안녕하세요.
졸업프로젝트를 시작한지 3개월, 그리고 그 졸업프로젝트를 위해 PoseNet 관련 프로젝트를 진행한지는 2개월 정도 된 듯 합니다.
저희 프로젝트는 PoseNet을 경량화 함으로써 실내 자율주행 로봇의 배터리 효율을 높이는 것을 목표로 하고 있습니다. 나아가, 실내 자율주행 로봇이 저희가 경량화한 모델을 학습하여 특정 공간 내에서 로봇이 실제로 자율주행을 할 수 있도록 구현하는것이 이번 프로젝트의 최종 목표입니다. 이를 위해서는 다음과 같은 단계들이 필요합니다.
——
1. PoseNet 논문 이해
2. PoseNet 논문 구현 (기존의 데이터셋 이용)
3. PoseNet 모델 경량화
4. 자율주행을 구현할 실제 공간 선정 및 데이터셋 생성
5. 생성한 데이터셋을 이용한 학습
6. 실제 자율주행 구현
——
‘졸업프로젝트-eLENS’ 시리즈의 게시글 역시 위와 같은 흐름으로 흘러갈 예정이며, 첫 번째로 이번 글에서는 '1. PoseNet 논문 이해'를 위해 간단히 논문 리뷰를 진행한 뒤 '2. PoseNet 논문 구현 (기존의 데이터셋 이용)' 에 대해 다루려고 합니다.
1. PoseNet 논문 이해
먼저, PoseNet에 대해 이해하기 위해 해당 논문을 간략하게 살펴보겠습니다.
PoseNet은 2015년, ICCV에 게재된 Alex Kendall,Matthew Grimes,Roberto Cipolla의 논문 'PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization'에서 처음 제안되었습니다.
정말 간단하게 말하면 어떤 건물이나 사물에 대해 영상을 찍어 학습을 시키면, 이후 해당 object의 사진이 주어졌을 때 그 사진이 어떤 위치와 방향에서 찍힌 것인지 6-Dof로 알려주는 모델입니다. (6-dof 중 3dof는 위치, 또 다른 3dof는 orientation을 나타냅니다.) 즉, PoseNet의 output인 pose vector p는 camera position x와 quaternion으로 나타나는 orientation vector q로 이루어진 p=[x,q] 입니다. p는 3D의 arbitrary global reference frame이고, q는 orientation을 나타내는 4개의 값으로 이루어진 quaternion입니다. 실제 논문에서 사용한 데이터로 좀 더 설명드리겠습니다.
논문에서 사용한 첫번째 데이터는 'Cambridge'데이터로, 이름 그대로 Cambridge의 5개 랜드마크에 대한 데이터입니다. 데이터 생성은 단순히 랜드마크들에 대한 영상 촬영으로 이루어집니다. 이는 곧, 해당 모델을 학습하는데 필요한 데이터를 생성하기 위한 비용이 굉장히 적음을 시사합니다. 실제 데이터 생성에 사용된 Cambridge - King's College 영상중 하나의 일부 구간 입니다.

해당 데이터는 이곳에서 다운받을 수 있습니다. 보시는 것 처럼 비가 내리는 흐린 날의 영상도 있고, 쨍쨍한 맑은 날의 영상도 있습니다. 뿐만 아니라 해당 논문에서는 7Scenes Data를 이용하여 실내 환경에 대한 훈련도 진행했습니다. 하지만 설명의 편의성을 위하여 이번 섹션에서는 Cambridge-King's College 데이터만 다루고, '2. PoseNet 논문 구현 (기존의 데이터셋 이용)'에서 7scenes Data를 다루도록 하겠습니다.
다시 돌아와서, 그렇다면 과연 영상을 가지고 어떻게 카메라의 pose를 예측하는 모델을 학습시키는 걸까요? 또, 그 모델은 어떤 Network Architecture를 가지고 있을까요? 하나하나 살펴보겠습니다.
1) PoseNet Model Architecture
먼저 PoseNet 모델의 아키텍처를 살펴보겠습니다. PoseNet은 GoogleNet Structure를 기반으로 합니다. GoogleNet은 22 Layer의 Convolutional Network이며, 6개의 'inception module'을 포함합니다.
