SELECT 쿼리 정리

혼자 공부하는 SQL을 보고 정리한 내용입니다.
where
- between ~ and
특정 범위 값을 구할 때 사용 하는 연산자
키가 163 ~ 165 범위의 회원을 검색한다고 할 때 AND 연산자를 사용하면 뭐 나쁘지 않은데 가독성이 다소 떨어짐
select * from member where height >= 163 and height <= 165를 between and 연산자를 이용해서 바꾸면 좀 더 가독성 좋게 바꿀 수 있음
select * from member where height between 163 and 165;- IN()
특정 값을 여러개 선택하는 연산자
경기, 전남, 경남 주소인 회원을 검색한다고 할 때 OR 연산자를 사용 했을 때 굉장히 쿼리가 길어짐
select * from member
where addr = '경기' or addr = '전남' or addr ='경남';하지만 IN 연산자를 쓰면 간결하게 작성할 수 있음
select * from member where add in('경기', '전남', '경남');- LIKE
특정 문자열을 검색할 때 사용하는 연산자
// 김으로 시작하는 mem_name 컬럼의 가진
// ex) 김농밀, 김깍두기
select * from member where mem_name like '김%'
// 김으로 끝나는 mem_name 컬럼 값을 검색
// ex) 양반김, 두부 튀김
select * from member where mem_name like '%김'
// 김이 포함된 mem_name을 컬럼 값을 모두 검색
//
select * from member where mem_name like '%김%'ORDER BY
정렬할 때 사용하는 쿼리 순서는 LIMIT 쿼리를 제외 한 SELECT 문 마지막에 위치함
기본값은 ASC 오름 차순 DESC 를 명시하면 내림차순
// height로 오름 차순 조회
select * from member order by height asc;
// 생량 가능 default asc
select * from member order by height;
// height로 내림 차순 조회
selec * from member order by height desc;정렬 기준은 1개가 아니라 여러 개 열을 지정 할 수 있음
// height 으로 먼저 내림 차순하고, 만약 height이 동일하면
// created_at으로 오름 차순 정렬을 함
select * from member order by height desc, created_at asc;LIMIT
LIMIT 출력하는 개수를 제한할 수 있음 페이징 처리 할 떄 주로 사용하고 select 쿼리의 맨 마지막에 위치 한다.*
select * from member limit 3;위의 쿼리를 실행하면 전체 member 중 맨위의 3개의 결과만 가져옴
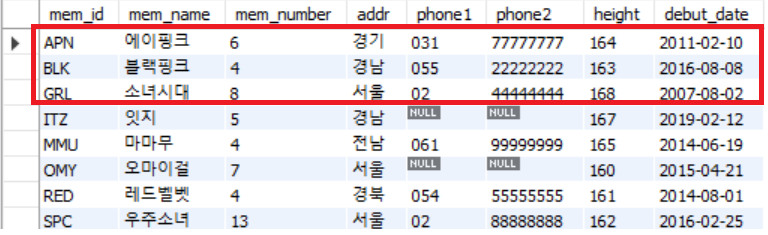
데이터를 가져오기 시작할 위치를 지정할 수 도 있음
// 3번째의 데이터 부터 3개를 가지고 오겠다는 말
select * from member limit 3, 3;
// offset을 이용할 수 있음
// 위에랑 똑같은 쿼리
select * from meber limit 3, offset 3;쿼리를 실행하면 빨간색으로 표시된 데이터를 가지고 오는걸 확인할 수 있음
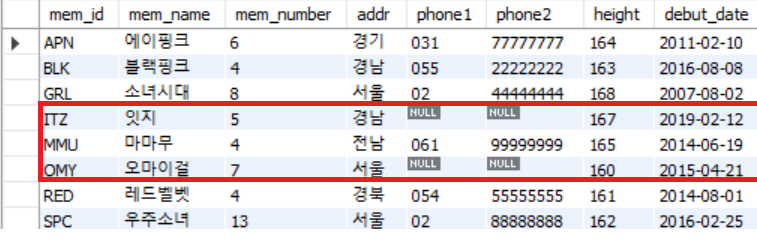
DISTINCT
중복된 결과에서 중복된 데이터를 제거 한다.
select aadr from meber;다음 회원의 주소(addr) 검색하면 경기, 성남, 서울, 전남, 경북 등 5 곳이 있는 것을 확인 할 수 있다.
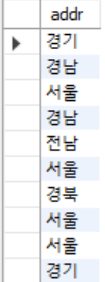
select distinct aadr from meber;distinct 를 사용하면 중복된 데이터를 제거 해준다.

