
1️⃣ 인덱스를 사용하지 못하는 경우
1)NOT 연산자
SELECT empno, ename, job FROM emp
WHERE empno != 7900;SELECT empno, ename, job FROM emp
WHERE empno NOT IN (7654, 7788);SELECT ename, job FROM emp
WHERE job NOT LIKE 'SALES%';2)NULL 연산자
SELECT empno, ename, job FROM emp
WHERE empno IS [NOT] NULL;B-Tree 인덱스는 널값을 저장하지 않기 때문에, 갖지 않는 정보가 됨으로써 인덱스를 사용할 필요가 없어진다.
3)External Supperssing
external supperssing이란, 인덱스를 구성하는 컬럼에 변형을 취함으로써, 해당 인덱스를 사용하지 못하게 하는 것을 의미한다.
SELECT ename, job FROM emp
WHERE SUBSTR(ename, 1, 1) = 'J';4)Internal Suppressing
Internal Supperssing은 서로 다른 데이터 타입끼리 비교할때 해당 인덱스를 사용하지 못하게 되는 것을 의미한다.
SELECT empno, ename, job FROM emp
WHERE empno LIKE '78*';empno는 숫자 타입이기 때문에, 컬럼의 데이터 타입이 문자로 전환되게 된다.
2️⃣ 결합 인덱스
결합 인덱스 컬럼의 선정 기준은 다음과 같다.
💡 컬럼 선정 기준
1) Where 절에서 AND 조건으로 자주 결합되어 사용되며, 각 칼럼의 분포도보다 2개 이상의 칼럼이 결합될때 분포도가 좋아지는 칼럼들2) 다른 테이블과 조인을 위한 연결고리로 자주 사용되는 칼럼들
결합 인덱스 칼럼 순서 결정은 다음과 같다.
💡 컬럼 순서 결정
1) Where 절 조건에 많이 사용되는 칼럼 우선
2) 주로 Equal을 사용하는 칼럼 우선
3) 분포도가 좋은 칼럼 우선
4) 자주 이용되는 order by절의 순서를 반영
급여IDX가 (연월, 급여코드, 사원번호) 다음과 같다 했을때, 결합 인덱스의 첫번째 컬럼이 정상적인 조건으로 WHERE절에 있는 한 결합 인덱스를 사용 가능_ 하다.
WHERE 연월 = '202011';WHERE 연월 = '202011'
AND 급여코드 = '정기급여';아래는 결합인덱스를 사용 불가능한 예시이다. WHERE절에 첫번째 칼럼이 주어지지 않거나, 첫번째 칼럼의 인덱스를 사용하지 못하는 조건이 주어지는 경우이다.
WHERE 연월 != '202110'
AND 급여코드 = '정기급여';INDEX SKIP SCANNING
만약, 결합 인덱스의 첫 번째 칼럼에 대한 조건이 범위를 좁히기에 적합하지 않거나 where 절에서 제외된 경우에도 결합 인덱스를 사용할 수 있게 하는 방법이다. 아래 세가지 힌트를 사용해 강제적으로 SKIP SCANNING을 유도할 수 있다.
Skip Scanning을 위한 힌트
1) INDEX_SS (tab명 idx 명)
2) INDEX_SS_ASC (tab명 idx 명)
3) INDEX_SS_DESC (tab명 idx 명)
'=' 조건이 미치는 영향
#인덱스: (col1, col2)
WHERE col1 between 111 and 113
AND col2 = 'A';먼저 1)between에 의해 범위가 결정되고, 검색 중에 2)A가 되는 데이터만 추출한 후 범위에서 벗어나면 마무리가 된다. 따라서 COL2에 대한 '='는 범위를 좁히지는 못하고 단지 해당 조건을 만족하는지 확인하는 용도로만 사용되는 것을 볼 수 있다.
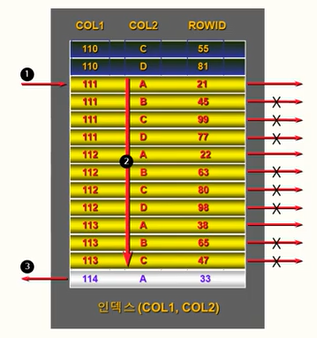
하지만 다음과 같이 IN으로 수정하게 되면 의미가 달라진다.