Posenet은 이러한 GoogleNet을 다음과 같이 수정했습니다.
Replace all three softmax classifiers with affine regressors. The softmax layers were removed and each final fully connected layer was modified to output a pose vector of 7-dimensions representing position(3) and orientation(4)
Insert another fully connected layer before the final regressor of feature size 2048. This was to form a localization feature vector which may them be explored for generalisation.
At test time we also normalize the quarternion orientation vector to unit length.
추가적으로, 논문에서 제시하는 PosetNet 모델은 Stochastic Gradient Descent를 위한 loss function으로 다음과 같은 Euclidean loss를 사용합니다.

loss function에서 β는 position과 orientation의 loss에 대한 가중치를 어디에 더 많이 둘 것인지를 결정하는 scale factor입니다.
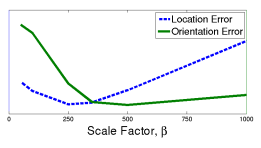
β가 커질수록 orientation error가 작아짐을 확인하실 수 있습니다.
2) Experiments & Results
앞서 단순히 랜드마크에 대한 영상 촬영 만으로 데이터를 모델 훈련을 위한 데이터 셋을 생성할 수 있다고 했던 것을 기억하실까요? 사실 영상으로부터 모델 훈련을 위한 데이터(라벨) 생성하기 위해 다음과 같은 추가적인 처리가 필요합니다.
1) 동영상으로부터 frame들을 추출
2) structure from motion 을 이용하여 frame별로 자동으로 label생성 (camera pose 라벨)
다행인 점은, 저희가 사용할 King's College 데이터와 7secenes 데이터는 위의 과정들(frame sequence 제작 + 라벨링)을 모두 거친 데이터가 제공된다는 점입니다.(7scenes의 경우에는 좀 더 추가적인 작업이 약간 필요하긴 하지만요.)
논문에 따르면, 실험 결과 PoseNet은 다른 모델들과 비교했을 때 모든 dataset에서 median 정도의performance를 보입니다.
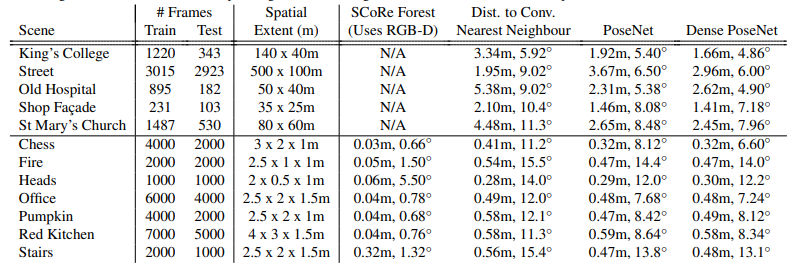
위 사진에서 연두색은 training, 빨간색은 prediction, 파란색은 true label을 나타냅니다. 제법 잘 예측한 것을 확인하실 수 있습니다.
3) PoseNet의 의미
그렇다면 이렇게 사진을 찍은 위치와 방향을 알려주는 PoseNet을 어떻게 활용할 수 있을까요?
PoseNet처럼 이미지만으로 camera의 위치를 예측하는 기술을 Visual localiztion 이라고 합니다. 이러한 Visual localization 기술은 robotics 특히 자율주행의 핵심 기술로 떠오르고 있습니다. 어떻게 보면 당연합니다. 내가 어디에 있는지 제대로 알아야, 어디로 어떻게 갈 지 정확하게 알 수 있으니까요. 따라서 PoseNet은 부가적인 센서 없이 이미지 만으로 localization을 가능하게 한다는 점에서 상당한 의의가 있습니다. 또, GPS가 많게는 몇 미터의 오차를 가지고, 지하나 실내에서는 제대로 작동하지 않는다는 점에서 더더욱이요.
2. PoseNet 논문 구현 (기존의 데이터셋 이용)
이제 이 PoseNet의 구현 코드를 살펴보고, Microsoft의 7scenes Dataset 으로 직접 모델을 train 시키고 test까지 해보겠습니다.
Training 과 Testing은 github https://github.com/hazirbas/poselstm-pytorch 를 clone하여 진행합니다.
