DB & SQL
1.RDBMS와 SQL

RDBMS와 SQL, 그리고 DW에 대해서 알아보자
2.Cloud와 AWS

Cloud와 AWS에 대해서 알아보자
3.[SQL] 기초
SQL의 기본 사용법, SELECT, COUNT, WHERE, GROUP BY, 타입 변환에 대해 알아보자
4.SQL 엔진 사용

Python notebook을 sql editor처럼 사용하는 방법python 코딩과 섞어서 진행 가능하다는 장점이 있다.위는 Redshift postgresql를 예시로 작성%sql 뒤에 Redshift 클러스터 정보를 위와 같이 입력함으로써 연결할 수 있다.%%sq
5.[SQL] 기초 2
GROUP BY와 집계함수, CTAS, CTE와 VIEW에 대해서 알아보자
6.[SQL] 기초 3
JOIN, Boolean과 Null의 비교 및 처리, ROW_NUMBER 함수에 대해서 알아보자
7.In-Memory DB vs. Disk-Based DB
In-Memory DB 와 Disk-Based DB 차이점이 뭘까?
8.Redis 와 Memcached
Redis와 Memcached, 어디에 쓰이는 걸까?
9.[SQL] FIRST_VALUE / LAST_VALUE / NTH_VALUE
그룹별 n번째 레코드 구하기
10.[SQL] DELETE FROM / TRUNCATE / DROP TABLE
셋 모두 데이터를 삭제한다는 점에서 공통점이 있다.다만 그 세부적인 작동 방법과 내용에 차이가 있다.테이블에서 레코드를 삭제WHERE절을 통해 일부 레코드만 삭제 가능속도가 느림DML테이블에서 레코드를 전부 삭제WHERE 사용 불가능트랜잭션 지원하지 않음전체 삭제 명령
11.[SQL] 기초 4 - 트랜잭션, 기타 고급 문법
Atomic하게 실행되어야 하는 쿼리를 묶어 하나의 작업처럼 처리하는 방법Ex. 은행 계좌이체 → 인출 + 입금 으로 구성 → 둘 다 성공하든지 둘 다 실패해야 함레코드 수정/추가/삭제 등에만 의미가 있음조회는 데이터가 변하지 않아 의미가 없음BEGIN - END 혹은
