
레디스가 원자적이여서 스레드 안전하다는 개념을 믿고 레디스를 적용했지만, 동시성 이슈가 발생했다. 참고로 추후 레디스를 사용하지 않는 방안으로 수정했지만, 그래도 SortedSet을 이용하며 발생했던 트러블 슈팅 과정들을 기록했다.
☁️ 비동기로 기능 분리
사용자가 해시태그로 검색을 하면, 조회수를 증가시켜주는 기능을 구현해야 했다.
-
비즈니스적으로 게시물 조회수와 다르게 해시 태그 조회수 증가 부분은 UI에 보여지지 않으며, 중요도도 떨어지기 때문에 늦게 반영되어도 괜찮은 데이터이다.
-
Redis를 사용한다면, 갑자기 통신이 안된다거나 하는 문제가 검색 기능까지 영향을 미치면 안된다.
따라서 해시 태그 조회수를 반영하고 정렬하는 기능은 비동기로 일어나도록 구성하였다. 원래 EvenListener 은 트랜잭션도 고려해주어야 하지만, 조회 기능이므로 별다른 트랜잭션 고려가 필요 없었다.
@Component
class HashTagSearchEventListener(
private val hashTagRankService: HashTagRankService
){
...
@Async
@EventListener(HashTagSearchEvent::class)
fun handle(event: HashTagSearchEvent) {
logger.info("new hashtag search event handled: ${event.hashTagName}")
try {
hashTagRankService.increaseCount(event.hashTagName)
} catch (e: Exception) {
logger.error(e.message)
}
}
}☁️ 해시 태그 조회 횟수를 어디에 저장할것인가?
우선, 해시 태그 조회수는 뷰에 직접적으로 보여지지 않는다. 마침 캐싱 기능을 위한 레디스 세팅도 다 되어있었고, 아래와 같은 두 가지 이유로 인해 Redis 를 사용하기로 결정했다.
-
게시물 조회수 같은 경우와 다르게, 굳이 DB에 저장해 일관성과 정합성을 보장하지 않아도 된다. (단순히 통계성 데이터로만 사용되기 때문)
-
RDBMS로 DB I/O로 인한 부하를 일으키는 것보다는, 가벼운 인메모리 데이터베이스가 좋다.

이후 애초에 레디스에서 갱신하면 싱글 스레드 기반으로 동작하니 동시성 이슈가 없을 것이라 생각했고, 일관성 보다는 가용성을 더 중요하게 생각했다. (느릴 수는 있겠지만 사용자에게 실시간으로 정확한 데이터를 보여줘야 하는게 아니므로)
☁️ 어떤 자료구조를 사용해야 할까?
초기에는, 딕셔너리 형태로 Redis 에 저장된 해시태그 데이터들을 불러온 후(key : 해시태그 이름, value : 해시태그 조회 횟수) 횟수 기준으로 정렬해서 반환하는 방식을 생각했다.
하지만 해당 방식은
O(N) * O(NlogN)의 성능을 지닌다.
자바 Collections.sort() 는 삽입 + 합병 정렬을 활용는 TimSort로 최악의 경우에도 O(NlogN) 을 보장하며, Redis 에서 모든 데이터를 읽어오는 Keys 과정은 O(N) 이 걸리기 때문이다.
🔖 TimSort
https://d2.naver.com/helloworld/0315536
가장 중요한 문제는 해당 조회 명령은 Blocking 방식으로 동작하기 때문에, 다른 모든 명령의 실행이 막힌다. 레디스는 싱글 스레드인만큼 Blocking 시간이 길어진다면 다른 작업들까지 영향을 미쳐 큰 성능 저하를 일으킬 수 있게 된다.
🫧 KEYS VS SCAN
SCAN은KEYS와 달리 가져오는 데이터 양을 줄여 다른 연산이 개입할 틈을 제공하여, 마치NonBlocking처럼 동작해 성능을 높인 연산이다. 레디스의bucket을 찾아가기 위한 다음index값을 의미하는 커서 값을 통해 분할이 이루어진다.redis 127.0.0.1:6379> scan 0 1) "17" // 다음 cursor 값 2) 1) "key:12" 2) "key:8" 3) "key:4" 4) "key:14" 5) "key:16" 6) "key:17" 7) "key:15" 8) "key:10" 9) "key:3" 10) "key:7" 11) "key:1"
하지만 SCAN 을 활용해도 SortedSet 의 O(logN) 보다 느린 O(NlogN) 이였고, 따라서 Redis 에서 제공하는 자료구조를 활용하기로 결정했다.
