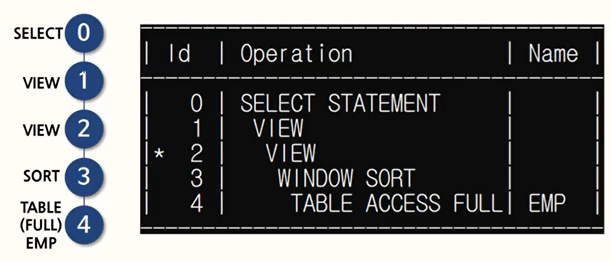
하지만 뷰를 사용하는 sql을 변경하여, 뷰에서 이용하는 base 테이블을 직접 액세스 하는 문장으로 변환되는 현상인 View Merge 현상이 일어날 수 있다. 이때, ORACLE의 경우 /**NO_MERGE(view_name)*/ 를 추가해주면 된다.
💡 View Merge 방지 위한 키워드
1) rownum
2) Select list에 그룹 함수(sum, avg, max, min, count etc..)
3) Set 연산자(union, all etc..)
4) ORDER BY, GROUP BY, DISTINCT
5) CONNECT BY
