
최근 프로젝트에서 대용량 파일을 읽어올 일이 많이 생겼다. 파일을 읽어와서
Json형태로 변환을 해줘야 했기에 한줄을 읽어와서 편하게 처리할 수 있도록BufferedReader.readLine()을 사용했었다. 하지만 성능상 문제가 있다는 글을 보고, 메서드 별로 어떻게 동작하는지 궁금해서 작성해보는 글이다.
참고로 자바에서 I/O 는 모두 기본적으로 Blocking I/O 이다. Non-Blocking I/O 를 사용하고 싶다면 NIO 패키지에 존재하는 AsynchronusFileChannel 을 사용해야 한다.
우선, I/O 기본 동작 원리를 보면 다음과 같다.
JAVA I/O 가 어떻게 이루어지는가?
먼저 기본 OS의 I/O 에 대해 알아보자.
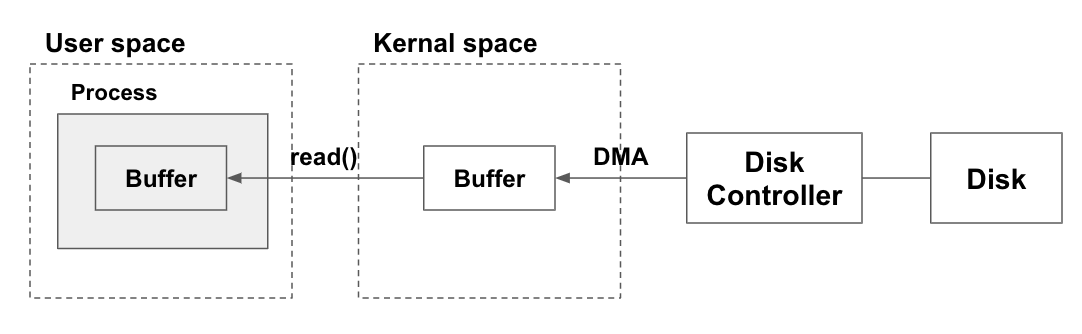
1. 사용자가 read() 요청
사용자 프로세스는 유저 영역에서만 동작하기 때문에, 하드웨어에 직접 접근하기 위해서는 파일을 읽어달라는 read() 시스템콜을 통해 I/O를 수행해야 한다.시스템콜이 수행되면, 컨텍스트 스위칭은 아니지만 CPU 모드 비트가 유저 모드에서 커널 모드로 스위칭된다.
이후 CPU 주도권을 잡은 커널이 1차적으로 커널 영역의 버퍼(캐시 메모리)에 요청한 데이터가 존재하는지 확인한다. 존재한다면 해당 데이터를 read() 호출 시 전달받은 메모리 영역에 복사하고 사용자 프로세스에게 다시 CPU 제어권을 양보한다.
하지만 이때 문제는, 커널 영역의 캐시 메모리에도 존재하지 않는다면 DMA를 통해 디스크로부터 데이터를 가져오는 과정이 추가되면서 느려진다.
2. 커널이 디스크 I/O를 요청
주의할 것이 CPU는 너무 많은 인터럽트에 효율적으로 작동하지 못하는 것을 막기 위해, 직접적으로 디스크에 접근하지 않는다.
대신 DMA Controller 라는 중간 계층을 두어, 대신해서 디스크로부터 직접 read / write 연산을 수행하도록 한다.
-
DMA Controller가 디스크에게 읽기를 요청하면, 실질적으로 각 장치에 달린Device Controller가 디스크에 접근한다. -
디스크 데이터 전송이 완료되면
DMA Controller는Device Controller버퍼에 저장된 데이터를 다시 커널 버퍼 메모리 영역에 블럭 단위로 복사 후 작업을 끝냈다는 CPU 인터럽트 수행한다. -
CPU 완료 인터럽트 발생을 감지한 CPU는, 커널 영역 버퍼 메모리의 데이터를 다시 유저 영역 버퍼 메모리에 복사한 뒤
read()과정을 종료한다. (유저 프로세스가 Spring Boot 였다면 JVM 힙 메모리에 복사가 될것이다.) 그제서야Block되어 있단 유저 프로세스 상태가 풀리고, 사이후 요청한 데이터를 사용할 수 있게 된다.
