Demand paging
- Page-level swapping을 하는 paging system
- 할당한 page(frame)을 secondary storage로 보내고 page(frame)이 필요할 때 physical memory로 page를 보내는 방식
- Cf) swapping : 프로세스 단위로 바꾸는 방식
- 운영체제는 메인 메모리를 프로세스에 의해 할당된 데이터의 cache처럼 사용한다
- 초기에 physical memory frames로부터 pages가 할당된다.
- Physical memory가 가득 차면, 새로운 page를 할당하기 위해 다른 page를 제거해야 한다.
- 제거 대상의 page는 memory에서 disk로 이동한다.
동작 방식
- 모든 entries를 invalid로 두고 메모리에 올리지 않은 상태에서 시작한다
- 페이지가 참조되는 시점에 메인 메모리로 page를 올려 사용한다.
Demand paging이 효율적인 이유 : locality
- Temporal locality : 최근에 참조된 영역은 곧 다시 참조되는 경향이 있다
- Spatial locality : 최근 참조된 영역의 주변 영역은 참조될 가능성이 높다.
- 오래 실행된 physical memory에 남아있는 page : 자주 참조되는, locality가 높은 page
Valid-invalid bit in demand paging
- If valid-invalid bit == v
- 참조할 수 있는 영역이면서 page가 memory에 있는 경우
- If valid-invalid bit == i
- 참조할 수 없는 영역(protection fault)이거나
- 참조할 수 있는 영역이지만 메모리에 없고 secondary storage에 있는 경우 (page fault)
다음과 같은 상황이 발생하는 경우
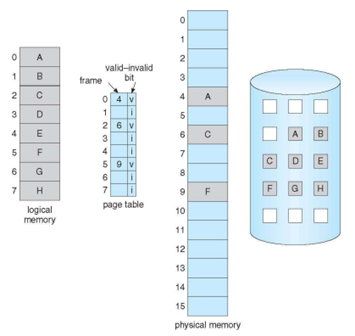
- 초기에 0, 2, 5번 page가 참조되는 경우
- 프로세스가 오래 실행된 경우 0, 2, 5번 page가 locality가 높은 경우
Page fault
-
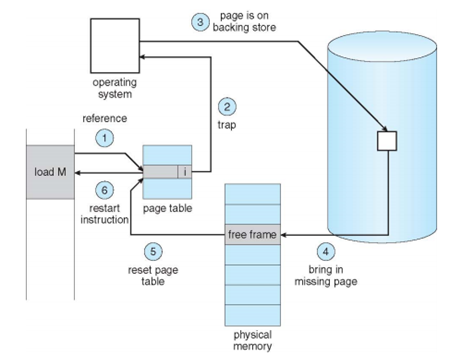
CPU가 Store, load등의 메모리 명령어를 실행할 때 메모리를 참조한다.
-
메모리를 참조할 때 TLB에 없는 경우 Page table을 참조하며 page table에서 해당 영역이 invalid상태라면 OS를 호출하기 위하여 Page fault를 발생시킨다.
-
Protection fault 혹은 page fault인지의 여부는 OS가 호출된 후 판단되므로 두 가지를 합쳐서 Page fault라고 지칭한다.
-
OS가 호출된 후 참조할 수 있는 영역이라면 Secondary storage의 page를 free frame으로 보내고 Page table을 reset한 후 명령어를 재실행한다.
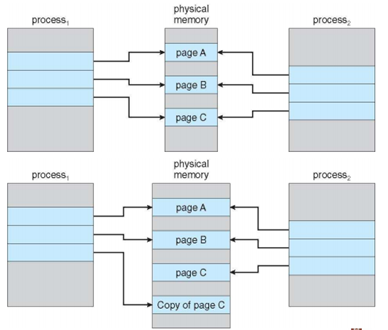
Copy-on-write
-
UNIX/LINUX의 Demand-paging 구현 방식
-
Fork()로 같은 프로세스를 복제하여 같은 physical memory를 가리킨다.
-
Page에 write하는 시점에 page를 복제하여 수정내용을 기재한다.
