결론부터 말하자면, HashSet 역시 내부적으로 HashMap 을 사용해서 동작한다. 그리고 HashMap 은 해시 테이블 기반으로 동작한다.
☁️ HashMap
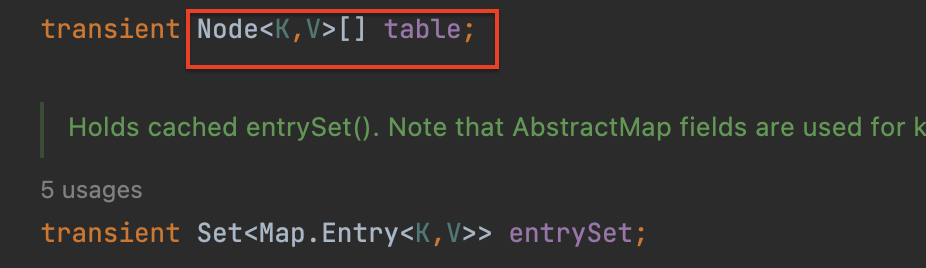
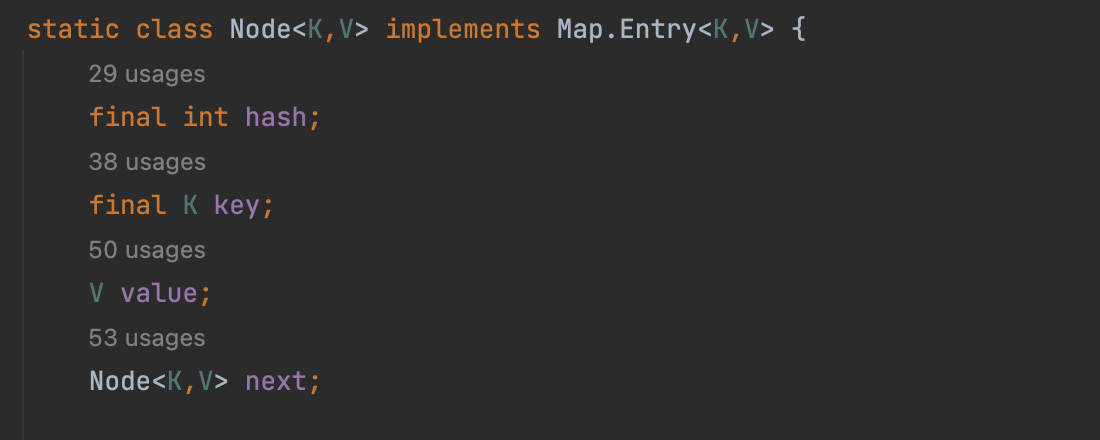
자바에서 해시맵은 Node 객체의 배열 을 저장소로 활용한다. Node 클래스는 해싱한 결과값, 키, 값, 그리고 Seperate Chaining 을 위한 다음 노드를 가리키기 위한 Node 객체 를 필드로 가진다.
저장 연산
key 로 들어온 값을 해싱하고, 그 결과값을 배열의 인덱스 로 사용해서 값을 집어넣는다.

사용되는 해시 함수는 다음과 같다.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}☁️ HashSet
해시셋도 해시맵을 내부적으로 사용하면, 대체 다른 점이 뭔가?
앞서서 Node 클래스에 Key 와 Value 필드가 있었다.