12.[DB/SQL] SP(Stored Procedure) 기초
“저장 프로시저”의 약자로, 데이터베이스에 저장해두고 반복적으로 실행할 수 있는 SQL 쿼리의 집합이다.반복 작업을 함수처럼 미리 정의해두고 재사용 가능여러 쿼리를 미리 컴파일해서 실행 → 속도 개선애플리케이션에서 직접 SQL을 조작하지 않고 SP만 호출 → 보안성 향
13.[DB/SQL] MySQL 실습 환경 구성
Docker 통해 MySQL 이미지를 다운받아 컨테이너를 구성컨테이너에서 MySQL 실행DBeaver를 사용해 MySQL에 접속DockerMySQL을 격리된 안전한 공간에서 실행설치가 간편 (로컬에 직접 설치 ❌)테스트/학습 환경 분리버전 변경 쉬움 (다른 MySQL
14.[DB/SQL] 테이블 설계 (정규화, 인덱스, 제약조건)
테이블을 중복 없이 논리적으로 잘게 나누는 과정데이터 무결성 보장 → 여러 테이블의 데이터가 변경시 자동 업데이트데이터 중복 제거 → 유지보수 용이저장 공간 절약 → 중복 데이터가 감소하면서 효율적 저장관계 명확화 → 테이블 간의 관계가 분리되어 설계 명확화1NF (제
15.[DB/SQL] 옵티마이저(Optimizer)
SQL 쿼리를 가장 효율적으로 실행하기 위해 DB가 내부적으로 실행 계획을 최적화하는 컴포넌트동일한 결과를 반환하는 여러 실행 경로 중 가장 빠른 방법을 선택비용(Cost), 통계(Statistics), 인덱스 정보 등을 바탕으로 판단 ➡️ 옵티마이저가 엉뚱한 선택을
16.[DB/SQL] 복합키/대체키 PK 지정과 성능
데이터들을 보다 보면 복합키로 PK를 구성할 수 있음에도 ID 컬럼을 만들어 사용하는 경우를 자주 확인할 수 있다.왜 이렇게 사용하는걸까? 장점이 뭘까??두 개 이상의 칼럼으로 구성된 기본키의미 없는 고유 ID를 인위적으로 부여한 키ex) 단순 증가 숫자, UUIDRD
17.[DB/SQL] DBMS와 MSSQL 기본 이해
