
☁️ 상속의 위험성
같은 패키지의 부모 클래스를 확장하는 상속은 코드를 재사용하는 강력한 수단이지만, 다른 패키지의 클래스를 상속하는 일은 위험하다.
왜냐면, 메서드 호출과 달리 상속은 캡슐화를 깨뜨릴 수 있기 때문이다.
🔖 캡슐화란?
데이터(필드)와 해당 데이터를 처리하는 행위(메서드)를 한 곳에 묶고 자세한 동작 방식을 외부로 드러내지 않는 것을 의미한다. 중복 코드를 줄일 수 있고, 그로 인해 당연하게 기능이 추가되거나 로직이 변경될 때 변경 전파를 막을 수 있다.
자세히 말하자면 확장을 충분히 고려하지 않고 문서화도 해놓지 않은, 즉 릴리스마다 내부 구현이 달라질 수 있는 상위 클래스를 상속받았을 경우 하위 클래스가 오동작할 수 있다. 예시를 봐보자.
☁️ 하위 클래스가 깨지는 경우
1. 자기사용(self-use)의 경우
성능을 높이기 위해, 처음 생성된 이후 원소가 몇 개 더해졌는지 알 수 있도록 변수와 접근자 메서드를 추가해야하는 상황을 가정해보자. 당연히 처음에는 HashSet 을 상속받고 필드를 추가해 구현할 것이다.
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0; // 추가된 원소 개수
public InstrumentedHashSet() {
}
public InstrumentedHashSet(int initCap, float loadFactor) {
super(initCap, loadFactor);
}
@Override public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
}그리고 아래와 같이 클래스 인스턴스에 원소 3개를 더했다.
public static void main(String[] args) {
InstrumentedHashSet<String> s = new InstrumentedHashSet<>();
s.addAll(List.of("틱", "탁탁", "펑"));
System.out.println(s.getAddCount()); // 6이 반환?
}하지만, getAddCount() 메서드를 호출하면 3이 아닌 6이 반환된다. 왜 이러한 현상이 발생할까?
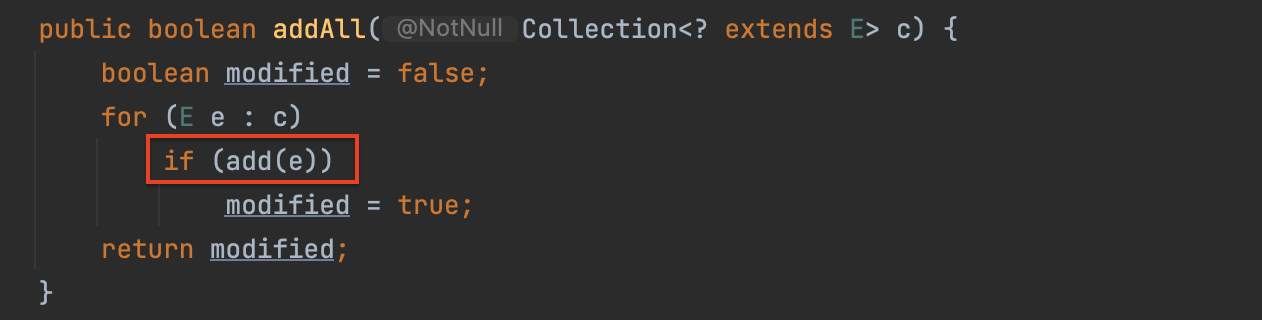
바로 부모 클래스인 HashSet 의 addAll 에서, add 메서드를 사용한다는 점이다. add 가 호출될 때 우리가 재정의 했던 InstrumentedHashSet 의 add 가 호출되면서, 카운팅이 중복으로 일어났다.
문제는, 이렇게 조심해야할 구현 방식이 문서에 명시가 되어 있지 않다.
이처럼 내부에서 같은 클래스의 다른 메서드를 사용하는 자기사용(self-use)여부는 해당 클래스의 내부 구현 방식에만 해당하기 때문에, 다음 릴리즈에서도 변경이 일어나면서 하위 클래스가 깨져버릴 가능성이 높다.
2. 보안 관련 문제
다음 릴리스에서 상위 클래스에 새로운 메서드를 추가하는 경우, 보안 때문에 컬렉션에 추가된 모든 원소가 특정 조건을 만족해야만 한다 가정하자.
하지만 컬렉션을 상속하여 원소를 추가하는 모든 메서드를 재정의해 필요한 조건을 먼저 검사하게 하는 방식은, 상위 클래스에 또 다른 원소 추가 메서드가 만들어지기 전까지만 유효하다.
하위 클래스에서 재정의하지 못한 새로운 메서드를 이용해 '허용되지 않은' 원소를 추가할 수 있게 되기 때문이다.
정리하면, 위의 두 문제 모두 한마디로 말하면 메서드 재정의가 원인이다.
따라서 클래스를 확장할때 재정의 하지 않고 새로운 메서드를 추가하면 괜찮다 생각할 수 있지만, 이는 만약 하위 클래스에 추가한 메서드와 시그니처가 같고 반환 타입이 다를 경우 클래스는 컴파일 조차 되지 않는 문제를 야기한다. 또한, 상위 클래스의 메서드가 요구하는 규약을 만족하지 못할 가능성이 크다.
☁️ 컴포지션을 활용하자
위의 모든 문제를 해결하는 묘안으로, 컴포지션을 사용할 수 있다.
컴포지션이란 기존 클래스를 확장하지 않고, 새롭게 만든 클래스 내부 private 필드로 기존 클래스의 인스턴스를 참조하는 방식이다. 기존 클래스가 새로운 클래스의 구성요소로 쓰인다는 뜻에서, 컴포지션이라고 이름이 붙여졌다.
