
MySQL 서버의 옵티마이저는 실행 계획을 수립할 때, 통계 정보와 옵티마이저 옵션을 결합해 최적의 실행 계획을 수립한다. 옵티마이저 스위치 옵션은 optimizer_switch 시스템 변수를 이용해서 제어한다.
SET GLOBAL optimizer_switch='index_merge=on'; // 전역 설정
SET SESSION optimizer_switch='index_merge=on'; // 로컬 설정☁️ MRR과 배치 키 액세스
Multi Range Read 란, Nested Loop 조인처럼 드라이빙 테이블의 레코드를 읽어서 바로바로 조인을 실행시키는 것이 아닌, 조인 대상 테이블 중 하나를 미리 버퍼링 해놓고 레코드가 가득 차게 되면 그때서야 스토리지 엔진으로 요청하는 방식이다.
MRR 방식의 기대효과
기본적으로 조인 처리는 MySQL 서버가, 실제 레코드를 검색하고 읽는 부분은 스토리지 엔진이 담당하게 되므로 MySQL 서버에서 드라이빙 레코드 건별로 드리븐 테이블의 레코드를 찾으면 스토리지 엔진에서는 최적화가 불가능하다.
조인 버퍼에 있는 값을 PK 기반으로 정렬을 추가적으로 한다. 따라서 한꺼번에 요청이 될 때 스토리지 엔진은 데이터 페이지에 정렬된 순서로 접근해 디스크 I/O를 최소화할 수 있다.
☁️ 블록 네스티드 루프 조인(block_nested_loop)
블록 네스티드 루프 조인이란, 기존 네스티드 루프 조인의 단점을 개선한 방식을 의미한다. 별도의 메모리 버퍼인 조인 버퍼를 이용하여 Driving 되는 테이블의 레코드를 조인 버퍼에 저장 한 후에 Driven 테이블(후행 테이블)을 스캔하면서 조인 버퍼를 탐색하는 방식이다.
네스티드 루프 조인 단점
네스티드 루프 조인이란, 조인의 연결 조건에 인덱스가 있는 경우 사용된다. 예를 들어 다음과 같은 경우, emp_no 가 클러스터링 인덱스이므로 NL 조인이 사용된다.
EXPLAIN
SELECT * FROM employees e
INNER JOIN salaries s ON s.emp_no = e.emp_no
AND s.from_date <= NOW()
AND s.to_date >= NOW() // 인덱스 사용 불가능
WHERE e.first_name='Amor';
NL 조인은 다음과 같이 이중 루프 방식으로 동작한다. 드라이빙 테이블 레코드를 읽으면서, 매번 드리븐 테이블을 탐색하며 찾아서 반환한다.
for (row1 IN employees) { // 드라이빙 테이블
for (row2 in salaries) { // 드리븐 테이블 =
if (condition) return (row1, row2);
}
}하지만 문제는, 드리븐 테이블에서 인덱스를 사용할 수 없는 경우 나타난다.
NL 조인 특성상 드리븐 테이블을 여러번 읽게 되는데, 만약 테이블에서 일치하는 레코드가 1000 건일 경우 드리븐 테이블 조인 조건이 인덱스를 사용할 수 없으므로 1000 번의 테이블 풀 스캔이 일어나게 되므로 성능이 매우 나빠진다.