1) Data Preprocessing
7scenes Dataset은 7가지 공간이나 사물에 대한 tracked RGB-D camera frame과 해당 frame의 depth, camera coordinates가 sequence 별로 포함되어 있습니다.
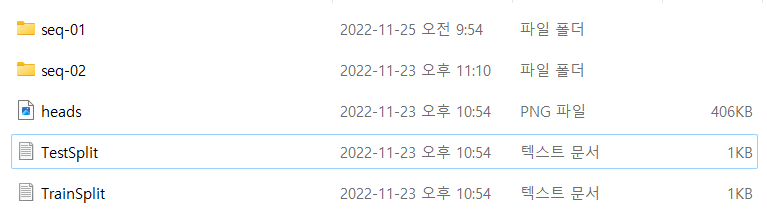
각 sequence 폴더는 다음과 같이 구성되어 있습니다. 7scenes 중 하나인 heads 데이터 셋의 seq-01 일부 입니다.
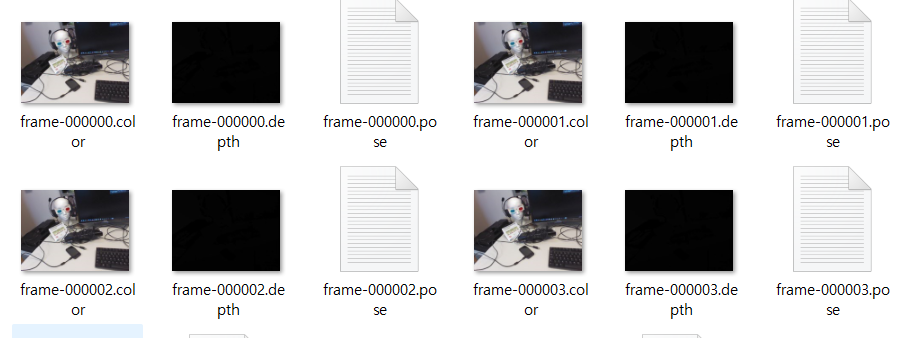
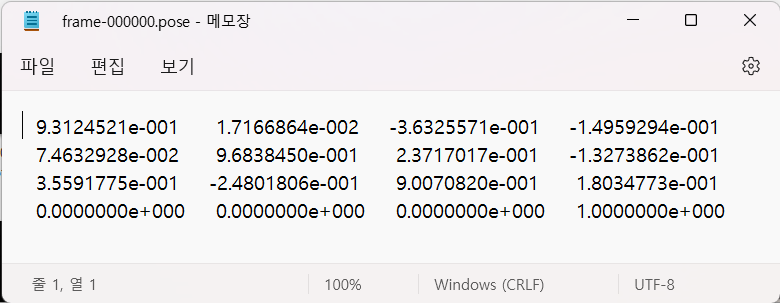
frame-000000.color 는 모델 훈련에 사용해야 할 RGB-D image 입니다. 그리고 각 image에 해당하는 camera coordinates가 frame-000000.pose 에 저장되어 있습니다. train image인 frame-000000.color와 train label에 해당하는 frame-000000.pose를 살펴보면 다음과 같습니다. (frame-000000.depth는 사용하지 않습니다.)

앞서 train, test를 위해 clone을 한다고 언급했던 깃허브의 코드에서는 논문 이해 파트에서 언급했던 KingsCollege 데이터를 사용하여 model train 및 test를 진행합니다. 하지만 저희는 실내 주행에 목적을 두는 만큼, 실내 데이터인 7scenes data에 중점을 두고 구현을 하려고 합니다. 그런데 한가지 주의해야 할 점은 KingsCollege 데이터와 7scenes 데이터의 camera pose(label)에 대한 데이터 형식이 다르다는 것입니다. 두 데이터가 어떻게 다른지 살펴보겠습니다.
다음은 King's College 데이터셋의 camera pose 데이터입니다.