🫧 SortedSet 성능에 대해 알아보자
SortedSet 은 정렬된 상태를 유지하는 집합을 의미한다. 정렬된 상태를 유지하면서, 삽입/삭제에 높은 성능을 유지하기 위해 두개의 자료구조를 사용한다.
레디스에서 SortedSet 은 삽입/삭제 모두 O(logN) 의 성능을 가진다.
HashTable 과 Skip List 자료구조 2개가 사용되며, HashTable 을 통해 빠른 접근 속도를 제공하는 동시에 skip list 로 데이터의 정렬을 유지한다.
🔖 Skip List
LinkedList와 달리 다음 노드뿐만 아니라 건너 건너의 데이터도 가르키는 포인터를 여러개 가지고 있는 구조이다. 삽입/삭제/조회 모두O(NlogN)이 아닌O(logN)*O(1)로 높은 성능을 지닌다.예를 들어 아래에서
7번 데이터를 찾아야할 때7번 포인터를 따라가지 않고,1->4로 연결된 포인터 한번과4->5,5->6,6->7번 데이터를 따라가면4번으로 속도를 줄일 수 있고 이렇게 극단적으로O(logN)까지 조회 속도를 향상시킬 수 있다.
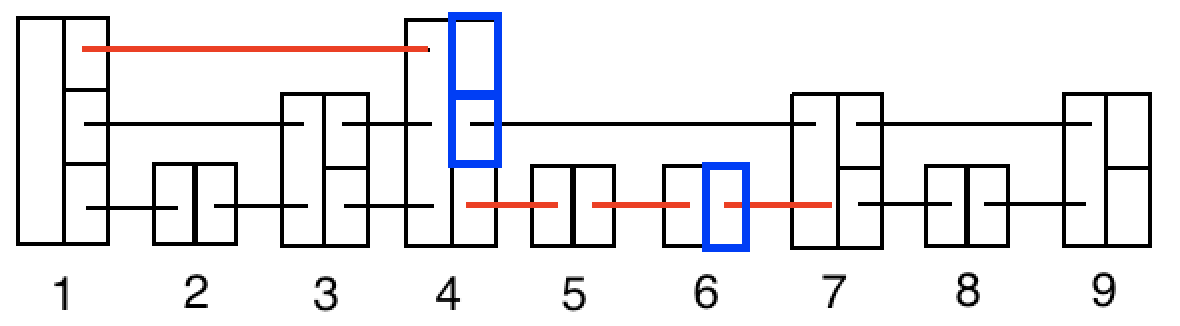
정리하자면 다음과 같다.
- 원소(score)를 삽입하면 해시 테이블에 데이터가 저장된다 :
O(1) - 동시에 해당 원소(score)는 스킵 리스트에 저장되어 정렬된 상태를 유지한다 :
O(logN)
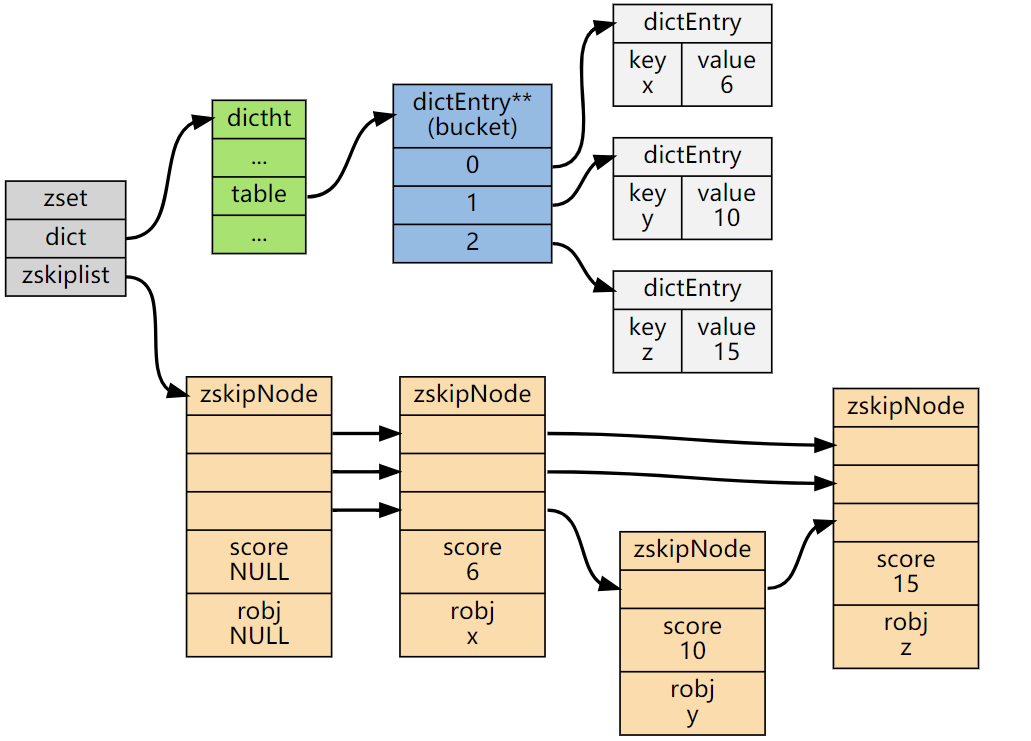
따로 내가 정렬해줄 필요도 없으며, 심지어 성능도 더 좋으니 Redis 에 데이터를 저장하기로 결정한 이상 사용안 할 이유가 없다.