블록 네스티드 루프 조인
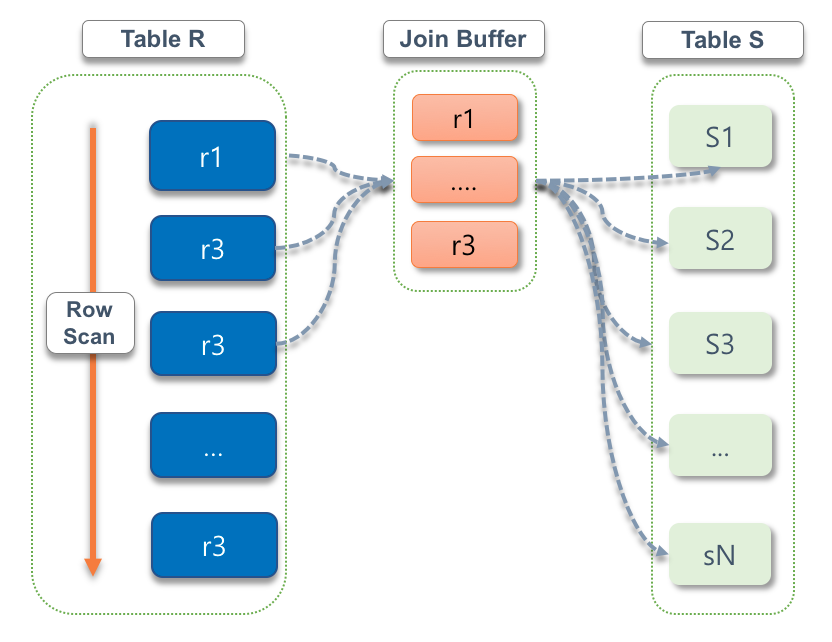
만약 드리븐 테이블에서 인덱스를 아예 사용할 수 없는 경우, 테이블 풀 스캔이 다수 일어나는 것을 방지하기 위해 옵티마이저가 자동으로 블록 네스티드 루프 조인 방식을 선택한다.
예제로 아래 쿼리는 조인 조건이 없으므로, 카테시안 조인이 수행된다.
EXPLAIN SELECT *
FROM dept_emp de, employees e
WHERE de.from_date > '1995-01-01' AND e.emp_no < 109004;
ix_fromdate인덱스를 통해 인덱스 레인지 스캔이 일어난다.- 조인에 필요한 나머지 칼럼들을 모두 읽어서 조인 버퍼에 저장한다.
- employees 테이블의 PK를 이용해 emp_no 조건에 만족하는 레코드를 검색한다.
- 검색 결과와 2번에서 캐시된 조인 버퍼의 레코드를 결합해서 반환한다.(이때 조인이 발생한다)
즉 드리븐 테이블을 매번 탐색하지 않고 한번만 탐색해서 반환한 데이터와 중간에 조인 버퍼에 저장해놓은 드라이빙 테이블 레코드를 결합(조인)한다.
주의사항
따라서 드리븐 테이블의 결과를 바탕으로 드라이빙 테이블과 조인을 수행하기 때문에, 조인 버퍼가 사용되는 경우 정렬 순서가 흐트러질 수 있다.
MySQL 8.0 부터는 해시 조인 알고리즘이 블록 네스티드 루프 조인을 대체한다.
☁️ 인덱스 컨디션 푸시다운(index_condition_pushdown)
인덱스 컨디션 푸시다운을 활성화하면, 복합 인덱스 테이블에서 인덱스를 활용하지 못하는 조건이라도 Random I/O 가 발생하지 않고 모두 인덱스에서 처리할 수 있도록 하는 것을 의미한다.
즉, 불필요한
Random I/O를 줄여 성능을 개선시켰다. 어떻게 이게 가능했던걸까?
개선 이전
ALTER TABLE employees ADD INDEX ix_lastname_firstname (last_name, first_name);
SET optimizer_switch='index_condition_pushdown=off';다음과 같은 쿼리를 실행해보면, %sal 로 인해 인덱스를 타지 못하고 테이블 풀 스캔이 일어난다. (Using Where)
EXPLAIN SELECT * FROM employees WHERE last_name='Action' AND first_name LIKE '%sal'; 
문제는 인덱스가 last_name, first_name 모두 복합 인덱스로 걸려 있음에도 다음과 같이 동작한다는 것이다.
last_name인덱스 레인지 스캔이 일어난다.- 인덱스로 필터링된 레코드를
Random I/O를 통해 실제 테이블에 접근하여first_name조건에 부합하는지 하나하나씩 확인한다.
만약 1번 과정에서 결과 레코드가 10만건이고 그중에 단 하나의 데이터만 2번 조건에 부합했다면? 나머지 99999 건의 레코드 읽기는 불필요한 작업이 되어버린다.
