와우.. 상상도 못했는데 후배가 FISA 치니까 내 글 3번째에 뜬다고 공유해서 봤더니 조회수가 300에 가까웠다. 열심히 써야겠구나
Tokkit AWS 인프라 작업 회고
이번 주는 인프라 구축을 주로 수행했다.
처음부터 스케일 아웃 구조로 운영하려다 보니 해야 할 게 많아졌고, 그 과정에서 꽤 많이 헤맸다.
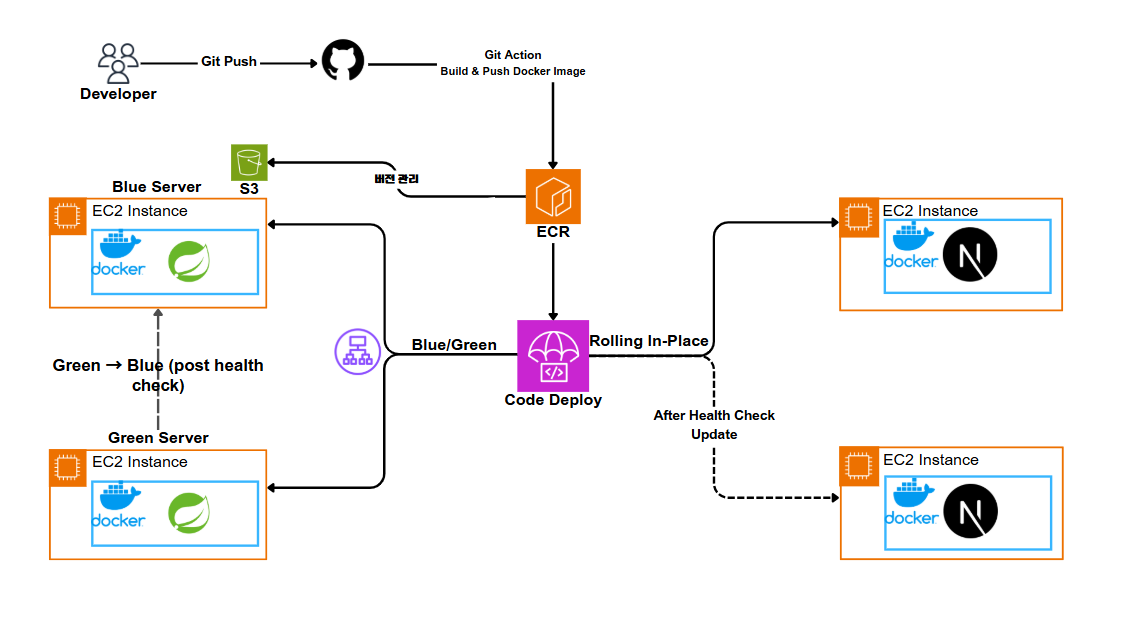
특히 Auto Scaling이랑 블루그린 배포, CI/CD 연동 쪽에서 단순히 구조를 세우는 걸 넘어서 어떻게 분산되어있는 환경에 배포를 할지 고민이 많아졌다.
AMI로 말고 docker pull 하면 끝인줄,,
Auto Scaling Group을 쓴다고 했을 때는 그냥 AMI 만들어두고, 그걸 템플릿에 넣어서 복제만 하면 다 될 줄 알았다.
그런데 막상 코드가 바뀌면, 새 인스턴스에는 그 변경 사항이 반영되지 않는 문제가 생겼다.
결국 AMI에는 도커랑 환경 설정만 포함시키고, 실제 코드나 이미지는 별도로 배포해줘야 한다는 걸 알게 됐다.
ECR에 이미지를 푸시하고, EC2에서는 pull 해서 띄우는 구조로 바꿨다.
CI/CD는 Auto-Scailing-Group에서 어떻게 하지?
처음엔 그냥 GitHub Actions에서 ECR에 이미지 푸시하고, EC2에 SSH 접속해서 docker-compose up 하면 되겠지 싶었다.
근데 Auto Scaling 구조에서는 인스턴스가 계속 바뀌니까 IP 기반 SSH는 무의미했고, 새로 뜨는 인스턴스는 배포 대상에 포함도 안 됐다.