☁️ 동시성 이슈 발생
동시성 이슈는
SortedSet으로 리팩토링 하기 이전,Map형태로 저장했을 때 발생했다. (물론SortedSet도 아래 로직 같이 했다면 똑같이 이슈가 생겼을 것이다.)
@Test
fun 조회수_증가_동시성_테스트() {
val executorService: ExecutorService = Executors.newFixedThreadPool(10)
val countDownLatch = CountDownLatch(10)
for (i in 1..10) {
executorService.execute {
hashTagRankingSupport.increaseCount("1호선")
countDownLatch.countDown()
}
}
countDownLatch.await()
val counts: Int = hashTagRankingSupport.get("1호선")!!
assertThat(counts).isEqualTo(10)
}구현이 끝난 이후 10 개의 스레드 풀을 생성해서, 동시에 접근해서 값을 증가시키도록 해보았다. 하지만 이런 경우 모든 스레드가 아래 부분에 동시에 접근해서 null 데이터를 가져가고, null 이므로 1만큼 증가되서 저장이 된 것이다.
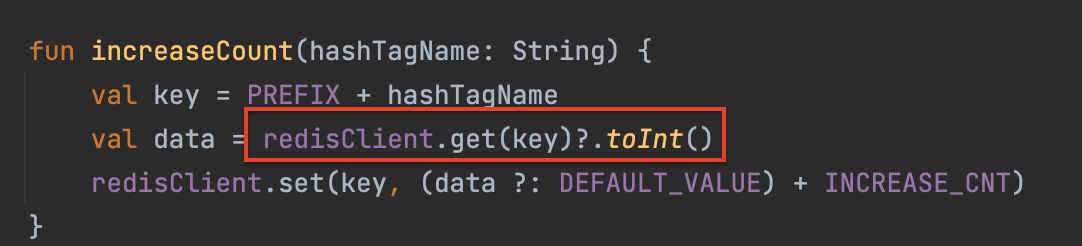
- 1번 스레드가
get(key)->null->1증가시킨다. - 2번 스레드가
get(key)-> 1번 스레드가 증가시킨1이 더해지기 이전에null값을 가져와서 다시1증가시키므로, 최종적으로redis에는1값이 들어가게 된다. 3번 ..10번까지 모두 마찬가지의 상황이다.
즉 (값을 가져감 + 가져온 값에 1을 더함) 이게 하나의 사이클로 원자적으로 작동하지 않은 것이다. 가져가고 더하는 과정이 분리되어 있어서 생기는 문제였던 것!
이렇게 프로그래밍을 하면 아무리
redis가 싱글 스레드라서 원자적이라 한들 소용이 없어지게 된다. 왜냐하면단일 명령(Instruction)이 끝나야만 CPU를 빼앗길 수 있는데, 위에서와 같이 고급 언어의 문장들은 단일 명령어가 아니기 때문에 중간에 CPU를 빼앗겨서race condition문제가 발생하게 되기 때문이다.
🫧 대안 1: Synchronized
synchornized 로 스레드가 동시에 접근할 때 Block 시켜 동시성 문제를 해결할 수 있다. Block 된 스레드는 메모리에 대기했다가, 다른 스레드가 락을 풀면 바로 ReadyQueue 로 이동해서 CPU의 할당을 기다리게 된다.
