안녕하세요.
오늘은 저희 팀 프로젝트 진행 중 JetsonNano를 사용하면서 겪었던 우여곡절들과, 저희가 그것들을 어떻게 헤쳐 나갔는지 기록해보려 합니다.
먼저 저희 팀은 PoseNet 모델을 경량화하는 프로젝트를 진행하고 있습니다. PoseNet 모델은 어떤 이미지가 주어졌을 때, 그 이미지가 찍힌 카메라의 위치와 방향(Camera pose)을 6-dof의 7가지 값으로 예측하는 CNN 모델입니다.
저희는 이 PoseNet을 Knowledge Distillation이라는 기법을 사용해서 경량화 하고자 합니다. 이 모델을 경량화해서, 저전력 환경의 디바이스에서도 camera pose estimation이 가능하게 함으로써 궁극적으로는 실내 주행 로봇의 배터리 효율을 개선하는 것을 목표로 합니다.
저희는 camera pose estimation 이라는 task에 적합하도록 Knowledge Distillation에서의 새로운 Loss fucntion을 고안했는데요, 이번 포스팅에서는 이 "경량화" 과정 보다는 경량화한 모델을 실제 보드에 올리고 실행하는 과정에 대해 좀 더 집중적으로 다루고자 합니다.
포스팅 목차는 다음과 같습니다.
- NVIDIA JetsonNaNo 2GB Developer Kit
- OS 설치 및 환경 설정
- JetPack 내장 환경 확인
- torch install
- Requirements install
- Git clone
- 모델 실행
- CPU, GPU 사용량 확인
- Inference Time 확인
- 전력 소모 측정 관련 내용
1. NVIDIA JetsonNaNo 2GB Developer Kit
앞서 말씀드린 저희의 연구 목표를 실제로 검증하기 위한 가장 좋은 방법은 실제 저전력 보드에 기존 모델과 저희가 경량화한 모델을 올려서 실험을 진행해보는 것입니다. 경량화된 모델을 사용했을 때 전력 소모가 더 적은지 확인하거나, 혹은 같은 배터리로 더 오래 작동시킬 수 있는지 확인하는 등의 방법으로 말이죠.
저희는 기존모델과 경량화한 모델의 비교를 위해 다음과 같은 세 가지 가설을 검증하기로 했습니다.
- 경량화한 모델이 CPU, GPU 사용량이 더 적을 것이다.
- 경량화한 모델이 Inference Time이 더 짧을 것이다.
- 경량화한 모델이 전력 소모량이 더 적을 것이다.
위 가설들을 검증하기 위해 저희는 NVIDIA의 JetsonNaNO 2GB Developer Kit 를 사용해서 실험을 진행했습니다. 5W의 저전력 환경 보드이구요, 현재 보드를 NVIDIA의 JetRacer에 설치해둔 상태입니다. 보드에 대한 정보는 이곳 에서 확인하실 수 있습니다.
2. OS 설치 및 환경 설정
앞서 말씀드린 NVIDIA의 JetsonNaNO 2GB Developer Kit 보드를 사용하기 위해서는 가장 먼저 보드에 OS를 깔고 환경설정을 해주어야 합니다. 이 내용은 지난 학기 저희가 제작한 영상에서 자세하게 확인하실 수 있습니다.
https://youtu.be/guaQbUvPNYM
과정을 간단하게 요약하면 다음과 같습니다. (영상을 따라하시는 것을 더 추천드리며, 영상을 따라하실 경우 8. pip3 install 만 따로 해주시면 됩니다.)
-
Etcher 프로그램 설치
-
OS를 설치할 SD카드 초기화
-
JetsonNaNo 2GB Developer Kit SD card image 파일 다운 및 압축 해제 (알집 프로그램 사용은 비추천합니다.)
-
Etcher 프로그램으로 SD카드에 developer kit img 파일 flash
-
JetPack img 파일 다운 및 압축 해제 (마찬가지로 알집 프로그램 사용은 비추천합니다.)
