
☁️ Redis를 사용한 이유?
Redis 나 Memcached 를 사용하는 방법은 글로벌 캐싱 전략이다.
즉, 서버마다 각각 캐시 저장소를 두지 않고 한 곳에서 관리한다. 이로써 서버가 확장되었을 때 서버 간 데이터 동기화가 필요하지 않아지지만, 그만큼 네트워크 트래픽을 더 탄다는 단점이 존재한다.
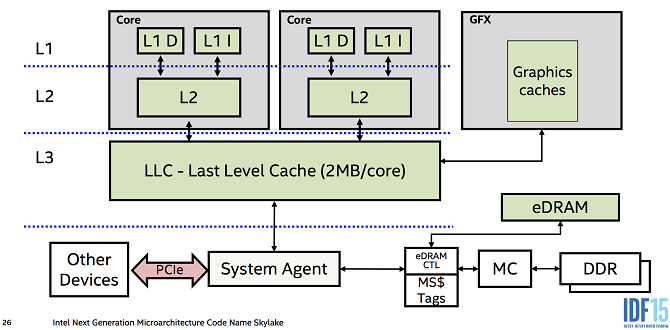
우리 서비스에서는 추후 확장 가능성을 고려하여, 글로벌 캐시 전략을 사용하였다. 마치 CPU에 존재하는 L1, L2 캐시와 외부에 존재하는 L3 캐시가 바로 글로벌 캐시이다.
☁️ @Cacheable이란?
우리는 쉽게 스프링의 @Cacheable 어노테이션을 통해 캐싱을 적용할 수 있다.
해당 어노테이션은 @transactional 과 유사하게 AOP 방식으로 동작하며, 스프링 부트에서 일종의 다양한 인메모리 데이터베이스들의 캐시 과정을 추상화해놓은 것이라 생각하면 된다.
인메모리 캐시 데이터베이스에는 Redis, Hazelcast, Apache Geode, Java Map/ConcurrentMap 등이 존재한다.
즉, 스프링 부트에서 다음의 과정을 내부적으로 처리해주는 것이다.
- 기존 데이터가 있다면 즉시 반환하고 메서드를 실행시키지 않는다.
- 기존 데이터가 없다면 메서드를 실행시키고, 반환된 데이터를 캐시 데이터로 저장한다.
Spring Boot 에서 제공하는 캐시는 Cache 와 CacheManager 인터페이스를 통해 추상화 되어 있다.
public interface Cache {
@Nullable
<T> T get(Object key, @Nullable Class<T> type); // 데이터를 조회
void put(Object key, @Nullable Object value); // 데이터를 저장
void evict(Object key);
void clear();
}public interface CacheManager {
@Nullable
Cache getCache(String name); // 이름에 해당하는 캐시 조회
Collection<String> getCacheNames();
}Redis 를 예시로 들어보자.

만약 위와 같은 CacheManager 나 CacheResolver 를 특별히 빈으로 등록하지 않으면, 스프링 부트가 자동으로 아래 우선순위에 따라 존재하는지 체크하고 결정해서 사용하게 된다.
- Generic
- JCache (JSR-107) (EhCache 3, Hazelcast, Infinispan, and others)
- Hazelcast
- Infinispan
- Couchbase
- Redis <-- 선택
- Caffeine
- Cache2k
- Simple // 메모리 map 기반
나와 같은 경우 Redis 설정 정보가 존재했기 때문에 RedisCacheManager 가 선택된 것을 볼 수 있다.
그렇다면 Aspect 에서는 어떠한 과정이 일어나는 걸까?
CacheAspectSupport
먼저, CacheInterceptor 는 단순히 AOP 호출용, 실제 모든 캐시 공통 로직은 CacheAspectSupport 에서 수행된다.