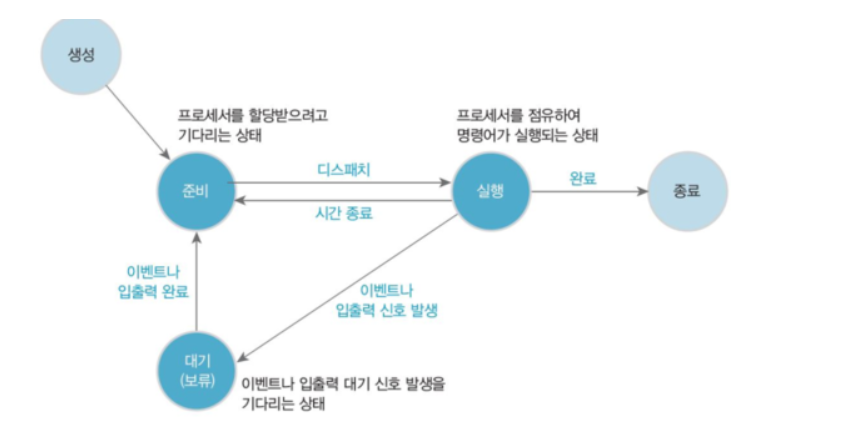
🔖 Monitor VS Mutex
synchornized는 내부적으로 모니터를 활용한다. 뮤텍스와 다른점은, 뮤텍스는Block이 아닌Suspend상태가 되어 버린다는 것이다.Suspend되면 메모리 큐에서 기다리는 것이 아닌 디스크 스왑 메모리로 추방당하기 때문에 성능이 더 좋지 않다.
fun increaseCount(hashTagName: String) {
val key = PREFIX + hashTagName
synchronized(this) { // 이 부분에 LOCK을 걸어서 하나로 묶어준다.
val data = redisClient.get(key)?.toInt()
redisClient.set(key, (data ?: DEFAULT_VALUE) + INCREASE_CNT)
}
}동시 접속 사용자를 1000 명까지 늘리면 1 초 정도 걸린다.
CountDownLatch란?
Thread.Sleep()을 사용해서 해도 될 것 같은데,CountDownLatch를 사용하는 이유가 있을까?
동시성 테스트는 스레드가 거의 동시에 실행되는 것처럼 CPU에서 정말 작은 시간 단위로 교체 작업이 이루어져야 하는데 Thread.sleep 을 쓴다면 순차적으로 실행될 가능성이 높아서 사용하지 않았다.
또한 CountDownLatch 의 await 메서드를 통해 다른 스레드들이 모두 실행될 때 까지 기다리게 함으로써 통해 메인 스레드가 먼저 실행되는 것을 방지하여, 맨 마지막에 결과를 볼 수 있게 된다.
https://dev-monkey-dugi.tistory.com/152
https://tecoble.techcourse.co.kr/post/2021-10-23-java-synchronize/
Redis의 원자성
Redis 는 여러 클라이언트들에게 시간의 차이는 조금 있겠지만 같은 서비스를 제공하되, 여러 스레드를 통해 데이터를 처리하지는 않는다(싱글 스레드). 즉, 동시성은 있지만 병렬성은 없다.
Single Thread 장점
- 스레드 생성 및 컨텍스트 스위칭으로 인한 오버헤드가 없다.
- 동시성 문제로 락을 도입했을 때 발생하는 복잡성 및 오버헤드가 없다.
Single Thread 단점
- 특정 연산이 오래 걸린다면 다른 연산에도 영향을 미치면서 장애 및 병목이 발생할 수 있다.
CPU멀티코어를 활용한 퍼포먼스 향상이 힘들다.- 싱글 스레드에서 병렬로 인한 동시성 문제는 없더라도,
Concurrent로 인해 동시성 문제가 발생할 수 있다.
2 번과 같은 단점은 아래 그림과 같이 레디스 클러스터(3대)를 구축해서 멀티 프로세스 방식처럼 사용하여 극복할 수 있다.
Q. INCR 연산과 같이 Atomic한 연산을 한 번이 아닌 여러 번 수행해야 한다면, 원자성은 깨지게 된다. 어떻게 보장할 수 있을까?
3 번과 같은 단점 역시, Transaction 과 lua script 와 같은 atomic 을 보장해주는 기능을 활용하는 것만으로도 동시성 문제를 일으키는 것을 보장할 수 있다. 그렇다면 우선 트랜잭션을 활용해보자.