-
Etcher 프로그램으로 SD카드에 jetpack img파일 flash (developer kit img 파일 flash 한 후 그 위에 바로 jetpack img 파일 flash하시면 됩니다.)
-
보드 전원 on, 아래의 코드 입력하여 GUI 환경 사용하도록 설정
sudo systemctl set-default graphical.target sudo reboot -
pip3 install
sudo apt-get install python3 -
wifi 연결
wifi연결까지 마치시면 같은 wifi에 연결되어 있는 pc를 통해 JetsonNano이 주피터노트북에 접속하실 수 있습니다. JetsoNano의 IP address를 확인하시고 PC에서
http://[IP address]:8888
로 접속하시면 됩니다.
3. JetPack 내장 환경 확인
이제, 여러 모델을 돌리는데 필요한 여러 패키지들을 설치하고, 버전을 맞추기 위해 앞서 sd카드에 설치한 jetpack의 내장 환경을 확인할 필요가 있습니다.
Jetson-stats 패키지의 jtop을 사용하면, JetsonNano 보드의 현재 상태들과 내장 환경 등을 확인하실 수 있습니다. 설치 및 실행 코드는 다음과 같습니다.
sudo -H pip3 install -U jetson-stats
sudo jtopjtop을 실행시키면 다음과 같은 화면을 보실 수 있습니다.