데이터를 체계적으로 저장하고 관리하며, 필요할 때 쉽게 꺼내 쓸 수 있도록 도와주는 소프트웨어주요 역할데이터 저장데이터 조회 (SELECT)데이터 수정 (INSERT, UPDATE, DELETE)데이터 무결성 유지 (제약 조건)동시성 제어 - 여러 사용자가 동시에 데이
18.[DB/SQL] 데이터베이스 설계 기초 (ERD, 정규화, 인덱스, 파티셔닝)
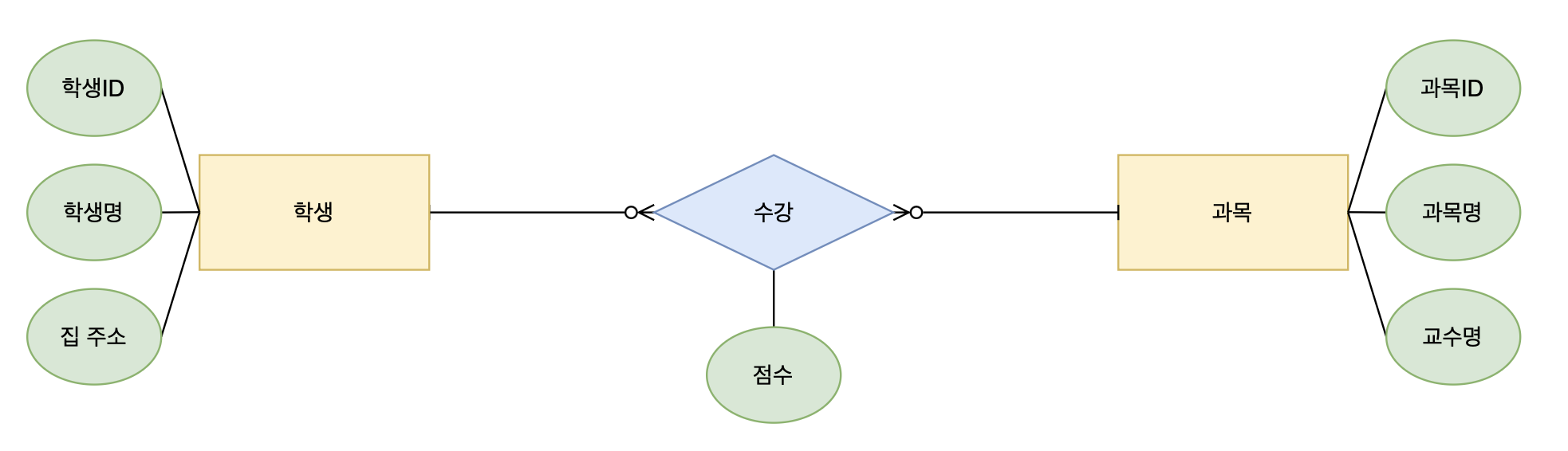
Entity-Relationship Diagram현실 세계의 정보를 추상화해서 표현한 데이터 모델엔터티 Entity독립적으로 존재하는 객체 (테이블)ex) 학생, 과목, 수강속성 Attribute엔터티가 가지는 특성 (컬럼)ex) 학생ID, 학생명, 과목ID, 교수명관
19.[DB/SQL] 성능 튜닝 기초
시스템 리소스를 효율적으로 사용하여 응답 시간 향상, 처리량 증대, 비용 절감을 도모하는 작업쿼리 튜닝SQL 문 자체를 개선불필요한 연산 제거JOIN 순서 최적화EXISTS vs. IN인덱스 튜닝인덱스를 전략적으로 설계B-Tree/해시 인덱스, 복합 인덱스, 커버링 인
20.[DB/SQL] JOIN 알고리즘
중첩 반복 조인한쪽 테이블의 각 행마다 다른 테이블을 검색 → 외부 루프 / 내부 루프외부 루소량의 데이터 조인에 적합외부 루프에서는 무조건 전체를 순차 탐색하고,내부 루프는 외부 테이블 행마다 조건에 맞게 탐색→ 내부 테이블에 인덱스가 있다면 빠름 (외부 테이블 인덱
21.[DB/SQL] 트리거 Trigger
테이블에 INSERT, UPDATE, DELETE 같은 이벤트가 발생할 때 자동으로 실행되는 저장 프로시저이벤트트리거를 호출할 DML 작업INSERT, UPDATE, DELETE일부 DBMS에서는 DDL 트리거(CREATE, ALTER, DROP) 또한 사용 가능시점B
22.[DB/SQL] 트랜잭션과 동시성 제어
Transaction하나의 논리적 작업 단위데이터베이스에서 모두 성공하거나 모두 실패해야 하는 연산 집합A - Atomicity - 원자성전부 수행되거나 전부 수행되지 않아야 함C - Consistency - 일관성트랜잭션 전후에 데이터 무결성이 유지되어야 함I - I