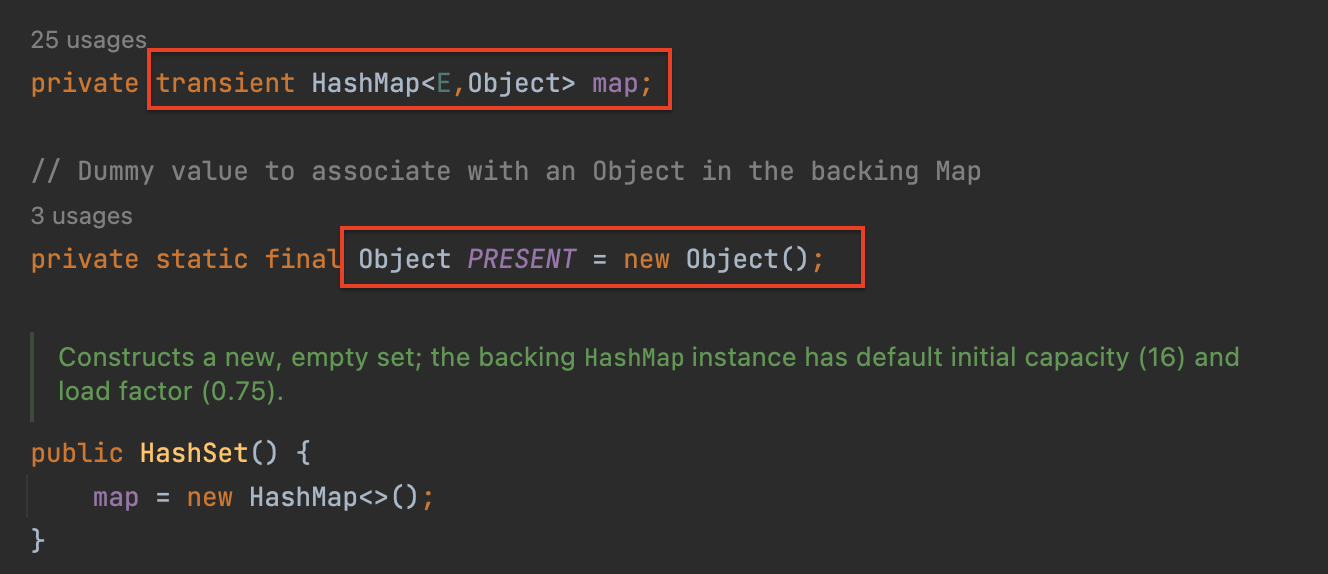
HashSet은 Key 자체에 Set에 넣으려는 해당 객체 가 들어가고, 객체의 해시값이 인덱스 로 사용된다. 즉 value 에는 아래에서 볼 수 있듯이 비어 있는 객체가 들어간다는 차이가 있다.

해시 자료구조에서 데이터의 중복을 판별하는 법
해시 맵이나, 해시셋이나 해시 충돌을 파악해서 후처리를 해야 한다.
- 해시 맵은 해시 충돌이 일어난다면 데이터를 이어서 붙이던지(
seperate chaining), 빈 공간에 넣던지(open adressing) 등의 처리를 한다. - 해시 셋은
Set자료구조의중복 불가특성을 고려함에 있어서 기존에 있던 값과 원래 있던 값이 같은지 파악해야 한다.
즉 새로 들어온 객체와 기존에 존재하는 객체가 정말 주소값도, 논리적인 값도 일치하는지 판단해야 한다. 그리고 바로 해당 근거를 판단하는 기준으로 hashCode 와 equals 를 사용한다.
- hashCode() 를 통해 객체 고유의 값을 비교한다. 같으면 2번 과정으로 넘어간다.
- equals() 를 통해 논리적인 값까지 비교한다.
다시 한번 코드로 봐보자!