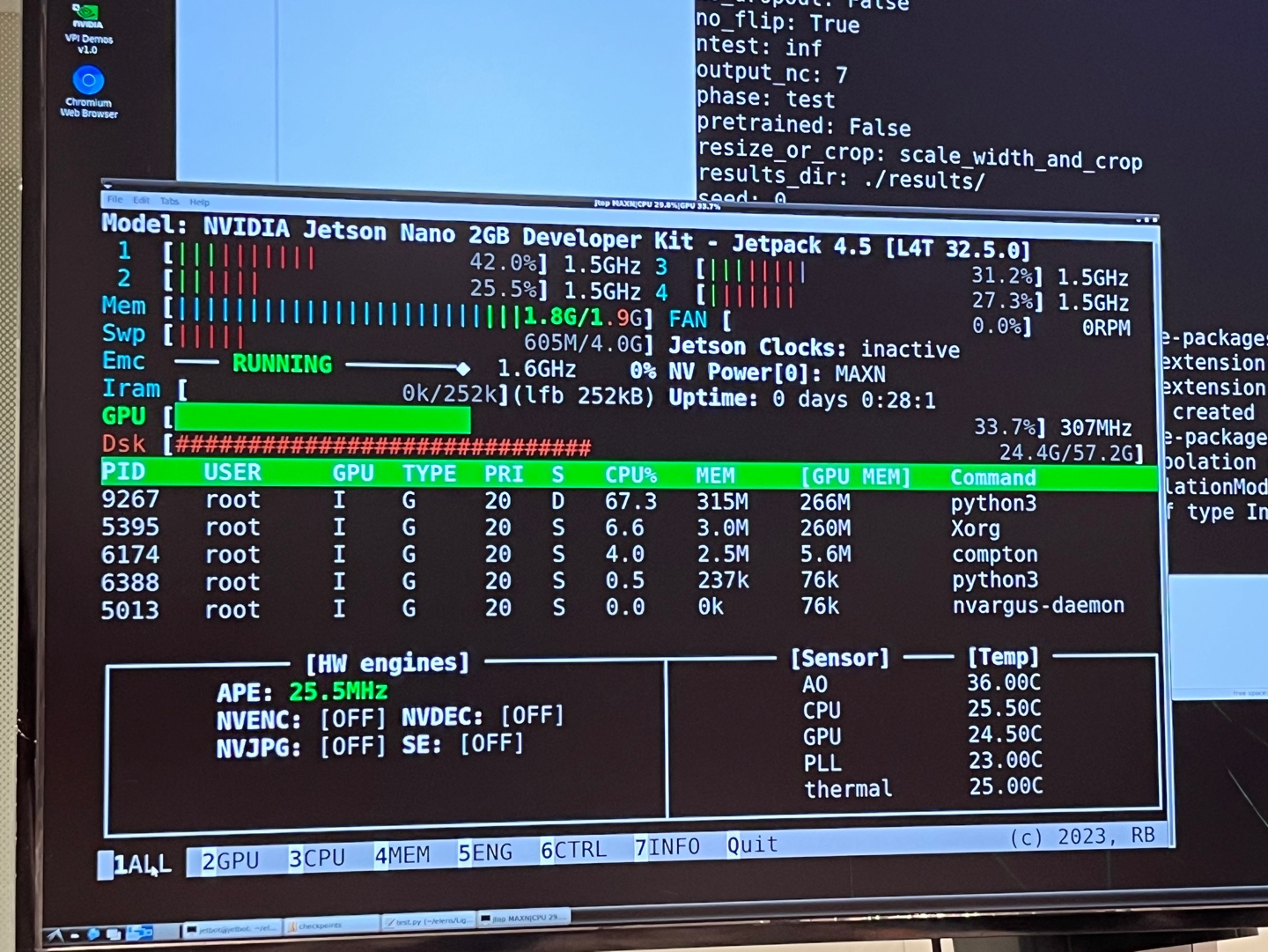
여기서 7 INFO 탭으로 가시면 아래 보시는 것 처럼 Jetpack이나 CUDA 버전 등 내장 환경을 확인하실 수 있습니다.
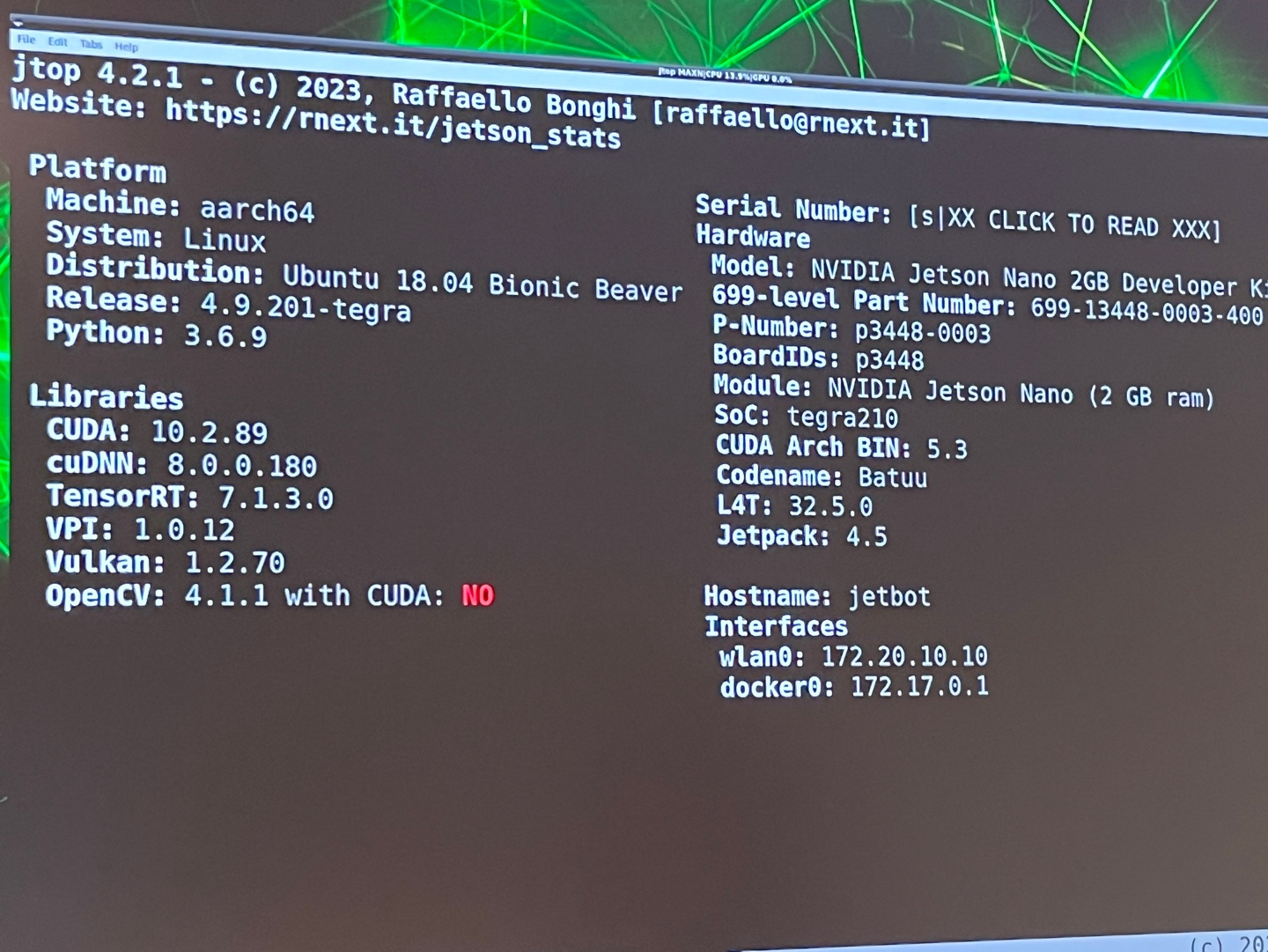
사진에서 보시는 것과 같이, 저희가 설치한 jetpack img 파일의 주요 내장 환경은 CUDA 10.2.89, python 3.6.9, jetpack 4.5 버전입니다.
4. Torch Install
다음으로 딥러닝 모델에서 사용할 Torch를 install 해 주어야 하는데요, 저희가 JetsonNaNo 보드에 모델을 올릴 때 가장 많은 우여곡절을 겪은 과정입니다. 결론부터 말씀드리자면,
JetPack에 내장되어있는 python3.6 버전을 python3.7 버전으로 업그레이드 하지 않는 것이 좋습니다.
저희가 처음에 OS를 설치하고 환경설정을 하면서 Developer kit img파일을 flash하지 않은 채로 바로 jetpack을 flash하는 등의 문제로 보드에서 주피터 노트북을 실행하는 것에서 시행착오를 겪었었는데요, 이 과정에서 문제를 해결하기 위해 python을 3.7 버전으로 업그레이드 시켰습니다.