☁️ Redis 트랜잭션
Redis 에서는 Atomic 한 결과를 위해, 트랜잭션을 사용해서 여러 쿼리를 하나의 동작처럼 묶을 수 있다.
이러한 특성을 이용해서 save + get 을 하나의 트랜잭션으로 묶고, 낙관적 락을 통해 아예 다른 스레드가 접근할 기회 조차 주지 않으면 동시성 문제를 해결할 수 있을 것이라 생각했다.
🔖 Redis 트랜잭션 연산 종류
MULTI: 트랜잭션을 시작하는 키워드이다.EXEC: 트랜잭션을 종료하는 키워드이다.WATCH: 낙관적 락으로, 키가 수정되지 않은 경우에만 레디스가 트랜잭션을 수행할 수 있도록 요청하는 키워드이다. 만약EXEC수행으로UNWATCH가 일어나기 전에 키가 수정된다면 전체 트랜잭션이 중단된다.
WATCH mykey // 낙관적 락
val = GET mykey
val = val + 1
MULTI
SET mykey $val // 동시성 이슈 보장
EXEC1. 트랜잭션 + 낙관적 락 사용
앞서서 보았던 synchornized 는 실제 데이터베이스에 락(공유락, 베타적 락)을 걸어버리는 비관적 락에 속한다. 낙관적 락은, 데이터베이스가 아닌 어플리케이션 단에서 버전 정보를 통해 충돌을 감지한다.
WATCH 는 트랜잭션에 Check-And-Set 연산이 가능하도록 하는 낙관적 락을 의미한다.
당연하겠지만 그냥 트랜잭션만으로는, 동시성 이슈를 해결할 수 없다.
주의사항
레디스는 관계형 데이터베이스처럼 완벽히 ACID 를 보장해주지 않으므로, 주의해야할 것들이 있다.
- 레디스는 그 자체가 가지는 빠른 성능을 해치지 않도록 롤백 기능을 제공하지 않는다.
- 하나의 트랜잭션이 실행중일 때 다른 트랜잭션이 접근하는 것이 감지된다면, 트랜잭션 자체가 실패로 끝나고 이를 알리기 위해
NULL을 반환한다. 그리고 해당 트랜잭션을 큐에서 제거해서 버려버린다.


실제 콘솔에서 간단한 테스트를 해보면, 중간에 SET TEST 11 연산이 한번 더 수행되었을 때 해당 트랜잭션이 nil 을 반환하면서 버려지고, EXEC 수행으로 감시가 풀리면 재시도 했을 때 OK 를 반환하며 성공하게 되는 것을 볼 수 있다.
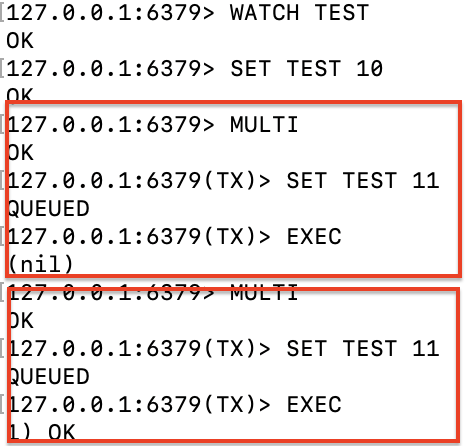
하지만 나와 같은 경우 조회수 증가 트랜잭션이 실패한 경우 그냥 버려버리면 안되고 재시도를 해야 했는데, 직접 버려진 트랜잭션을 다시 재시도하거나 에러 처리를 구현해야 했다. 다만 아무리 공식 문서를 찾아봐도 테스트를 성공시킬 방법을 찾지 못했다. 🥹
fun increaseCount(hashTagName: String) {
val key: String = PREFIX + hashTagName
redisTemplate.execute(object : SessionCallback<List<Any>> {
override fun <K : Any?, V : Any?> execute(operations: RedisOperations<K, V>): List<Any> {
operations.watch(key)
operations.multi()
val data = redisClient.get(key)?.toInt()
redisClient.set(key, (data ?: DEFAULT_VALUE) + INCREASE_CNT)
val result = operations.exec()
logger.info("=================$result=============")
return result
}
})
}https://redis.io/docs/interact/transactions/
2. Redis INCR 사용
결국 트랜잭션 + 낙관적 락으로 원자성 보장하는데에는 실패하고, 그 다음 차선책을 생각해보았다.