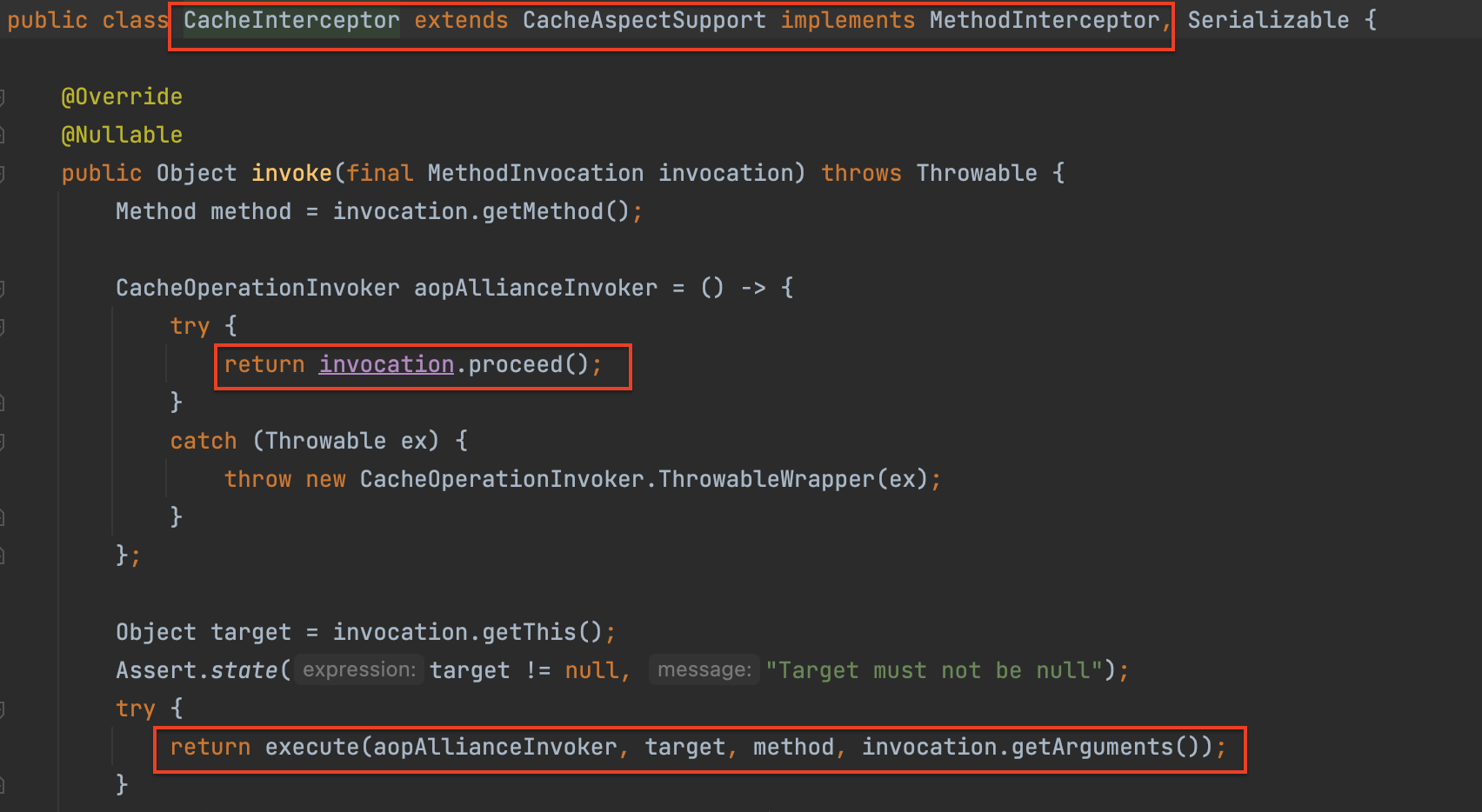
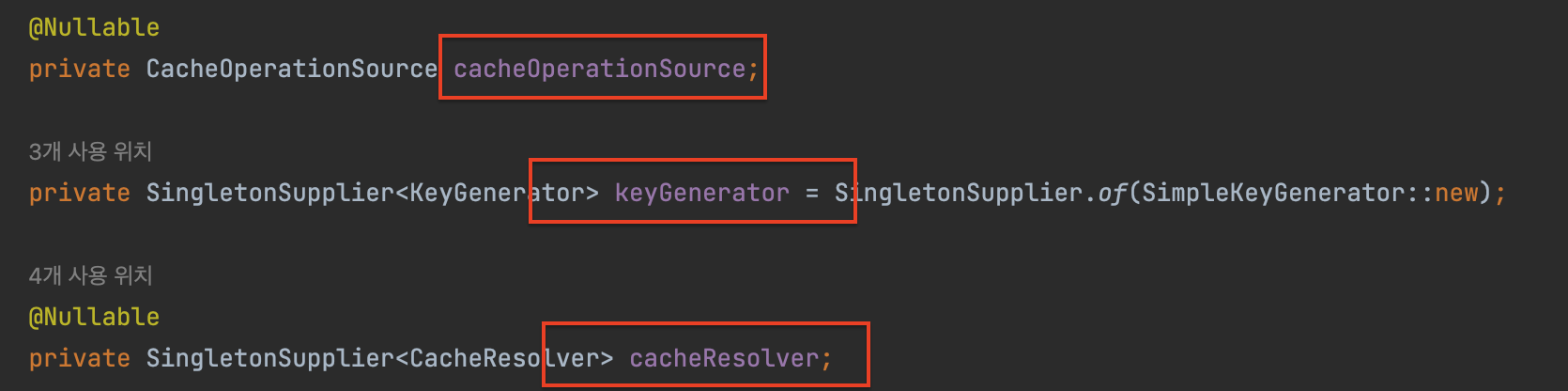
CacheAspectSupport 는 Strategy 패턴을 활용해 동적으로 달라지는 알고리즘을 인터페이스로 추상화하고, 구성 방식을 활용해 갈아끼울 수 있도록 해 유연성을 증가시켰다. 아래 세가지 필드를 세터로 받는다.