사실 python 버전 업그레이드가 명확한 해결 방법은 아니었고, 혹시나 python 버전이 낮아서 문제가 생긴것일까 싶어 기도하는 마음으로 python 버전을 업그레이드 한 것이었습니다. 문제의 원인이 python 버전이 아니었기 때문에 python 업그레이드로 문제가 해결되지는 않았고, 더 높은 버전을 깔아두었었기 때문에 굳이 다운그레이드를 하지도 않았었습니다. 그런데 이때 한 파이썬 업그레이드가 torch install 과정에서 문제가 되었습니다.
먼저, JetsonNaNo 보드에 torch를 install하는 과정은 다음과 같습니다.
https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
위 NVIDIA Forum 링크에 접속하시면 torch 버전에 따른 wheel 파일들이 업로드 되어 있습니다. JetsonNaNo에서 이 링크에 접속하셔서 앞서 확인하신 Jetpack 버전에 맞는 것으로 whl 파일을 다운받아주신 뒤, 터미널에서 아래 코드를 실행시켜주시면 됩니다.
pip3 install [다운받은 whl 파일 경로]그런데 처음에 업그레이드 해 둔 python3.7을 사용했을 때 이 과정에서 아래와 같은 에러가 떴습니다.
[whl파일명] is not a supported wheel on this platform
이 오류는 install 하는 torch whl 파일과 python 버전이 맞지 않아 발생하는 오류입니다.
