Mass-Storage (Secondary-Storage)
SDD
- Flash-memory가 내장되어 있으며, flash memory안에 CPU가 들어가 Memory READ/WRITE를 담당한다
Ram DISK
- RAM을 DISK처럼 사용하며 휘발성 메모리이기 때문에 전원이 꺼지면 데이터가 사라진다.
- Ip – time (LINUX 기기)
- LINUX 파일 시스템 원본을 압축해서 Flash-memory에 가지고 있으며, 전원을 키면 ip-time 기기가 메인 메모리에 RAM-disk를 만들고 파일시스템을 복사하여 파일 시스템처럼 활용한다.
Magnetic tape
- 백업 용도로 많이 사용되고 있다.
HDD
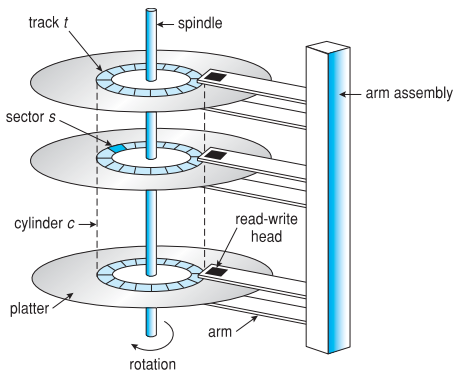
Disk performance
- Seek : moving the disk arm to the correct cylinder
- Head가 원하는 track으로 가는데 걸리는 시간
- Disk arm의 이동 속도에 좌우되며 매우 느리게 증가한다.
- Rotation : waiting for the sector to rotate under head
- track에서 읽고자 하는 sector가 head 밑으로 오는데 걸리는 시간
- disk의 rotation rate에 좌우되며 매우 느리게 증가한다.
- Transfer : transferring data from surface into disk controller, sending it back to the host
- Disk의 byte 밀집도에 의해 좌우되며 매우 빠르게 증가한다.
Disk scheduling
- seek time은 seek distance와 비례하며 비용이 굉장히 비싸다
- OS는 디스크를 기다리는 대기열에 있는 디스크 요청을 예약한다.
Interacting with disks
- Specifying disk requests requires a lot of info : cylinder #, surface #, track #, sector # etc.
- Older disks required the OS to specify all of this
- The OS needs to know all disk parameters
- Modern disks are more complicated
- Not all sector are the same size, sectors are remapped etc.
- Current disks provide a higher-level interface (e.g. SCSI)
- The disks exports its data as a logical array of blocks
- Disk maps logical blocks to cylinder/surface/track/sector
- Only need to specify the logical block # to read/write
- As a result, physical parameters are hidden from OS
Disk attachment
Host attached via an I/O port
- 대부분이 사용하는 Disk attachment
Network attached via a network connection (NAS)
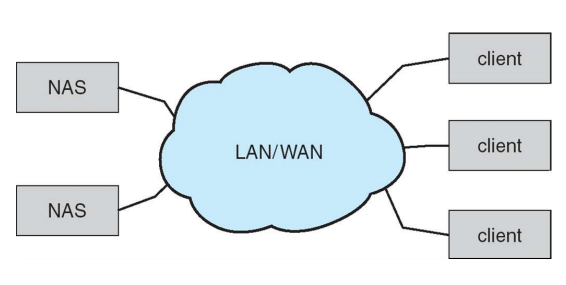
- Accessed via IP networks
- NFS, CIFS etc.
- File level access
- File system이 mount되어 파일 단위로 접근한다.
- 연구실 등에서 IP네트워크를 통하여 공유 데이터를 사용하는 구조
- 그룹 별로 작업할 때 많이 사용한다.
Storage-area network(SAN, 데이터 센터 서버에서 사용)
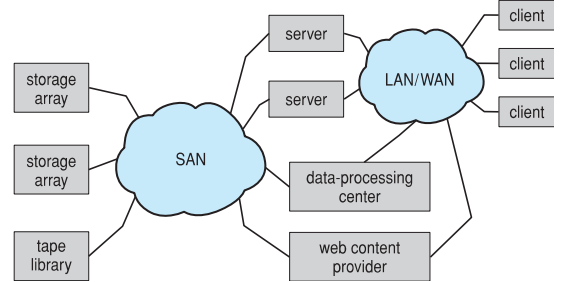
- Accessed via private network dedicated for storages
- Use storage protocols such as SCSI or Fibre channel
- Block-level access
- File systems for SAN is another story (e.g. GFS)
- 서버를 하나의 disk라고 생각하고 블록 단위로 접근한다.
