Model Fitting - Logistic Regression

7. Model Fitting - Logistic Regression
1) Hyper Parameter Tuning
logistic=LogisticRegression(solver='sag')
param_logistic={'C': [0,0.001, 0.01, 0.1, 1, 10, 100], 'penalty' : ['l2','l1','none']}
grid_logistic=GridSearchCV(logistic,param_grid=param_logistic, cv=5, refit=True)
grid_logistic.fit(X_train,y_train)
print("best_param:",grid_logistic.best_params_)
print("mean cv of best parameter:",grid_logistic.best_score_)best_param: {'C': 0.001, 'penalty': 'l2'}
mean cv of best parameter: 0.5545893719806763
- training cv error는 0.55 정도이고, parameter는 'C':0.001, 'penalty':'l2'가 선택되었습니다.
- LogisticRegression객체의 solver parameter는 optimization하는 방법을 지정하는 parameter입니다. scikit learn의 LogisticRegrission 문서를 참고하여 Stochastic Average Gradient descent 방법을 사용하는 sag를 sovler로 지정했습니다.
- reference : https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
2) 기대 승률 예측
hyper parameter를 사용한 Logistic Regression 모델에서 예측한 test data에 대한 2Q 종료 후 기대 승률은 다음과 같습니다.
estimator_logistic=LogisticRegression(C=0.001,penalty='l2',solver='sag')
estimator_logistic.fit(X_train,y_train)
probability=estimator_logistic.predict_proba(X_test)
probability
estimator_logistic.classes_array([0, 1])
- estimator_logistic 클래스 내에서 classes가 0,1 순서로 설정되어 있으므로 probability의 첫번째 열이 홈팀이 패배할 확률이고, 두번째 열이 홈팀이 승리할 확률 즉, 기대 승률인 것을 알 수 있습니다.
이를 이용하여 각 test data에 대한 홈팀의 2Q 종료 후 기대 승률을 다음과 같이 구할 수 있습니다. (이미지에는 일부만 포함)
probability[:,1]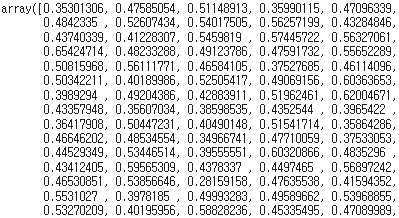
3) 승부 예측
LogisticRegression Classifier의 예측 확률(predict_proba)을 사용한 승부 예측 결과입니다.
preds_logistic=estimator_logistic.predict(X_test)
preds_logistic
- LogisticRegression 클래스는 기대 승률 예측에서 구한 확률값(probability)을 사용하여, 기대 승률이 이 0.5보다 작으면 0(홈팀 패배)로 분류하고, 0.5보다 크면 1(홈팀 승리)로 분류합니다. 즉, probability의 두번째 열의 값인 홈팀의 기대 승률이 0.5보다 크면 홈팀 승리로 예측하고, 그렇지 않으면 홈팀 패배로 예측하는 것이죠.
4) 승부 예측에 대한 Model Evaluation
accuracy_list=[]
precision_list=[]
recall_list=[]
f1_list=[]
for i in range(3):
estimator_logistic=LogisticRegression(C=0.001,penalty='l2',solver='sag')
estimator_logistic.fit(X_train,y_train)
print("\n",estimator_logistic.coef_,"\n")
preds_logistic=estimator_logistic.predict(X_test)
test_accuracy_logistic=accuracy_score(preds_logistic,y_test)
accuracy_list.append(test_accuracy_logistic)
precision_list.append(precision_score(preds_logistic, y_test))
recall_list.append(recall_score(preds_logistic, y_test))
f1_list.append(f1_score(preds_logistic, y_test))
print(i+1," test accuracy of logistic : ",test_accuracy_logistic)
- Confusion Matrix of last testing
confusion_matrix(y_test, preds_logistic)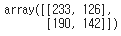
print("accuracy list : ",accuracy_list)
print("mean of test accuracy : ",np.mean(accuracy_list))
print("variance of test accuracy : ", np.var(accuracy_list))
-
train data를 fit할 때마다 coefficient가 아주 약간씩 달라지지만 예측 결과는 변하지 않습니다. 이에 따라 predict accuracy가 계속 같은 값이 나오는 것을 볼 수 있습니다.