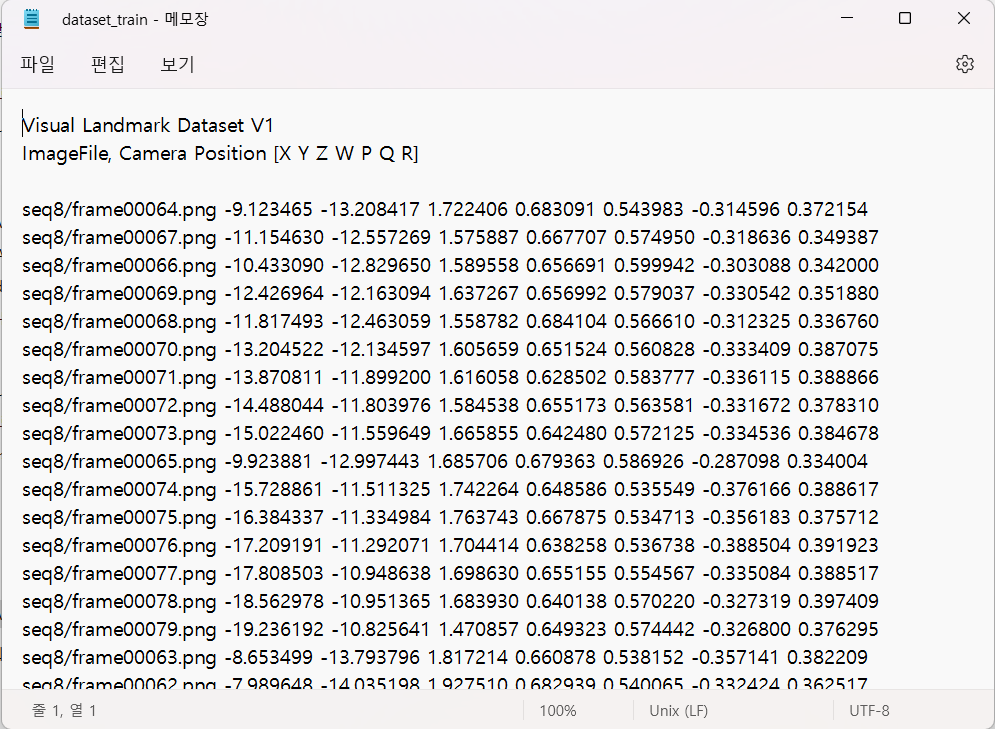
보시는 것과 같이 하나의 image frame 당 총 7개의 숫자가 존재합니다. 논문 이해 섹션에서 말씀드린 PoseNet의 output과 같은 6-dof형태 ( p=[x,q] )입니다. 스크롤을 조금만 올려 heads 데이터의 frame-000000.pose에서 camera pose data로 4x4 matrix가 주어진 것을 보면, 두 데이터가 확실히 다른 형태로 이루어져 있음을 알 수 있습니다. 그렇다면 두 가지 다른 형태의 데이터는 각각 어떻게 camera pose를 나타내는 것일까요?
먼저 King's College의 camera pose 는 6-dof의 camera pose로 데이터에 나타난 순서대로 [X,Y,Z,W,P,Q,R] 을 의미합니다. (X,Y,Z)는 Position(위치)를 나타내고 (W,P,Q,R)는 Orientation(회전, 기울기)를 나타내는 Quaternion입니다. PoseNet의 output인 p=[x,q]와 정확히 같은 형태입니다.
7scenes data에 있는 camera pose는 앞서 잠깐 언급했던 것 처럼 camera의 coordinates로, 4x4 행렬로 주어집니다.
이 4x4 행렬을 Transformation matrix라고 부릅니다. 이 Transformation matrix는 Rotation matrix라고 불리는 행렬과 translation vector라고 불리는 벡터로 나누어 지는데요, 단순히 왼쪽 위 3x3 행렬이 Rotation matrix(R)이고, 4열의 1행~3행이 translation vector(T)가 됩니다. 다시말해, Translation matrix는 [R T; 0 0 0 1] 으로 구성된 것이죠. 사진으로 보시면 다음과 같습니다.

각 행렬과 벡터가 의미하는 바는 이곳을 참고하시면 이해에 좀 더 도움이 될 듯 합니다. Camera 좌표계와 그에 따른 Rotation matrix, translation vector에 대한 설명이 있습니다.