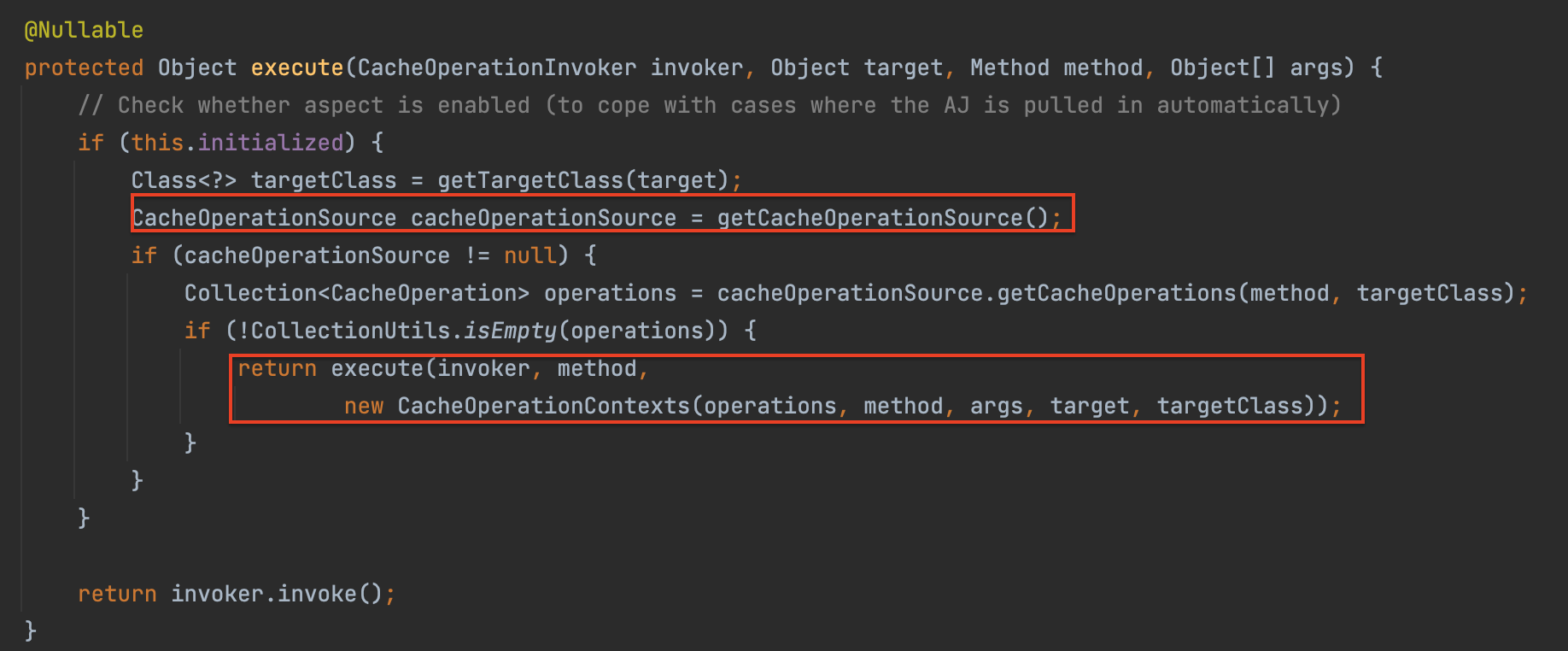
우선 주어진 메서드와 클래스에 대해 적용 가능한 모든 캐시 연산 (CacheOperation=@CachePut, @Cacheable, @CacheEvict 등 ) 들을 찾는다. 그리고 아래 과정들이 발생한다.
1. @Cacheable
- 메서드 결과를 캐시에 저장하고, 이 후 같은 파라미터로 메서드가 호출될 경우 캐시 된 결과를 반환한다. (읽기 작업)
2. @CachePut
- 메서드를 실행하고 그 결과를 캐시에 저장한다. (쓰기 작업)
3. @CacheEvict
- 캐시에서 하나 이상의 엔트리를 제거하며, 메서드가 실행된 후 지정된 키 또는 캐시 이름의 엔트리를 제거한다.
자세한 동작 과정을 직접 코드로 확인해보자.