굳이 트랜잭션으로 값을 가져와서 업데이트 하는 로직을 묶어주지 않고도, 이미 레디스에 해당 연산이 구현되어 있다는 것이 기억났다. 바로 INCR 이다. 하지만 앞에서 말했듯이 싱글 스레드도 concurrent 하게 수행된다면 충분히 동시성 문제가 발생할 수 있다.
@Service
class HashTagRankService(
val redisClient: RedisClient
){
fun increaseCount(hashTagName: String) {
val valueOperations = redisTemplate.opsForValue()
val key: String = PREFIX + hashTagName
valueOperations.increment(key)
}
...
}https://redis.io/commands/incr/
1000명-3000명 동시 접속 테스트
동일하게 1000 명 기준 614ms 성능이 나왔고, 먹통이 되었던 synchornized 보다 훨씬 빨라졌다.
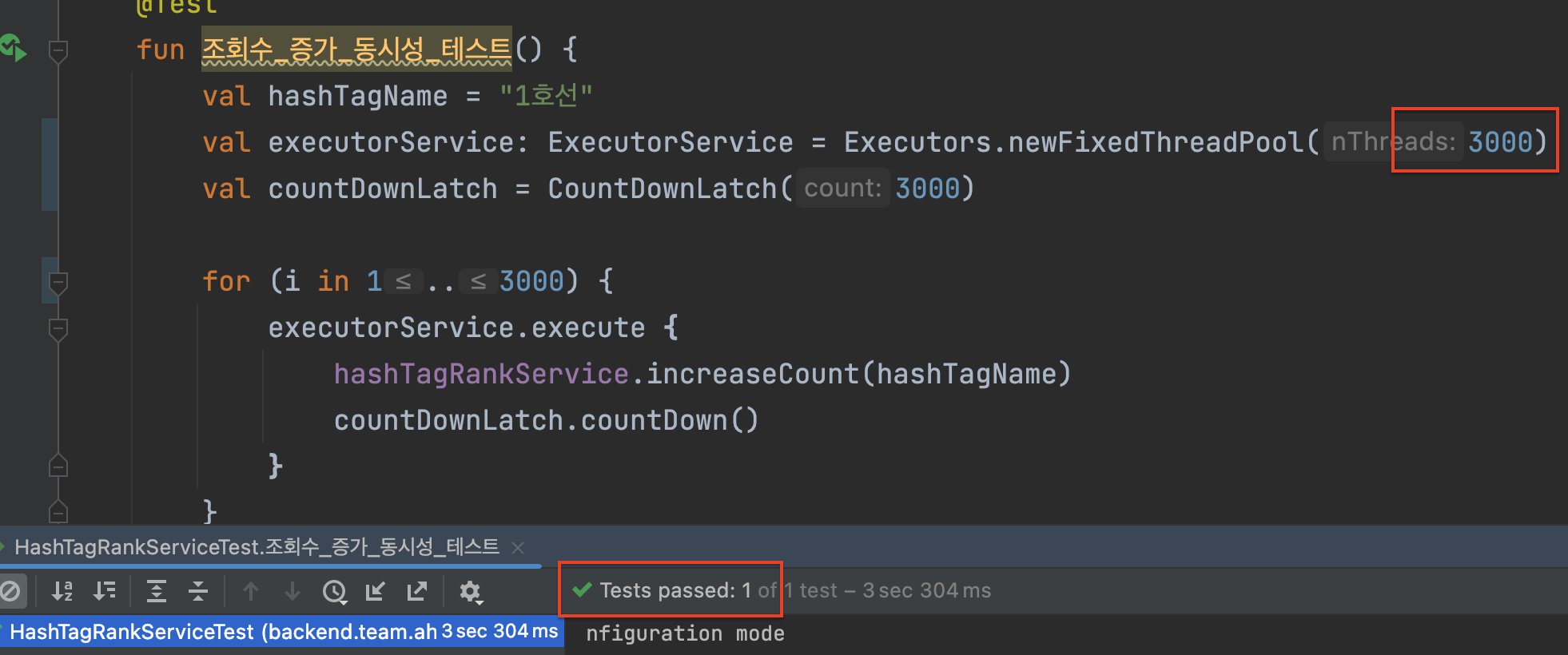
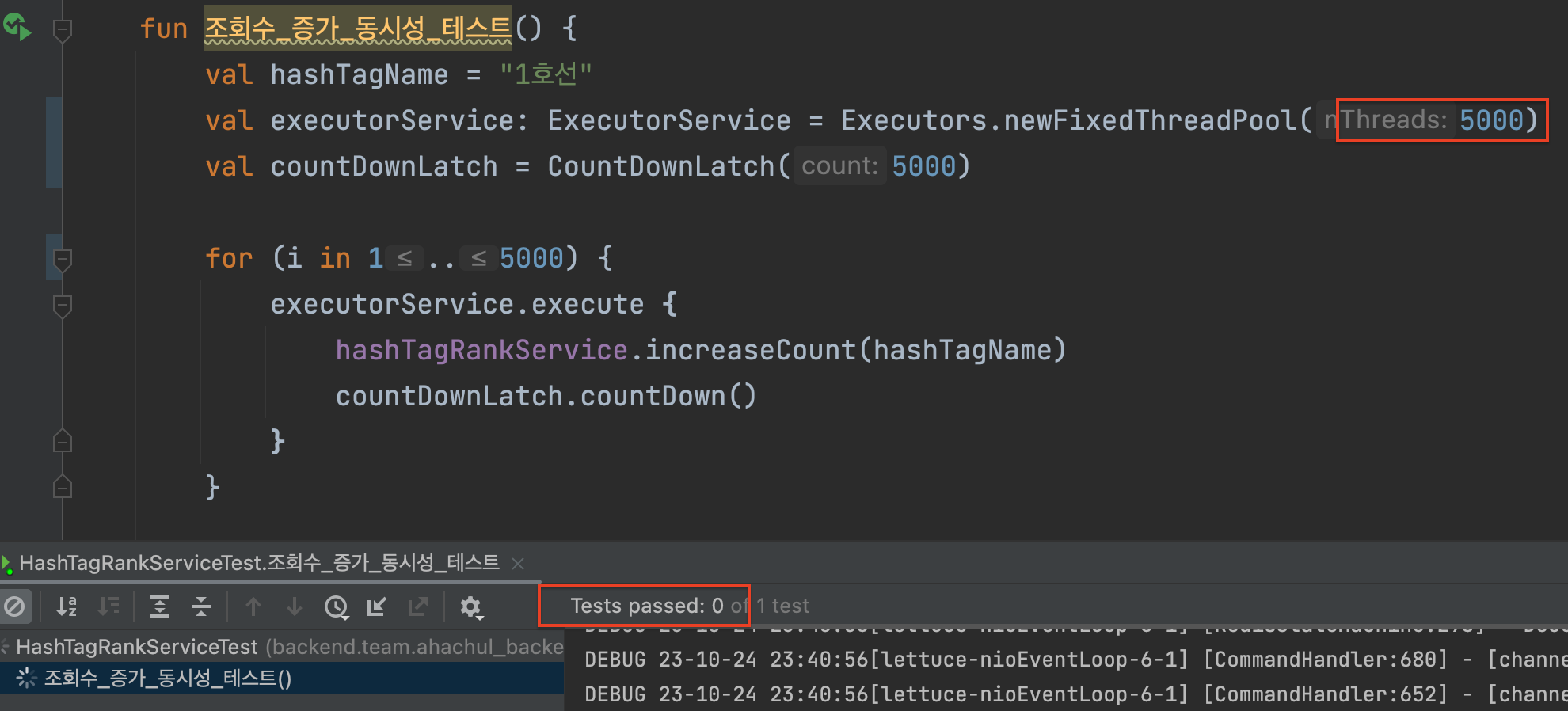
5000이상 동시 접속 테스트
FixedThreadPool 크기는 처음에 쓰레드 풀에 생성해놓는 스레드의 개수이므로, 처음에는 이 값을 너무 크게 잡아서 메모리 부족 에러가 났고 더 이상 스레드를 생성해내지 못해 테스트가 무한 루프를 도는 문제가 발생했었다.
적절히 값을 낮춰주니 테스트 성공!