Python으로는 다음과 같은 코드로 Transformation matrix로 부터 Rotation matrix와 translation vector를 쉽게 분리해낼 수 있습니다.
import numpy as np
Transformation= [[ 9.3124521e-001,1.7166864e-002,-3.6325571e-001,-1.4959294e-001],
[7.4632928e-002,9.6838450e-001,2.3717017e-001,-1.3273862e-001,],
[3.5591775e-001,-2.4801806e-001,9.0070820e-001,1.8034773e-001],
[0.0000000e+000,0.0000000e+000,0.0000000e+000,1.0000000e+000]]
transformation=np.array(Transformation)
rotation=transformation[0:3,0:3]
translation=transformation[0:3,3]Rotation matrix와 translation vector가 있으면, position(X,Y,Z)과 quarternion(W,P,Q,R)을 구하는 것은 어렵지 않습니다. python scipy에서 관련 패키지 scipy.spatial.transform 을 제공하기 때문입니다. 해당 패키지의 Rotation.as_quat()를 이용하면, 다음과 같이 4개의 값으로 이루어진 quarternion을 구할 수 있습니다. 또, Position을 나타내는 (X,Y,Z)는 translation vector와 같습니다. Python 코드도 함께 살펴보시죠.
from scipy.spatial.transform import Rotation as R
#position is the origin
X,Y,Z=translation
r=R.from_matrix(np.asarray(rotation))
heading=r.as_quat()
W,P,Q,R=(heading[0],heading[1],heading[2],heading[3])
print(X,Y,Z,W,P,Q,R)이제 7scenes 데이터를 PoseNet 코드에서 사용할 수 있도록 모두 [X,Y,Z,W,P,Q,R] 형태로 변환할 수 있습니다. 7scenes 데이터의 경우 이러한 방법으로 6-dof 형태로 변환된 데이터가 이 github에 업로드 되어 있습니다. 그래서 PoseNet model train/test를 위해 올라와 있는 변환된 데이터를 다운받아 사용하셔도 되고, scipy.spatial.transform을 이용해 원본 데이터를 직접 가공해서 사용하셔도 됩니다.
이렇게 가공된 label데이터들을 모아 heads 데이터셋 폴더 내부에 각 image 별 label이 매칭되어있는 dataset_train.txt와 dataset_test.txt를 생성해줍니다. 각각은 다음과 같은 파일입니다.

보시는 바와 같이 heads폴더 내부에서 각 image파일의 경로와 해당 이미지의 6-dof label 이 각 행에 해당합니다.
추가적으로 아주 간단한 한 가지 작업이 더 필요합니다. Train,test 이전에 추후의 오류 방지를 위해 7scenes dataset에 존재하는 frame-000000.color 데이터의 파일 명을 frame-000000_color형태로 바꾸어 주어야 합니다. 저 같은 경우에는 따로 다음과 같은 코드의 python 실행파일을 사용하여 로컬에서 변환 해 주었습니다.
import os
for i in range(1,3):
file_path='D:\\fromC\DataSet\heads\seq'+str(i)
file_names=os.listdir(file_path)
print('\n\n\n\n\n\n\n\n\n##########\nseq',i)
for name in file_names:
if 'color' in name:
newname=name.replace('.color','_color')
os.rename(file_path+"\\"+name,file_path+"\\"+newname)
print(newname)이제 7scenes 데이터를 이용해 PoseNet을 train하고 test할 준비가 끝났습니다!
2) Training & Testing
저는 모든 과정을 google colab으로 진행하였기 때문에 colab 기준으로 설명하겠습니다. 로컬에서도 마찬가지로 진행하시면 됩니다 :)
Training 과 Testing은 github https://github.com/hazirbas/poselstm-pytorch 를 clone하여 진행합니다. 따라서 git clone, 모듈 설치 그리고 clone한 .py 파일 import하여 사용하기 위해 명령 프롬포트 처럼 사용할 주피터 노트북 파일을 'git_clone_heads'라는 이름으로 생성해 주었습니다. 아래의 모든 코드들은 'git_clone_heads.ipynb' colab 파일에서 돌린 코드들입니다.