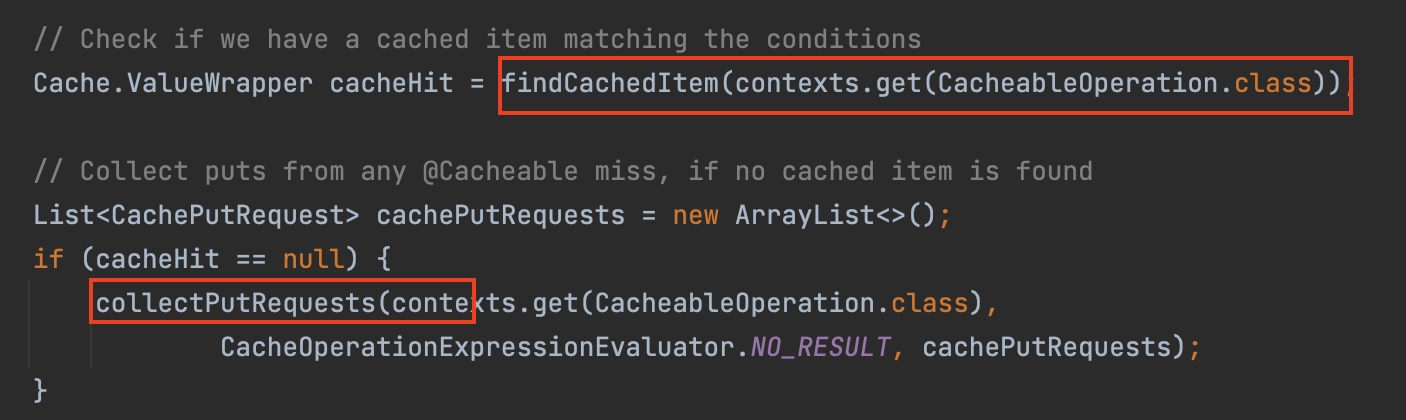
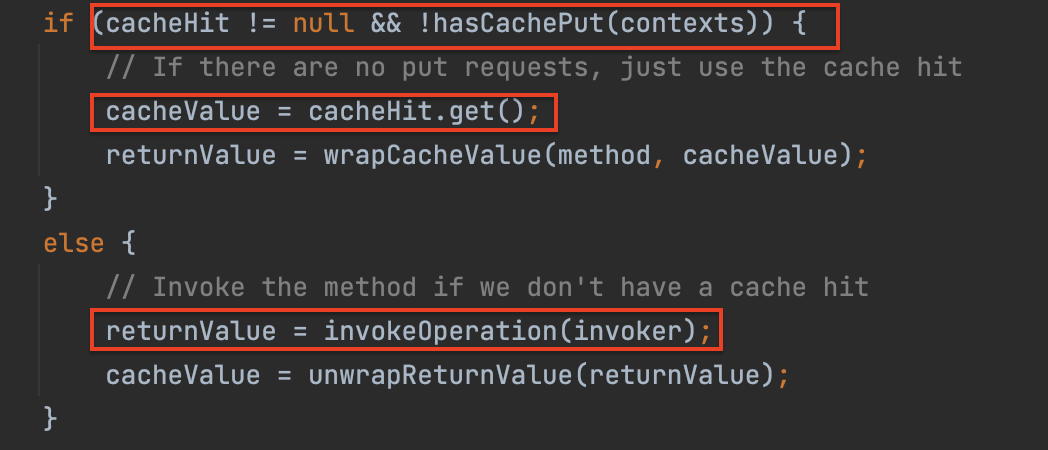
- 이미 캐시 데이터가 있는지 인메모리 DB에서 키 값으로 조회하여 확인하고, 캐시 미스가 난 경우
@Cacheable이 붙어있는 메서드들을 불러와서 이후 캐시를 업데이트하도록 쓰기 요청을 날리기 위해cachePutRequests에 추가해둔다.
-
캐시 히트가 발생했고 별도 저장 요청이 없다면 캐시에 있는 데이터를 가져와서 옵셔널 형태로 감싸서 바로 반환한다.
만약 그렇지 않다면invoke를 통해 실제 메서드를 실행시켜서 원본 저장소로부터 값을 받아오고, 반환 값을unwrap(옵셔널 형태라면get()을 하는 과정)한다.