이 모든 과정동안 자바에서 read() 를 호출하면 스레드가 block 상태로 멈춰있게 되니, 오랜 시간 스레드가 점유되는 문제가 발생할 것이다.
가상 메모리를 사용하는 방식
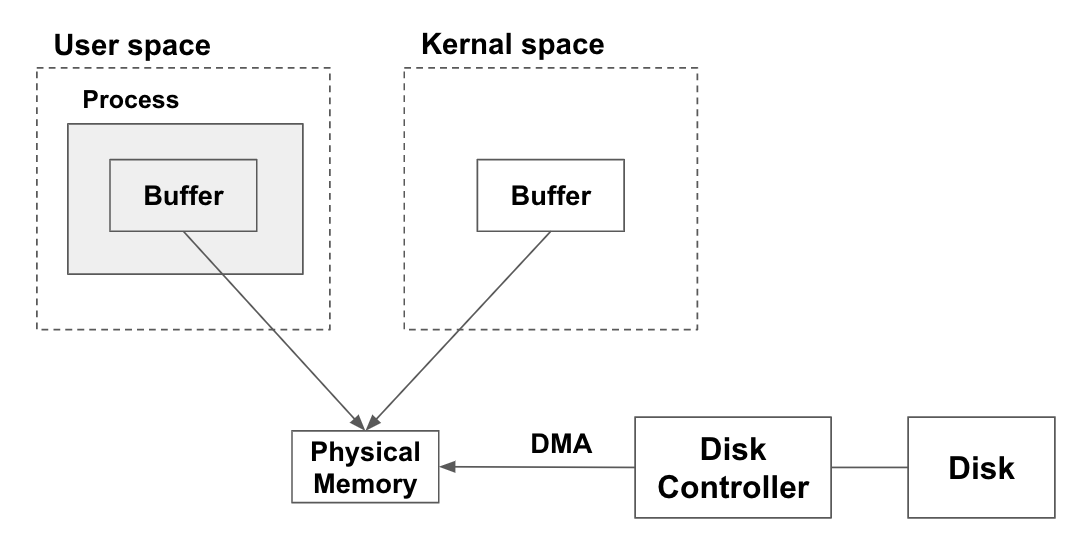
가상 메모리의 장점은 다음과 같다.
- 1개 이상의 가상 주소가 실제로 같은 물리 메모리 위치와 연결될 수 있다.
- 가상 메모리 크기는 실제 디스크 크기 보다 클 수 있다.
이러한 장점을 활용한다면, Disk Controller 가 하나의 물리 메모리 영역에다가만 데이터를 복사해두고 유저 영역의 버퍼와 커널 영역의 버퍼가 이를 참조하는 형태로 둘 수 있다. 즉 커널 영역에서 유저 영역으로 다시 한번 복사하는 과정이 줄어들어 메모리도 아끼고 성능도 좋아진다.
물론 이때 버퍼의 크기는 블럭(페이지) 사이즈의 배수여야 한다.
하지만 자바에서는 가상 메모리를 통한 커널 <-> 사용자 영역 간 메모리 공유가 불가능하다는데, 자세한 이유는 더 찾아봐야 할 것 같다.
FileInputStream

버퍼가 존재하지 않는 단방향 스트림이다.
흔히
BufferedInputStream이 더 성능이 좋다 하는 것은read()처럼1바이트씩 파일을 읽어왔을 때 이야기이다.
read(byte[] b) 메서드를 사용한다면, BufferedInputStream 을 사용했을 때 같은 버퍼 사이즈라는 가정 하에 성능 차이가 나지 않기 때문에 사실상 똑같다.