저희가 python3.7 상에서 jetpack 버전 4.5임을 확인했고, torch 1.10.0 버전을 install 위해 앞선 NVIDIA Forum 링크에서 이런 이름의 whl 파일을 다운받았습니다.
torch-1.10.0-cp36-cp36m-linux_aarch64.whl
이 파일을 install 했더니 위와 같은 not supported wheel 오류가 떴는데요, whl 파일 명 상에서 볼드체로 표시된 숫자가 해당 whl 파일에 알맞는 python 버전입니다. 저희가 install 하려 했던 whl torch 1.10.0 whl 파일은 python3.6 버전에 맞는 파일이었던거죠. 그런데 그 때의 JetsonNaNo 에는 python3.7이 깔려있었고, 그렇기 때문에 not supported wheel 에러가 발생한 것입니다.
not supported wheel 에러의 발생 원인이 python 버전 문제임을 알게 된 후, 이를 해결하고 torch를 install하기 위해 python 버전을 python3.6으로 다시 다운그레이드 하려 했습니다. 파이썬을 다운그레이드 하는 코드는 이 링크를 참고하시면 되는데요, 저희의 경우에는 링크에 있는 대로 해도 파이썬 다운그레이드가 되지 않아(이 문제는 아직도 원인을 찾지 못했습니다.) 결국 sd카드를 초기화 하고 OS설치부터 다시 진행했습니다.(ㅎㅎㅠㅠ)
그러니 torch를 설치하실 때
1. 파이썬 버전을 확인하시고