가장 먼저, Workspace를 설정합니다. 저는 코랩에서 작업을 했기 때문에 구글 드라이브를 마운트 해주었고, 드라이브에 PoseNet이라는 폴더를 만들었습니다.
from google.colab import drive
drive.mount('/content/drive')
cd "/content/drive/MyDrive/PoseNet"그리고 위의 깃허브를 제 Workspace에 clone해 옵니다. !를 사용하여 주피터 노트북에서 바로 clone 실행합니다.
!git clone https://github.com/hazirbas/posenet-pytorch그러면 다음과 같이 PoseNet 폴더 안에 posenet-pytorch 라는 폴더가 생성되고, 그 안에 링크의 깃허브가 clone 된 것을 확인하실 수 있습니다.
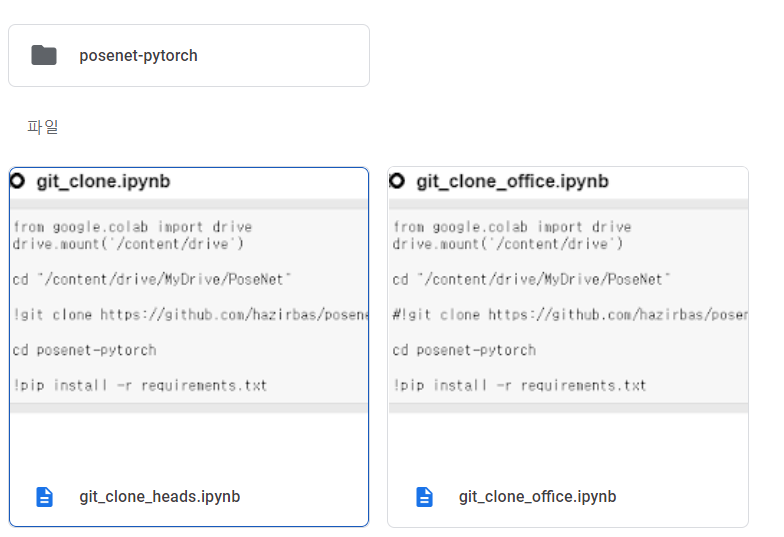
잘 clone 되어 왔습니다. 제가 posenet-pytorch 폴더 내부를 캡쳐한 시점은 모델을 7scenes-heads,office 데이터 셋에 대해 train/test 시킨 이후입니다. 이 때문에 원래 github에 존재하는 data,models, options, util 외의 폴더들이 생성되어 있는 상태이고, git clone을 실행한 직후라면 data, models, options, util 폴더만 있는 것이 정상입니다.
git clone을 무사히 마쳤다면, Workspace를 posenet-pytorch 폴더로 옮겨줍니다. (앞으로 사용해야 할 파일들이 전부 posenet-pytorch 폴더 내부에 있기 때문입니다.)
cd posenet-pytorch그리고 posenet-pytorch 폴더에 있는 requirements.txt 파일을 이용하여 필요한 모듈을 모두 다운받아 줍니다. dominate 모듈 같은 경우에는 requirements.txt가 작성된 시기와 현재의 버전이 달라 따로 또 다운받아 줘야 합니다.
! pip install -r requirements.txt
! pip install dominatepytorch의 경우에는 colab에 내장되어 있기 때문에 error가 뜨는 것이 정상입니다.
그리고 train.py 파일을 실행하는 과정에서 pretrained_model을 사용하기 때문에 pretrained model이 포함된 폴더를 Workspace에 업로드 해야 합니다. pretrained model 폴더는 이 링크에 들어가시면 있는 pretrained_models 폴더를 그대로 다운받아 Workspace에 업로드 해주시면 됩니다.
자! 그럼 이제 본격적인 train을 시작해 보겠습니다.
train/test에 사용할 dataset을 Workspace에 업로드 해야 합니다. 저는 dataset들만 모아두는 datasets 폴더를 새로 만들어 전처리를 마친 heads 폴더를 datasets 내부에 업로드했습니다. 백문이 불여일견, 구글 드라이브에 업로드 되어 있는 heads 폴더를 보여드리겠습니다.

frame sequence 별 폴더가 따로 있고, 가공된 label을 모아둔 dataset_train.txt, dataset_test.txt 등이 있습니다. (현재 시점에서는 mean_image.npy, mean_image.png는 없는 것이 맞습니다.)