23.[DB/SQL] 백업과 복구 기초
데이터베이스의 현재 상태를 안전하게 복사하여 보관하는 행위장애, 삭제, 손상 등 비상상황에서 데이터를 복구하기 위한 대비백업 파일은 따로 저장백업 파일을 이용해 데이터베이스를 특정 시점의 상태로 되돌리는 행위실제 장애 발생 후 정상 상태로 복원백업 파일을 읽어 DB에
24.[DB/SQL] Stored Procedure의 처리 흐름 (에러 핸들링 / 커서)
MySQL 기준클라이언트 요청 (CALL 프로시저)DB 서버에서 SP 실행매개변수 처리 ( IN / OUT / INOUT )BEGIN ~ END 내부 SQL 로직 순차 실행필요 시 트랜잭션, 조건문, 반복문, 예외처리 수행OUT / INOUT 결과 반환클라이언트에 결과
25.[DB/SQL] 실습: MySQL 기반 유저 리워드 시스템 - 기초 구현

테이블 설계SP 설계커서 활용 반복 처리조건 분기 기반 포인트 지급 로직로깅을 통한 결과 추적SP 호출유저 테이블에서 특정 조건을 만족하는 유저에게 포인트 지급지급 대상이 아닌 경우 지급하지 않고 로깅레벨이 5 이상이라면 50 포인트를 지급레벨이 5 미만이라면 포인트
26.[DB/MSSQL] OUTPUT과 DELETED, INSERTED
INSERT, UPDATE, DELETE, MERGE문과 함께 사용되며, 각 DML문에 처리되는 행을 반환하는 문법INTO 구문을 통해 TABLE/TEMP TABLE에 해당 햅을 삽입deleted 타겟 테이블 row의 변경 전/삭제 행을 반환하는 접두사 insert
27.[DB/SQL] 조인튜닝 - 소트머지조인
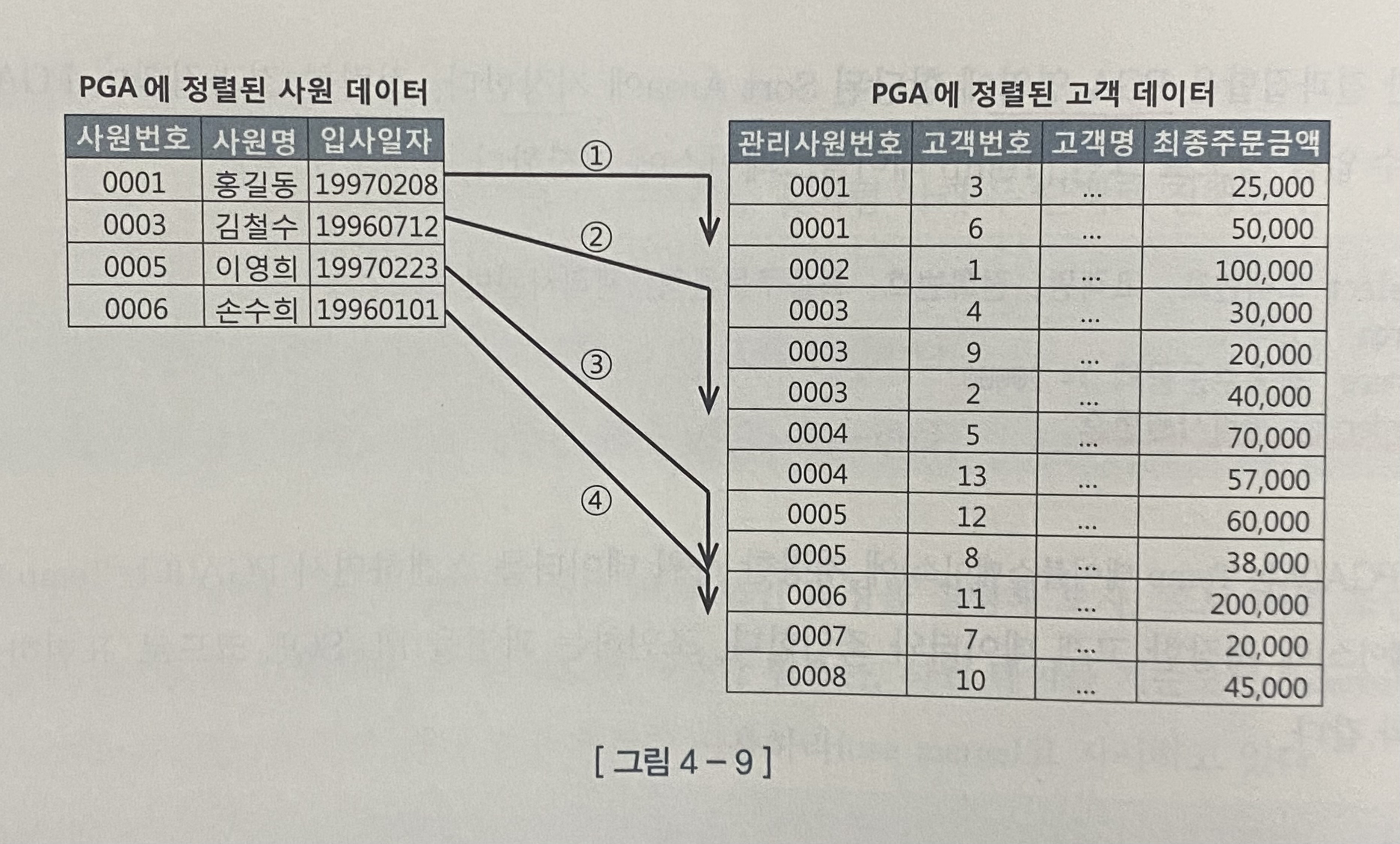
친절한 SQL 튜닝 4. 조인튜닝SGA (System/Shared Global Area)공유 메모리 영역여러 프로세스가 공유 가능 but 동시에 액세스 불가한 데이터 저장프로세스 간 액세스를 직렬화 > 래치 메커니즘PGA (Process/Program/Private G