따라서 만약 파일과 같이 적절한 버퍼 사이즈(파일 크기)를 정할 수 있는 상황이라면 FileInputStream 을 사용하고, 웹상의 파일 전송과 같이 정확한 버퍼 사이즈를 모르겠다면 BufferedInputStream 를 사용하는 것이 좋다. (서버는 content-length 필드를 제공하지 않는다)
BufferedInputStream
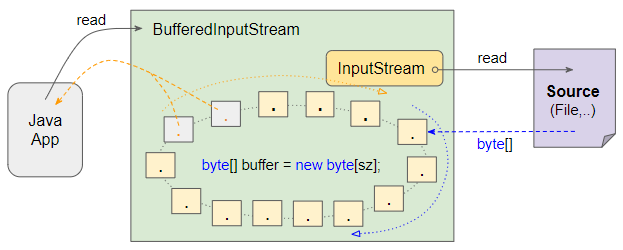
JAVA I/O 동작 과정의 그림과 같이 버퍼가 존재하는 단방향 스트림이다. 버퍼를 사용하기 때문에 높은 성능을 보여준다.
예를 들어 파일 크기가 32768 바이트이고, 버퍼 사이즈가 8192 바이트라고 해보자.
-
FileInputStream.read()
시스템 콜 호출이32768번 일어난다. -
BufferedInputStream.read()
시스템 콜 한번에8192사이즈 만큼의 버퍼에 데이터가 복사되기 때문에, 총 4번의 시스템 콜만 호출된다. 이후 내부 버퍼에서 차례대로 하나씩 데이터를 가져온다.
BufferedReader VS BufferedInputStream
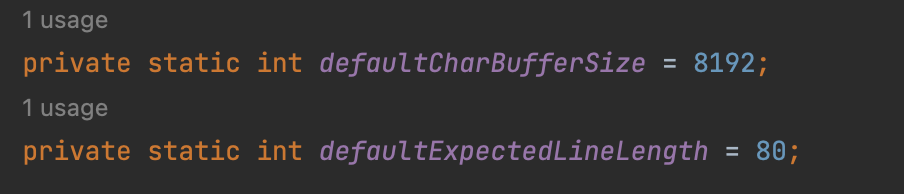
BufferedReader 가 BufferedInputStream 보다 통상 느리다고 하는 이유는 문자열로 반환문자 디코딩 작업이 추가되어 있기 때문이다. 디코딩 작업은 다음과 같이 동작한다.
- 2중 루프를 돈다. 첫번째 루프는 버퍼를 돌고, 두번째 루프는 해당 버퍼에서 한줄씩 읽기 위해
\n과 같은 문자가 나오기 전까지 탐색하는 로직이다.
BufferLoop: // 버퍼 전체를 탐색한다.
CharLoop: // 한 줄을 탐색한다.- 처음 생성한
StringBuilder인스턴스에 문자를 추가하고, 바로String으로 변환하기 때문에 문자당 두 개의 복사본이 생성된다.
String readLine(boolean ignoreLF, boolean[] term) throws IOException {
...
String str;
if (s == null) {
str = new String(cb, startChar, i - startChar);
} else {
s.append(cb, startChar, i - startChar);
str = s.toString(); // 계속 해서 새로운 문자열 객체를 생성해낸다.
}
...
}따라서 BufferedReader.readLine() 은 모든 I/O 중에 메모리 사용률도 현저히 높다. 속도도 당연히 느릴 것이라 생각하고 테스트를 해봤는데, 예상 밖의 결과가 나왔다.
각 file i/o 별로 속도 테스트하기
먼저 굉장히 큰 파일을 하나 생성해준다.
리눅스 기준으로 all.json1, all.json2.. all.jsonX 파일이 있다고 할 때 다음과 같이 기존 파일의 크기를 5배 불린 파일을 만들 수 있다.
ls all.json* | xargs cat > total-all.json 300MB 정도의 파일 기준으로 테스트해보았다.
1. BufferedInputStream_read()
@Test
fun buffered_input_stream_read_test() {
var totalCnt = 0
val start = System.currentTimeMillis()
BufferedInputStream(FileInputStream(readPath)).use { stream -> // read() -> buffer 크기 만큼 채워서 하나씩 가져온다.
while (stream.read() != -1) { // default buffer size = 8192 byte = 2^13
totalCnt += 1
}
}
val end = System.currentTimeMillis()
println("time : ${end - start}, total read cnt : $totalCnt") // 6
}
BufferedInputStream 의 read() 메서드는 4초 정도 걸렸다.
