
이번주는 카카오맵 프런트엔드, 백엔드 둘 다 개발하는데에 집중했다. 강사님 멘토링, 현업 멘토링 2차례 멘토링을 받았고, DDD OT를 진행했다.
https://www.data.go.kr/data/15083033/fileData.do
가맹점 더미 데이터 만들기 (공공 데이터 포탈)
데이터의 필요 이유
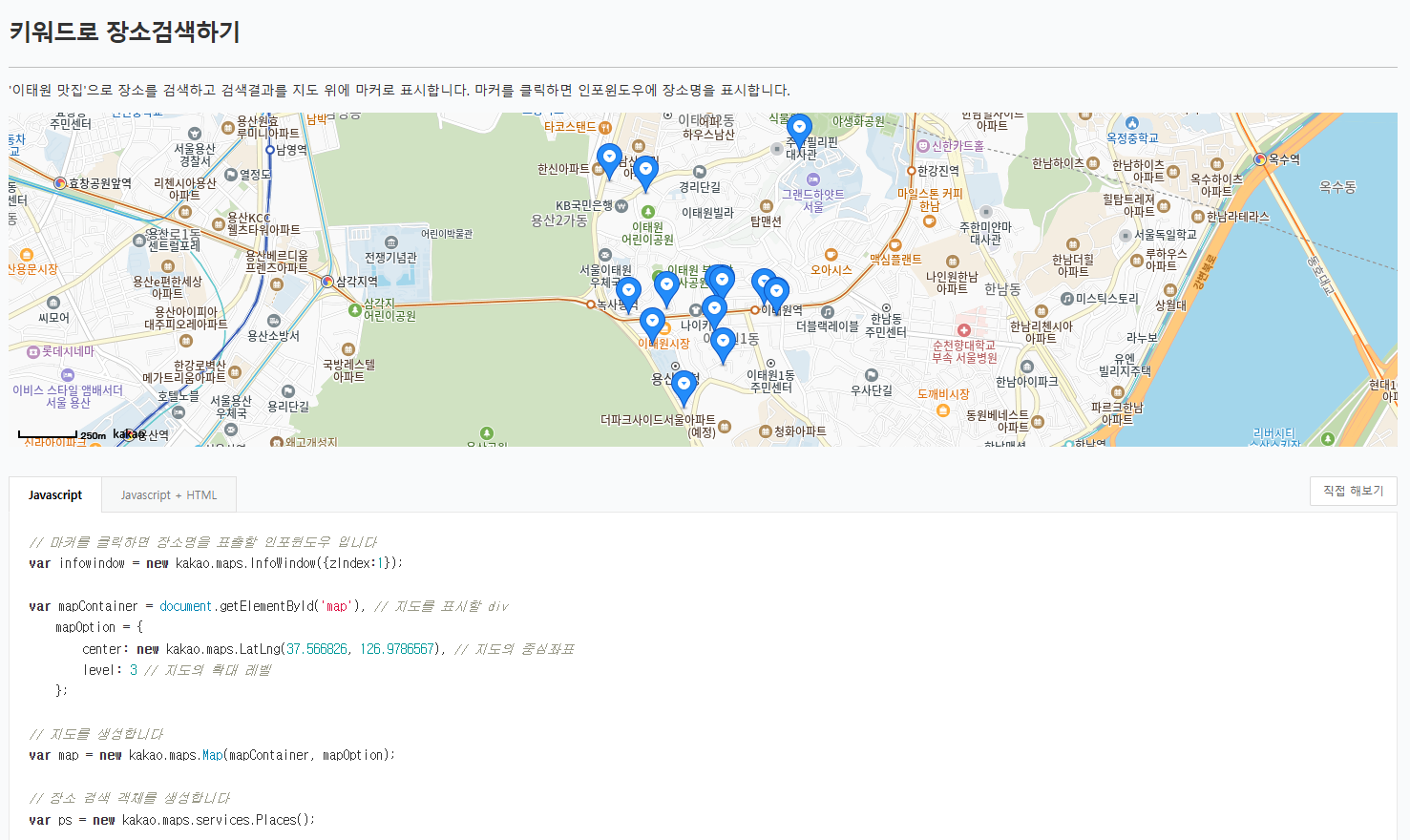
사실 카카오맵에서 상점 정보를 API를 제공하고 있다.