2. jetpack 버전을 확인하시고
3. 그 버전들에 맞는 원하는 버전의 torch whl 파일을 다운 받아 pip3로 install
하시면 됩니다.
5. Requirements install
다음은 간단합니다. 모델을 돌리는 데 필요한 requirements들을 버전에 맞게 install 해주시면 됩니다. install 하실 때 버전이 맞지 않는 패키지의 경우에는 install 가능한 버전들을 list up 해 줍니다. 그 중 골라서 install 하시면 됩니다.
6. Git clone
JetsonNano 보드에 올리고자 하는 모델을 깃에서 가져옵니다. 늘 하시던 대로 터미널에서 git clone을 하시면 됩니다.
git clone [github link]7. 모델 실행
이제 실질적으로 보드에 모델을 올리는 마지막 단계입니다. clone 해 두었던 모델을 실행하면 됩니다! 저희 같은 경우에는 모델이 잘 실행되는지 확인하기 위해 일부 데이터를 임의로 뽑아 test 파일에 넣어 실행시켜 보았습니다. 그 결과, 다음과 같이 모델이 잘 돌아가는 것을 확인할 수 있었습니다.
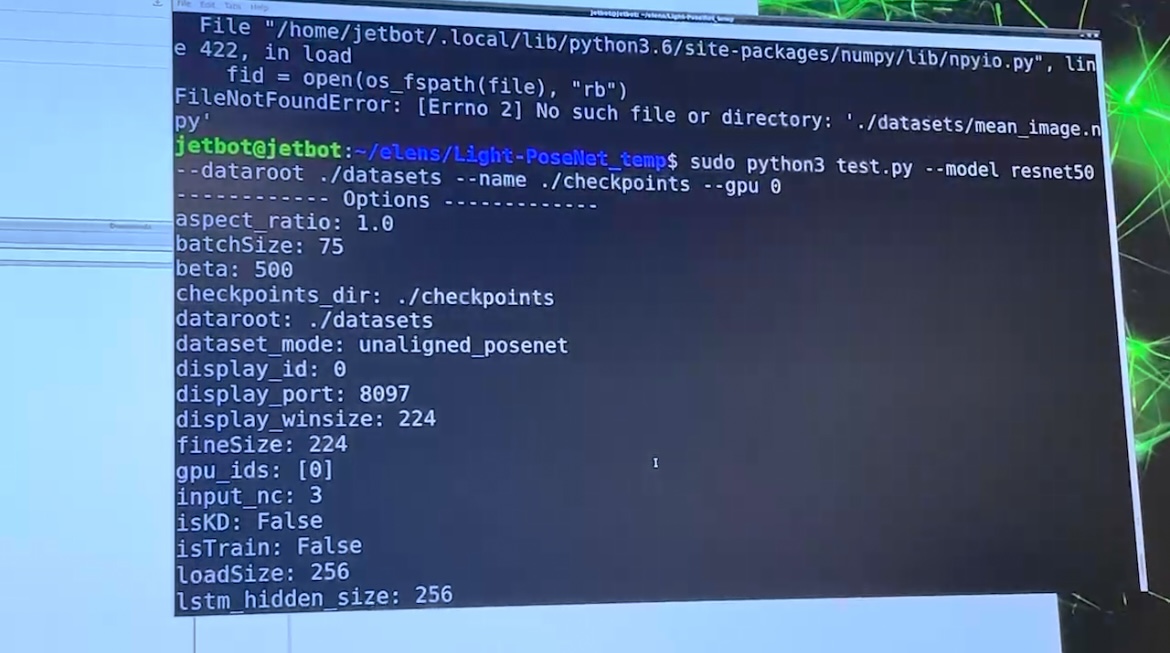
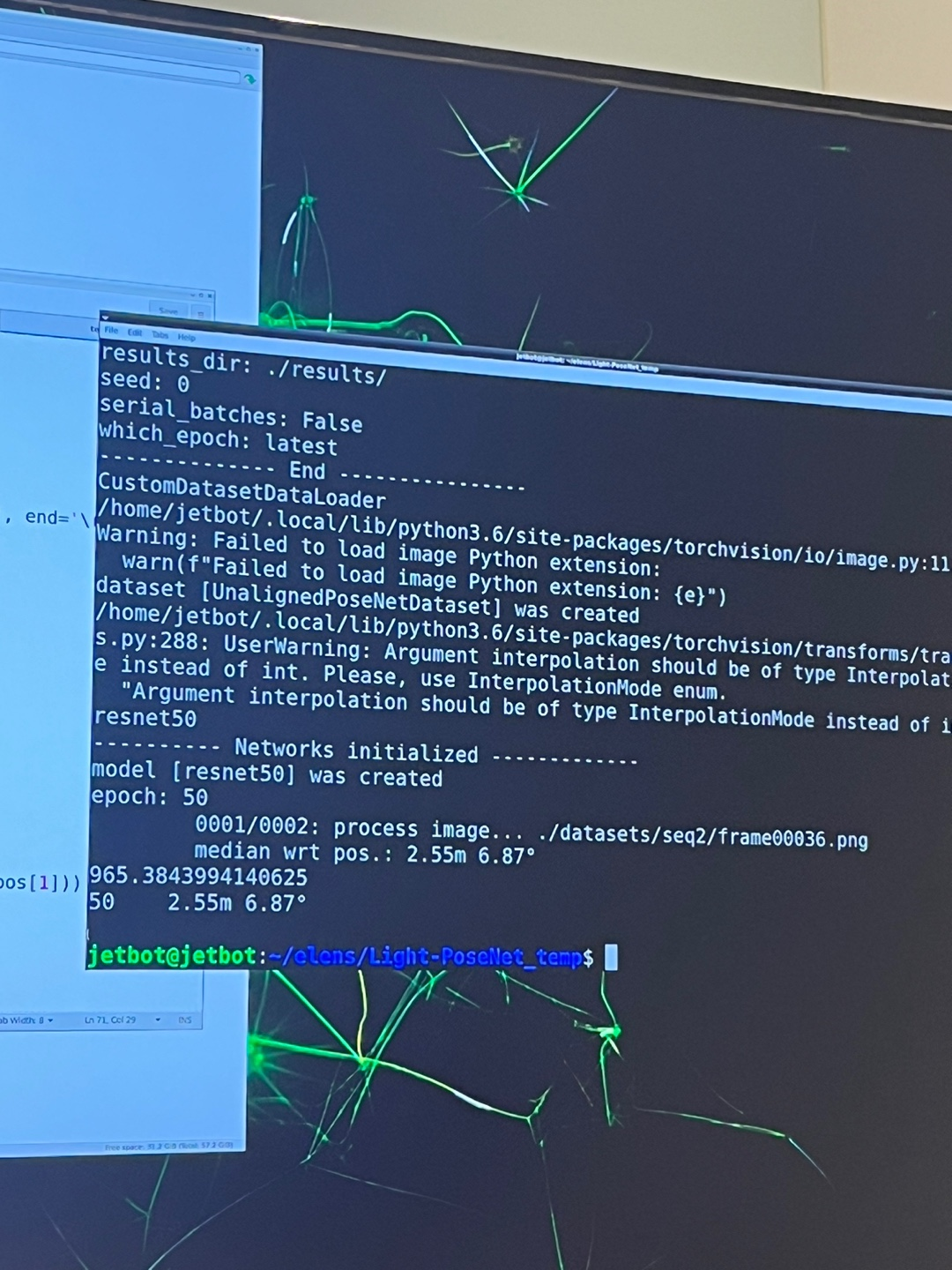
시험삼아 train 과정에서 저장된 모델 pth파일 중 아무 파일이나 사용했더니 성능이 그리 좋지는 않게 나왔습니다. 그래도 모델은 잘 돌아 가는 것을 확인할 수 있었습니다.
