
- 2022년 12월 개인적으로 진행했던 토이프로젝트를 재업로드합니다.
8. Model Fitting - RandomForest
- reference :https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
1) Hyper Parameter Tuning
# define parameter search space
param_grid = {'n_estimators': [100, 200, 350],
'min_samples_leaf': [2, 10, 30],
'max_depth':[3,6,9],
'max_features': ['auto', 'sqrt'],
'criterion': ['gini', 'entropy']}
clf = RandomForestClassifier()
grid_rf = GridSearchCV(clf, param_grid, refit = True, cv=5, verbose = 3, scoring='accuracy')
# fit the model for grid search
grid_rf.fit(X_train, y_train)print("best params:",grid_rf.best_params_)
print("best cv error : ", grid_rf.best_score_)
- training cv error는 0.59 정도이고, parameter는 {'criterion': 'gini', 'max_depth': 6, 'max_features': 'auto', 'min_samples_leaf': 30, 'n_estimators': 100} 이 선택되었습니다.
- max_depth : 트리의 깊이, 트리가 깊을 수록 모델이 복잡해짐
- criterion : 각 트리의 split에서 child node의 impurity를 계산하는 지표
- max_features : 각 트리에서 사용할 feature의 갯수
- min_samples_leaf : 각 트리의 터미널 노드에 속하는 data의 최소 갯수. split 시 min_samples_leaf에 도달하면 split을 멈춤
- n_estimators : 생성할 tree의 갯수
2) 기대 승률 예측
hyper parameter를 사용한 RandomForest 모델에서 예측한 test data에 대한 2Q 종료 후 기대 승률은 다음과 같습니다.
estimator_rf=grid_rf.best_estimator_
estimator_rf.fit(X_train,y_train)
probability_rf=estimator_rf.predict_proba(X_test)
probability_rf
estimator_rf.classes_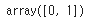
- estimator_rf 클래스 내에서 classes가 0,1 순서로 설정되어 있으므로 probability의 첫번째 열이 홈팀이 패배할 확률이고, 두번째 열이 홈팀이 승리할 확률 즉, 홈팀의 기대 승률입니다.
각 test data에 대한 홈팀의 2Q 종료 후 기대 승률은 다음과 같습니다. (이미지에는 일부 결과만 포함)
probability_rf[:,1]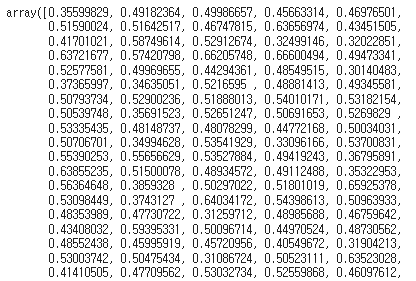
3) 승부 예측
(1) PCA 적용하지 않은 데이터 사용 (estimator_rf)
RandomForest Classifier의 예측 결과입니다.
estimator_rf=RandomForestClassifier(criterion='gini', max_depth= 6, max_features= 'auto', min_samples_leaf= 30, n_estimators= 100)
estimator_rf.fit(X_train,y_train)
preds_rf=estimator_rf.predict(X_test)
preds_rf
(1)-2 Feature Importance 확인
-
RandomForest와 같은 tree기반 모델의 경우, feature importance attribute을 제공합니다. 이 feature importance는 해당 feature가 예측에서 빠졌을 때 모델 성능이 얼마나 나빠지는지를 이용하여 측정합니다.
-
reference : https://github.com/MazeLearner/MachineLearning2022/blob/main/MachineLearning_TeamProject_MazeLearner.ipynb
feature_scores = pd.Series(estimator_rf.feature_importances_, index=X_train.columns).sort_values(ascending=False)
feature_scores
f, ax = plt.subplots()
ax = sns.barplot(x=feature_scores, y=feature_scores.index)
ax.set_yticklabels(feature_scores.index)
ax.set_xlabel("Feature importance score")
ax.set_ylabel("Features")
plt.show()
print(feature_scores[:5])
- 홈팀과 원정팀의 전반 득점이 가장 많은 영향을 미치는 것으로 보이네요.