검색 키워드,카테고리로 주변 장소를 검색하는 API를 제공하고 있지만 카테고리 값이 우리가 설정해둔 값과 달랐고 우리는 지도에 사용자가 소유한 바우처를 결제할 수 있는 가맹점만을 조회하고 싶었다.
카카오맵 API를 사용하면 우리가 원하는 조건을 걸 수 없었기에 직접 상점 데이터를 구해야했고 공공데이터에서 데이터를 엑셀파일로 불러왔다.
근데 어떻게 DB에 넣지?
Excel 파일을 막상 받아왔는데 용량이 상당했다 각 파일은 지역별로 구분되어있고 강원도만 해도 최소 백만개의 상점이 있었고, 불필요한 정보를 거르고 Region,Store로 분리해서 데이터를 입력해야했다.
든든한 GPT에게 물어봤고, Python 코드를 짤 줄 모르는 나지만 덕분에 엑셀파일을 읽고 DB에 입력하는 코드를 프롬프팅해서 얻어냈다.
예시 코드 (DatabaseManager)
class DatabaseManager:
def __init__(self):
self.conn = pymysql.connect(
host='DB_HOST',
user='USER',
password='PW',
database='DB',
charset='utf8mb4',
port=PORT,
autocommit=False
)
self.cursor = self.conn.cursor()
print("✅ DB 연결 완료")
def close(self):
self.cursor.close()
self.conn.close()
print("🔌 DB 연결 종료")
def commit(self):
self.conn.commit()
def rollback(self):
self.conn.rollback()
class DataLoader:
def __init__(self, data_path: str = 'data'):
self.data_path = data_path
self.csv_files = [f for f in os.listdir(data_path) if f.endswith('.csv')]
def read_csv(self, file_name: str, columns: List[str] = None) -> pd.DataFrame:
dtypes = {
'시도코드': str,
'시도명': str,
'시군구코드': str,
'시군구명': str,
'상호명': str,
'도로명주소': str,
'신우편번호': str,
'경도': float,
'위도': float,
'상권업종대분류명': str
}
usecols = columns if columns else None
return pd.read_csv(
os.path.join(self.data_path, file_name),
encoding='utf-8',
dtype=dtypes,
usecols=usecols,
na_values=['', 'NULL', 'nan'],
keep_default_na=True,
low_memory=False
)
@staticmethod
def prepare_store_data(df: pd.DataFrame,
category_map: Dict[str, int],
region_map: Dict[Tuple[str, str, str, str], int],
batch_size: int = 50000) -> List[Tuple]:
try:
# 데이터 타입 변환
df['경도'] = pd.to_numeric(df['경도'], errors='coerce')
df['위도'] = pd.to_numeric(df['위도'], errors='coerce')
# 결측치 처리
df['신우편번호'] = df['신우편번호'].fillna('')
df['도로명주소'] = df['도로명주소'].fillna('')
# 필터링할 카테고리
excluded = ['부동산', '소매', '수리', '시설관리']
df = df[~df['상권업종대분류명'].isin(excluded)].copy()
# 지역 ID 매핑
df['region_key'] = df.apply(
lambda x: (
str(x['시도코드']).strip(),
str(x['시도명']).strip(),
str(x['시군구코드']).strip(),
str(x['시군구명']).strip()
),
axis=1
)
df['region_id'] = df['region_key'].map(region_map)
# 카테고리 ID 매핑
df['category_id'] = df['상권업종대분류명'].map(category_map)
# 유효한 데이터만 선택
df = df.dropna(subset=['region_id', 'category_id']).head(batch_size)
# 데이터 변환 - 스키마 순서에 맞게 조정
store_data = []
for _, row in df.iterrows():
try:
lon = float(row['경도']) if pd.notna(row['경도']) else None
lat = float(row['위도']) if pd.notna(row['위도']) else None