- Resource를 공유하다 수정 상황이 생기면 복제본을 만들어 수정사항을 기재하고 포인터만을 바꾸어 사용함으로써 메모리 효율을 높였다.
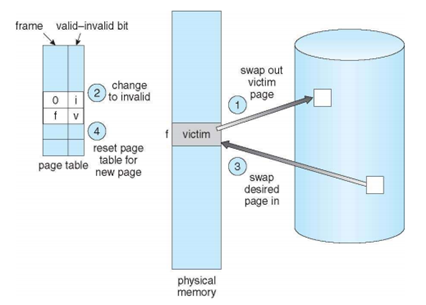
Page Replacement
- Page fault가 발생한 경우 secondary memory로부터 메모리로 올려야 하는데 free frame이 없는 경우
- Locality를 고려하면 오래 사용되지 않은 page를 secondary memory를 내린다.
Page Replacement Algorithms
- Goal: lowest page-fault rate
- 메모리를 참조하는 특정한 string에 알고리즘을 적용하여 낮은 page-fault rate를 찾는다.
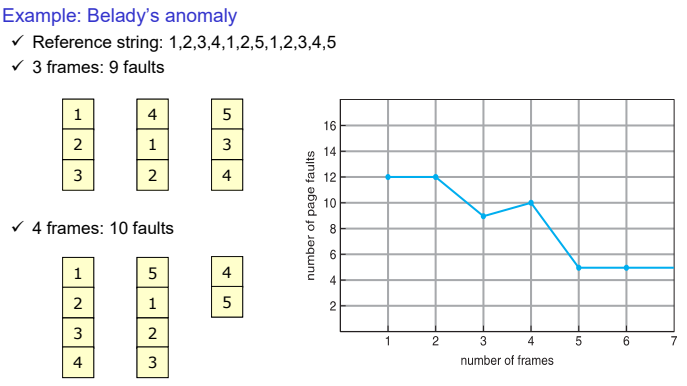
FIFO
- 가장 오래전에 메모리에 올라온 Page를 victim으로 선정한다.
- Belady’s Anomaly : locality를 고려하지 않고, 메모리가 커질수록 낮은 성능을 나타낸다.
- 초기 상태에서는 page fault가 발생한다.
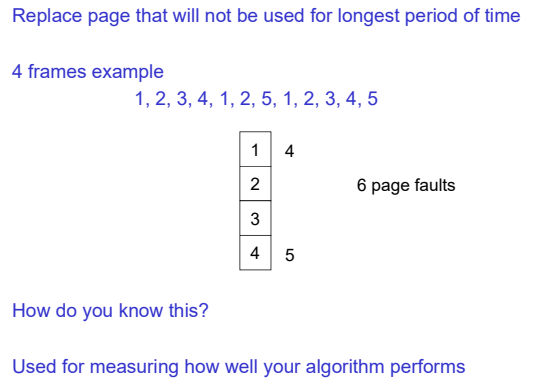
Optimal Algorithm
- 참조될 메모리를 미리 알 수 없기 때문에 이전의 참조 기록을 보고 locality를 고려하여 가장 오래 사용되지 않은 것을 내린다. >> LRU
LRU (Least Recently Used) Algorithm Implementation
Timestamp implementation
- page별로 counter를 가진다.
- Page가 참조될 때마다 clock이 counter에 복사된다.
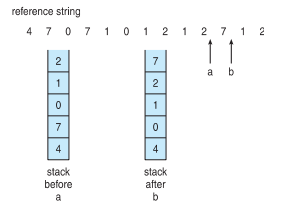
Stack implementation
- Page number의 stack을 관리한다.
- 참조된 메모리를 stack의 가장 위로 올리며 포인터를 변경한다
- 오버헤드가 너무 크다
Approximation
- Timestamp를 정확하게 기재하는 것은 비싼 작업
- Reference bit를 두어 참조되었으면 1, 참조되지 않았으면 0을 사용하여 효율을 높인다. (1bit)
- 순서에 상관하지 않고 랜덤하게 0의 값을 가지는 비트를 내린다.