여기서 나도 헷갈리는게 있었다 여러 컬럼이 오면 어떻게 될까? 라고 생각했다. 핵심은 중복된 데이터이다. 당연하거지만 distinct가 앞에 온다해서 그 앞에 있는 컬럼만 제거하는게 아니라 여러 컬럼에 사용하면 한가지의 컬럼이 아니고 똑같은 데이터만 제거 한다.
GROUP BY 과 HAVING
GROUP BY 는 특정 값을 가진 컬럼 끼리 그루핑 연산자 보통 집계 함수와 같이 사용한다.
집계 함수 표
| 함수명 | 설명 |
|---|---|
| SUM() | 합계를 구합니다. |
| AVG() | 평균을 구합니다. |
| MIN() | 최소값을 구합니다. |
| MAX() | 최대값을 구합니다. |
| COUNT() | 행의 개수를 셉니다. |
예를 들어 상품을 판매하는 도메인의 판매한 정보를 관리하는 buy 라는 테이블이 있다고 과정하자
select * from buy;buy 테이블을 전체 조회 했을 때
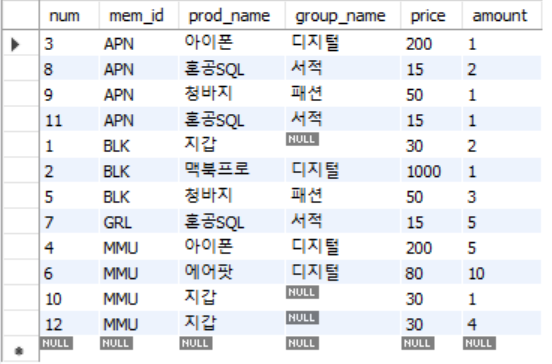
buy 테이블에는 회원 아이디인 mem_id, 상품 금액 price, 상품 갯수 amount 같은 컬럼이 있다.
특정 회원이 여러번 상품들을 구매할 수 있다.
만약 회원들의 총 결제한 금액을 확인 하고 싶다하면 어떻게 할까?
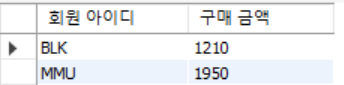
select mem_id '회원 아이디' , sum(price*amount) '구매 금액'
from buy group by mem_id;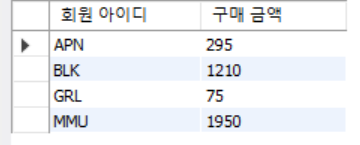
group by 절을 쓰면 회원 별 (mem_id) 그루핑 해서 집계 함수를 사용해서 결과 값을 얻을 수 있다.
결과 중에서 총 구매액이 1000원 이상인 회원에게만 사은품을 증정한다면 어떻게 할까? where을 사용하면 어떻게 될까?
// where 에 집계함수를 사용하면 문법 오류가 발생한다 X
select mem_id '회원 아이디' , sum(price*amount) '구매 금액'
from buy
where sum(price*amount) >= 1000
group by mem_id;

where 절에 집계 함수를 사용하면 위와 같은 문법 오류가 발생 한다. HAVING 절을 사용하면 집계 함수에 대한 조건을 제한할 수 있다.
select mem_id '회원 아이디' , sum(price*amount) '구매 금액'
from buy
group by mem_id
having sum(price*amount) >= 1000;