(2) PCA를 적용한 데이터 사용 (estimator_rf_pca)
- RandomForest Classifier의 승부 예측 결과
estimator_rf_pca=RandomForestClassifier(criterion='gini', max_depth= 6, max_features= 'auto', min_samples_leaf= 30, n_estimators= 100)
estimator_rf_pca.fit(X_train_pca,y_train)
preds_rf_pca=estimator_rf_pca.predict(X_test_pca)
preds_rf_pca
4) 승부 예측에 대한 Model Evaluation
(1) PCA를 적용하지 않은 데이터 사용 (estimator_rf)
accuracy_list=[]
precision_list=[]
recall_list=[]
f1_list=[]
for i in range(3):
estimator_rf.fit(X_train,y_train)
preds_rf=estimator_rf.predict(X_test)
test_accuracy_rf=accuracy_score(preds_rf,y_test)
accuracy_list.append(test_accuracy_rf)
precision_list.append(precision_score(preds_rf, y_test))
recall_list.append(recall_score(preds_rf, y_test))
f1_list.append(f1_score(preds_rf, y_test))- Confusion Matrix of last testing
confusion_matrix(y_test, preds_rf)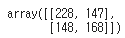
print("accuracy list : ",accuracy_list)
print("mean of test accuracy : ",np.mean(accuracy_list))
print("variance of test accuracy : ", np.var(accuracy_list))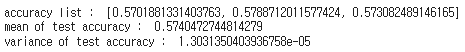
-
train data를 fit할 때마다 예측 결과가 약간씩 달라지고, 이에 따라 predict accuracy도 아주 약간씩 달라집니다.
-
모델의 평균 test accuracy는 0.5740472744814279 이고 variance는 1.3031350403936758e-05으로 0에 가깝습니다.
-
모델의 예측 정확도가 그리 높지 않습니다.
print("precision list : ",precision_list)
print("mean of test precision : ",np.mean(precision_list))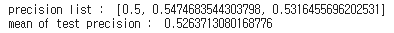
print("recall list : ",recall_list)
print("mean of test recall : ",np.mean(recall_list))
print("f1 list : ",f1_list)
print("mean of test f1 : ",np.mean(f1_list))
(2) PCA를 적용한 데이터 사용 (estimator_rf_pca)
accuracy_list_pca=[]
precision_list_pca=[]
recall_list_pca=[]
f1_list_pca=[]
for i in range(3):
estimator_rf_pca.fit(X_train_pca,y_train)
preds_rf_pca=estimator_rf_pca.predict(X_test_pca)
test_accuracy_rf_pca=accuracy_score(preds_rf_pca,y_test)
accuracy_list_pca.append(test_accuracy_rf_pca)
precision_list_pca.append(precision_score(preds_rf_pca, y_test))
recall_list_pca.append(recall_score(preds_rf_pca, y_test))
f1_list_pca.append(f1_score(preds_rf_pca, y_test))- Confusion Matrix of last testing
confusion_matrix(y_test, preds_rf_pca)
print("accuracy list : ",accuracy_list_pca)
print("mean of test accuracy : ",np.mean(accuracy_list_pca))
print("variance of test accuracy : ", np.var(accuracy_list_pca))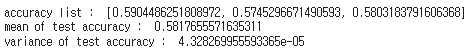
-
train data를 fit할 때마다 예측 결과가 약간씩 달라지고, 이에 따라 predict accuracy도 달라집니다.
-
모델의 평균 test accuracy는 0.5817655571635311 이고 variance는 4.328269955593365e-05 입니다.
-
모델의 예측 정확도가 그리 높지 않습니다.
print("precision list : ",precision_list_pca)
print("mean of test precision : ",np.mean(precision_list_pca))
print("recall list : ",recall_list_pca)
print("mean of test recall : ",np.mean(recall_list_pca))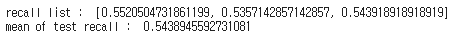
print("f1 list : ",f1_list_pca)
print("mean of test f1 : ",np.mean(f1_list_pca))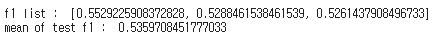
예측 정확도의 경우 PCA를 사용했을 때가 약간 더 높고, 나머지 수치들은 거의 비슷합니다. 따라서 RandomForest를 이용한 분류에는 PCA를 적용한 데이터를 사용하기로 결정했습니다.