그래서 Code Deploy를 쓰기로 했고, AMI를 다시 말아야했다. Code Deploy Agent를 다시 깔아서 처음부터 다시 작업을 수행했다. 덕분에 모든 인스턴스에 동시에 명령을 보내 docker pull 하도록해서 최신 소스를 반영하게 만들어주었다.
결국 지금은 GitHub Actions → ECR 푸시까지만 하고, EC2 쪽은 Code Deploy가ㅓ pull && up 해주는 방식이다.
이제 인스턴스가 새로 생겨도 따로 손댈 필요는 없다.
블루그린 배포도 생각보다 손이 간다
처음엔 ALB의 타겟 그룹만 바꾸면 끝이라고 생각했다.
근데 실제로는 Green에 붙은 인스턴스가 컨테이너도 제대로 안 뜨고, 헬스체크 실패하는 경우도 있었다.
그래서 AMI를 만들기 전에 컨테이너 상태를 먼저 확인하고, UserData에도 docker-compose up -d를 넣어서 부팅 시점에 바로 뜨도록 했다.
근데 나는 왜인지 모르겠지만, UserData에 도커 명령어를 입력했지만 새 인스턴스가 뜰 때 도커가 실행되진 않았다. 제일 어려웠던건 그린 인스턴스가 자꾸 헬스 체크를 통과하지 못할때마다 그린 인스턴스가 삭제가 안되고 ASG도 복제되어 계속해서 지우고 또 원인을 찾으면 처음부터 AMI를 말아서 ASG를 갈아 치워야하는 경우가 많았다. 심지어, BlueGreen은 5분가량의 시간이 걸리기에 결과를 확인하기 까지 오랜시간이 걸려 매번 스트레스가 심해졌다. 결국 해결했는데 늘 그랬듯이 기계는 거짓말 하지 않는다. 자잘한 실수들이 많았고 특히 appspec.yml이나 start.sh의 권한문제라던가 아니면 application.yml의 오타나 들여쓰기 오류가 많았다.
하드햇 네트워크는 단일로
초기에는 서버가 직접 스마트 컨트랙트를 배포하고, 그 주소랑 ABI를 파싱해서 사용하는 구조였다.
근데 Auto Scaling이 되니까 서버가 복제될 때마다 새로운 배포 주소를 만들어서 거래 내역이 초기화 되는 이슈가 있었다.
그래서 하드햇은 EC2 하나에서만 고정으로 띄우고, 컨트랙트를 배포하면 그 주소와 ABI를 서버에 POST로 전달하는 방식으로 바꿨다.
이제 서버는 받은 정보를 기준으로 Web3 초기화만 하고, 직접 배포하지는 않는다.
서버가 몇 개든 똑같은 컨트랙트 정보를 쓰니까 안정성 면에서 훨씬 낫다.
클라이언트는 블루그린 포기..
처음에는 클라이언트도 서버처럼 블루그린 배포를 하려고 했다.
Auto Scaling 없이 EC2 두 개 띄워놓고, CodeDeploy에서 태그 기반으로 알아서 잘 인식하겠지 싶었다.
근데 웬걸, 태그를 붙여도 CodeDeploy가 블루그린 구조로 인식 자체를 못 했다.
배포 시도할 때마다 실패하고, 로그에도 제대로 된 타겟 그룹이나 ASG가 없다고 나왔다.
처음엔 내가 뭘 잘못했나 싶었는데, 찾아보니까 블루그린은 ASG가 있어야 동작한다는 게 거의 전제 조건처럼 되어 있었다.
클라이언트는 굳이 Auto Scaling까지 쓸 필요가 없다고 판단했고,
결국 블루그린을 포기하고 롤링 방식으로 변경했다.
지금은 두 인스턴스를 번갈아 가며 업데이트하는 방식으로 구성해놨고,
알아서 헬스체크 통과한 뒤에 다음 인스턴스로 넘어가게 설정했다.
이걸 해보면서 느낀 건, 무중단 배포니 뭐니 다 좋지만
결국 구조에 따라 적절한 방식을 골라야 한다는 거였다.
안 되는 걸 억지로 붙이기보다, 구조에 맞게 방향을 바꾸는 게 오히려 더 안정적이라는 걸 이번에 확실히 배웠다.
