data-related issues
- 데이터 타입은 분석에 필요한 tools와 technique에 영향을 미친다.
Distinction between attributes and attribute values
- 같은 상태의 attribute는 서로 다른 attributes value로 mapping될 수 있다.
- ex) feet or meters
- 서로 다른 attribute가 같은 값으로 mapped될 수 있다.
- ex) ID와 학번 등
Measurement Scale
- 특정 대상에 특정 symbolic / numerical value를 부여하는 것이 measurement
- object의 attribute를 numerical or symbolic value로 할당하기 위한 rule이나 function
- measurement scale이 잘못 되어있으면 물체나 현상을 잘 대변하지 못한다.
- ex) feet or meter / pound or kilogram
measurement of length

- 위의 두 경우와 같이 길이를 다양한 방식으로 나타낼 수 있다.
- 왼쪽의 방식은 길이간의 순서만을 나타내며 오른쪽의 방식은 길이간의 순서와 연산의 가능성을 포함한다.
Properties of attribute values
- Distinctness (=, !=) / Order (<, >) / Addition (+, - ex) 섭씨, 화씨) / Multiplication ( *, /, ex) Kelvin)
Nominal attribute
- distinctness
Ordinal attribute
- distinctness, order
Interval attribute
- distinctness, order, addition
Ratio attribute
- distinctness, order, addition, Multiplication
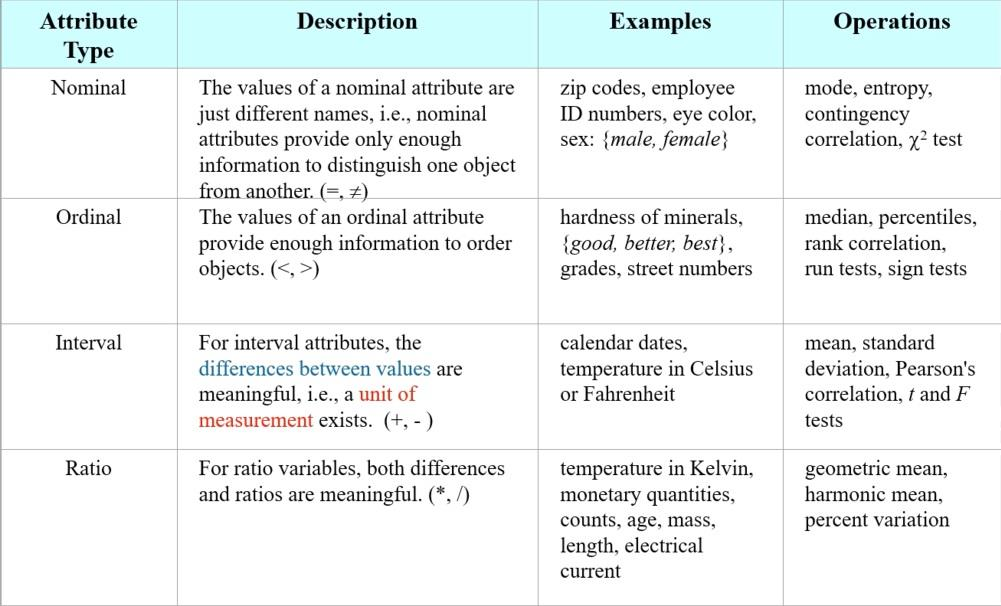
the definition of the attribute types is cumulative
-
누적적으로 적용된다.
Attibutes types
Discrete attribute
- 유한하거나 셀 수 있는 무한한 value의 set을 가지는 attribute
- ex) 우편 번호, 문서의 단어 집합 → categorical attribute or numerical attribute
Continuous attribute
- 실수를 attribute value로 가지는 attribute
- ex ) 기온, 키, 몸무게 → 유한한 수의 집합으로 나타낼 수 밖에 없다.
Asymmetric attributes
- Non-zero attribute value(관심이 있는 값)만 중요하게 생각한다.
- attribute에 대한 개념 : 하나의 attribute에 대한 value의 경향
Important charateristics of structured data
Dimensionality
- data set의 attributes의 수
- Curse of Dimensionality : 높은 차원의 데이터를 다루는 것에 대한 어려움을 의미한다.
Sparsity
- data set에 대한 개념 / non-zero 값이 적은 data set (ex) 사망자 표시, 마트 구입 물건 표시
- non-zero 값에 대해서면 저장하고 조작한다.
Resolution (해상도)
- 정보를 표현하는 양, 방식에 대한 기본적인 measurement
- resolution이 너무 fine하면 pattern이 보이지 않거나 noise에 의한 방해가 심해진다.
- resolution이 coarse하면 pattern이 사라지게 된다.
types of data sets
Record Data
- 고정된 attributes의 set으로 이루어진 record의 모음으로 이루어진 data
- record나 attributes간에 명백한 관계는 없으며, flat file로 저장되거나 관계 DB안에 저장된다.
- 관계 DB : record의 모음일 뿐만 아니라 split/join의 기능도 제공한다
data matrix
- numeric attributes로 구성된 same fixed set을 가진 data object
- 행렬의 연산에 사용되는 수식이 사용될 수 있다.
document data
- 각각의 문서가 가지는 단어의 수에 대한 term vector를 가진다.
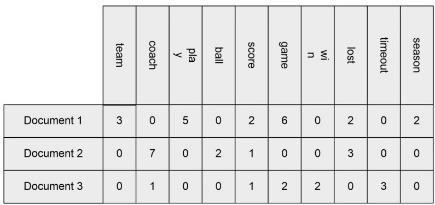
transaction data
- each record involves a set of items
- asymmetric attribute, binary
- 발생이 시간이나 공간의 동시성을 가진다.
- ex) 플레이리스트에 노래를 추가하는 행위(id에 시간을 추가하면 틀을 유지할 수 있다)
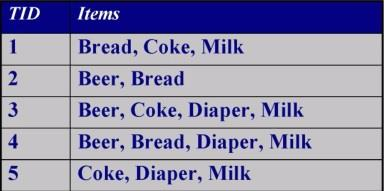
Graph-Based Data
- data objects 간의 관계를 포착하고, 각각의 data object는 스스로를 대표한다.
- 화학적 분자 구조를 node에 원자, link에 화학 결합을 표현함으로써 나타낼 수 있다.
- Node : data object와 mapping된다
- Link : object의 관계를 표현하는 데 사용된다. 방향과 가중치의 특징을 가진다.
Ordered Data
- 시간이나 공간에 관련된 순서를 가지고 관련된 attribute를 가지고 있다.
Sequential data : temporal data
- 각 데이터는 시간과 관련된 정보를 담고 있으며 patterns를 찾는데 사용될 수 있다.
Sequence data
- individual entities의 위치상 선후체계에 중점을 둔 data set, 시간정보를 담고 있지 않다.
- ex) 유전 정보의 GGTTCCGCTT 와 같은 형태
Time Series Data
- sequential data의 특수한 형태
- 특정 attribute에 대해 반복적이고 연속적인 측정을 수행한 data, 특정 시간 텀을 두고 측정
- Temporal Autocorrelation : 두 측정이 시간적으로 너무 가까워 매우 비슷한 경향을 가지는 경우
Spatial data
- 공간의 특성을 가지는 data set, 기후 데이터 등을 2, 3차원의 mesh형태로 나타낸다.
- Spatial autocorrelation : 두 측정이 공간적으로 너무 가까워 매우 비슷한 경향을 가지는 경우
Temporal data

KHU, SWCON