
☁️ 동시성 프로그래밍의 역사
1. 릴리스
스레드, 동기화, wait/notify를 지원했다.
wait: 갖고 있던 고유 락을 해제하고, 스레드를 잠들게 한다.notify:잠들어 있던 스레드 중 임의로 하나를 골라 깨운다.
2. 자바 5 이후
동시성 컬렉션인 java.util.concurrent 라이브러리와 실행자(Executor) 프레임워크 지원했다.
3. 자바 7 이후
고성능 병렬 분해 프레임워크인 포크-조인(fork-join) 패키지를 추가했다.
4. 자바 8 이후
parallel 메서드만 한 번 호출하면 파이프라인을 병렬 실행할 수 있는 스트림을 지원했다.
이처럼 동시성 프로그램을 작성하기 점점 쉬워지고 있지만, 동시성 프로그래밍을 할때는 항상 안전성(safety)와 응답 가능(liveness) 상태를 유지 해야 하는 것에 주의해야 한다.
☁️ 동시성 프로그래밍 주의점
1. 스트림 병렬화를 사용하면 안되는 경우
public class ParallelMersennePrimes {
public static void main(String[] args) {
primes().map(p -> TWO.pow(p.intValueExact()).subtract(ONE))
.parallel() // 스트림 병렬화
.filter(mersenne -> mersenne.isProbablePrime(50))
.limit(20)
.forEach(System.out::println);
}
static Stream<BigInteger> primes() {
return Stream.iterate(TWO, BigInteger::nextProbablePrime);
}
}무작정 성능을 향상시키기 위해 parallel() 를 사용하면, 위와 같이 아무것도 출력하지 못하면서 CPU는 90% 나 잡아먹는 상태가 무한히 계속되는 문제가 발생할 수 있다. 스트림 라이브러리가 이 파이프라인을 병렬화하는 방법을 찾아내지 못했기 때문이다.
🔖 파이프라인 병렬화로 성능 개선을 할 수 없는 경우
1. 데이터 소스가Stream.iterate인 경우
2. 중간 연산으로limit을 사용하는 경우
스트림 병렬화 + forEach
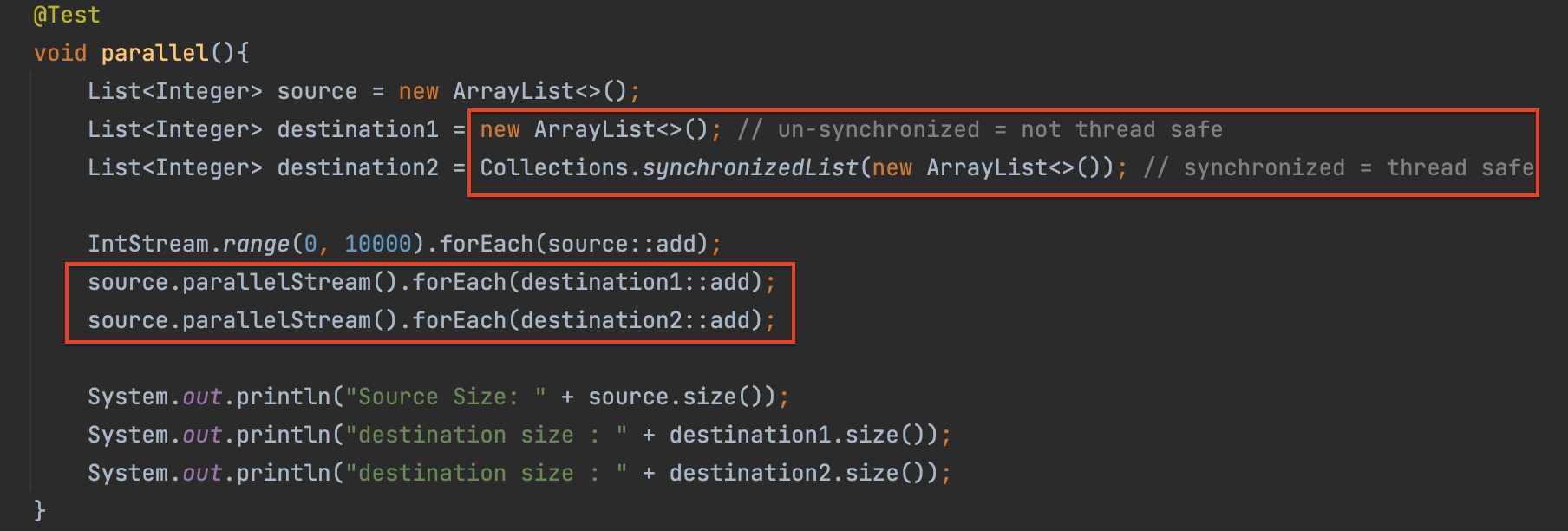

☁️ 스트림 병렬화는 어떤 경우 사용해야 할까
대체로 스트림의 소스가 ArrayList, HashMap, HashSet, ConcurrentHashMap의 인스턴스거나 배열, int 범위, long 범위일 때 병렬화의 효과가 가장 좋다.