카카오맵 개선 작업
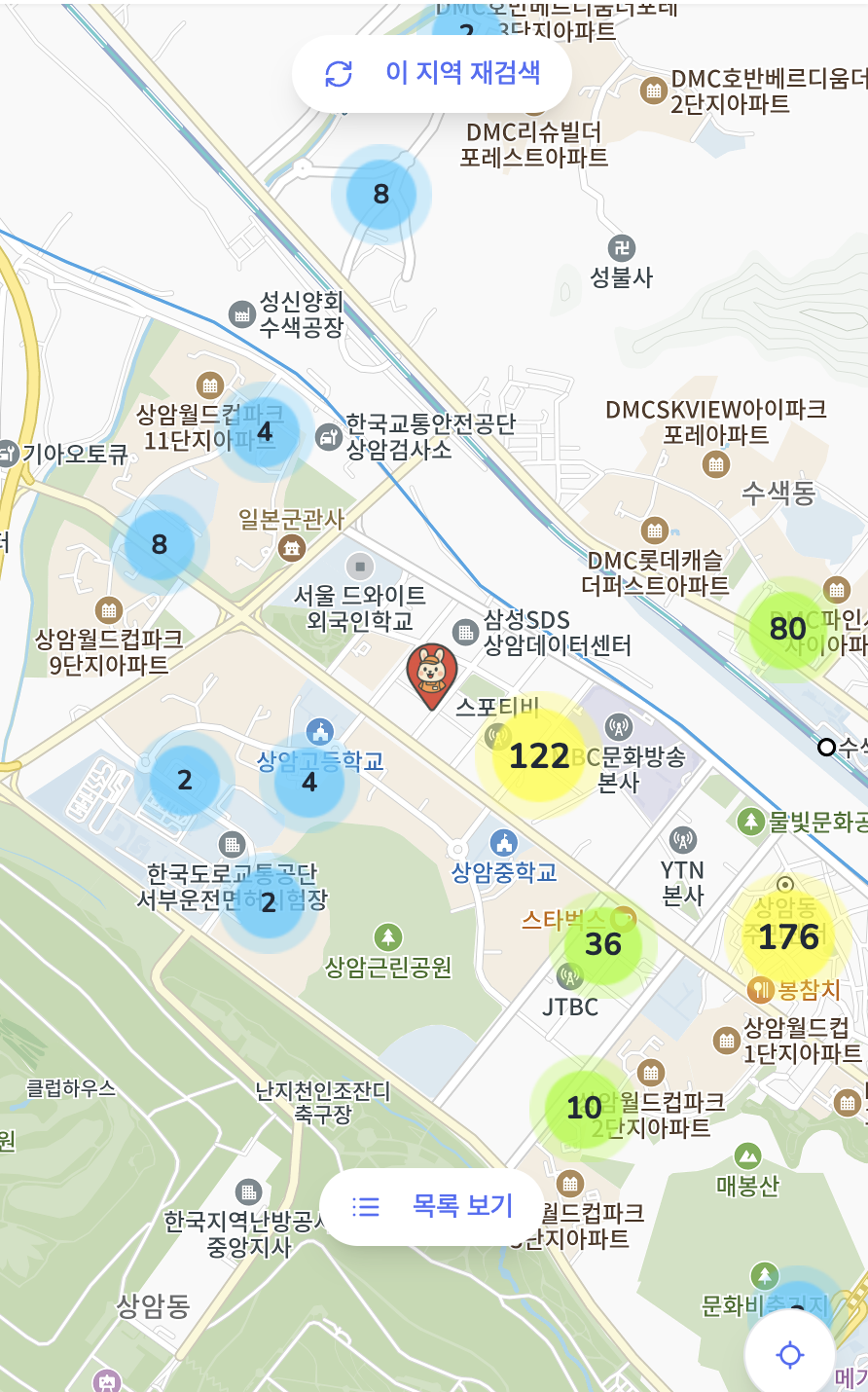
카카오맵 API를 처음 붙였을 땐, 응답 속도가 15초 가까이 걸렸다.
처음엔 단순히 API 문제인 줄 알았는데, 분석해보니 Sphere 쿼리에서 Full Scan이 발생하고 있었고,
마커 수가 많아질수록 그리는 데 걸리는 시간도 함께 늘어나고 있었다.
이걸 해결하기 위해 클러스터링을 도입했다.
