프로젝트 소개
Data set
- data set 출처 : https://www.kaggle.com/datasets/gpiosenka/100-bird-species
- 58388 Training dataset with label
- 2000 Test dataset with label
- Class : 400
- Image Size : 224x224
사용
- gdrive 업로드 후 google colab notebook 사용
- zip 형식으로 압축 후 kaggle notebook 사용
평가지표
- Accuracy
훈련 조건
- Parameter 5M 미만으로 제한
- Pretrained Model 사용금지
- Personal Data 추가 금지
- Epoch 최대 50회 제한
Basic Code
import numpy as np
import matplotlib.pyplot as plt
import sys
import os
import time
import random
import pandas as pd
import torch
from torch import nn, cuda, optim
from torchvision import models,transforms,datasets
from torch.utils.data import DataLoader,random_split
from PIL import Image
import seaborn as sns
import torch.nn.functional as F
from google.colab import drive
drive.mount('/content/drive')
!mkdir ./dataset
!unzip /content/drive/MyDrive/Bird.zip -d ./dataset- 라이브러리 import 후 deep learning을 위한 기본 setting
class AverageMeter(object):
r"""Computes and stores the average and current value
"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
class ProgressMeter(object):
def __init__(self, num_batches, *meters, prefix=""):
self.batch_fmtstr = self._get_batch_fmtstr(num_batches)
self.meters = meters
self.prefix = prefix
def print(self, batch):
entries = [self.prefix + self.batch_fmtstr.format(batch)]
entries += [str(meter) for meter in self.meters]
print('\t'.join(entries))
def _get_batch_fmtstr(self, num_batches):
num_digits = len(str(num_batches // 1))
fmt = '{:' + str(num_digits) + 'd}'
return '[' + fmt + '/' + fmt.format(num_batches) + ']'
def accuracy(output, target, topk=(1,)):
r"""Computes the accuracy over the $k$ top predictions for the specified values of k
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
# _, pred = output.topk(maxk, 1, True, True)
# pred = pred.t()
# correct = pred.eq(target.view(1, -1).expand_as(pred))
# faster topk (ref: https://github.com/pytorch/pytorch/issues/22812)
_, idx = output.sort(descending=True)
pred = idx[:,:maxk]
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res- train시 로그를 보여주기 위한 목적으로 선언된 class
def conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_planes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = conv3x3(3,64)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=2)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 128, num_blocks[2], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18(num_classes=10):
return ResNet(BasicBlock, [2,2,2,2], num_classes)
def ResNet34(num_classes=10):
return ResNet(BasicBlock, [3,4,6,3], num_classes)
def ResNet50(num_classes=10):
return ResNet(Bottleneck, [3,4,6,3], num_classes)
def ResNet101(num_classes=10):
return ResNet(Bottleneck, [3,4,23,3], num_classes)
def ResNet152(num_classes=10):
return ResNet(Bottleneck, [3,8,36,3], num_classes)- parameter 5M 이하를 위해 Cumtom된 resnet code
model = ResNet34(num_classes=400).cuda()
pytorch_total_params = sum(p.numel() for p in model.parameters())
print(f"Number of parameters: {pytorch_total_params}")
if int(pytorch_total_params) > 5000000:
print('Your model has the number of parameters more than 5 millions..')
sys.exit()
device = torch.device('cuda:0' if cuda.is_available() else 'cpu')
model.to(device)
print(device)- 매개변수 수 확인 코드
train_transform = transforms.Compose([transforms.Resize((64,64)),transforms.RandomRotation(45),transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
val_transform = transforms.Compose([transforms.Resize((64,64)),transforms.RandomRotation(45),transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])- 훈련데이터를 train / valid set으로 분할 후 증강 기법을 적용한다.
data = datasets.ImageFolder(data_dir)
train_size = int(len(data)*0.9)
val_size = int((len(data)-train_size))
train_data,val_data = random_split(data,[train_size,val_size])
torch.manual_seed(3334)
print(f'train size: {len(train_data)}\nval size: {len(val_data)}')
train_data.dataset.transform = train_transform
val_data.dataset.transform = val_transform
batch_size = 128
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True)
val_loader = DataLoader(val_data,batch_size=batch_size,shuffle=True)- data size 확인
- 증강 기법이 적용된 후 변형된 이미지가 data set에 추가된는 것이 아닌 각 epoch와 iteration마다 image가 변형되어 훈련이 진행된다.