Storage Architecture
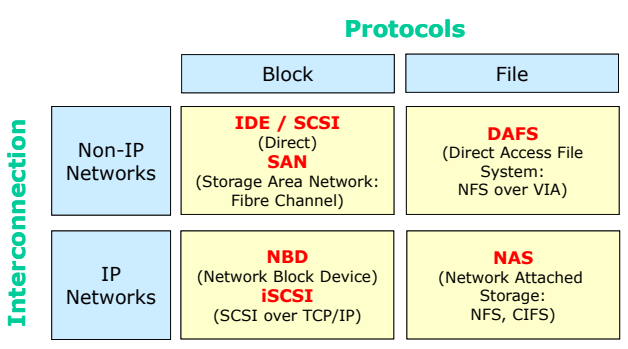
- IDE / SCSI : Host attached 방식(우리가 사용하는 방식)
- SAN : 별도의 네트워크로 연결하여 블록 단위로 사용한다.
Disk scheduling algorithm (Seek time 최소화)
FCFS
- 공평하지만 굉장히 비효율적인 방식
- 요청이 온 순서대로 요청 처리, seek time이 매우 길다.
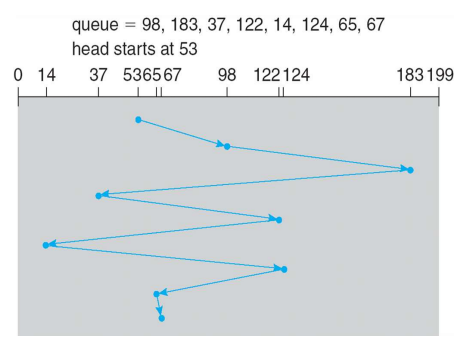
SSTF (Shortest Seek Time First)
- 현재의 head position에서 가장 짧은 seek time을 가지는 실린더 먼저 처리한다.
- SJF 스케줄링의 형태이며 몇몇 요청에 대하여 Starvation 문제를 야기한다.
- SJF 스케줄링은 이후의 작업을 예상하지 못하기 때문에 사용하지 못했지만, SSTF는 이후의 일을 미리 알 수 있기 때문에 사용할 수 있다.
- 일반적인 상황에서 많이 사용된다.
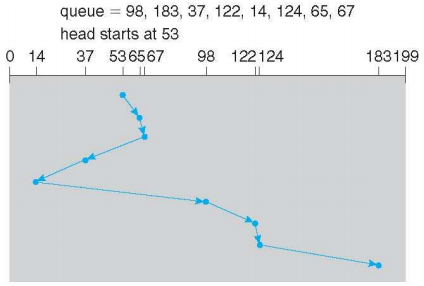
SCAN (Elevator algorithm)
- Head를 한쪽 방향으로 움직이면서 요청을 처리하고 다시 반대 방향으로 움직이면서 요청을 처리한다.
- 디스크 요청이 아주 많은 상황(VOD 시청 등)에서 사용된다,
- 공평하면서 FCFS보다 더 좋은 성능을 보인다.
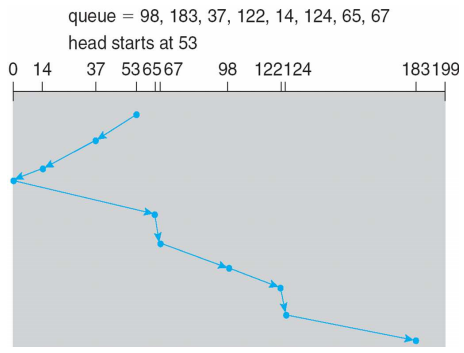
C-SCAN (Circular Scan)
- SCAN은 방향을 바꿔가며 한쪽 방향으로 처리하기 때문에 양 끝점에서는 처리가 지연될 수 있다. C-SCAN은 한 쪽 방향으로 작업을 처리한 후 다른 쪽 끝까지 작업을 처리하지 않고 가며 다시 한 쪽 방향으로 작업을 처리한다.
- 필요 없는 오버헤드 발생, SCAN이 더 많이 사용된다.