if lon is not None and lat is not None:
store_data.append((
lat, # latitude
lon, # longitude
None, # created_at
None, # merchant_id를 null로 설정
int(row['region_id']),
int(row['category_id']),
str(row['신우편번호'])[:255],
str(row['도로명주소'])[:255],
str(row['상호명'])[:255]
))
except (ValueError, TypeError) as e:
print(f"⚠️ 데이터 변환 오류 (무시됨): {e}")
continue
return store_data[:batch_size]
except Exception as e:
print(f"❌ 데이터 준비 중 오류 발생: {e}")
return []
class DataImporter:
def __init__(self, db: DatabaseManager, data_loader: DataLoader):
self.db = db
self.data_loader = data_loader
def init_mappings(self) -> Tuple[Dict, Dict]:
# 카테고리 데이터 삽입
categories = [
('01', '음식'),
('02', '의료'),
('03', '서비스'),
('04', '관광/여가/오락'),
('05', '숙박'),
('06', '교육')
]
self._insert_categories(categories)
# 지역 데이터 준비 및 삽입
required_columns = ['시도코드', '시도명', '시군구코드', '시군구명']
region_dfs = []
for f in os.listdir('data'):
if f.endswith('.csv'):
try:
df = self.data_loader.read_csv(f, columns=required_columns)
region_dfs.append(df)
except Exception as e:
print(f"⚠️ {f} 파일 읽기 중 오류: {e}")
continue
sample_df = pd.concat(region_dfs).drop_duplicates()
regions = [
(str(row['시도코드']).strip(),
str(row['시도명']).strip(),
str(row['시군구코드']).strip(),
str(row['시군구명']).strip())
for _, row in sample_df.iterrows()
if pd.notna(row['시도코드']) and pd.notna(row['시군구코드'])
]
self._insert_regions(regions)
return self._load_mappings()
def _insert_categories(self, categories: List[Tuple[str, str]]):
try:
sql = "INSERT INTO store_category (code, name) VALUES (%s, %s)"
self.db.cursor.executemany(sql, categories)
self.db.commit()
print(f"✅ {len(categories)}개 카테고리 입력 완료")
except Exception as e:
print(f"❌ 카테고리 입력 실패: {e}")
self.db.rollback()
def _insert_regions(self, regions: List[Tuple]):
try:
sql = "INSERT INTO region (sido_code, sido_name, sigungu_code, sigungu_name) VALUES (%s, %s, %s, %s)"
self.db.cursor.executemany(sql, regions)
self.db.commit()
print(f"✅ {len(regions)}개 지역 입력 완료")
except Exception as e:
print(f"❌ 지역 입력 실패: {e}")
self.db.rollback()
def _load_mappings(self) -> Tuple[Dict, Dict]:
# 카테고리 매핑
self.db.cursor.execute("SELECT id, name FROM store_category")
category_map = {row[1]: row[0] for row in self.db.cursor.fetchall()}
# 지역 매핑
self.db.cursor.execute("SELECT id, sido_code, sido_name, sigungu_code, sigungu_name FROM region")
region_map = {
(str(row[1]).strip(), str(row[2]).strip(), str(row[3]).strip(), str(row[4]).strip()): row[0]