-
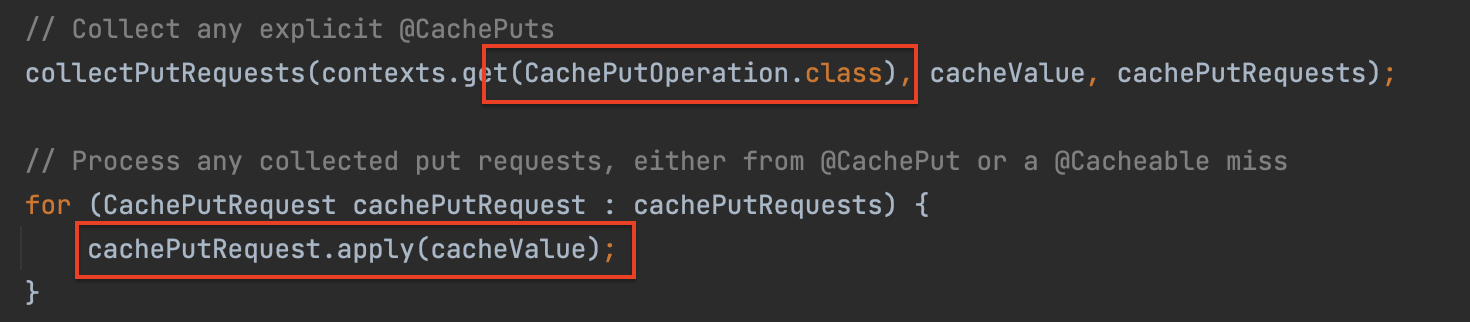
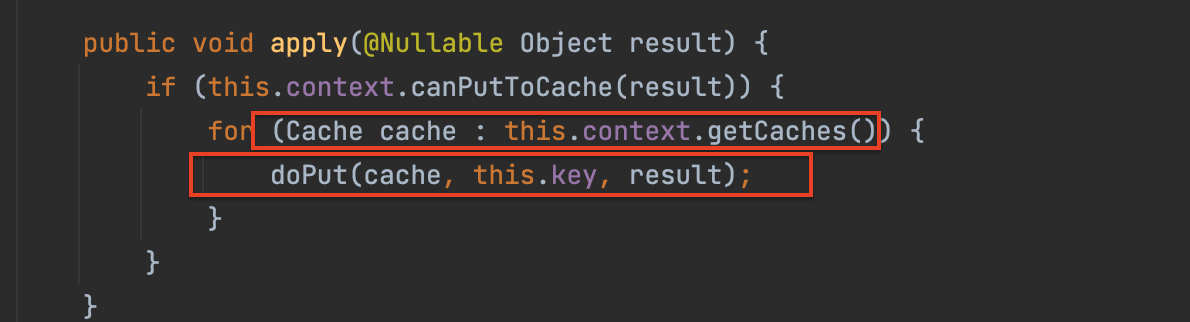
원본 저장소로부터 가져온 값을 업데이트 하기 위해 다시 인메모리 DB로 저장 요청을 날리는 과정이 수행된다. 이때 내부적으로
RedisCache가 동작해서 실제 쓰기 연산이 수행된다.

CacheResolver
CacheResolver 는 CacheManager 를 내부 필드로 가지고 있으며, 해당 클래스를 활용해 인터셉트된 메서드 호출에 사용할 캐시 인스턴스를 결정한다.
@FunctionalInterface
public interface CacheResolver {
Collection<? extends Cache> resolveCaches(CacheOperationInvocationContext<?> context);
}🧚🏻 직렬화를 하지 못하는 이슈
하지만, 단순히 @Cacheable 와 @EnableCaching 만 등록시켜놓으면 다음과 같은 에러가 나게 된다.
org.springframework.data.redis.serializer.SerializationException: Cannot serialize org.springframework.data.redis.serializer.JdkSerializationRedisSerializer.serialize
☁️ STEP 01: 직렬화 관련 이슈 해결하기
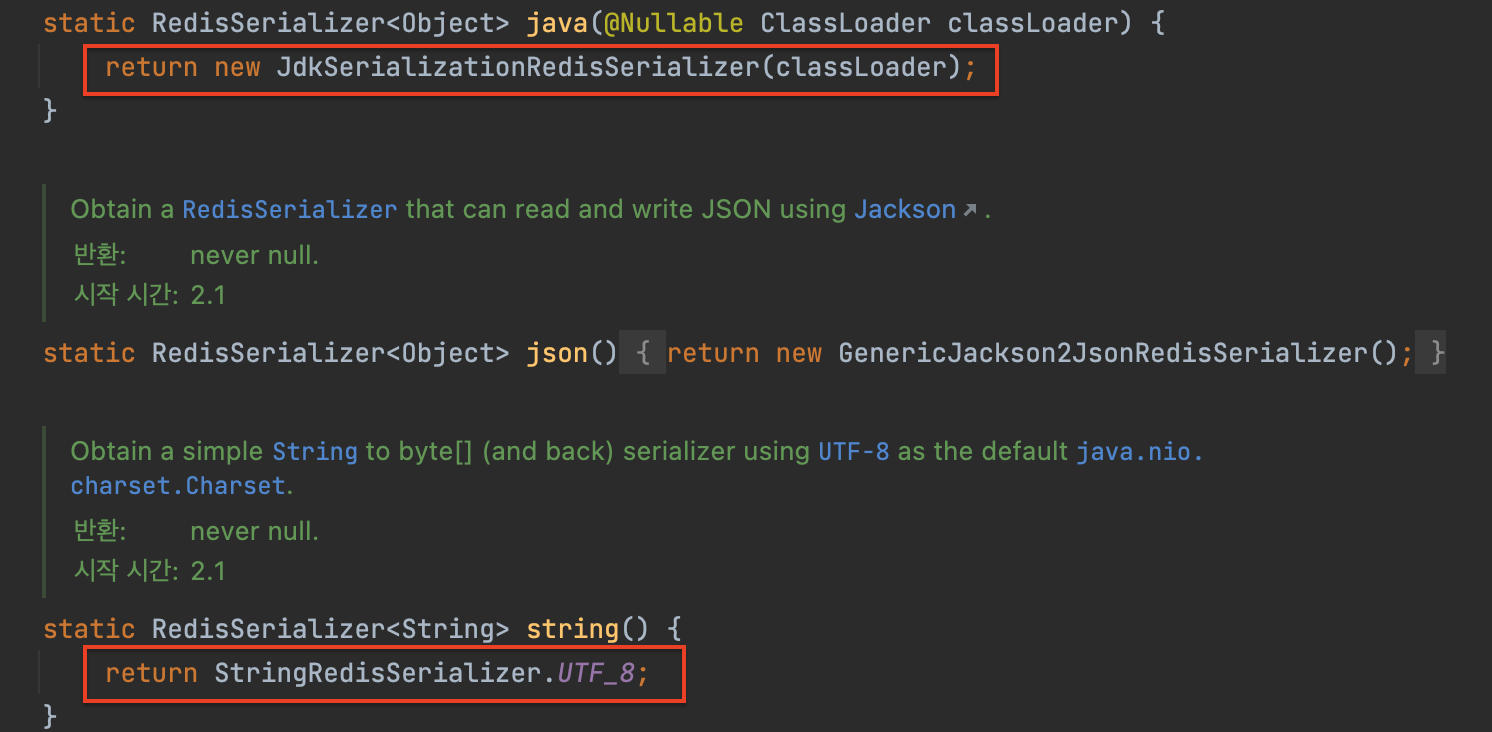
왜 직렬화에 실패했을까? 이유는 바로 우리가 따로 직렬화 구현체를 빈으로 등록하지 않으면, Default 로 JDKSerializationRedisSerializer 가 등록되기 때문이다.