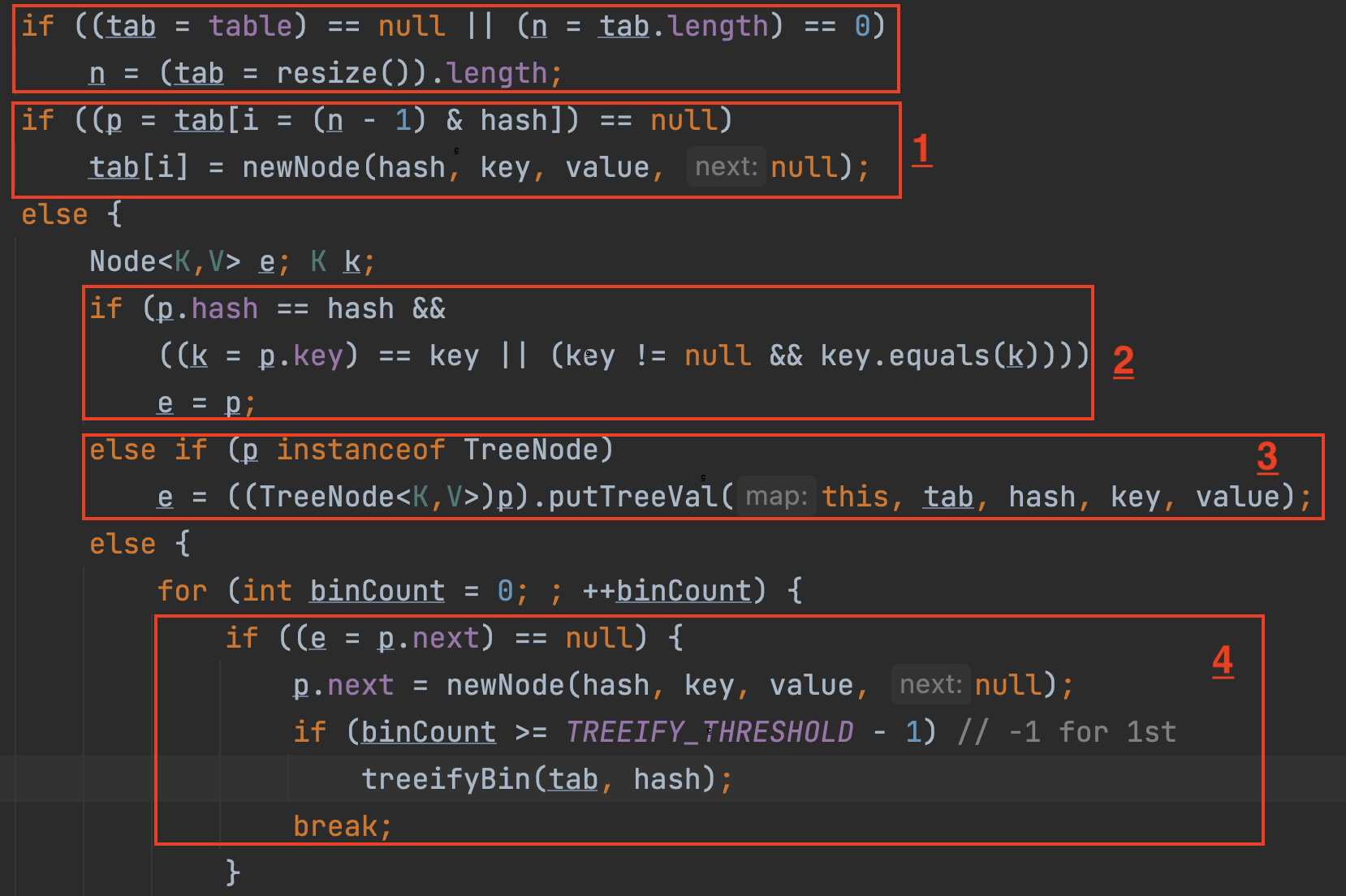
e 는 새롭게 바꿔치기 할 노드, p 는 기존 해시 테이블에 있던 값을 의미한다.
-
해시값으로 찾은 배열의 인덱스에 값이 아직 없다면(null) 새롭게 할당을 한다. -
이미 해시 테이블에 값이 존재한다면,
Key 중복을 판별한다.- 해시값 동일 여부 판단
- 키 값으로 넣으려는 객체의 주소값 판단
- 키 값으로 넣으려는 객체의 논리적 동등성 판단
기존에 존재하는 데이터와 함수 인자로 넘어온
key를 비교해서 완벽하게 같다면 기존 노드가 그대로 대체된다. 해당 과정에서hashCode()와equals()가 활용된다. -
만약
Key가 완벽하게 같은 노드가 아니라면,seperate chaining이 일어난다. 레드 블랙 트리의 노드 구조인TreeNode의 인스턴스일 경우 트리에 값을 추가한다.