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9, nesterov=True, weight_decay=5e-4)- 손실함수와 optimizer를 선언하는 부분
- 각 데이터의 특성과 분류 목적에 맞는 손실함수와 optimizer선택을 통하여 성능을 올릴 수 있다.
def fit(model,criterion,optimizer,num_epochs=10):
print_freq = 30
start = time.time()
best_model = model.state_dict()
best_acc = 0
train_loss_over_time = []
val_loss_over_time = []
train_acc_over_time = []
val_acc_over_time = []
# each epoch has a training and validation phase
for epoch in range(num_epochs):
print("\n----- epoch: {}, lr: {} -----".format(epoch, optimizer.param_groups[0]["lr"]))
batch_time = AverageMeter('Time', ':6.3f')
acc = AverageMeter('Accuracy', ':.4e')
progress = ProgressMeter(len(train_loader), batch_time, acc, prefix="Epoch: [{}]".format(epoch))
for phase in ['train','val']:
if phase == 'train':
data_loader = train_loader
model.train() # set the model to train mode
end = time.time()
else:
data_loader = val_loader
model.eval() # set the model to evaluate mode
end = time.time()
running_loss = 0.0
running_corrects = 0.0
# iterate over the data
for i,(inputs,labels) in enumerate(data_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_,pred = torch.max(outputs,dim=1)
loss = criterion(outputs,labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# calculating the loss and accuracy
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(pred == labels.data)
epoch_acc = (running_corrects.double()/len(train_data)).cpu().numpy()
acc.update(epoch_acc.item(), inputs.size(0))
if phase == 'train':
batch_time.update(time.time() - end)
end = time.time()
if i % print_freq == 0:
progress.print(i)
if phase == 'train':
epoch_loss = running_loss/len(train_data)
train_loss_over_time.append(epoch_loss)
epoch_acc = (running_corrects.double()/len(train_data)).cpu().numpy()
train_acc_over_time.append(epoch_acc)
else:
epoch_loss = running_loss/len(val_data)
val_loss_over_time.append(epoch_loss)
epoch_acc = (running_corrects.double()/len(val_data)).cpu().numpy()
val_acc_over_time.append(epoch_acc)
print(f'{phase} loss: {epoch_loss:.3f}, acc: {epoch_acc:.3f}')
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), 'model_best.pt')
torch.save(model.state_dict(),'model_latest.pt')
print('-'*60)
print('\n')
elapsed_time = time.time() - start
print('==> {:.2f} seconds to train this epoch\n'.format(elapsed_time))
print(f'best accuracy: {best_acc:.3f}')
# load best model weights
model.load_state_dict(best_model)
loss = {'train':train_loss_over_time, 'val':val_loss_over_time}
acc = {'train':train_acc_over_time, 'val':val_acc_over_time}
return model,loss, acc- train을 위한 code
epochs = 50
history, loss, acc = fit(model, criterion, optimizer, num_epochs = epochs)- 각 epoch만큼 train함수를 통하여 학습이 진행된다.
ex) epoch 0
----- epoch: 0, lr: 0.0001 -----
Epoch: [0][ 0/411] Time 0.372 ( 0.372) Accuracy 3.6157e-04 (3.6157e-04)
Epoch: [0][ 30/411] Time 0.360 ( 0.363) Accuracy 1.1589e-02 (5.8643e-03)
Epoch: [0][ 60/411] Time 0.374 ( 0.365) Accuracy 2.3064e-02 (1.1609e-02)
Epoch: [0][ 90/411] Time 0.359 ( 0.365) Accuracy 3.5186e-02 (1.7431e-02)