실제로 디버깅해보면 RedisCacheConfiguration 에서 key 직렬화/역직렬화에는 StringRedisSerializer 를, value 에는 JDKSerializationRedisSerializer 를 기본값으로 채택하고 있는 것을 볼 수 있다.
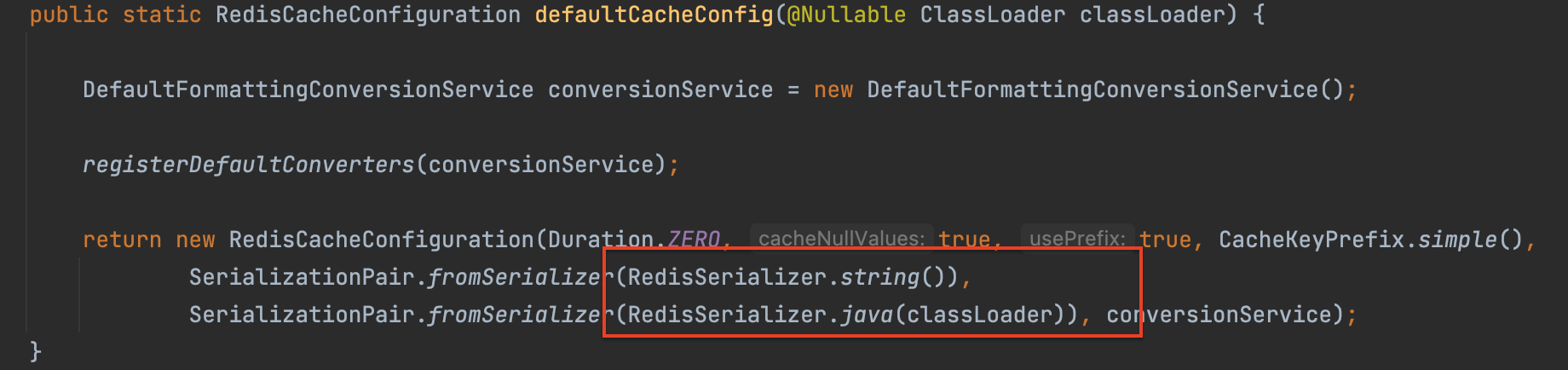
당연히 우리는 캐싱하려는 객체에 Seralizable 을 구현해주지 않았다. 따라서 직렬화를 할 수 없다는 에러가 났던 것이므로, 안전하게 UID 까지 붙여주면 성공이다.
class SearchSubwayLineDto {
data class Response(
val subwayLines: List<SubwayLine>
): Serializable {
companion object {
private const val serialVersionUID: Long = -4129628067395047900L
}
}
}
JDKSerializationRedisSerializer 단점
-
serialVersionUID설정을 하지 않으면, 자동으로 클래스의 구조와 필드 값을 활용해 만든 기본 해쉬값을serialVersionUID로 사용한게 된다.따라서 만약에 클래스 구조가 변경되면,
serialVersionUID값이 달라서 기존 저장 데이터의 역직렬화에 실패하게 된다. 하지만 이 역시serialVersionUID를 수동으로 설정해도 타입이 바뀌면 역직렬화 에러가 발생하고, 구조가 바뀌면 데이터가 누락되어 저장된다.즉 직렬화 구현은 언제 터질지 모르는 시한폭탄이 되버린다.