#인덱스: (col1, col2)
WHERE col1 IN (111, 112, 113)
AND col2 = 'A';먼저 1)범위에 속한 값들을 나열시키고 각 값들마다 2)해당 조건에 맞는 컬럼을 선택한다. 즉, 두 칼럼에 대한 '='를 모두 사용해서 범위를 좁히는데 사용되는 것을 볼 수 있으며 이런 경우 성능이 좋은 SQL문이 된다.
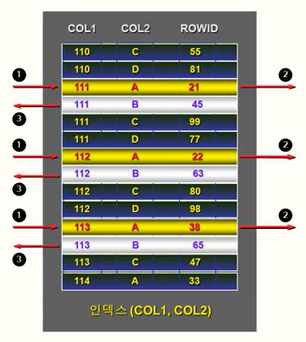
3️⃣ 인덱스 생성과 스캔
1)인덱스 생성
인덱스를 생성할 때는 한 개 이상의 칼럼을 사용해서 생성할 수 있다.
키는 기본적으로 오름차순으로 정렬하고, 'DESC' 구를 포함하면 내림차순으로 정렬할 수 있다.
CREATE INDEX IND[명] EMP[테이블명] ON EMP (ENAME ASC, SAL DESC);2)인덱스 스캔
인덱스 스캔은, 인덱스를 구성하는 칼럼의 값을 기반으로 데이터를 추출하는 액세스 기법이다.
검색을 위해 인덱스의 리프 블록을 읽으면, 인덱스 구성 칼럼의 값과 테이블의 레코드 식별자를 알 수 있다. 만약 인덱스에 존재하지 않는 칼럼의 값이 필요한 경우에는 현재 읽은 레코드 식별자를 이용하여 테이블을 액세스해야 한다.
👉따라서, SQL 문에서 필요로 하는 모든 칼럼이 인덱스 구성 칼럼에 포함된 경우 테이블에 대한 액세스는 발생하지 않는다.
💡인덱스 정렬 방법
인덱스는, 인덱스 구성 칼럼의 순서로 정렬되어 있기 때문에 ⭐인덱스를 경유하여 데이터를 읽으면 그 결과 또한 정렬되어 반환된다.
ex) A+B 라면 칼럼 A 정렬 => 칼럼 A의 값이 동일할 경우에는 칼럼 B 정렬 => 칼럼 B 까지 모두 동일할시 레코드 식별자로 정렬
인덱스 스캔에는 아래와 같이 3가지 방법이 존재한다.
2-1) 유일 스캔(Index Unique SCAN)
유일 인덱스(Unique Index)를 사용하여 단 하나의 데이터를 추출하는 방식이다.
인덱스 유일 스캔은 유일 인덱스 구성 칼럼에 대해 모두 ‘=’로 값이 주어진 경우에만 가능하다.
SELECT * FROM EMP WHERE EMPNO = 100;2-2) 범위 스캔(Index Range SCAN)
인덱스 범위 스캔은 인덱스를 이용하여 한 건 이상의 데이터를 추출하는 방식이다.
즉 Leaf Block의 특정 범위를 스캔한 것으로, SELECT문에서 특정 범위를 조회하는 WHERE문
을 사용할 경우 발생된다.
ex) Like, Between
물론, 데이터 양이 적은 경우는 자체를 실행하지 않고 TABLE FULL SCAN이 될 수 있다.
💡 TABLE FULL SCAN
인덱스를 사용하지 않고 테이블에 존재하는 모든 블록의 데이터를 읽는다. 즉, 한번에 여러개의 data block을 동시에 읽는다.
이렇게 읽은 블록들은 재사용성이 떨어지기 때문에, 전체 테이블 스캔 방식으로 읽은 블록들은 메모리에서 곧 제거될 수 있도록 관리된다.show parameter db_file_multiblock_read_count #한꺼번에 얼마나 읽을것인지 확인SELECT EMPNO FROM EMP WHERE EMPNO >= 100;
2-3) 전체 스캔(Index Full SCAN)
검색되는 키가 많은 경우에 Leaf Block의 처음부터 끝까지 전체를 읽어 들이는 방식이다.
SELECT ENAME, SAL FROM EMP WHERE ENAME Like '%' AND SAL > 0;