8. CPU, GPU 사용량 확인
이제 저희가 경량화 한 모델과 기존 모델을 각각 돌려보고, 각 모델로 camera pose를 예측할 때 JetsonNaNo 보드의 CPU, GPU사용량을 살펴 볼 차례입니다. 앞서 내장 환경을 확인 할 때 사용했던 jtop을 사용하면, CPU와 GPU 사용량을 실시간으로 모니터링하실 수 있습니다.
sudo jtop또, tegrastats를 사용하는 방법도 있습니다.
sudo tegrastats다만, tegrastats의 경우 값들이 아래 사진과 같은 형태로 출력되어 직관적으로 이해하기 어려워 그리 추천드리지는 않습니다.(저희의 경우에는 이해하는 데 어려움이 있었습니다.) tegrastats 출력값들에 대한 정보는 이곳에서 확인 가능합니다.

9. Inference Time 확인
다음으로, 기존 모델과 저희가 경량화한 모델의 Interference Time을 비교해봤습니다. interference time 측정에는 torch.cuda.EVENT를 사용했습니다. 정확한 코드는 다음과 같습니다.
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
[Inference time 측정이 필요한 코드]
end.record()
torch.cuda.synchronize()
print("[Batch Computation Time] ", start.elapsed_time(end))측정 결과, resnet50을 BackBone으로 사용한 기존 모델은 평균 inference time이 125 정도 나왔고, resnet18을 BackBone으로 사용하여 저희가 경량화한 모델은 inference time이 60 정도로 나왔습니다. 그 중간인 resent34를 backbone으로 사용한 모델은 90 정도의 inference time이 걸리는 것으로 나타나 모델이 복잡할수록 inference에 오랜 시간이 걸리는 것을 실험적으로도 확인할 수 있었습니다.
한 가지 주의해야 할 점은, GPU를 사용해서 inference를 진행하게 되면 처음 몇 개의 데이터에 대해서는 모델 복잡도에 관계 없이 inference time이 매우 크게 나타납니다. 그리고 점차 해당 모델의 평균적인 inference time으로 수렴해가게 되는데요, 이는 GPU의 예열이 필요하기 때문이라고 합니다. 그래서 저희는 보다 정확한 inference time을 얻기 위해 진짜 데이터를 모델에 넣기 전에, 랜덤 값을 가지는 더미 데이터를 생성해 모델에 넣어줌으로써 GPU를 예열하고 이후 진짜 데이터로 inference time을 측정했습니다. (해당 내용에 대해서는 아직 아는 바가 많지 않아 참고 정도로만 봐주시면 감사하겠습니다.)