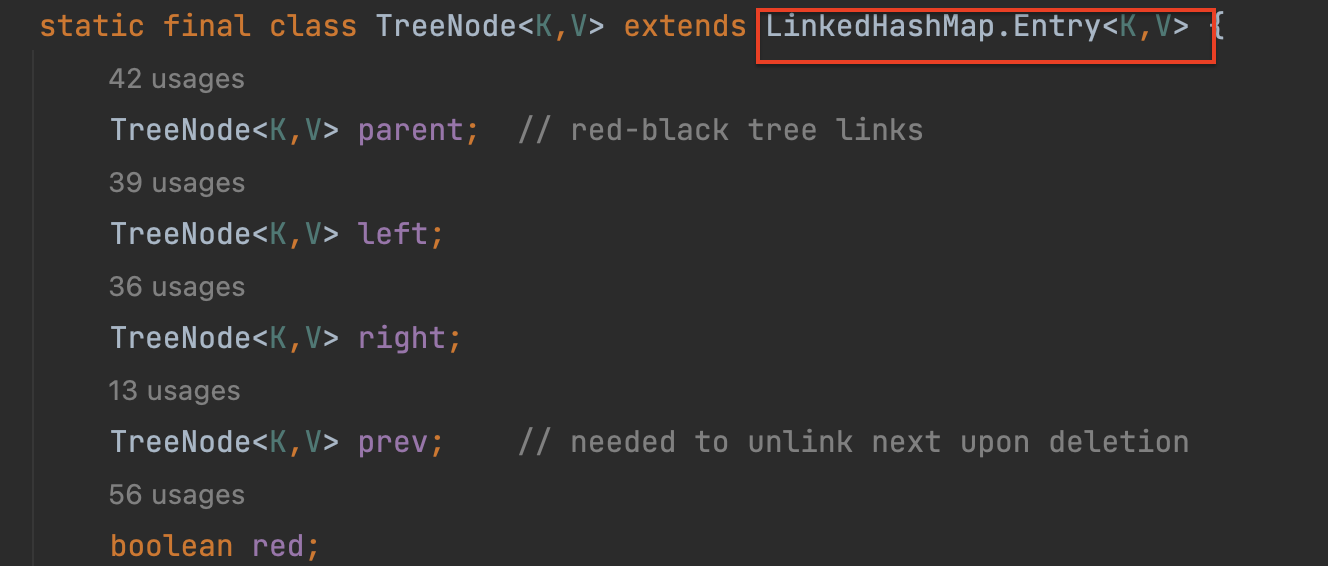
- 만약
Key가 완벽하게 같은 노드가 아닌데TreeNode의 인스턴스가 아니라면, 연결 리스트 형태로 노드를 추가해나가다가 총 사이즈가TREEIFY_THRESHOLD값인8개 이상이 된다면 트리 형태로 바뀌는 작업이 일어난다.

☁️ LinkedHashMap
추가적으로, LinkedHashMap 은 해시맵에 넣은 순서가 보장이 되는 자료구조이다. 내부적으로 Doubly-Linked List 형태로 구현되어 있다.
어떻게 순서를 보장할 수 있을까?
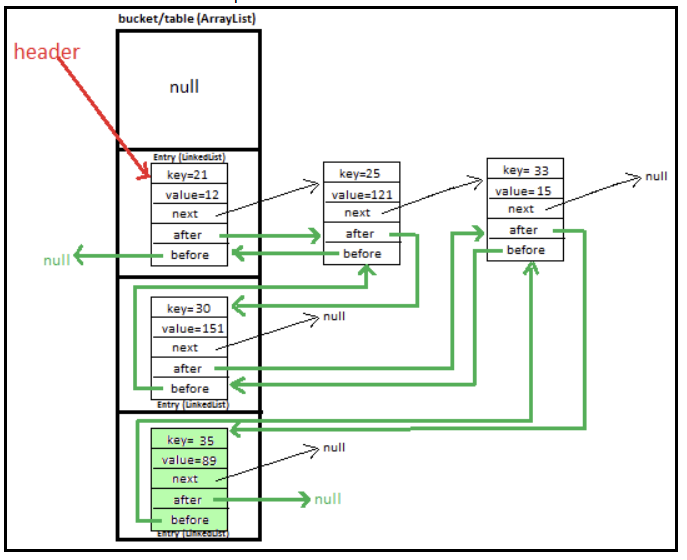
Entry 클래스는 현재 값을 담고 있는 기본 노드 에, 이전을 가르키는 노드 하나와 다음을 가르키는 노드 로 구성되어 있다.