for row in self.db.cursor.fetchall()
}
return category_map, region_map
def bulk_insert_stores(self, stores: List[Tuple], batch_size: int = 1000):
if not stores:
return
sql = """
INSERT INTO store
(latitude, longitude, store_name, road_address, new_zipcode,
store_category_id, region_id, location)
VALUES (%s, %s, %s, %s, %s, %s, %s, POINT(%s, %s)) \
"""
for i in range(0, len(stores), batch_size):
batch = stores[i:i + batch_size]
try:
formatted_batch = []
for store in batch:
if store[0] is not None and store[1] is not None: # latitude, longitude 체크
formatted_batch.append((
store[0], # latitude
store[1], # longitude
store[8], # store_name
store[7], # road_address
store[6], # new_zipcode
store[5], # store_category_id
store[4], # region_id
store[1], # longitude for POINT
store[0] # latitude for POINT
))
if formatted_batch:
self.db.cursor.executemany(sql, formatted_batch)
self.db.commit()
except Exception as e:
print(f"❌ 입력 실패: {e}")
self.db.rollback()
def main():
try:
# 초기화
db = DatabaseManager()
data_loader = DataLoader()
importer = DataImporter(db, data_loader)
# 기초 데이터 입력 및 매핑 로드
category_map, region_map = importer.init_mappings()
# CSV 파일별 처리
for csv_file in data_loader.csv_files:
print(f"\n📂 처리 시작: {csv_file}")
# 데이터 준비
df = data_loader.read_csv(csv_file)
stores = DataLoader.prepare_store_data(
df, category_map, region_map, batch_size=50000
)
# 데이터 삽입
importer.bulk_insert_stores(stores)
print(f"✅ {csv_file} 처리 완료")
except Exception as e:
print(f"❌ 오류 발생: {e}")
sys.exit(1)
finally:
db.close()
if __name__ == "__main__":
main()
우린 개발계 DB에 데이터를 채워넣고 마운트 해놨지만 실수로 jpa만 create로 해도 쉽게 날아가 버리기 때문에 불상사를 막기 위해서 cron으로 DB를 백업하도록 스케줄러를 돌려놨다. 최근에 내가 실수로 날려먹었는데 복구를 하면서 cron을 해두길 정말 정말 잘했다고 생각했다.
굳이 스케줄러까지 돌려야 하나 싶지만 데이터의 용량이 꽤 되다보니까 bulk insert를 해도 DB에 입력하는데까지 꽤나 시간이 소요됐다. 이 과정에 소요되는 시간이 너무 아까워서 백업까지 생각하게 됐다.
Tokkit 지도 마커와 오버레이 만들기
검색된 위치를 표시해주는 마커에 이미지를 넣을 수 있어서 우리 서비스의 캐릭터를 넣고 싶었다!
가맹점을 조회하는거니까 일하고 있는 토끼를 넣었다 ㅋㅋㅋ 처음엔
처음에는 이렇게 빨간색으로 했는데 줌 레벨을 축소시키면 잘 안보여가지구 색을 변경했다
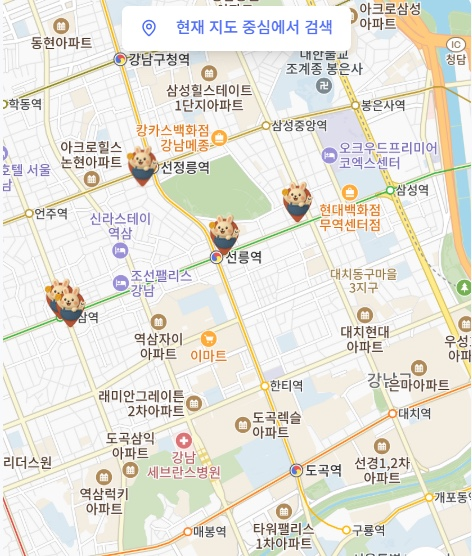
주변 가맹점 조회 API 구현
가맹점 조회는 Join을 통해 유저가 소유한 바우처를 사용가능한 상점을 조회해온다. 문제는 좌표에 대한 검색인데 우리는 Mysql의 ST_DISTANCE_SPHERE 함수를 사용하여 검색을 시행하는데 이런 특수한 함수로 인해 JPA와 JQPL을 사용할 수 없었다. 심지어 QueryDSL도 그래서 NativeQuery로 직접 써주는 방법뿐이었는데 쿼리가 너무 길어서 Mybatis처럼 쿼리를 분리하여 관리할 방법이 없는지 찾아보고 이에 대한 리뷰를 요청했었다!
Query를 따로 저장하려면 Procedure라는걸 써서 쿼리를 DB에 미리 저장해두는 방법이 있었다. 근데 이렇게 하면 팀원의 로컬 디비에도 매번 Procedure를 저장해줘야 하기 때문에 너무 비효율적이라고 생각해서 그냥 현재 상태를 유지하기로 했다.