맵을 불러올 때 마커들을 전부 렌더링하는 대신, 클러스터 단위로 묶어서 처리하게 했고,
DB 쿼리는 지도 바운더리를 기준으로 먼저 필터링한 뒤, Sphere 연산을 수행하는 방식으로 바꿨다.
그 결과 응답시간이 3초 이내로 줄었고, 화면에 마커가 뜨는 시간도 훨씬 빨라졌다.
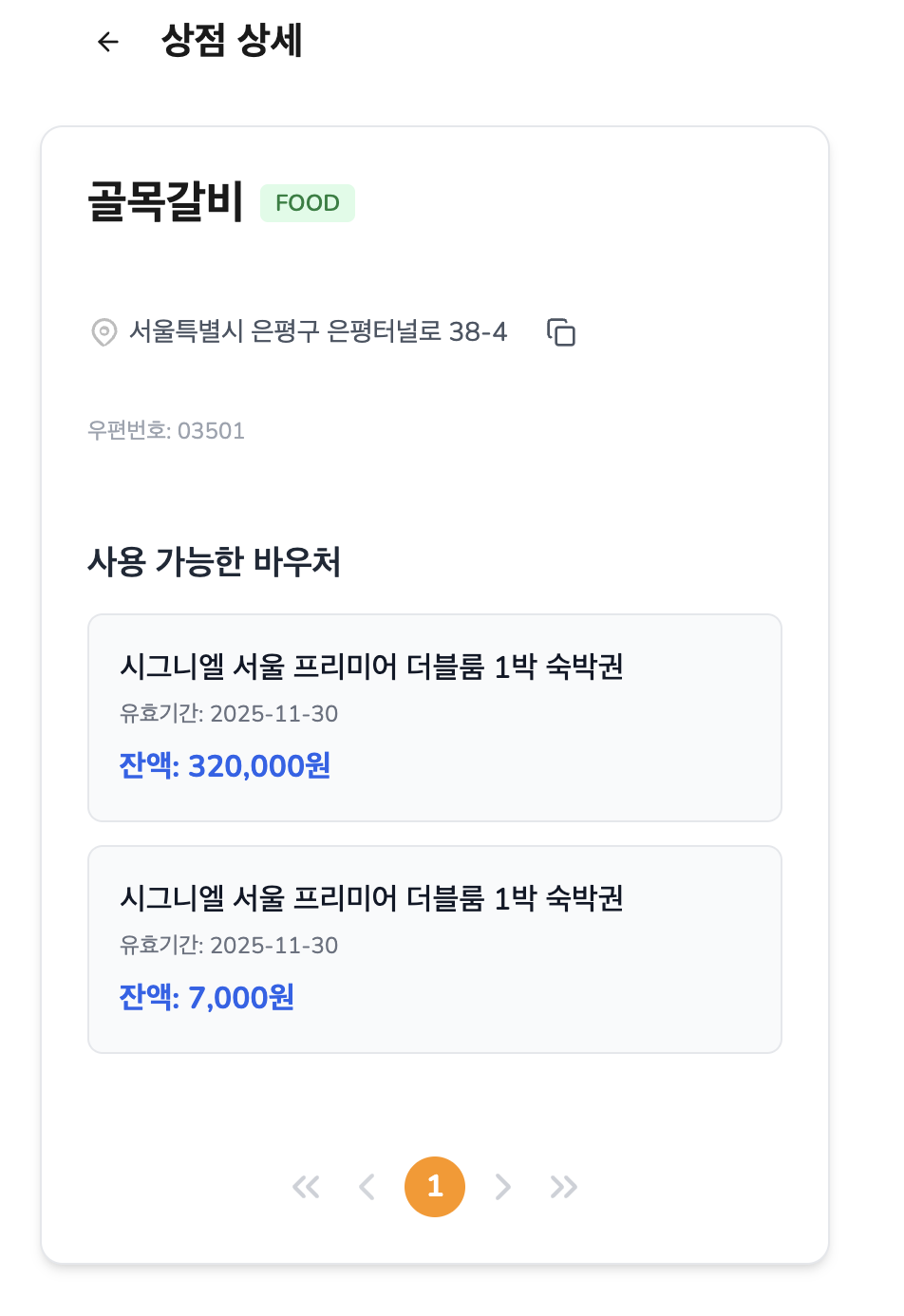
거기에 하나 더, 단순히 바우처 사용 가능한 가맹점만 보여주는 게 아!