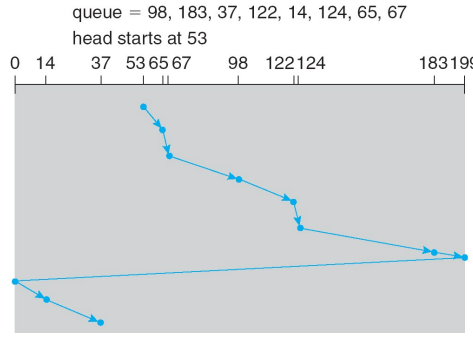
C-LOOK
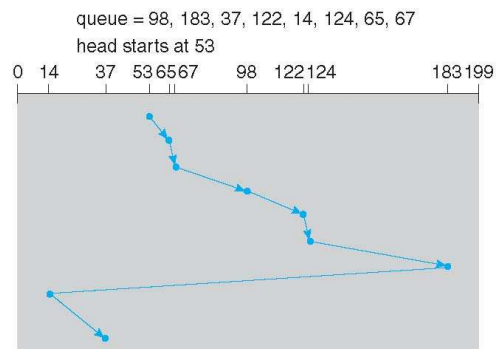
- 디스크의 끝까지 가는 것이 아닌 요청의 끝까지만 작업을 진행한다.
Disk controllers
Intelligent controllers
- 최근에는 disk controller 내부에 작은 CPU와 많은 kilobyte 단위의 메모리가 내장된다.
- CPU로부터 전달된 I/O 요청을 진행하기 위하여 controller에 의해 작성된 프로그램을 실행
- Read-ahead : the current track
- Caching : frequently-used blocks
- Request reordering : 스케줄링, for seek and/or rotational optimality
- Request retry on hardware failure
- Bad block identification
- Bad block remapping : onto spare blocks and/or tracks
Swap-space management
Swap-space
- Virtual memory uses disk space as an extension of main memory
- windows에서는 일반 파일 시스템의 파일 형태로 Swap space를 관리하며, Linux에서는 별도의 partition을 만들어 관리한다.
- 4.3 BSD는 프로세스가 시작할 때 Swap-space를 할당하며, Solaris2는 가상 메모리 페이지가 처음 생성될 때가 아닌 페이지가 physical memory로 갈 때 할당된다.
RAID (NAS에서 많이 사용한다)
Redundant Array of Inexpensive Disks
- a storage system, not a file system
- 비싸지 않은 하드디스크를 많이(중복하여) 사용하여 신뢰성을 향상시킨다.
- Parallelism을 이용하여 performance를 향상시킨다.
motivations
- 크고 비싼 disk 대신 작고 싼 disk를 많이 이용함으로써 경제적인 효율을 얻는다.(inexpensive)
- 더 높은 신뢰도와 data-transfer을 달성한다 (independent)
Improving reliability via redundancy
- Mirroring (shadowing) : 같은 것을 복사한다.
- Parity or error-correcting codes
- 단순히 복사하면 비용이 비싸기 때문에 용량을 줄이거나 error-correcting codes를 사용한다.
Improving performance via parallelism
- Data striping : bit level (parallelism) vs. block-level (concurrency)
- Bit-level striping : 데이터를 읽고 쓸 때, 여러 개의 디스크에 한 번에 저장하거나 읽는 방식
- 하나의 디스크 블록을 여러 개의 디스크에 나누어 저장한다.
- Block-level striping (성능이 더 우수하다, 한 번의 SEEK에 더 많이 읽는다)
- Multiple disk 0번, 1번 등등 순차적으로 하나의 디스크에 저장되지만, 0번 블록은 0번 디스크에, 1번 블록을 1번 디스크에 나누어서 저장함으로써 데이터 접근을 한 번의 접근으로 할 수 있다.
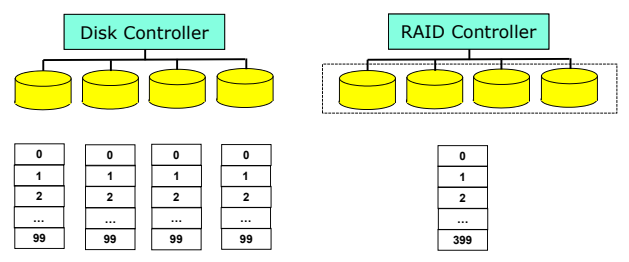
- raid controller는 여러 개의 디스크가 아닌 용량이 큰 디스크 하나가 있는 것처럼 관리한다.
RAID levels
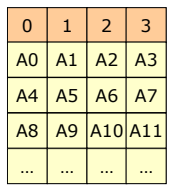
RAID 0
- Non-redundant striping : 신뢰성은 고려하지 않고 block-level striping만 한다.
- 데이터가 블록 단위로 분할되고 각 블록은 Multiple disk에 striped된다.
- I/O load를 많은 채널과 드라이브에 분배함으로써 I/O 성능을 향상시킨다.
- Data rate intensive한 애플리케이션(video editing 등)에 많이 사용된다.