-
직렬화 데이터에 타입에 대한 모든 메타 데이터들까지 포함되기 때문에 용량이 커진다. 만약
Redis와 같은 인메모리 DB에 저장하게 된다면, 이는 고려 대상이 된다.
https://techblog.woowahan.com/2551/

나와 같은 경우 DTO 를 직렬화 시켜야 하므로 응용 계층에 인접한 특성상, 변경에 대한 여지가 높았다. 이처럼 자바 직렬화는 변경에 매우 취약하기 때문에 다른 직렬화 방식을 도입해보기로 했다.
☁️ STEP 02: 다른 직렬화 방식 사용
GenericJackson2JsonRedisSerializer 를 쓰도록 결정했다.
Jackson2JsonRedisSerializer: 직접 클래스 타입을 지정해주어야 해서 글로벌 설정에서는 한정적이였다.StringRedisSerializer: 매번ObjectMapper를 통해 인코딩과 디코딩을 해야 하는데 나와 같은 경우는@Cacheable때문에 스프링 내부에서 해당 과정이 일어나서 적합하지 않다고 판단했다.
.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(GenericJackson2JsonRedisSerializer(objectMapper))
)GenericJackson2JsonRedisSerializer
별도의 Class Type 을 지정할 필요 없이 자동으로 Object를 Json 으로 직렬화해주지만, 해당 Class Type 을 포함한 데이터까지 저장하게 된다는 단점이 존재한다.
이때, 문제가 되는 것이 해당 클래스의 패키지까지 함께 저장되게 되면서 만약 서버가 다수라면 해당 데이터를 역직렬화하기 위해서는 무조건 루트, 경로에 같은 이름으로 DTO Class를 생성해야만 에러가 나지 않는다.


문제 발생
하지만 위 코드와 같이 그냥 objectMapper 만 넣어주었더니 아래와 같은 문제가 발생했다.
java.lang.ClassCastException:
class java.util.LinkedHashMap cannot be cast to class backend.team.ahachul_backend.api.common.adapter.in.dto.SearchSubwayLineDto$Response
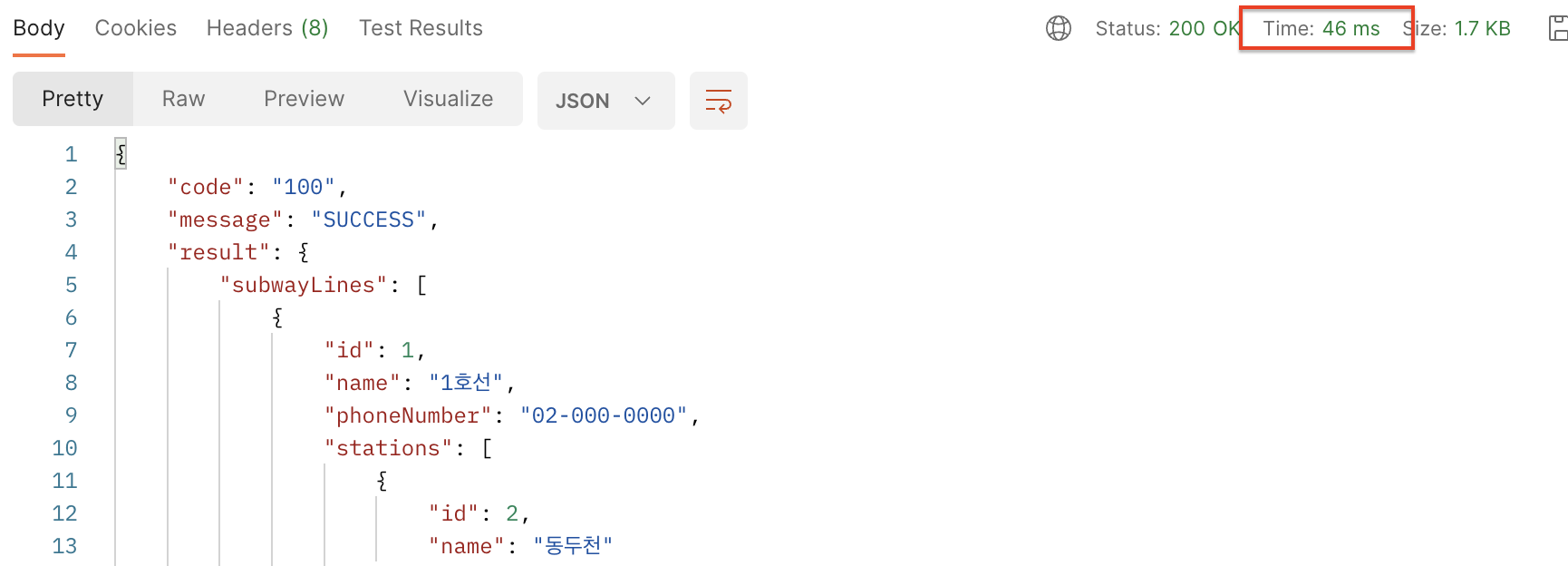
현재 저장하려는 데이터 구조는 다음과 같다. 하지만 이런 경우 objectMapper 가 원소 타입을 모르기 때문에, 역직렬화 시도에서 대상 유형 정보가 제공되지 않으면 기본 유형인 LinkedHashMap 을 사용하게 된다.