왜 이러한 현상이 발생할까?
기존에는 1번의 인덱스 비교 작업은 InnoDB 와 같은 스토리지 엔진이, 2번 테이블 스캔은 MySQL 엔진이 수행하는 작업이다. 하지만 인덱스 범위 제한 조건(EX)레인지 스캔)으로 사용할 수 없는 경우엔 스토리지 엔진으로 조건 자체를 전달 조차 하지 못했다.
스토리지 엔진이 넘겨 준 데이터 (인덱스를 사용해 걸러진 데이터) 중에서 MySQL (MariaDB) 엔진이 한번 더 걸러야되는 조건 (필터링 혹은 체크 조건)이 있다면 옵티마이저 실행 계획에
Using where로 나온다. 즉, PK나 다른 인덱스를 활용한 조건은 스토리지 엔진이, like 연산과 같은 비교는 MySQL 엔진에서 수행한다.
스토리지 엔진 입장에서는, 해당 필드에 대한 조건은 받은게 없으니 당연히 테이블을 한번 더 읽을 수 밖에 없었던것이다.
https://jojoldu.tistory.com/474
MySQL 5.6 개선 이후
그 이후 버전부터는 인덱스 범위 조건에 사용될 수 없어도, 인덱스에 포함된 필드라면 스토리지 엔진으로 전달하여 최대한 스토리지 엔진에서 걸러낸 데이터만 MySQL 엔진에만 전달되도록 핸들러 API가 개선되었다.
인덱스 조건을 스토리지 엔진으로 넘겨주기 때문에 인덱스 컨디션 푸시 다운이란 이름이 되었다.
SET optimizer_switch='index_condition_pushdown=on';이제 다시 쿼리를 실행해보면, 인덱스 레인지 스캔이 수행된 것을 볼 수 있다.

☁️ 인덱스 확장(use_index_extensions)
인덱스 확장 옵티마이저 옵션은, InnoDB 스토리지 엔진에서 사용하는 테이블에서 세컨더리 인덱스에 자동으로 추가된 PK 활용 여부를 결정한다.
🫧 세컨더리 인덱스에 자동으로 추가된 PK
InnoDB는 클러스터링 인덱스가 기본이므로, 세컨더리 인덱스 리프 노드에 프라이머리 키 값을 가지고 있다. 세컨더리 인덱스를 명시했다면, 사실상(세컨더리 인덱스 칼럼, PK 칼럼)구조의 인덱스를 생성한 것과 흡사하게 작동한다.
개선 이전의 MySQL 에서는 이러한 PK를 성능 최적화를 위해 적절히 활용하지 못했지만, 이후의 MySQL에서는 세컨더리 인덱스에 PK 인덱스 칼럼이 있다는 것까지 인지하고 실행 계획을 수립한다.
즉, 해당 옵션도 마찬가지로 실제 테이블에 접근하는
Random I/O발생을 줄여 성능을 최적화시킨다.
예를 들어, 다음과 같이 인덱스가 걸려 있는 테이블을 봐보자.
PK(deptno_empno):(dept_no, emp_no)KEY(ix_fromdate):(from_date)
EXPLAIN SELECT COUNT(*) FROM dept_emp WHERE from_date='1987-07-25' AND dept_no='d001';세컨더리 인덱스와 PK 조건이 걸렸는데, 실제 인덱스를 구성하는 칼럼중 어느부분까지 사용했는지 바이트 단위로 표시하는 key_len 정보를 보면 dept_emp 클러스터링 인덱스까지 활용했음을 알 수 있다.

EXPLAIN SELECT COUNT(*) FROM dept_emp WHERE from_date='1987-07-25';
마찬가지로 정렬 작업에서도 세컨더리 인덱스에 포함되어 있는 PK 값을 활용할 수 있다. 실제로 PK 로 정렬을 하는 경우, 별도의 정렬 작업 없이 인덱스만을 읽어서 끝내는 것을 볼 수 있다.
EXPLAIN SELECT COUNT(*) FROM dept_emp WHERE from_date='1987-07-25' ORDER BY dept_no;