2. BufferedReader_read()
@Test
fun buffered_reader_read_test() {
var totalCnt = 0
val start = System.currentTimeMillis()
BufferedReader(FileReader(readPath)).use { reader ->
while (reader.read() != -1) {
totalCnt += 1
}
}
val end = System.currentTimeMillis()
println("time : ${end - start}, total read cnt : $totalCnt")
}BufferedReader 의 read() 메서드 역시 4초 정도 걸렸다.

3. BufferedReader_readLine()
@Test
fun buffered_reader_read_line_test() {
var totalCnt = 0
val start = System.currentTimeMillis()
BufferedReader(FileReader(readPath)).use { reader ->
var line: String?
while (reader.readLine().also { line = it } != null) {
totalCnt += 1
}
}
val end = System.currentTimeMillis()
println("time : ${end - start}, total read cnt : $totalCnt")
}놀랍게도, BufferedReader 의 readLine() 메서드는 1초 정도 걸렸다.

왜 이렇게 성능에서 큰 차이가 나는지 나름대로 분석을 해보았다.
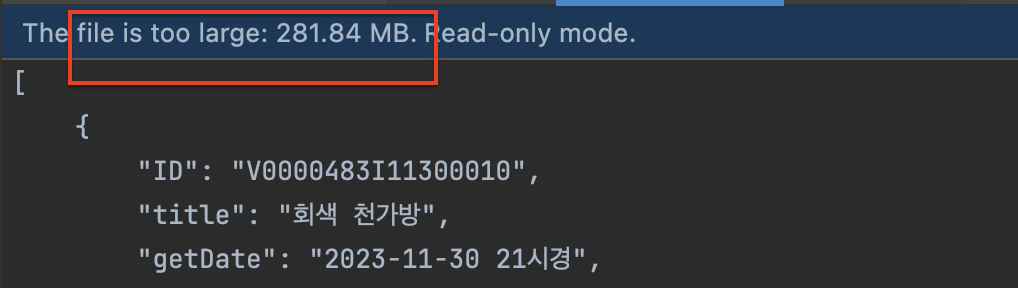
현재 읽어오려는 파일이 다음과 같은 형식인데, 아마 한줄 당 길이가 너무 짧아서 2중 반복문이 아니고 1중 반복문만 도는 시간 복잡도가 나왔을 거라 추정한다.
[
{
"ID": "V0000483I11300010",
"title": "회색 천가방",
"getDate": "2023-11-30 21시경",
"getPlace": "신창(순천향대)역(한국철도공사)",
"type": "가방 > 기타가방",
"receiptPlace": "신창(순천향대)역(한국철도공사)",
"storagePlace": "신창(순천향대)역(한국철도공사)",
"lostStatus": "보관중",
"phone": "041-543-7788",
"context": "...",
"image": "https://www.lost112.go.kr/lostnfs/images/sub/img04_no_img.gif",
"source": "lost112",
"page": "https://www.lost112.go.kr/find/findDetail.do?ATC_ID=V0000483I11300010&FD_SN=1"
},
...
]물론 메모리 사용량이 매우 높은거는 사실이다. 아직까지는 이로 인해 메모리 초과 등의 문제가 발생하지 않아서 우선 문자열을 처리하기 쉽도록 readline() 을 선택하고, 이후 문제가 발생하면 조금 느리더라도 메모리 사용량이 적은 read() 로 리팩토링해야겠다.
NIO 패키지에 속해있는 FileChannel, AsynchronusFileChannel 은 다음 시간에 알아보도록 하자.
참고자료
https://howtodoinjava.com/java/io/how-java-io-works-internally/
https://stackoverflow.com/questions/17473863/how-bufferedinputstream-makes-the-read-operation-faster
https://docs.oracle.com/javase/8/docs/api/java/io/BufferedReader.html