- 데이터 손실에 대한 영향이 적고 성능이 중요할 때 사용한다.
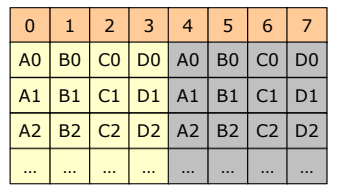
RAID 1
- Mirrored disks
- 하나의 디스크 트랜잭션을 두 번 읽고, 같은 내용을 다른 디스크에 write한다.
- 비싸며 disk overhead가 크다.
- independent하게 동작하며 같은 것을 복사함으로써 성능보다 신뢰성을 중요시한다.
RAID2
- 하나의 Disk block을 n개에 나누어서 저장하며, 나누어진 디스크를 동시에 읽어 하나의 블록으로 만든다.
- Memory-style error-correcting codes(ECC) / Bit-level striping (성능)
- Mirroring은 오버헤드가 크기 때문에 error correcting code로 저장한다. (신뢰성)
- 각각의 data word는 ECC disk에 저장된 Hamming Code ECC word를 갖는다.
- ECC는 현대 디스크 드라이브에 대부분 내장되어 있다.
- 4개 중 3개의 디스크가 고장나도 3개의 ECC가 있으면 복구가 가능하다.
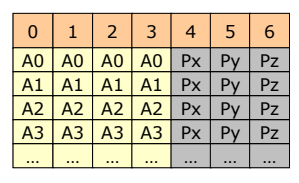
RAID 3
- Bit-interleaved parity
- Write 시에 하나의 parity disk가 생기며 디스크를 복사해 둔다.
- RAID2 보다 저장상의 오버헤드가 작으며 효율적인 사용을 위해 하드웨어의 도움이 필요하다.
- 1개의 parity만 작성했기 때문에 2개 이상의 디스크가 고장나면 복구할 수 없다.
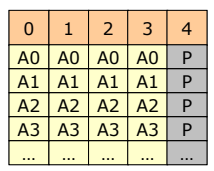
RAID 4
- Block-interleaved parity
- write시에 같은 block rank에 관한 parity가 생성되면, parity disk에 저장되며 read시에 확인
- read는 RAID 0과 같이 성능이 좋지만 Write시에 매번 parity도 업데이트되야 하기 때문에 성능이 좋지 않다.
- 동시에 write하는 연산이 없다면 RAID5에 비해 장점이 없다.
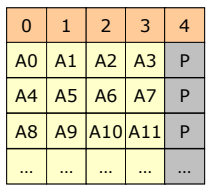
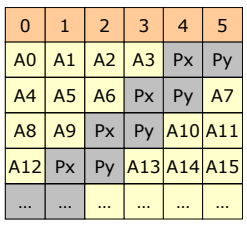
RAID 5 (자주 사용된다)
- Block-interleaved distributed parity
- write시에 같은 rank에 관하여 생성되는 parity를 여러 disk에 분배함으로써 성능을 높인다.
- Parity가 병목현상을 일으키지 않기 때문에 write의 성능이 향상된다.
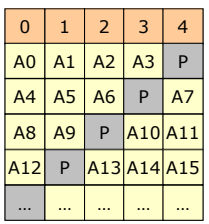
RAID 6
- P + Q redundancy scheme
- RAID 5에 추가적인 Parity를 둠으로써 신뢰성을 높인다.
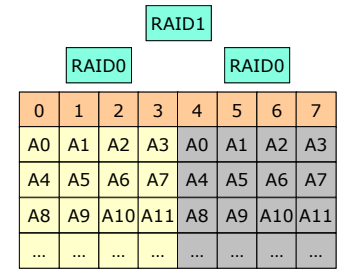
RAID 0 + 1
- Disk를 striped한 후 (RAID 0) , Mirroring 한다 (RAID 1)
- 하나의 Disk가 고장나면 해당 RAID 0의 Disk 전체를 사용하지 않고, mirroring된 디스크 사용
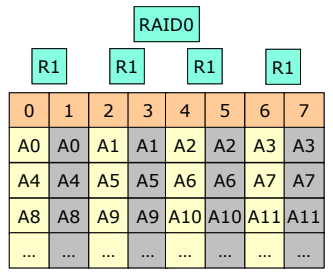
RAID 10 (1 + 0) (자주 사용된다)
- Disk를 mirroring 한 후, striping 한다.
- 하나의 디스크가 고장나면 해당 디스크가 동작하지 않는다.
- RAID 0 + 1보다 신뢰성 등 성능이 우수하다.

KHU, SWCON