class SearchSubwayLineDto {
data class Response(
val subwayLines: List<SubwayLine>
)
data class SubwayLine(
val id: Long,
val name: String,
val phoneNumber: String,
val stations: List<Station>
)
}
따라서 objectMapper 에 따로 타입을 유추하도록 하는 설정, 즉 enableDeafultTyping 을 추가했다. ObjectMapper 는 기본적으로 직렬화/역직렬화 시 class type 정보를 포함하지 않기 때문에, 직렬화된 데이터에는 type 정보가 존재하지 않는다.
🔖 enableDefaultTyping
사용될 클래스의 타입을 지정하며, 명시적으로 유형 정보를 지정해주지 않은 경우에만 사용된다.
{
@Bean
fun redisCacheManager(redisConnectionFactory: RedisConnectionFactory, objectMapper: ObjectMapper): RedisCacheManager {
val validator = BasicPolymorphicTypeValidator.builder().build()
objectMapper.activateDefaultTyping(validator, ObjectMapper.DefaultTyping.NON_FINAL)
val configuration = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.serializeKeysWith(
RedisSerializationContext.SerializationPair
.fromSerializer(StringRedisSerializer()))
.serializeValuesWith(
RedisSerializationContext.SerializationPair
.fromSerializer(GenericJackson2JsonRedisSerializer(objectMapper))
)
return RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(configuration).build()
}하지만 또 다른 에러가 발생했으니.. JSON 관련 파싱 에러이다. 이 문제는 래퍼 클래스로 고쳤다고 하는데, 도무지 안고쳐져서 아예 objectMapper 를 제거해보았다.
Resolved [org.springframework.data.redis.serializer.SerializationException: Could not read JSON: Unexpected token (START_OBJECT), expected START_ARRAY:

☁️ STEP 03: ObjectMapper 전달 X
결국 objectMapper 를 내가 직접 지정해주는 과정에서 기존 GenericJackson2JsonRedisSerializer 의 로직에서 혼동이 생겼던 것 같다. 아예 생성자에 전달하지 않으니, 이제 위에서 봤던 에러는 나오지 않았다.
기본 생성자가 없는 이슈
Could not read JSON: Cannot construct instance of
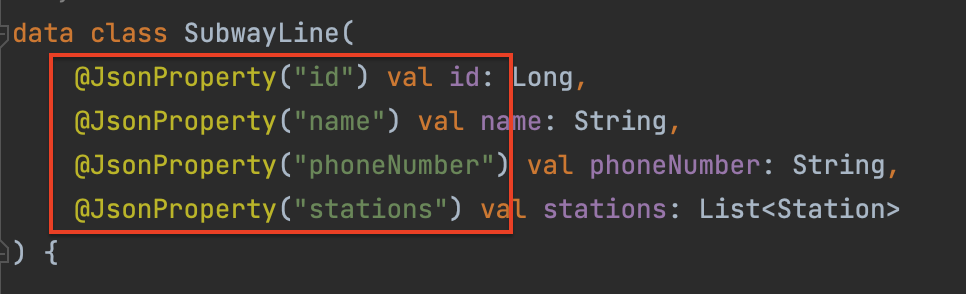
하지만 JSON 을 클래스의 인스턴스로 역직렬화 하는 과정에서 기본 생성자가 없다는 에러가 발생했다. kotlin data class 를 사용하고 있어서 롬복을 적용하지 못하는 상황이였고, 가장 간단한 방법인 @JsonProperty 를 적용해서 해결하였다.
🔖 @JsonProperty
해당 객체를 만드는 설명서 역할을Jackson에게 전달하는 방안 중 하나로, 기본 생성자가 없어도 해당 정보를 보고 자동으로 객체를 생성해낸다.
참고 자료
https://shanepark.tistory.com/374
https://stackoverflow.com/questions/72092382/does-redis-cache-have-advantage-over-spring-cache-if-used-only-for-simple-cache