ST_DISTANCE_SPHERE 함수란?
MySQL에서 제공하는 지리 함수 중 하나로, 두 지점 사이의 거리를 구하는 데 사용한다.구의 표면을 이용하여 두 지점 사이의 최단 거리를 계산하고 이를 미터로 환산해준다.
Spatial_Index 적용
이런 좌표 자료형에 대한 검색 인덱스가 따로 존재했다. 그게 스페이셜 인덱스였고 데이터도 직접 넣은김에 성능도 고려해서 인덱스를 알아보고 적용하려고 했다. 말처럼 쉽지 않았고 결국 인덱스는 적용하지 못했습니다 ㅠㅠ
왜 자꾸 Full Scan?
EXPLAIN SELECT ...
WHERE ST_Distance_Sphere(...) <= 1000Explain을 써서 쿼리를 실행해보았는데 계속해서 Type이 ALL로 나와 풀 스캔을 하고 있다는걸 알게 되었다. 원인을 찾아보니까 인덱스를 적용하는 좌표인 location 컬럼의 SRID를 4613으로 지정해주어야 한다고 한다.
SRID는 좌표계의 형식 id이다 위도 경도를 다루는 여러가지 형식이 있는데 그중 하나인 것 같습니다
여전히 인덱스 미적용
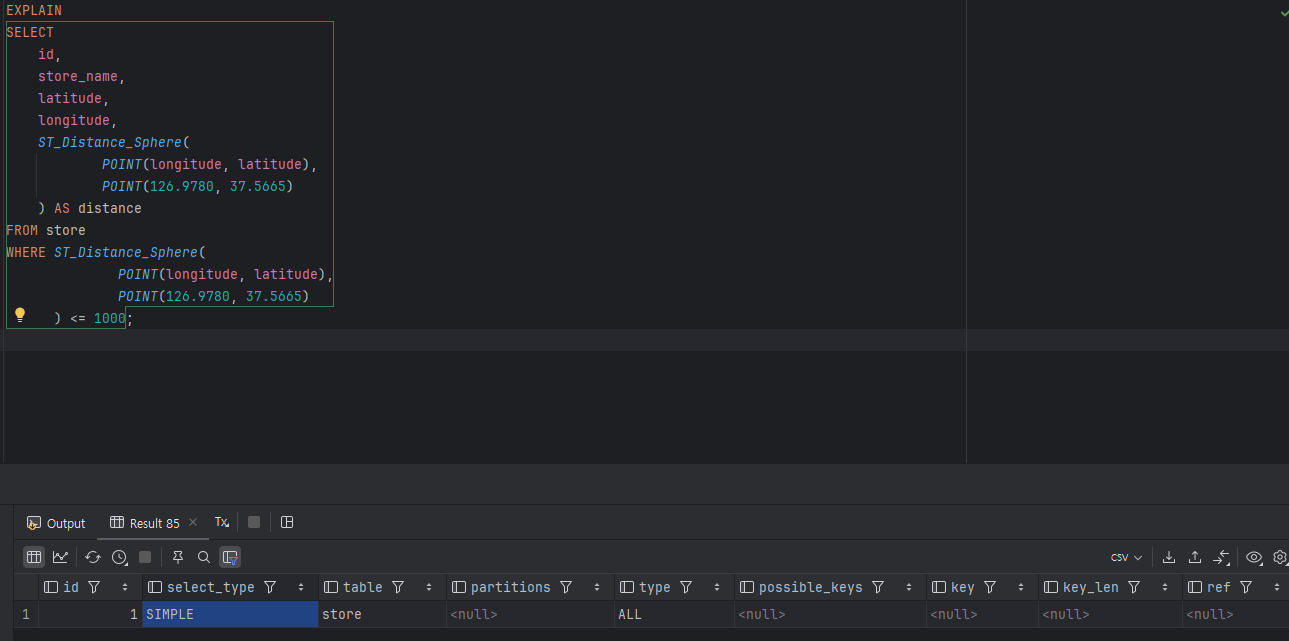
SRID도 넣고 인덱스도 다시 만들었는데...