6) 특정 경기에 대한 기대 승률 및 승부 예측
어떤 한 경기에 대한 기대승률 및 승부를 예측하고 싶다면 다음과 같은 과정을 거치면 됩니다. 아래 예시는 2015년 2월 11일에 치러진 Golden State Warriors (Home) 과 Minnesota Timberwolves (Away)의 경기의 전반전 세부 스탯 데이터에 대한 기대 승률 및 승부 예측과정입니다.
# 1. 데이터 입력
test_match_stat=pd.DataFrame(columns=['Team_H','Team_A',
'MP_H','FG_H','FGA_H','FG%_H','3P_H','3PA_H','3P%_H','FT_H','FTA_H','FT%_H','ORB_H','DRB_H','TRB_H','AST_H','STL_H','BLK_H','TOV_H','PF_H','PTS_H',
'MP_A','FG_A','FGA_A','FG%_A','3P_A','3PA_A','3P%_A','FT_A','FTA_A','FT%_A','ORB_A','DRB_A','TRB_A','AST_A','STL_A','BLK_A','TOV_A','PF_A','PTS_A'])
test_match_stat.loc[0]=['GSW','MIN',120,24,46,.522,4,14,.286,4,5,.800,7,21,28,15,4,3,11,7,56, 120,18,46,.391,4,10,.400,6,8,.750,6,14,20,11,5,0,8,7,46]
test_match_stat
#2. data Preprocessing
#1) NA imputation
if(test_match_stat['FT%_H'].empty):
test_match_stat['FT%_H']= -1.0
if(test_match_stat['FT%_A'].empty):
test_match_stat['FT%_A']= -1.0
#2) MP 변수 삭제
test_match_stat=test_match_stat.drop(['MP_H','MP_A'],axis=1)
#3) 2점 야투에 대한 변수 생성 및 전체 야투 변수 삭제
test_match_stat['2P_H']=test_match_stat['FG_H']-test_match_stat['3P_H']
test_match_stat['2P_A']=test_match_stat['FG_A']-test_match_stat['3P_A']
test_match_stat['2PA_H']=test_match_stat['FGA_H']-test_match_stat['3PA_H']
test_match_stat['2PA_A']=test_match_stat['FGA_A']-test_match_stat['3PA_A']
test_match_stat['2P%_H']=test_match_stat['2P_H']/test_match_stat['2PA_H']
test_match_stat['2P%_A']=test_match_stat['2P_A']-test_match_stat['2PA_A']
test_match_stat=test_match_stat.drop(['FG_H','FG_A','FGA_H','FGA_A','FG%_H','FG%_A'],axis=1)
#4) ORB,DRB, Team feature 삭제
test_match_stat=test_match_stat.drop(['ORB_H','ORB_A','DRB_H','DRB_A','Team_H','Team_A'],axis=1)
#4) Log Transformation, Square Transformation
test_match_stat["BLK_H"] = np.log1p(test_match_stat["BLK_H"][0])
test_match_stat["BLK_A"] = np.log1p(test_match_stat["BLK_A"][0])
test_match_stat['FT%_H']=(test_match_stat['FT%_H'])**2
test_match_stat['FT%_A']=(test_match_stat['FT%_A'])**2
#5) PCA
test_match_stat=pca.transform(test_match_stat)
#3. Fit 되어 있는 모델 사용하여 Predict
probability_of_victory=estimator_rf_pca.predict_proba(test_match_stat)
print("홈팀의 2Q 종료 후 기대 승률 : ",probability_of_victory[0][1])
predict_of_victory=estimator_rf_pca.predict(test_match_stat)
if(predict_of_victory==1):
print("승부 예측 - Home Team 승리 ")
else:
print("승부 예측 - Away Team 승리")

- 참고로, 해당 경기는 Golden Staete Worriers (Home)가 94:91로 승리했습니다.