-
모델의 평균 test accuracy는 0.5426917510853835 이고 variance는 0입니다.
-
모델의 예측 정확도가 그리 높지 않습니다.
print("precision list : ",precision_list)
print("mean of test precision : ",np.mean(precision_list))
print("recall list : ",recall_list)
print("mean of test recall : ",np.mean(recall_list))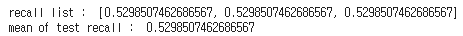
print("f1 list : ",f1_list)
print("mean of test f1 : ",np.mean(f1_list))
- accuracy, recall에 비해 precision이 낮게 나옵니다.
5) 특정 경기에 대한 기대 승률 및 승부 예측
어떤 한 경기에 대한 기대승률 및 승부를 예측하고 싶다면 다음과 같은 과정을 거치면 됩니다. 아래 예시는 2015년 2월 11일에 치러진 Golden State Warriors (Home) 과 Minnesota Timberwolves (Away)의 경기의 전반전 세부 스탯 데이터에 대한 기대 승률 및 승부 예측과정입니다.
# 1. 데이터 입력
test_match_stat=pd.DataFrame(columns=['Team_H','Team_A',
'MP_H','FG_H','FGA_H','FG%_H','3P_H','3PA_H','3P%_H','FT_H','FTA_H','FT%_H','ORB_H','DRB_H','TRB_H','AST_H','STL_H','BLK_H','TOV_H','PF_H','PTS_H',
'MP_A','FG_A','FGA_A','FG%_A','3P_A','3PA_A','3P%_A','FT_A','FTA_A','FT%_A','ORB_A','DRB_A','TRB_A','AST_A','STL_A','BLK_A','TOV_A','PF_A','PTS_A'])
test_match_stat.loc[0]=['GSW','MIN',120,24,46,.522,4,14,.286,4,5,.800,7,21,28,15,4,3,11,7,56, 120,18,46,.391,4,10,.400,6,8,.750,6,14,20,11,5,0,8,7,46]
test_match_stat
#2. data Preprocessing
#1) NA imputation
if(test_match_stat['FT%_H'].empty):
test_match_stat['FT%_H']= -1.0
if(test_match_stat['FT%_A'].empty):
test_match_stat['FT%_A']= -1.0
#2) MP 변수 삭제
test_match_stat=test_match_stat.drop(['MP_H','MP_A'],axis=1)
#3) 2점 야투에 대한 변수 생성 및 전체 야투 변수 삭제
test_match_stat['2P_H']=test_match_stat['FG_H']-test_match_stat['3P_H']
test_match_stat['2P_A']=test_match_stat['FG_A']-test_match_stat['3P_A']
test_match_stat['2PA_H']=test_match_stat['FGA_H']-test_match_stat['3PA_H']
test_match_stat['2PA_A']=test_match_stat['FGA_A']-test_match_stat['3PA_A']
test_match_stat['2P%_H']=test_match_stat['2P_H']/test_match_stat['2PA_H']
test_match_stat['2P%_A']=test_match_stat['2P_A']-test_match_stat['2PA_A']
test_match_stat=test_match_stat.drop(['FG_H','FG_A','FGA_H','FGA_A','FG%_H','FG%_A'],axis=1)
#4) ORB,DRB, Team feature 삭제
test_match_stat=test_match_stat.drop(['ORB_H','ORB_A','DRB_H','DRB_A','Team_H','Team_A'],axis=1)
#4) Log Transformation, Square Transformation
test_match_stat["BLK_H"] = np.log1p(test_match_stat["BLK_H"][0])
test_match_stat["BLK_A"] = np.log1p(test_match_stat["BLK_A"][0])
test_match_stat['FT%_H']=(test_match_stat['FT%_H'])**2
test_match_stat['FT%_A']=(test_match_stat['FT%_A'])**2
#3. Fit 되어 있는 모델 사용하여 Predict
probability_of_victory=estimator_logistic.predict_proba(test_match_stat)
print("홈팀의 2Q 종료 후 기대 승률 : ",probability_of_victory[0][1])
predict_of_victory=estimator_logistic.predict(test_match_stat)
if(predict_of_victory==1):
print("승부 예측 - Home Team 승리 ")
else:
print("승부 예측 - Away Team 승리")

- 해당 경기는 Golden Staete Worriers (Home)가 94:91로 승리했습니다.