데이터셋이 업로드 되었으면, 해당 데이터셋에 대한 mean_image를 계산해주어야 합니다. 이후 posenet model initialize에서 필요한 과정입니다.
!python util/compute_image_mean.py --dataroot datasets/heads --height 256 --width 455 --save_resized_imgsdataroot는 본인이 데이터셋을 모아두는 폴더로 생성한 폴더/데이터셋폴더 (저같은 경우에는 datasets/heads) 로 설정해주시면 되고, image의 height와 width 는 각각 256,455의 일정한 size로 만들어 준 뒤 저장해둡니다.
그럼 이렇게 생성한 mean_image 와 options 폴더의 파일에서 정의되어있는 옵션들을 사용해 model을 initalize하고 train시켜 보겠습니다.
!python train.py --model posenet --dataroot datasets/heads --name posenet/heads/beta500 --beta 500 --gpu 0posenet이라는 이름의 model을 생성하고, datasets/heads 에 있는 데이터를 가지고 train.py를 실행시켜 model을 train 합니다. beta는 PoseNet의 loss function에서 사용되는 Beta scale factor입니다. 또, --gpu0 옵션으로 gpu를 사용하도록 설정해주었습니다. train이 진행됨에 따라 다음과 같이 train 과정이 epoch 마다 출력됩니다.
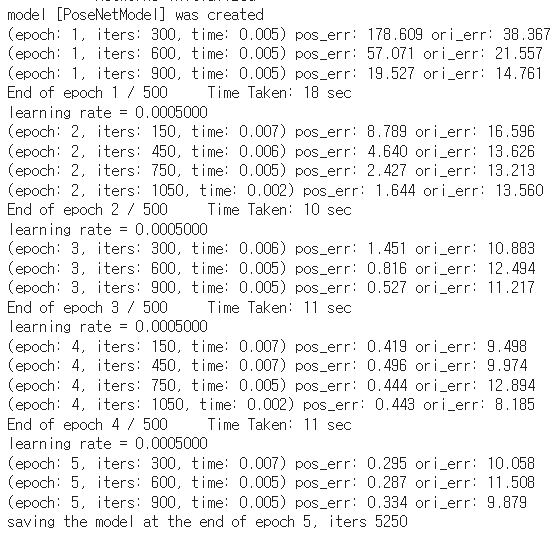

epoch가 증가함에 따라 train loss가 확연히 줄어들었음을 확인하실 수 있습니다. train이 완료되고 나면, train loss log가 Workspace:/checkpoints 폴더 내부에서 txt파일 형태로 저장됩니다.
추가적으로 Posnet model architecture는 models 디렉토리의 networks.py에 구현되어 있습니다.

해당 코드 내에서 ReLu와 같은 Activation Function, InceptionBlock 등을 찾아볼 수 있습니다.
train data로 model을 train 했으니 이제 test를 해 볼 차례입니다. test를 위한 실행 명령은 train을 위한 실행 명령과 크게 다르지 않습니다.
!python test.py --model posenet --dataroot datasets/heads --name posenet/heads/beta500 --gpu 0train과 비슷하게, test가 모두 완료되고 나면 test 결과가 Workspace:/results:/posenet(model이름):/heads(dataset이름):/beta500(설정한 beta값) 내부에 저장됩니다.
보시는 바와 같이 5 epoch 단위로 test prediction 값들이 저장되고, test_median.txt 파일을 통해 epoch 별 median prediction 값도 볼 수 있습니다.
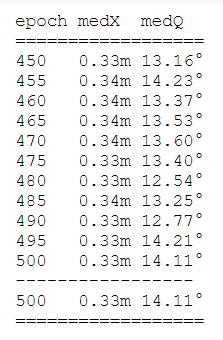
대략 위치 X에 대해서는 0.33m의 오차가, orientation Q대해서는 14.11도 정도의 오차가 있는 것으로 보입니다.
이것으로 PoseNet model의 train과 test가 모두 끝났습니다. 자, 그럼 test data에 대해 PoseNet이 얼마나 잘 predict 했는지 직접 확인해 볼까요? 한 예로, 500 epoch에서 27번(tmi.제가 좋아하는 숫자입니다) test data frame의 prediction과 실제 label을 비교해 보겠습니다.