Epoch: [0][120/411] Time 0.361 ( 0.365) Accuracy 4.6566e-02 (2.3260e-02)
Epoch: [0][150/411] Time 0.365 ( 0.364) Accuracy 5.7775e-02 (2.9015e-02)
Epoch: [0][180/411] Time 0.361 ( 0.364) Accuracy 6.9706e-02 (3.4808e-02)
Epoch: [0][210/411] Time 0.353 ( 0.364) Accuracy 8.1714e-02 (4.0654e-02)
Epoch: [0][240/411] Time 0.360 ( 0.364) Accuracy 9.2942e-02 (4.6486e-02)
Epoch: [0][270/411] Time 0.360 ( 0.364) Accuracy 1.0525e-01 (5.2354e-02)
Epoch: [0][300/411] Time 0.360 ( 0.364) Accuracy 1.1753e-01 (5.8257e-02)
Epoch: [0][330/411] Time 0.368 ( 0.364) Accuracy 1.2891e-01 (6.4164e-02)
Epoch: [0][360/411] Time 0.363 ( 0.364) Accuracy 1.4109e-01 (7.0066e-02)
Epoch: [0][390/411] Time 0.362 ( 0.364) Accuracy 1.5294e-01 (7.5987e-02)
train loss: 4.026, acc: 0.161
val loss: 4.023, acc: 0.169
train_loss = loss['train']
val_loss = loss['val']
train_acc = acc['train']
val_acc = acc['val']
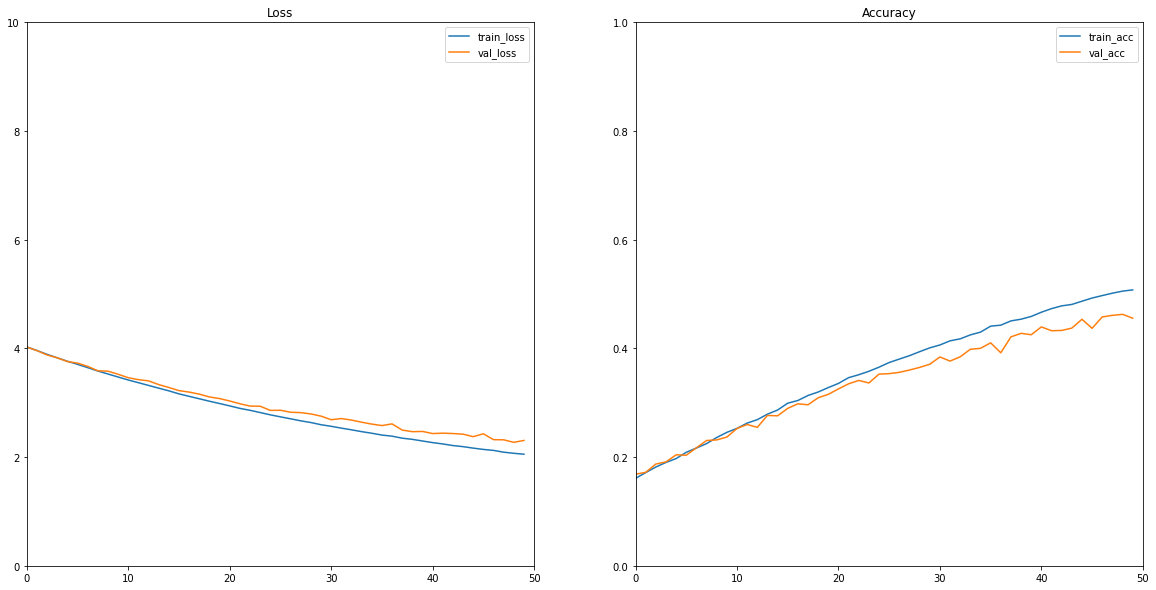
epochs_range = range(epochs)
plt.figure(figsize=(20,10))
plt.subplot(1,2,1)
plt.ylim(0,10)
plt.xlim(0,50)
plt.plot(epochs_range, train_loss, label='train_loss')
plt.plot(epochs_range, val_loss, label='val_loss')
plt.legend(loc=0)
plt.title('Loss')
plt.subplot(1,2,2)
plt.plot(epochs_range, train_acc ,label='train_acc')
plt.plot(epochs_range, val_acc, label='val_acc')
plt.legend(loc=0)
plt.ylim(0,1)
plt.xlim(0,50)
plt.title('Accuracy')- train 결과의 시각화 code
seed = 0
torch.manual_seed(seed)
if cuda:
torch.cuda.manual_seed(seed)
torch.manual_seed(3334)
test_transform = transforms.Compose([transforms.Resize((64,64)),transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# splitting the data into train/validation/test sets
test_data_dir = '/content/dataset/test'
_data = datasets.ImageFolder(test_data_dir)
test1_size = int(len(_data)*1)
test2_size = int((len(_data)-test1_size))
test_data, test2_data = torch.utils.data.random_split(_data,[test1_size, test2_size])
torch.manual_seed(3334)
print(f'test size: {len(test_data)}')
test_data.dataset.transform = test_transform
batch_size = 128
test_loader = DataLoader(test_data, batch_size = batch_size, shuffle = False)
print(test_loader)- test dataset load
import itertools
# testing how good the model is
def evaluate(model,criterion):
model.eval() # setting the model to evaluate mode
preds = []
Category = []
test_model = ResNet34(num_classes=400).cuda()
#저장경로는 변경하셔도 됩니다.
test_model.load_state_dict(torch.load('/content/model_best.pt'))
for inputs, label_ in test_loader:
inputs = inputs.to(device)
labels = label_.to(device)
# predicting
with torch.no_grad():
outputs = test_model(inputs)
_,pred = torch.max(outputs,dim=1)
preds.append(pred)
category = [t.cpu().numpy() for t in preds]
t_category = list(itertools.chain(*category))
Id = list(range(0, len(t_category)))
prediction = {
'Id': Id,
'Category': t_category
}
prediction_df = pd.DataFrame(prediction, columns=['Id','Category'])
#저장경로는 변경하셔도 됩니다.
prediction_df.to_csv('/content/drive/MyDrive/prediction.csv', index=False)
print('Done!!')
return preds
# testing the model
predictions = evaluate(model, criterion)- 예측 결과를 csv파일로 저장
- csv파일을 제출하여 정확도 측정

KHU, SWCON