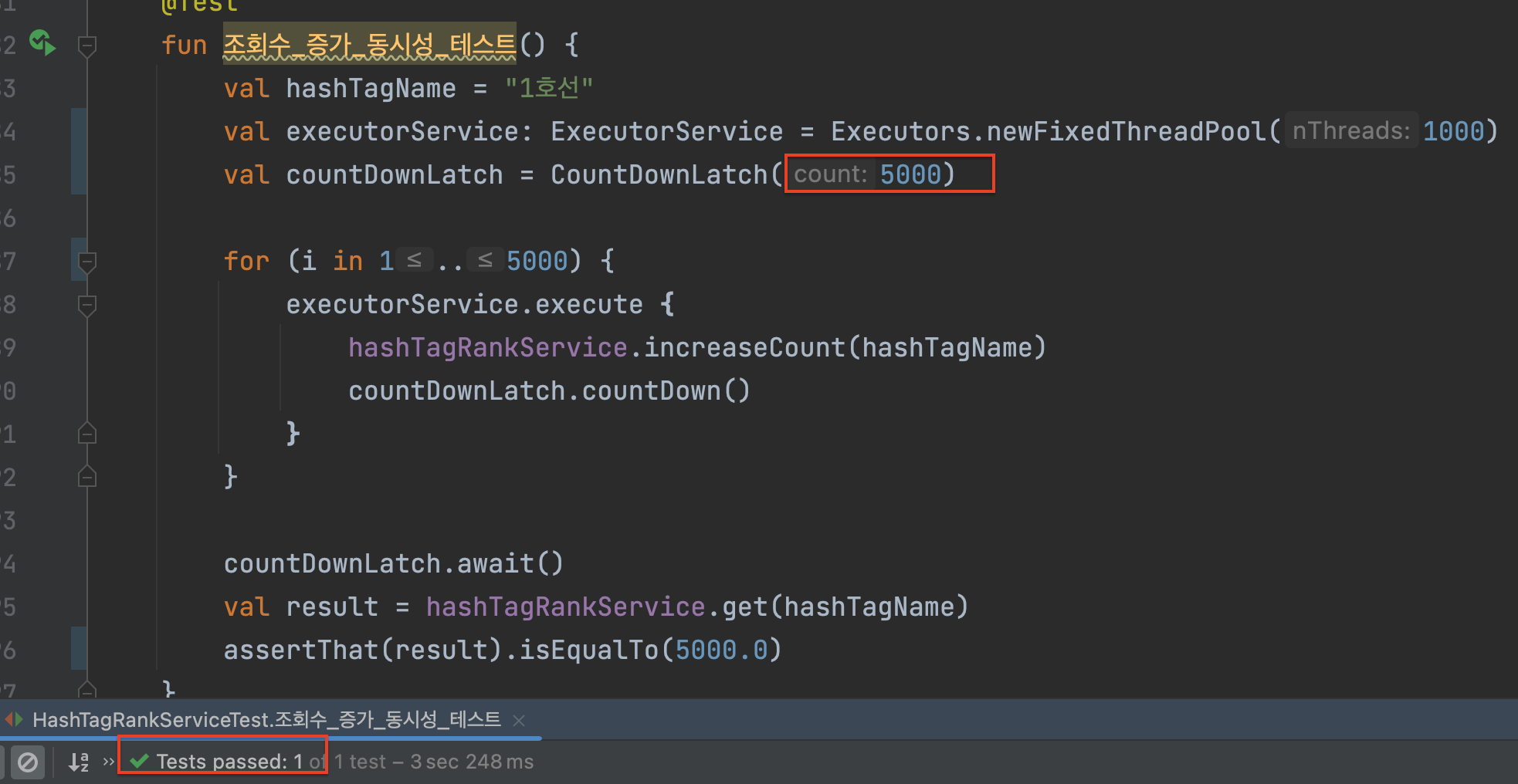
아래 코드는
SortedSet로 수정한 최종본!
@Service
class HashTagRankService(
val redisClient: RedisClient
){
fun increaseCount(hashTagName: String) {
val setOperations = redisClient.getZSetOps()
setOperations.incrementScore(KEY, hashTagName, INCREASE_CNT.toDouble())
}
fun getRank(): GetHashTagRankDto.Response {
val setOperations = redisClient.getZSetOps()
val responseSet = setOperations.reverseRange(KEY, 0, LIMIT)
val response = responseSet?.toList() ?: listOf()
return GetHashTagRankDto.Response(response)
}
fun get(hashTagName: String): Double? {
val setOperations = redisClient.getZSetOps()
return setOperations.score(KEY, hashTagName)
}
}참고하면 좋을 자료들
You Don’t Need Transaction Rollbacks in Redis
Everything You Need to Know About Redis
Handling Race Conditions Using Redis Atomic Operations
Redis is single-threaded, then how does it do concurrent I/O?
An In-Depth Look Into the Internal Workings of Redis
[Spring & Java] 🚀 재고시스템으로 알아보는 동시성이슈 해결방법