니라,
가맹점을 클릭하면 그 상점에서 사용 가능한 내 바우처가 바로 뜨고,
거기서 바우처를 선택하면 결제까지 이어지는 흐름을 만들었다.
이건 단순히 정보 제공을 넘어서, 실제 사용자 흐름을 생각해서 만든 기능이라 꽤 만족스럽다.
중간에 겪은 삽질들
- IAM Role 누락: Launch Template 만들 때 IAM Role을 빼먹어서 CodeDeploy가 아예 동작을 안 했다. EC2에서 s3 명령어도 안 먹히고, 처음부터 막힘.
- AMI에 aws-cli 미설치: docker는 있었는데 aws-cli가 빠져 있어서 배포 때 ecr 로그인부터 실패했다.
- S3 경로 착오: app.zip을 루트에 넣었는데 appspec에선
deployments/app.zip으로 찾고 있어서 실패. - EC2 하나에 서버 둘 띄운 실수: 8080/8081로 Spring과 Admin을 하나에 넣었는데, Target Group은 인스턴스 단위라 라우팅 분리가 안 됐다. 결국 EC2를 분리하고 라우팅도 나눔.
- 퍼블릭 EC2에서 내부 ALB 접근 불가: 내부 ALB는 퍼블릭 DNS가 없고 보안 그룹도 막혀 있어서 접근 자체가 안 됐다. 결국 ALB를 퍼블릭 하나로 통합했다.
- 이건 아직도 이해가 안가는데 혹시 외부 LB에서 내부 LB로 라우팅하는법을 아신다면 꼭 댓글남겨주시길,, 난 내부 LB가 대상그룹을 이미 설정하고있어서 외부에서 내부 대상그룹을 찾을 수 없거나 혹은 선택이 불가했다.
- CodeDeploy 구조 재설계: 처음엔 클라이언트/어드민/서버/어드민서버를 하나로 묶었는데, 배포가 복잡해서 전부 분리했다. 지금은 클라이언트 쪽은 롤링, 서버는 블루그린 방식으로 각각 따로 배포된다.
현재 구조
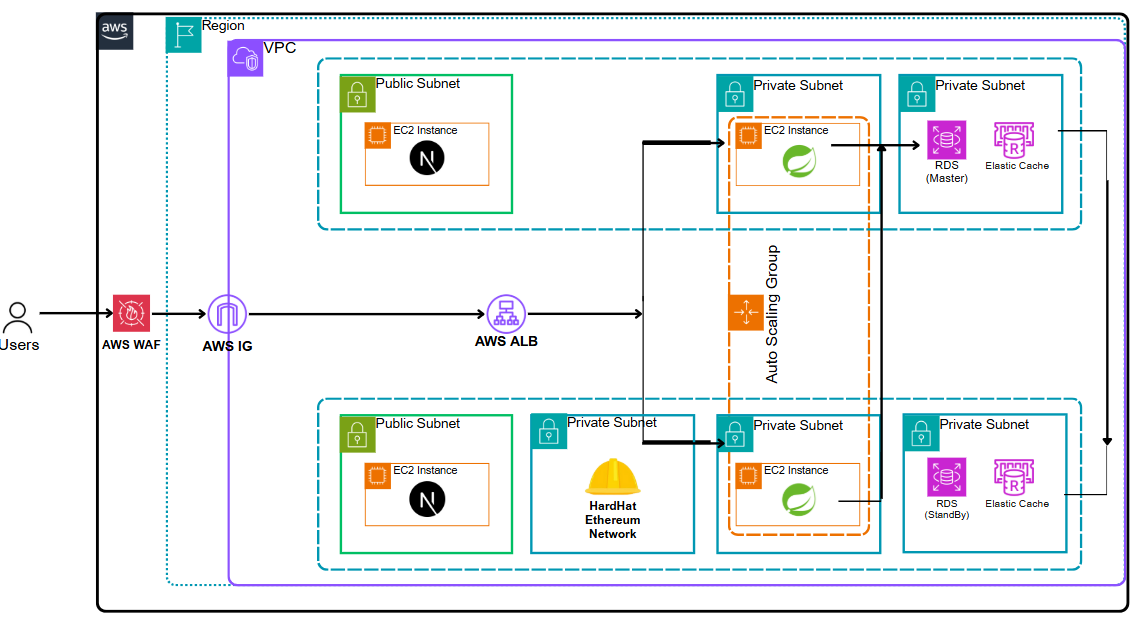
/api는 Spring 서버,/admin-api는 어드민 서버로 나뉘고 포트도 8080 / 8081로 다르게 설정- ALB 리스너에서 path 기준으로 분기 처리
- 각 서버는 AMI + Launch Template + ASG + CodeDeploy로 완전히 분리 운영
- 클라이언트는 Auto Scaling 없이 블루그린 배포만 적용
- 백엔드는 SSM 명령으로 전체 인스턴스에 pull + restart 처리
구조를 두고 있었던 생각 차이
이번 프로젝트 후반부에는 인프라 구조를 두고 팀원들 사이에 진지한 논의가 있었다.