ST_Distance_Sphere(...) 쓰니까 또다시 ALL 풀스캔
바보 엔딩
ST_Distance_Sphtere는 좌표 간의 거리 계산을 직접 수행하는 함수여서 Spatial_Index가 적용되지 않는 함수라고 하더라구요.. 그래서 MYSQL 옵티마이저가 인덱스를 활용할 수 없어서 계속 풀스캔이 났던 하하 공부좀 하고 도입했다고 생각했는데 여전히 많이 부족한것 같아요 다음엔 더 고민하고 투입을 해야겠더라구요 그래도 열심히 했으니까 한잔해
1. API 설명
카카오맵에서 userId를 기준으로 wallet, voucher_ownership, voucher_store, store 테이블을 조인하여, 사용자가 소유한 바우처와 관련된 매장을 특정 반경 내에서 검색하는 기능인데, 추가적으로 카테고리와 키워드로 필터링해주는 API
2. 현재 코드 첨부
2.1 StoreRepository 코드
@Repository
public interface StoreRepository extends JpaRepository<Store, Long> {
@Query(value =
SELECT s.*,
ST_Distance_Sphere(POINT(s.longitude, s.latitude), POINT(:lng, :lat)) AS distance
FROM wallet w
JOIN voucher_ownership vo ON w.id = vo.wallet_id
JOIN voucher_store vs ON vo.voucher_id = vs.voucher_id
JOIN store s ON vs.store_id = s.id
WHERE w.user_id = :userId
AND ST_Distance_Sphere(POINT(s.longitude, s.latitude), POINT(:lng, :lat)) <= :radius
AND (:category IS NULL OR s.category = :category)
AND (:keyword IS NULL OR s.name LIKE %:keyword% OR s.address LIKE %:keyword%)
ORDER BY distance
, nativeQuery = true)
List<Object[]> findNearbyStores(
@Param("userId") Long userId,
@Param("lat") double lat,
@Param("lng") double lng,
@Param("radius") double radius,
@Param("category") String category,
@Param("keyword") String keyword
);
}3. JPQL을 못 쓰는 이유
JPQL은 JPA 표준 쿼리 언어로, 데이터베이스 독립성을 유지하기 위해 특정 DB 함수(ST_Distance_Sphere)를 지원하지 않습니다.
→ 아래는 Sphere라는 Mysql의 좌표 기반 검색 함수를 안 쓰면 하버사인이라는 물리? 수학 공식을 적용해야하는데 유지보수가 빡세서 Sphere를 선택함. 따라서, JPQL을 사용할 수 없음.
/**
* 주변 매장 검색 (하버사인 공식 사용)
* @param lat 위도
* @param lng 경도
* @param radius 반경 (미터)
* @return 매장 목록
*/
@Query(value =
"SELECT *, " +
"(6371000 * acos(cos(radians(:lat)) * cos(radians(s.lat)) * cos(radians(s.lng) - radians(:lng)) + sin(radians(:lat)) * sin(radians(s.lat)))) AS distance " +
"FROM stores s " +
"WHERE (6371000 * acos(cos(radians(:lat)) * cos(radians(s.lat)) * cos(radians(s.lng) - radians(:lng)) + sin(radians(:lat)) * sin(radians(s.lat)))) < :radius +
"ORDER BY distance",
nativeQuery = true)
List<Object[]> findNearbyStores(@Param("lat") double lat, @Param("lng") double lng, @Param("radius") int radius);4. Sphere를 써야 하는 이유
- 하버사인 공식의 한계: 수식이 복잡하고 성능이 떨어질 가능성이 있음.
ST_Distance_Sphere의 장점: MySQL에서 최적화된 함수로, 구면 거리 계산을 간단하고 효율적으로 처리.
