Datamining - 개요
0
용어
Holdout method
- data를 training & test set인 disjoint한 그룹으로 분할한다.
- training set으로 분류 모델을 학습하며 test set으로 모델의 정확도를 판별한다.
- training set과 test set의 비율은 분석가가 결정한다 (At the discretion of the analysts)
data
- 실세계의 관측 결과 혹은 raw facts
information
- raw data를 가공함으로써 얻어지는 의미있는 패턴
- 넓은 의미에서 전화번호와 같은 관계적으로 연결되어 의미를 부여 받은 data를 포함한다
knowledge
- information을 유용하게 만드는 간결하고 명확한 information의 집합
- 주어진 정보 집합 내의 패턴이 확정되는 결정론적 과정을 의미한다.
data set
- collection of data objects described by their attirbutes
attribute
- 시간에 따라 혹은 객체에 따라 바뀌는 객체의 특징
- also known as variable / field / characteristic / feature
- ex) 사람의 눈 색깔, 온도 등
data object
- attributes를 설명하는 data objects의 모임
- also known as record / point / vector / event / case / sample / observations / entity / instance
data mining
정의
- 데이터에서 암시적이고 알져지지 않은 유용한 정보의 비선택적 추출
- 의미있는 패턴을 발견하기 위해 빅데이터를 자동/반자동적으로 분석하는 작업
- 의미 있는 패턴 추출이 data mining의 작업
- ex) Amazon 검색 결과를 문맥에 맞춰 비슷한 정보끼리 그룹화, 특정 지역의 이름 패턴 추출
What is not Data Mining
- DBMS를 통한 record열람이나 query를 통한 web-page 검색은 information retireval
- ex) 연락처에서 전화번호를 검색, Amazon의 정보를 query를 통한 web search
issues
전통적인 기법의 문제점
- 조악한 데이터
- 높은 차원의 데이터
- 중복되거나 분산되어있는 데이터
key challenges
- 분산되어있는 데이터 간의 커뮤니케이션을 어떻게 효과적으로 수행할지
- multiple source에서 진행된 데이터마이닝의 결과물을 어떻게 효과적으로 통합할지
- 보안 문제를 어떻게 효과적으로 다룰지
KDD Process
- input data -> data preprocessing -> data mining -> postprocessing -> information
preprocessing
- 데이터를 데이터마이닝 작업에 적합하도록 정제하는 작업
- data cleaning 혹은 data cleasing이라고 지칭하기도 한다.
- aggregation / sampling / dimensionality reduction / feature / subset selection / feature creation / discretization / binarization / variable transformation 작업을 포함한다.
postprocessing
- 데이터 마이닝의 결과물을 decision support system에 통합하는 작업
data mining task
Prediction Methods
- 특정 value를 사용하여 unknown이거나 다른 attribute의 미래 value를 예측하는 방법
- attributes와 categories의 관계를 표현하는, 이미 알고 있는 data를 통해 특정한 data에 category value를 할당한다.
- About one data / future or unknown data
- Model은 future or unknown data에 대해서 대표성을 나타내지 않으며, historical data set이나 past pattern은 더 이상 유효하지 않다.
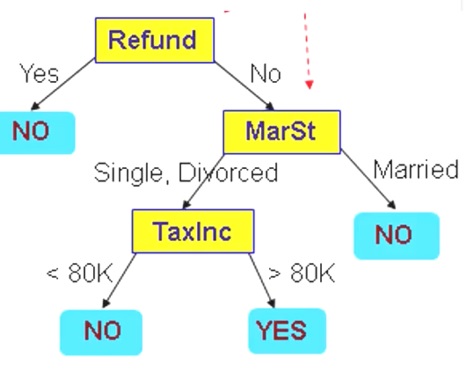
Description Methods
- 일반적으로 상관관계, 빈도 등을 제공하는 데 사용되며, 데이터 규칙성을 결정하고 인간이 이해가능한 패턴을 추출하는 용도로 사용된다.
- 같은 카테고리안에 나타나는 각각의 data를 통해 각각의 데이터에 대한 설명을 한다.
- About more than one data / past(known data)
- Model은 언제나 historical data를 나타낸다.
Data Mining Process (Cross Industry Standard Process for Data Mining, CRISP-DM)
Business Understanding → Data Understanding → Data Preparation →
Modeling → Evaluation → Deployment
- 순차적으로 진행해야 하며, 이전 단계에서 결정된 사항을 이후 단계에서 적용해야 의미 있는
결과를 도출할 수 있다
Two frameworks for big data analysis
DFAI (분석에 대한 목표와 목적이 사전에 정의된 경우)
- Define a purpose and goals of analysis
- Find big data available for the purpose and goals
- Analyze big data selected for the purpose and goals
- Interpret revealed patterns
ILAI (분석에 사용할 데이터를 사전에 수집한 경우)
- Identify the big data in hand
- List up purposes of analysis achievable from the big data
- Analyze the big data for the selected purpose
- Interpret revealed patterns
Challenges of Data Mining
Scalability (확장성, 데이터 마이닝 알고리즘의 성능)
- 데이터의 생성과 수집 영역이 진보되면서 massive한 data인 giga byte, terabytes 등을 다루기 위해서는 scalable해야한다.
- 데이터 마이닝 알고리즘의 수요나 데이터가 커져도 감당이 가능해야 한다.
- 새로운 module을 장착하여 업그레이드 가능하도록 하는 것도 scalability
Dimensionality (attributes의 개수)
- attributes가 증가함에 따라 처리 속도도 빠르게 증가가 가능해야 한다.
Data Quality
- 많은 데이터 수집이 분석이나 목적이 정해지지 않은 경우에서 수집되었기 때문
- missing, inconsistent, duplicates, biased and noise, outlier 등이 포함되는 경우
Data Ownership and Distribution
- 데이터 사용에 필요한 승인절차를 거쳐야한다.
- data가 한 곳에 있지 않거나 하나의 단체가 소유하고 있지 않고 geographically distributed되어 있다. 따라서 커뮤니케이션의 양을 줄이는 것과 효율적으로 통합하는 것, 그리고 데이터 보안 문제를 효율적으로 처리하는 것이 중요하다.
Privacy Preservation
- 특정 데이터들은 privacy issue로 수집할 수 없다.
Streaming data
- 실시간으로 수집되는 양이 많은 경우, 데이터 마이닝 알고리즘은 large scale에 대해 real time에 처리할 수 있는 성능을 갖추어야한다.

KHU, SWCON