InstrumentedHashSet 을 컴포지션과 전달 방식으로 다시 구현해보자.
하나는 집합 클래스 자신이고, 다른 하나는 전달 메서드만으로 이뤄진 재사용 가능한 전달 클래스이다.
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s; // 내부 필드로 상위 클래스의 참조를 지님
public ForwardingSet(Set<E> s) { this.s = s; }
public void clear() { s.clear(); }
public boolean contains(Object o) { return s.contains(o); }
public boolean isEmpty() { return s.isEmpty(); }
public int size() { return s.size(); }
public Iterator<E> iterator() { return s.iterator(); }
public boolean add(E e) { return s.add(e); }
public boolean remove(Object o) { return s.remove(o); }
public boolean containsAll(Collection<?> c)
{ return s.containsAll(c); }
public boolean addAll(Collection<? extends E> c)
{ return s.addAll(c); }
public boolean removeAll(Collection<?> c)
{ return s.removeAll(c); }
public boolean retainAll(Collection<?> c)
{ return s.retainAll(c); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
@Override public boolean equals(Object o)
{ return s.equals(o); }
@Override public int hashCode() { return s.hashCode(); }
@Override public String toString() { return s.toString(); }
}잠깐, 이렇게 래퍼 클래스로 감싸는 모양 어디서 보지 않았는가?
그렇다. 바로 데코레이터 패턴과도 유사한 모양새를 하고 있다.
해당 예제에서 기본 Set 의 기능에 원소가 몇 개 더해졌는지 알 수 있는 계측 기능을 추가적으로 꾸민 것처럼, 데코레이턴 패턴은 상속을 사용해 구체 클래스들을 만들지 않아도 유연하게 기능을 동적으로 확장을 할 수 있는 패턴이다.
public class InstrumentedSet<E> extends ForwardingSet<E> {
private int addCount = 0;
public InstrumentedSet(Set<E> s) {
super(s);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
public int getAddCount() {
return addCount;
}
public static void main(String[] args) {
InstrumentedSet<String> s = new InstrumentedSet<>(new HashSet<>());
s.addAll(List.of("틱", "탁탁", "펑"));
System.out.println(s.getAddCount()); // 3
}
}이제는 정상적으로 3 이 출력된다. 직접적으로 상속하지 않았으니 addAll 가 호출되었을 때 더 이상 InstrumentedSet 에서 재정의된 add 메서드를 부르지 않기 때문이다.
쉽게 말하면 부가 기능이 존재하는 래퍼 클래스(InstrumentedSet)와 실제 상위 클래스(Set ) 사이에 중간 계층(ForwardingSet)을 하나 두어, 래퍼 클래스에서 실제 상위 클래스의 메서드가 호출되어도 상속 관계가 아닌 단순히 인자로 받고 호출된 것이므로 재정의에 전혀 영향을 받지 않는다.
컴포지션 장점
-
기존 클래스의 내부 구현 방식과 독립적이게 되서, 메서드 재정의에 따른 부가 영향을 고려하지 않아도 되어 안전하다.
-
재사용할 수 있는 전달 클래스를 하나만 만들어두어도, 원하는 기능을 덧씌우는 클래스들을 손쉽게 구현할 수 있다. 역시 상속을 사용했다면, 매번 부모 클래스를 상속 받은 새로운 구체 클래스를 생성했어야 할 것이다.
Set<Instant> times = new InstrumentedSet<>(new TreeSet<>(cmp)); // 기본이 TreeSet
Set<E> s = new InstrumentedSet<>(new HashSet<>(INIT)CAPACITY)); // 기본이 HashSet컴포지션 단점
콜백(Callback) 프레임워크와는 어울리지 않는다.
🔖 콜백 프레임워크
자기 자신의 참조를 다른 객체에 넘겨서, 다음 호출(콜백) 때 사용하도록 하는 방식
콜백 때는 래퍼가 아닌 내부 객체를 호출하게 되는 SELF 문제를 일으킬 수 있으니, 주의하자.
https://stackoverflow.com/questions/28254116/wrapper-classes-are-not-suited-for-callback-frameworks
☁️ 컴포지션 대신 상속을 사용할때 주의사항
- 상속은
IS-A관계에서만 써야 한다.
즉, 하위 클래스(B)가 상위 클래스(A)의 '진짜' 하위 타입인 상황일 때만 써야한다. 확신할 수 없다면, 컴포지션을 활용하자.
public
class Properties extends Hashtable<Object,Object> { // 속성 목록은 해시 테이블이 아니다.
}Properties p = new Properties();
p.getProperty("key"); // Properties의 메서드
p.get("key"); // Hashtable의 메서드- 확장하려는 클래스의 API에 아무런 결함이 없고, 결함이 해당 클래스의
API까지 전파되도 괜찮은가를 확신해야 한다. 컴포지션은 상위 클래스의 결함을 숨기는 새로운 API를 설계할 수 있지만, 상속은 상위 클래스의 API의 결함까지도 그대로 가져온다.
📚 핵심 정리
상속은 강력하지만 캡슐화를 해친다는 문제가 있다. 상속은 상위 클래스와 하위 클래스가 순수한 is-a 관계일 때만 써야 하는데, 여전히 하위 클래스의 패키지가 상위 클래스와 다르고, 상위 클래스가 확장을 고려해 설계되지 않았다면 문제가 될 수 있다. 상속의 취약점을 피하려면 상속 대신 컴포지션과 전달을 사용하자.