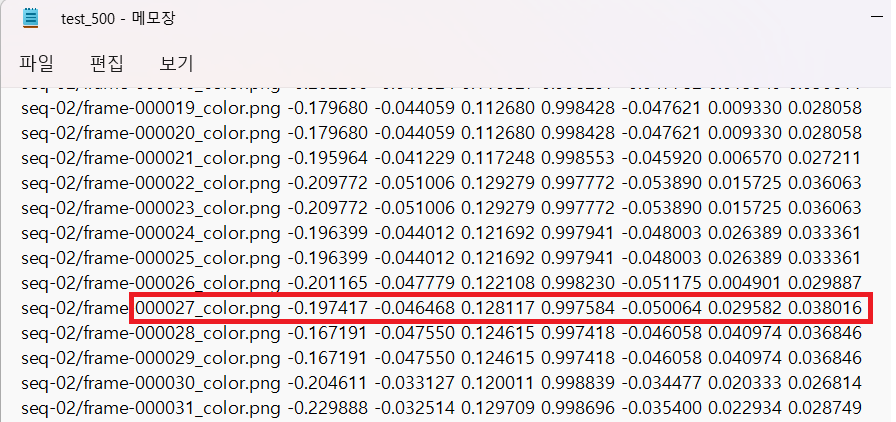
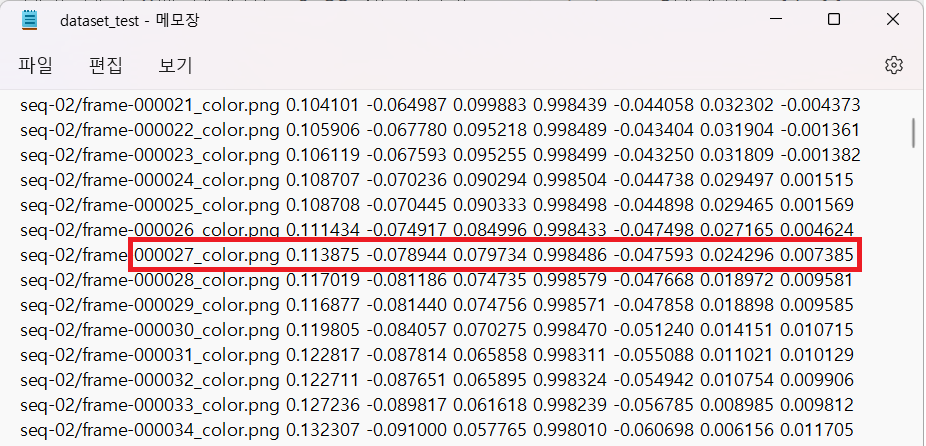
사실, 그냥 단순히 보이는 숫자로만 봤을 때는 소름끼치게 정확한 예측을 한 건 아닌 것 같아 보입니다. 다른 데이터들도 비슷비슷 합니다. 한 가지 주목할 점은, Position(X,Y,Z)을 의미하는 앞의 3개 원소 보다는 Orientation[W,P,Q,R]을 의미하는 뒤 4개 원소가 predict와 label이더 비슷해 보입니다. 이는 Beta를 500으로 크게 설정하였기 때문에 Orientation error가 Lotation error보다 상대적으로 작아지도록 train되었기 때문이라고 생각할 수 있습니다.
이것으로 이번 글은 마치도록 하겠습니다.
프로젝트 목표 달성까지 글의 맨 앞에 간략히 적어둔 것만 해도 3번부터 6번까지 꽤나 많은 단계가 남아 있습니다.
현재는 NVIDIA의 Jetson Nano Car를 작동시켜 보려 애쓰는 중입니다.
산넘어 산이 계속 보이지만, 그래도 한 고개 한 고개 넘어가면서 이 블로그에도 글을 하나하나 늘려가려 합니다.
읽어주셔서 감사합니다.
참고)
PoseNet 논문
PoseNet 구현 github
7scenes dataset
Transformation matrix로부터 Quaternion 구하기

잘 읽었어요~