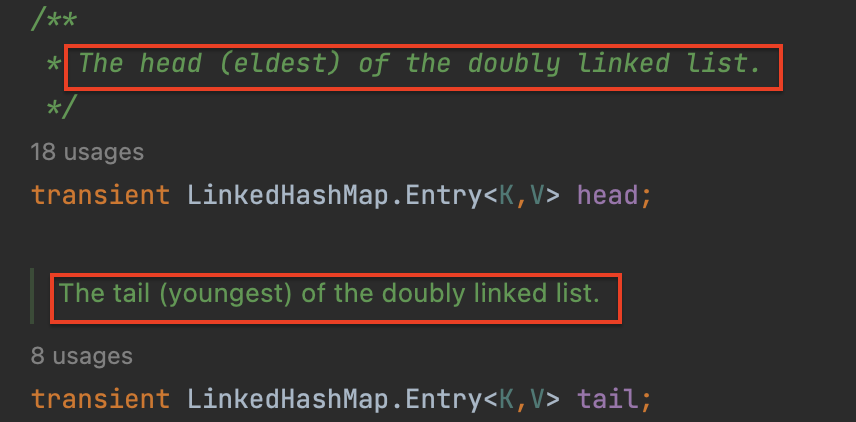
기본 노드에 들어있는 next 포인터는 seperate chaining 방식에서 사용될 연결 리스트의 다음 노드를 가르키는 역할을 한다.
반면 Entry 클래스에 들어있는 before, after 포인터는 키 충돌 발생과 관계 없이 추가되는 순서대로 연결이 되도록 가르키는 역할을 하므로 넣은 순서를 기억할 수 있는 것이다.
만약 새로운 노드가 추가된다고 가정해보자.
tail노드가null, 즉 아무런 데이터가 없다면 첫 번째로 들어오는 데이터를header로 설정한다.- 이미 데이터가 존재한다면 넣으려는 데이터의
before이 기존에 존재했던 마지막Entry를 가리키게 하고, 마지막 존재했던Entry의next를 본인으로 설정해서 연결한다.
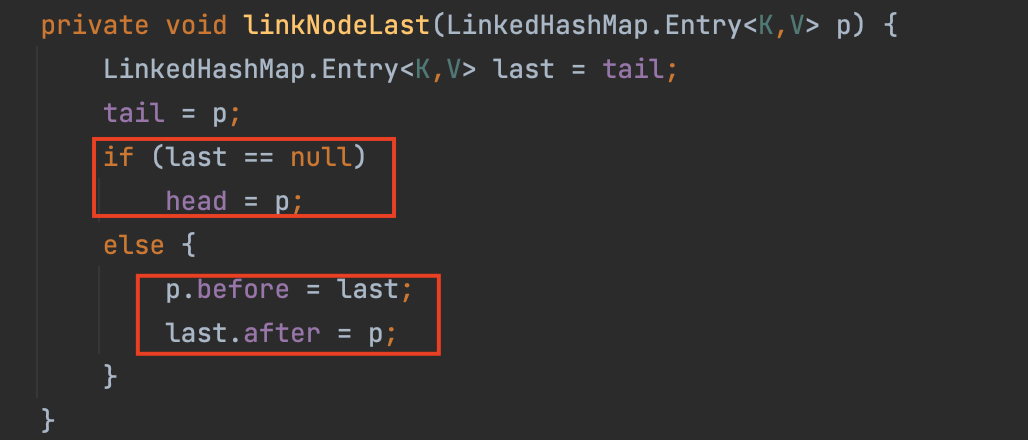
구조를 그림으로 보면 다음과 같다.