지금 쓰고 있는 구조는 Auto Scaling 기반으로 EC2와 ALB를 나눠 쓰는 방식인데,
나는 그때 쿠버네티스 도입을 한 번쯤 고려해볼만하다고 생각하고 있었다.
우리 개발 진도도 빠른 편이었고, 현직 멘토님도 이 정도면 쿠버 해볼만하겠다는 말을 해주셨다.
사실 나도 이미 쿠버를 염두에 두고 있었고, 우리가 이번 프로젝트에서 한 가지 정도는 차별화된 기술을 써보는 것도 괜찮겠다고 생각했다.
나처럼 기능 개발이 일찍 끝난 경우엔 인프라 쪽에 시간을 쓸 여유도 있었고,
마침 옆반에 인프라 관련해서 물어볼 수 있는 친구도 있어서 가능성은 있다고 봤다.
근데 우리 팀은 쿠버네티스를 굳이 써야 하는 이유를 잘 모르겠다고 했고,
기능 개발이 아직 안 끝난 상태에서 새로운 도구를 들이는 건 부담스럽다고 느끼는 분위기였다.
결국 지금의 구조로 가기로 했고, 나도 그 판단이 틀렸다고 생각하진 않는다.
쿠버는 단지 띄우는 것만으로 끝이 아니고, 그걸 운용하고 컨트롤하는 것도 함께 고민해야 하는 거니까.
나도 공부하면서 생각보다 더 복잡하고 손이 많이 가겠다는 걸 알게 됐고,
지금 쓰고 있는 ALB 기반의 AZ 분리 구조만으로도 충분히 높은 가용성을 확보할 수 있다는 걸 인정하게 됐다.
내가 그때 조금 더 조급하게 밀어붙였던 것 같아서, 지금은 팀에게 미안한 마음이 있다.
잘해보려던 의도였지만, 모두가 같은 속도로 준비된 건 아니었고, 팀 안에서도 속도는 존중되어야 한다는 걸 배웠다.
URL 공개와 기술 공유를 두고
배포를 마친 뒤에, 우리는 우리가 만든 URL을 다른 팀에게 공유했다.
그런데 이 부분이 팀원 몇 명에게는 불편하게 느껴졌던 것 같다.
아직 발표도 하지 않았고, 다른 팀이 기술을 흉내낼 수도 있다는 우려였다.
내 입장에선 최대한 빨리 외부 피드백을 받아보고 싶었고,
우리는 애자일 방식을 도입했기 때문에 조기공개와 피드백 수집이 자연스러운 방향이라고 생각했다.
기술 유출보다 더 중요한 건 실제 사용자의 반응과 우리가 놓치고 있는 문제들을 빨리 알아차리는 거라고 생각했고,
그걸 위해 공개는 나쁜 선택은 아니라고 생각했다.
근데 그게 팀원들에게는 다르게 느껴졌던 것 같다.
결과적으로는 감정적인 대립으로까지 이어졌고, 나도 그 부분에선 내가 너무 밀어붙였다는 걸 인정하게 됐다.
우리는 결국 레포를 private으로 돌리고, 공개 시점을 발표 이후로 미루기로 결정했다.
이후에 옆팀과 얘기해보면서도 느낀 건, 사람마다 일의 속도나 공유에 대한 감각이 다 다르다는 거였다.
팀으로서 움직일 땐 어느 시점에서는 물러서는 것도 필요하다는 걸 배웠다.