5. Specification을 사용할 수 없는 이유
- 참고 링크 JPA에서 이런 복잡한 필터조건을 다루는 방법이 없을까 하고 검색해봤음. 하지만, 별도의 파일로 분리해야하고 잘 사용하지 않는것같아서 @Query로 처리하는 경우가 더 많을 것같음. [TOY] JPA와 복잡한 동적 쿼리 사용 위한 Specification의 사용
Spring Data JPA의 Specification은 동적 쿼리를 작성하는 데 유용하지만, MySQL의 ST_Distance_Sphere와 같은 특정 함수는 지원하지 않습니다. 결국 네이티브 쿼리를 사용해야 하므로 Specification으로는 완전한 대체가 어렵습니다.
6. SQL로 별도 관리 vs 현재 방식
- SQL로 별도 관리:
- 장점: 쿼리가 코드에서 분리돼서 보기 편하고 재사용성도 높아짐.
- 단점: SQL 파일 읽어오는 작업 추가로 필요.
- 현재 방식 유지:
- 장점: 구현이 간단하고 빠름.
- 단점: 쿼리가 복잡해질수록 유지보수가 어려워질 수 있음.
7. 결론
- 결론은 SQL로 분리하는게 좋을까 아님 그냥 레포지터리에서 Query로 달아놓는게 좋을까? 의견좀~~ 만약 sql로 저장하면 src/main/resources/sql/store_queries.sql 이런식의 경로로 저장할 것 같음
- 아래는 변경시 코드 procedure를 써서 단점은, Mysql에 Query를 저장해야 함.. 그걸 Prodecure라고 하고 모든 팀원이 DB에 저장해야 에러가 나지 않음
@Procedure(procedureName = "find_nearby_stores")
List<Object[]> findNearbyStores(
@Param("userId") Long userId,
@Param("lat") double lat,
@Param("lng") double lng,
@Param("radius") double radius,
@Param("category") String category,
@Param("keyword") String keyword
);
'
멘토링
Q1. 인증/인가 어떻게?
이메일 인증이 완료된 경우에만 회원가입 요청을 남기도록 처리해두었고, 로그인은 Spring Security로 완료된 상태.
토큰 발급 이후 프론트가 그 토큰을 어디에 저장할지, 어떤 방식으로 인가를 처리할지도 고민해봐야 한다.
질문의 핵심은 AccessToken/RefreshToken의 관리와 재발급 로직, 그리고 Role에 따른 인가 처리였다. 이 부분은 프론트 상태관리랑도 연관되니 좀 더 논의가 필요하다고 느꼈습니다
Q2. OCR이 틀리면 수정은?
자동 인식을 기본으로 하되, 사용자가 수동으로 수정할 수 있게 inputBox도 제공하는 방식으로 결정.
인식 후 유저가 값들을 편하게 고칠 수 있게 만드는 UX가 중요하다는 피드백을 받았습니다
Q3. 전자지갑 토큰 발행
유효성 검증을 마친 뒤 스마트 컨트랙트를 붙이는 흐름으로 진행 중.
MVP 완성을 위해 결제 흐름부터 구현하고, 나중에 블록체인 연동을 붙이는 방향이 현실적.
에러 메시지도 따로 관리하는 것이 좋고, controller는 최대한 단순하게 유지하며 DTO 중심 구조가 적합하다.
스마트 컨트랙트 결제 → DB 기록 시 트랜잭션 롤백이 가능한지에 대해선, 트랜잭션으로 묶으면 문제 없다는 답변이 나왔다. 실시간 결제가 아니라면 통합 트랜잭션 처리 방식이 무난하다.
유효기간 지난 바우처를 배치로 처리하는 부분도 스케줄러로 충분히 가능하다. 개발 기간이 아직 남아서 이 정도는 직접 구현해봐도 좋을것같다고 하셨다!
Q4. 중복 요청, 멱등키
중복 클릭(=따닥) 방지에 대한 논의가 있었고, 이를 위해 멱등키 도입을 고려해볼 수 있다. 구현 난이도는 높지 않으며, 실제 서비스에서 안정성을 높이는 데 기여할 수 있다. 발표에서 언급하면 좋을 포인트라는 평가를 받았다.