10. 전력 소모 측정 관련 내용
마지막으로, 기존 모델과 저희가 경량화한 모델의 전력 소모를 측정하여 비교하고자 합니다. 그런데 결론부터 말씀드리면,
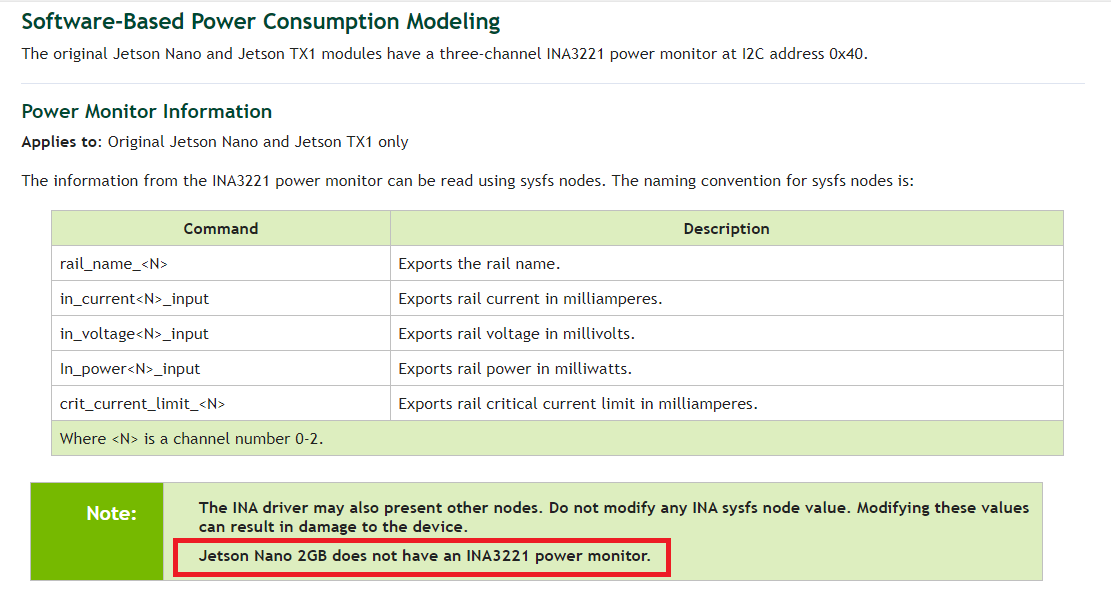
JetsonNaNo 2GB Developer Kit으로는 전력 소모를 정확하게 모니터링 할 수 없습니다.
같은 라인의 모델인 4GB 보드에서는 가능합니다. 이는 2GB 보드에 INA 모듈이 없기 때문입니다.
tegrastats, Ups power module을 비롯하여 4GB 보드에서 power consumption을 측정할 수 있다고 되어있는 거의 모든 방법을 저희가 가진 2GB 보드에서 시도해 보았는데요, command가 없다고 뜨거나 다른 지표들은 확인 가능한데 power consumption을 확인할 수 있는 지표는 나타나지 않거나... 등등 이었습니다.
뿐만 아니라, NVIDIA 페이지에도 2GB 보드에서는 측정이 불가능하다고 명시되어 있습니다.
이에 저희는 약간 부정확할 수 있더라도 실행 가능한 방법으로 모델 별 전력 소모 측정을 계획하고 있습니다. 배터리를 동일하게 일정량 충전해둔 뒤 기존 모델과 경량화된 모델을 각각 실행시켜 배터리가 소모되는 시간을 측정하는 것입니다. 해당 실험은 아직 진행 전이기 때문에, 실험 결과가 나오는 대로 포스팅 내용에 추가하도록 하겠습니다.
혹시라도, 이 글을 보시는 분들 중 JetsonNaNO 2GB 보드에서 Power Consumption을 측정하는 방법을 아시는 분이 계시다면 댓글 달아주시면 정말 감사하겠습니다!
이와 같이 저희가 JetsonNaNo 보드에 딥러닝 모델을 올리고, 실행시키는 과정에서 겪은 것들과 알게된 것들을 정리해 보았습니다.
저희를 포함한 누군가가 원하는 딥러닝 모델들이 원하는 보드에서 무사히 실행되기를 바라면서 이만 줄이겠습니다. 읽어주셔서 감사합니다!