해당 자료구조들은 아래와 같은 두 가지 공통점을 지닌다.
1. 정확성
모두 데이터를 원하는 크기로 정확하고 손쉽게 나눌 수 있어 다수의 스레드에 일을 분배하기에 좋다. 나누는 작업은 Spliterator 를 통해 이루어지며, Iterable 과 Stream 에서 얻을 수 있다.
2. 참조 지역성(locality of reference)
참조 지역성은, 다음과 같이 세가지로 나누어진다.
- 시간 지역성 : 최근에 참조된 주소는 빠른 시간 내에 다시 참조되는 특성
- 공간 지역성 : 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
- 순차 지역성 : 데이터가 순차적으로 엑세스 되는 특성(공간 지역성)
🔖 참조 지역성
1.높음: 이웃한 원소의 참조들이 메모리에 연속해서 저장되어 있는 경우
2.낮음: 참조들이 가리키는 실제 객체가 메모리에서 서로 떨어져 있는 경우
참조 지역성은, 요청할 데이터를 캐시 메모리에서 찾을 확률인 Cache Hit Rate 과도 비례한다. 참조 지역성이 높으면 캐시에서 데이터를 바로 찾을 수 있으므로 속도가 빨라지지만, 낮다면 주 메모리에서 캐시로 다시 로드하는 과정이 필요하기 때문에 성능이 낮아진다.
기본 타입의 배열과 같은 경우, 데이터 자체가 메모리에 연속해서 저장되기 때문에, 참조 지역성 중에서도 공간 지역성이 좋아 Cache Hit Rate 이 가장 높다.
ArrayList 나 Hash 자료구조 또한 내부적으로 배열(해시 테이블)을 사용하기 때문에, 참조 지역성이 높다.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table;
}결론적으로, 다량의 데이터를 처리하는 벌크 연산을 병렬화 할 때는 반드시 참조 지역성을 고려하도록 하자.
☁️ 종단 연산과 병렬화
종단 연산에서 수행하는 작업량이 파이프라인 전체 작업에서 상당 비중을 차지하면서 순차적인 연산이라면, 파이프라인 병렬 수행의 효과가 떨어진다.
적합한 종단 연산
파이프라인에서 만들어진 원소를 하나로 합치는 작업으로, 비교적 간단한 연산들이 적합하다.
reduceanyMatch,allMatch,noneMatch
나쁜 종단 연산
collect 와 같이 컬렉션들을 합치는 부담이 큰 메서드는 병렬화에 적합하지 않다.
📚 핵심 정리
parallel stream의 오버헤드가stream보다 훨씬 크기 때문에, 이를 뛰어 넘을 정도로 병렬 처리가 효율적인 작업인 경우(ex) 빅데이터) 테스트를 해보고 사용하도록 하자.