Second chance (LRU Clock)
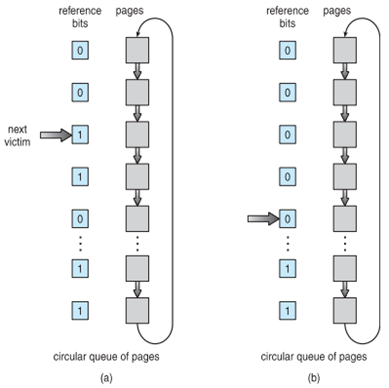
- Reference bit가 1인 bit를 만나면 0으로 setting 후 다음 bit를 검사하면 0인 bit를 만나면 victim으로 선정한다.
Not Recently Used (NRU) : 현재 사용하는 방법
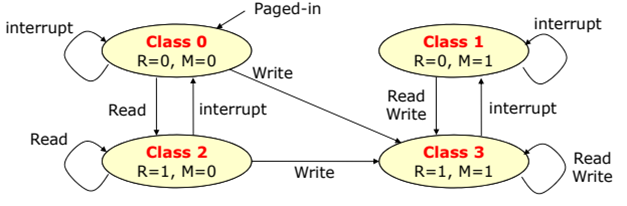
- R : reference READ
- M : modify / WRITE
- Modify bit는 NRU 알고리즘에 적용하는 것 외에도 Cache memory관리를 위해 유지하여야 한다.
- Victim 선정 순서 : class 0 → class 1 → class 2 → class 3
Least Frequently Used (LFU)
- Counting-based page replacement
- 가장 적제 참조된 것을 counter로 관리하여 victim으로 선정한다.
- Cf ) MFU : 가장 많이 참조된 것을 내린다. Count가 적은 메모리는 최근에 올라온 메모리일 수 있기에
Allocation of frames (free frame을 어떤 process에 할당할지)
Allocation algorithm
- Equal allocation
- Proportional allocation
- Priority-based allocation
Page replacement
- global replacement
- Local replacement
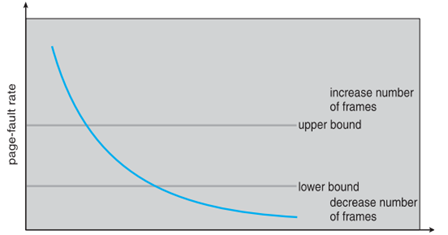
- Page-fault rate를 관찰 후 upper, lower bound 내에서 발생하도록 frame 수를 조정한다.
Thrashing ~= a process is busy swapping pages in and out
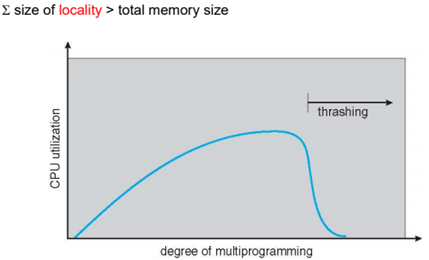
- 프로세스가 많아지면 locality가 높은 page들이 많아져 swapping / Disk I/O만 수행함으로써 CPU utilization이 떨어지는 현상
- 메모리에 비해서 프로세스의 수가 많다는 의미
해결법
- 메모리 추가
- 프로세스의 수를 줄인다
Working-Set Model
- Working set : 자주 사용되는 page/ locality의 크기, 델타 시간안에 사용된 페이지의 크기

Prepaging
- Fault가 발생한 page의 인근에 위치한 page도 미리 fault처리하여 디스크에서 미리 읽어온다.
Page size selection
- Internal fragmentation을 고려하여 page size를 작게 한다.
- Page table size를 고려하면 page size를 크게 한다.
- I/O Overhead의 seek time을 고려하여 page size를 크게 한다.
- Locality를 고려하여 page size를 크게 한다.
TLB Reach
- TLB가 커버하는 영역의 크기
- TLB Reach = TLB size * Page size : page size가 크면 클수록 좋다.
Program structure
program 구조에 따라 page fault의 수가 차이 난다.
I/O Interlock
- DMA와 같이 하드웨어가 직접 메모리를 사용할 수 있다.
- LOCK을 걸고 하드웨어가 독점적으로 사용한다.
- 연속적인 Physical memory를 할당 받아서 쓰면 free frame으로 사용하면 안된다.

KHU, SWCON